 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Intrusion Detection System in Smart Home Network Using Bidirectional LSTM and Convolutional Neural Networks Hybrid Model
May 27, 2021
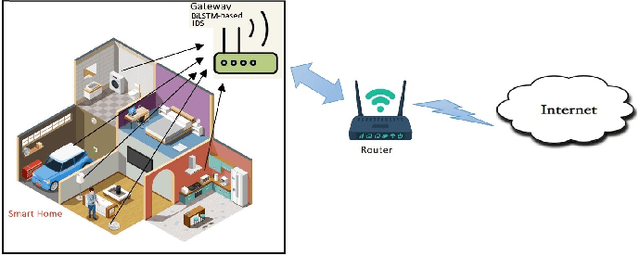
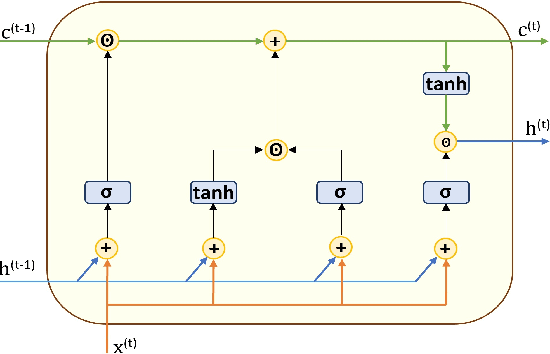
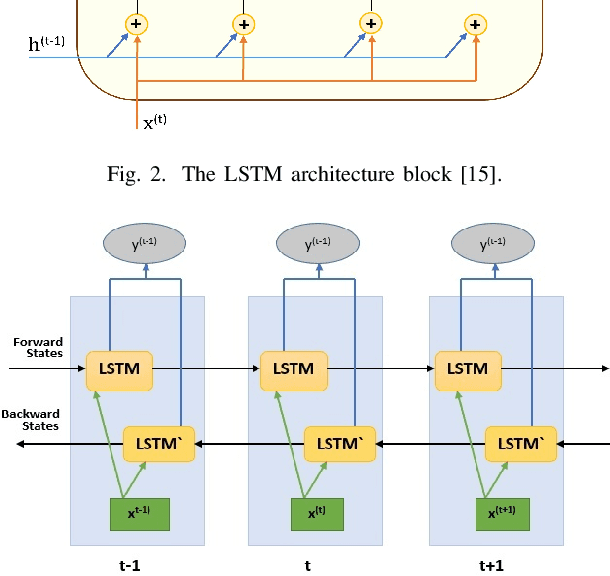
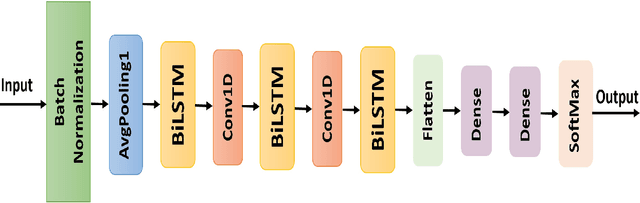
Internet of Things (IoT) allowed smart homes to improve the quality and the comfort of our daily lives. However, these conveniences introduced several security concerns that increase rapidly. IoT devices, smart home hubs, and gateway raise various security risks. The smart home gateways act as a centralized point of communication between the IoT devices, which can create a backdoor into network data for hackers. One of the common and effective ways to detect such attacks is intrusion detection in the network traffic. In this paper, we proposed an intrusion detection system (IDS) to detect anomalies in a smart home network using a bidirectional long short-term memory (BiLSTM) and convolutional neural network (CNN) hybrid model. The BiLSTM recurrent behavior provides the intrusion detection model to preserve the learned information through time, and the CNN extracts perfectly the data features. The proposed model can be applied to any smart home network gateway.
