 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Is Medical Chest X-ray Data Anonymous?
Mar 15, 2021
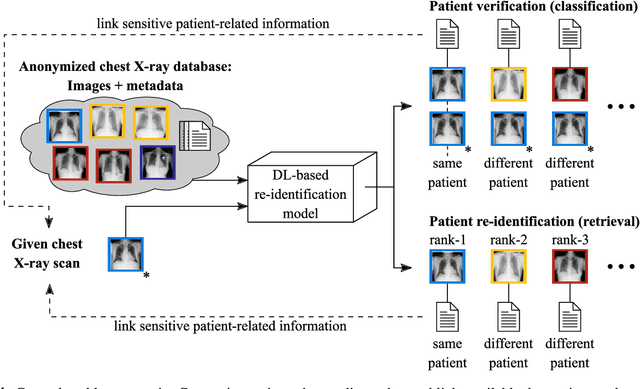
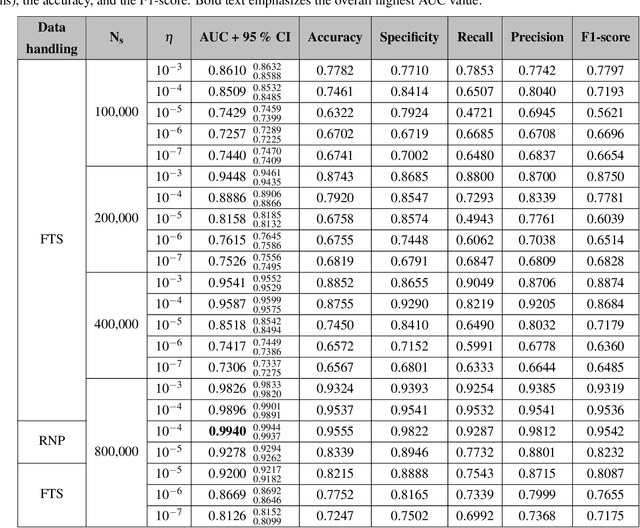
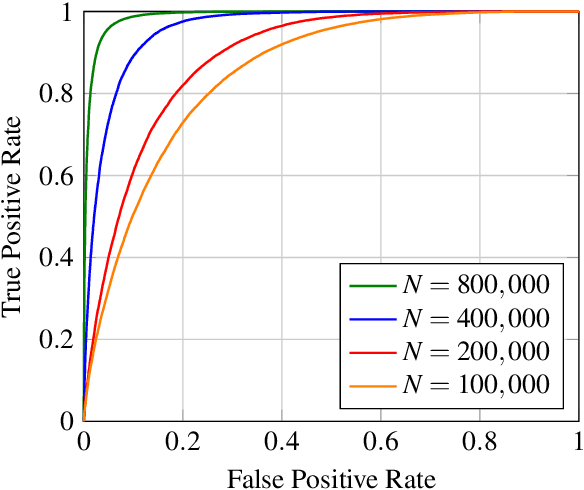
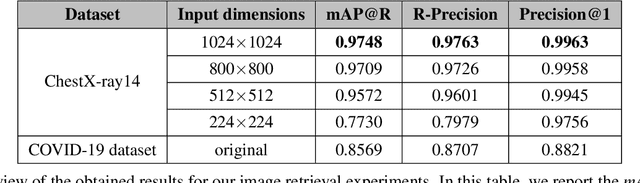
With the rise and ever-increasing potential of deep learning techniques in recent years, publicly available medical data sets became a key factor to enable reproducible development of diagnostic algorithms in the medical domain. Medical data contains sensitive patient-related information and is therefore usually anonymized by removing patient identifiers, e.g., patient names before publication. To the best of our knowledge, we are the first to show that a well-trained deep learning system is able to recover the patient identity from chest X-ray data. We demonstrate this using the publicly available large-scale ChestX-ray14 dataset, a collection of 112,120 frontal-view chest X-ray images from 30,805 unique patients. Our verification system is able to identify whether two frontal chest X-ray images are from the same person with an AUC of 0.9940 and a classification accuracy of 95.55%. We further highlight that the proposed system is able to reveal the same person even ten and more years after the initial scan. When pursuing a retrieval approach, we observe an mAP@R of 0.9748 and a precision@1 of 0.9963. Based on this high identification rate, a potential attacker may leak patient-related information and additionally cross-reference images to obtain more information. Thus, there is a great risk of sensitive content falling into unauthorized hands or being disseminated against the will of the concerned patients. Especially during the COVID-19 pandemic, numerous chest X-ray datasets have been published to advance research. Therefore, such data may be vulnerable to potential attacks by deep learning-based re-identification algorithms.
