 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Robust Task Scheduling for Heterogeneous Robot Teams under Capability Uncertainty
Jun 23, 2021
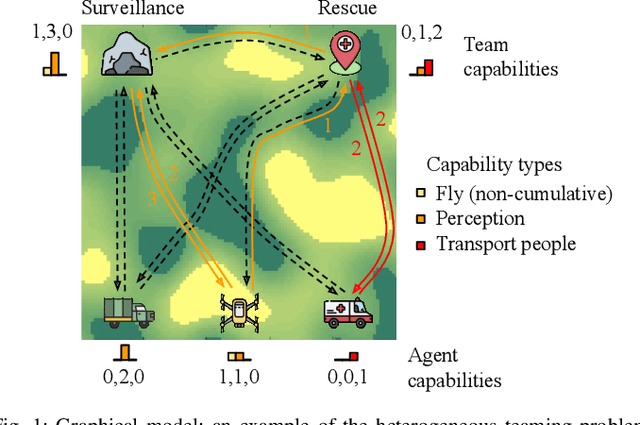
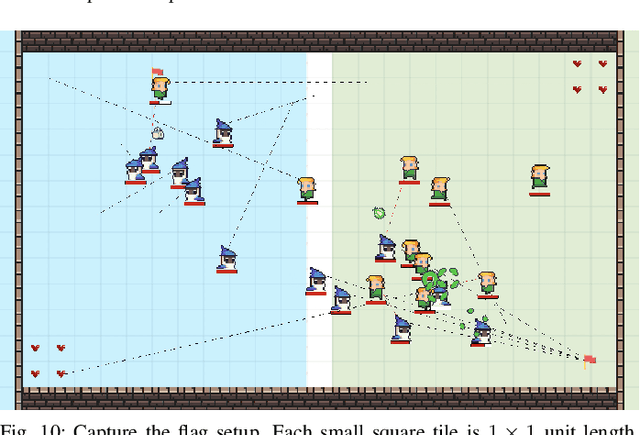
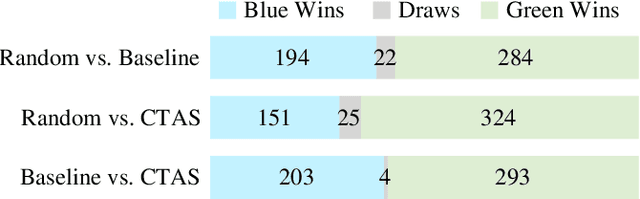
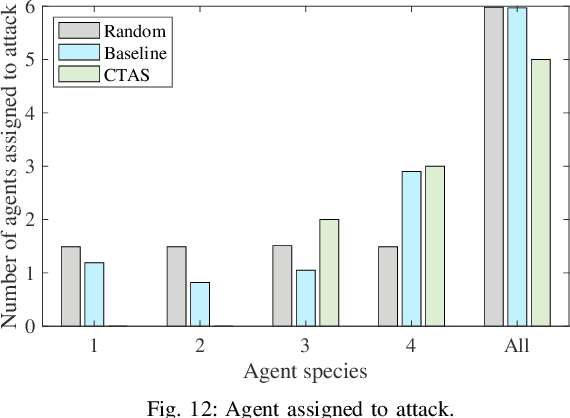
This paper develops a stochastic programming framework for multi-agent systems where task decomposition, assignment, and scheduling problems are simultaneously optimized. Due to their inherent flexibility and robustness, multi-agent systems are applied in a growing range of real-world problems that involve heterogeneous tasks and uncertain information. Most previous works assume a unique way to decompose a task into roles that can later be assigned to the agents. This assumption is not valid for a complex task where the roles can vary and multiple decomposition structures exist. Meanwhile, it is unclear how uncertainties in task requirements and agent capabilities can be systematically quantified and optimized under a multi-agent system setting. A representation for complex tasks is proposed to avoid the non-convex task decomposition enumeration: agent capabilities are represented as a vector of random distributions, and task requirements are verified by a generalizable binary function. The conditional value at risk (CVaR) is chosen as a metric in the objective function to generate robust plans. An efficient algorithm is described to solve the model, and the whole framework is evaluated in two different practical test cases: capture-the-flag and robotic service coordination during a pandemic (e.g., COVID-19). Results demonstrate that the framework is scalable, generalizable, and provides low-cost plans that ensure a high probability of success.
