 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GraphMixup: Improving Class-Imbalanced Node Classification on Graphs by Self-supervised Context Prediction
Jun 21, 2021
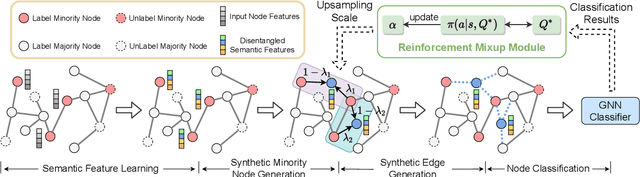

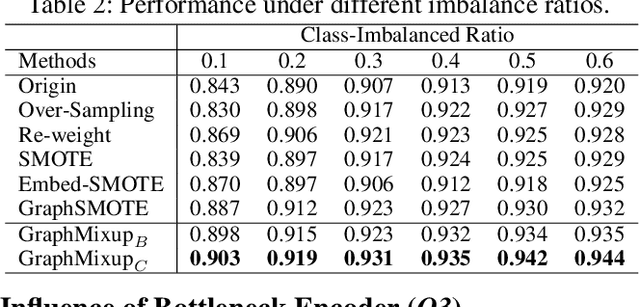
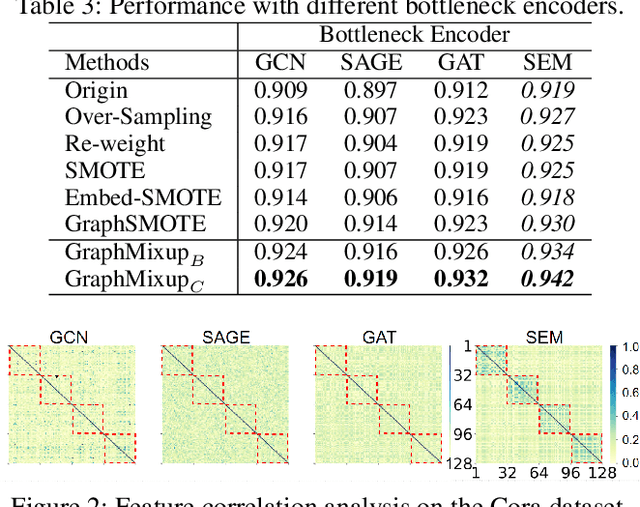
Recent years have witnessed great success in handling node classification tasks with Graph Neural Networks (GNNs). However, most existing GNNs are based on the assumption that node samples for different classes are balanced, while for many real-world graphs, there exists the problem of class imbalance, i.e., some classes may have much fewer samples than others. In this case, directly training a GNN classifier with raw data would under-represent samples from those minority classes and result in sub-optimal performance. This paper presents GraphMixup, a novel mixup-based framework for improving class-imbalanced node classification on graphs. However, directly performing mixup in the input space or embedding space may produce out-of-domain samples due to the extreme sparsity of minority classes; hence we construct semantic relation spaces that allows the Feature Mixup to be performed at the semantic level. Moreover, we apply two context-based self-supervised techniques to capture both local and global information in the graph structure and then propose Edge Mixup specifically for graph data. Finally, we develop a \emph{Reinforcement Mixup} mechanism to adaptively determine how many samples are to be generated by mixup for those minority classes. Extensive experiments on three real-world datasets show that GraphMixup yields truly encouraging results for class-imbalanced node classification tasks.
