 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Why Should I Trust a Model is Private? Using Shifts in Model Explanation for Evaluating Privacy-Preserving Emotion Recognition Model
Apr 18, 2021
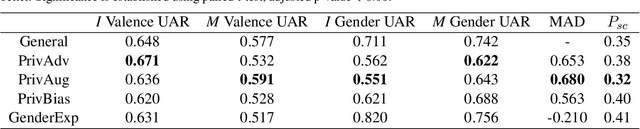
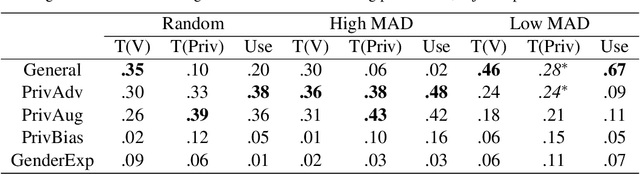
Privacy preservation is a crucial component of any real-world application. Yet, in applications relying on machine learning backends, this is challenging because models often capture more than a designer may have envisioned, resulting in the potential leakage of sensitive information. For example, emotion recognition models are susceptible to learning patterns between the target variable and other sensitive variables, patterns that can be maliciously re-purposed to obtain protected information. In this paper, we concentrate on using interpretable methods to evaluate a model's efficacy to preserve privacy with respect to sensitive variables. We focus on saliency-based explanations, explanations that highlight regions of the input text, which allows us to understand how model explanations shift when models are trained to preserve privacy. We show how certain commonly-used methods that seek to preserve privacy might not align with human perception of privacy preservation. We also show how some of these induce spurious correlations in the model between the input and the primary as well as secondary task, even if the improvement in evaluation metric is significant. Such correlations can hence lead to false assurances about the perceived privacy of the model because especially when used in cross corpus conditions. We conduct crowdsourcing experiments to evaluate the inclination of the evaluators to choose a particular model for a given task when model explanations are provided, and find that correlation of interpretation differences with sociolinguistic biases can be used as a proxy for user trust.
Context-Aware Image Inpainting with Learned Semantic Priors
Jun 14, 2021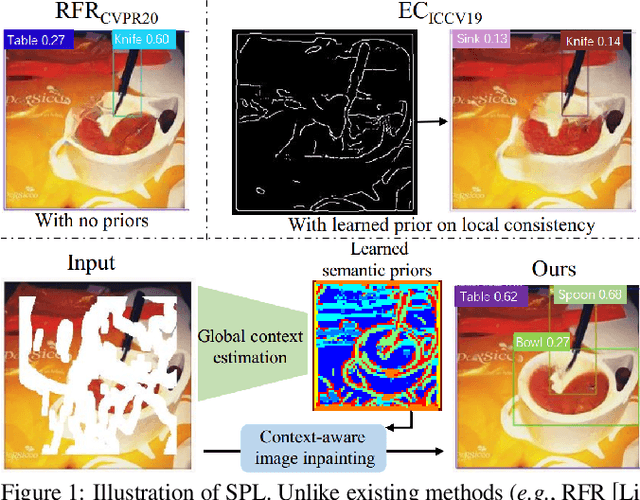
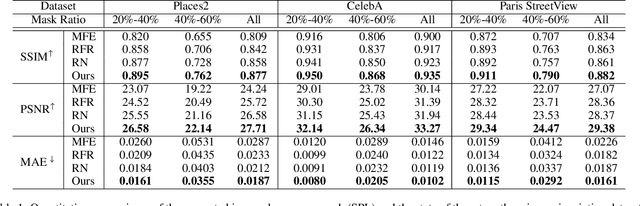
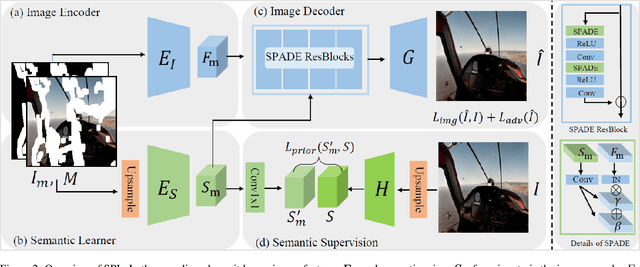

Recent advances in image inpainting have shown impressive results for generating plausible visual details on rather simple backgrounds. However, for complex scenes, it is still challenging to restore reasonable contents as the contextual information within the missing regions tends to be ambiguous. To tackle this problem, we introduce pretext tasks that are semantically meaningful to estimating the missing contents. In particular, we perform knowledge distillation on pretext models and adapt the features to image inpainting. The learned semantic priors ought to be partially invariant between the high-level pretext task and low-level image inpainting, which not only help to understand the global context but also provide structural guidance for the restoration of local textures. Based on the semantic priors, we further propose a context-aware image inpainting model, which adaptively integrates global semantics and local features in a unified image generator. The semantic learner and the image generator are trained in an end-to-end manner. We name the model SPL to highlight its ability to learn and leverage semantic priors. It achieves the state of the art on Places2, CelebA, and Paris StreetView datasets.
