 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Using Deep Neural Network to Analyze Travel Mode Choice With Interpretable Economic Information: An Empirical Example
Dec 11, 2018
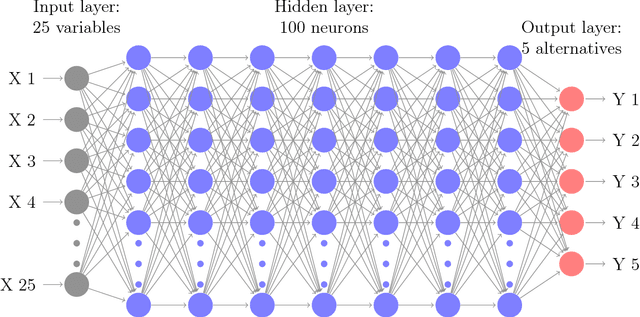

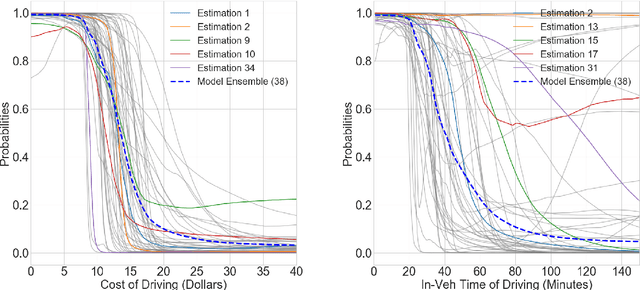
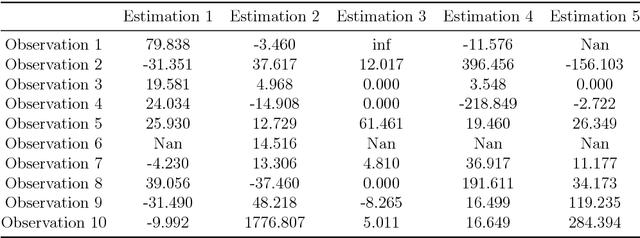
Deep neural network (DNN) has been increasingly applied to microscopic demand analysis. While DNN often outperforms traditional multinomial logit (MNL) model, it is unclear whether we can obtain interpretable economic information from DNN-based choice model beyond prediction accuracy. This paper provides an empirical method of numerically extracting valuable economic information such as choice probability, probability derivatives (or elasticities), and marginal rates of substitution. Using a survey collected in Singapore, we find that when the economic information is aggregated over population or models, DNN models can reveal roughly S-shaped choice probability curves, inverse bell-shaped driving probability derivatives regarding costs and time, and reasonable median value of time (VOT). However at the disaggregate level, choice probability curves of DNN models can be non-monotonically decreasing with costs and highly sensitive to the particular estimation; derivatives of choice probabilities regarding costs and time can be positive at some region; VOT can be infinite, undefined, zero, or arbitrarily large. Some of these patterns can be seen as counter-intuitive, while others can potentially be regarded as advantages of DNN for its flexibility to reflect certain behavior peculiarities. These patterns broadly relate to two theoretical challenges of DNN, irregularity of its probability space and large estimation errors. Overall, this study provides a practical guidance of using DNN for demand analysis with two suggestions: First, researchers can use numerical methods to obtain behaviorally intuitive choice probabilities, probability derivatives, and reasonable VOT. Second, given the large estimation errors and irregularity of the probability space of DNN, researchers should always ensemble either over population or individual models to obtain stable economic information.