Inferring Objectives in Continuous Dynamic Games from Noise-Corrupted Partial State Observations
Jun 16, 2021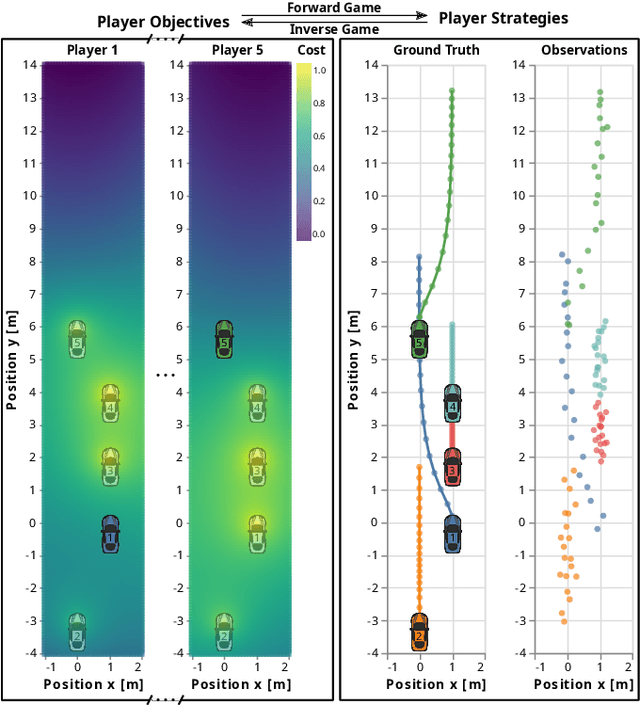
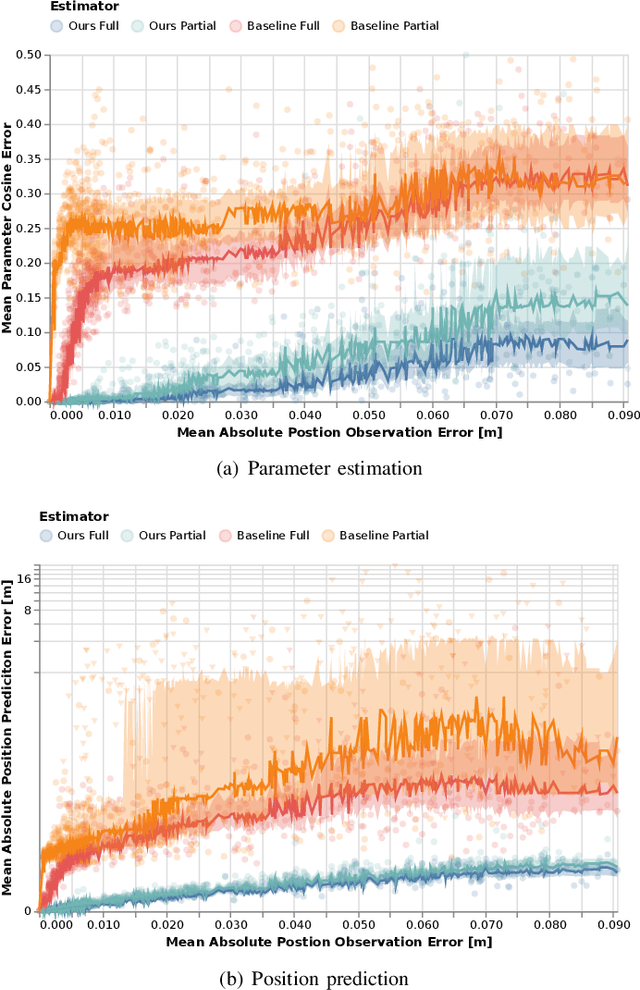
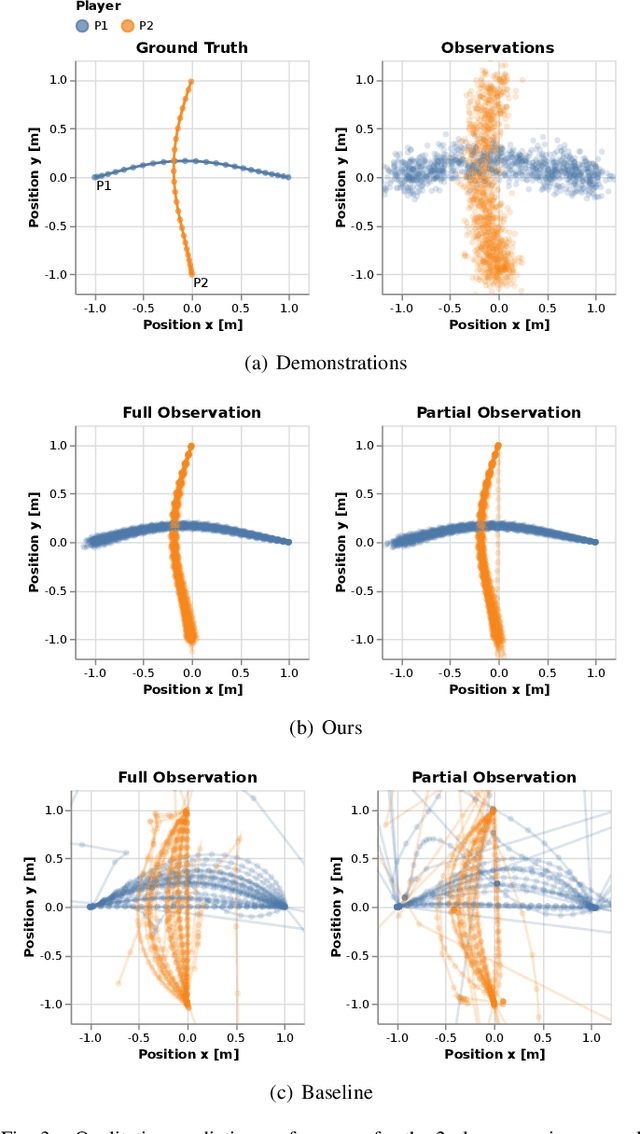
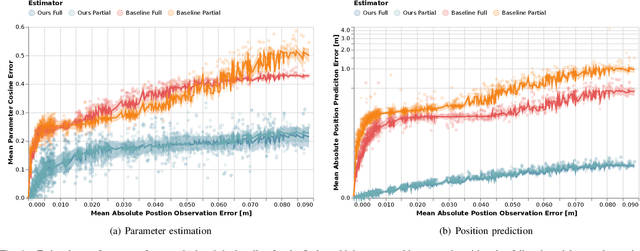
Robots and autonomous systems must interact with one another and their environment to provide high-quality services to their users. Dynamic game theory provides an expressive theoretical framework for modeling scenarios involving multiple agents with differing objectives interacting over time. A core challenge when formulating a dynamic game is designing objectives for each agent that capture desired behavior. In this paper, we propose a method for inferring parametric objective models of multiple agents based on observed interactions. Our inverse game solver jointly optimizes player objectives and continuous-state estimates by coupling them through Nash equilibrium constraints. Hence, our method is able to directly maximize the observation likelihood rather than other non-probabilistic surrogate criteria. Our method does not require full observations of game states or player strategies to identify player objectives. Instead, it robustly recovers this information from noisy, partial state observations. As a byproduct of estimating player objectives, our method computes a Nash equilibrium trajectory corresponding to those objectives. Thus, it is suitable for downstream trajectory forecasting tasks. We demonstrate our method in several simulated traffic scenarios. Results show that it reliably estimates player objectives from a short sequence of noise-corrupted partial state observations. Furthermore, using the estimated objectives, our method makes accurate predictions of each player's trajectory.
