 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Lifting Transformer for 3D Human Pose Estimation in Video
Apr 10, 2021
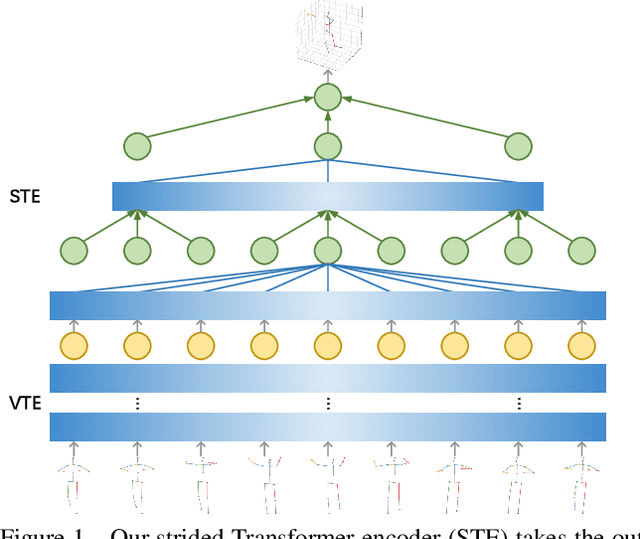
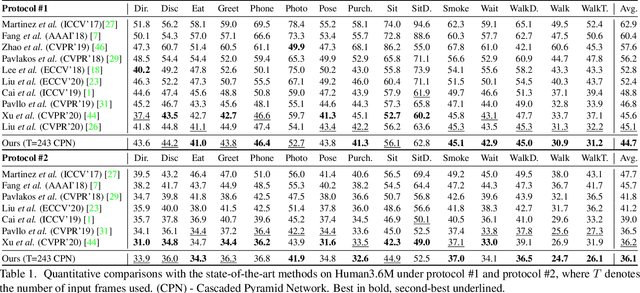
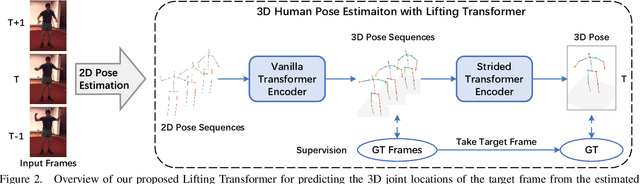
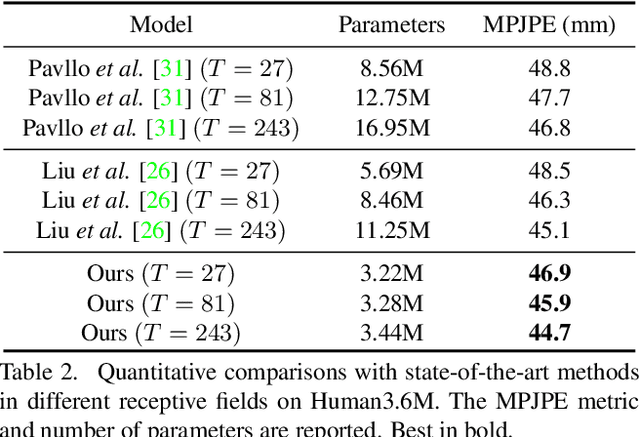
Despite great progress in video-based 3D human pose estimation, it is still challenging to learn a discriminative single-pose representation from redundant sequences. To this end, we propose a novel Transformer-based architecture, called Lifting Transformer, for 3D human pose estimation to lift a sequence of 2D joint locations to a 3D pose. Specifically, a vanilla Transformer encoder (VTE) is adopted to model long-range dependencies of 2D pose sequences. To reduce redundancy of the sequence and aggregate information from local context, fully-connected layers in the feed-forward network of VTE are replaced with strided convolutions to progressively reduce the sequence length. The modified VTE is termed as strided Transformer encoder (STE) and it is built upon the outputs of VTE. STE not only significantly reduces the computation cost but also effectively aggregates information to a single-vector representation in a global and local fashion. Moreover, a full-to-single supervision scheme is employed at both the full sequence scale and single target frame scale, applying to the outputs of VTE and STE, respectively. This scheme imposes extra temporal smoothness constraints in conjunction with the single target frame supervision. The proposed architecture is evaluated on two challenging benchmark datasets, namely, Human3.6M and HumanEva-I, and achieves state-of-the-art results with much fewer parameters.
