 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hierarchical Graph Representations in Digital Pathology
Mar 17, 2021
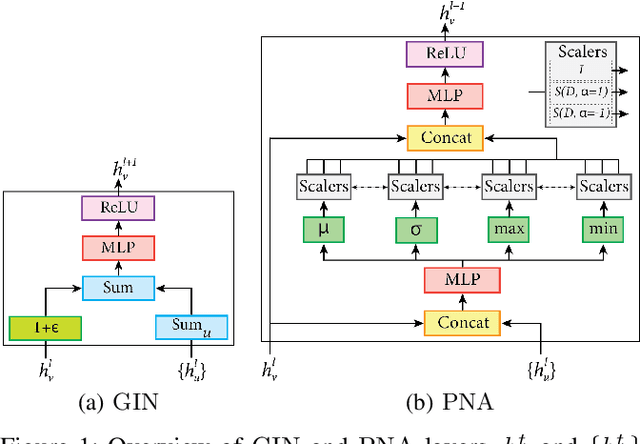
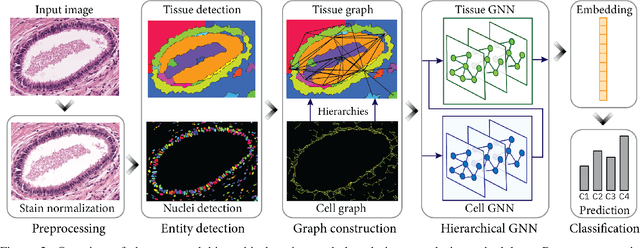
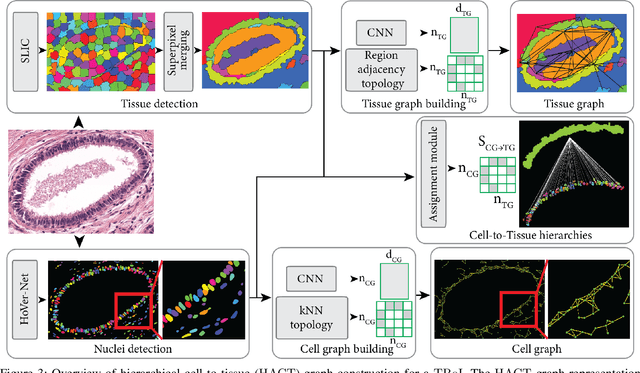
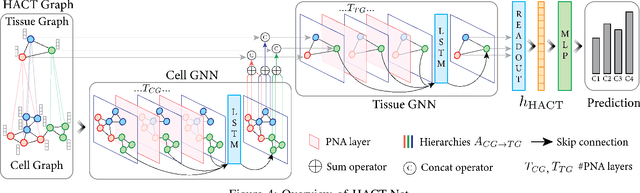
Cancer diagnosis, prognosis, and therapy response predictions from tissue specimens highly depend on the phenotype and topological distribution of constituting histological entities. Thus, adequate tissue representations for encoding histological entities is imperative for computer aided cancer patient care. To this end, several approaches have leveraged cell-graphs that encode cell morphology and organization to denote the tissue information. These allow for utilizing machine learning to map tissue representations to tissue functionality to help quantify their relationship. Though cellular information is crucial, it is incomplete alone to comprehensively characterize complex tissue structure. We herein treat the tissue as a hierarchical composition of multiple types of histological entities from fine to coarse level, capturing multivariate tissue information at multiple levels. We propose a novel multi-level hierarchical entity-graph representation of tissue specimens to model hierarchical compositions that encode histological entities as well as their intra- and inter-entity level interactions. Subsequently, a graph neural network is proposed to operate on the hierarchical entity-graph representation to map the tissue structure to tissue functionality. Specifically, for input histology images we utilize well-defined cells and tissue regions to build HierArchical Cell-to-Tissue (HACT) graph representations, and devise HACT-Net, a graph neural network, to classify such HACT representations. As part of this work, we introduce the BReAst Carcinoma Subtyping (BRACS) dataset, a large cohort of H&E stained breast tumor images, to evaluate our proposed methodology against pathologists and state-of-the-art approaches. Through comparative assessment and ablation studies, our method is demonstrated to yield superior classification results compared to alternative methods as well as pathologists.
