 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Related family-based attribute reduction of covering information systems when varying attribute sets
Nov 16, 2017
In practical situations, there are many dynamic covering information systems with variations of attributes, but there are few studies on related family-based attribute reduction of dynamic covering information systems. In this paper, we first investigate updated mechanisms of constructing attribute reducts for consistent and inconsistent covering information systems when varying attribute sets by using related families. Then we employ examples to illustrate how to compute attribute reducts of dynamic covering information systems with variations of attribute sets. Finally, the experimental results illustrates that the related family-based methods are effective to perform attribute reduction of dynamic covering information systems when attribute sets are varying with time.
Human Action Recognition Based on Multi-scale Feature Maps from Depth Video Sequences
Jan 19, 2021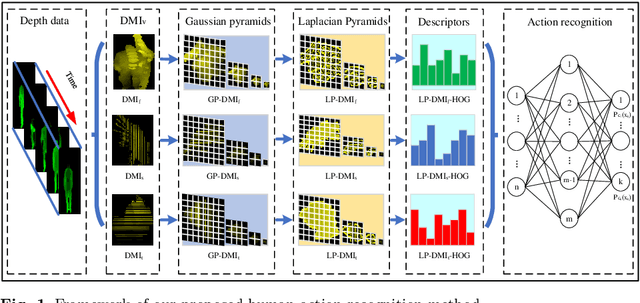
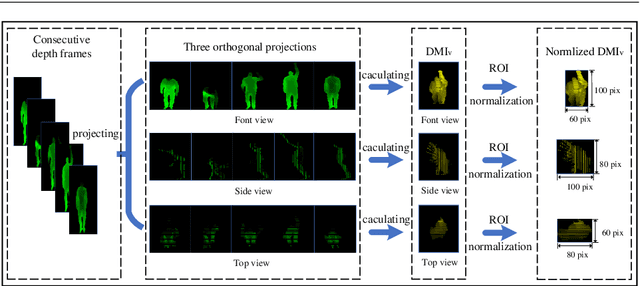

Human action recognition is an active research area in computer vision. Although great process has been made, previous methods mostly recognize actions based on depth data at only one scale, and thus they often neglect multi-scale features that provide additional information action recognition in practical application scenarios. In this paper, we present a novel framework focusing on multi-scale motion information to recognize human actions from depth video sequences. We propose a multi-scale feature map called Laplacian pyramid depth motion images(LP-DMI). We employ depth motion images (DMI) as the templates to generate the multi-scale static representation of actions. Then, we caculate LP-DMI to enhance multi-scale dynamic information of motions and reduces redundant static information in human bodies. We further extract the multi-granularity descriptor called LP-DMI-HOG to provide more discriminative features. Finally, we utilize extreme learning machine (ELM) for action classification. The proposed method yeilds the recognition accuracy of 93.41%, 85.12%, 91.94% on public MSRAction3D dataset, UTD-MHAD and DHA dataset. Through extensive experiments, we prove that our method outperforms state-of-the-art benchmarks.
