 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Lifting Transformer for 3D Human Pose Estimation in Video
Apr 14, 2021
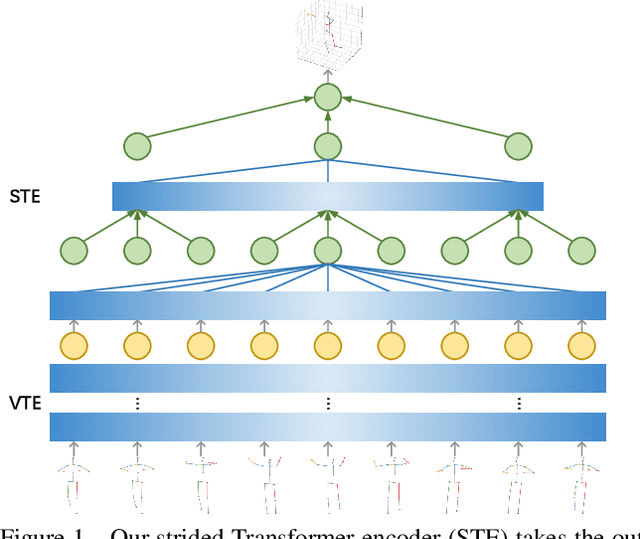
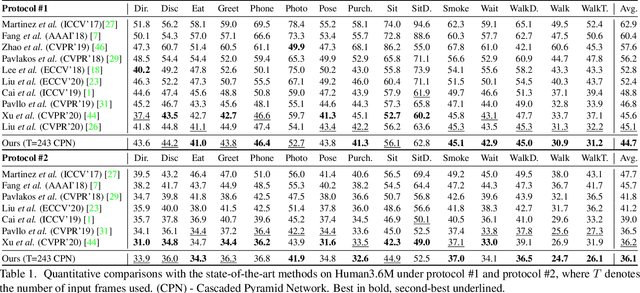
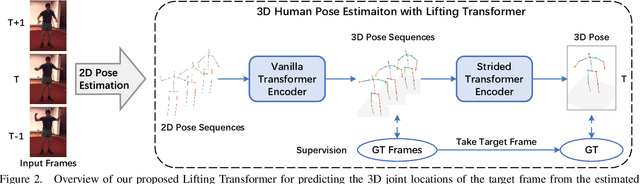
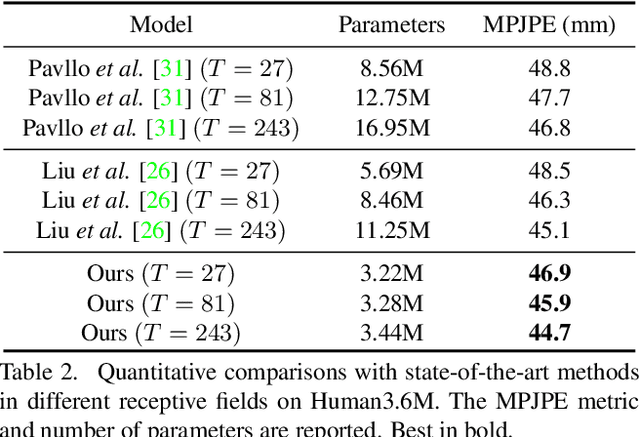
Despite great progress in video-based 3D human pose estimation, it is still challenging to learn a discriminative single-pose representation from redundant sequences. To this end, we propose a novel Transformer-based architecture, called Lifting Transformer, for 3D human pose estimation to lift a sequence of 2D joint locations to a 3D pose. Specifically, a vanilla Transformer encoder (VTE) is adopted to model long-range dependencies of 2D pose sequences. To reduce redundancy of the sequence and aggregate information from local context, fully-connected layers in the feed-forward network of VTE are replaced with strided convolutions to progressively reduce the sequence length. The modified VTE is termed as strided Transformer encoder (STE) and it is built upon the outputs of VTE. STE not only significantly reduces the computation cost but also effectively aggregates information to a single-vector representation in a global and local fashion. Moreover, a full-to-single supervision scheme is employed at both the full sequence scale and single target frame scale, applying to the outputs of VTE and STE, respectively. This scheme imposes extra temporal smoothness constraints in conjunction with the single target frame supervision. The proposed architecture is evaluated on two challenging benchmark datasets, namely, Human3.6M and HumanEva-I, and achieves state-of-the-art results with much fewer parameters.