Learning Large-scale Location Embedding From Human Mobility Trajectories with Graphs
Feb 23, 2021
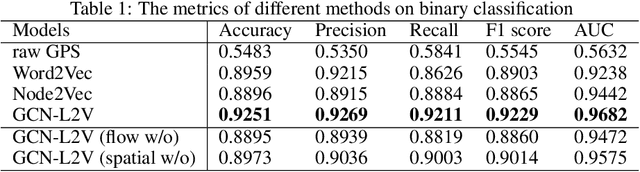
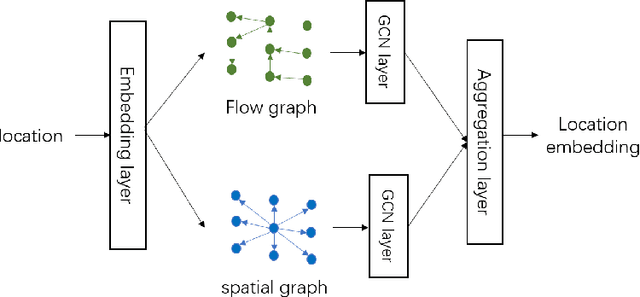
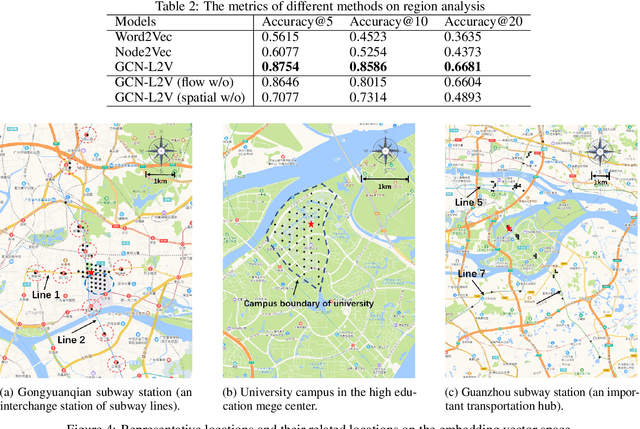
GPS coordinates and other location indicators are fine-grained location indicators that are difficult to be effectively utilized by machine learning models in Geo-aware applications. Previous location embedding methods are mostly tailored for specific problems that are taken place within areas of interest. When it comes to the scale of the entire cities, existing approaches always suffer from extensive computational cost and signigicant information loss. An increasing amount of location-based service (LBS) data are being accumulated and released to the public and enables us to study urban dynamics and human mobility. This study learns vector representations for locations using the large-scale LBS data. Different from existing studies, we propose to consider both spatial connection and human mobility, and jointly learn the representations from a flow graph and a spatial graph through a GCN-aided skip-gram model named GCN-L2V. This model embeds context information in human mobility and spatial information. By doing so, GCN-L2V is able to capture relationships among locations and provide a better notion of semantic similarity in a spatial environment. Across quantitative experiments and case studies, we empirically demonstrate that the representations learned by GCN-L2V are effective. GCN-L2V can be applied in a complementary manner to other place embedding methods and down-streaming Geo-aware applications.