Depth Quality-Inspired Feature Manipulation for Efficient RGB-D Salient Object Detection
Jul 06, 2021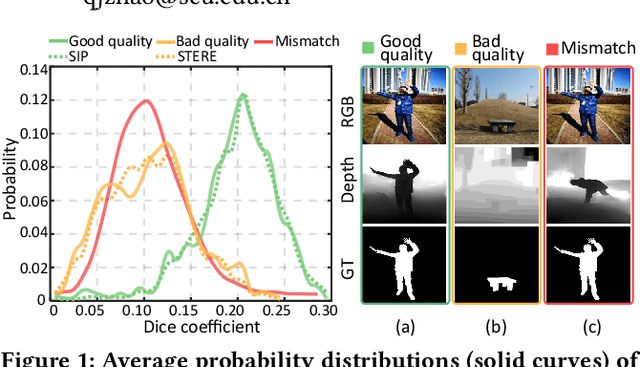
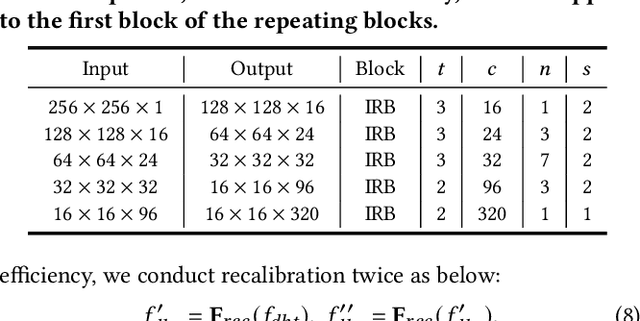
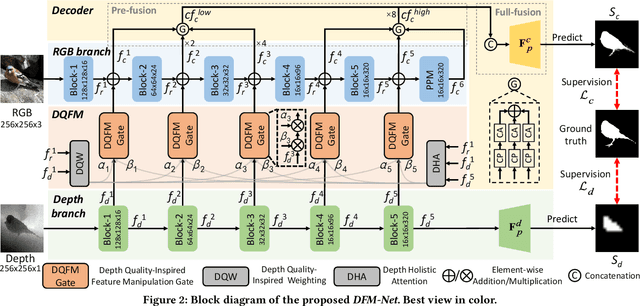
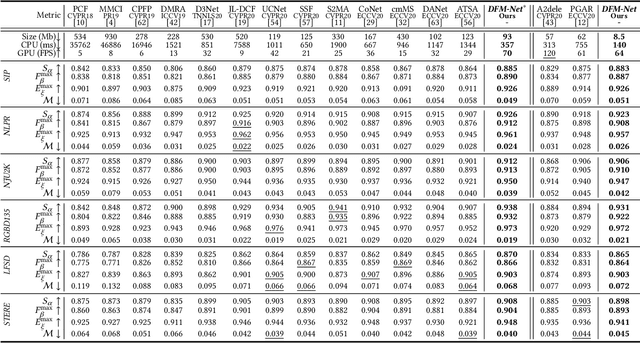
RGB-D salient object detection (SOD) recently has attracted increasing research interest by benefiting conventional RGB SOD with extra depth information. However, existing RGB-D SOD models often fail to perform well in terms of both efficiency and accuracy, which hinders their potential applications on mobile devices and real-world problems. An underlying challenge is that the model accuracy usually degrades when the model is simplified to have few parameters. To tackle this dilemma and also inspired by the fact that depth quality is a key factor influencing the accuracy, we propose a novel depth quality-inspired feature manipulation (DQFM) process, which is efficient itself and can serve as a gating mechanism for filtering depth features to greatly boost the accuracy. DQFM resorts to the alignment of low-level RGB and depth features, as well as holistic attention of the depth stream to explicitly control and enhance cross-modal fusion. We embed DQFM to obtain an efficient light-weight model called DFM-Net, where we also design a tailored depth backbone and a two-stage decoder for further efficiency consideration. Extensive experimental results demonstrate that our DFM-Net achieves state-of-the-art accuracy when comparing to existing non-efficient models, and meanwhile runs at 140ms on CPU (2.2$\times$ faster than the prior fastest efficient model) with only $\sim$8.5Mb model size (14.9% of the prior lightest). Our code will be available at https://github.com/zwbx/DFM-Net.
