 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Real-time Road Traffic Information Detection Through Social Media
Jan 16, 2018
In current study, a mechanism to extract traffic related information such as congestion and incidents from textual data from the internet is proposed. The current source of data is Twitter. As the data being considered is extremely large in size automated models are developed to stream, download, and mine the data in real-time. Furthermore, if any tweet has traffic related information then the models should be able to infer and extract this data. Currently, the data is collected only for United States and a total of 120,000 geo-tagged traffic related tweets are extracted, while six million geo-tagged non-traffic related tweets are retrieved and classification models are trained. Furthermore, this data is used for various kinds of spatial and temporal analysis. A mechanism to calculate level of traffic congestion, safety, and traffic perception for cities in U.S. is proposed. Traffic congestion and safety rankings for the various urban areas are obtained and then they are statistically validated with existing widely adopted rankings. Traffic perception depicts the attitude and perception of people towards the traffic. It is also seen that traffic related data when visualized spatially and temporally provides the same pattern as the actual traffic flows for various urban areas. When visualized at the city level, it is clearly visible that the flow of tweets is similar to flow of vehicles and that the traffic related tweets are representative of traffic within the cities. With all the findings in current study, it is shown that significant amount of traffic related information can be extracted from Twitter and other sources on internet. Furthermore, Twitter and these data sources are freely available and are not bound by spatial and temporal limitations. That is, wherever there is a user there is a potential for data.
Intrusion Detection System in Smart Home Network Using Bidirectional LSTM and Convolutional Neural Networks Hybrid Model
May 27, 2021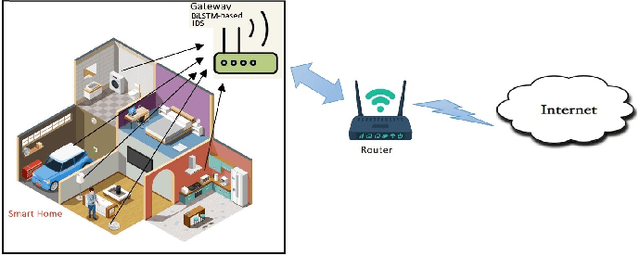
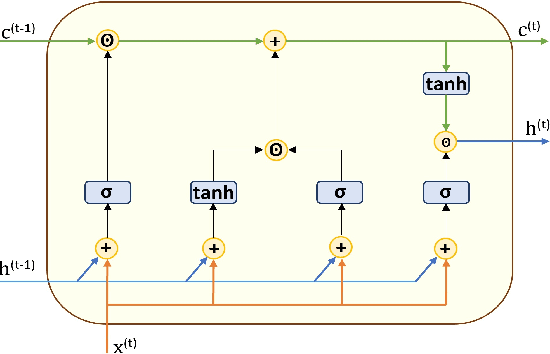
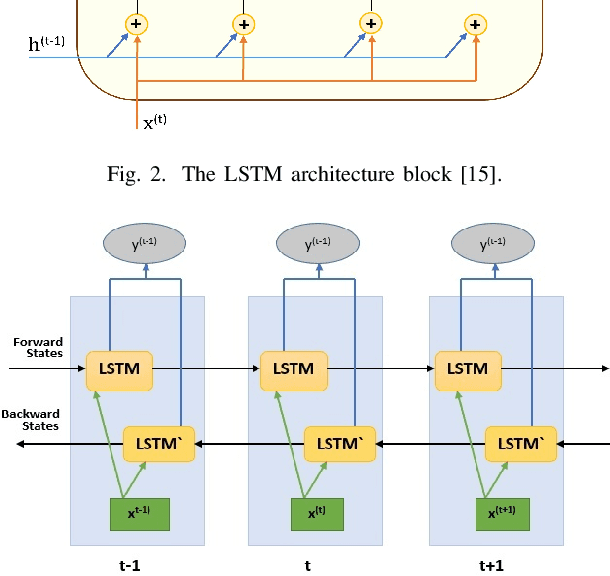
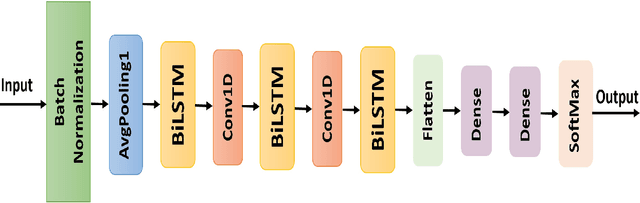
Internet of Things (IoT) allowed smart homes to improve the quality and the comfort of our daily lives. However, these conveniences introduced several security concerns that increase rapidly. IoT devices, smart home hubs, and gateway raise various security risks. The smart home gateways act as a centralized point of communication between the IoT devices, which can create a backdoor into network data for hackers. One of the common and effective ways to detect such attacks is intrusion detection in the network traffic. In this paper, we proposed an intrusion detection system (IDS) to detect anomalies in a smart home network using a bidirectional long short-term memory (BiLSTM) and convolutional neural network (CNN) hybrid model. The BiLSTM recurrent behavior provides the intrusion detection model to preserve the learned information through time, and the CNN extracts perfectly the data features. The proposed model can be applied to any smart home network gateway.