Graph Symbiosis Learning
Jun 10, 2021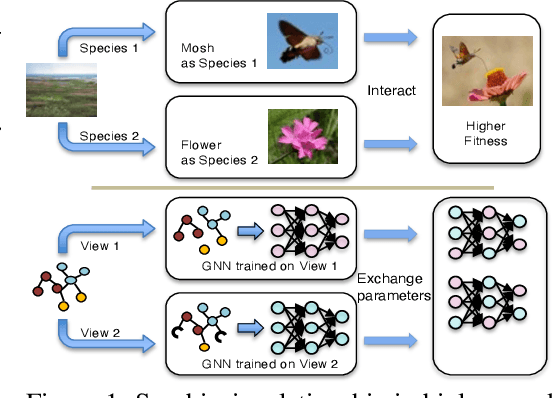
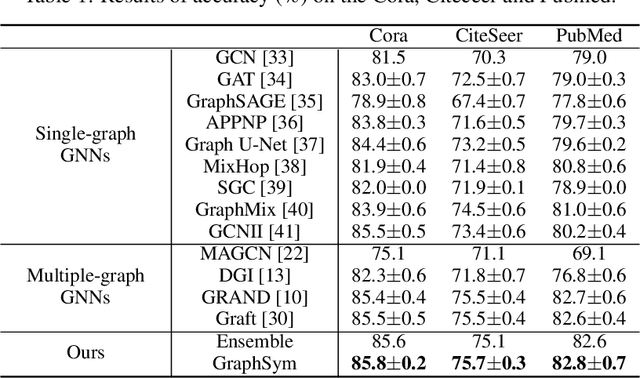
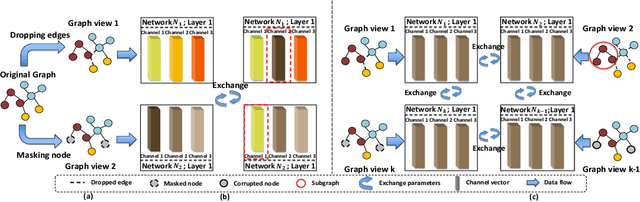
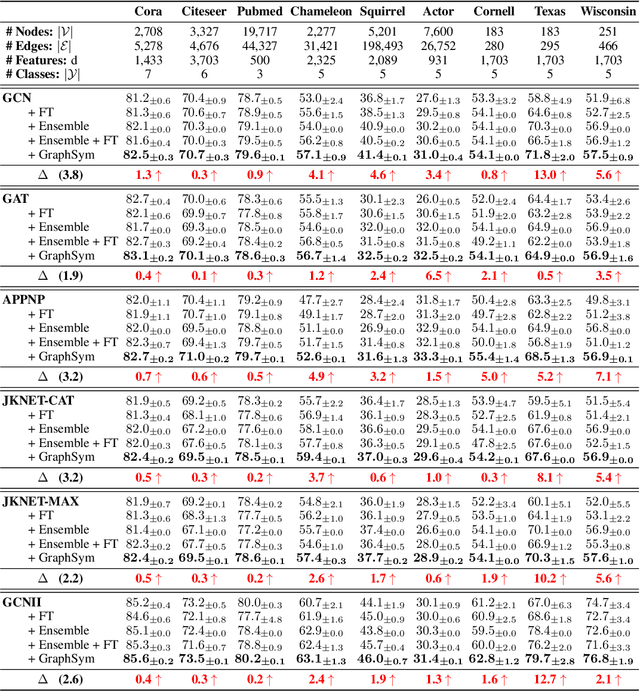
We introduce a framework for learning from multiple generated graph views, named graph symbiosis learning (GraphSym). In GraphSym, graph neural networks (GNN) developed in multiple generated graph views can adaptively exchange parameters with each other and fuse information stored in linkage structures and node features. Specifically, we propose a novel adaptive exchange method to iteratively substitute redundant channels in the weight matrix of one GNN with informative channels of another GNN in a layer-by-layer manner. GraphSym does not rely on specific methods to generate multiple graph views and GNN architectures. Thus, existing GNNs can be seamlessly integrated into our framework. On 3 semi-supervised node classification datasets, GraphSym outperforms previous single-graph and multiple-graph GNNs without knowledge distillation, and achieves new state-of-the-art results. We also conduct a series of experiments on 15 public benchmarks, 8 popular GNN models, and 3 graph tasks -- node classification, graph classification, and edge prediction -- and show that GraphSym consistently achieves better performance than existing popular GNNs by 1.9\%$\sim$3.9\% on average and their ensembles. Extensive ablation studies and experiments on the few-shot setting also demonstrate the effectiveness of GraphSym.
A Generalized Vector Space Model for Ontology-Based Information Retrieval
Jul 20, 2018Named entities (NE) are objects that are referred to by names such as people, organizations and locations. Named entities and keywords are important to the meaning of a document. We propose a generalized vector space model that combines named entities and keywords. In the model, we take into account different ontological features of named entities, namely, aliases, classes and identifiers. Moreover, we use entity classes to represent the latent information of interrogative words in Wh-queries, which are ignored in traditional keyword-based searching. We have implemented and tested the proposed model on a TREC dataset, as presented and discussed in the paper.