TransMIL: Transformer based Correlated Multiple Instance Learning for Whole Slide Image Classication
Jun 02, 2021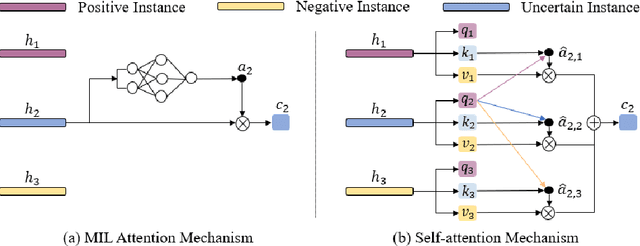
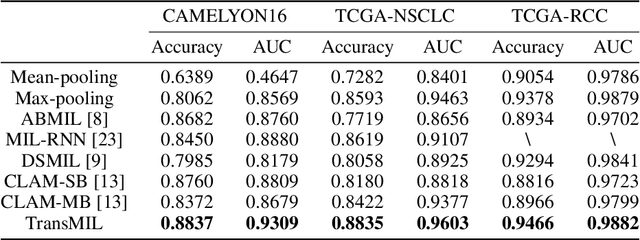

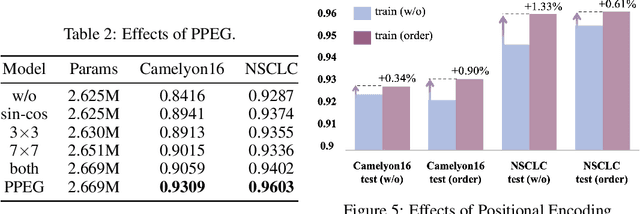
Multiple instance learning (MIL) is a powerful tool to solve the weakly supervised classification in whole slide image (WSI) based pathology diagnosis. However, the current MIL methods are usually based on independent and identical distribution hypothesis, thus neglect the correlation among different instances. To address this problem, we proposed a new framework, called correlated MIL, and provided a proof for convergence. Based on this framework, we devised a Transformer based MIL (TransMIL), which explored both morphological and spatial information. The proposed TransMIL can effectively deal with unbalanced/balanced and binary/multiple classification with great visualization and interpretability. We conducted various experiments for three different computational pathology problems and achieved better performance and faster convergence compared with state-of-the-art methods. The test AUC for the binary tumor classification can be up to 93.09% over CAMELYON16 dataset. And the AUC over the cancer subtypes classification can be up to 96.03% and 98.82% over TCGA-NSCLC dataset and TCGA-RCC dataset, respectively.
Combining GCN and Transformer for Chinese Grammatical Error Detection
May 19, 2021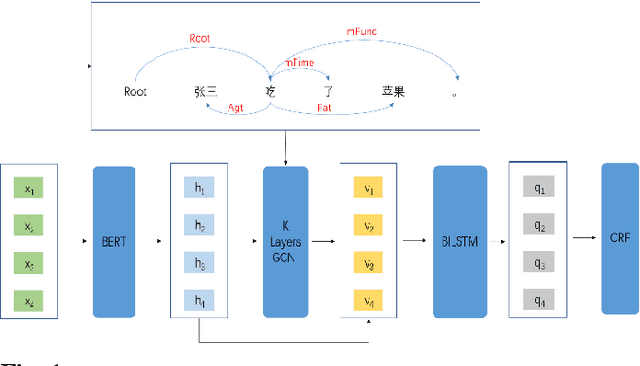
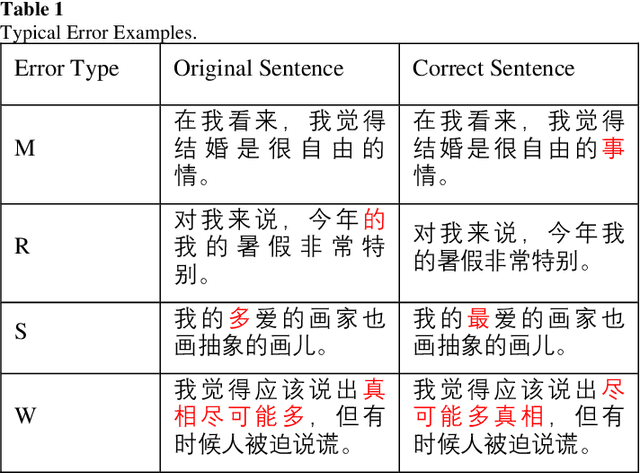
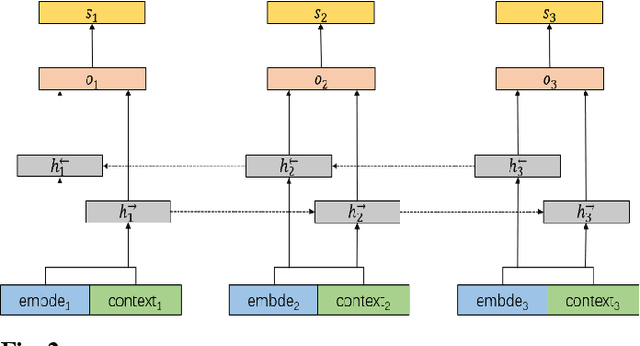
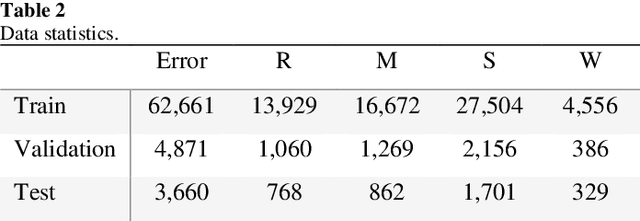
This paper introduces our system at NLPTEA-2020 Task: Chinese Grammatical Error Diagnosis (CGED). CGED aims to diagnose four types of grammatical errors which are missing words (M), redundant words (R), bad word selection (S) and disordered words (W). The automatic CGED system contains two parts including error detection and error correction and our system is designed to solve the error detection problem. Our system is built on three models: 1) a BERT-based model leveraging syntactic information; 2) a BERT-based model leveraging contextual embeddings; 3) a lexicon-based graph neural network. We also design an ensemble mechanism to improve the performance of the single model. Finally, our system obtains the highest F1 scores at detection level and identification level among all teams participating in the CGED 2020 task.
