 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Language and Multimodal Privacy-Preserving Markers of Mood from Mobile Data
Jun 24, 2021
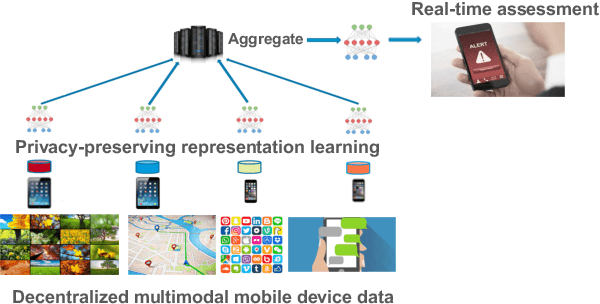
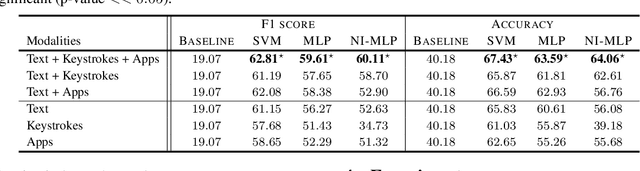
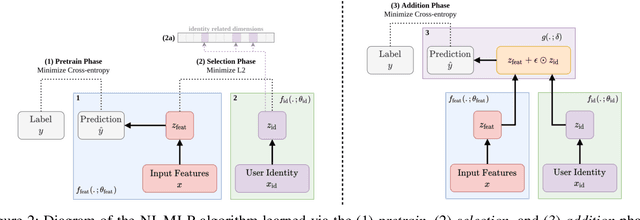
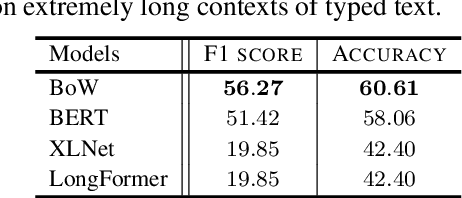
Mental health conditions remain underdiagnosed even in countries with common access to advanced medical care. The ability to accurately and efficiently predict mood from easily collectible data has several important implications for the early detection, intervention, and treatment of mental health disorders. One promising data source to help monitor human behavior is daily smartphone usage. However, care must be taken to summarize behaviors without identifying the user through personal (e.g., personally identifiable information) or protected (e.g., race, gender) attributes. In this paper, we study behavioral markers of daily mood using a recent dataset of mobile behaviors from adolescent populations at high risk of suicidal behaviors. Using computational models, we find that language and multimodal representations of mobile typed text (spanning typed characters, words, keystroke timings, and app usage) are predictive of daily mood. However, we find that models trained to predict mood often also capture private user identities in their intermediate representations. To tackle this problem, we evaluate approaches that obfuscate user identity while remaining predictive. By combining multimodal representations with privacy-preserving learning, we are able to push forward the performance-privacy frontier.
Hierarchical Semantic Segmentation using Psychometric Learning
Jul 07, 2021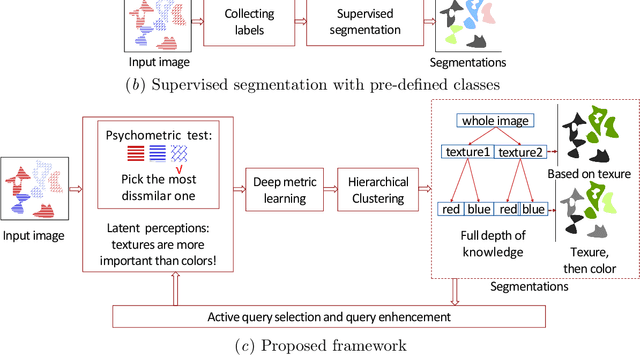


Assigning meaning to parts of image data is the goal of semantic image segmentation. Machine learning methods, specifically supervised learning is commonly used in a variety of tasks formulated as semantic segmentation. One of the major challenges in the supervised learning approaches is expressing and collecting the rich knowledge that experts have with respect to the meaning present in the image data. Towards this, typically a fixed set of labels is specified and experts are tasked with annotating the pixels, patches or segments in the images with the given labels. In general, however, the set of classes does not fully capture the rich semantic information present in the images. For example, in medical imaging such as histology images, the different parts of cells could be grouped and sub-grouped based on the expertise of the pathologist. To achieve such a precise semantic representation of the concepts in the image, we need access to the full depth of knowledge of the annotator. In this work, we develop a novel approach to collect segmentation annotations from experts based on psychometric testing. Our method consists of the psychometric testing procedure, active query selection, query enhancement, and a deep metric learning model to achieve a patch-level image embedding that allows for semantic segmentation of images. We show the merits of our method with evaluation on the synthetically generated image, aerial image and histology image.