Stein Latent Optimization for GANs
Jun 09, 2021
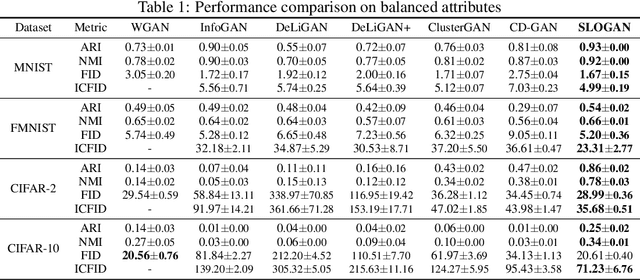

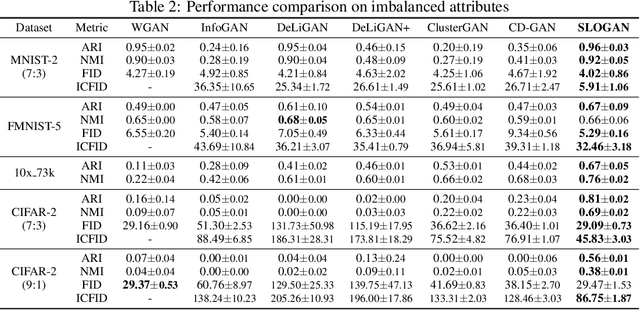
Generative adversarial networks (GANs) with clustered latent spaces can perform conditional generation in a completely unsupervised manner. However, the salient attributes of unlabeled data in the real-world are mostly imbalanced. Existing unsupervised conditional GANs cannot properly cluster the attributes in their latent spaces because they assume uniform distributions of the attributes. To address this problem, we theoretically derive Stein latent optimization that provides reparameterizable gradient estimations of the latent distribution parameters assuming a Gaussian mixture prior in a continuous latent space. Structurally, we introduce an encoder network and a novel contrastive loss to help generated data from a single mixture component to represent a single attribute. We confirm that the proposed method, named Stein Latent Optimization for GANs (SLOGAN), successfully learns the balanced or imbalanced attributes and performs unsupervised tasks such as unsupervised conditional generation, unconditional generation, and cluster assignment even in the absence of information of the attributes (e.g. the imbalance ratio). Moreover, we demonstrate that the attributes to be learned can be manipulated using a small amount of probe data.