Mutation Sensitive Correlation Filter for Real-Time UAV Tracking with Adaptive Hybrid Label
Jun 15, 2021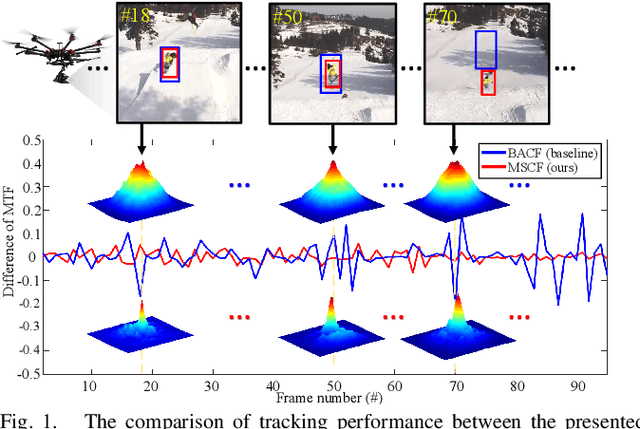
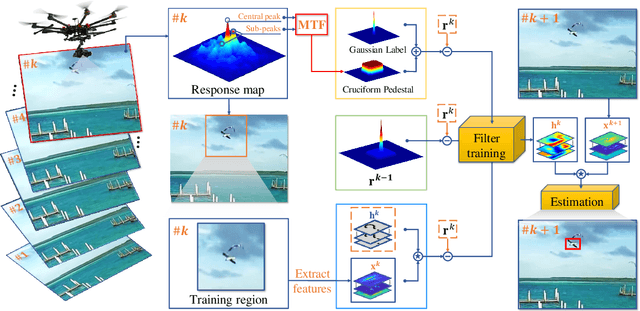
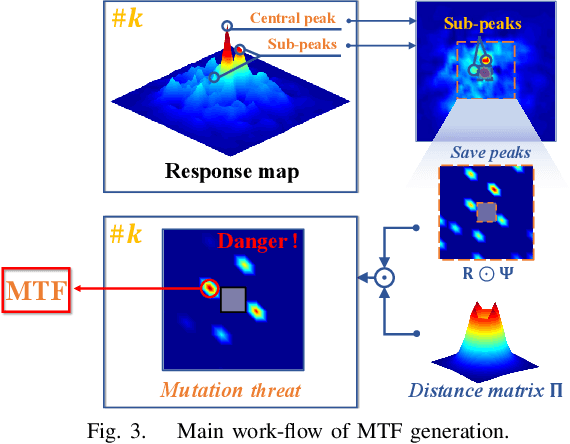
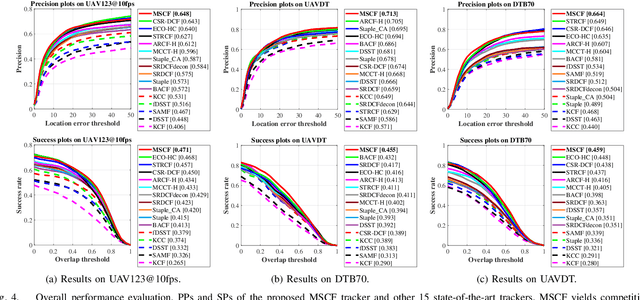
Unmanned aerial vehicle (UAV) based visual tracking has been confronted with numerous challenges, e.g., object motion and occlusion. These challenges generally introduce unexpected mutations of target appearance and result in tracking failure. However, prevalent discriminative correlation filter (DCF) based trackers are insensitive to target mutations due to a predefined label, which concentrates on merely the centre of the training region. Meanwhile, appearance mutations caused by occlusion or similar objects usually lead to the inevitable learning of wrong information. To cope with appearance mutations, this paper proposes a novel DCF-based method to enhance the sensitivity and resistance to mutations with an adaptive hybrid label, i.e., MSCF. The ideal label is optimized jointly with the correlation filter and remains temporal consistency. Besides, a novel measurement of mutations called mutation threat factor (MTF) is applied to correct the label dynamically. Considerable experiments are conducted on widely used UAV benchmarks. The results indicate that the performance of MSCF tracker surpasses other 26 state-of-the-art DCF-based and deep-based trackers. With a real-time speed of _38 frames/s, the proposed approach is sufficient for UAV tracking commissions.