MIxBN: library for learning Bayesian networks from mixed data
Jun 24, 2021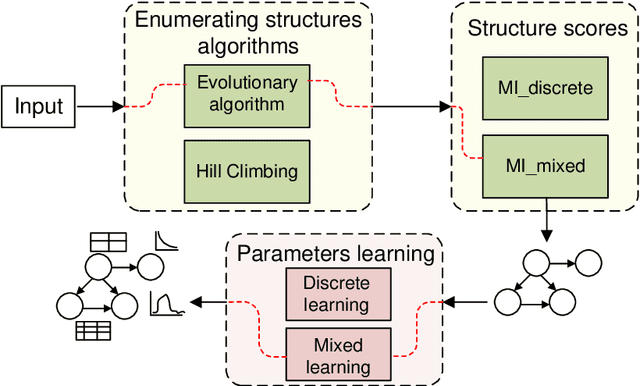
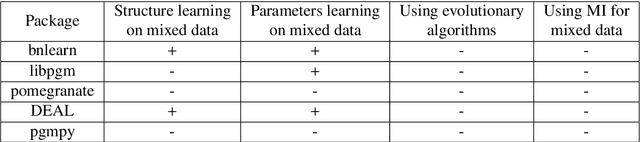


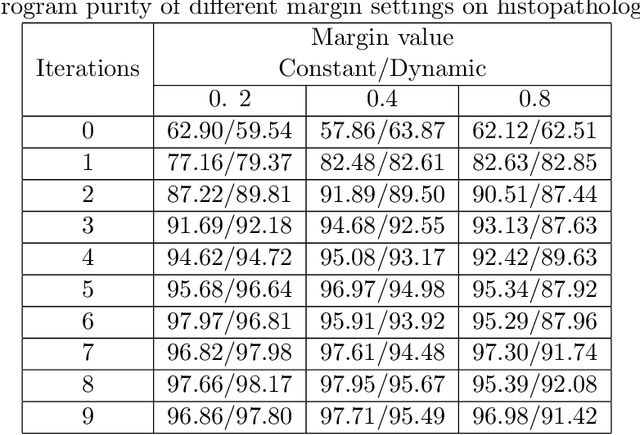
This paper describes a new library for learning Bayesian networks from data containing discrete and continuous variables (mixed data). In addition to the classical learning methods on discretized data, this library proposes its algorithm that allows structural learning and parameters learning from mixed data without discretization since data discretization leads to information loss. This algorithm based on mixed MI score function for structural learning, and also linear regression and Gaussian distribution approximation for parameters learning. The library also offers two algorithms for enumerating graph structures - the greedy Hill-Climbing algorithm and the evolutionary algorithm. Thus the key capabilities of the proposed library are as follows: (1) structural and parameters learning of a Bayesian network on discretized data, (2) structural and parameters learning of a Bayesian network on mixed data using the MI mixed score function and Gaussian approximation, (3) launching learning algorithms on one of two algorithms for enumerating graph structures - Hill-Climbing and the evolutionary algorithm. Since the need for mixed data representation comes from practical necessity, the advantages of our implementations are evaluated in the context of solving approximation and gap recovery problems on synthetic data and real datasets.