Probabilistic feature extraction, dose statistic prediction and dose mimicking for automated radiation therapy treatment planning
Feb 24, 2021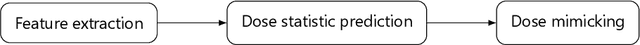
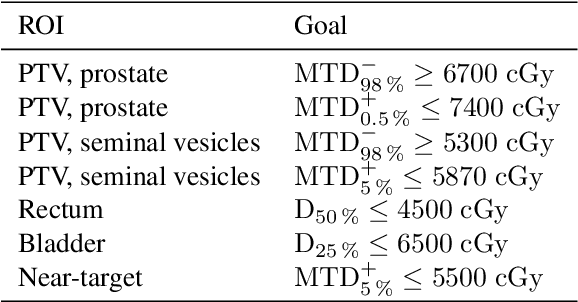
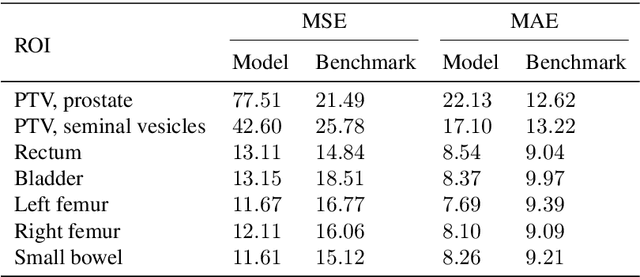
Purpose: We propose a general framework for quantifying predictive uncertainties of dose-related quantities and leveraging this information in a dose mimicking problem in the context of automated radiation therapy treatment planning. Methods: A three-step pipeline, comprising feature extraction, dose statistic prediction and dose mimicking, is employed. In particular, the features are produced by a convolutional variational autoencoder and used as inputs in a previously developed nonparametric Bayesian statistical method, estimating the multivariate predictive distribution of a collection of predefined dose statistics. Specially developed objective functions are then used to construct a dose mimicking problem based on the produced distributions, creating deliverable treatment plans. Results: The numerical experiments are performed using a dataset of 94 retrospective treatment plans of prostate cancer patients. We show that the features extracted by the variational autoencoder captures geometric information of substantial relevance to the dose statistic prediction problem, that the estimated predictive distributions are reasonable and outperforms a benchmark method, and that the deliverable plans agree well with their clinical counterparts. Conclusions: We demonstrate that prediction of dose-related quantities may be extended to include uncertainty estimation and that such probabilistic information may be leveraged in a dose mimicking problem. The treatment plans produced by the proposed pipeline resemble their original counterparts well, illustrating the merits of a holistic approach to automated planning based on probabilistic modeling.
EnHMM: On the Use of Ensemble HMMs and Stack Traces to Predict the Reassignment of Bug Report Fields
Mar 15, 2021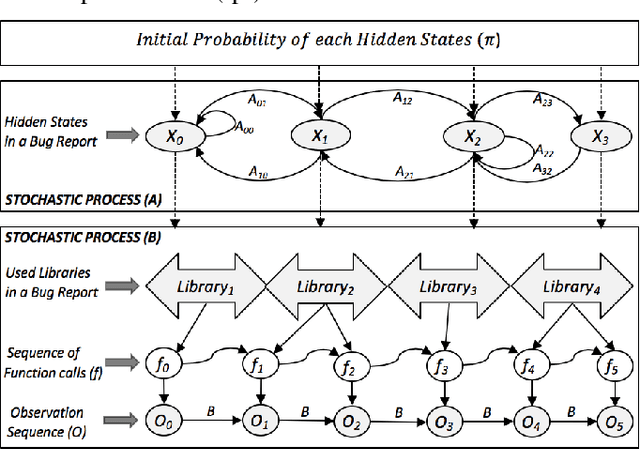