Interactive GIS Web-Atlas for Twelve Pacific Islands Countries
Jul 15, 2021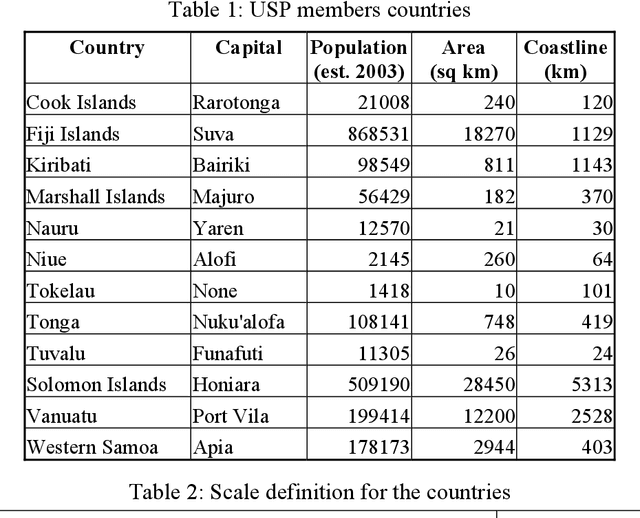
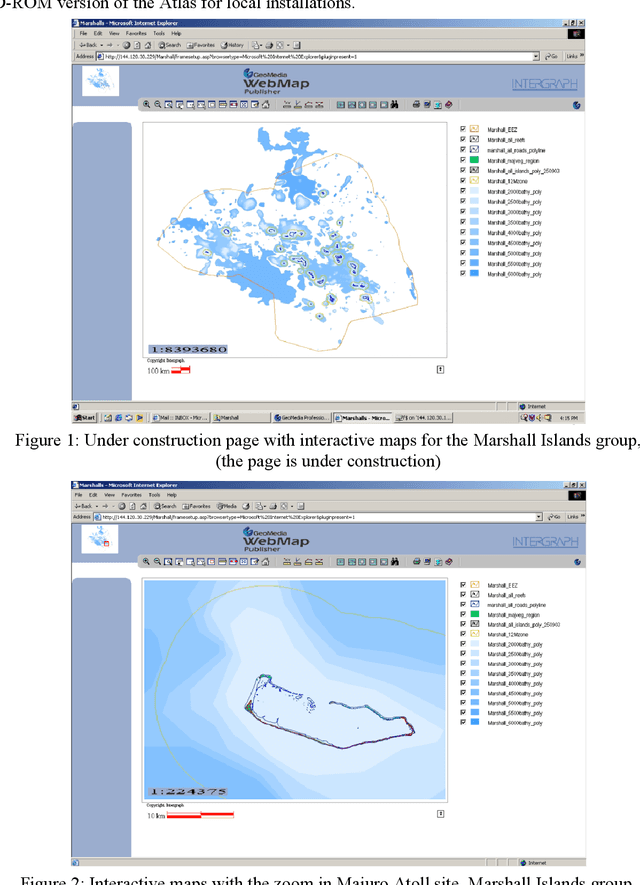
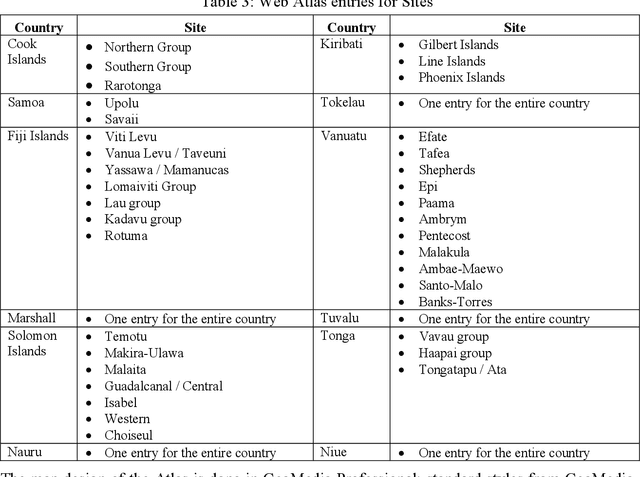
This article deals with the development of an interactive up-to-date Pacific Islands Web GIS Atlas. It focuses on the compilation of spatial data from the twelve member countries of the University of the South Pacific (Cook Islands, Fiji Islands, Kiribati Islands, Marshall Islands, Nauru, Niue, Tonga, Tuvalu, Tokelau, Solomon Islands, Vanuatu, and Western Samoa). A previous bitmap web Atlas was created in 1996, and was a pilot activity investigating the potential for using Geographical Information Systems (GIS) in the South Pacific. The objective of the new atlas is to provide sets of spatial and attributive data and maps for use of educators, students, researchers, policy makers and other relevant user groups and the public. GIS is a highly flexible and dynamic technology that allows the construction and analysis of maps and data sets from a variety of sources and formats. Nowadays, GIS application has moved from local and client-server applications to a three-tier architecture: Client (Web Browser) -- Application Web Map Server -- Spatial Data Warehouses. The objective of this project is to produce an Atlas that will include interactive maps and data on an Application Web Map Server. Intergraph products such as GeoMedia Professional, Web Map and Web Publisher have been selected for the web atlas production and design. In an interactive environment, an atlas will be composed from a series of maps and data profiles, which will be based on legend entries, queries, hot spots and cartographic tools. Only the first stage of development of the atlas and related technological solutions are outlined in this article.