Learning and Generalization in RNNs
May 31, 2021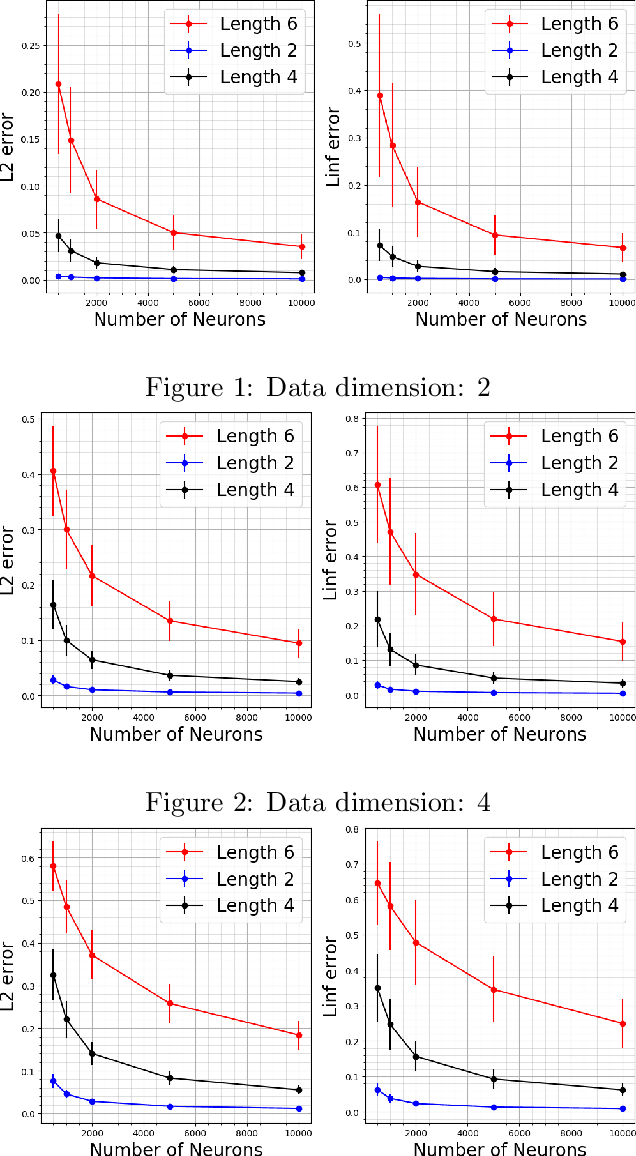
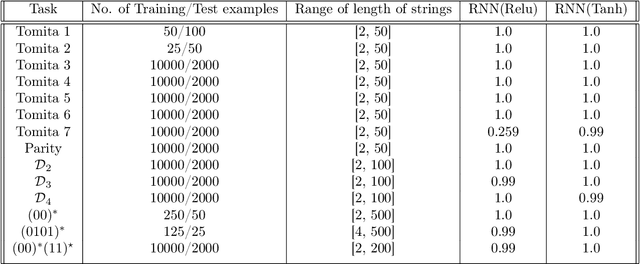
Simple recurrent neural networks (RNNs) and their more advanced cousins LSTMs etc. have been very successful in sequence modeling. Their theoretical understanding, however, is lacking and has not kept pace with the progress for feedforward networks, where a reasonably complete understanding in the special case of highly overparametrized one-hidden-layer networks has emerged. In this paper, we make progress towards remedying this situation by proving that RNNs can learn functions of sequences. In contrast to the previous work that could only deal with functions of sequences that are sums of functions of individual tokens in the sequence, we allow general functions. Conceptually and technically, we introduce new ideas which enable us to extract information from the hidden state of the RNN in our proofs -- addressing a crucial weakness in previous work. We illustrate our results on some regular language recognition problems.