Performance Evaluation of Cooperative NOMA-based Improved Hybrid SWIPT Protocol
Jun 21, 2021
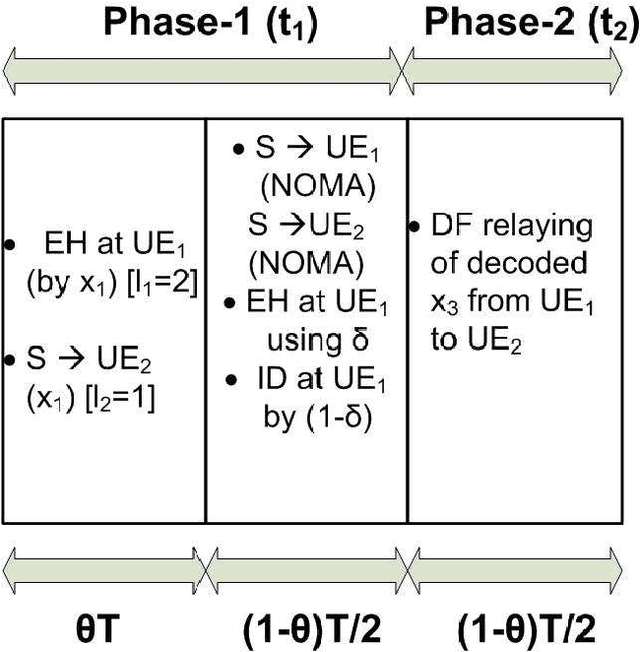
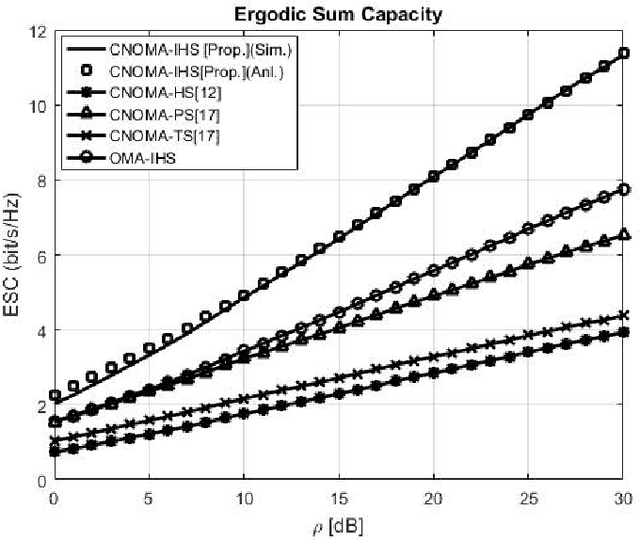
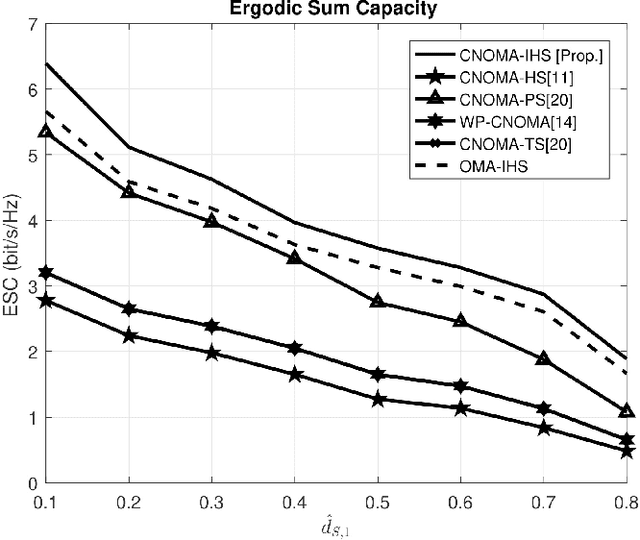
This study proposes the integration of a cooperative non-orthogonal multiple access (CNOMA) and improved hybrid simultaneous wireless information and power transfer (IHS SWIPT) protocol (termed as CNOMA-IHS) to enhance the spectral efficiency (SE) of a downlink (DL) CNOMA communication system. CNOMA-IHS scheme can enhance the ergodic sum capacity (ESC) and energy efficiency (EE) of DL CNOMA by transferring additional symbols towards the users and energize the relay operation as well without any additional resources (e.g., time slot/frequency/code). The analytical and simulation results indicate that the proposed CNOMA-IHS scheme outperforms other existing SWIPT-based schemes (e.g., CNOMA with hybrid SWIPT, CNOMA with power-splitting SWIPT, wireless-powered CNOMA, CNOMA with time switching SWIPT, and orthogonal multiple access with IHS SWIPT) in terms of the ESC. Moreover, the CNOMA-IHS scheme also enhances EE compared with other conventional TS-SWIPT-based schemes, which is also illustrated by the simulation results. In addition, the proposed CNOMA-IHS scheme with the considered EE optimization technique outplayed the proposed CNOMA-IHS scheme without EE optimization and other existing TS-SWIPT-based schemes in terms of EE.