Interpretable and Low-Resource Entity Matching via Decoupling Feature Learning from Decision Making
Jun 08, 2021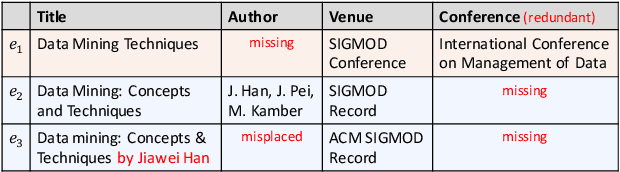
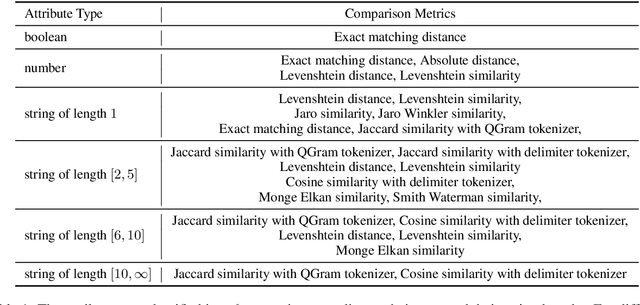
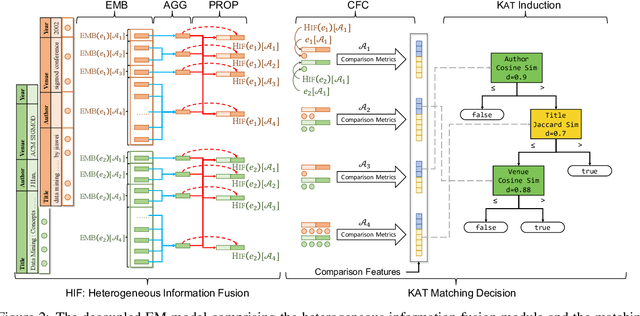
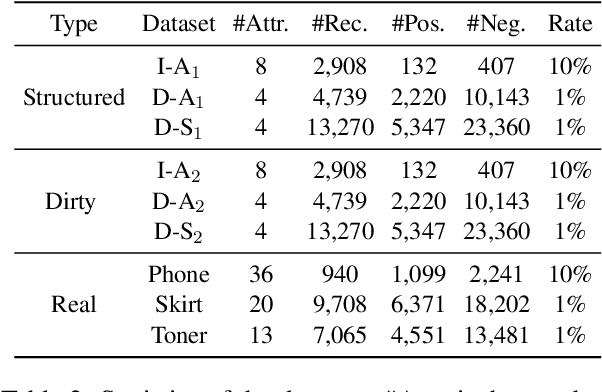
Entity Matching (EM) aims at recognizing entity records that denote the same real-world object. Neural EM models learn vector representation of entity descriptions and match entities end-to-end. Though robust, these methods require many resources for training, and lack of interpretability. In this paper, we propose a novel EM framework that consists of Heterogeneous Information Fusion (HIF) and Key Attribute Tree (KAT) Induction to decouple feature representation from matching decision. Using self-supervised learning and mask mechanism in pre-trained language modeling, HIF learns the embeddings of noisy attribute values by inter-attribute attention with unlabeled data. Using a set of comparison features and a limited amount of annotated data, KAT Induction learns an efficient decision tree that can be interpreted by generating entity matching rules whose structure is advocated by domain experts. Experiments on 6 public datasets and 3 industrial datasets show that our method is highly efficient and outperforms SOTA EM models in most cases. Our codes and datasets can be obtained from https://github.com/THU-KEG/HIF-KAT.