A Graph-guided Multi-round Retrieval Method for Conversational Open-domain Question Answering
Apr 17, 2021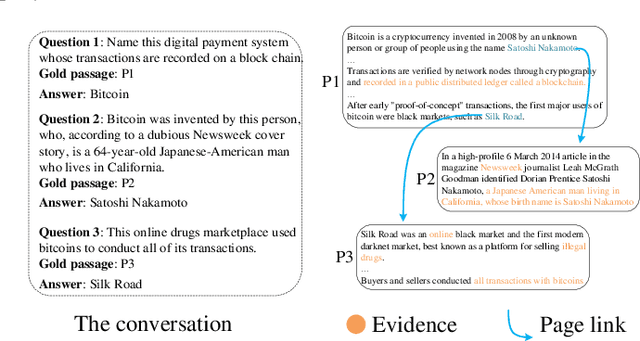
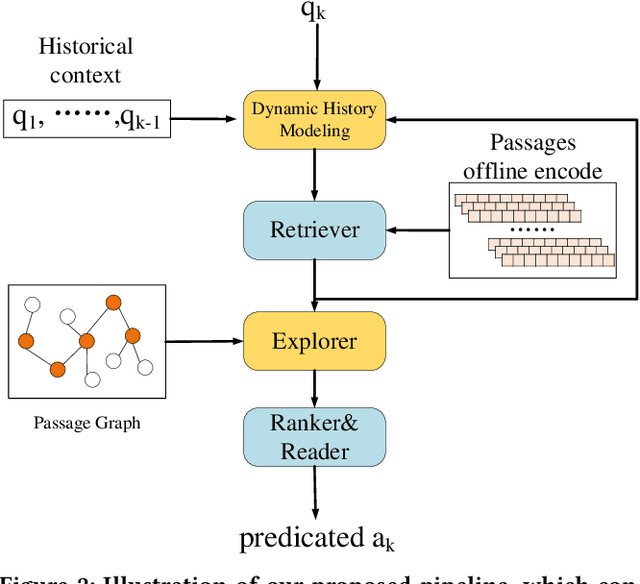
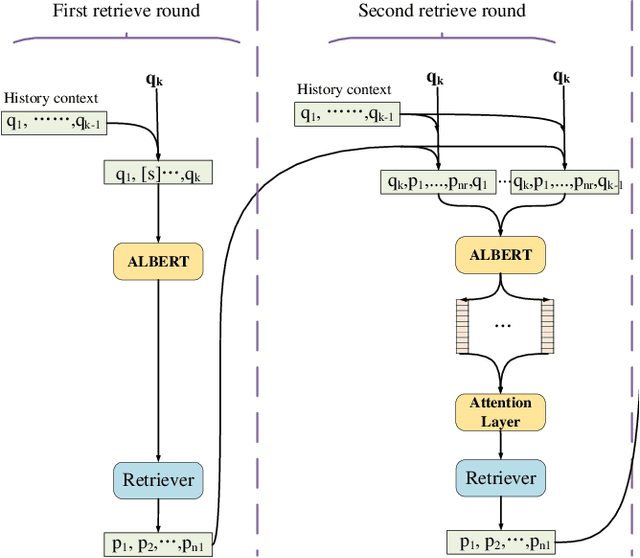
In recent years, conversational agents have provided a natural and convenient access to useful information in people's daily life, along with a broad and new research topic, conversational question answering (QA). Among the popular conversational QA tasks, conversational open-domain QA, which requires to retrieve relevant passages from the Web to extract exact answers, is more practical but less studied. The main challenge is how to well capture and fully explore the historical context in conversation to facilitate effective large-scale retrieval. The current work mainly utilizes history questions to refine the current question or to enhance its representation, yet the relations between history answers and the current answer in a conversation, which is also critical to the task, are totally neglected. To address this problem, we propose a novel graph-guided retrieval method to model the relations among answers across conversation turns. In particular, it utilizes a passage graph derived from the hyperlink-connected passages that contains history answers and potential current answers, to retrieve more relevant passages for subsequent answer extraction. Moreover, in order to collect more complementary information in the historical context, we also propose to incorporate the multi-round relevance feedback technique to explore the impact of the retrieval context on current question understanding. Experimental results on the public dataset verify the effectiveness of our proposed method. Notably, the F1 score is improved by 5% and 11% with predicted history answers and true history answers, respectively.