BERT Embeddings Can Track Context in Conversational Search
Apr 13, 2021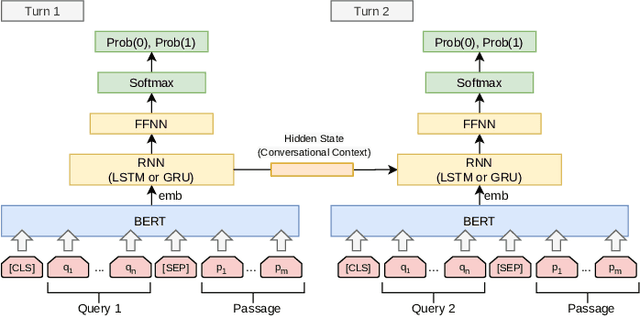
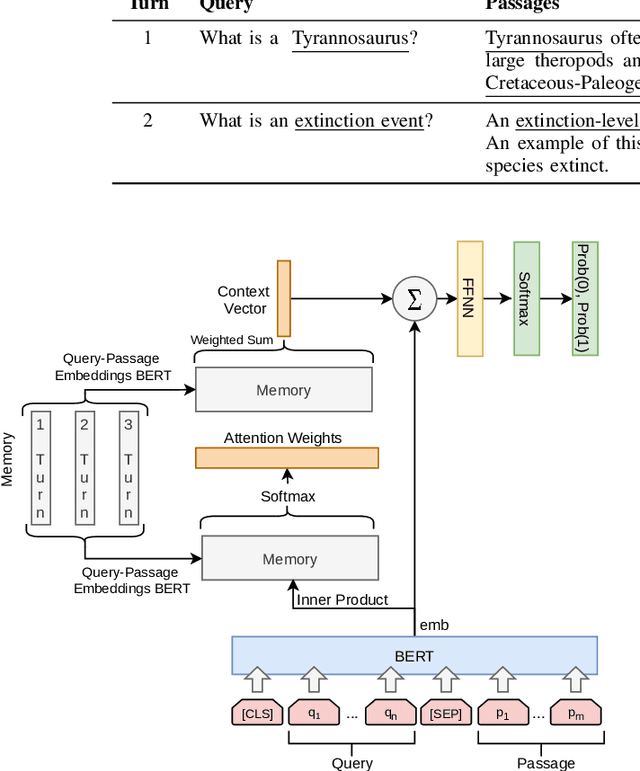
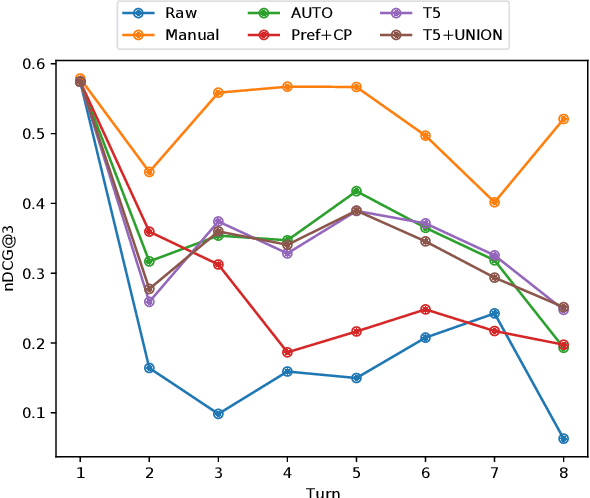
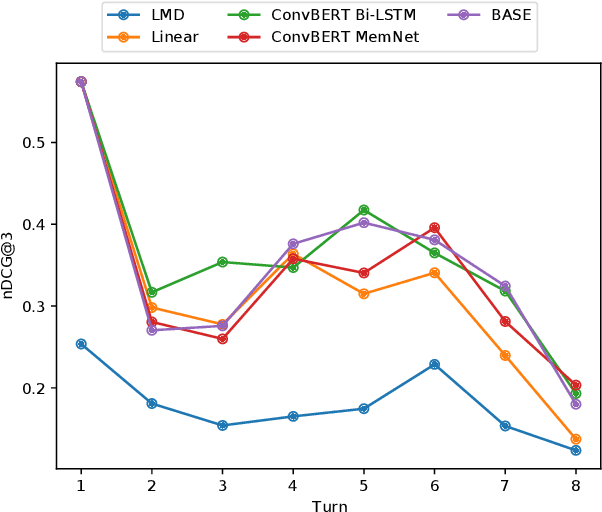
The use of conversational assistants to search for information is becoming increasingly more popular among the general public, pushing the research towards more advanced and sophisticated techniques. In the last few years, in particular, the interest in conversational search is increasing, not only because of the generalization of conversational assistants but also because conversational search is a step forward in allowing a more natural interaction with the system. In this work, the focus is on exploring the context present of the conversation via the historical utterances and respective embeddings with the aim of developing a conversational search system that helps people search for information in a natural way. In particular, this system must be able to understand the context where the question is posed, tracking the current state of the conversation and detecting mentions to previous questions and answers. We achieve this by using a context-tracking component based on neural query-rewriting models. Another crucial aspect of the system is to provide the most relevant answers given the question and the conversational history. To achieve this objective, we used a Transformer-based re-ranking method and expanded this architecture to use the conversational context. The results obtained with the system developed showed the advantages of using the context present in the natural language utterances and in the neural embeddings generated throughout the conversation.