A Grounded Approach to Modeling Generic Knowledge Acquisition
May 07, 2021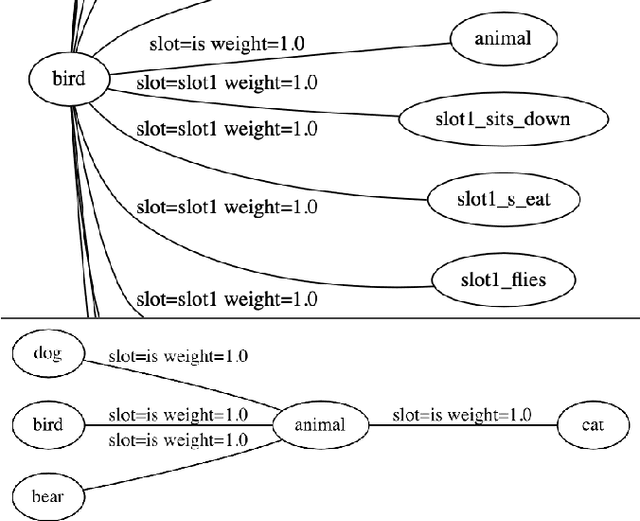
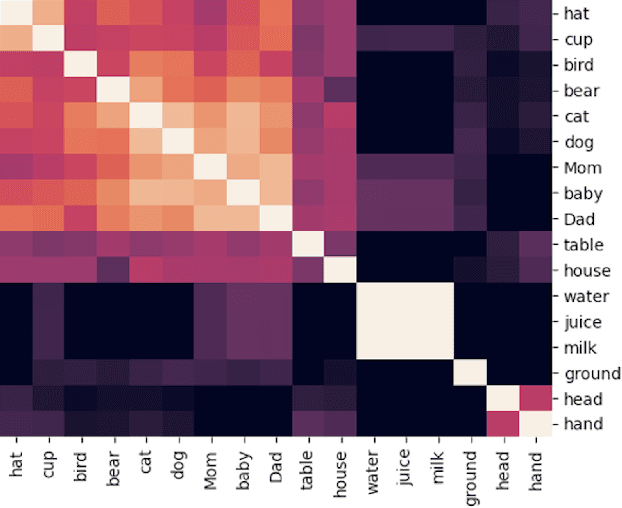

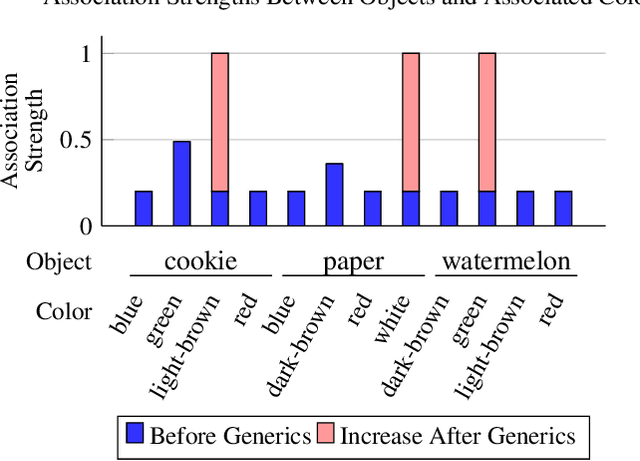
We introduce and implement a cognitively plausible model for learning from generic language, statements that express generalizations about members of a category and are an important aspect of concept development in language acquisition (Carlson & Pelletier, 1995; Gelman, 2009). We extend a computational framework designed to model grounded language acquisition by introducing the concept network. This new layer of abstraction enables the system to encode knowledge learned from generic statements and represent the associations between concepts learned by the system. Through three tasks that utilize the concept network, we demonstrate that our extensions to ADAM can acquire generic information and provide an example of how ADAM can be used to model language acquisition.