Smart Vectorizations for Single and Multiparameter Persistence
Apr 10, 2021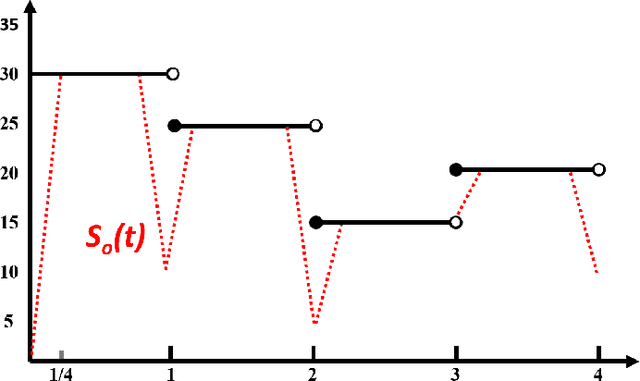
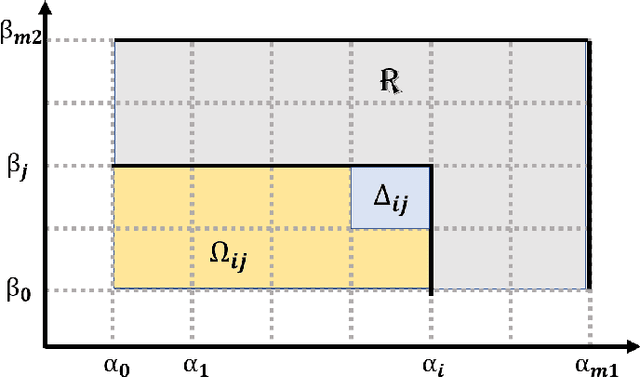
The machinery of topological data analysis becomes increasingly popular in a broad range of machine learning tasks, ranging from anomaly detection and manifold learning to graph classification. Persistent homology is one of the key approaches here, allowing us to systematically assess the evolution of various hidden patterns in the data as we vary a scale parameter. The extracted patterns, or homological features, along with information on how long such features persist throughout the considered filtration of a scale parameter, convey a critical insight into salient data characteristics and data organization. In this work, we introduce two new and easily interpretable topological summaries for single and multi-parameter persistence, namely, saw functions and multi-persistence grid functions, respectively. Compared to the existing topological summaries which tend to assess the numbers of topological features and/or their lifespans at a given filtration step, our proposed saw and multi-persistence grid functions allow us to explicitly account for essential complementary information such as the numbers of births and deaths at each filtration step. These new topological summaries can be regarded as the complexity measures of the evolving subspaces determined by the filtration and are of particular utility for applications of persistent homology on graphs. We derive theoretical guarantees on the stability of the new saw and multi-persistence grid functions and illustrate their applicability for graph classification tasks.
Graph Contrastive Clustering
Apr 03, 2021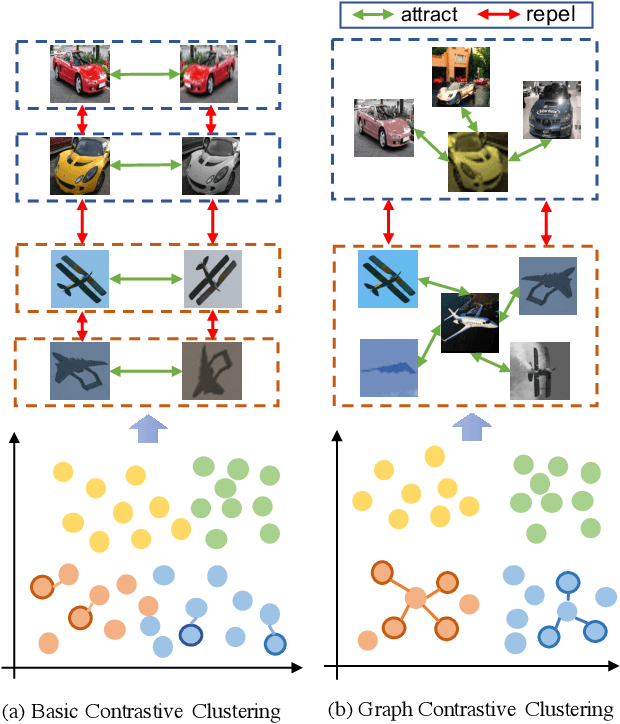
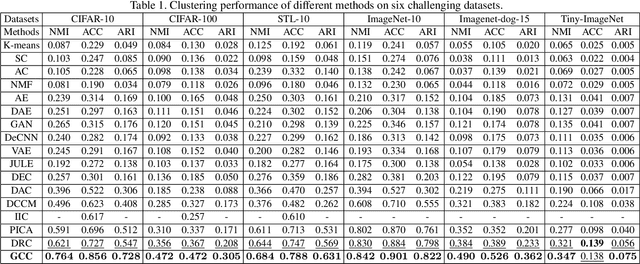
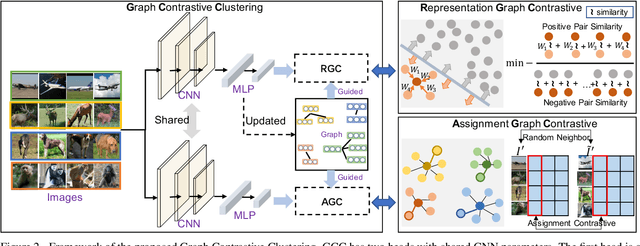
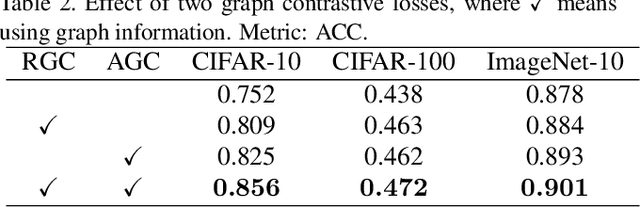
