 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MiDeCon: Unsupervised and Accurate Fingerprint and Minutia Quality Assessment based on Minutia Detection Confidence
Jun 10, 2021
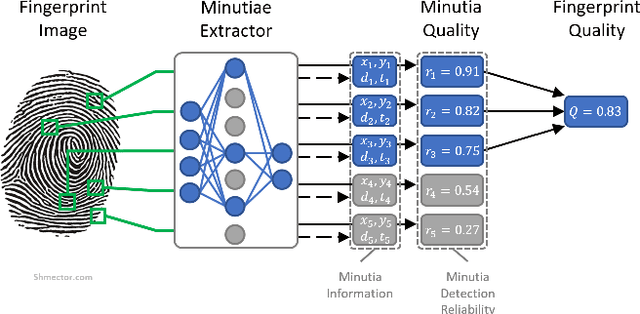
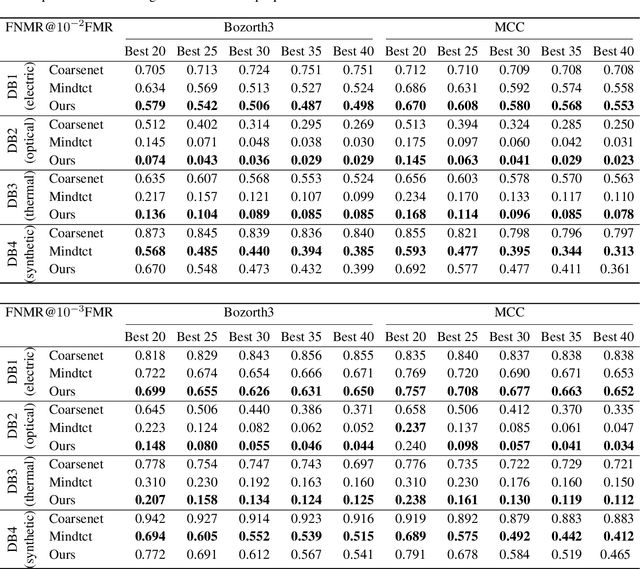
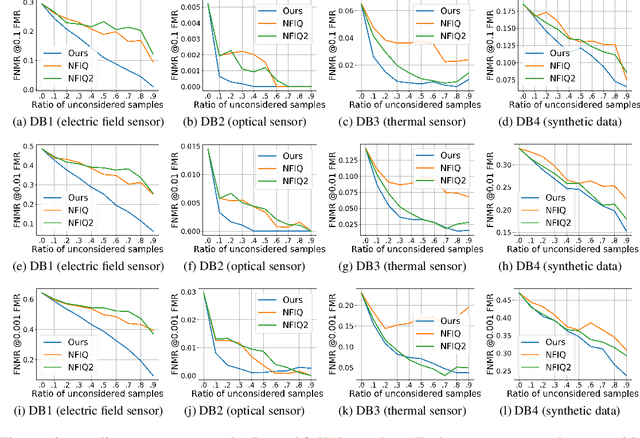
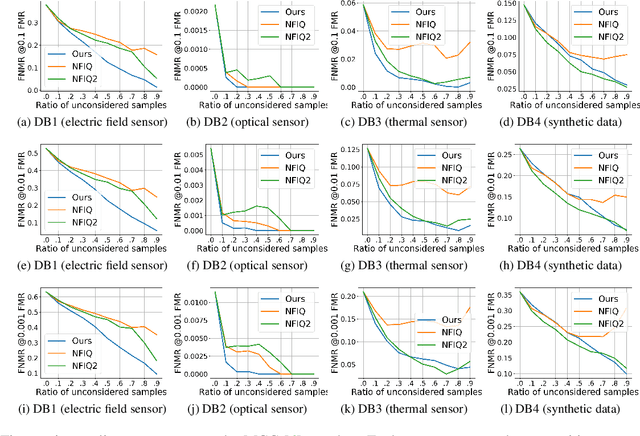
An essential factor to achieve high accuracies in fingerprint recognition systems is the quality of its samples. Previous works mainly proposed supervised solutions based on image properties that neglects the minutiae extraction process, despite that most fingerprint recognition techniques are based on detected minutiae. Consequently, a fingerprint image might be assigned a high quality even if the utilized minutia extractor produces unreliable information. In this work, we propose a novel concept of assessing minutia and fingerprint quality based on minutia detection confidence (MiDeCon). MiDeCon can be applied to an arbitrary deep learning based minutia extractor and does not require quality labels for learning. We propose using the detection reliability of the extracted minutia as its quality indicator. By combining the highest minutia qualities, MiDeCon also accurately determines the quality of a full fingerprint. Experiments are conducted on the publicly available databases of the FVC 2006 and compared against several baselines, such as NIST's widely-used fingerprint image quality software NFIQ1 and NFIQ2. The results demonstrate a significantly stronger quality assessment performance of the proposed MiDeCon-qualities as related works on both, minutia- and fingerprint-level. The implementation is publicly available.