Fully Transformer Networks for Semantic Image Segmentation
Jun 08, 2021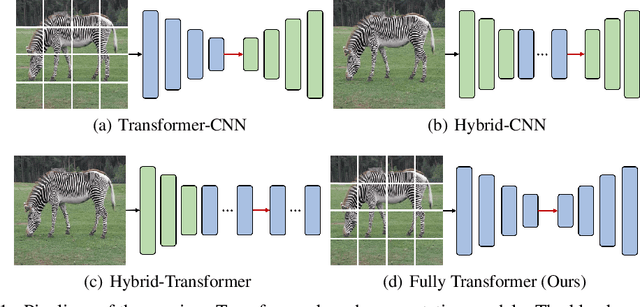
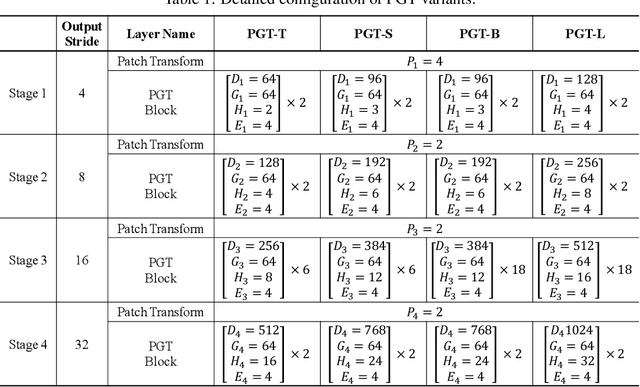
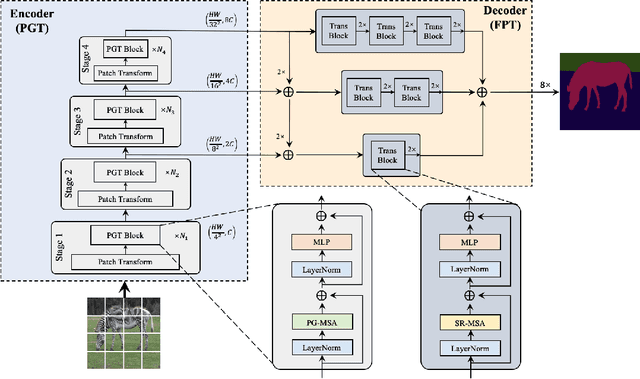
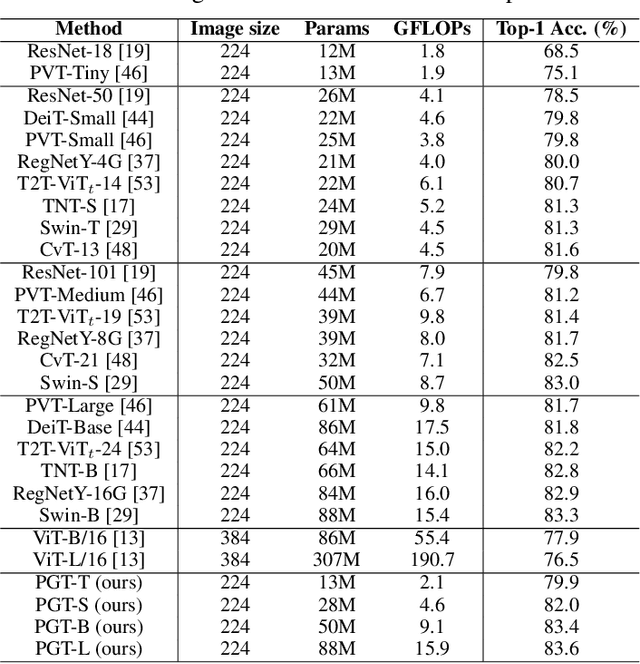
Transformers have shown impressive performance in various natural language processing and computer vision tasks, due to the capability of modeling long-range dependencies. Recent progress has demonstrated to combine such transformers with CNN-based semantic image segmentation models is very promising. However, it is not well studied yet on how well a pure transformer based approach can achieve for image segmentation. In this work, we explore a novel framework for semantic image segmentation, which is encoder-decoder based Fully Transformer Networks (FTN). Specifically, we first propose a Pyramid Group Transformer (PGT) as the encoder for progressively learning hierarchical features, while reducing the computation complexity of the standard visual transformer(ViT). Then, we propose a Feature Pyramid Transformer (FPT) to fuse semantic-level and spatial-level information from multiple levels of the PGT encoder for semantic image segmentation. Surprisingly, this simple baseline can achieve new state-of-the-art results on multiple challenging semantic segmentation benchmarks, including PASCAL Context, ADE20K and COCO-Stuff. The source code will be released upon the publication of this work.