Quantifying Predictive Uncertainty in Medical Image Analysis with Deep Kernel Learning
Jun 01, 2021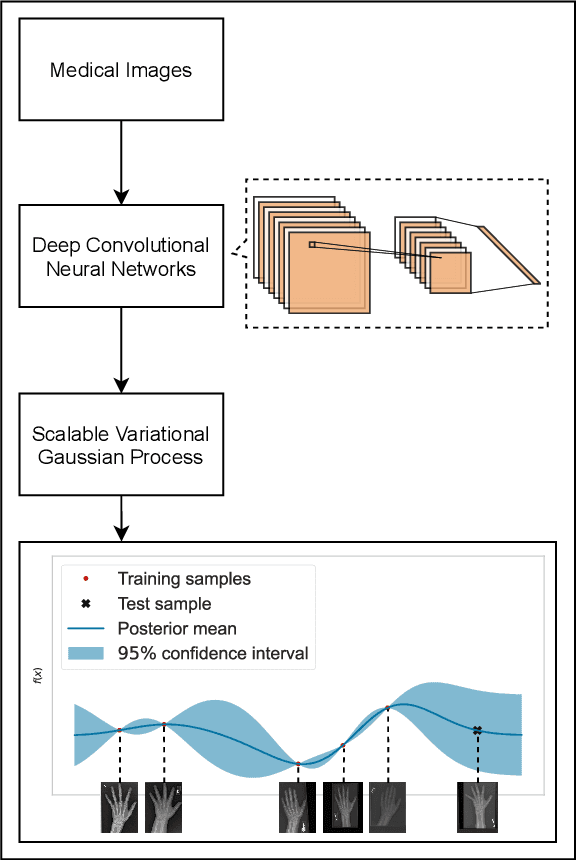
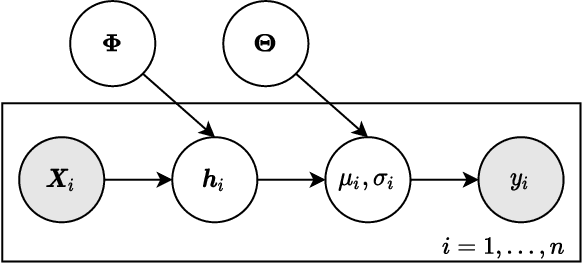
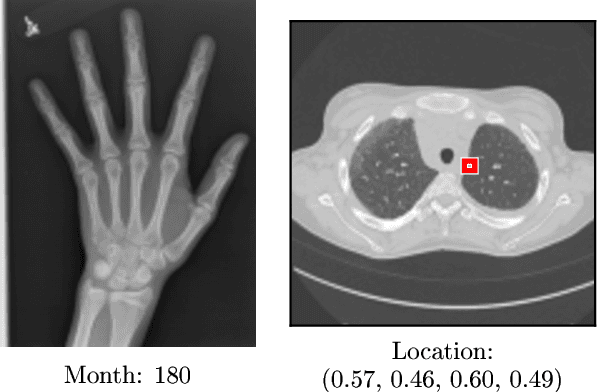
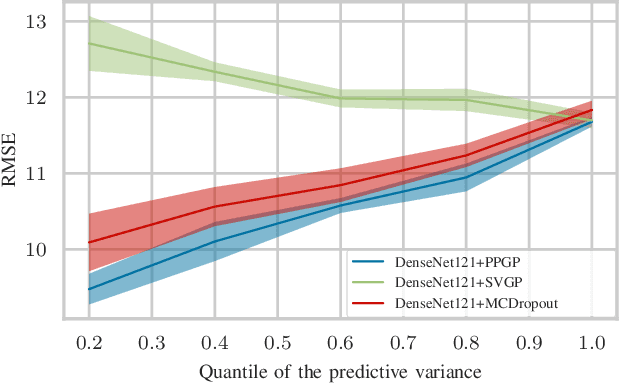
Deep neural networks are increasingly being used for the analysis of medical images. However, most works neglect the uncertainty in the model's prediction. We propose an uncertainty-aware deep kernel learning model which permits the estimation of the uncertainty in the prediction by a pipeline of a Convolutional Neural Network and a sparse Gaussian Process. Furthermore, we adapt different pre-training methods to investigate their impacts on the proposed model. We apply our approach to Bone Age Prediction and Lesion Localization. In most cases, the proposed model shows better performance compared to common architectures. More importantly, our model expresses systematically higher confidence in more accurate predictions and less confidence in less accurate ones. Our model can also be used to detect challenging and controversial test samples. Compared to related methods such as Monte-Carlo Dropout, our approach derives the uncertainty information in a purely analytical fashion and is thus computationally more efficient.