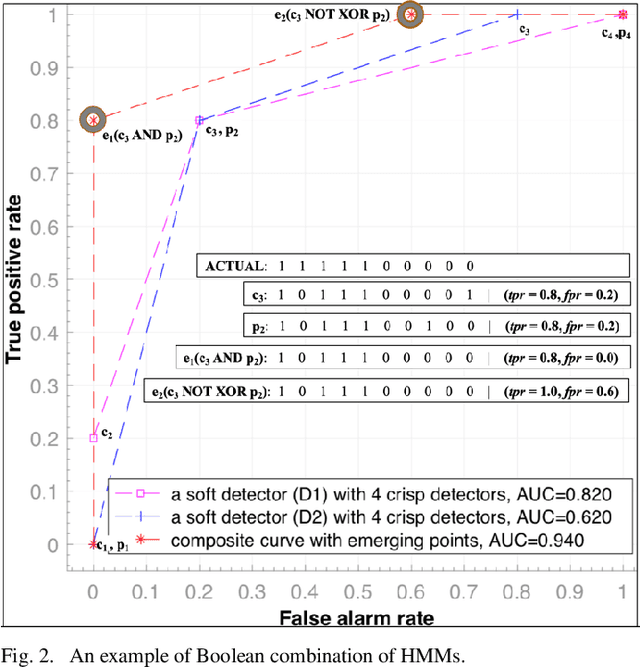
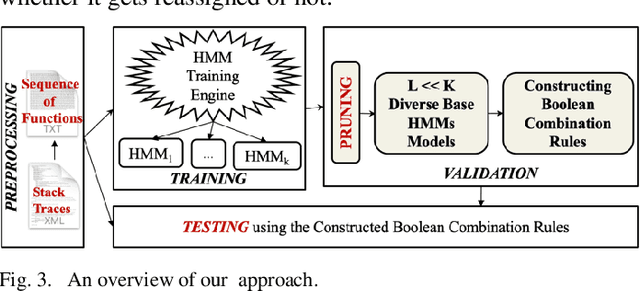
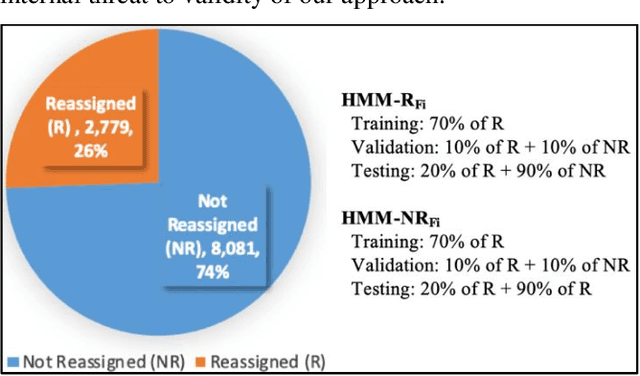
Bug reports (BR) contain vital information that can help triaging teams prioritize and assign bugs to developers who will provide the fixes. However, studies have shown that BR fields often contain incorrect information that need to be reassigned, which delays the bug fixing process. There exist approaches for predicting whether a BR field should be reassigned or not. These studies use mainly BR descriptions and traditional machine learning algorithms (SVM, KNN, etc.). As such, they do not fully benefit from the sequential order of information in BR data, such as function call sequences in BR stack traces, which may be valuable for improving the prediction accuracy. In this paper, we propose a novel approach, called EnHMM, for predicting the reassignment of BR fields using ensemble Hidden Markov Models (HMMs), trained on stack traces. EnHMM leverages the natural ability of HMMs to represent sequential data to model the temporal order of function calls in BR stack traces. When applied to Eclipse and Gnome BR repositories, EnHMM achieves an average precision, recall, and F-measure of 54%, 76%, and 60% on Eclipse dataset and 41%, 69%, and 51% on Gnome dataset. We also found that EnHMM improves over the best single HMM by 36% for Eclipse and 76% for Gnome. Finally, when comparing EnHMM to Im.ML.KNN, a recent approach in the field, we found that the average F-measure score of EnHMM improves the average F-measure of Im.ML.KNN by 6.80% and improves the average recall of Im.ML.KNN by 36.09%. However, the average precision of EnHMM is lower than that of Im.ML.KNN (53.93% as opposed to 56.71%).
FINet: Dual Branches Feature Interaction for Partial-to-Partial Point Cloud Registration
Jun 07, 2021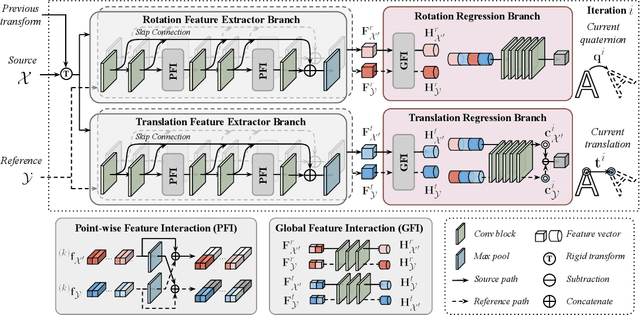
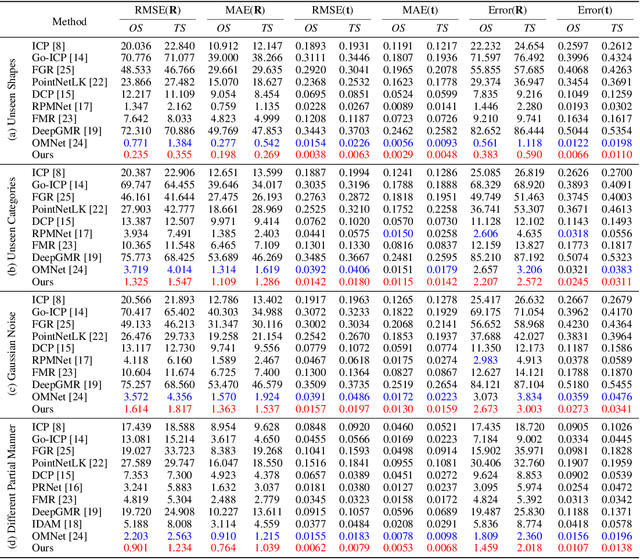
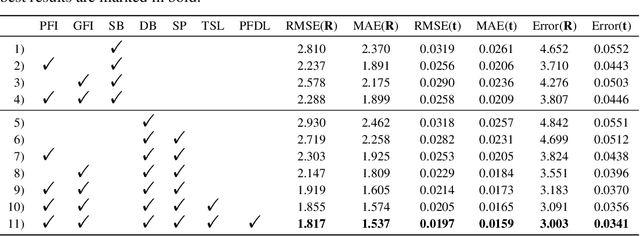
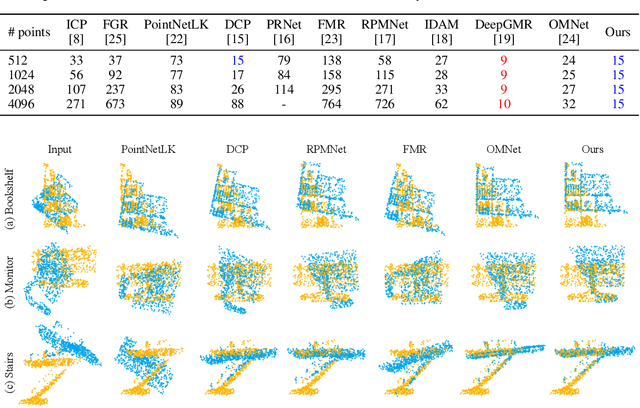