Deep Neural Networks Learn Meta-Structures to Segment Fluorescence Microscopy Images
Mar 22, 2021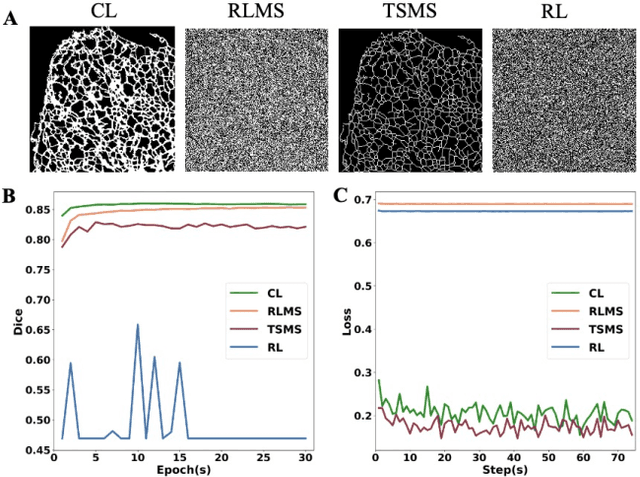
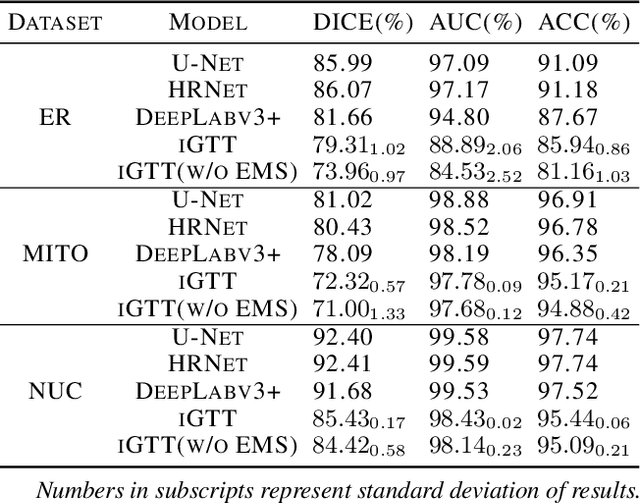
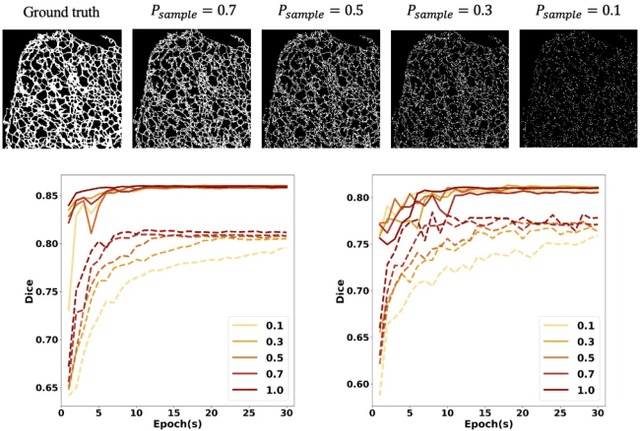
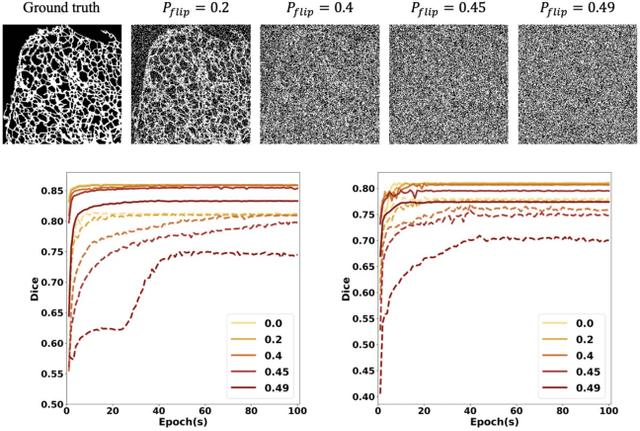
Fluorescence microscopy images play the critical role of capturing spatial or spatiotemporal information of biomedical processes in life sciences. Their simple structures and semantics provide unique advantages in elucidating learning behavior of deep neural networks (DNNs). It is generally assumed that accurate image annotation is required to train DNNs for accurate image segmentation. In this study, however, we find that DNNs trained by label images in which nearly half (49%) of the binary pixel labels are randomly flipped provide largely the same segmentation performance. This suggests that DNNs learn high-level structures rather than pixel-level labels per se to segment fluorescence microscopy images. We refer to these structures as meta-structures. In support of the existence of the meta-structures, when DNNs are trained by a series of label images with progressively less meta-structure information, we find progressive degradation in their segmentation performance. Motivated by the learning behavior of DNNs trained by random labels and the characteristics of meta-structures, we propose an unsupervised segmentation model. Experiments show that it achieves remarkably competitive performance in comparison to supervised segmentation models.