Trilateral Attention Network for Real-time Medical Image Segmentation
Jun 17, 2021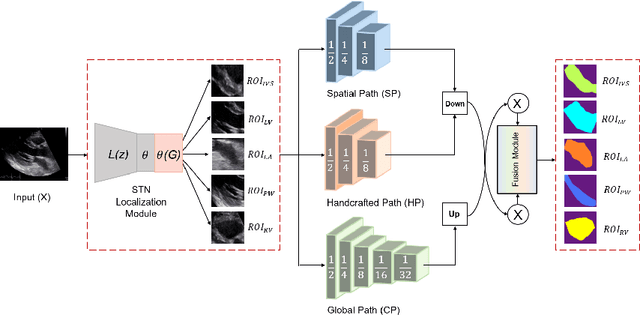
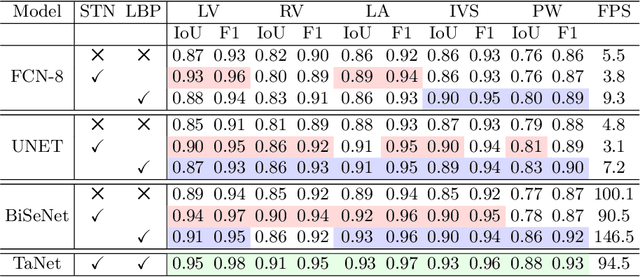

Accurate segmentation of medical images into anatomically meaningful regions is critical for the extraction of quantitative indices or biomarkers. The common pipeline for segmentation comprises regions of interest detection stage and segmentation stage, which are independent of each other and typically performed using separate deep learning networks. The performance of the segmentation stage highly relies on the extracted set of spatial features and the receptive fields. In this work, we propose an end-to-end network, called Trilateral Attention Network (TaNet), for real-time detection and segmentation in medical images. TaNet has a module for region localization, and three segmentation pathways: 1) handcrafted pathway with hand-designed convolutional kernels, 2) detail pathway with regular convolutional kernels, and 3) a global pathway to enlarge the receptive field. The first two pathways encode rich handcrafted and low-level features extracted by hand-designed and regular kernels while the global pathway encodes high-level context information. By jointly training the network for localization and segmentation using different sets of features, TaNet achieved superior performance, in terms of accuracy and speed, when evaluated on an echocardiography dataset for cardiac segmentation. The code and models will be made publicly available in TaNet Github page.
Formulating Intuitive Stack-of-Tasks with Visuo-Tactile Perception for Collaborative Human-Robot Fine Manipulation
Mar 09, 2021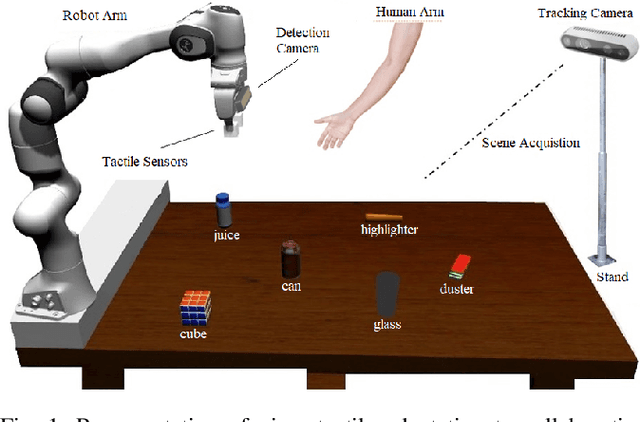
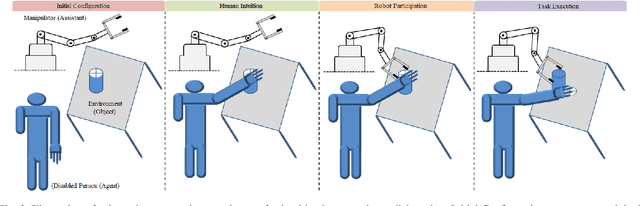
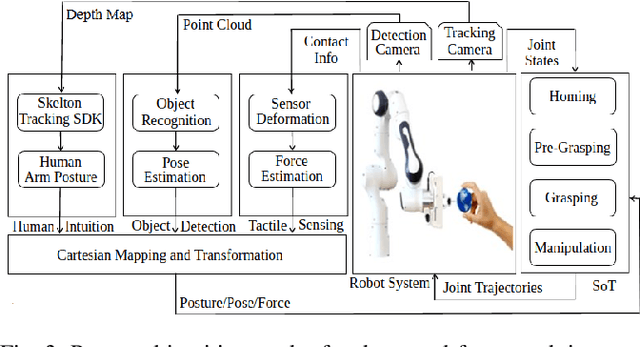
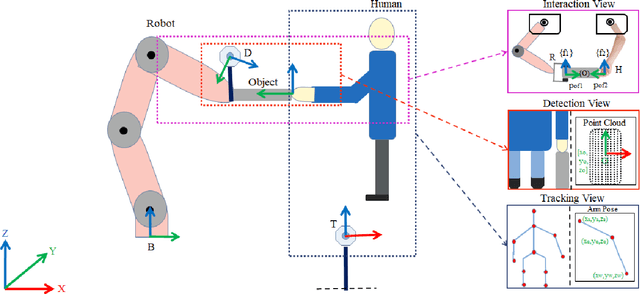
Enabling robots to work in close proximity with humans necessitates to employ not only multi-sensory information for coordinated and autonomous interactions but also a control framework that ensures adaptive and flexible collaborative behavior. Such a control framework needs to integrate accuracy and repeatability of robots with cognitive ability and adaptability of humans for co-manipulation. In this regard, an intuitive stack of tasks (iSOT) formulation is proposed, that defines the robots actions based