Meta-Mining Discriminative Samples for Kinship Verification
Mar 28, 2021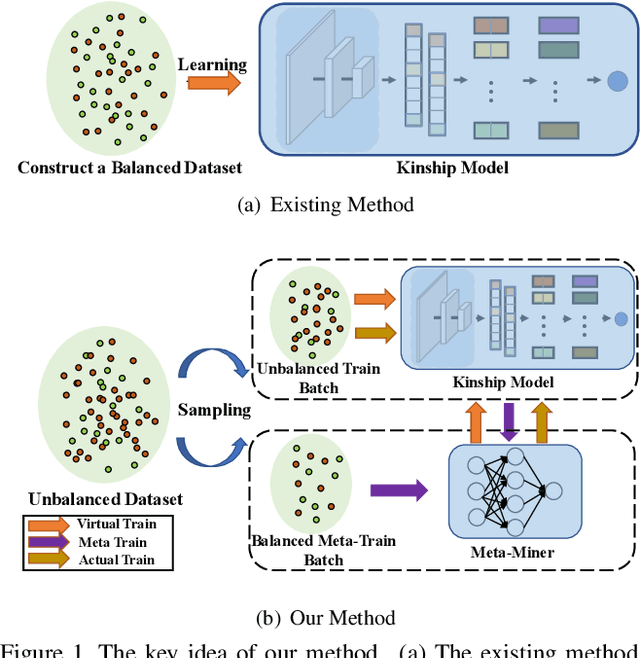
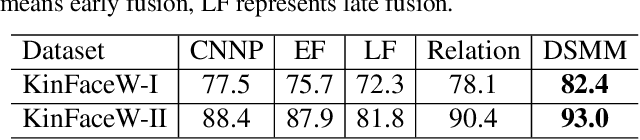
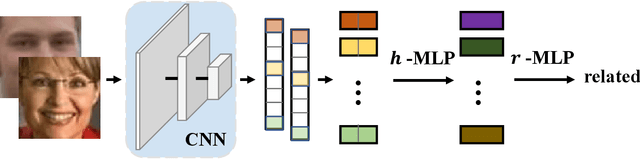
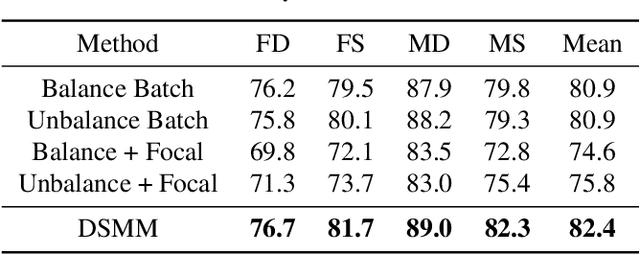
Kinship verification aims to find out whether there is a kin relation for a given pair of facial images. Kinship verification databases are born with unbalanced data. For a database with N positive kinship pairs, we naturally obtain N(N-1) negative pairs. How to fully utilize the limited positive pairs and mine discriminative information from sufficient negative samples for kinship verification remains an open issue. To address this problem, we propose a Discriminative Sample Meta-Mining (DSMM) approach in this paper. Unlike existing methods that usually construct a balanced dataset with fixed negative pairs, we propose to utilize all possible pairs and automatically learn discriminative information from data. Specifically, we sample an unbalanced train batch and a balanced meta-train batch for each iteration. Then we learn a meta-miner with the meta-gradient on the balanced meta-train batch. In the end, the samples in the unbalanced train batch are re-weighted by the learned meta-miner to optimize the kinship models. Experimental results on the widely used KinFaceW-I, KinFaceW-II, TSKinFace, and Cornell Kinship datasets demonstrate the effectiveness of the proposed approach.