A Microarchitecture Implementation Framework for Online Learning with Temporal Neural Networks
May 27, 2021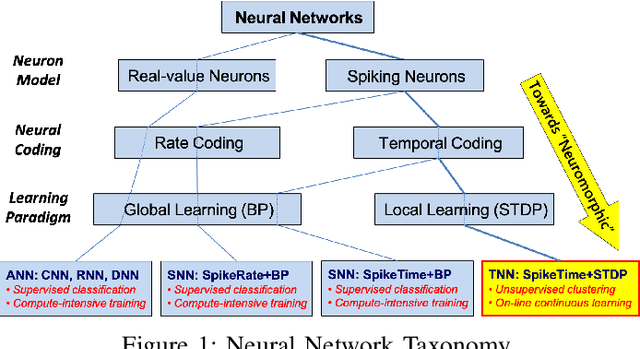

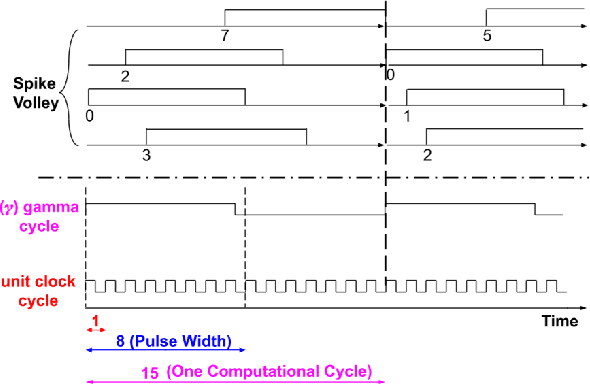
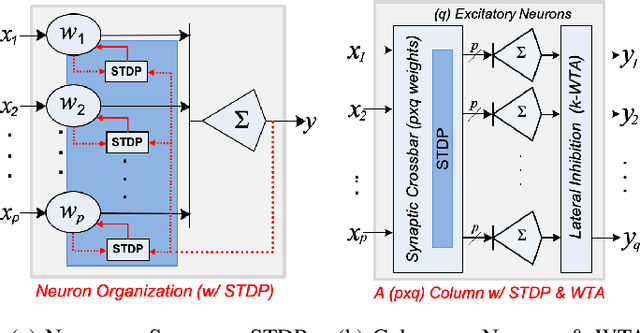
Temporal Neural Networks (TNNs) are spiking neural networks that use time as a resource to represent and process information, similar to the mammalian neocortex. In contrast to compute-intensive Deep Neural Networks that employ separate training and inference phases, TNNs are capable of extremely efficient online incremental/continuous learning and are excellent candidates for building edge-native sensory processing units. This work proposes a microarchitecture framework for implementing TNNs using standard CMOS. Gate-level implementations of three key building blocks are presented: 1) multi-synapse neurons, 2) multi-neuron columns, and 3) unsupervised and supervised online learning algorithms based on Spike Timing Dependent Plasticity (STDP). The TNN microarchitecture is embodied in a set of characteristic scaling equations for assessing the gate count, area, delay and power consumption for any TNN design. Post-synthesis results (in 45nm CMOS) for the proposed designs are presented, and their online incremental learning capability is demonstrated.