Influence Estimation and Maximization via Neural Mean-Field Dynamics
Jun 03, 2021



We propose a novel learning framework using neural mean-field (NMF) dynamics for inference and estimation problems on heterogeneous diffusion networks. Our new framework leverages the Mori-Zwanzig formalism to obtain an exact evolution equation of the individual node infection probabilities, which renders a delay differential equation with memory integral approximated by learnable time convolution operators. Directly using information diffusion cascade data, our framework can simultaneously learn the structure of the diffusion network and the evolution of node infection probabilities. Connections between parameter learning and optimal control are also established, leading to a rigorous and implementable algorithm for training NMF. Moreover, we show that the projected gradient descent method can be employed to solve the challenging influence maximization problem, where the gradient is computed extremely fast by integrating NMF forward in time just once in each iteration. Extensive empirical studies show that our approach is versatile and robust to variations of the underlying diffusion network models, and significantly outperform existing approaches in accuracy and efficiency on both synthetic and real-world data.
Harmless label noise and informative soft-labels in supervised classification
Apr 07, 2021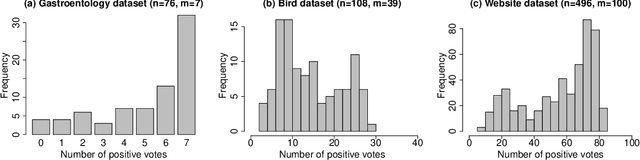
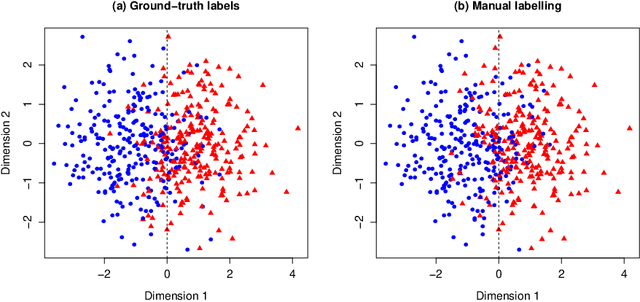

Manual labelling of training examples is common practice in supervised learning. When the labelling task is of non-trivial difficulty, the supplied labels may not be equal to the ground-truth labels, and label noise is introduced into the training dataset. If the manual annotation is carried out by multiple experts, the same training example can be given different class assignments by different experts, which is indicative of label noise. In the framework of model-based classification, a simple, but key observation is that when the manual labels are sampled using the posterior probabilities of class membership, the noisy labels are as valuable as the ground-truth labels in terms of statistical information. A relaxation of this process is a random effects model for imperfect labelling by a group that uses approximate posterior probabilities of class membership. The relative efficiency of logistic regression using the noisy labels compared to logistic regression using the ground-truth labels can then be derived. The main finding is that logistic regression can be robust to label noise when label noise and classification difficulty are positively correlated. In particular, when classification difficulty is the only source of label errors, multiple sets of noisy labels can supply more information for the estimation of a classification rule compared to the single set of ground-truth labels.