Day-to-day and seasonal regularity of network passenger delay for metro networks
Jul 07, 2021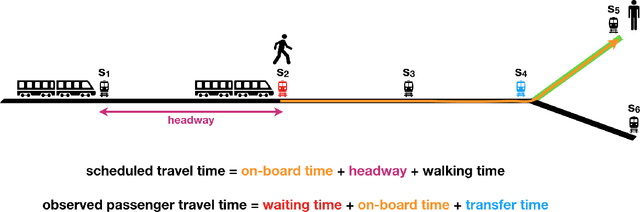
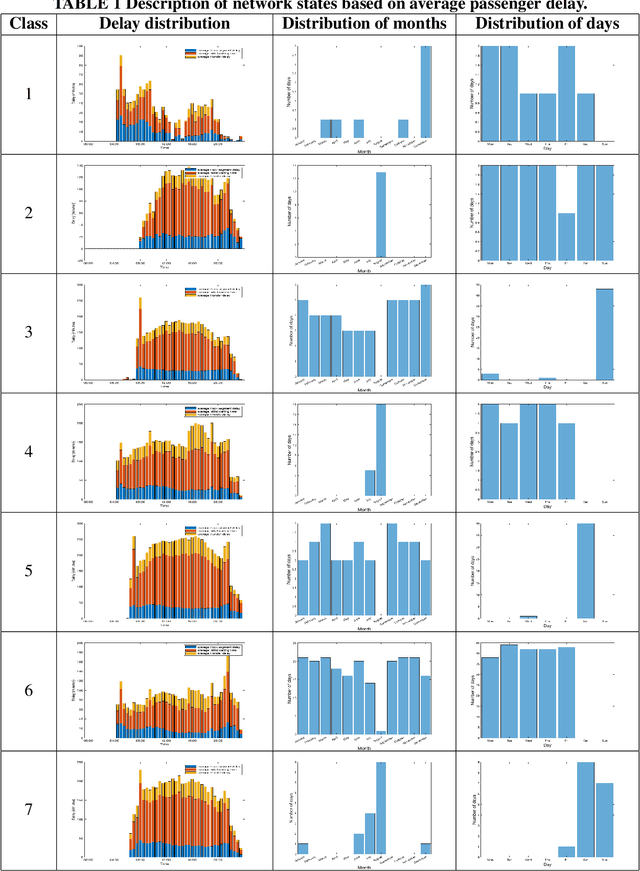
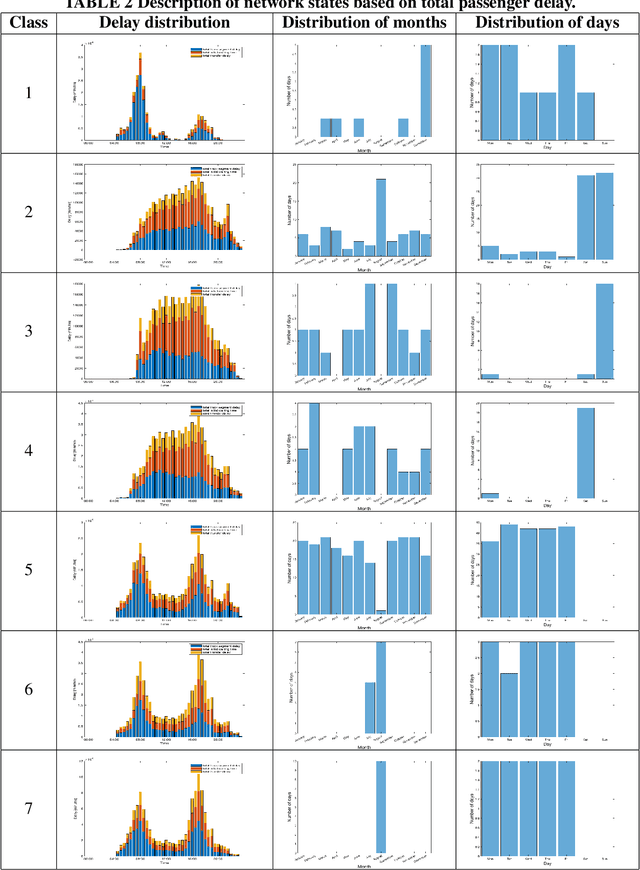
In an effort to improve user satisfaction and transit image, transit service providers worldwide offer delay compensations. Smart card data enables the estimation of passenger delays throughout the network and aid in monitoring service performance. Notwithstanding, in order to prioritize measures for improving service reliability and hence reducing passenger delays, it is paramount to identify the system components - stations and track segments - where most passenger delay occurs. To this end, we propose a novel method for estimating network passenger delay from individual trajectories. We decompose the delay along a passenger trajectory into its corresponding track segment delay, initial waiting time and transfer delay. We distinguish between two different types of passenger delay in relation to the public transit network: average passenger delay and total passenger delay. We employ temporal clustering on these two quantities to reveal daily and seasonal regularity in delay patterns of the transit network. The estimation and clustering methods are demonstrated on one year of data from Washington metro network. The data consists of schedule information and smart card data which includes passenger-train assignment of the metro network for the months of August 2017 to August 2018. Our findings show that the average passenger delay is relatively stable throughout the day. The temporal clustering reveals pronounced and recurrent and thus predictable daily and weekly patterns with distinct characteristics for certain months.