Stage-wise Fine-tuning for Graph-to-Text Generation
May 17, 2021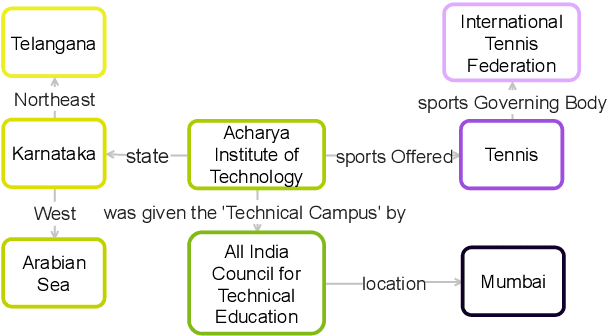

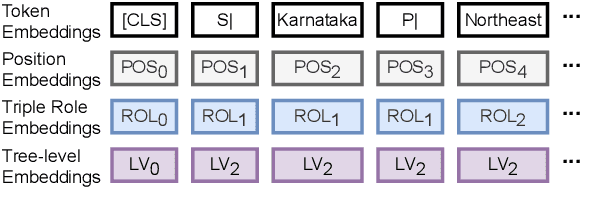
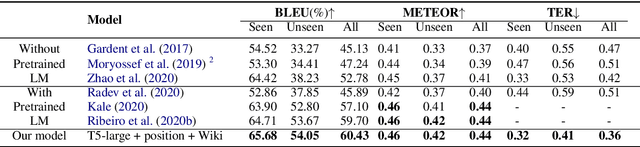
Graph-to-text generation has benefited from pre-trained language models (PLMs) in achieving better performance than structured graph encoders. However, they fail to fully utilize the structure information of the input graph. In this paper, we aim to further improve the performance of the pre-trained language model by proposing a structured graph-to-text model with a two-step fine-tuning mechanism which first fine-tunes model on Wikipedia before adapting to the graph-to-text generation. In addition to using the traditional token and position embeddings to encode the knowledge graph (KG), we propose a novel tree-level embedding method to capture the inter-dependency structures of the input graph. This new approach has significantly improved the performance of all text generation metrics for the English WebNLG 2017 dataset.
Selective Forgetting of Deep Networks at a Finer Level than Samples
Dec 22, 2020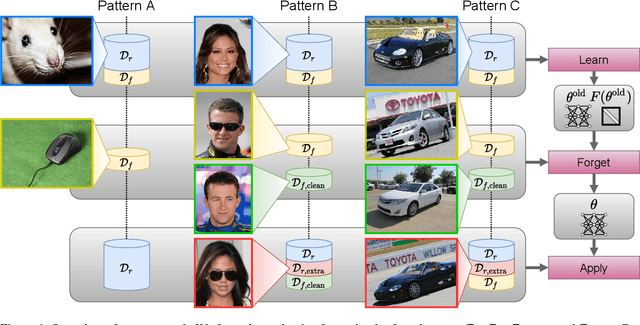
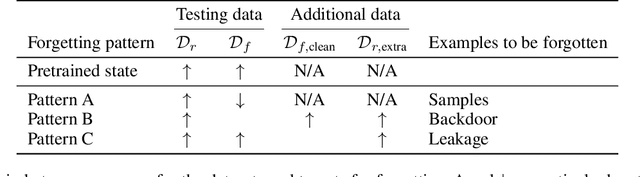

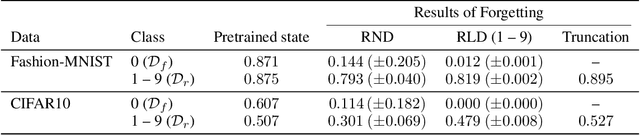
Selective forgetting or removing information from deep neural networks (DNNs) is essential for continuous learning and is challenging in controlling the DNNs. Such forgetting is crucial also in a practical sense since the deployed DNNs may be trained on the data with outliers, poisoned by attackers, or with leaked/sensitive information. In this paper, we formulate selective forgetting for classification tasks at a finer level than the samples' level. We specify the finer level based on four datasets distinguished by two conditions: whether they contain information to be forgotten and whether they are available for the forgetting procedure. Additionally, we reveal the need for such formulation with the datasets by showing concrete and practical situations. Moreover, we introduce the forgetting procedure as an optimization problem on three criteria; the forgetting, the correction, and the remembering term. Experimental results show that the proposed methods can make the model forget to use specific information for classification. Notably, in specific cases, our methods improved the model's accuracy on the datasets, which contains information to be forgotten but is unavailable in the forgetting procedure. Such data are unexpectedly found and misclassified in actual situations.
