 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Open Information Extraction
Jul 10, 2016
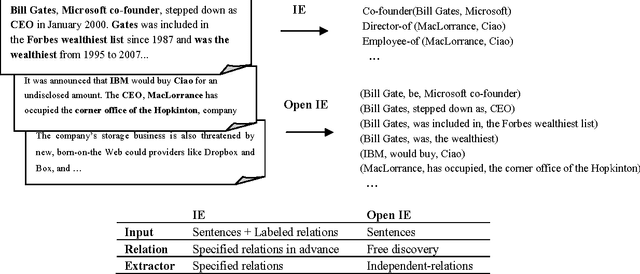
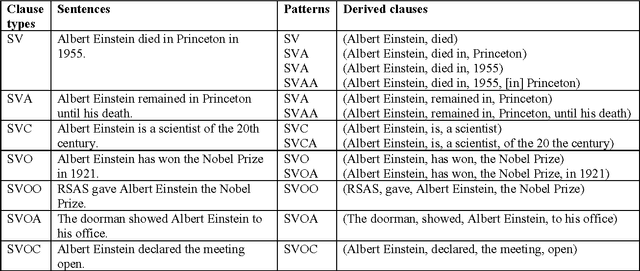
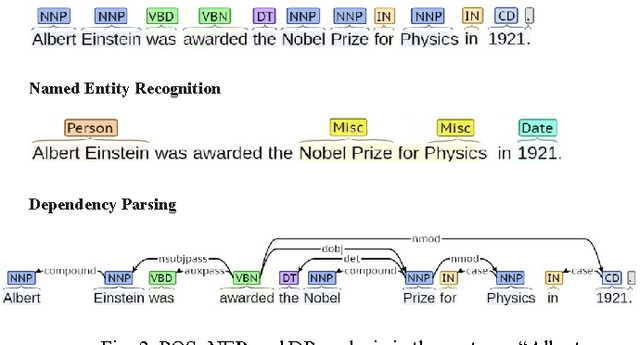
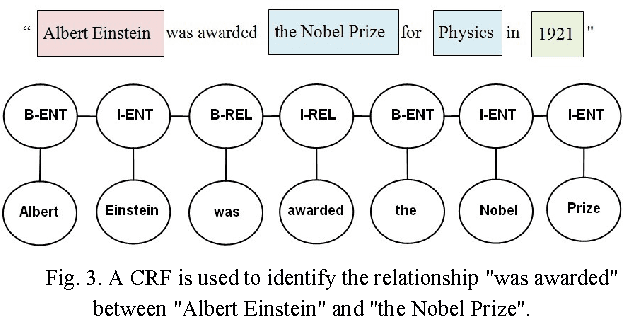
Open Information Extraction (Open IE) systems aim to obtain relation tuples with highly scalable extraction in portable across domain by identifying a variety of relation phrases and their arguments in arbitrary sentences. The first generation of Open IE learns linear chain models based on unlexicalized features such as Part-of-Speech (POS) or shallow tags to label the intermediate words between pair of potential arguments for identifying extractable relations. Open IE currently is developed in the second generation that is able to extract instances of the most frequently observed relation types such as Verb, Noun and Prep, Verb and Prep, and Infinitive with deep linguistic analysis. They expose simple yet principled ways in which verbs express relationships in linguistics such as verb phrase-based extraction or clause-based extraction. They obtain a significantly higher performance over previous systems in the first generation. In this paper, we describe an overview of two Open IE generations including strengths, weaknesses and application areas.