Recently, some contrastive learning methods have been proposed to simultaneously learn representations and clustering assignments, achieving significant improvements. However, these methods do not take the category information and clustering objective into consideration, thus the learned representations are not optimal for clustering and the performance might be limited. Towards this issue, we first propose a novel graph contrastive learning framework, which is then applied to the clustering task and we come up with the Graph Constrastive Clustering~(GCC) method. Different from basic contrastive clustering that only assumes an image and its augmentation should share similar representation and clustering assignments, we lift the instance-level consistency to the cluster-level consistency with the assumption that samples in one cluster and their augmentations should all be similar. Specifically, on the one hand, the graph Laplacian based contrastive loss is proposed to learn more discriminative and clustering-friendly features. On the other hand, a novel graph-based contrastive learning strategy is proposed to learn more compact clustering assignments. Both of them incorporate the latent category information to reduce the intra-cluster variance while increasing the inter-cluster variance. Experiments on six commonly used datasets demonstrate the superiority of our proposed approach over the state-of-the-art methods.
Achievable Information Rates for Nonlinear Fiber Communication via End-to-end Autoencoder Learning
Sep 17, 2018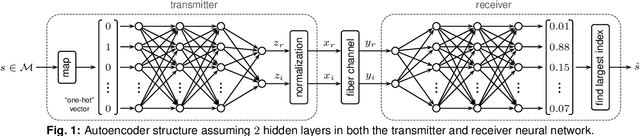
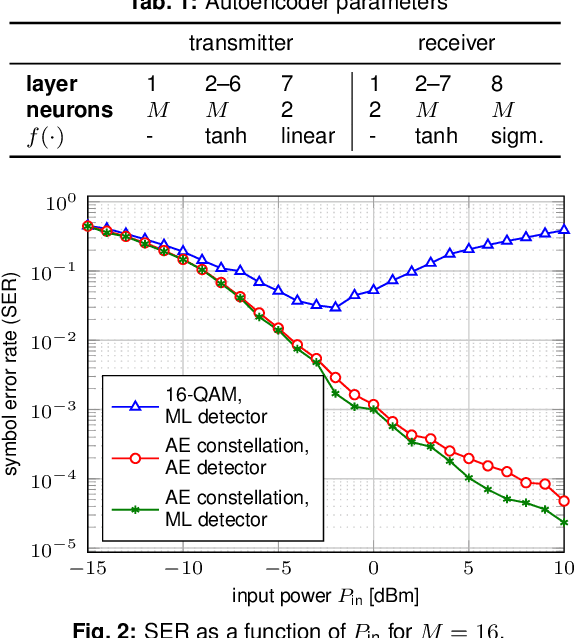

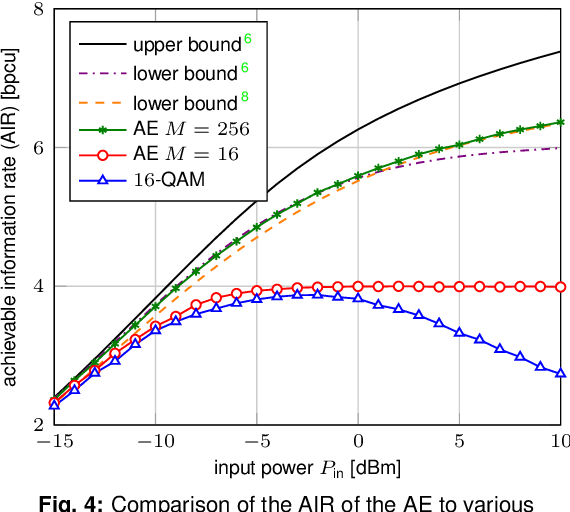
Machine learning is used to compute achievable information rates (AIRs) for a simplified fiber channel. The approach jointly optimizes the input distribution (constellation shaping) and the auxiliary channel distribution to compute AIRs without explicit channel knowledge in an end-to-end fashion.