Unsupervised Video Person Re-identification via Noise and Hard frame Aware Clustering
Jun 10, 2021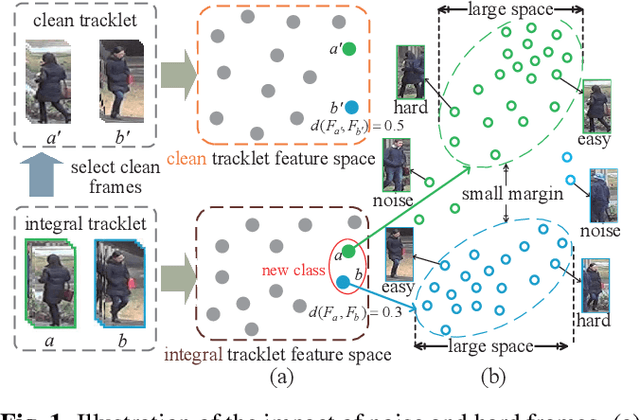
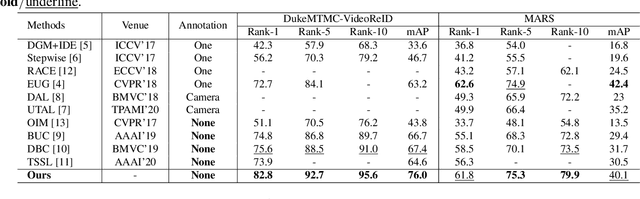
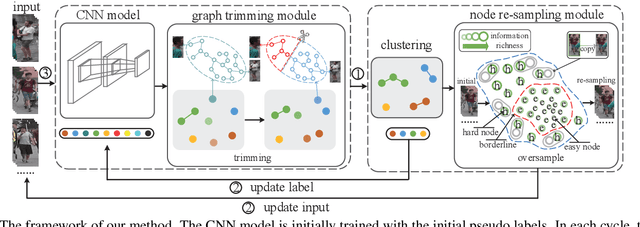
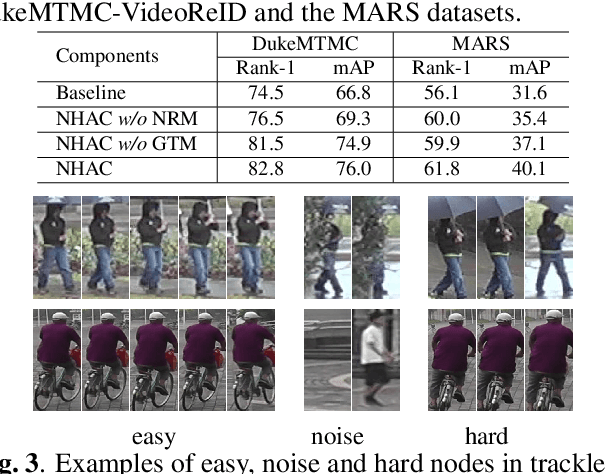
Unsupervised video-based person re-identification (re-ID) methods extract richer features from video tracklets than image-based ones. The state-of-the-art methods utilize clustering to obtain pseudo-labels and train the models iteratively. However, they underestimate the influence of two kinds of frames in the tracklet: 1) noise frames caused by detection errors or heavy occlusions exist in the tracklet, which may be allocated with unreliable labels during clustering; 2) the tracklet also contains hard frames caused by pose changes or partial occlusions, which are difficult to distinguish but informative. This paper proposes a Noise and Hard frame Aware Clustering (NHAC) method. NHAC consists of a graph trimming module and a node re-sampling module. The graph trimming module obtains stable graphs by removing noise frame nodes to improve the clustering accuracy. The node re-sampling module enhances the training of hard frame nodes to learn rich tracklet information. Experiments conducted on two video-based datasets demonstrate the effectiveness of the proposed NHAC under the unsupervised re-ID setting.