on human ergonomics and task progress. The framework is augmented with visuo-tactile perception for flexible interaction and autonomous adaption. The visual information using depth cameras, monitors and estimates the object pose and human arm gesture while the tactile feedback provides exploration skills for maintaining the desired contact to avoid slippage. Experiments conducted on robot system with human partnership for assembly and disassembly tasks confirm the effectiveness and usability of proposed framework.
Efficient First-Order Contextual Bandits: Prediction, Allocation, and Triangular Discrimination
Jul 05, 2021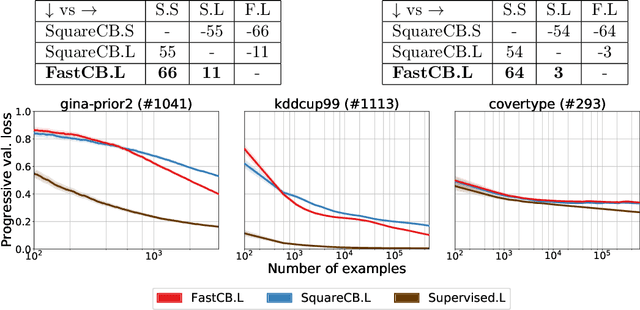
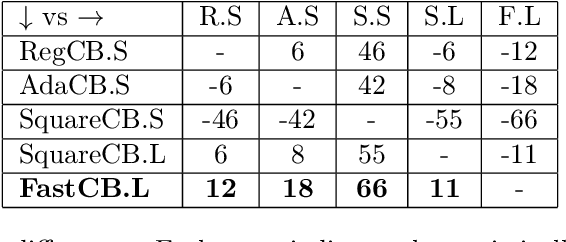
A recurring theme in statistical learning, online learning, and beyond is that faster convergence rates are possible for problems with low noise, often quantified by the performance of the best hypothesis; such results are known as first-order or small-loss guarantees. While first-order guarantees are relatively well understood in statistical and online learning, adapting to low noise in contextual bandits (and more broadly, decision making) presents major algorithmic challenges. In a COLT 2017 open problem, Agarwal, Krishnamurthy, Langford, Luo, and Schapire asked whether first-order guarantees are even possible for contextual bandits and -- if so -- whether they can be attained by efficient algorithms. We give a resolution to this question by providing an optimal and efficient reduction from contextual bandits to online regression with the logarithmic (or, cross-entropy) loss. Our algorithm is simple and practical, readily accommodates rich function classes, and requires no distributional assumptions beyond realizability. In a large-scale empirical evaluation, we find that our approach typically outperforms comparable non-first-order methods. On the technical side, we show that the logarithmic loss and an information-theoretic quantity called the triangular discrimination play a fundamental role in obtaining first-order guarantees, and we combine this observation with new refinements to the regression oracle reduction framework of Foster and Rakhlin. The use of triangular discrimination yields novel results even for the classical statistical learning model, and we anticipate that it will find broader use.