Data association is important in the point cloud registration. In this work, we propose to solve the partial-to-partial registration from a new perspective, by introducing feature interactions between the source and the reference clouds at the feature extraction stage, such that the registration can be realized without the explicit mask estimation or attentions for the overlapping detection as adopted previously. Specifically, we present FINet, a feature interaction-based structure with the capability to enable and strengthen the information associating between the inputs at multiple stages. To achieve this, we first split the features into two components, one for the rotation and one for the translation, based on the fact that they belong to different solution spaces, yielding a dual branches structure. Second, we insert several interaction modules at the feature extractor for the data association. Third, we propose a transformation sensitivity loss to obtain rotation-attentive and translation-attentive features. Experiments demonstrate that our method performs higher precision and robustness compared to the state-of-the-art traditional and learning-based methods.
ReadTwice: Reading Very Large Documents with Memories
May 11, 2021
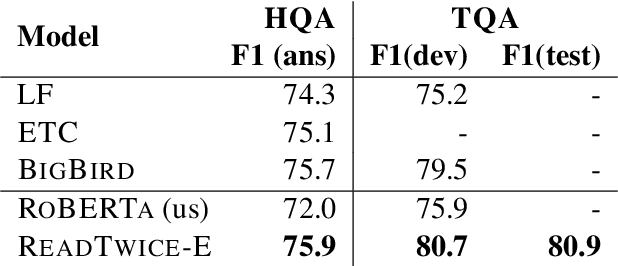
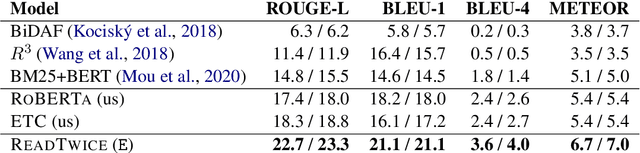
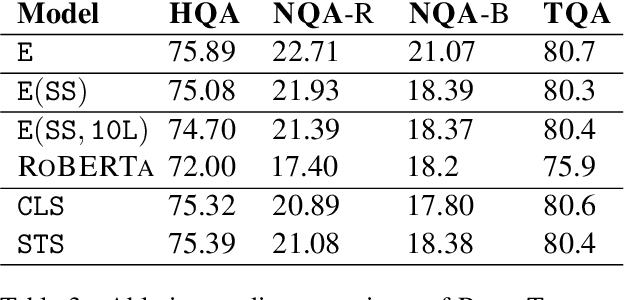
Knowledge-intensive tasks such as question answering often require assimilating information from different sections of large inputs such as books or article collections. We propose ReadTwice, a simple and effective technique that combines several strengths of prior approaches to model long-range dependencies with Transformers. The main idea is to read text in small segments, in parallel, summarizing each segment into a memory table to be used in a second read of the text. We show that the method outperforms models of comparable size on several question answering (QA) datasets and sets a new state of the art on the challenging NarrativeQA task, with questions about entire books. Source code and pre-trained checkpoints for ReadTwice can be found at https://goo.gle/research-readtwice.