Joint Geometric and Topological Analysis of Hierarchical Datasets
Apr 03, 2021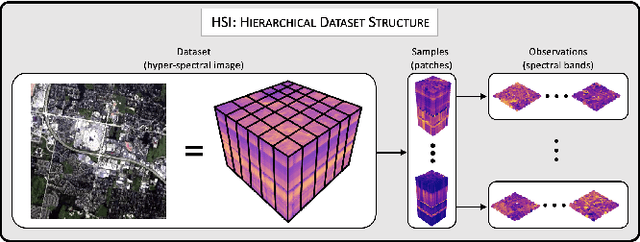

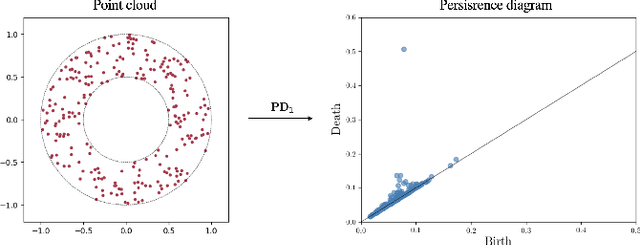
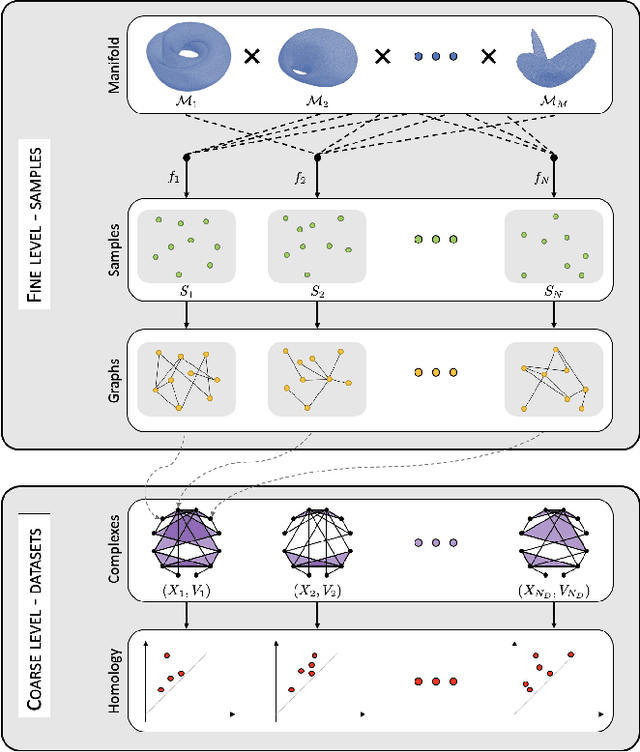
In a world abundant with diverse data arising from complex acquisition techniques, there is a growing need for new data analysis methods. In this paper we focus on high-dimensional data that are organized into several hierarchical datasets. We assume that each dataset consists of complex samples, and every sample has a distinct irregular structure modeled by a graph. The main novelty in this work lies in the combination of two complementing powerful data-analytic approaches: topological data analysis (TDA) and geometric manifold learning. Geometry primarily contains local information, while topology inherently provides global descriptors. Based on this combination, we present a method for building an informative representation of hierarchical datasets. At the finer (sample) level, we devise a new metric between samples based on manifold learning that facilitates quantitative structural analysis. At the coarser (dataset) level, we employ TDA to extract qualitative structural information from the datasets. We showcase the applicability and advantages of our method on simulated data and on a corpus of hyper-spectral images. We show that an ensemble of hyper-spectral images exhibits a hierarchical structure that fits well the considered setting. In addition, we show that our new method gives rise to superior classification results compared to state-of-the-art methods.