The Possible, the Plausible, and the Desirable: Event-Based Modality Detection for Language Processing
Jun 15, 2021
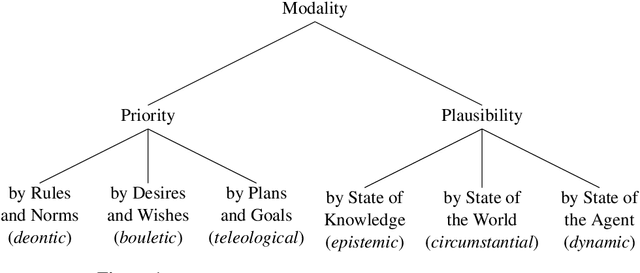

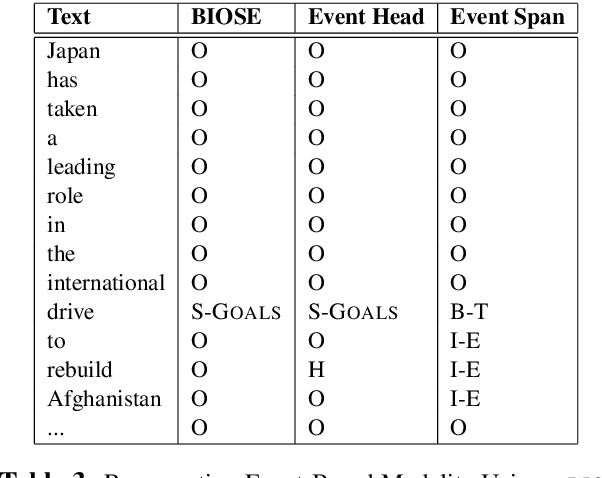
Modality is the linguistic ability to describe events with added information such as how desirable, plausible, or feasible they are. Modality is important for many NLP downstream tasks such as the detection of hedging, uncertainty, speculation, and more. Previous studies that address modality detection in NLP often restrict modal expressions to a closed syntactic class, and the modal sense labels are vastly different across different studies, lacking an accepted standard. Furthermore, these senses are often analyzed independently of the events that they modify. This work builds on the theoretical foundations of the Georgetown Gradable Modal Expressions (GME) work by Rubinstein et al. (2013) to propose an event-based modality detection task where modal expressions can be words of any syntactic class and sense labels are drawn from a comprehensive taxonomy which harmonizes the modal concepts contributed by the different studies. We present experiments on the GME corpus aiming to detect and classify fine-grained modal concepts and associate them with their modified events. We show that detecting and classifying modal expressions is not only feasible, but also improves the detection of modal events in their own right.
Multivariate Business Process Representation Learning utilizing Gramian Angular Fields and Convolutional Neural Networks
Jun 15, 2021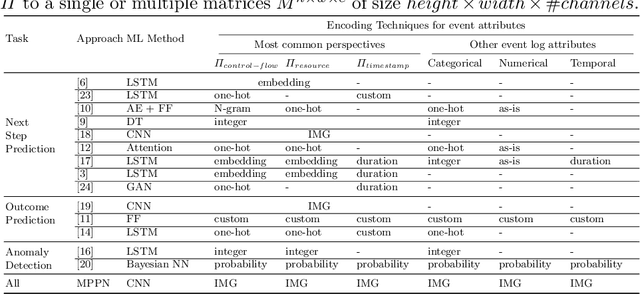
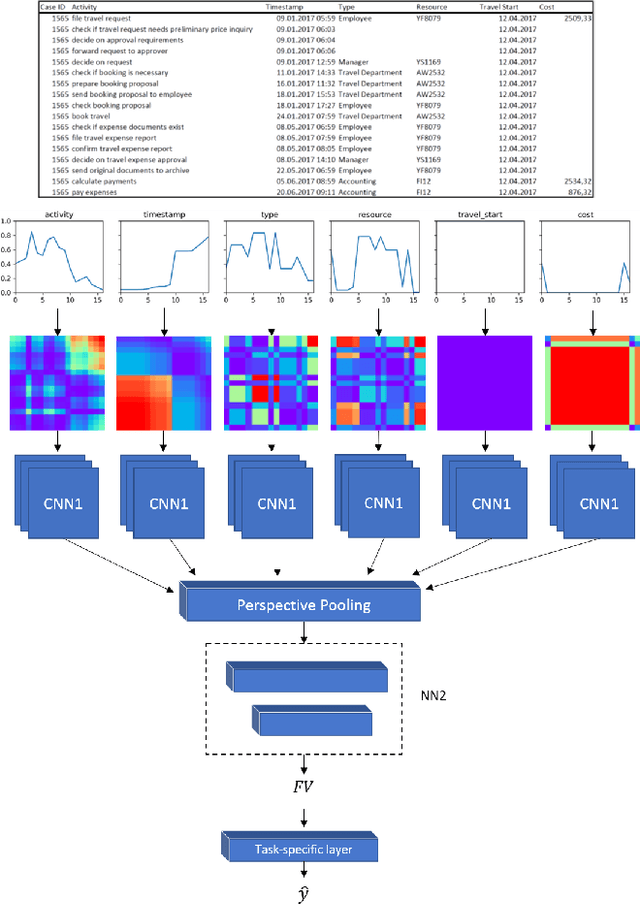
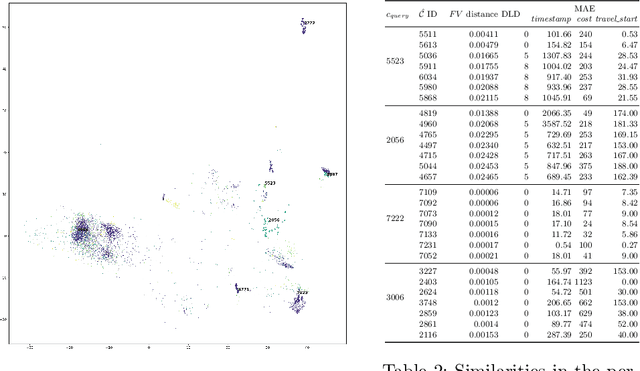
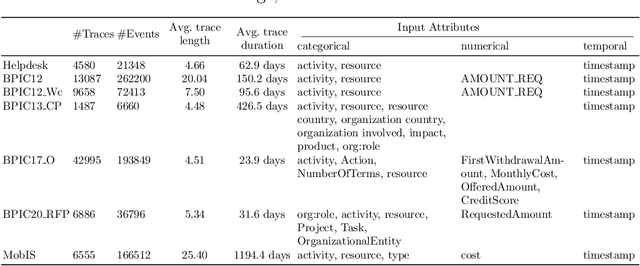
Learning meaningful representations of data is an important aspect of machine learning and has recently been successfully applied to many domains like language understanding or computer vision. Instead of training a model for one specific task, representation learning is about training a model to capture all useful information in the underlying data and make it accessible for a predictor. For predictive process analytics, it is essential