Selective Forgetting of Deep Networks at a Finer Level than Samples
Dec 22, 2020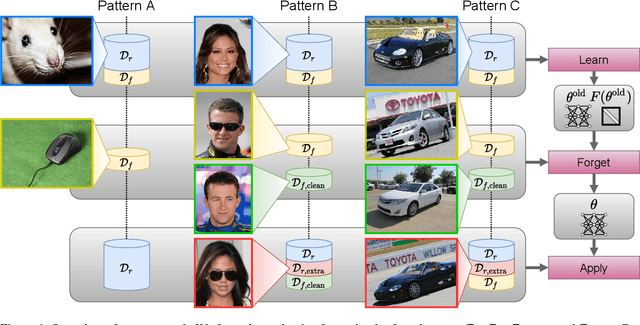
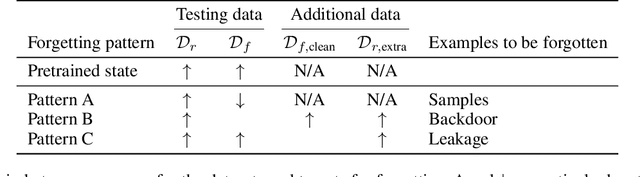

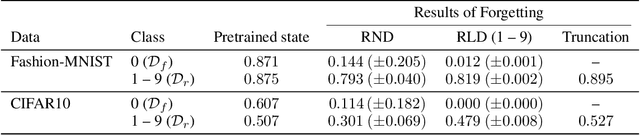
Selective forgetting or removing information from deep neural networks (DNNs) is essential for continuous learning and is challenging in controlling the DNNs. Such forgetting is crucial also in a practical sense since the deployed DNNs may be trained on the data with outliers, poisoned by attackers, or with leaked/sensitive information. In this paper, we formulate selective forgetting for classification tasks at a finer level than the samples' level. We specify the finer level based on four datasets distinguished by two conditions: whether they contain information to be forgotten and whether they are available for the forgetting procedure. Additionally, we reveal the need for such formulation with the datasets by showing concrete and practical situations. Moreover, we introduce the forgetting procedure as an optimization problem on three criteria; the forgetting, the correction, and the remembering term. Experimental results show that the proposed methods can make the model forget to use specific information for classification. Notably, in specific cases, our methods improved the model's accuracy on the datasets, which contains information to be forgotten but is unavailable in the forgetting procedure. Such data are unexpectedly found and misclassified in actual situations.