Audio-Oriented Multimodal Machine Comprehension: Task, Dataset and Model
Jul 04, 2021
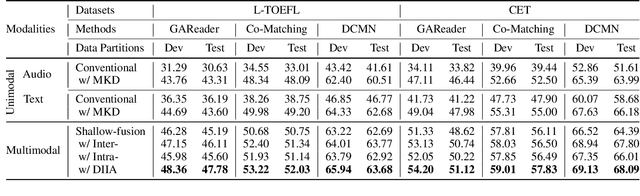
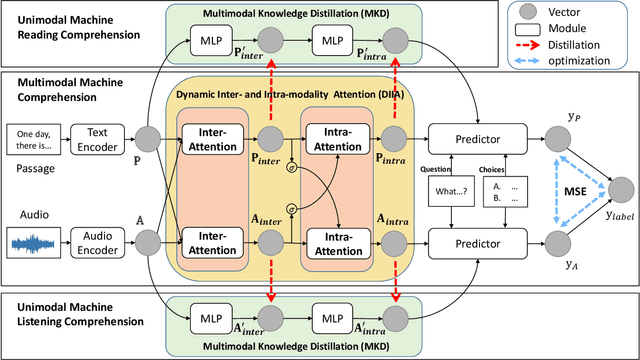
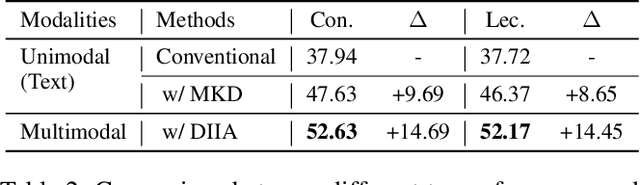
While Machine Comprehension (MC) has attracted extensive research interests in recent years, existing approaches mainly belong to the category of Machine Reading Comprehension task which mines textual inputs (paragraphs and questions) to predict the answers (choices or text spans). However, there are a lot of MC tasks that accept audio input in addition to the textual input, e.g. English listening comprehension test. In this paper, we target the problem of Audio-Oriented Multimodal Machine Comprehension, and its goal is to answer questions based on the given audio and textual information. To solve this problem, we propose a Dynamic Inter- and Intra-modality Attention (DIIA) model to effectively fuse the two modalities (audio and textual). DIIA can work as an independent component and thus be easily integrated into existing MC models. Moreover, we further develop a Multimodal Knowledge Distillation (MKD) module to enable our multimodal MC model to accurately predict the answers based only on either the text or the audio. As a result, the proposed approach can handle various tasks including: Audio-Oriented Multimodal Machine Comprehension, Machine Reading Comprehension and Machine Listening Comprehension, in a single model, making fair comparisons possible between our model and the existing unimodal MC models. Experimental results and analysis prove the effectiveness of the proposed approaches. First, the proposed DIIA boosts the baseline models by up to 21.08% in terms of accuracy; Second, under the unimodal scenarios, the MKD module allows our multimodal MC model to significantly outperform the unimodal models by up to 18.87%, which are trained and tested with only audio or textual data.