On the Distribution, Sparsity, and Inference-time Quantization of Attention Values in Transformers
Jun 02, 2021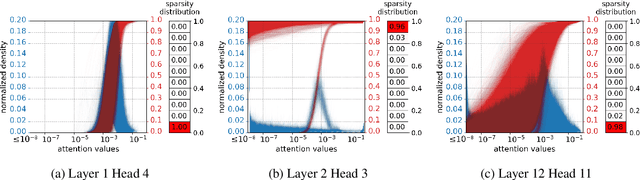
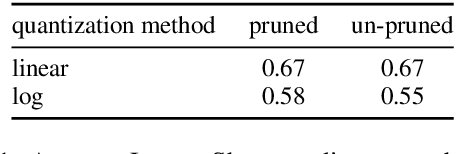
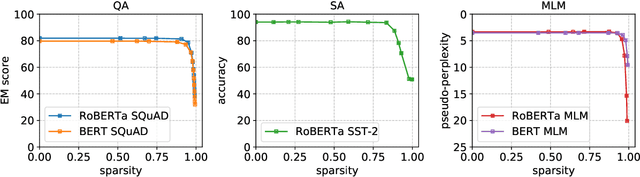
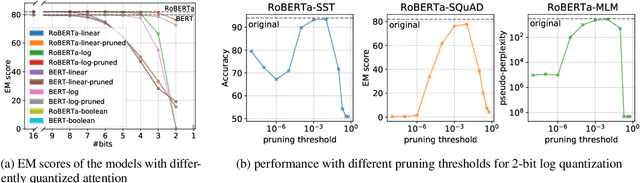
How much information do NLP tasks really need from a transformer's attention mechanism at application-time (inference)? From recent work, we know that there is sparsity in transformers and that the floating-points within its computation can be discretized to fewer values with minimal loss to task accuracies. However, this requires retraining or even creating entirely new models, both of which can be expensive and carbon-emitting. Focused on optimizations that do not require training, we systematically study the full range of typical attention values necessary. This informs the design of an inference-time quantization technique using both pruning and log-scaled mapping which produces only a few (e.g. $2^3$) unique values. Over the tasks of question answering and sentiment analysis, we find nearly 80% of attention values can be pruned to zeros with minimal ($< 1.0\%$) relative loss in accuracy. We use this pruning technique in conjunction with quantizing the attention values to only a 3-bit format, without retraining, resulting in only a 0.8% accuracy reduction on question answering with fine-tuned RoBERTa.
Harmless label noise and informative soft-labels in supervised classification
Apr 07, 2021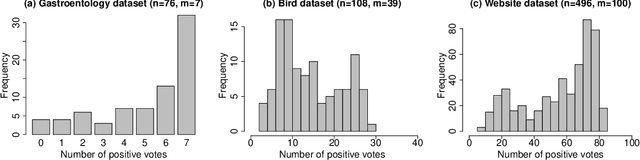
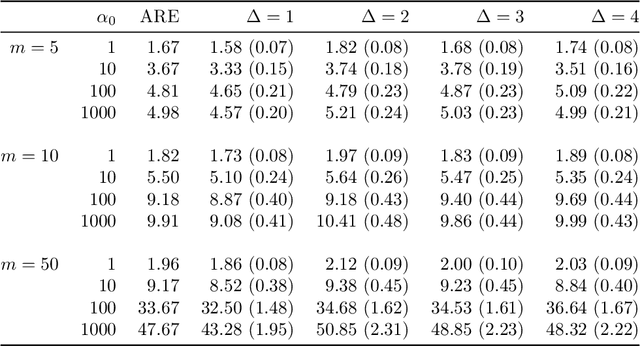
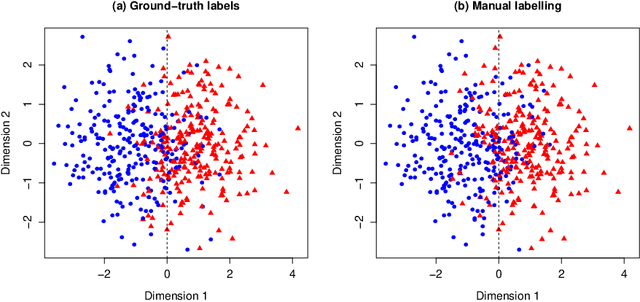

Manual labelling of training examples is common practice in supervised learning. When the labelling task is of non-trivial difficulty, the supplied labels may not be equal to the ground-truth labels, and label noise is introduced into the training dataset. If the manual annotation is carried out by multiple experts, the same training example can be given different class assignments by different experts, which is indicative of label noise. In the framework of model-based classification, a simple, but key observation is that when the manual labels are sampled using the posterior probabilities of class membership, the noisy labels are as valuable as the ground-truth labels in terms of statistical information. A relaxation of this process is a random effects model for imperfect labelling by a group that uses approximate posterior probabilities of class membership. The relative efficiency of logistic regression using the noisy labels compared to logistic regression using the ground-truth labels can then be derived. The main finding is that logistic regression can be robust to label noise when label noise and classification difficulty are positively correlated. In particular, when classification difficulty is the only source of label errors, multiple sets of noisy labels can supply more information for the estimation of a classification rule compared to the single set of ground-truth labels.