Cross-Modal Discrete Representation Learning
Jun 10, 2021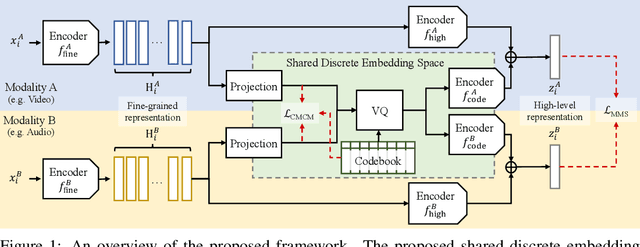
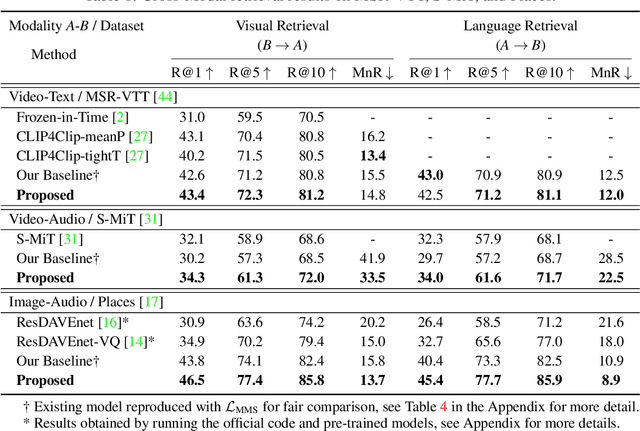
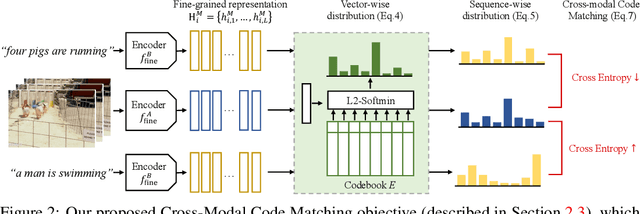
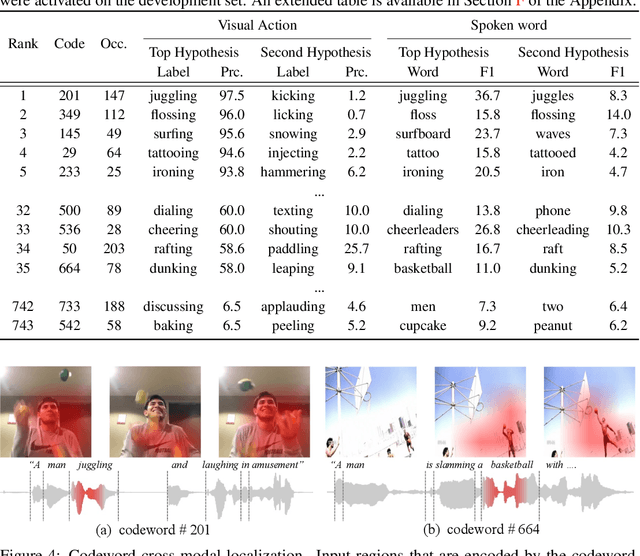
Recent advances in representation learning have demonstrated an ability to represent information from different modalities such as video, text, and audio in a single high-level embedding vector. In this work we present a self-supervised learning framework that is able to learn a representation that captures finer levels of granularity across different modalities such as concepts or events represented by visual objects or spoken words. Our framework relies on a discretized embedding space created via vector quantization that is shared across different modalities. Beyond the shared embedding space, we propose a Cross-Modal Code Matching objective that forces the representations from different views (modalities) to have a similar distribution over the discrete embedding space such that cross-modal objects/actions localization can be performed without direct supervision. In our experiments we show that the proposed discretized multi-modal fine-grained representation (e.g., pixel/word/frame) can complement high-level summary representations (e.g., video/sentence/waveform) for improved performance on cross-modal retrieval tasks. We also observe that the discretized representation uses individual clusters to represent the same semantic concept across modalities.