Case Studies on using Natural Language Processing Techniques in Customer Relationship Management Software
Jun 09, 2021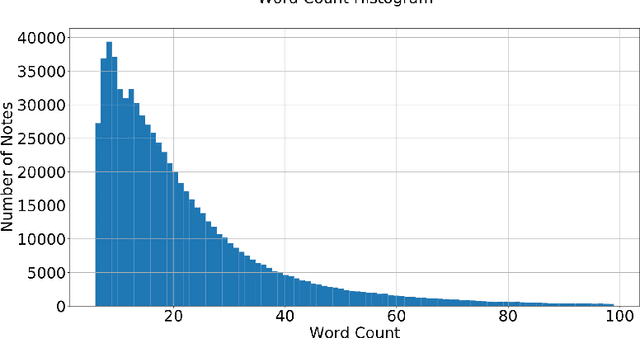


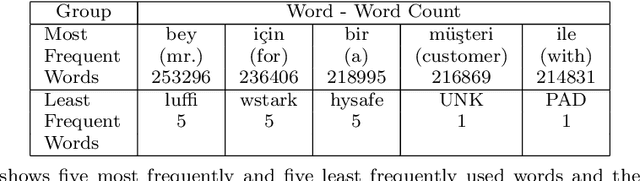
How can a text corpus stored in a customer relationship management (CRM) database be used for data mining and segmentation? In order to answer this question we inherited the state of the art methods commonly used in natural language processing (NLP) literature, such as word embeddings, and deep learning literature, such as recurrent neural networks (RNN). We used the text notes from a CRM system which are taken by customer representatives of an internet ads consultancy agency between years 2009 and 2020. We trained word embeddings by using the corresponding text corpus and showed that these word embeddings can not only be used directly for data mining but also be used in RNN architectures, which are deep learning frameworks built with long short term memory (LSTM) units, for more comprehensive segmentation objectives. The results prove that structured text data in a CRM can be used to mine out very valuable information and any CRM can be equipped with useful NLP features once the problem definitions are properly built and the solution methods are conveniently implemented.
* Pre-print version of the article titled "Case Studies on using Natural Language Processing Techniques in Customer Relationship Management Software"
Supervised Speech Representation Learning for Parkinson's Disease Classification
Jun 01, 2021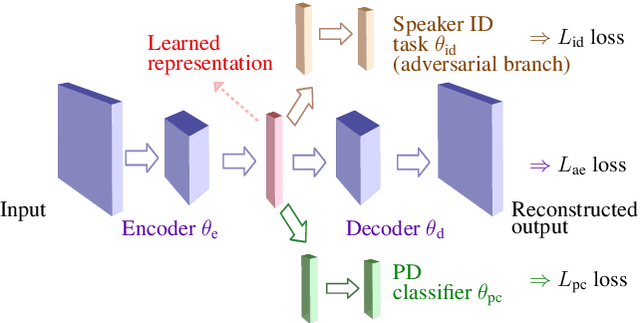

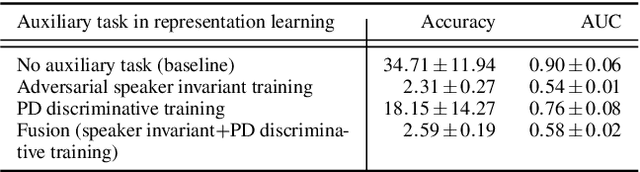
Recently proposed automatic pathological speech classification techniques use unsupervised auto-encoders to obtain a high-level abstract representation of speech. Since these representations are learned based on reconstructing the input, there is no guarantee that they are robust to pathology-unrelated cues such as speaker identity information. Further, these representations are not necessarily discriminative for pathology detection. In this paper, we exploit supervised auto-encoders to extract robust and discriminative speech representations for Parkinson's disease classification. To reduce the influence of speaker variabilities unrelated to pathology, we propose to obtain speaker identity-invariant representations by adversarial training of an auto-encoder and a speaker identification task. To obtain a discriminative representation, we propose to jointly train an auto-encoder and a pathological speech classifier. Experimental results on a Spanish database show that the proposed supervised representation learning methods yield more robust and discriminative representations for automatically classifying Parkinson's disease speech, outperforming the baseline unsupervised representation learning system.