Streaming Belief Propagation for Community Detection
Jun 09, 2021

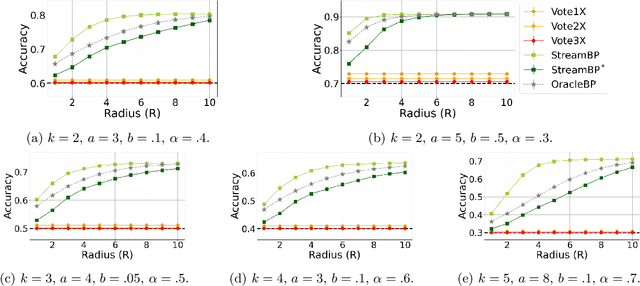
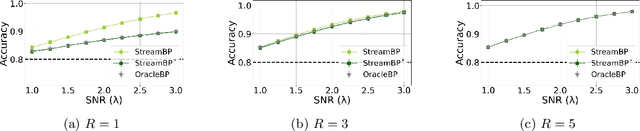
The community detection problem requires to cluster the nodes of a network into a small number of well-connected "communities". There has been substantial recent progress in characterizing the fundamental statistical limits of community detection under simple stochastic block models. However, in real-world applications, the network structure is typically dynamic, with nodes that join over time. In this setting, we would like a detection algorithm to perform only a limited number of updates at each node arrival. While standard voting approaches satisfy this constraint, it is unclear whether they exploit the network information optimally. We introduce a simple model for networks growing over time which we refer to as streaming stochastic block model (StSBM). Within this model, we prove that voting algorithms have fundamental limitations. We also develop a streaming belief-propagation (StreamBP) approach, for which we prove optimality in certain regimes. We validate our theoretical findings on synthetic and real data.
Harnessing Heterogeneity: Learning from Decomposed Feedback in Bayesian Modeling
Jul 07, 2021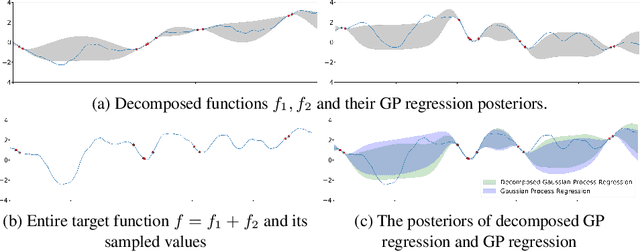

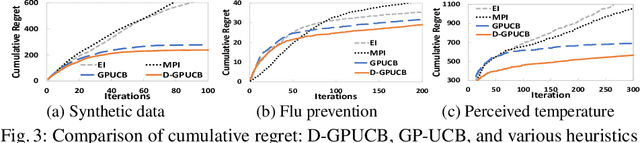

There is significant interest in learning and optimizing a complex system composed of multiple sub-components, where these components may be agents or autonomous sensors. Among the rich literature on this topic, agent-based and domain-specific simulations can capture complex dynamics and subgroup interaction, but optimizing over such simulations can be computationally and algorithmically challenging. Bayesian approaches, such as Gaussian processes (GPs), can be used to learn a computationally tractable approximation to the underlying dynamics but typically neglect the detailed information about subgroups in the complicated system. We attempt to find the best of both worlds by proposing the idea of decomposed feedback, which captures group-based heterogeneity and dynamics. We introduce a novel decomposed GP regression to incorporate the subgroup decomposed feedback. Our modified regression has provably lower variance -- and thus a more accurate posterior -- compared to previous approaches; it also allows us to introduce a decomposed GP-UCB optimization algorithm that leverages subgroup feedback. The Bayesian nature of our method makes the optimization algorithm trackable with a theoretical guarantee on convergence and no-regret property. To demonstrate the wide applicability of this work, we execute our algorithm on two disparate social problems: infectious disease control in a heterogeneous population and allocation of distributed weather sensors. Experimental results show that our new method provides significant improvement compared to the state-of-the-art.