to have all explanatory characteristics of a process instance available when making predictions about the future, as well as for clustering and anomaly detection. Due to the large variety of perspectives and types within business process data, generating a good representation is a challenging task. In this paper, we propose a novel approach for representation learning of business process instances which can process and combine most perspectives in an event log. In conjunction with a self-supervised pre-training method, we show the capabilities of the approach through a visualization of the representation space and case retrieval. Furthermore, the pre-trained model is fine-tuned to multiple process prediction tasks and demonstrates its effectiveness in comparison with existing approaches.
Impacts of the Numbers of Colors and Shapes on Outlier Detection: from Automated to User Evaluation
Mar 10, 2021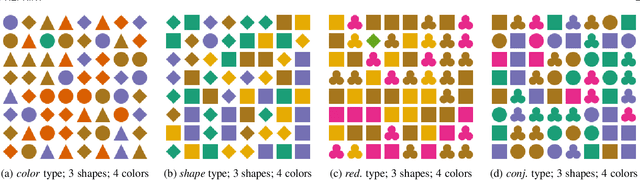
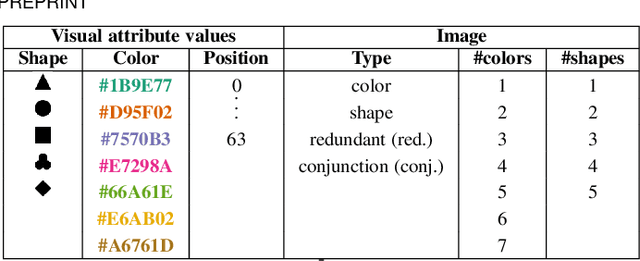
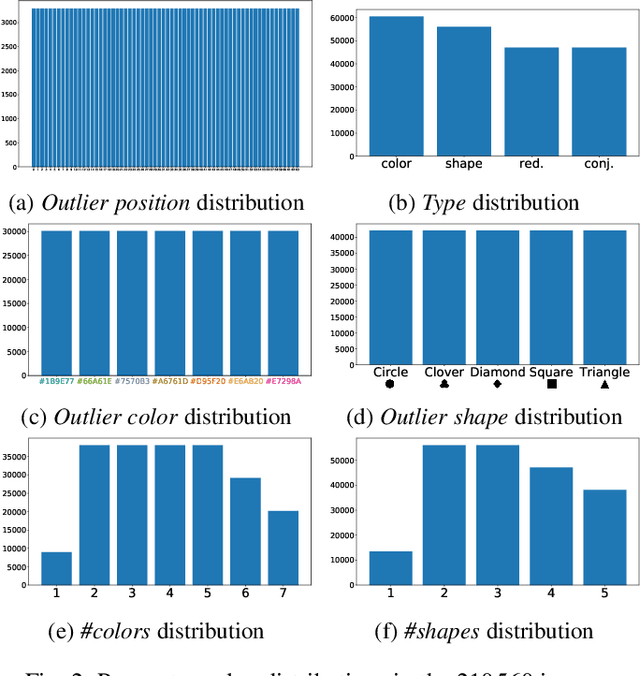
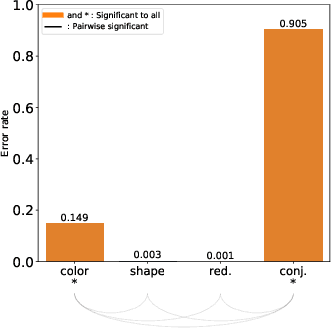
The design of efficient representations is well established as a fruitful way to explore and analyze complex or large data. In these representations, data are encoded with various visual attributes depending on the needs of the representation itself. To make coherent design choices about visual attributes, the visual search field proposes guidelines based on the human brain perception of features. However, information visualization representations frequently need to depict more data than the amount these guidelines have been validated on. Since, the information visualization community has extended these guidelines to a wider parameter space. This paper contributes to this theme by extending visual search theories to an information visualization context. We consider a visual search task where subjects are asked to find an unknown outlier in a grid of randomly laid out distractor. Stimuli are defined by color and shape features for the purpose of visually encoding categorical data. The experimental protocol is made of a parameters space reduction step (i.e., sub-sampling) based on