A Multi-task convolutional neural network for blind stereoscopic image quality assessment using naturalness analysis
Jun 21, 2021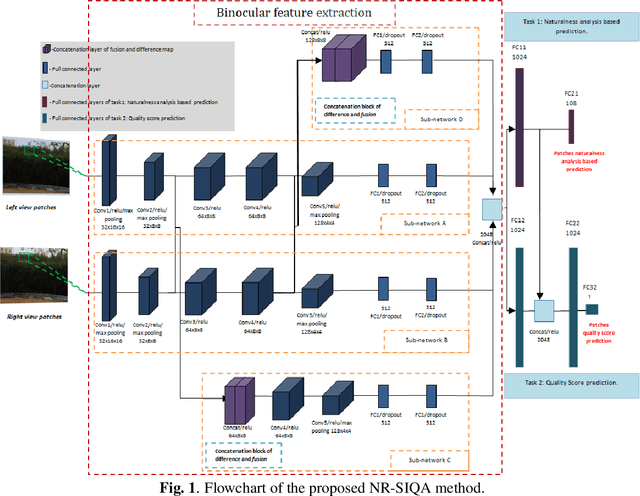
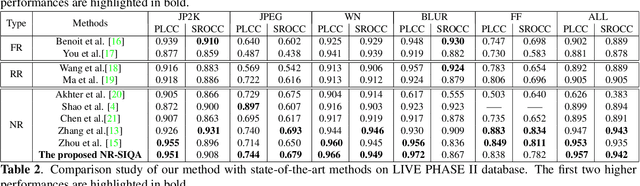
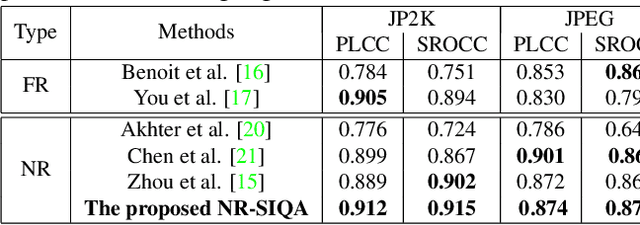
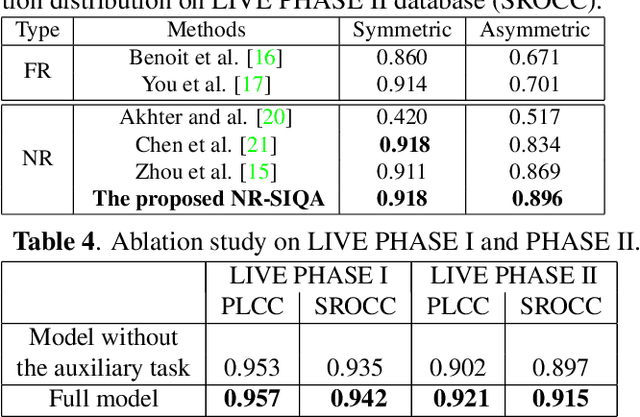
This paper addresses the problem of blind stereoscopic image quality assessment (NR-SIQA) using a new multi-task deep learning based-method. In the field of stereoscopic vision, the information is fairly distributed between the left and right views as well as the binocular phenomenon. In this work, we propose to integrate these characteristics to estimate the quality of stereoscopic images without reference through a convolutional neural network. Our method is based on two main tasks: the first task predicts naturalness analysis based features adapted to stereo images, while the second task predicts the quality of such images. The former, so-called auxiliary task, aims to find more robust and relevant features to improve the quality prediction. To do this, we compute naturalness-based features using a Natural Scene Statistics (NSS) model in the complex wavelet domain. It allows to capture the statistical dependency between pairs of the stereoscopic images. Experiments are conducted on the well known LIVE PHASE I and LIVE PHASE II databases. The results obtained show the relevance of our method when comparing with those of the state-of-the-art. Our code is available online on https://github.com/Bourbia-Salima/multitask-cnn-nrsiqa_2021.