Multilingual Transfer Learning for Code-Switched Language and Speech Neural Modeling
Apr 13, 2021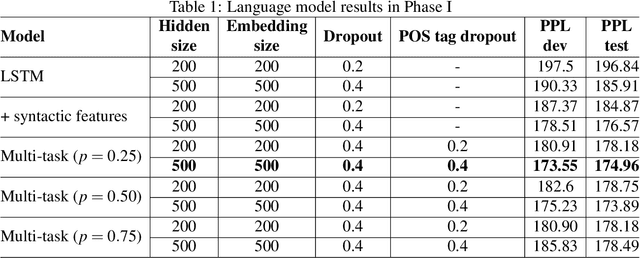
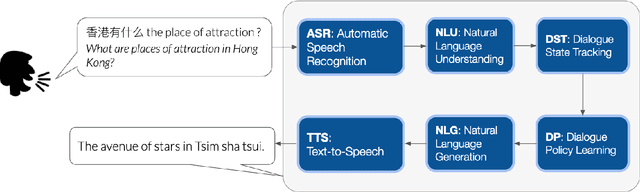
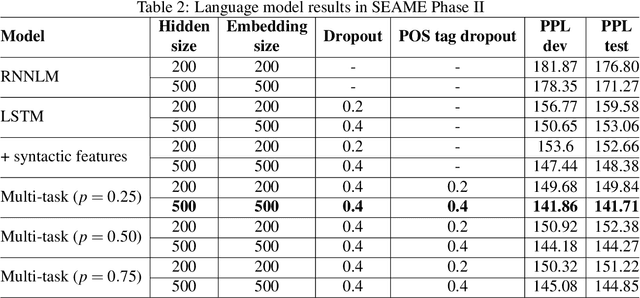
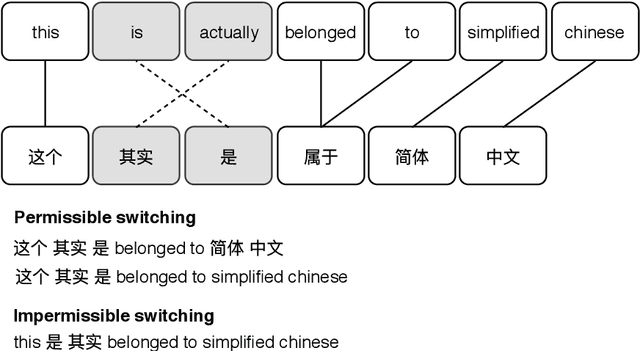
In this thesis, we address the data scarcity and limitations of linguistic theory by proposing language-agnostic multi-task training methods. First, we introduce a meta-learning-based approach, meta-transfer learning, in which information is judiciously extracted from high-resource monolingual speech data to the code-switching domain. The meta-transfer learning quickly adapts the model to the code-switching task from a number of monolingual tasks by learning to learn in a multi-task learning fashion. Second, we propose a novel multilingual meta-embeddings approach to effectively represent code-switching data by acquiring useful knowledge learned in other languages, learning the commonalities of closely related languages and leveraging lexical composition. The method is far more efficient compared to contextualized pre-trained multilingual models. Third, we introduce multi-task learning to integrate syntactic information as a transfer learning strategy to a language model and learn where to code-switch. To further alleviate the aforementioned issues, we propose a data augmentation method using Pointer-Gen, a neural network using a copy mechanism to teach the model the code-switch points from monolingual parallel sentences. We disentangle the need for linguistic theory, and the model captures code-switching points by attending to input words and aligning the parallel words, without requiring any word alignments or constituency parsers. More importantly, the model can be effectively used for languages that are syntactically different, and it outperforms the linguistic theory-based models.