BERT Embeddings Can Track Context in Conversational Search
Apr 13, 2021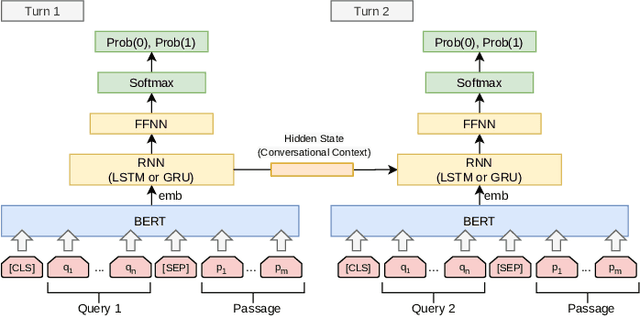
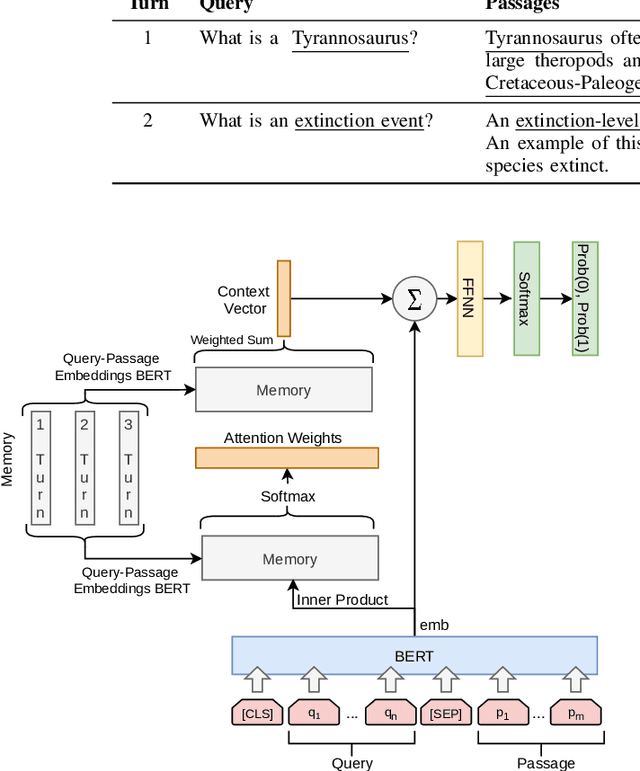
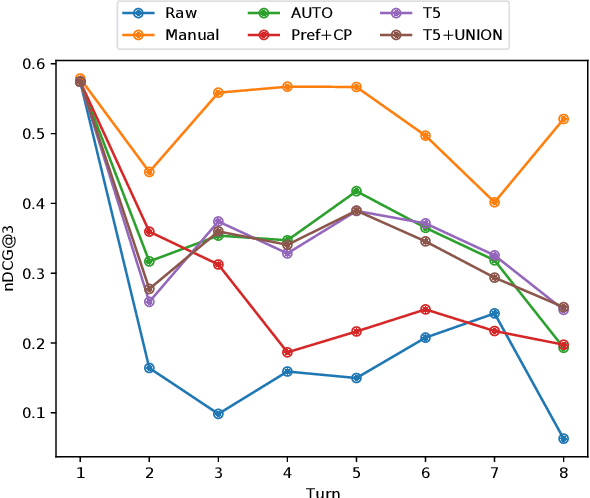
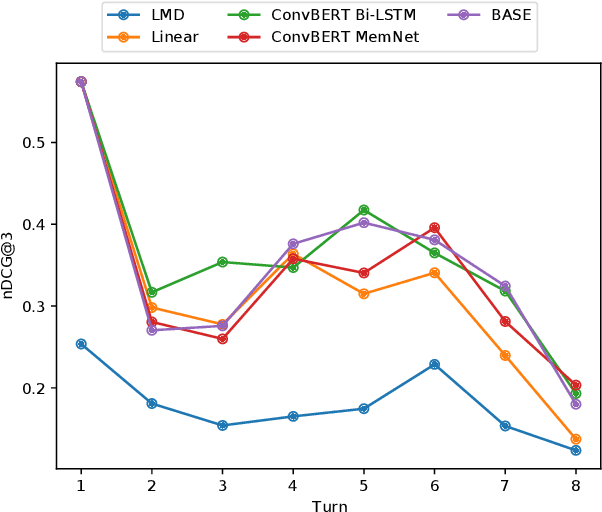
The use of conversational assistants to search for information is becoming increasingly more popular among the general public, pushing the research towards more advanced and sophisticated techniques. In the last few years, in particular, the interest in conversational search is increasing, not only because of the generalization of conversational assistants but also because conversational search is a step forward in allowing a more natural interaction with the system. In this work, the focus is on exploring the context present of the conversation via the historical utterances and respective embeddings with the aim of developing a conversational search system that helps people search for information in a natural way. In particular, this system must be able to understand the context where the question is posed, tracking the current state of the conversation and detecting mentions to previous questions and answers. We achieve this by using a context-tracking