On the Evaluation of Commit Message Generation Models: An Experimental Study
Jul 13, 2021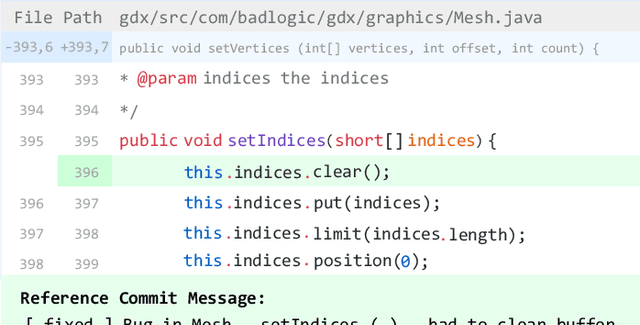
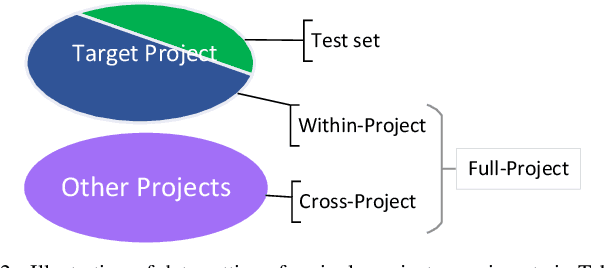
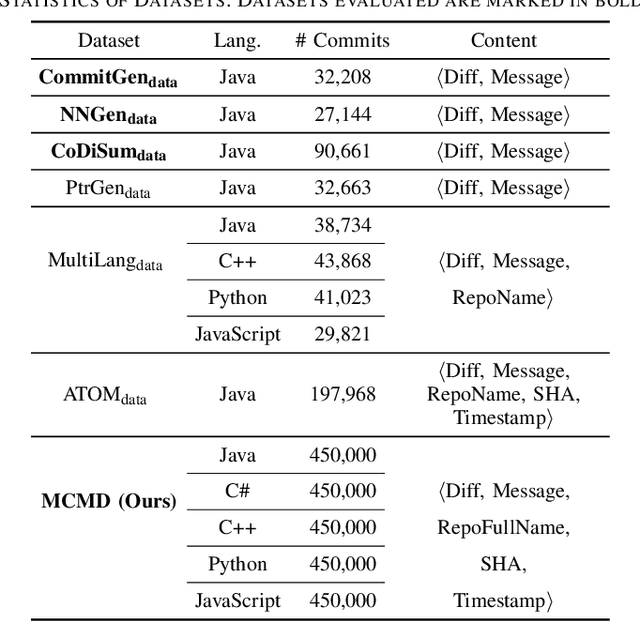
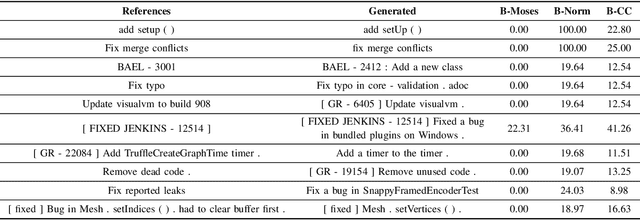
Commit messages are natural language descriptions of code changes, which are important for program understanding and maintenance. However, writing commit messages manually is time-consuming and laborious, especially when the code is updated frequently. Various approaches utilizing generation or retrieval techniques have been proposed to automatically generate commit messages. To achieve a better understanding of how the existing approaches perform in solving this problem, this paper conducts a systematic and in-depth analysis of the state-of-the-art models and datasets. We find that: (1) Different variants of the BLEU metric are used in previous works, which affects the evaluation and understanding of existing methods. (2) Most existing datasets are crawled only from Java repositories while repositories in other programming languages are not sufficiently explored. (3) Dataset splitting strategies can influence the performance of existing models by a large margin. Some models show better performance when the datasets are split by commit, while other models perform better when the datasets are split by timestamp or by project. Based on our findings, we conduct a human evaluation and find the BLEU metric that best correlates with the human scores for the task. We also collect a large-scale, information-rich, and multi-language commit message dataset MCMD and evaluate existing models on this dataset. Furthermore, we conduct extensive experiments under different dataset splitting strategies and suggest the suitable models under different scenarios. Based on the experimental results and findings, we provide feasible suggestions for comprehensively evaluating commit message generation models and discuss possible future research directions. We believe this work can help practitioners and researchers better evaluate and select models for automatic commit message generation.