Interventional Video Grounding with Dual Contrastive Learning
Jun 21, 2021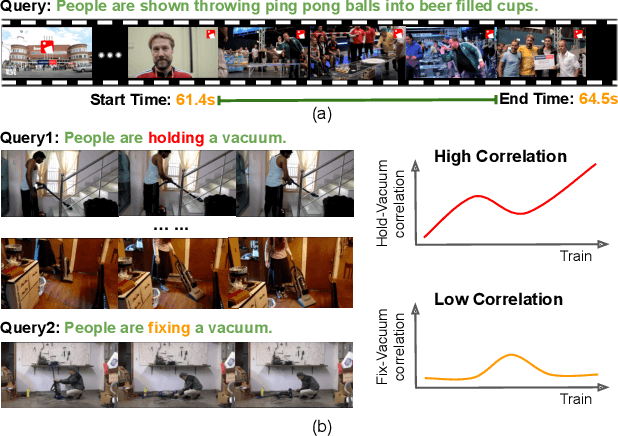
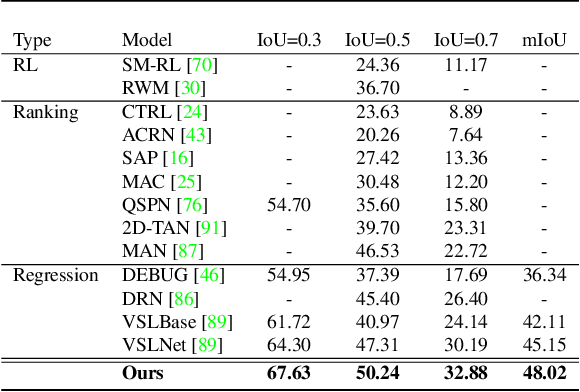
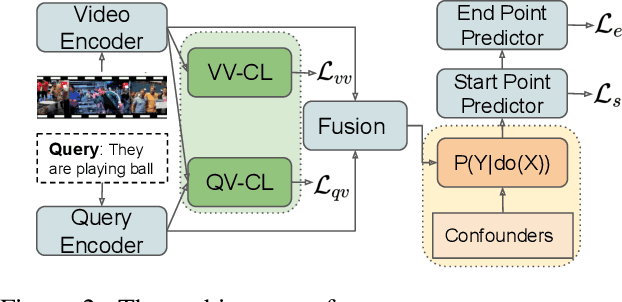
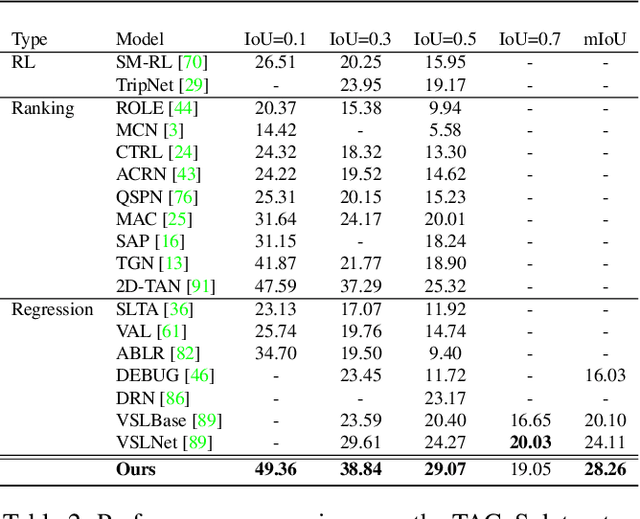
Video grounding aims to localize a moment from an untrimmed video for a given textual query. Existing approaches focus more on the alignment of visual and language stimuli with various likelihood-based matching or regression strategies, i.e., P(Y|X). Consequently, these models may suffer from spurious correlations between the language and video features due to the selection bias of the dataset. 1) To uncover the causality behind the model and data, we first propose a novel paradigm from the perspective of the causal inference, i.e., interventional video grounding (IVG) that leverages backdoor adjustment to deconfound the selection bias based on structured causal model (SCM) and do-calculus P(Y|do(X)). Then, we present a simple yet effective method to approximate the unobserved confounder as it cannot be directly sampled from the dataset. 2) Meanwhile, we introduce a dual contrastive learning approach (DCL) to better align the text and video by maximizing the mutual information (MI) between query and video clips, and the MI between start/end frames of a target moment and the others within a video to learn more informative visual representations. Experiments on three standard benchmarks show the effectiveness of our approaches.