Exploring the Limits of Few-Shot Link Prediction in Knowledge Graphs
Feb 05, 2021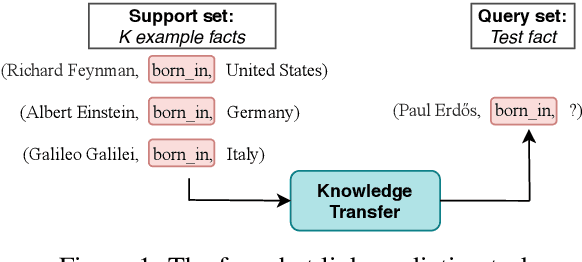
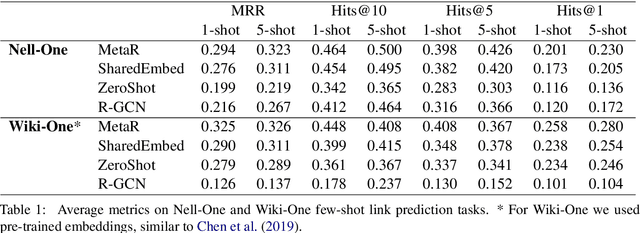

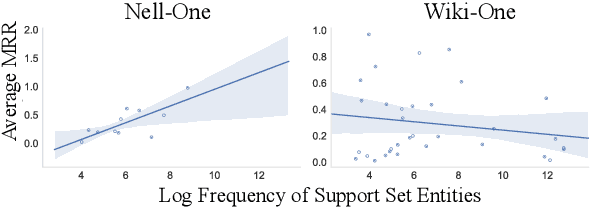
Real-world knowledge graphs are often characterized by low-frequency relations - a challenge that has prompted an increasing interest in few-shot link prediction methods. These methods perform link prediction for a set of new relations, unseen during training, given only a few example facts of each relation at test time. In this work, we perform a systematic study on a spectrum of models derived by generalizing the current state of the art for few-shot link prediction, with the goal of probing the limits of learning in this few-shot setting. We find that a simple zero-shot baseline - which ignores any relation-specific information - achieves surprisingly strong performance. Moreover, experiments on carefully crafted synthetic datasets show that having only a few examples of a relation fundamentally limits models from using fine-grained structural information and only allows for exploiting the coarse-grained positional information of entities. Together, our findings challenge the implicit assumptions and inductive biases of prior work and highlight new directions for research in this area.
* code available at https://github.com/dorajam/few-shot-link-prediction-paper
Entropy and mutual information in models of deep neural networks
Oct 29, 2018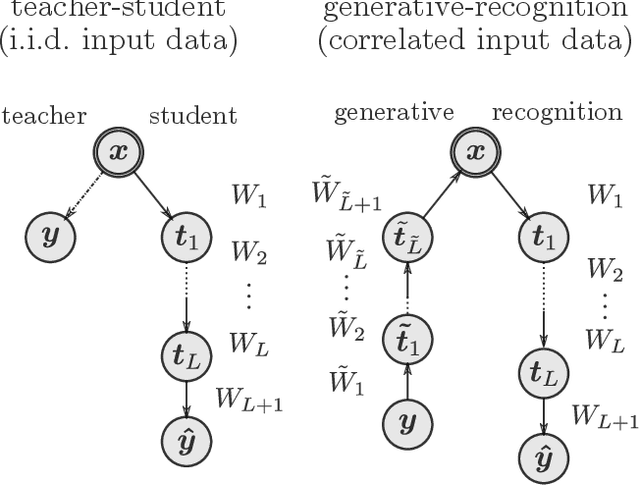
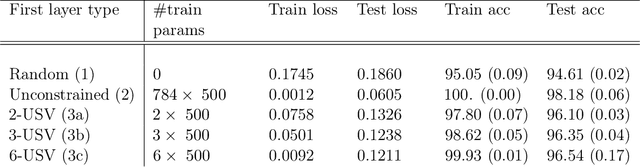
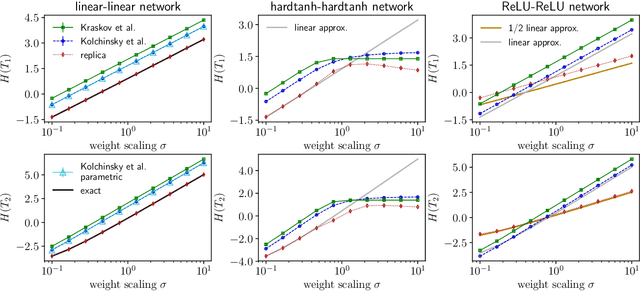
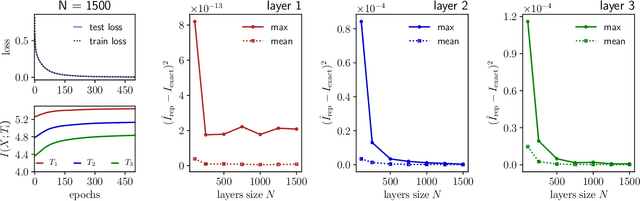
We examine a class of deep learning models with a tractable method to compute information-theoretic quantities. Our contributions are three-fold: (i) We show how entropies and mutual informations can be derived from heuristic statistical physics methods, under the assumption that weight matrices are independent and orthogonally-invariant. (ii) We extend particular cases in which this result is known to be rigorously exact by providing a proof for two-layers networks with Gaussian random weights, using the recently introduced adaptive interpolation method. (iii) We propose an experiment framework with generative models of synthetic datasets, on which we train deep neural networks with a weight constraint designed so that the assumption in (i) is verified during learning. We study the behavior of entropies and mutual informations throughout learning and conclude that, in the proposed setting, the relationship between compression and generalization remains elusive.