Represent Items by Items: An Enhanced Representation of the Target Item for Recommendation
Apr 26, 2021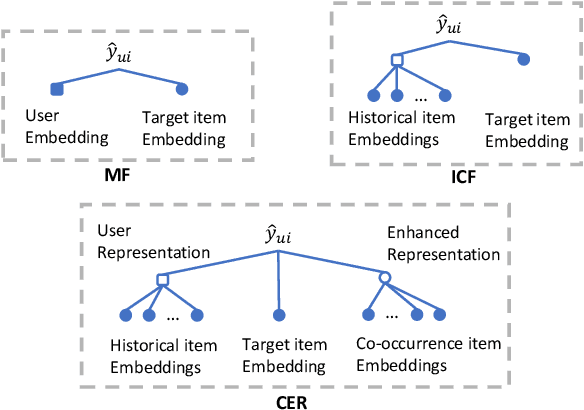

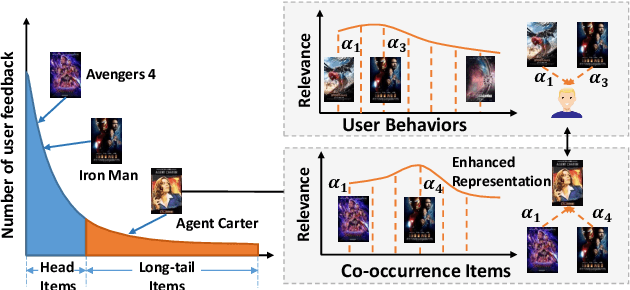
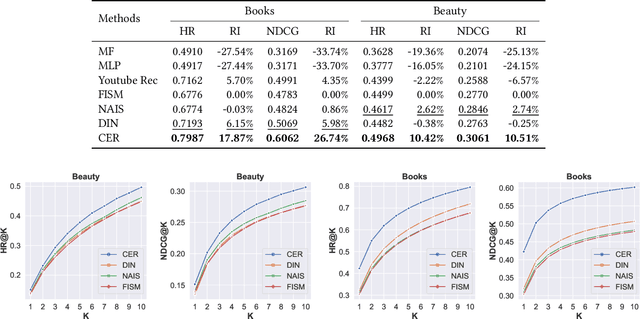
Item-based collaborative filtering (ICF) has been widely used in industrial applications such as recommender system and online advertising. It models users' preference on target items by the items they have interacted with. Recent models use methods such as attention mechanism and deep neural network to learn the user representation and scoring function more accurately. However, despite their effectiveness, such models still overlook a problem that performance of ICF methods heavily depends on the quality of item representation especially the target item representation. In fact, due to the long-tail distribution in the recommendation, most item embeddings can not represent the semantics of items accurately and thus degrade the performance of current ICF methods. In this paper, we propose an enhanced representation of the target item which distills relevant information from the co-occurrence items. We design sampling strategies to sample fix number of co-occurrence items for the sake of noise reduction and computational cost. Considering the different importance of sampled items to the target item, we apply attention mechanism to selectively adopt the semantic information of the sampled items. Our proposed Co-occurrence based Enhanced Representation model (CER) learns the scoring function by a deep neural network with the attentive user representation and fusion of raw representation and enhanced representation of target item as input. With the enhanced representation, CER has stronger representation power for the tail items compared to the state-of-the-art ICF methods. Extensive experiments on two public benchmarks demonstrate the effectiveness of CER.
SD-6DoF-ICLK: Sparse and Deep Inverse Compositional Lucas-Kanade Algorithm on SE(3)
Mar 30, 2021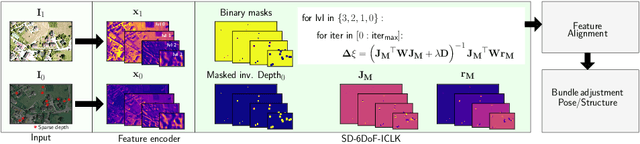
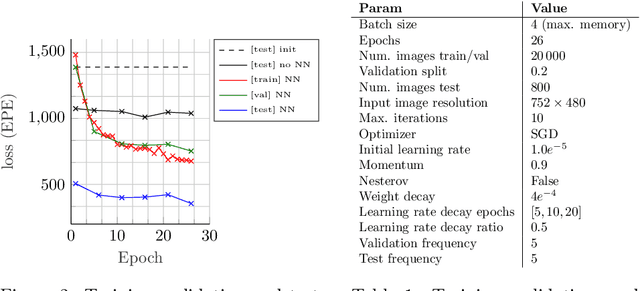


This paper introduces SD-6DoF-ICLK, a learning-based Inverse Compositional Lucas-Kanade (ICLK) pipeline that uses sparse depth information to optimize the relative pose that best aligns two images on SE(3). To compute this six Degrees-of-Freedom (DoF) relative transformation, the proposed formulation requires only sparse depth information in one of the images, which is often the only available depth source in visual-inertial odometry or Simultaneous Localization and Mapping (SLAM) pipelines. In an optional subsequent step, the framework further refines feature locations and the relative pose using individual feature alignment and bundle adjustment for pose and structure re-alignment. The resulting sparse point correspondences with subpixel-accuracy and refined relative pose can be used for depth map generation, or the image alignment module can be embedded in an odometry or mapping framework. Experiments with rendered imagery show that the forward SD-6DoF-ICLK runs at 145 ms per image pair with a resolution of 752 x 480 pixels each, and vastly outperforms the classical, sparse 6DoF-ICLK algorithm, making it the ideal framework for robust image alignment under severe conditions.