Efficient Human Pose Estimation by Learning Deeply Aggregated Representations
Dec 15, 2020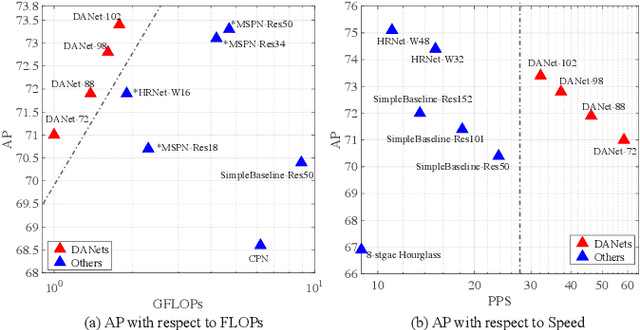
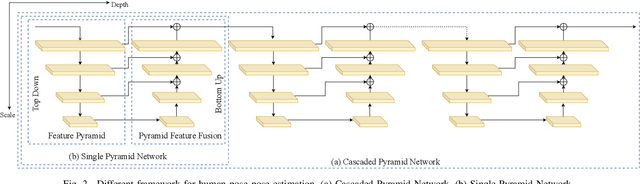
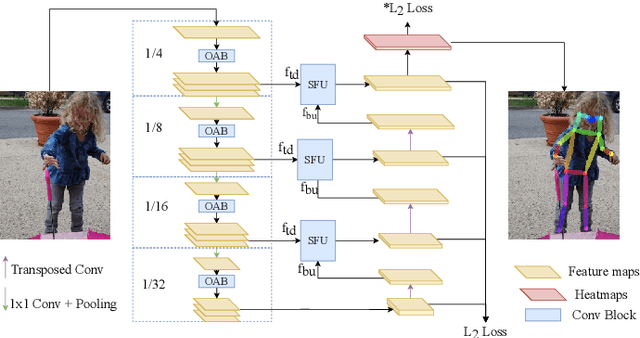
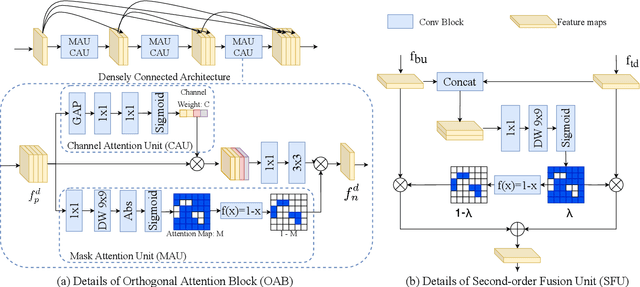
In this paper, we propose an efficient human pose estimation network (DANet) by learning deeply aggregated representations. Most existing models explore multi-scale information mainly from features with different spatial sizes. Powerful multi-scale representations usually rely on the cascaded pyramid framework. This framework largely boosts the performance but in the meanwhile makes networks very deep and complex. Instead, we focus on exploiting multi-scale information from layers with different receptive-field sizes and then making full of use this information by improving the fusion method. Specifically, we propose an orthogonal attention block (OAB) and a second-order fusion unit (SFU). The OAB learns multi-scale information from different layers and enhances them by encouraging them to be diverse. The SFU adaptively selects and fuses diverse multi-scale information and suppress the redundant ones. This could maximize the effective information in final fused representations. With the help of OAB and SFU, our single pyramid network may be able to generate deeply aggregated representations that contain even richer multi-scale information and have a larger representing capacity than that of cascaded networks. Thus, our networks could achieve comparable or even better accuracy with much smaller model complexity. Specifically, our \mbox{DANet-72} achieves $70.5$ in AP score on COCO test-dev set with only $1.0G$ FLOPs. Its speed on a CPU platform achieves $58$ Persons-Per-Second~(PPS).