Mapping Human Muscle Force to Supernumerary Robotics Device for Overhead Task Assistance
Jul 29, 2021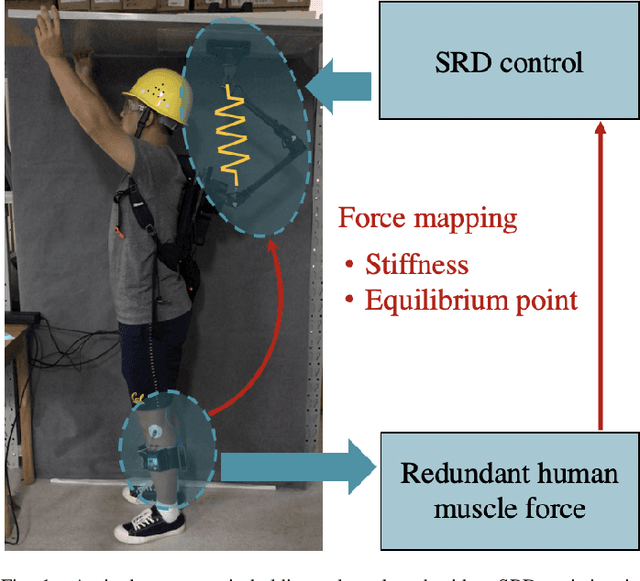
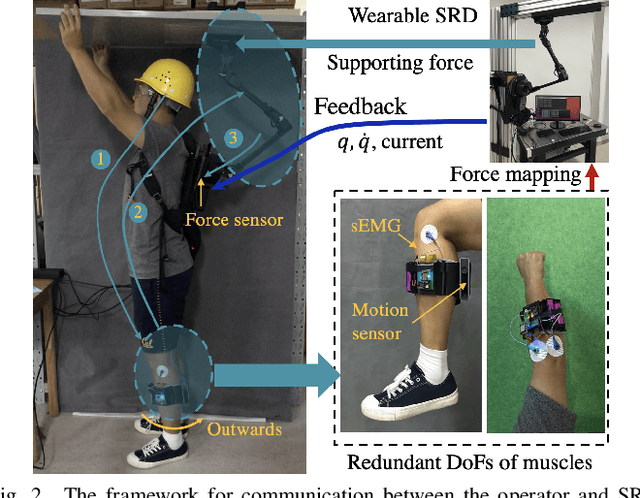
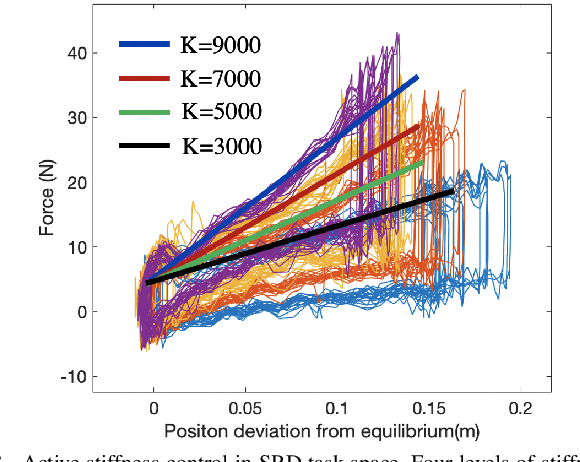
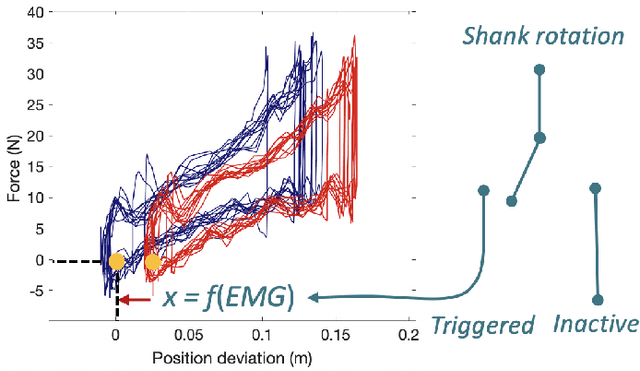
Supernumerary Robotics Device (SRD) is an ideal solution to provide robotic assistance in overhead manual manipulation. Since two arms are occupied for the overhead task, it is desired to have additional arms to assist us in achieving other subtasks such as supporting the far end of a long plate and pushing it upward to fit in the ceiling. In this study, a method that maps human muscle force to SRD for overhead task assistance is proposed. Our methodology is to utilize redundant DoFs such as the idle muscles in the leg to control the supporting force of the SRD. A sEMG device is worn on the operator's shank where muscle signals are measured, parsed, and transmitted to SRD for control. In the control aspect, we adopted stiffness control in the task space based on torque control at the joint level. We are motivated by the fact that humans can achieve daily manipulation merely through simple inherent compliance property in joint driven by muscles. We explore to estimate the force of some particular muscles in humans and control the SRD to imitate the behaviors of muscle and output supporting forces to accomplish the subtasks such as overhead supporting. The sEMG signals detected from human muscles are extracted, filtered, rectified, and parsed to estimate the muscle force. We use this force information as the intent of the operator for proper overhead supporting force. As one of the well-known compliance control methods, stiffness control is