component based on neural query-rewriting models. Another crucial aspect of the system is to provide the most relevant answers given the question and the conversational history. To achieve this objective, we used a Transformer-based re-ranking method and expanded this architecture to use the conversational context. The results obtained with the system developed showed the advantages of using the context present in the natural language utterances and in the neural embeddings generated throughout the conversation.
Identifying COVID-19 Fake News in Social Media
Feb 01, 2021
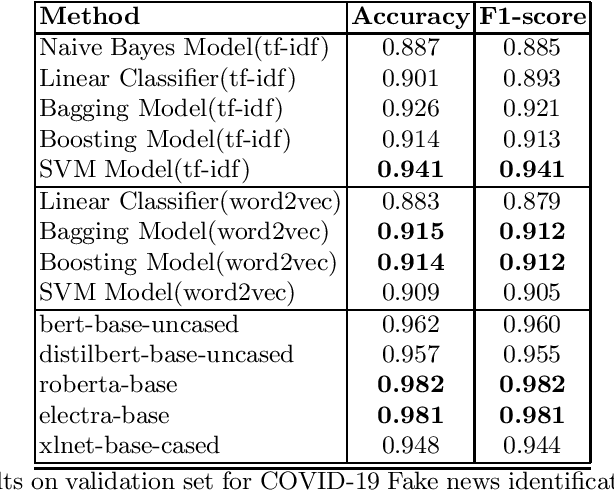
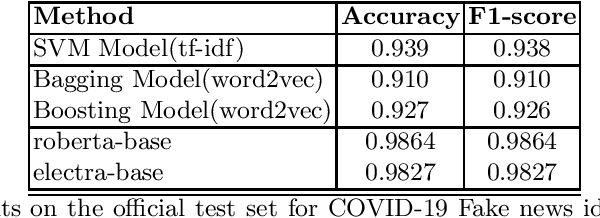
The evolution of social media platforms have empowered everyone to access information easily. Social media users can easily share information with the rest of the world. This may sometimes encourage spread of fake news, which can result in undesirable consequences. In this work, we train models which can identify health news related to COVID-19 pandemic as real or fake. Our models achieve a high F1-score of 98.64%. Our models achieve second place on the leaderboard, tailing the first position with a very narrow margin 0.05% points.