a machine learning model, and a user evaluation to measure capacity limits and validate hypotheses. The results show that the major difficulty factor is the number of visual attributes that are used to encode the outlier. When redundantly encoded, the display heterogeneity has no effect on the task. When encoded with one attribute, the difficulty depends on that attribute heterogeneity until its capacity limit (7 for color, 5 for shape) is reached. Finally, when encoded with two attributes simultaneously, performances drop drastically even with minor heterogeneity.
Change Detection from SAR Images Based on Deformable Residual Convolutional Neural Networks
Apr 06, 2021

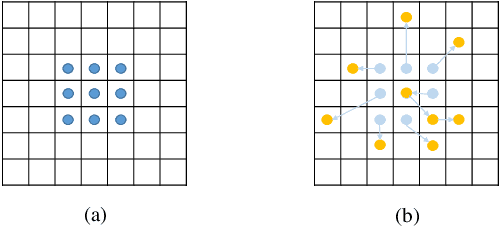
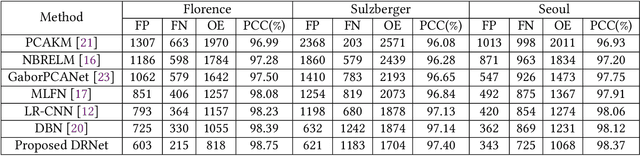
Convolutional neural networks (CNN) have made great progress for synthetic aperture radar (SAR) images change detection. However, sampling locations of traditional convolutional kernels are fixed and cannot be changed according to the actual structure of the SAR images. Besides, objects may appear with different sizes in natural scenes, which requires the network to have stronger multi-scale representation ability. In this paper, a novel \underline{D}eformable \underline{R}esidual Convolutional Neural \underline{N}etwork (DRNet) is designed for SAR images change detection. First, the proposed DRNet introduces the deformable convolutional sampling locations, and the shape of convolutional kernel can be adaptively adjusted according to the actual structure of ground objects. To create the deformable sampling locations, 2-D offsets are calculated for each pixel according to the spatial information of the input images. Then the sampling location of pixels can adaptively reflect the spatial structure of the input images. Moreover, we proposed a novel pooling module replacing the vanilla pooling to utilize multi-scale information effectively, by constructing hierarchical residual-like connections within one pooling layer, which improve the multi-scale representation ability at a granular level. Experimental results on three real SAR datasets demonstrate the effectiveness of the proposed DRNet.