easy to achieve using a few of straightforward parameters such as stiffness and equilibrium point. Through tuning the stiffness and equilibrium point, the supporting force of SRD in task space can be easily controlled. The muscle force estimated by sEMG is mapped to the desired force in the task space of the SRD. The desired force is transferred into stiffness or equilibrium point to output the corresponding supporting force.
ConvoSumm: Conversation Summarization Benchmark and Improved Abstractive Summarization with Argument Mining
Jun 01, 2021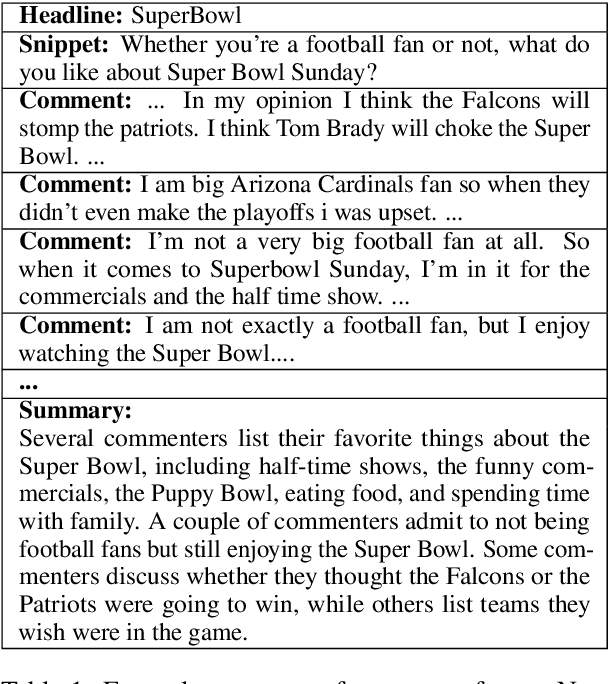
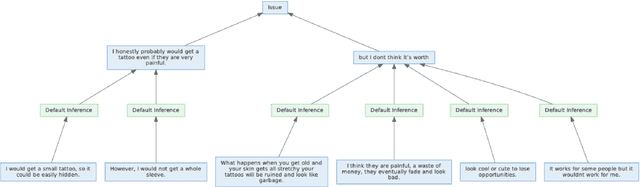


While online conversations can cover a vast amount of information in many different formats, abstractive text summarization has primarily focused on modeling solely news articles. This research gap is due, in part, to the lack of standardized datasets for summarizing online discussions. To address this gap, we design annotation protocols motivated by an issues--viewpoints--assertions framework to crowdsource four new datasets on diverse online conversation forms of news comments, discussion forums, community question answering forums, and email threads. We benchmark state-of-the-art models on our datasets and analyze characteristics associated with the data. To create a comprehensive benchmark, we also evaluate these models on widely-used conversation summarization datasets to establish strong baselines in this domain. Furthermore, we incorporate argument mining through graph construction to directly model the issues, viewpoints, and assertions present in a conversation and filter noisy input, showing comparable or improved results according to automatic and human evaluations.