Intrusion Detection System in Smart Home Network Using Bidirectional LSTM and Convolutional Neural Networks Hybrid Model
May 25, 2021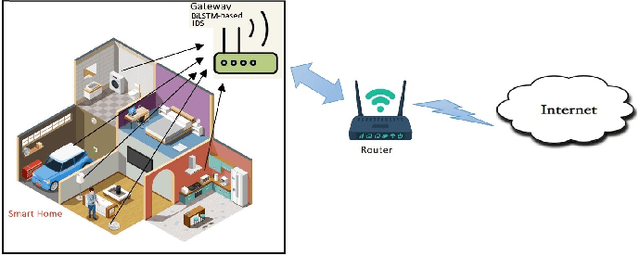
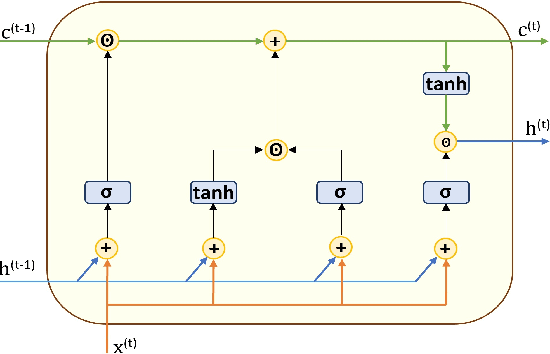
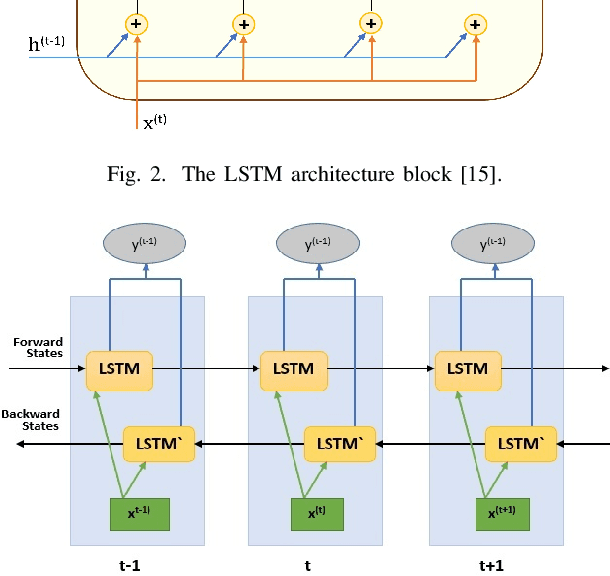
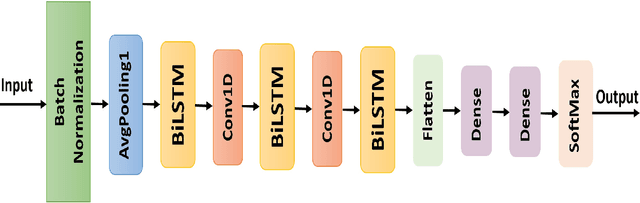
Internet of Things (IoT) allowed smart homes to improve the quality and the comfort of our daily lives. However, these conveniences introduced several security concerns that increase rapidly. IoT devices, smart home hubs, and gateway raise various security risks. The smart home gateways act as a centralized point of communication between the IoT devices, which can create a backdoor into network data for hackers. One of the common and effective ways to detect such attacks is intrusion detection in the network traffic. In this paper, we proposed an intrusion detection system (IDS) to detect anomalies in a smart home network using a bidirectional long short-term memory (BiLSTM) and convolutional neural network (CNN) hybrid model. The BiLSTM recurrent behavior provides the intrusion detection model to preserve the learned information through time, and the CNN extracts perfectly the data features. The proposed model can be applied to any smart home network gateway.