Zero-sample surface defect detection and classification based on semantic feedback neural network
Jun 15, 2021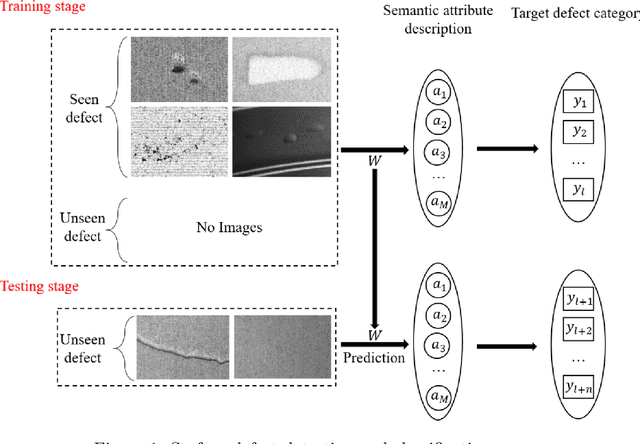



Defect detection and classification technology has changed from traditional artificial visual inspection to current intelligent automated inspection, but most of the current defect detection methods are training related detection models based on a data-driven approach, taking into account the difficulty of collecting some sample data in the industrial field. We apply zero-shot learning technology to the industrial field. Aiming at the problem of the existing "Latent Feature Guide Attribute Attention" (LFGAA) zero-shot image classification network, the output latent attributes and artificially defined attributes are different in the semantic space, which leads to the problem of model performance degradation, proposed an LGFAA network based on semantic feedback, and improved model performance by constructing semantic embedded modules and feedback mechanisms. At the same time, for the common domain shift problem in zero-shot learning, based on the idea of co-training algorithm using the difference information between different views of data to learn from each other, we propose an Ensemble Co-training algorithm, which adaptively reduces the prediction error in image tag embedding from multiple angles. Various experiments conducted on the zero-shot dataset and the cylinder liner dataset in the industrial field provide competitive results.
Cascading Convolutional Temporal Colour Constancy
Jun 15, 2021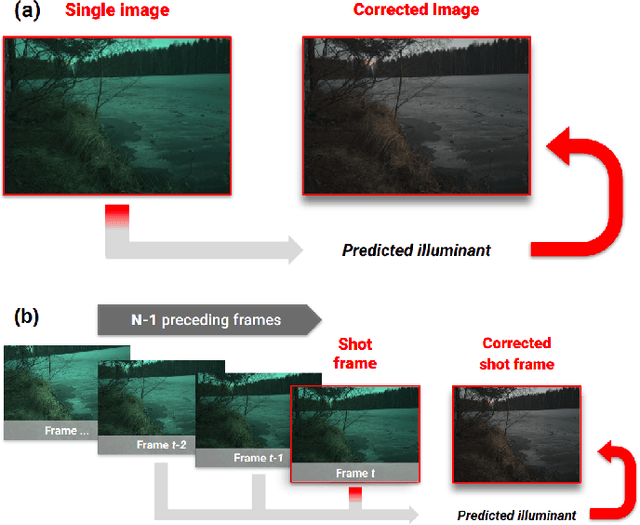
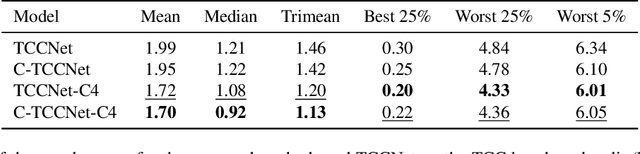
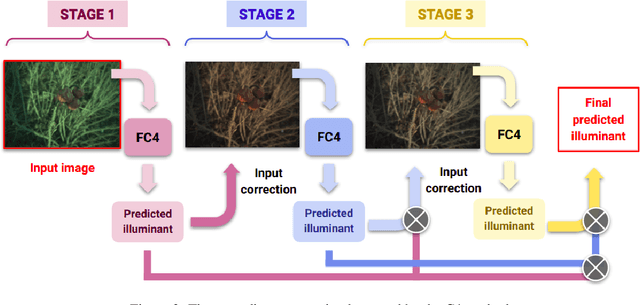
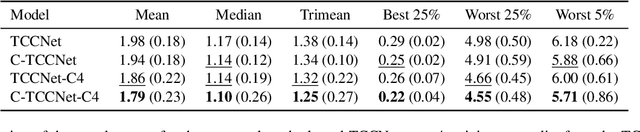
Computational Colour Constancy (CCC) consists of estimating the colour of one or more illuminants in a scene and using them to remove unwanted chromatic distortions. Much research has focused on illuminant estimation for CCC on single images, with few attempts of leveraging the temporal information intrinsic in sequences of correlated images (e.g., the frames in a video), a task known as Temporal Colour Constancy (TCC). The state-of-the-art for TCC is TCCNet, a deep-learning architecture that uses a ConvLSTM for aggregating the encodings produced by CNN submodules for each image in a sequence. We extend this architecture with different models obtained by (i) substituting the TCCNet submodules with C4, the state-of-the-art method for CCC targeting images; (ii) adding a cascading strategy to perform an iterative improvement of the estimate of the illuminant. We tested our models on the recently released TCC benchmark and achieved results that surpass the state-of-the-art. Analyzing the impact of the number of frames involved in illuminant estimation on performance, we show that it is possible to reduce inference time by training the models on few selected frames from the sequences while retaining comparable accuracy.