Domain Adaptation for Facial Expression Classifier via Domain Discrimination and Gradient Reversal
Jun 02, 2021
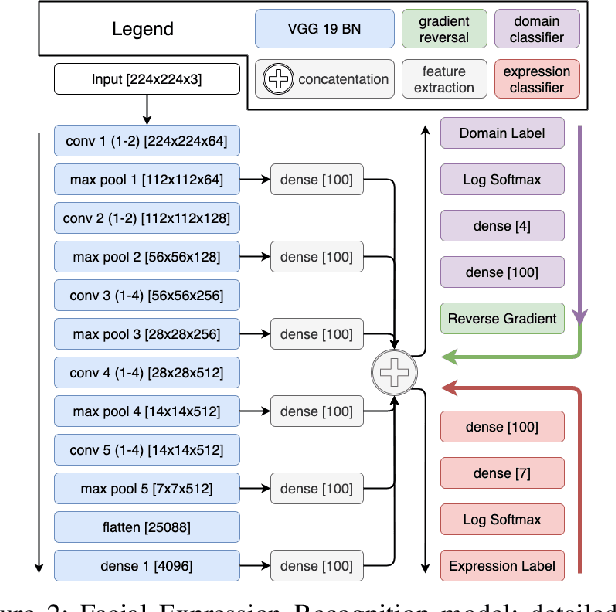
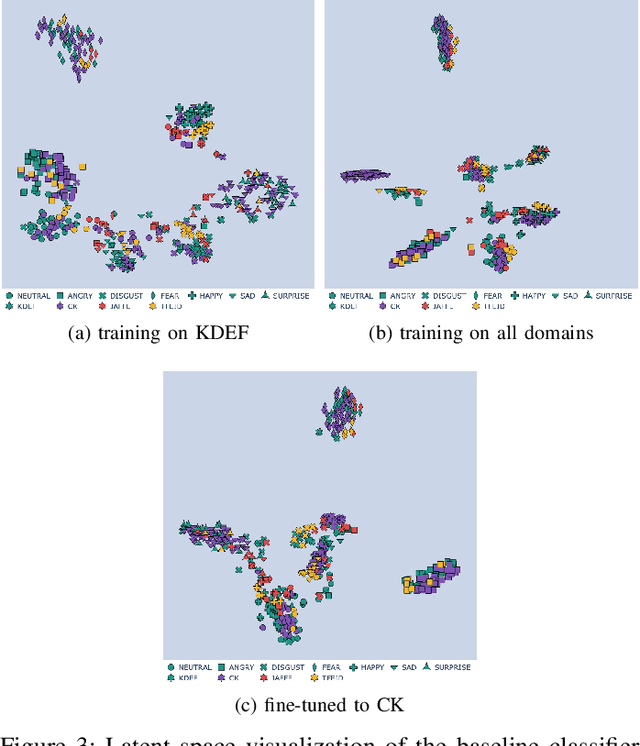
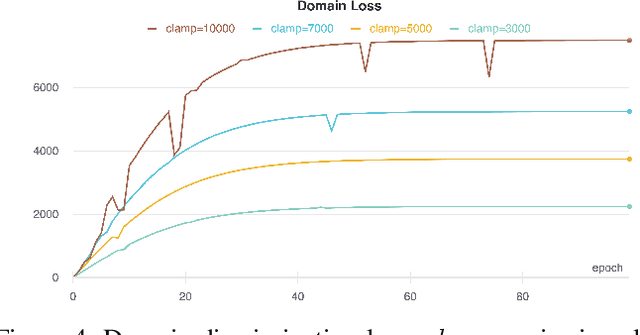
Bringing empathy to a computerized system could significantly improve the quality of human-computer communications, as soon as machines would be able to understand customer intentions and better serve their needs. According to different studies (Literature Review), visual information is one of the most important channels of human interaction and contains significant behavioral signals, that may be captured from facial expressions. Therefore, it is consistent and natural that the research in the field of Facial Expression Recognition (FER) has acquired increased interest over the past decade due to having diverse application area including health-care, sociology, psychology, driver-safety, virtual reality, cognitive sciences, security, entertainment, marketing, etc. We propose a new architecture for the task of FER and examine the impact of domain discrimination loss regularization on the learning process. With regard to observations, including both classical training conditions and unsupervised domain adaptation scenarios, important aspects of the considered domain adaptation approach integration are traced. The results may serve as a foundation for further research in the field.