Fully Transformer Networks for Semantic Image Segmentation
Jun 08, 2021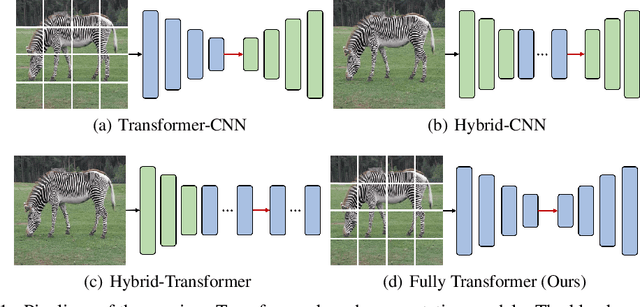
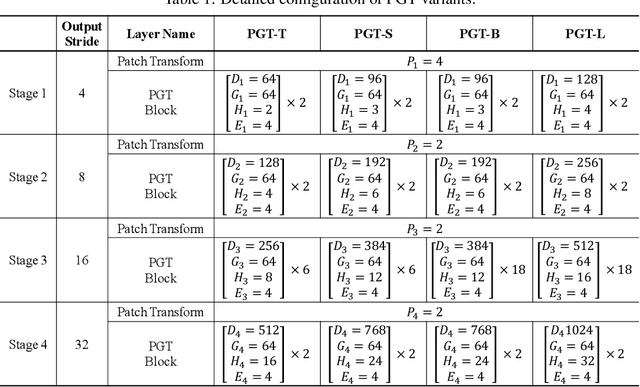
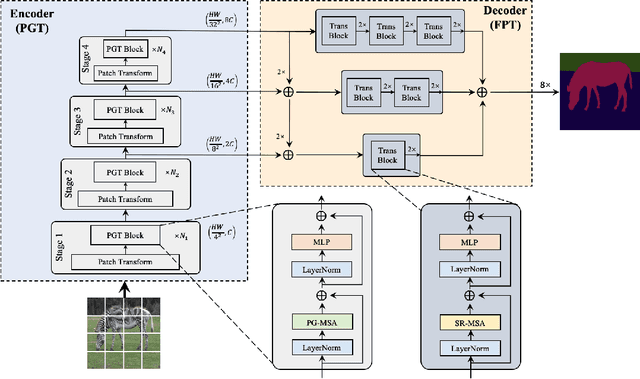
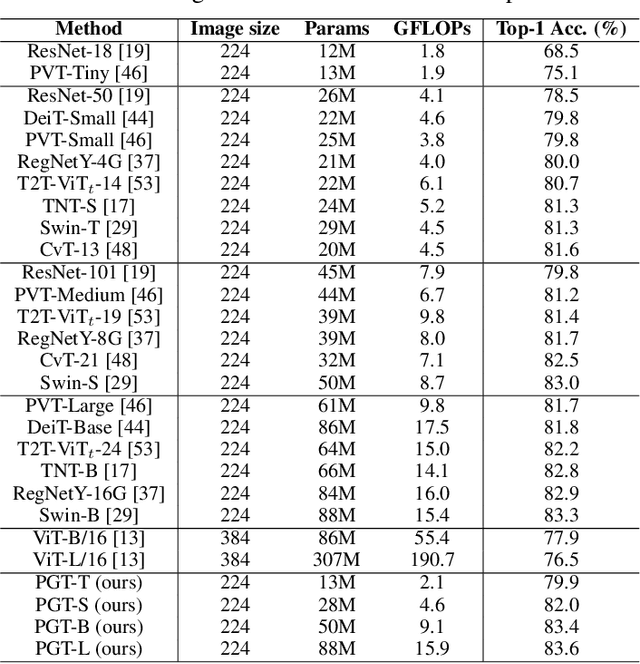
Transformers have shown impressive performance in various natural language processing and computer vision tasks, due to the capability of modeling long-range dependencies. Recent progress has demonstrated to combine such transformers with CNN-based semantic image segmentation models is very promising. However, it is not well studied yet on how well a pure transformer based approach can achieve for image segmentation. In this work, we explore a novel framework for semantic image segmentation, which is encoder-decoder based Fully Transformer Networks (FTN). Specifically, we first propose a Pyramid Group Transformer (PGT) as the encoder for progressively learning hierarchical features, while reducing the computation complexity of the standard visual transformer(ViT). Then, we propose a Feature Pyramid Transformer (FPT) to fuse semantic-level and spatial-level information from multiple levels of the PGT encoder for semantic image segmentation. Surprisingly, this simple baseline can achieve new state-of-the-art results on multiple challenging semantic segmentation benchmarks, including PASCAL Context, ADE20K and COCO-Stuff. The source code will be released upon the publication of this work.