Autonomous Deep Quality Monitoring in Streaming Environments
Jun 26, 2021



The common practice of quality monitoring in industry relies on manual inspection well-known to be slow, error-prone and operator-dependent. This issue raises strong demand for automated real-time quality monitoring developed from data-driven approaches thus alleviating from operator dependence and adapting to various process uncertainties. Nonetheless, current approaches do not take into account the streaming nature of sensory information while relying heavily on hand-crafted features making them application-specific. This paper proposes the online quality monitoring methodology developed from recently developed deep learning algorithms for data streams, Neural Networks with Dynamically Evolved Capacity (NADINE), namely NADINE++. It features the integration of 1-D and 2-D convolutional layers to extract natural features of time-series and visual data streams captured from sensors and cameras of the injection molding machines from our own project. Real-time experiments have been conducted where the online quality monitoring task is simulated on the fly under the prequential test-then-train fashion - the prominent data stream evaluation protocol. Comparison with the state-of-the-art techniques clearly exhibits the advantage of NADINE++ with 4.68\% improvement on average for the quality monitoring task in streaming environments. To support the reproducible research initiative, codes, results of NADINE++ along with supplementary materials and injection molding dataset are made available in \url{https://github.com/ContinualAL/NADINE-IJCNN2021}.
* This paper has been accepted for publication in IJCNN, 2021
Intelligent Reconfigurable Surface-assisted Multi-UAV Networks: Efficient Resource Allocation with Deep Reinforcement Learning
May 28, 2021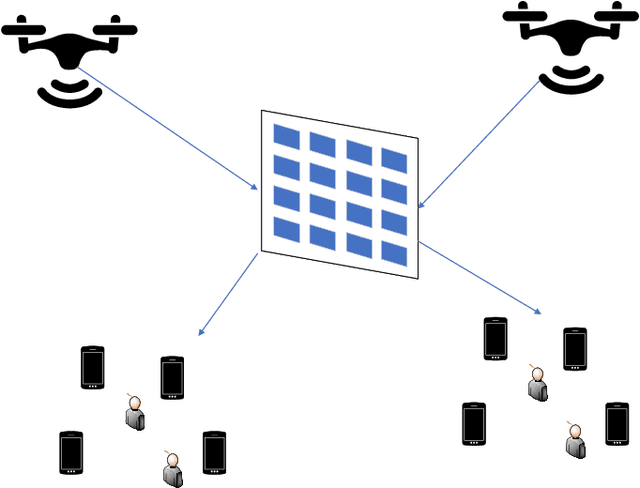
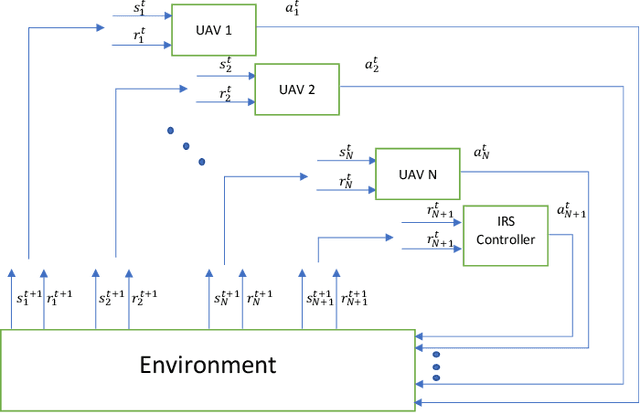
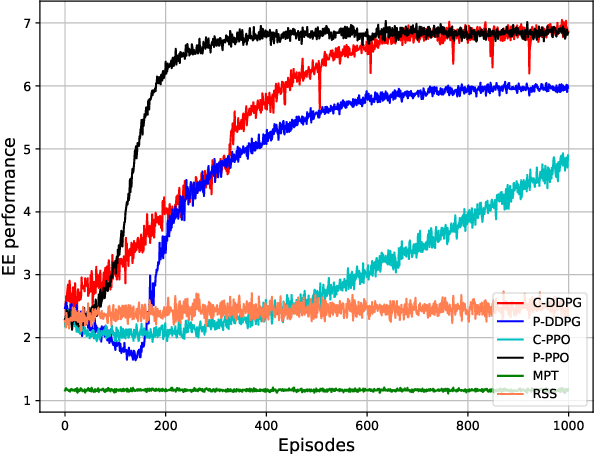
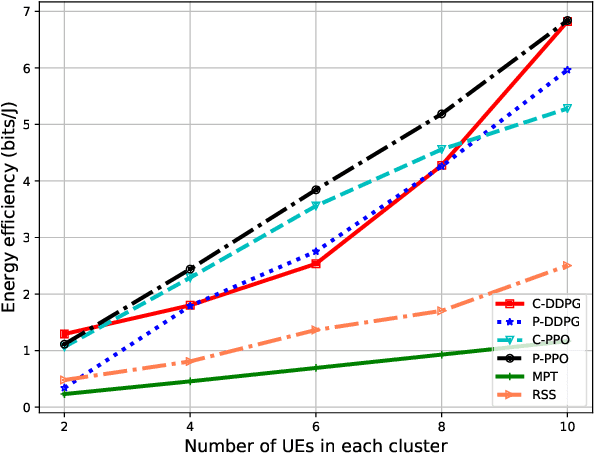