Planning Multimodal Exploratory Actions for Online Robot Attribute Learning
Jun 06, 2021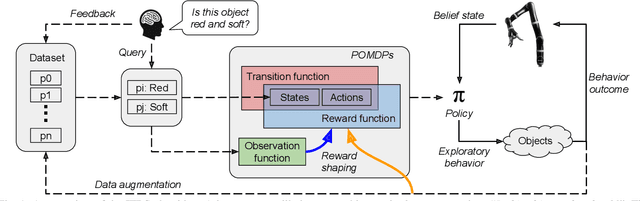

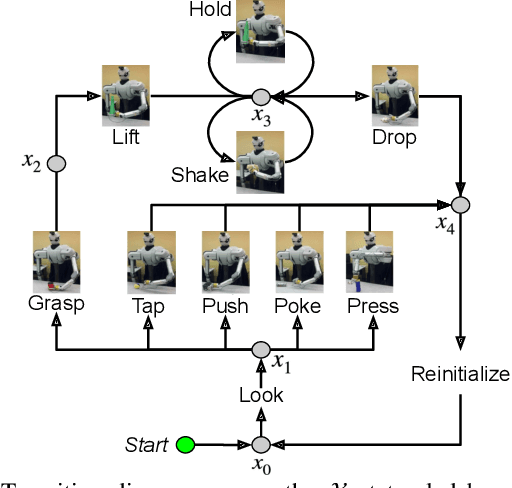
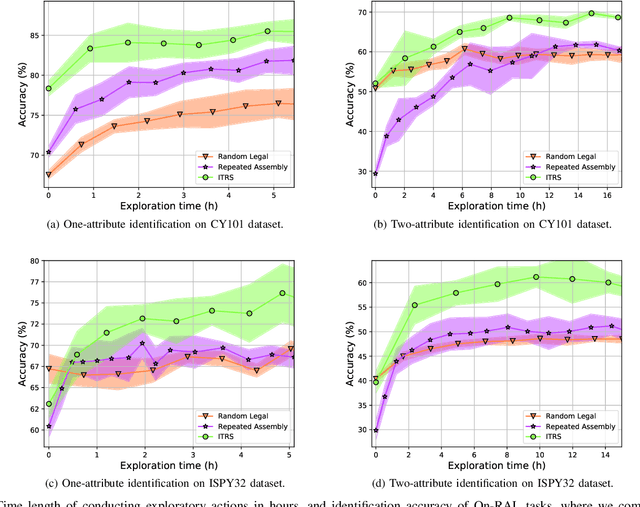
Robots frequently need to perceive object attributes, such as "red," "heavy," and "empty," using multimodal exploratory actions, such as "look," "lift," and "shake." Robot attribute learning algorithms aim to learn an observation model for each perceivable attribute given an exploratory action. Once the attribute models are learned, they can be used to identify attributes of new objects, answering questions, such as "Is this object red and empty?" Attribute learning and identification are being treated as two separate problems in the literature. In this paper, we first define a new problem called online robot attribute learning (On-RAL), where the robot works on attribute learning and attribute identification simultaneously. Then we develop an algorithm called information-theoretic reward shaping (ITRS) that actively addresses the trade-off between exploration and exploitation in On-RAL problems. ITRS was compared with competitive robot attribute learning baselines, and experimental results demonstrate ITRS' superiority in learning efficiency and identification accuracy.