Generative Adversarial Networks (GAN) Powered Fast Magnetic Resonance Imaging -- Mini Review, Comparison and Perspectives
May 04, 2021
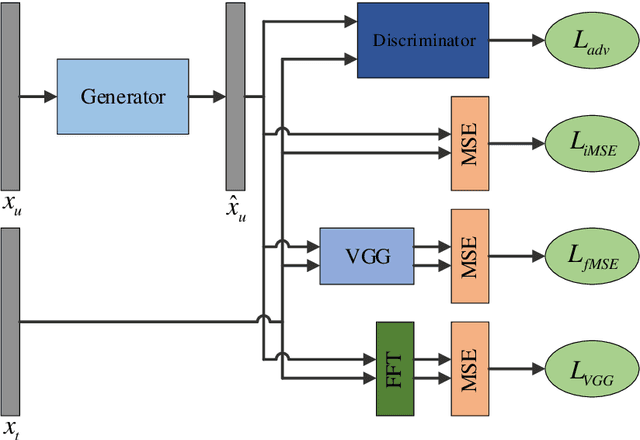
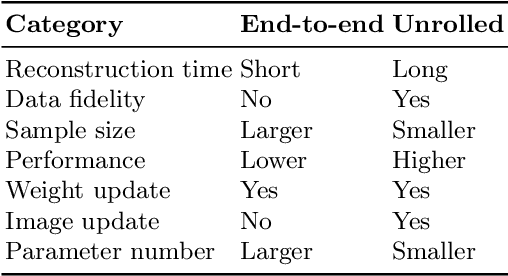
Magnetic Resonance Imaging (MRI) is a vital component of medical imaging. When compared to other image modalities, it has advantages such as the absence of radiation, superior soft tissue contrast, and complementary multiple sequence information. However, one drawback of MRI is its comparatively slow scanning and reconstruction compared to other image modalities, limiting its usage in some clinical applications when imaging time is critical. Traditional compressive sensing based MRI (CS-MRI) reconstruction can speed up MRI acquisition, but suffers from a long iterative process and noise-induced artefacts. Recently, Deep Neural Networks (DNNs) have been used in sparse MRI reconstruction models to recreate relatively high-quality images from heavily undersampled k-space data, allowing for much faster MRI scanning. However, there are still some hurdles to tackle. For example, directly training DNNs based on L1/L2 distance to the target fully sampled images could result in blurry reconstruction because L1/L2 loss can only enforce overall image or patch similarity and does not take into account local information such as anatomical sharpness. It is also hard to preserve fine image details while maintaining a natural appearance. More recently, Generative Adversarial Networks (GAN) based methods are proposed to solve fast MRI with enhanced image perceptual quality. The encoder obtains a latent space for the undersampling image, and the image is reconstructed by the decoder using the GAN loss. In this chapter, we review the GAN powered fast MRI methods with a comparative study on various anatomical datasets to demonstrate the generalisability and robustness of this kind of fast MRI while providing future perspectives.