Dynamic Weighted Learning for Unsupervised Domain Adaptation
Mar 22, 2021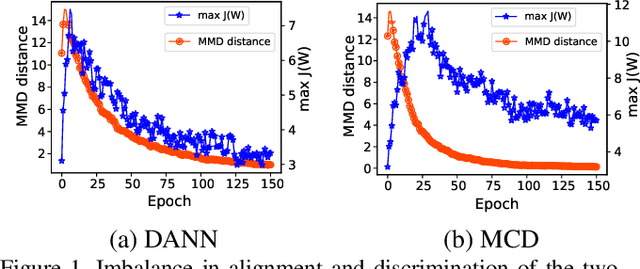

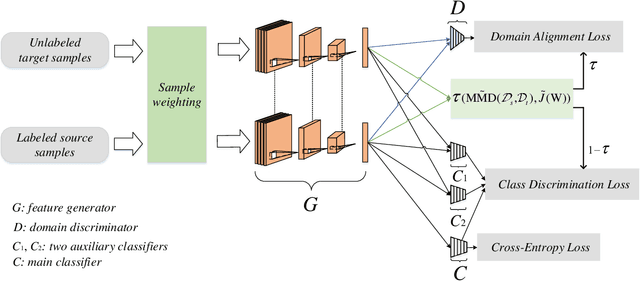
Unsupervised domain adaptation (UDA) aims to improve the classification performance on an unlabeled target domain by leveraging information from a fully labeled source domain. Recent approaches explore domain-invariant and class-discriminant representations to tackle this task. These methods, however, ignore the interaction between domain alignment learning and class discrimination learning. As a result, the missing or inadequate tradeoff between domain alignment and class discrimination are prone to the problem of negative transfer. In this paper, we propose Dynamic Weighted Learning (DWL) to avoid the discriminability vanishing problem caused by excessive alignment learning and domain misalignment problem caused by excessive discriminant learning. Technically, DWL dynamically weights the learning losses of alignment and discriminability by introducing the degree of alignment and discriminability. Besides, the problem of sample imbalance across domains is first considered in our work, and we solve the problem by weighing the samples to guarantee information balance across domains. Extensive experiments demonstrate that DWL has an excellent performance in several benchmark datasets.
Towards an Online Empathetic Chatbot with Emotion Causes
May 11, 2021
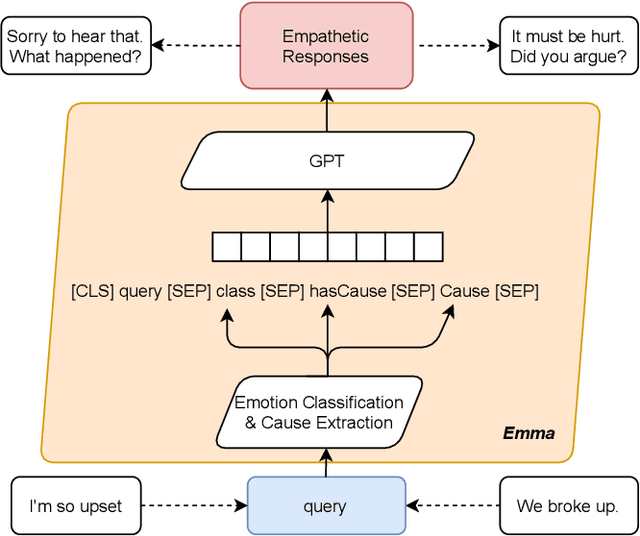

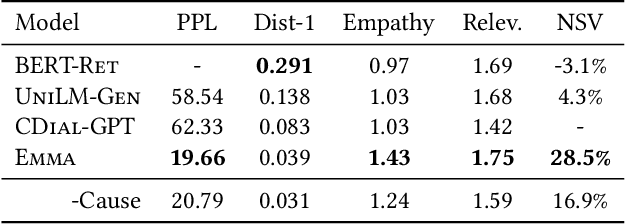
Existing emotion-aware conversational models usually focus on controlling the response contents to align with a specific emotion class, whereas empathy is the ability to understand and concern the feelings and experience of others. Hence, it is critical to learn the causes that evoke the users' emotion for empathetic responding, a.k.a. emotion causes. To gather emotion causes in online environments, we leverage counseling strategies and develop an empathetic chatbot to utilize the causal emotion information. On a real-world online dataset, we verify the effectiveness of the proposed approach by comparing our chatbot with several SOTA methods using automatic metrics, expert-based human judgements as well as user-based online evaluation.