Iterative Methods for Private Synthetic Data: Unifying Framework and New Methods
Jun 14, 2021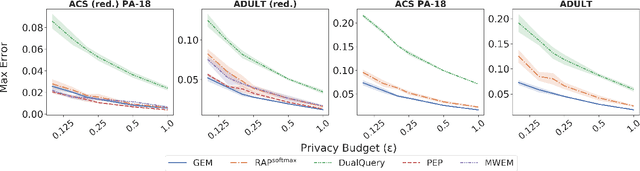
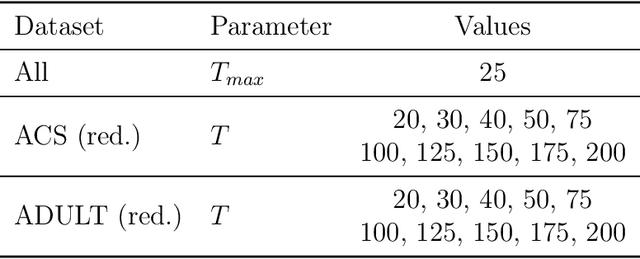
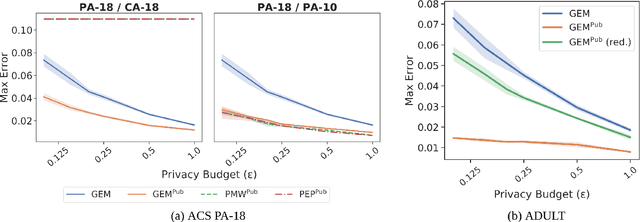
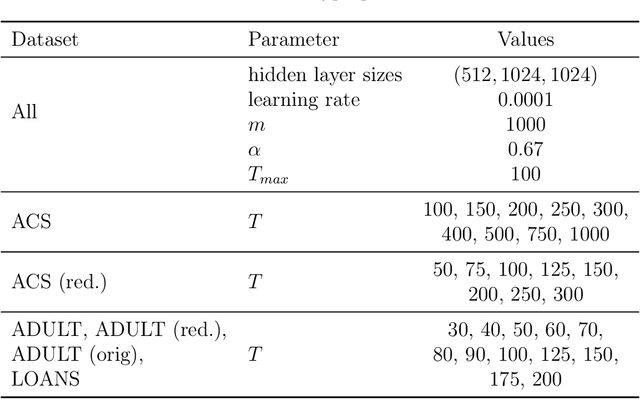
We study private synthetic data generation for query release, where the goal is to construct a sanitized version of a sensitive dataset, subject to differential privacy, that approximately preserves the answers to a large collection of statistical queries. We first present an algorithmic framework that unifies a long line of iterative algorithms in the literature. Under this framework, we propose two new methods. The first method, private entropy projection (PEP), can be viewed as an advanced variant of MWEM that adaptively reuses past query measurements to boost accuracy. Our second method, generative networks with the exponential mechanism (GEM), circumvents computational bottlenecks in algorithms such as MWEM and PEP by optimizing over generative models parameterized by neural networks, which capture a rich family of distributions while enabling fast gradient-based optimization. We demonstrate that PEP and GEM empirically outperform existing algorithms. Furthermore, we show that GEM nicely incorporates prior information from public data while overcoming limitations of PMW^Pub, the existing state-of-the-art method that also leverages public data.