On the Statistical and Information-theoretic Characteristics of Deep Network Representations
Nov 08, 2018
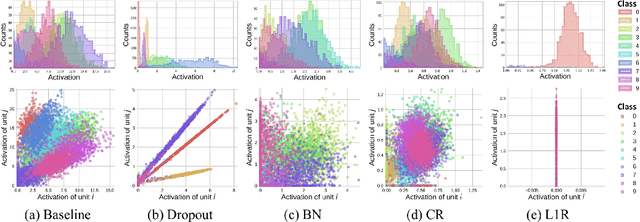
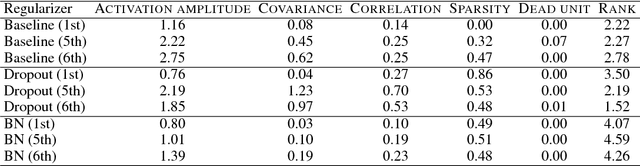
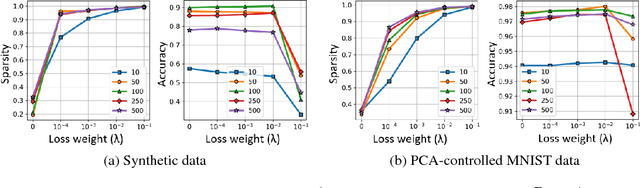
It has been common to argue or imply that a regularizer can be used to alter a statistical property of a hidden layer's representation and thus improve generalization or performance of deep networks. For instance, dropout has been known to improve performance by reducing co-adaptation, and representational sparsity has been argued as a good characteristic because many data-generation processes have a small number of factors that are independent. In this work, we analytically and empirically investigate the popular characteristics of learned representations, including correlation, sparsity, dead unit, rank, and mutual information, and disprove many of the \textit{conventional wisdom}. We first show that infinitely many Identical Output Networks (IONs) can be constructed for any deep network with a linear layer, where any invertible affine transformation can be applied to alter the layer's representation characteristics. The existence of ION proves that the correlation characteristics of representation is irrelevant to the performance. Extensions to ReLU layers are provided, too. Then, we consider sparsity, dead unit, and rank to show that only loose relationships exist among the three characteristics. It is shown that a higher sparsity or additional dead units do not imply a better or worse performance when the rank of representation is fixed. We also develop a rank regularizer and show that neither representation sparsity nor lower rank is helpful for improving performance even when the data-generation process has a small number of independent factors. Mutual information $I(\mathbf{z}_l;\mathbf{x})$ and $I(\mathbf{z}_l;\mathbf{y})$ are investigated, and we show that regularizers can affect $I(\mathbf{z}_l;\mathbf{x})$ and thus indirectly influence the performance. Finally, we explain how a rich set of regularizers can be used as a powerful tool for performance tuning.
Disambiguatory Signals are Stronger in Word-initial Positions
Feb 03, 2021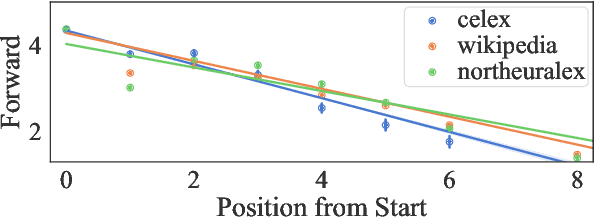
Psycholinguistic studies of human word processing and lexical access provide ample evidence of the preferred nature of word-initial versus word-final segments, e.g., in terms of attention paid by listeners (greater) or the likelihood of reduction by speakers (lower). This has led to the conjecture -- as in Wedel et al. (2019b), but common elsewhere -- that languages have evolved to provide more information earlier in words than later. Information-theoretic methods to establish such tendencies in lexicons have suffered from several methodological shortcomings that leave open the question of whether this high word-initial informativeness is actually a property of the lexicon or simply an artefact of the incremental nature of recognition. In this paper, we point out the confounds in existing methods for comparing the informativeness of segments early in the word versus later in the word, and present several new measures that avoid these confounds. When controlling for these confounds, we still find evidence across hundreds of languages that indeed there is a cross-linguistic tendency to front-load information in words.