FRaC: FMCW-Based Joint Radar-Communications System via Index Modulation
Jun 28, 2021
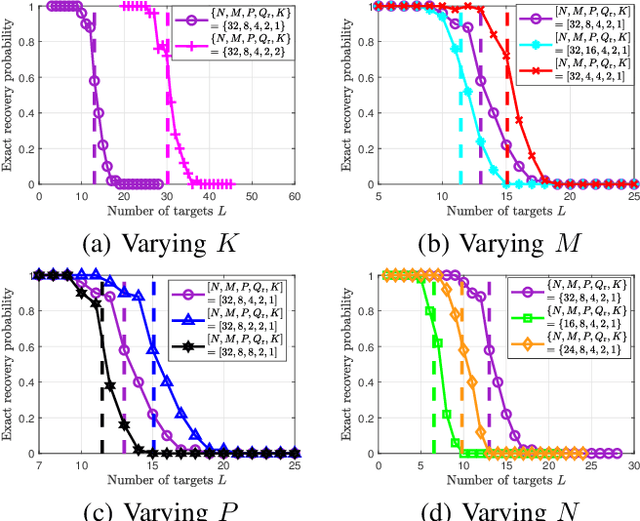
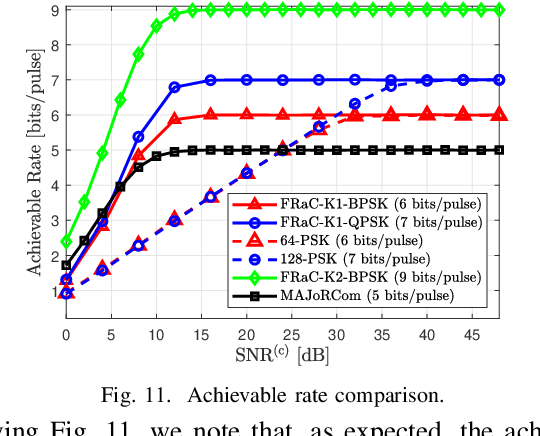
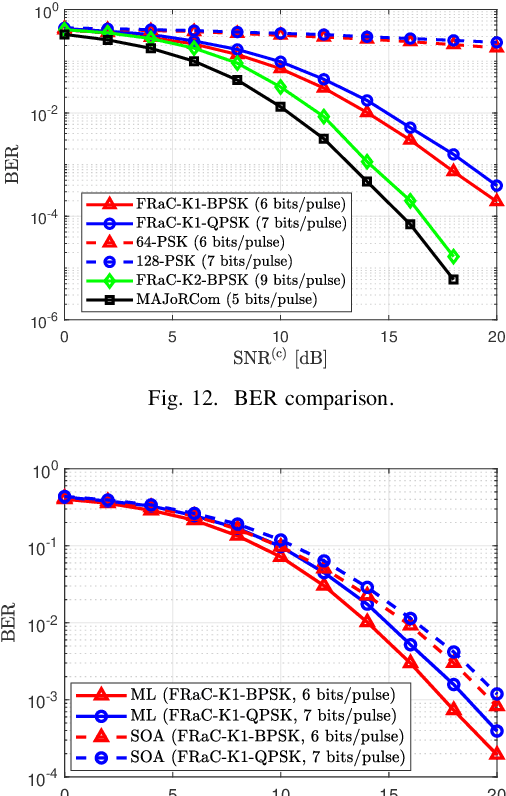
Dual function radar communications (DFRC) systems are attractive technologies for autonomous vehicles, which utilize electromagnetic waves to constantly sense the environment while simultaneously communicating with neighbouring devices. An emerging approach to implement DFRC systems is to embed information in radar waveforms via index modulation (IM). Implementation of DFRC schemes in vehicular systems gives rise to strict constraints in terms of cost, power efficiency, and hardware complexity. In this paper, we extend IM-based DFRC systems to utilize sparse arrays and frequency modulated continuous waveforms (FMCWs), which are popular in automotive radar for their simplicity and low hardware complexity. The proposed FMCW-based radar-communications system (FRaC) operates at reduced cost and complexity by transmitting with a reduced number of radio frequency modules, combined with narrowband FMCW signalling. This is achieved via array sparsification in transmission, formulating a virtual multiple-input multiple-output array by combining the signals in one coherent processing interval, in which the narrowband waveforms are transmitted in a randomized manner. Performance analysis and numerical results show that the proposed radar scheme achieves similar resolution performance compared with a wideband radar system operating with a large receive aperture, while requiring less hardware overhead. For the communications subsystem, FRaC achieves higher rates and improved error rates compared to dual-function signalling based on conventional phase modulation.