Amortized Auto-Tuning: Cost-Efficient Transfer Optimization for Hyperparameter Recommendation
Jun 17, 2021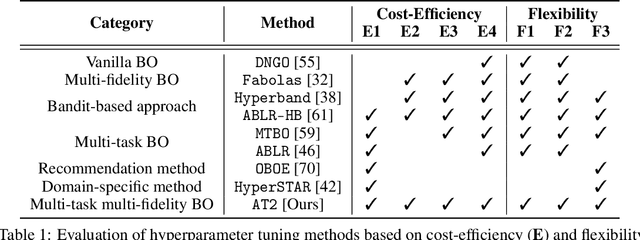
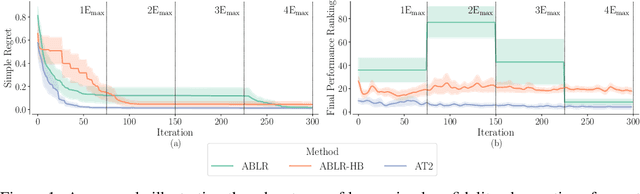
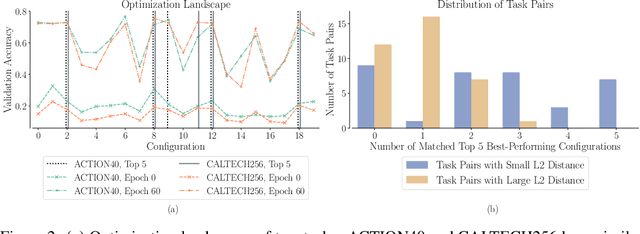

With the surge in the number of hyperparameters and training times of modern machine learning models, hyperparameter tuning is becoming increasingly expensive. Although methods have been proposed to speed up tuning via knowledge transfer, they typically require the final performance of hyperparameters and do not focus on low-fidelity information. Nevertheless, this common practice is suboptimal and can incur an unnecessary use of resources. It is more cost-efficient to instead leverage the low-fidelity tuning observations to measure inter-task similarity and transfer knowledge from existing to new tasks accordingly. However, performing multi-fidelity tuning comes with its own challenges in the transfer setting: the noise in the additional observations and the need for performance forecasting. Therefore, we conduct a thorough analysis of the multi-task multi-fidelity Bayesian optimization framework, which leads to the best instantiation--amortized auto-tuning (AT2). We further present an offline-computed 27-task hyperparameter recommendation (HyperRec) database to serve the community. Extensive experiments on HyperRec and other real-world databases illustrate the effectiveness of our AT2 method.
Bayesian reconstruction of memories stored in neural networks from their connectivity
May 16, 2021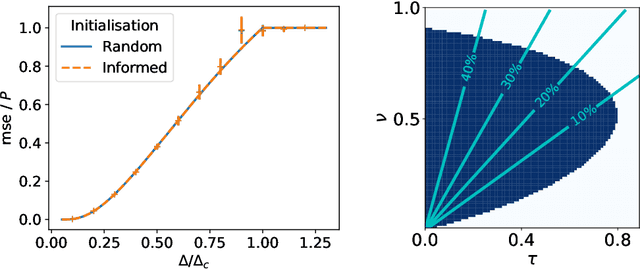
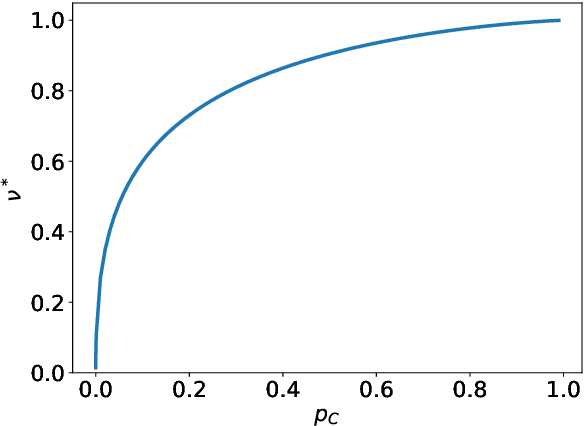
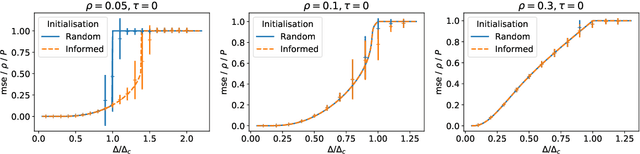
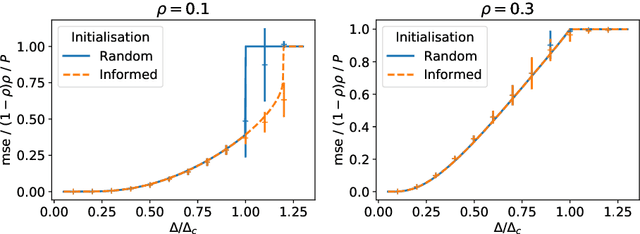
The advent of comprehensive synaptic wiring diagrams of large neural circuits has created the field of connectomics and given rise to a number of open research questions. One such question is whether it is possible to reconstruct the information stored in a recurrent network of neurons, given its synaptic connectivity matrix. Here, we address this question by determining when solving such an inference problem is theoretically possible in specific attractor network models and by providing a practical algorithm to do so. The algorithm builds on ideas from statistical physics to perform approximate Bayesian inference and is amenable to exact analysis. We study its performance on three different models and explore the limitations of reconstructing stored patterns from synaptic connectivity.