Cloth-Changing Person Re-identification from A Single Image with Gait Prediction and Regularization
Apr 18, 2021
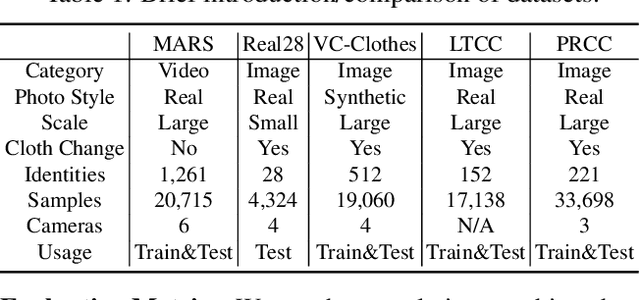
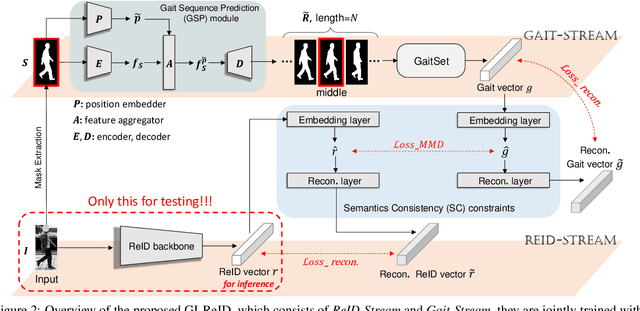
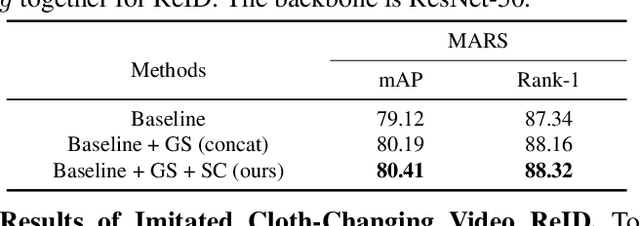
Cloth-Changing person re-identification (CC-ReID) aims at matching the same person across different locations over a long-duration, e.g., over days, and therefore inevitably meets challenge of changing clothing. In this paper, we focus on handling well the CC-ReID problem under a more challenging setting, i.e., just from a single image, which enables high-efficiency and latency-free pedestrian identify for real-time surveillance applications. Specifically, we introduce Gait recognition as an auxiliary task to drive the Image ReID model to learn cloth-agnostic representations by leveraging personal unique and cloth-independent gait information, we name this framework as GI-ReID. GI-ReID adopts a two-stream architecture that consists of a image ReID-Stream and an auxiliary gait recognition stream (Gait-Stream). The Gait-Stream, that is discarded in the inference for high computational efficiency, acts as a regulator to encourage the ReID-Stream to capture cloth-invariant biometric motion features during the training. To get temporal continuous motion cues from a single image, we design a Gait Sequence Prediction (GSP) module for Gait-Stream to enrich gait information. Finally, a high-level semantics consistency over two streams is enforced for effective knowledge regularization. Experiments on multiple image-based Cloth-Changing ReID benchmarks, e.g., LTCC, PRCC, Real28, and VC-Clothes, demonstrate that GI-ReID performs favorably against the state-of-the-arts. Codes are available at https://github.com/jinx-USTC/GI-ReID.
Looking Twice for Partial Clues: Weakly-supervised Part-Mentored Attention Network for Vehicle Re-Identification
Jul 17, 2021

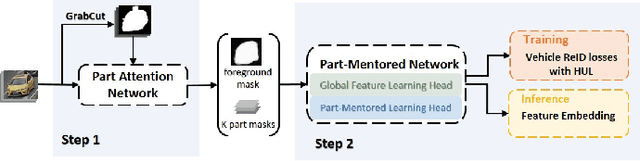
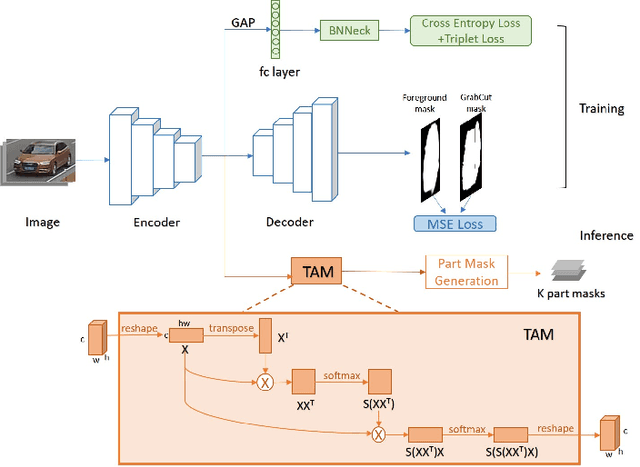
Vehicle re-identification (Re-ID) is to retrieve images of the same vehicle across different cameras. Two key challenges lie in the subtle inter-instance discrepancy caused by near-duplicate identities and the large intra-instance variance caused by different views. Since the holistic appearance suffers from viewpoint variation and distortion, part-level feature learning has been introduced to enhance vehicle description. However, existing approaches to localize and amplify significant parts often fail to handle spatial misalignment as well as occlusion and require expensive annotations. In this paper, we propose a weakly supervised Part-Mentored Attention Network (PMANet) composed