Mutation Sensitive Correlation Filter for Real-Time UAV Tracking with Adaptive Hybrid Label
Jun 15, 2021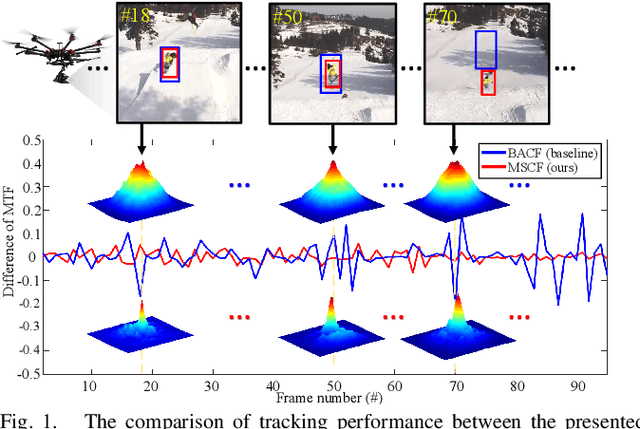
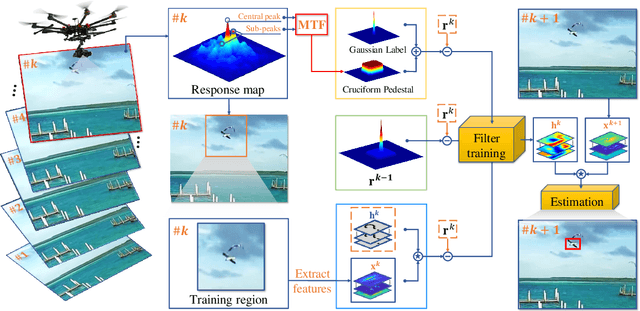
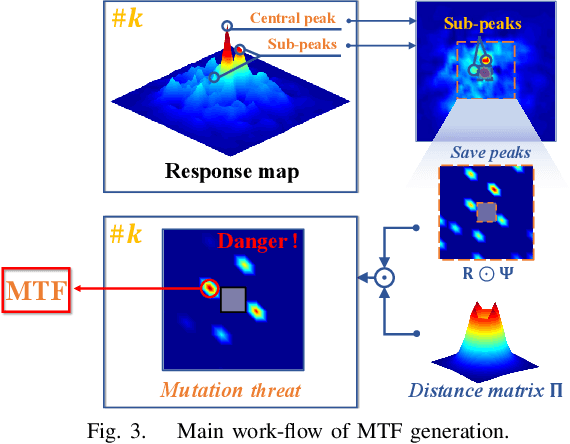
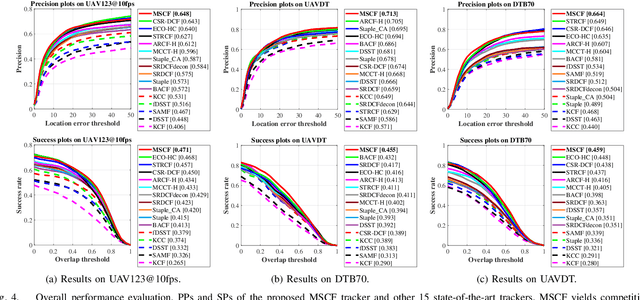
Unmanned aerial vehicle (UAV) based visual tracking has been confronted with numerous challenges, e.g., object motion and occlusion. These challenges generally introduce unexpected mutations of target appearance and result in tracking failure. However, prevalent discriminative correlation filter (DCF) based trackers are insensitive to target mutations due to a predefined label, which concentrates on merely the centre of the training region. Meanwhile, appearance mutations caused by occlusion or similar objects usually lead to the inevitable learning of wrong information. To cope with appearance mutations, this paper proposes a novel DCF-based method to enhance the sensitivity and resistance to mutations with an adaptive hybrid label, i.e., MSCF. The ideal label is optimized jointly with the correlation filter and remains temporal consistency. Besides, a novel measurement of mutations called mutation threat factor (MTF) is applied to correct the label dynamically. Considerable experiments are conducted on widely used UAV benchmarks. The results indicate that the performance of MSCF tracker surpasses other 26 state-of-the-art DCF-based and deep-based trackers. With a real-time speed of _38 frames/s, the proposed approach is sufficient for UAV tracking commissions.