A Mutual Reference Shape for Segmentation Fusion and Evaluation
Feb 05, 2021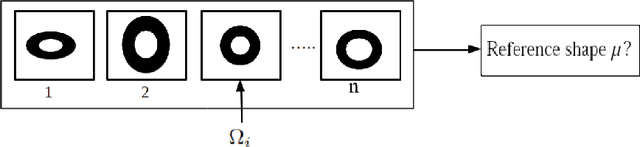

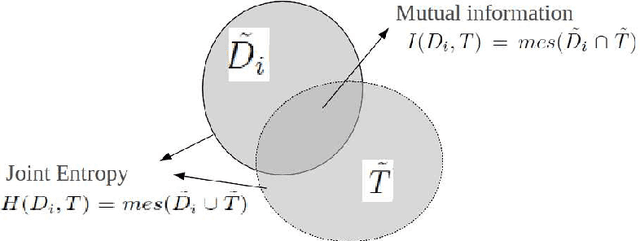
This paper proposes the estimation of a mutual shape from a set of different segmentation results using both active contours and information theory. The mutual shape is here defined as a consensus shape estimated from a set of different segmentations of the same object. In an original manner, such a shape is defined as the minimum of a criterion that benefits from both the mutual information and the joint entropy of the input segmentations. This energy criterion is justified using similarities between information theory quantities and area measures, and presented in a continuous variational framework. In order to solve this shape optimization problem, shape derivatives are computed for each term of the criterion and interpreted as an evolution equation of an active contour. A mutual shape is then estimated together with the sensitivity and specificity of each segmentation. Some synthetic examples allow us to cast the light on the difference between the mutual shape and an average shape. The applicability of our framework has also been tested for segmentation evaluation and fusion of different types of real images (natural color images, old manuscripts, medical images).
Multilingual Transfer Learning for Code-Switched Language and Speech Neural Modeling
Apr 13, 2021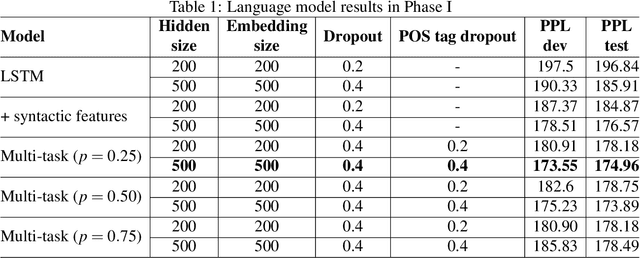
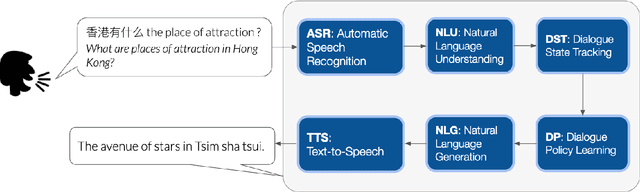
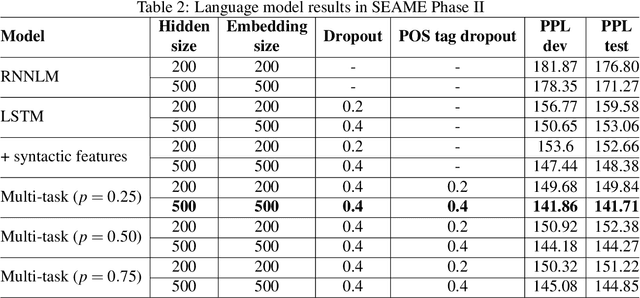
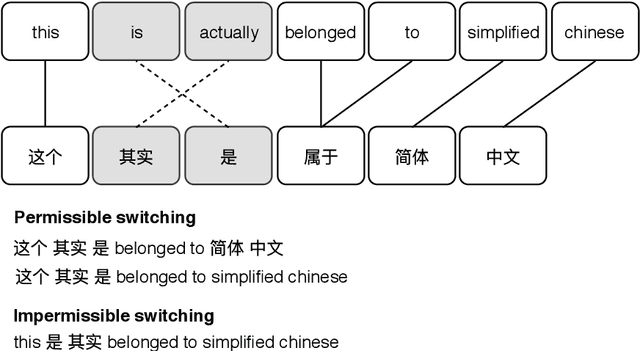
In this thesis, we address the data scarcity and limitations of linguistic theory by proposing language-agnostic multi-task training methods. First, we introduce a meta-learning-based approach, meta-transfer learning, in which information is judiciously extracted from high-resource monolingual speech data to the code-switching domain. The meta-transfer learning quickly adapts the model to the code-switching task from a number of monolingual tasks by learning to learn in a multi-task learning fashion. Second, we propose a novel multilingual meta-embeddings approach to effectively represent code-switching data by acquiring useful knowledge learned in other languages, learning the commonalities of closely related languages and leveraging lexical composition. The method is far more efficient compared to contextualized pre-trained