Gender Bias in Machine Translation
May 07, 2021
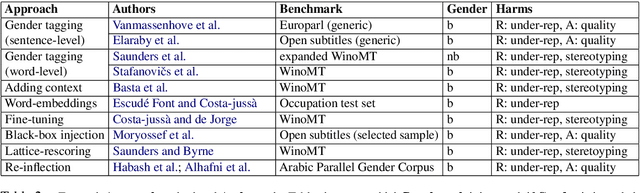
Machine translation (MT) technology has facilitated our daily tasks by providing accessible shortcuts for gathering, elaborating and communicating information. However, it can suffer from biases that harm users and society at large. As a relatively new field of inquiry, gender bias in MT still lacks internal cohesion, which advocates for a unified framework to ease future research. To this end, we: i) critically review current conceptualizations of bias in light of theoretical insights from related disciplines, ii) summarize previous analyses aimed at assessing gender bias in MT, iii) discuss the mitigating strategies proposed so far, and iv) point toward potential directions for future work.
Search from History and Reason for Future: Two-stage Reasoning on Temporal Knowledge Graphs
Jun 01, 2021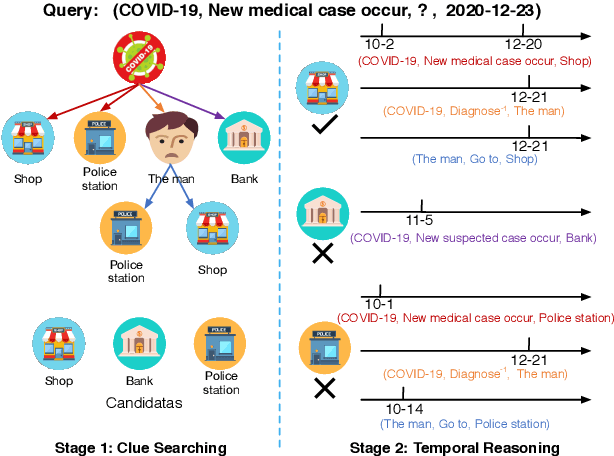
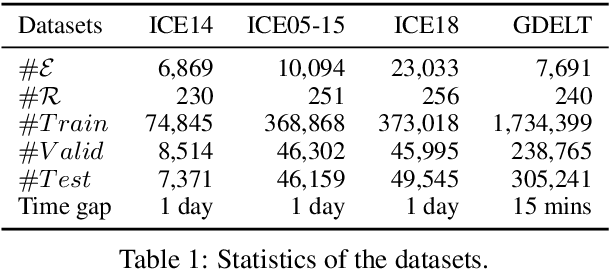
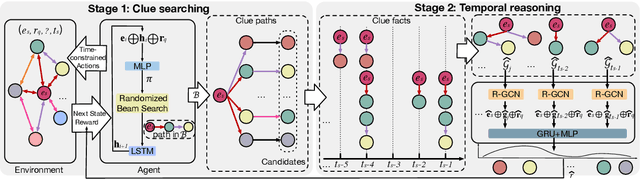
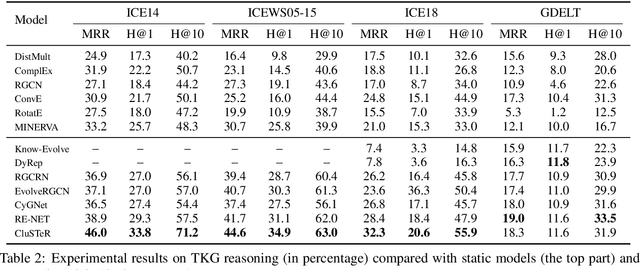
Temporal Knowledge Graphs (TKGs) have been developed and used in many different areas. Reasoning on TKGs that predicts potential facts (events) in the future brings great challenges to existing models. When facing a prediction task, human beings usually search useful historical information (i.e., clues) in their memories and then reason for future meticulously. Inspired by this mechanism, we propose CluSTeR to predict future facts in a two-stage manner, Clue Searching and Temporal Reasoning, accordingly. Specifically, at the clue searching stage, CluSTeR learns a beam search policy via reinforcement learning (RL) to induce multiple clues from historical facts. At the temporal reasoning stage, it adopts a graph convolution network based sequence method to deduce answers from clues. Experiments on four datasets demonstrate the substantial advantages of CluSTeR compared with the state-of-the-art methods. Moreover, the clues found by CluSTeR further provide interpretability for the results.