Intelligent Zero Trust Architecture for 5G/6G Tactical Networks: Principles, Challenges, and the Role of Machine Learning
May 04, 2021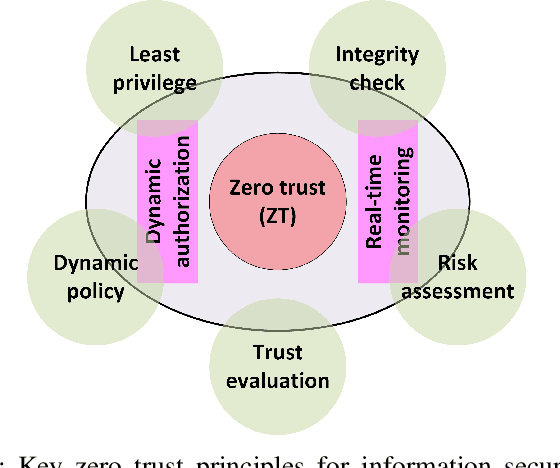
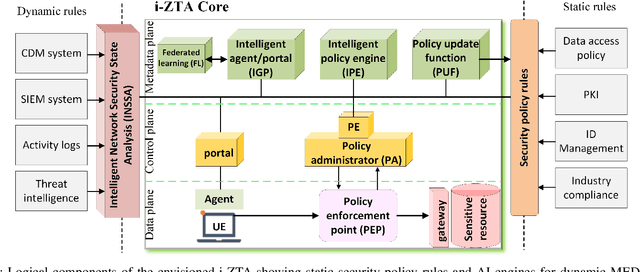
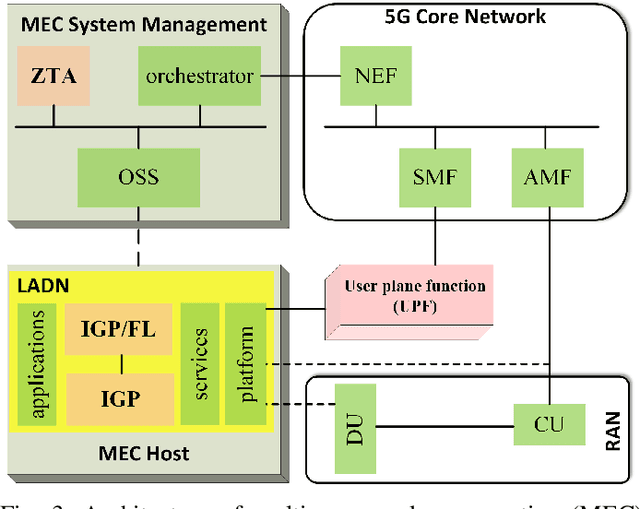
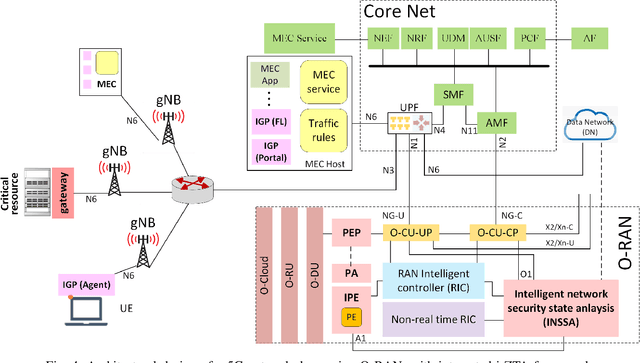
In this position paper, we discuss the critical need for integrating zero trust (ZT) principles into next-generation communication networks (5G/6G) for both tactical and commercial applications. We highlight the challenges and introduce the concept of an intelligent zero trust architecture (i-ZTA) as a security framework in 5G/6G networks with untrusted components. While network virtualization, software-defined networking (SDN), and service-based architectures (SBA) are key enablers of 5G networks, operating in an untrusted environment has also become a key feature of the networks. Further, seamless connectivity to a high volume of devices in multi-radio access technology (RAT) has broadened the attack surface on information infrastructure. Network assurance in a dynamic untrusted environment calls for revolutionary architectures beyond existing static security frameworks. This paper presents the architectural design of an i-ZTA upon which modern artificial intelligence (AI) algorithms can be developed to provide information