Malware Knowledge Graph Generation
Feb 10, 2021
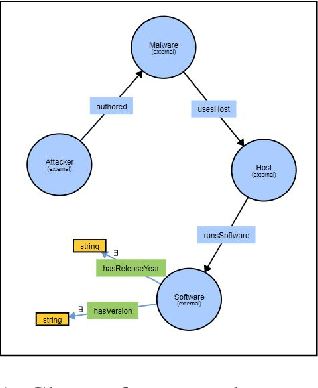
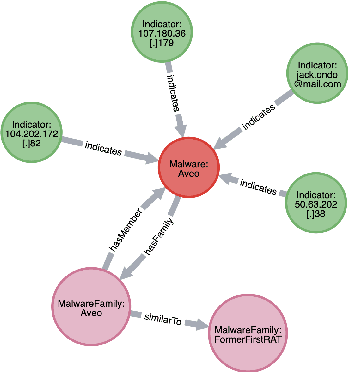
Cyber threat and attack intelligence information are available in non-standard format from heterogeneous sources. Comprehending them and utilizing them for threat intelligence extraction requires engaging security experts. Knowledge graphs enable converting this unstructured information from heterogeneous sources into a structured representation of data and factual knowledge for several downstream tasks such as predicting missing information and future threat trends. Existing large-scale knowledge graphs mainly focus on general classes of entities and relationships between them. Open-source knowledge graphs for the security domain do not exist. To fill this gap, we've built \textsf{TINKER} - a knowledge graph for threat intelligence (\textbf{T}hreat \textbf{IN}telligence \textbf{K}nowl\textbf{E}dge g\textbf{R}aph). \textsf{TINKER} is generated using RDF triples describing entities and relations from tokenized unstructured natural language text from 83 threat reports published between 2006-2021. We built \textsf{TINKER} using classes and properties defined by open-source malware ontology and using hand-annotated RDF triples. We also discuss ongoing research and challenges faced while creating \textsf{TINKER}.
Attribute Selection using Contranominal Scales
Jun 21, 2021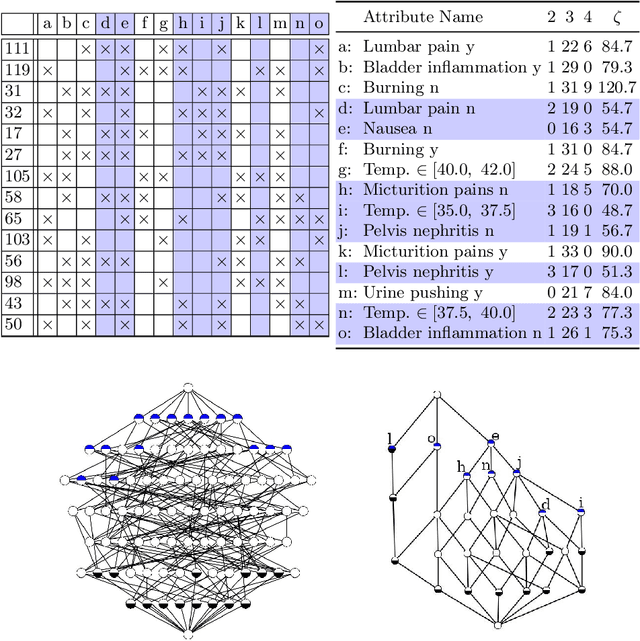
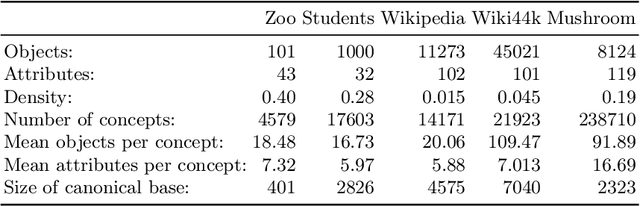
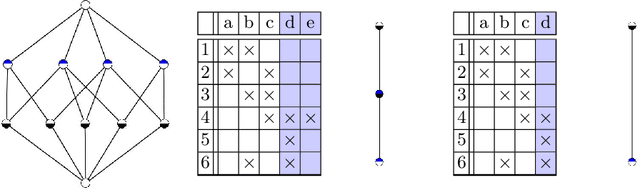
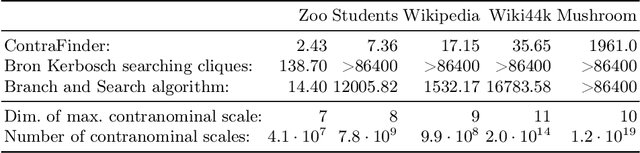
Formal Concept Analysis (FCA) allows to analyze binary data by deriving concepts and ordering them in lattices. One of the main goals of FCA is to enable humans to comprehend the information that is encapsulated in the data; however, the large size of concept lattices is a limiting factor for the feasibility of understanding the underlying structural properties. The size of such a lattice depends on the number of subcontexts in the corresponding formal context that are isomorphic to a contranominal scale of high dimension. In this work, we propose the algorithm ContraFinder that enables the computation of all contranominal scales of a given formal context. Leveraging this algorithm, we introduce delta-adjusting, a novel approach in order to decrease the number of contranominal scales in a formal context by the selection of an appropriate attribute subset. We demonstrate that delta-adjusting a context reduces the size of the hereby emerging sub-semilattice and that the implication set is restricted to meaningful implications. This is evaluated with respect to its associated knowledge by means of a classification task. Hence, our proposed technique strongly improves understandability while preserving important conceptual structures.