Form2Seq : A Framework for Higher-Order Form Structure Extraction
Jul 09, 2021
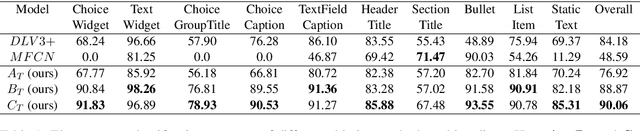
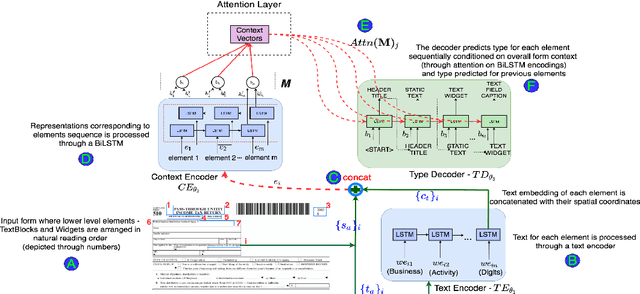
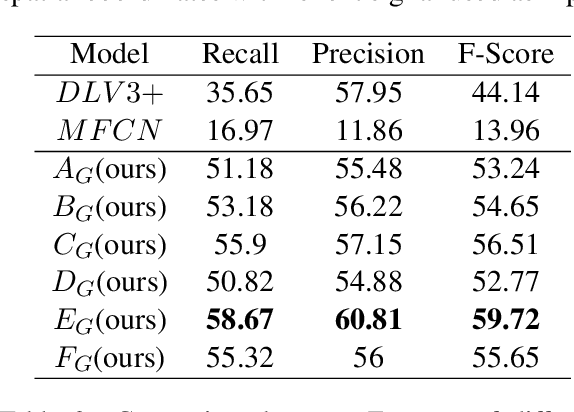
Document structure extraction has been a widely researched area for decades with recent works performing it as a semantic segmentation task over document images using fully-convolution networks. Such methods are limited by image resolution due to which they fail to disambiguate structures in dense regions which appear commonly in forms. To mitigate this, we propose Form2Seq, a novel sequence-to-sequence (Seq2Seq) inspired framework for structure extraction using text, with a specific focus on forms, which leverages relative spatial arrangement of structures. We discuss two tasks; 1) Classification of low-level constituent elements (TextBlock and empty fillable Widget) into ten types such as field captions, list items, and others; 2) Grouping lower-level elements into higher-order constructs, such as Text Fields, ChoiceFields and ChoiceGroups, used as information collection mechanism in forms. To achieve this, we arrange the constituent elements linearly in natural reading order, feed their spatial and textual representations to Seq2Seq framework, which sequentially outputs prediction of each element depending on the final task. We modify Seq2Seq for grouping task and discuss improvements obtained through cascaded end-to-end training of two tasks versus training in isolation. Experimental results show the effectiveness of our text-based approach achieving an accuracy of 90% on classification task and an F1 of 75.82, 86.01, 61.63 on groups discussed above respectively, outperforming segmentation baselines. Further we show our framework achieves state of the results for table structure recognition on ICDAR 2013 dataset.