multilingual models. Third, we introduce multi-task learning to integrate syntactic information as a transfer learning strategy to a language model and learn where to code-switch. To further alleviate the aforementioned issues, we propose a data augmentation method using Pointer-Gen, a neural network using a copy mechanism to teach the model the code-switch points from monolingual parallel sentences. We disentangle the need for linguistic theory, and the model captures code-switching points by attending to input words and aligning the parallel words, without requiring any word alignments or constituency parsers. More importantly, the model can be effectively used for languages that are syntactically different, and it outperforms the linguistic theory-based models.
Contrastive Reinforcement Learning of Symbolic Reasoning Domains
Jun 16, 2021
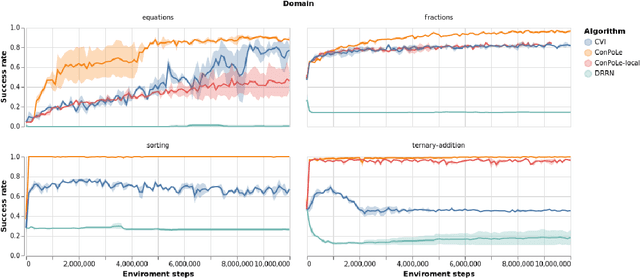
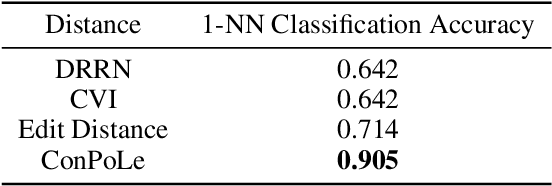
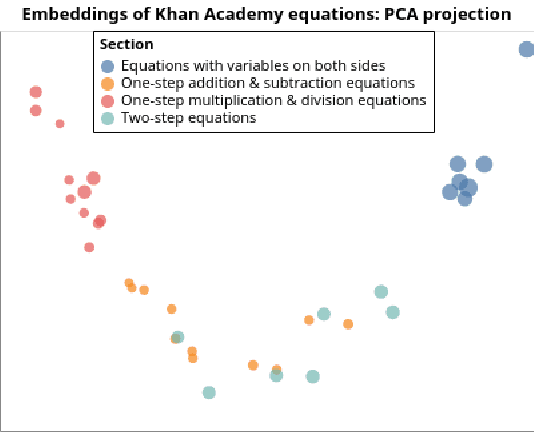
Abstract symbolic reasoning, as required in domains such as mathematics and logic, is a key component of human intelligence. Solvers for these domains have important applications, especially to computer-assisted education. But learning to solve symbolic problems is challenging for machine learning algorithms. Existing models either learn from human solutions or use hand-engineered features, making them expensive to apply in new domains. In this paper, we instead consider symbolic domains as simple environments where states and actions are given as unstructured text, and binary rewards indicate whether a problem is solved. This flexible setup makes it easy to specify new domains, but search and planning become challenging. We introduce four environments inspired by the Mathematics Common Core Curriculum, and observe that existing Reinforcement Learning baselines perform poorly. We then present a novel learning algorithm, Contrastive Policy Learning (ConPoLe) that explicitly optimizes the InfoNCE loss, which lower bounds the mutual information between the current state and next states that continue on a path to the solution. ConPoLe successfully solves all four domains. Moreover, problem representations learned by ConPoLe enable accurate prediction of the categories of problems in a real mathematics curriculum. Our results suggest new directions for reinforcement learning in symbolic domains, as well as applications to mathematics education.