Overlapping Community Detection in Temporal Text Networks
Jan 13, 2021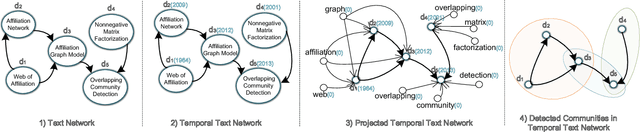
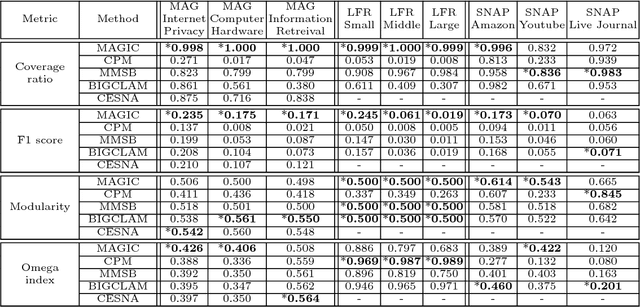
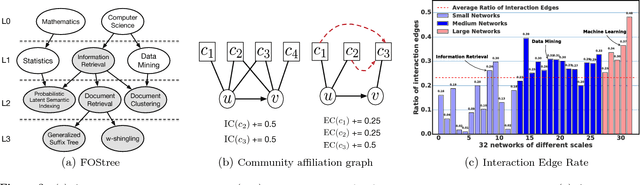

Analyzing the groups in the network based on same attributes, functions or connections between nodes is a way to understand network information. The task of discovering a series of node groups is called community detection. Generally, two types of information can be utilized to fulfill this task, i.e., the link structures and the node attributes. The temporal text network is a special kind of network that contains both sources of information. Typical representatives include online blog networks, the World Wide Web (WWW) and academic citation networks. In this paper, we study the problem of overlapping community detection in temporal text network. By examining 32 large temporal text networks, we find a lot of edges connecting two nodes with no common community and discover that nodes in the same community share similar textual contents. This scenario cannot be quantitatively modeled by practically all existing community detection methods. Motivated by these empirical observations, we propose MAGIC (Model Affiliation Graph with Interacting Communities), a generative model which captures community interactions and considers the information from both link structures and node attributes. Our experiments on 3 types of datasets show that MAGIC achieves large improvements over 4 state-of-the-art methods in terms of 4 widely-used metrics.
Feature Reuse and Fusion for Real-time Semantic segmentation
Jun 02, 2021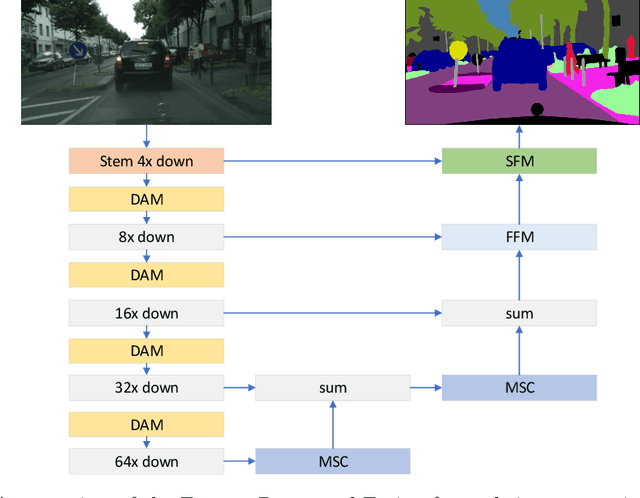
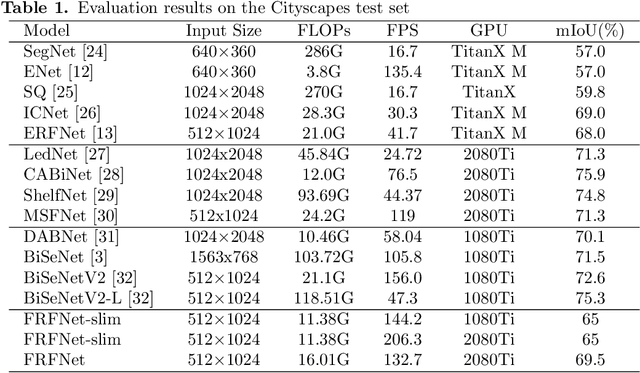
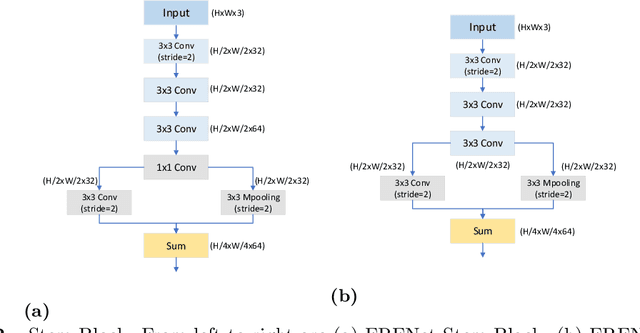

For real-time semantic segmentation, how to increase the speed while maintaining high resolution is a problem that has been discussed and solved. Backbone design and fusion design have always been two essential parts of real-time semantic segmentation. We hope to design a light-weight network based on previous design experience and reach the level of state-of-the-art real-time semantic segmentation without any pre-training. To achieve this goal, a encoder-decoder architectures are proposed to solve this problem by applying a