The Possible, the Plausible, and the Desirable: Event-Based Modality Detection for Language Processing
Jun 15, 2021
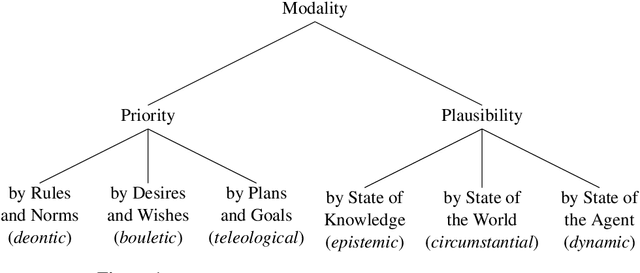

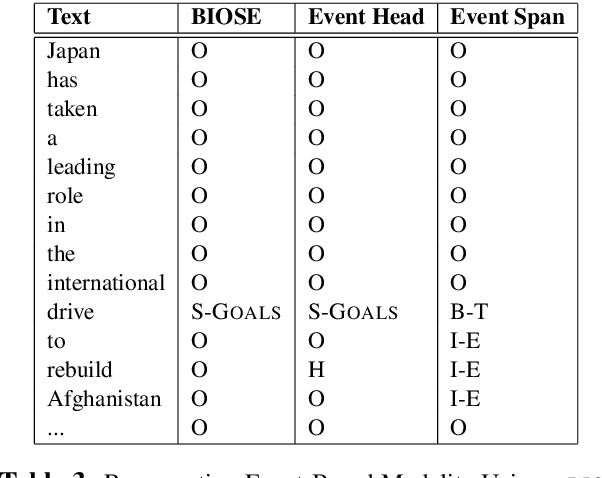
Modality is the linguistic ability to describe events with added information such as how desirable, plausible, or feasible they are. Modality is important for many NLP downstream tasks such as the detection of hedging, uncertainty, speculation, and more. Previous studies that address modality detection in NLP often restrict modal expressions to a closed syntactic class, and the modal sense labels are vastly different across different studies, lacking an accepted standard. Furthermore, these senses are often analyzed independently of the events that they modify. This work builds on the theoretical foundations of the Georgetown Gradable Modal Expressions (GME) work by Rubinstein et al. (2013) to propose an event-based modality detection task where modal expressions can be words of any syntactic class and sense labels are drawn from a comprehensive taxonomy which harmonizes the modal concepts contributed by the different studies. We present experiments on the GME corpus aiming to detect and classify fine-grained modal concepts and associate them with their modified events. We show that detecting and classifying modal expressions is not only feasible, but also improves the detection of modal events in their own right.