On the Distribution, Sparsity, and Inference-time Quantization of Attention Values in Transformers
Jun 02, 2021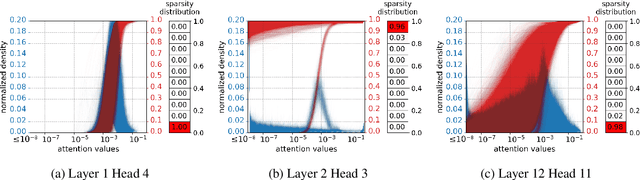
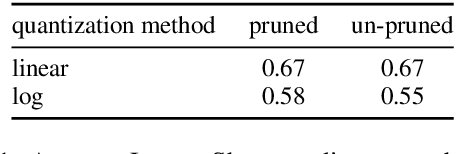
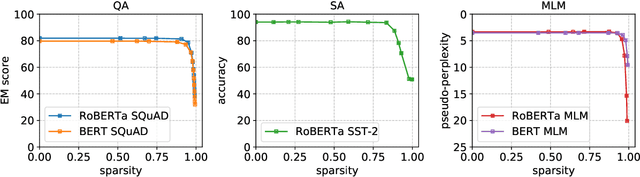
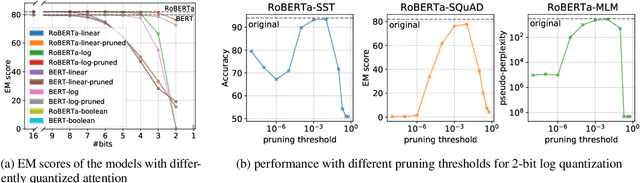
How much information do NLP tasks really need from a transformer's attention mechanism at application-time (inference)? From recent work, we know that there is sparsity in transformers and that the floating-points within its computation can be discretized to fewer values with minimal loss to task accuracies. However, this requires retraining or even creating entirely new models, both of which can be expensive and carbon-emitting. Focused on optimizations that do not require training, we systematically study the full range of typical attention values necessary. This informs the design of an inference-time quantization technique using both pruning and log-scaled mapping which produces only a few (e.g. $2^3$) unique values. Over the tasks of question answering and sentiment analysis, we find nearly 80% of attention values can be pruned to zeros with minimal ($< 1.0\%$) relative loss in accuracy. We use this pruning technique in conjunction with quantizing the attention values to only a 3-bit format, without retraining, resulting in only a 0.8% accuracy reduction on question answering with fine-tuned RoBERTa.