DYPLOC: Dynamic Planning of Content Using Mixed Language Models for Text Generation
Jun 01, 2021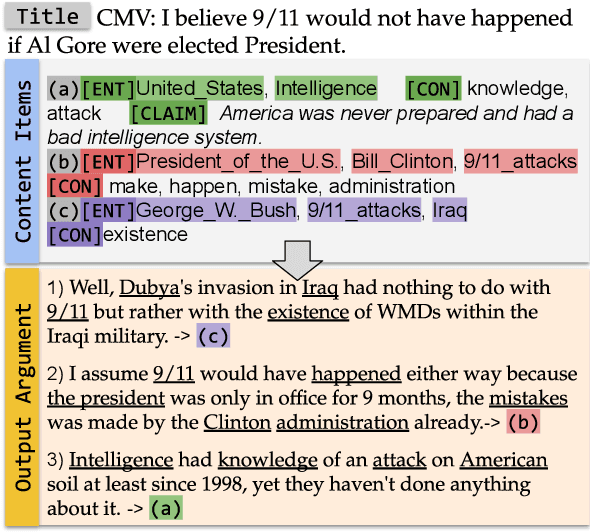
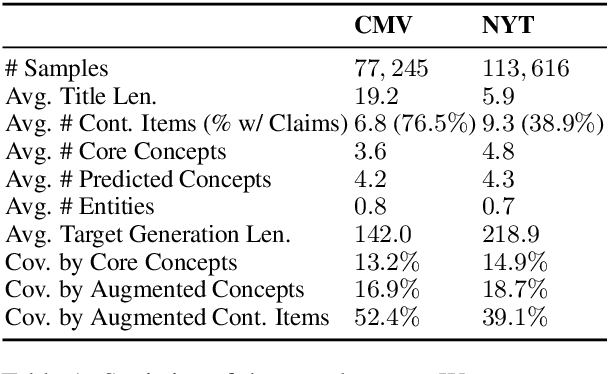
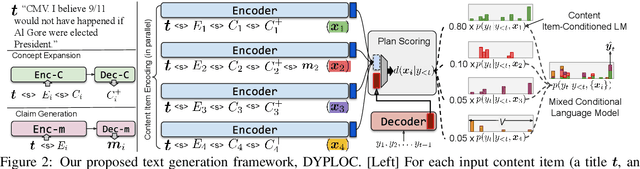
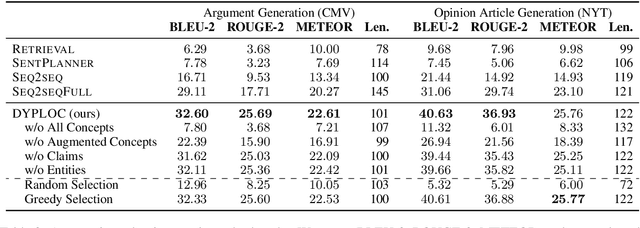
We study the task of long-form opinion text generation, which faces at least two distinct challenges. First, existing neural generation models fall short of coherence, thus requiring efficient content planning. Second, diverse types of information are needed to guide the generator to cover both subjective and objective content. To this end, we propose DYPLOC, a generation framework that conducts dynamic planning of content while generating the output based on a novel design of mixed language models. To enrich the generation with diverse content, we further propose to use large pre-trained models to predict relevant concepts and to generate claims. We experiment with two challenging tasks on newly collected datasets: (1) argument generation with Reddit ChangeMyView, and (2) writing articles using New York Times' Opinion section. Automatic evaluation shows that our model significantly outperforms competitive comparisons. Human judges further confirm that our generations are more coherent with richer content.