Text Summarization with Latent Queries
May 31, 2021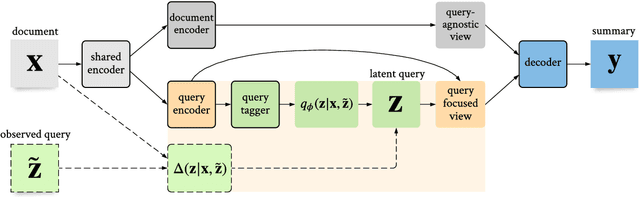


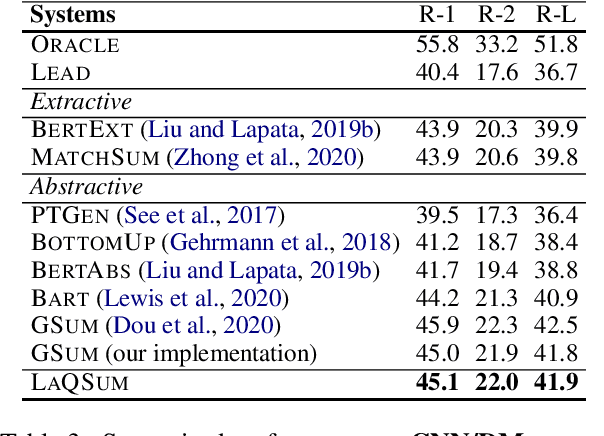
The availability of large-scale datasets has driven the development of neural models that create summaries from single documents, for generic purposes. When using a summarization system, users often have specific intents with various language realizations, which, depending on the information need, can range from a single keyword to a long narrative composed of multiple questions. Existing summarization systems, however, often either fail to support or act robustly on this query focused summarization task. We introduce LaQSum, the first unified text summarization system that learns Latent Queries from documents for abstractive summarization with any existing query forms. Under a deep generative framework, our system jointly optimizes a latent query model and a conditional language model, allowing users to plug-and-play queries of any type at test time. Despite learning from only generic summarization data and requiring no further optimization for downstream summarization tasks, our system robustly outperforms strong comparison systems across summarization benchmarks with different query types, document settings, and target domains.
Hierarchical Lovász Embeddings for Proposal-free Panoptic Segmentation
Jun 08, 2021
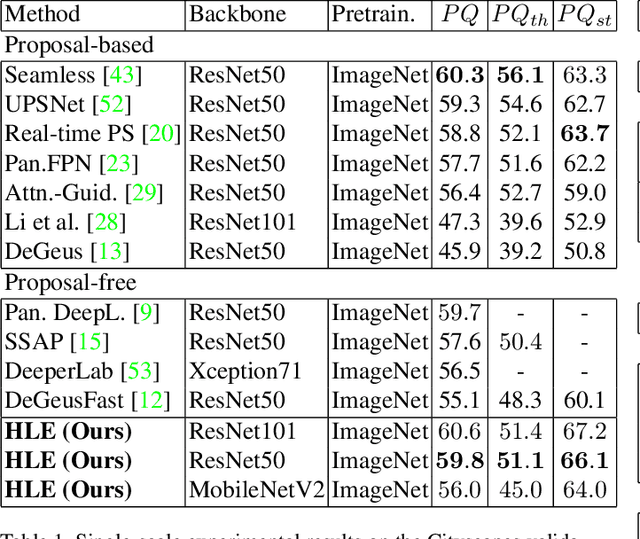
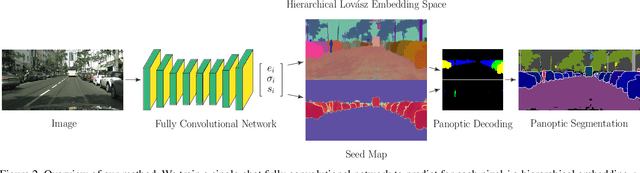

Panoptic segmentation brings together two separate tasks: instance and semantic segmentation. Although they are related, unifying them faces an apparent paradox: how to learn simultaneously instance-specific and category-specific (i.e. instance-agnostic) representations jointly. Hence, state-of-the-art panoptic segmentation methods use complex models with a distinct stream for each task. In contrast, we propose Hierarchical