LSTM Based Sentiment Analysis for Cryptocurrency Prediction
Mar 27, 2021

Recent studies in big data analytics and natural language processing develop automatic techniques in analyzing sentiment in the social media information. In addition, the growing user base of social media and the high volume of posts also provide valuable sentiment information to predict the price fluctuation of the cryptocurrency. This research is directed to predicting the volatile price movement of cryptocurrency by analyzing the sentiment in social media and finding the correlation between them. While previous work has been developed to analyze sentiment in English social media posts, we propose a method to identify the sentiment of the Chinese social media posts from the most popular Chinese social media platform Sina-Weibo. We develop the pipeline to capture Weibo posts, describe the creation of the crypto-specific sentiment dictionary, and propose a long short-term memory (LSTM) based recurrent neural network along with the historical cryptocurrency price movement to predict the price trend for future time frames. The conducted experiments demonstrate the proposed approach outperforms the state of the art auto regressive based model by 18.5% in precision and 15.4% in recall.
Generalization in the Face of Adaptivity: A Bayesian Perspective
Jun 20, 2021
Repeated use of a data sample via adaptively chosen queries can rapidly lead to overfitting, wherein the issued queries yield answers on the sample that differ wildly from the values of those queries on the underlying data distribution. Differential privacy provides a tool to ensure generalization despite adaptively-chosen queries, but its worst-case nature means that it cannot, for example, yield improved results for low-variance queries. In this paper, we give a simple new characterization that illuminates the core problem of adaptive data analysis. We show explicitly that the harms of adaptivity come from the covariance between the behavior of future queries and a Bayes factor-based measure of how much information about the data sample was encoded in the responses given to past queries. We leverage this intuition to introduce a new stability notion; we then use it to prove new generalization results for the most basic noise-addition mechanisms (Laplace and Gaussian noise addition), with guarantees that scale with the variance of the queries rather than the square of their range. Our characterization opens the door to new insights and new algorithms for the fundamental problem of achieving generalization in adaptive data analysis.
Resource-aware Online Parameter Adaptation for Computationally-constrained Visual-Inertial Navigation Systems
Jun 01, 2021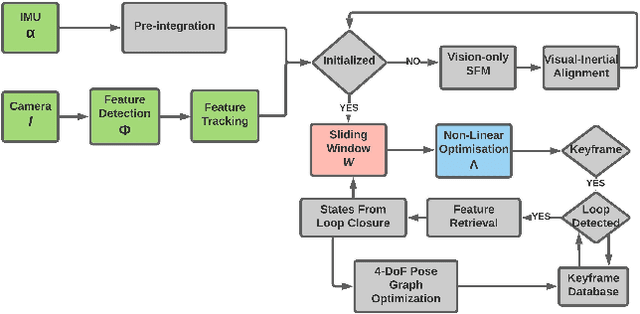
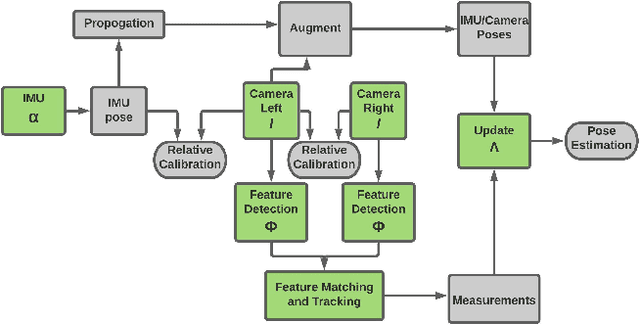