security in untrusted networks. We introduce key ZT principles as real-time Monitoring of the security state of network assets, Evaluating the risk of individual access requests, and Deciding on access authorization using a dynamic trust algorithm, called MED components. The envisioned architecture adopts an SBA-based design, similar to the 3GPP specification of 5G networks, by leveraging the open radio access network (O-RAN) architecture with appropriate real-time engines and network interfaces for collecting necessary machine learning data. The i-ZTA is also expected to exploit the multi-access edge computing (MEC) technology of 5G as a key enabler of intelligent MED components for resource-constraint devices.
Boundary-Aware 3D Object Detection from Point Clouds
May 04, 2021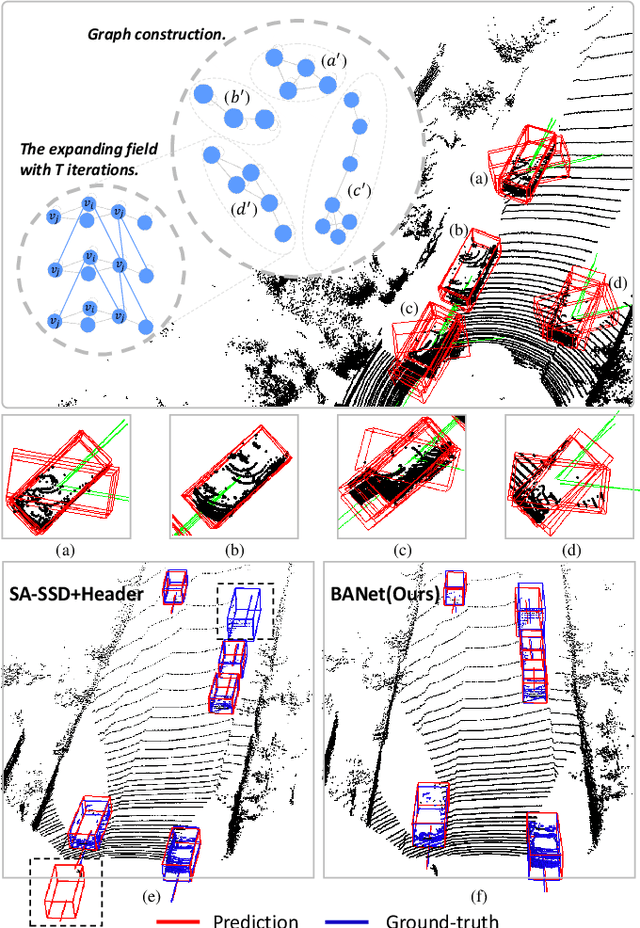
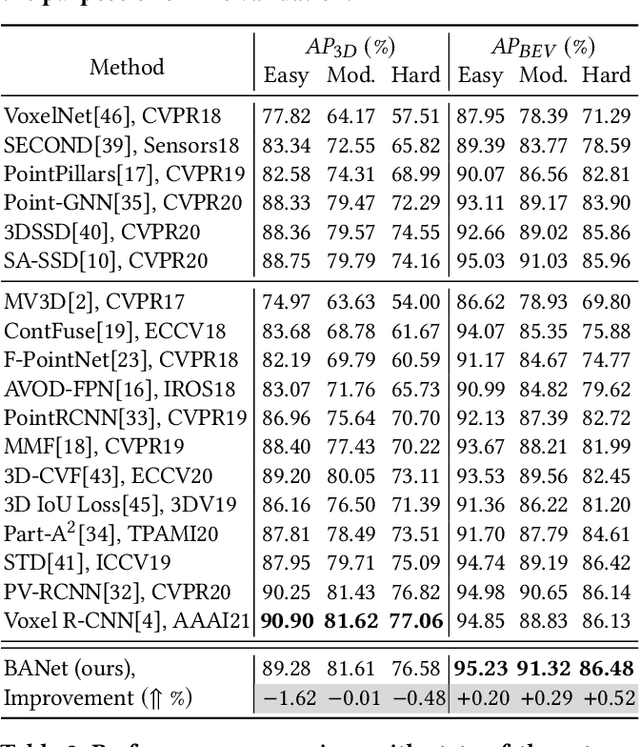
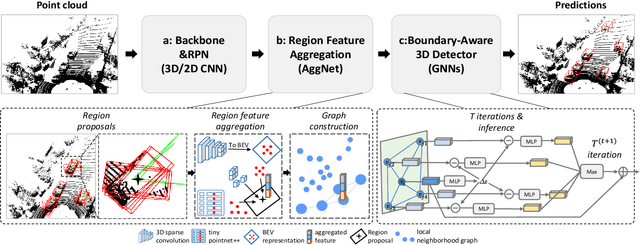
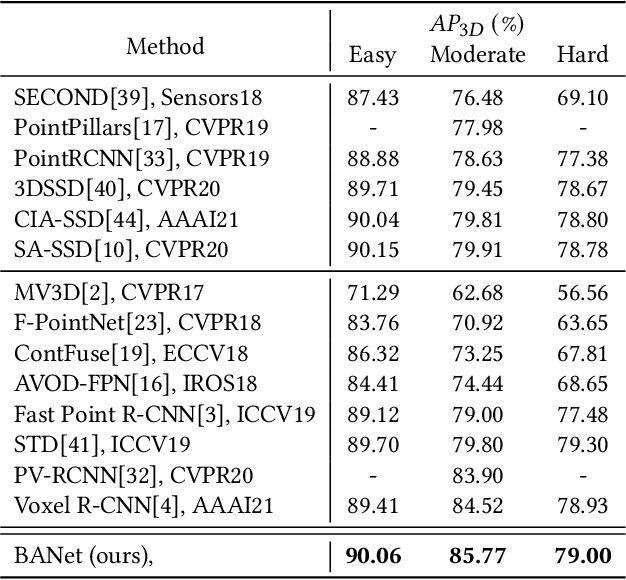
Currently, existing state-of-the-art 3D object detectors are in two-stage paradigm. These methods typically comprise two steps: 1) Utilize region proposal network to propose a fraction of high-quality proposals in a bottom-up fashion. 2) Resize and pool the semantic features from the proposed regions to summarize RoI-wise representations for further refinement. Note that these RoI-wise representations in step 2) are considered individually as an uncorrelated entry when fed to following detection headers. Nevertheless, we observe these proposals generated by step 1) offset from ground truth somehow, emerging in local neighborhood densely with an underlying probability. Challenges arise in the case where a proposal largely forsakes its boundary information due to coordinate offset while existing networks lack corresponding information compensation mechanism. In this paper, we propose BANet for 3D object detection from point clouds. Specifically, instead of refining each proposal independently as previous works do, we represent each proposal as a node for graph construction within a given cut-off threshold, associating proposals in the form of local neighborhood graph, with boundary correlations of an object being explicitly exploited. Besides, we devise a lightweight Region Feature Aggregation Network to fully exploit voxel-wise, pixel-wise, and point-wise feature with expanding receptive fields for more informative RoI-wise representations. As of Apr. 17th, 2021, our BANet achieves on par performance on KITTI 3D detection leaderboard and ranks $1^{st}$ on $Moderate$ difficulty of $Car$ category on KITTI BEV detection leaderboard. The source code will be released once the paper is accepted.