Lov\'asz Embeddings, per pixel feature vectors that simultaneously encode instance- and category-level discriminative information. We use a hierarchical Lov\'asz hinge loss to learn a low-dimensional embedding space structured into a unified semantic and instance hierarchy without requiring separate network branches or object proposals. Besides modeling instances precisely in a proposal-free manner, our Hierarchical Lov\'asz Embeddings generalize to categories by using a simple Nearest-Class-Mean classifier, including for non-instance "stuff" classes where instance segmentation methods are not applicable. Our simple model achieves state-of-the-art results compared to existing proposal-free panoptic segmentation methods on Cityscapes, COCO, and Mapillary Vistas. Furthermore, our model demonstrates temporal stability between video frames.
Retrieval-Free Knowledge-Grounded Dialogue Response Generation with Adapters
May 13, 2021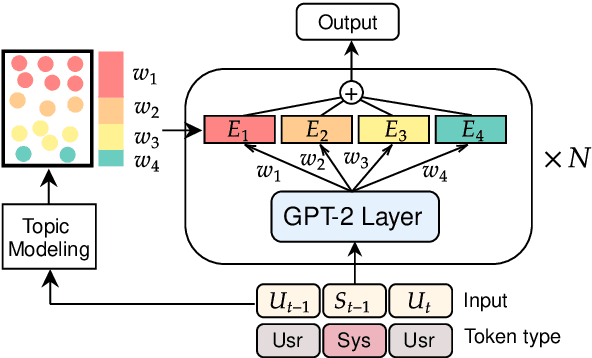
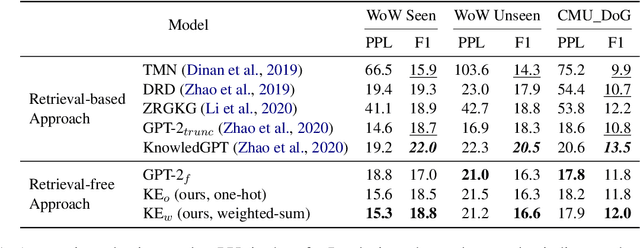
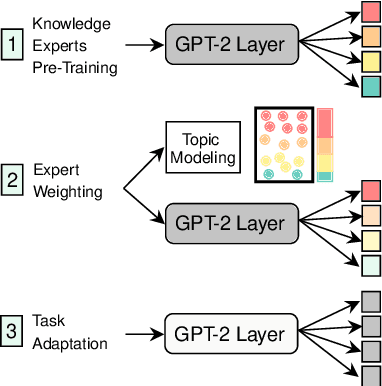

To diversify and enrich generated dialogue responses, knowledge-grounded dialogue has been investigated in recent years. Despite the success of the existing methods, they mainly follow the paradigm of retrieving the relevant sentences over a large corpus and augment the dialogues with explicit extra information, which is time- and resource-consuming. In this paper, we propose KnowExpert, an end-to-end framework to bypass the retrieval process by injecting prior knowledge into the pre-trained language models with lightweight adapters. To the best of our knowledge, this is the first attempt to tackle this task relying solely on a generation-based approach. Experimental results show that KnowExpert performs comparably with the retrieval-based baselines, demonstrating the potential of our proposed direction.