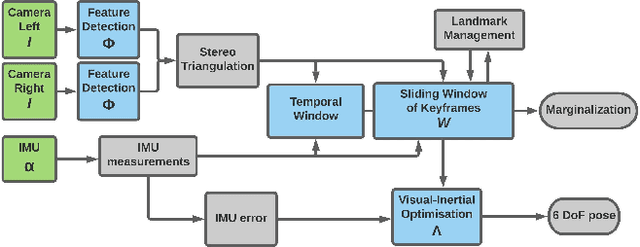
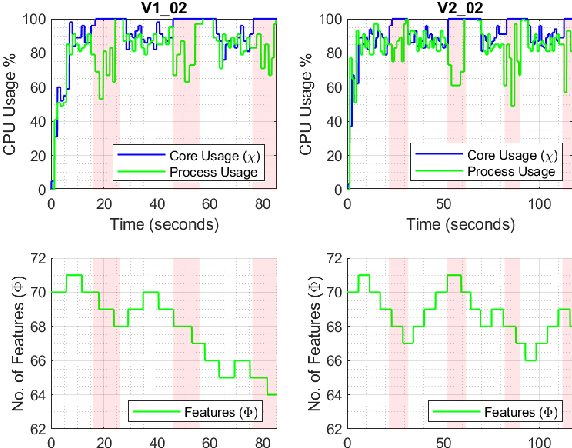
In this paper, a computational resources-aware parameter adaptation method for visual-inertial navigation systems is proposed with the goal of enabling the improved deployment of such algorithms on computationally constrained systems. Such a capacity can prove critical when employed on ultra-lightweight systems or alongside mission critical computationally expensive processes. To achieve this objective, the algorithm proposes selected changes in the vision front-end and optimization back-end of visual-inertial odometry algorithms, both prior to execution and in real-time based on an online profiling of available resources. The method also utilizes information from the motion dynamics experienced by the system to manipulate parameters online. The general policy is demonstrated on three established algorithms, namely S-MSCKF, VINS-Mono and OKVIS and has been verified experimentally on the EuRoC dataset. The proposed approach achieved comparable performance at a fraction of the original computational cost.
Exploring the Scope of Using News Articles to Understand Development Patterns of Districts in India
Jul 03, 2021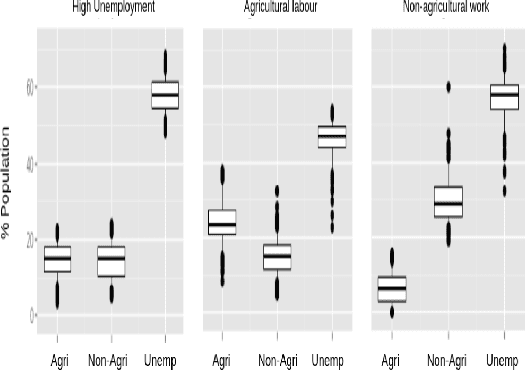
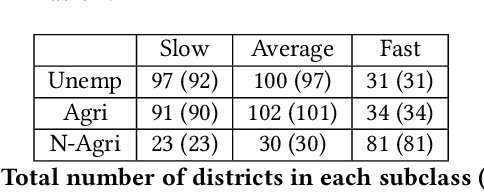
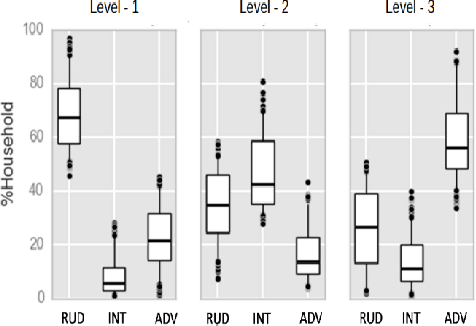

Understanding what factors bring about socio-economic development may often suffer from the streetlight effect, of analyzing the effect of only those variables that have been measured and are therefore available for analysis. How do we check whether all worthwhile variables have been instrumented and considered when building an econometric development model? We attempt to address this question by building unsupervised learning methods to identify and rank news articles about diverse events occurring in different districts of India, that can provide insights about what may have transpired in the districts. This can help determine whether variables related to these events are indeed available or not to model the development of these districts. We also describe several other applications that emerge from this approach, such as to use news articles to understand why pairs of districts that may have had similar socio-economic indicators approximately ten years back ended up at different levels of development currently, and another application that generates a newsfeed of unusual news articles that do not conform to news articles about typical districts with a similar socio-economic profile. These applications outline the need for qualitative data to augment models based on quantitative data, and are meant to open up research on new ways to mine information from unstructured qualitative data to understand development.