decoder network onto a backbone model designed for real-time segmentation tasks and designed three different ways to fuse semantics and detailed information in the aggregation phase. We have conducted extensive experiments on two semantic segmentation benchmarks. Experiments on the Cityscapes and CamVid datasets show that the proposed FRFNet strikes a balance between speed calculation and accuracy. It achieves 69% Mean Intersection over Union (mIoU%) on the Cityscapes test dataset with the speed of 132on a single RTX 2080Ti card. The Code is available at https://github.com/favoMJ/FRFNet.
Multimodal Emergent Fake News Detection via Meta Neural Process Networks
Jun 22, 2021
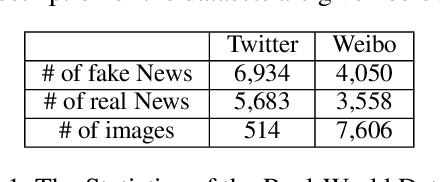
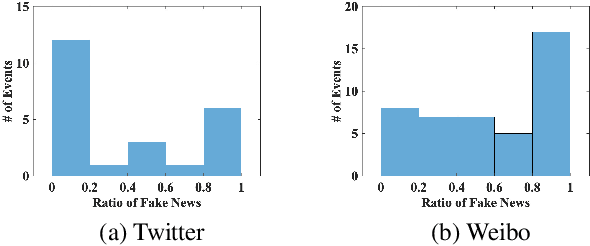

Fake news travels at unprecedented speeds, reaches global audiences and puts users and communities at great risk via social media platforms. Deep learning based models show good performance when trained on large amounts of labeled data on events of interest, whereas the performance of models tends to degrade on other events due to domain shift. Therefore, significant challenges are posed for existing detection approaches to detect fake news on emergent events, where large-scale labeled datasets are difficult to obtain. Moreover, adding the knowledge from newly emergent events requires to build a new model from scratch or continue to fine-tune the model, which can be challenging, expensive, and unrealistic for real-world settings. In order to address those challenges, we propose an end-to-end fake news detection framework named MetaFEND, which is able to learn quickly to detect fake news on emergent events with a few verified posts. Specifically, the proposed model integrates meta-learning and neural process methods together to enjoy the benefits of these approaches. In particular, a label embedding module and a hard attention mechanism are proposed to enhance the effectiveness by handling categorical information and trimming irrelevant posts. Extensive experiments are conducted on multimedia datasets collected from Twitter and Weibo. The experimental results show our proposed MetaFEND model can detect fake news on never-seen events effectively and outperform the state-of-the-art methods.