RF PIX2PIX Unsupervised Wi-Fi to Video Translation
Feb 14, 2021

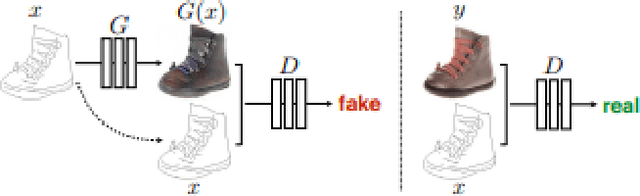
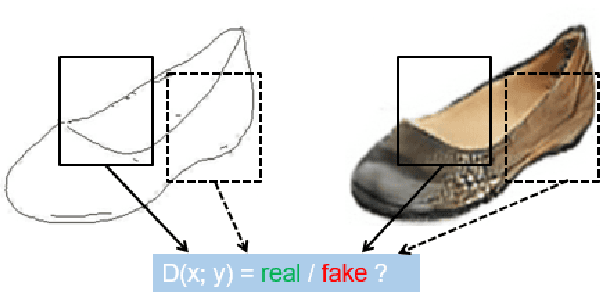
With the proliferation of Wi-Fi devices in the environment, our surroundings are increasingly illuminated with low-level RF scatter. This scatter illuminates objects in the environment much like radar or LIDAR. We show that a novel unsupervised network, based on the PIX2PIX GAN architecture, can recover and visually reconstruct scene information solely from Wi-Fi background energy; in contrast to a significantly less accurate approach by Kefayati (et. all) which requires careful object labeling to recover object location from a scene. This is accomplished by learning a more robust mapping function between the channel state information (CSI) from Wi-Fi packets and Video image sample distributions.
Learning from Perturbations: Diverse and Informative Dialogue Generation with Inverse Adversarial Training
May 31, 2021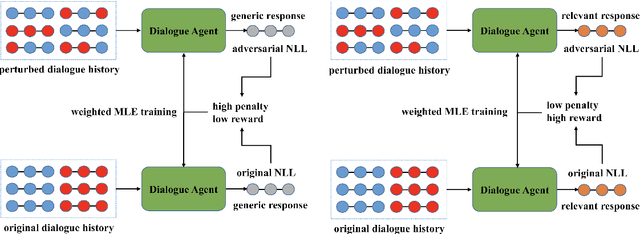
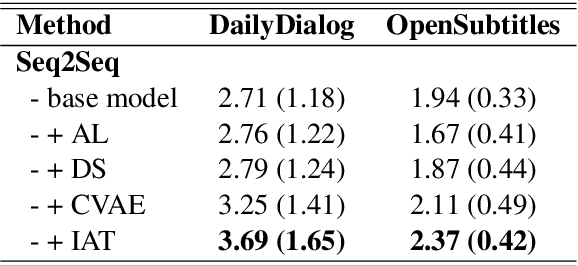
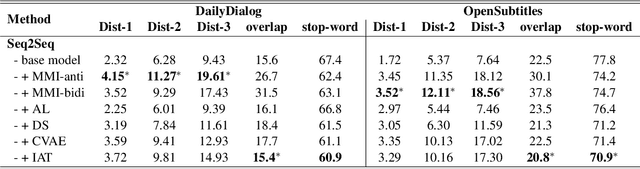
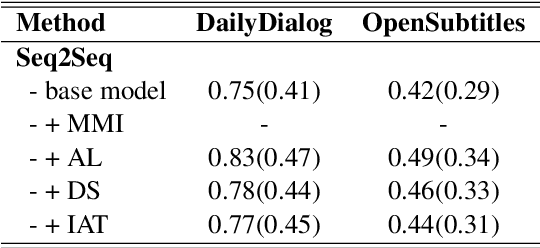
In this paper, we propose Inverse Adversarial Training (IAT) algorithm for training neural dialogue systems to avoid generic responses and model dialogue history better. In contrast to standard adversarial training algorithms, IAT encourages the model to be sensitive to the perturbation in the dialogue history and therefore learning from perturbations. By giving higher rewards for responses whose output probability reduces more significantly when dialogue history is perturbed, the model is encouraged to generate more diverse and consistent responses. By penalizing the model when generating the same response given perturbed dialogue history, the model is forced to better capture dialogue history and generate more informative responses. Experimental results on two benchmark datasets show that our approach can better model dialogue history and generate more diverse and consistent responses. In addition, we point out a problem of the widely used maximum mutual information (MMI) based methods for improving the diversity of dialogue response generation models and demonstrate it empirically.