In this paper, we propose intelligent reconfigurable surface (IRS)-assisted unmanned aerial vehicles (UAVs) networks that can utilise both advantages of agility and reflection for enhancing the network's performance. To aim at maximising the energy efficiency (EE) of the considered networks, we jointly optimise the power allocation of the UAVs and the phaseshift matrix of the IRS. A deep reinforcement learning (DRL) approach is proposed for solving the continuous optimisation problem with time-varying channel gain in a centralised fashion. Moreover, a parallel learning approach is also proposed for reducing the information transmission requirement of the centralised approach. Numerical results show a significant improvement of our proposed schemes compared with the conventional approaches in terms of EE, flexibility, and processing time. Our proposed DRL methods for IRS-assisted UAV networks can be used for real-time applications due to their capability of instant decision-making and handling the time-varying channel with the dynamic environmental setting.
ReadTwice: Reading Very Large Documents with Memories
May 10, 2021
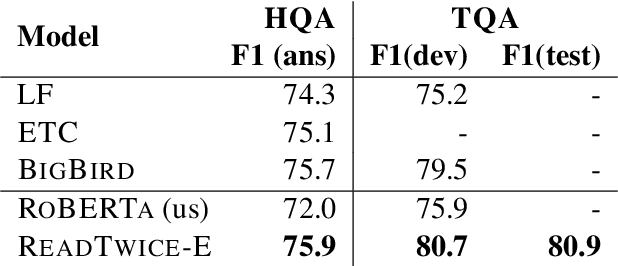
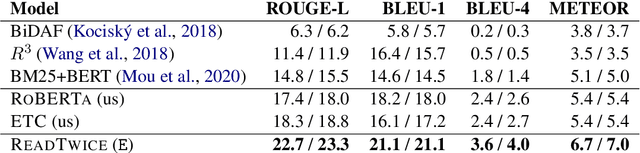
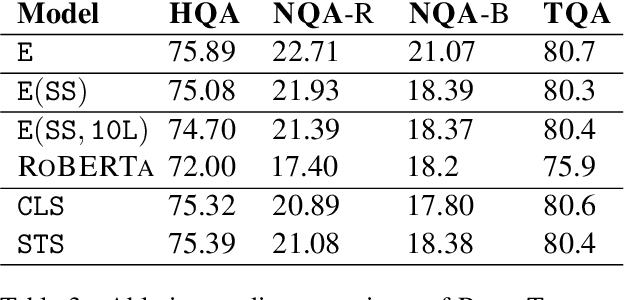
Knowledge-intensive tasks such as question answering often require assimilating information from different sections of large inputs such as books or article collections. We propose ReadTwuce, a simple and effective technique that combines several strengths of prior approaches to model long-range dependencies with Transformers. The main idea is to read text in small segments, in parallel, summarizing each segment into a memory table to be used in a second read of the text. We show that the method outperforms models of comparable size on several question answering (QA) datasets and sets a new state of the art on the challenging NarrativeQA task, with questions about entire books. Source code and pre-trained checkpoints for ReadTwice can be found at https://goo.gle/research-readtwice.