Sentiment Progression based Searching and Indexing of Literary Textual Artefacts
Jun 16, 2021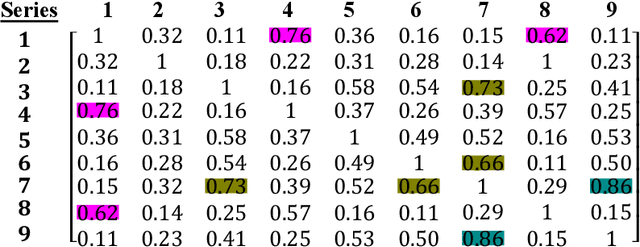
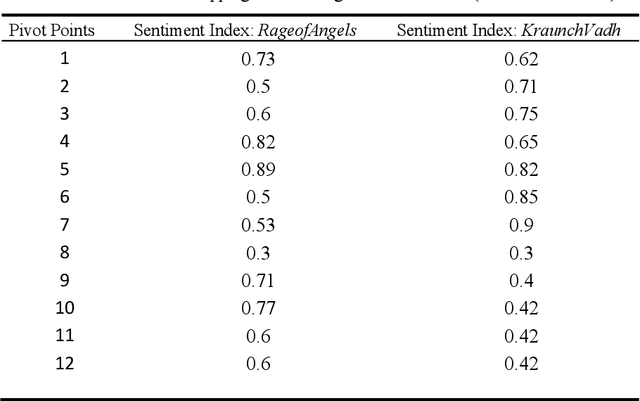
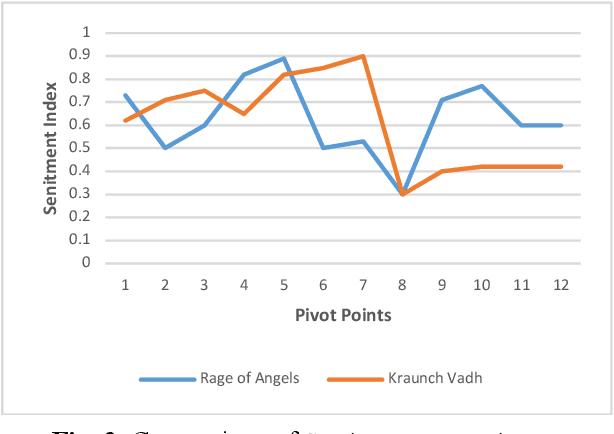
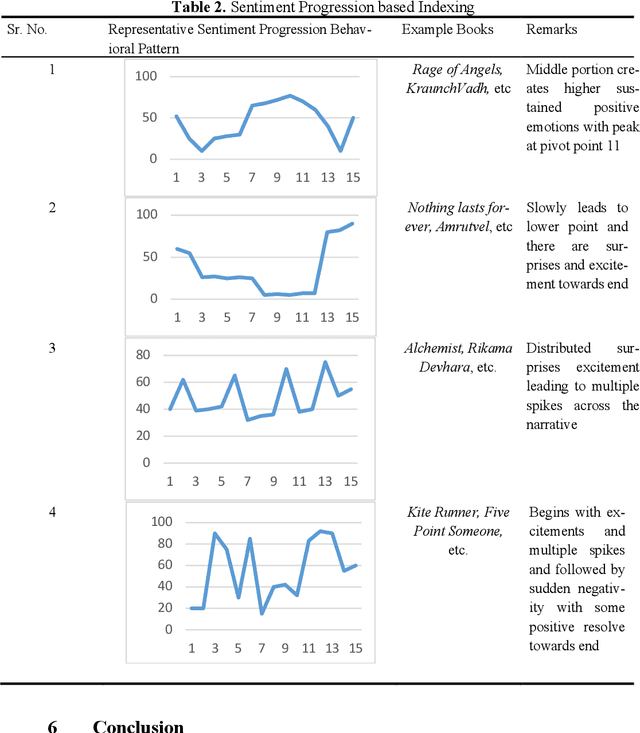
Literary artefacts are generally indexed and searched based on titles, meta data and keywords over the years. This searching and indexing works well when user/reader already knows about that particular creative textual artefact or document. This indexing and search hardly takes into account interest and emotional makeup of readers and its mapping to books. When a person is looking for a literary textual artefact, he/she might be looking for not only information but also to seek the joy of reading. In case of literary artefacts, progression of emotions across the key events could prove to be the key for indexing and searching. In this paper, we establish clusters among literary artefacts based on computational relationships among sentiment progressions using intelligent text analysis. We have created a database of 1076 English titles + 20 Marathi titles and also used database http://www.cs.cmu.edu/~dbamman/booksummaries.html with 16559 titles and their summaries. We have proposed Sentiment Progression based Indexing for searching and recommending books. This can be used to create personalized clusters of book titles of interest to readers. The analysis clearly suggests better searching and indexing when we are targeting book lovers looking for a particular type of book or creative artefact. This indexing and searching can find many real-life applications for recommending books.