Explainable Diabetic Retinopathy Detection and Retinal Image Generation
Jul 01, 2021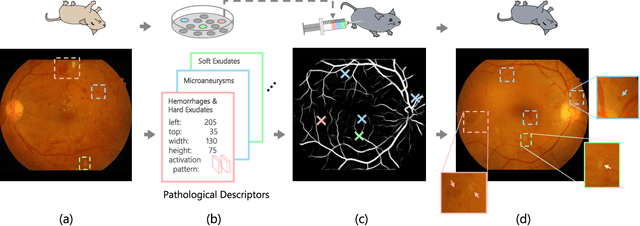
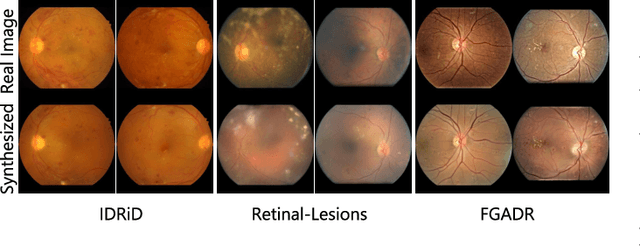
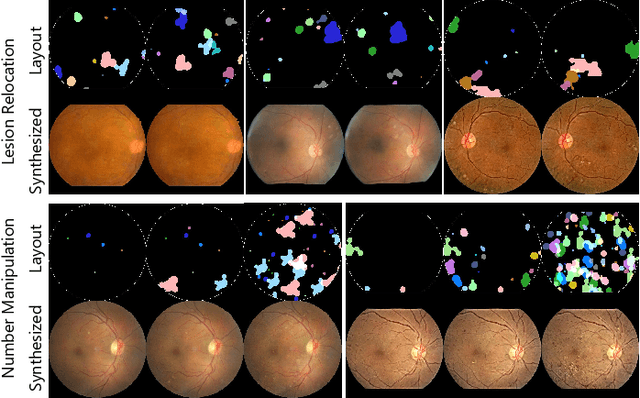
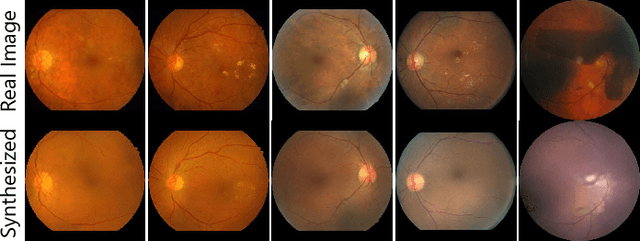
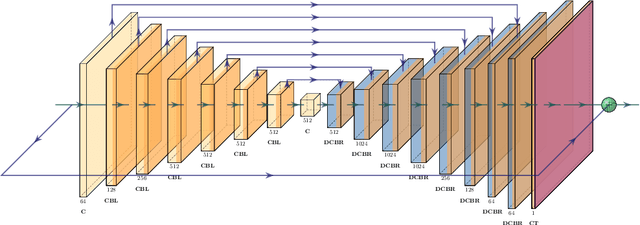
Though deep learning has shown successful performance in classifying the label and severity stage of certain diseases, most of them give few explanations on how to make predictions. Inspired by Koch's Postulates, the foundation in evidence-based medicine (EBM) to identify the pathogen, we propose to exploit the interpretability of deep learning application in medical diagnosis. By determining and isolating the neuron activation patterns on which diabetic retinopathy (DR) detector relies to make decisions, we demonstrate the direct relation between the isolated neuron activation and lesions for a pathological explanation. To be specific, we first define novel pathological descriptors using activated neurons of the DR detector to encode both spatial and appearance information of lesions. Then, to visualize the symptom encoded in the descriptor, we propose Patho-GAN, a new network to synthesize medically plausible retinal images. By manipulating these descriptors, we could even arbitrarily control the position, quantity, and categories of generated lesions. We also show that our synthesized images carry the symptoms directly related to diabetic retinopathy diagnosis. Our generated images are both qualitatively and quantitatively superior to the ones by previous methods. Besides, compared to existing methods that take hours to generate an image, our second level speed endows the potential to be an effective solution for data augmentation.