* 11 pages of main text, 4 pages of supplementary material
Learning-Based UAV Trajectory Optimization with Collision Avoidance and Connectivity Constraints
Apr 03, 2021
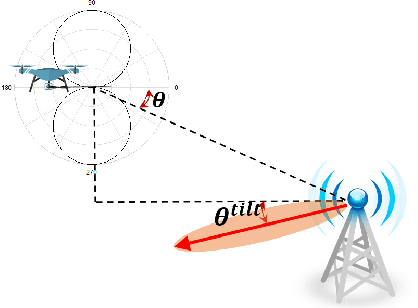
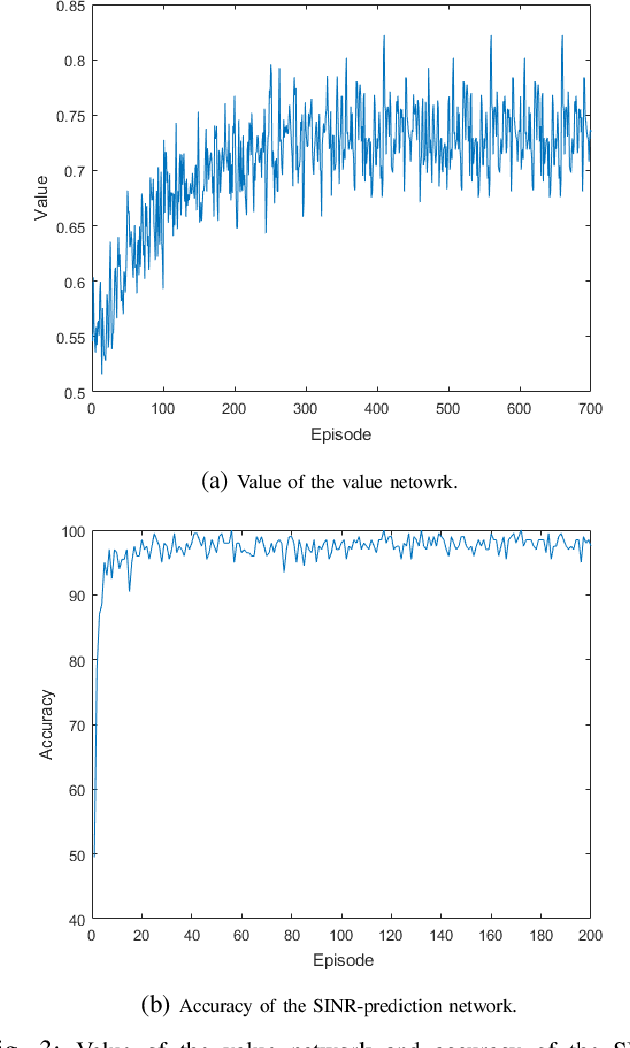
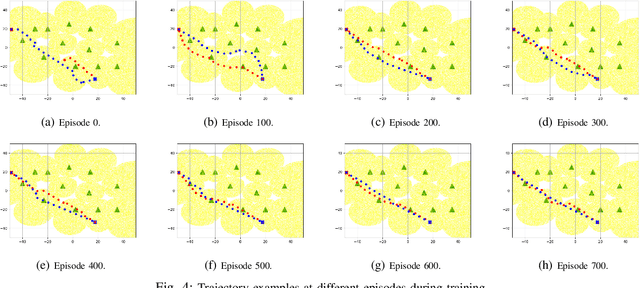
Unmanned aerial vehicles (UAVs) are expected to be an integral part of wireless networks, and determining collision-free trajectories for multiple UAVs while satisfying requirements of connectivity with ground base stations (GBSs) is a challenging task. In this paper, we first reformulate the multi-UAV trajectory optimization problem with collision avoidance and wireless connectivity constraints as a sequential decision making problem in the discrete time domain. We, then, propose a decentralized deep reinforcement learning approach to solve the problem. More specifically, a value network is developed to encode the expected time to destination given the agent's joint state (including the agent's information, the nearby agents' observable information, and the locations of the nearby GBSs). A signal-to-interference-plus-noise ratio (SINR)-prediction neural network is also designed, using accumulated SINR measurements obtained when interacting with the cellular network, to map the GBSs' locations into the SINR levels in order to predict the UAV's SINR. Numerical results show that with the value network and SINR-prediction network, real-time navigation for multi-UAVs can be efficiently performed in various environments with high success rate.