Progressive Open-Domain Response Generation with Multiple Controllable Attributes
Jun 07, 2021
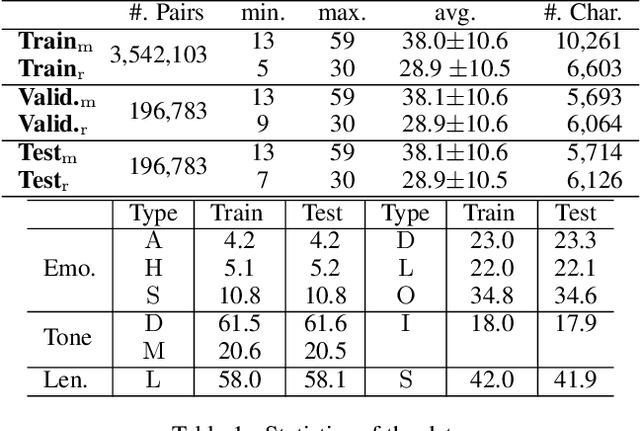
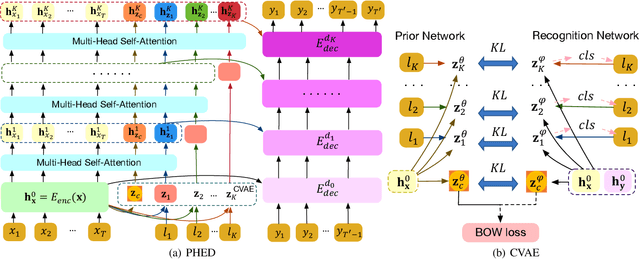
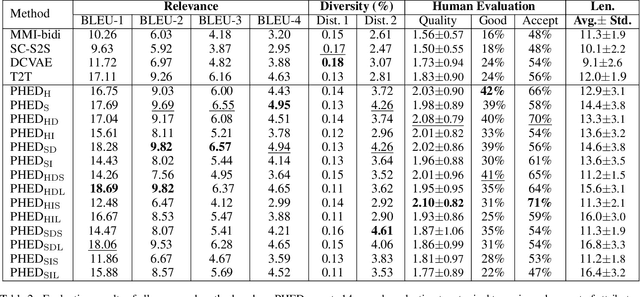
It is desirable to include more controllable attributes to enhance the diversity of generated responses in open-domain dialogue systems. However, existing methods can generate responses with only one controllable attribute or lack a flexible way to generate them with multiple controllable attributes. In this paper, we propose a Progressively trained Hierarchical Encoder-Decoder (PHED) to tackle this task. More specifically, PHED deploys Conditional Variational AutoEncoder (CVAE) on Transformer to include one aspect of attributes at one stage. A vital characteristic of the CVAE is to separate the latent variables at each stage into two types: a global variable capturing the common semantic features and a specific variable absorbing the attribute information at that stage. PHED then couples the CVAE latent variables with the Transformer encoder and is trained by minimizing a newly derived ELBO and controlled losses to produce the next stage's input and produce responses as required. Finally, we conduct extensive evaluations to show that PHED significantly outperforms the state-of-the-art neural generation models and produces more diverse responses as expected.
Disambiguatory Signals are Stronger in Word-initial Positions
Feb 03, 2021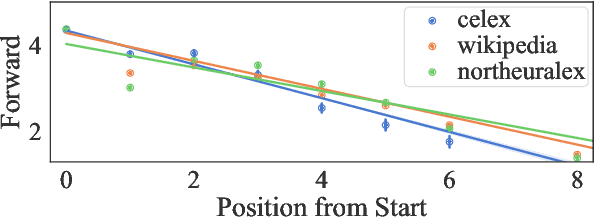
Psycholinguistic studies of human word processing and lexical access provide ample evidence of the preferred nature of word-initial versus word-final segments, e.g., in terms of attention paid by listeners (greater) or the likelihood of reduction by speakers (lower). This has led to the conjecture -- as in Wedel et al. (2019b), but common elsewhere -- that languages have evolved to provide more information earlier in words than later. Information-theoretic methods to establish such tendencies in lexicons have suffered from several methodological shortcomings that leave open the question of whether this high word-initial informativeness is actually a property of the lexicon or simply an artefact of the incremental nature of recognition. In this paper, we point out the confounds in existing methods for comparing the informativeness of segments early in the word versus later in the word, and present several new measures that avoid these confounds. When controlling for these confounds, we still find evidence across hundreds of languages that indeed there is a cross-linguistic tendency to front-load information in words.