of a Part Attention Network (PANet) for vehicle part localization with self-attention and a Part-Mentored Network (PMNet) for mentoring the global and local feature aggregation. Firstly, PANet is introduced to predict a foreground mask and pinpoint $K$ prominent vehicle parts only with weak identity supervision. Secondly, we propose a PMNet to learn global and part-level features with multi-scale attention and aggregate them in $K$ main-partial tasks via part transfer. Like humans who first differentiate objects with general information and then observe salient parts for more detailed clues, PANet and PMNet construct a two-stage attention structure to perform a coarse-to-fine search among identities. Finally, we address this Re-ID issue as a multi-task problem, including global feature learning, identity classification, and part transfer. We adopt Homoscedastic Uncertainty to learn the optimal weighing of different losses. Comprehensive experiments are conducted on two benchmark datasets. Our approach outperforms recent state-of-the-art methods by averagely 2.63% in CMC@1 on VehicleID and 2.2% in mAP on VeRi776. Results on occluded test sets also demonstrate the generalization ability of PMANet.
Self-Supervised Metric Learning in Multi-View Data: A Downstream Task Perspective
Jun 14, 2021
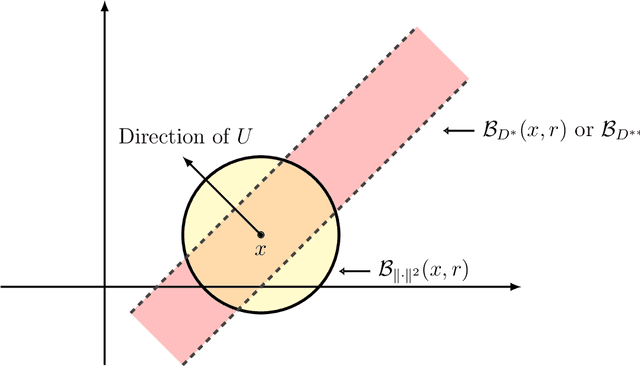

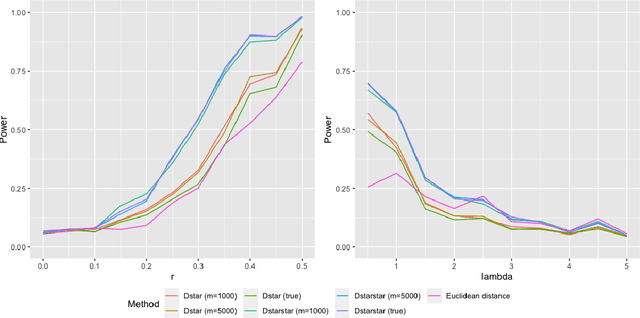
Self-supervised metric learning has been a successful approach for learning a distance from an unlabeled dataset. The resulting distance is broadly useful for improving various distance-based downstream tasks, even when no information from downstream tasks is utilized in the metric learning stage. To gain insights into this approach, we develop a statistical framework to theoretically study how self-supervised metric learning can benefit downstream tasks in the context of multi-view data. Under this framework, we show that the target distance of metric learning satisfies several desired properties for the downstream tasks. On the other hand, our investigation suggests the target distance can be further improved by moderating each direction's weights. In addition, our analysis precisely characterizes the improvement by self-supervised metric learning on four commonly used downstream tasks: sample identification, two-sample testing, $k$-means clustering, and $k$-nearest neighbor classification. As a by-product, we propose a simple spectral method for self-supervised metric learning, which is computationally efficient and minimax optimal for estimating target distance. Finally, numerical experiments are presented to support the theoretical results in the paper.