Generalized Linear Bandits with Local Differential Privacy
Jun 07, 2021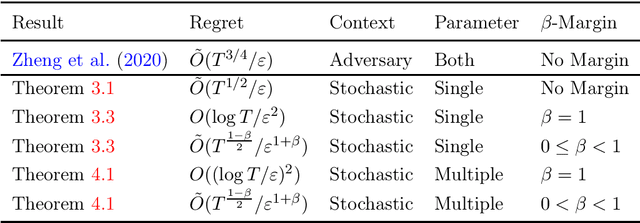
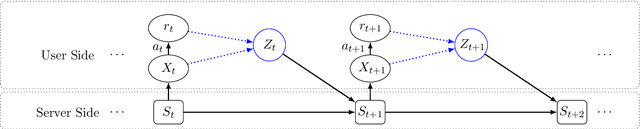
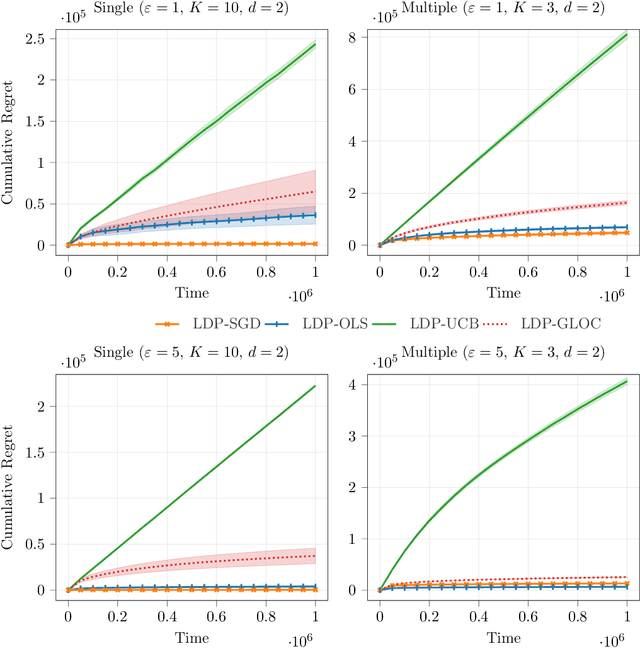
Contextual bandit algorithms are useful in personalized online decision-making. However, many applications such as personalized medicine and online advertising require the utilization of individual-specific information for effective learning, while user's data should remain private from the server due to privacy concerns. This motivates the introduction of local differential privacy (LDP), a stringent notion in privacy, to contextual bandits. In this paper, we design LDP algorithms for stochastic generalized linear bandits to achieve the same regret bound as in non-privacy settings. Our main idea is to develop a stochastic gradient-based estimator and update mechanism to ensure LDP. We then exploit the flexibility of stochastic gradient descent (SGD), whose theoretical guarantee for bandit problems is rarely explored, in dealing with generalized linear bandits. We also develop an estimator and update mechanism based on Ordinary Least Square (OLS) for linear bandits. Finally, we conduct experiments with both simulation and real-world datasets to demonstrate the consistently superb performance of our algorithms under LDP constraints with reasonably small parameters $(\varepsilon, \delta)$ to ensure strong privacy protection.
Why Should I Trust a Model is Private? Using Shifts in Model Explanation for Evaluating Privacy-Preserving Emotion Recognition Model
Apr 18, 2021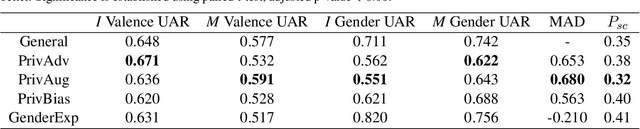
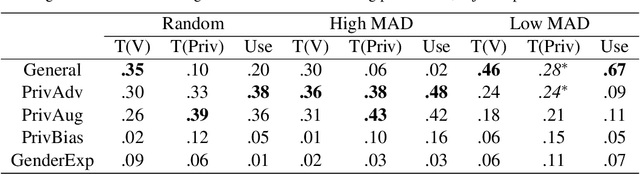
Privacy preservation is a crucial component of any real-world application. Yet, in applications relying on machine learning backends, this is challenging because models often capture more than a designer may have envisioned, resulting in the potential leakage of sensitive information. For example, emotion recognition models are susceptible to learning patterns between the target variable and other sensitive variables, patterns that can be maliciously re-purposed to obtain protected information. In this paper, we concentrate on using interpretable methods to evaluate a model's efficacy to preserve privacy with respect to sensitive variables. We focus on saliency-based explanations, explanations that highlight regions of the input text, which allows us to understand how model explanations shift when models are trained to preserve privacy. We show how certain commonly-used methods that seek to preserve privacy might not align with human perception of privacy preservation. We also show how some of these induce spurious correlations in the model between the input and the primary as well as secondary task, even if the improvement in evaluation metric is significant. Such correlations can hence lead to false assurances about the perceived privacy of the model because especially when used in cross corpus conditions. We conduct crowdsourcing experiments to evaluate the inclination of the evaluators to choose a particular model for a given task when model explanations are provided, and find that correlation of interpretation differences with sociolinguistic biases can be used as a proxy for user trust.