Learnable Fourier Features for Multi-DimensionalSpatial Positional Encoding
Jun 05, 2021
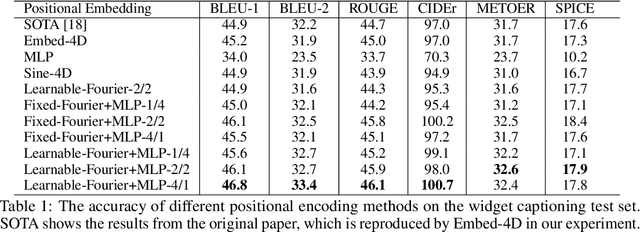
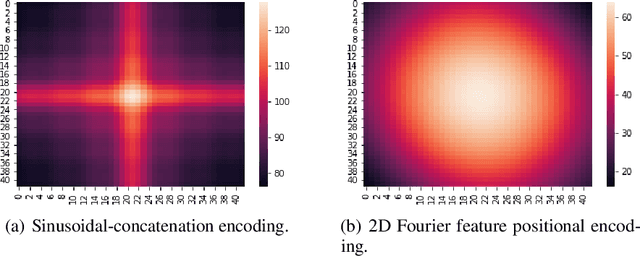

Attentional mechanisms are order-invariant. Positional encoding is a crucial component to allow attention-based deep model architectures such as Transformer to address sequences or images where the position of information matters. In this paper, we propose a novel positional encoding method based on learnable Fourier features. Instead of hard-coding each position as a token or a vector, we represent each position, which can be multi-dimensional, as a trainable encoding based on learnable Fourier feature mapping, modulated with a multi-layer perceptron. The representation is particularly advantageous for a spatial multi-dimensional position, e.g., pixel positions on an image, where $L_2$ distances or more complex positional relationships need to be captured. Our experiments based on several public benchmark tasks show that our learnable Fourier feature representation for multi-dimensional positional encoding outperforms existing methods by both improving the accuracy and allowing faster convergence.
Time Series is a Special Sequence: Forecasting with Sample Convolution and Interaction
Jun 17, 2021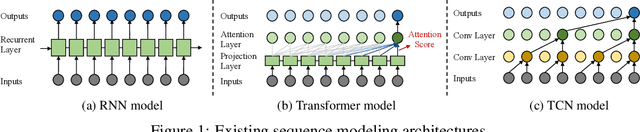

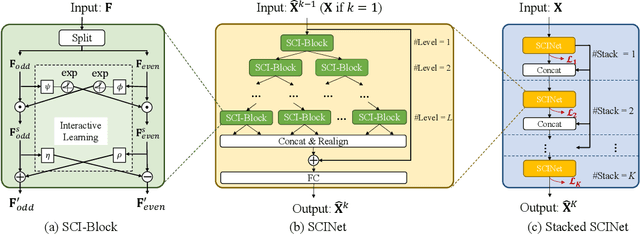
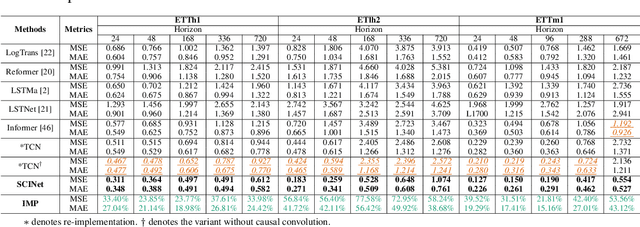
Time series is a special type of sequence data, a set of observations collected at even intervals of time and ordered chronologically. Existing deep learning techniques use generic sequence models (e.g., recurrent neural network, Transformer model, or temporal convolutional network) for time series analysis, which ignore some of its unique properties. For example, the downsampling of time series data often preserves most of the information in the data, while this is not true for general sequence data such as text sequence and DNA sequence. Motivated by the above, in this paper, we propose a novel neural network architecture and apply it for the time series forecasting problem, wherein we conduct sample convolution and interaction at multiple resolutions for temporal modeling. The proposed architecture, namelySCINet, facilitates extracting features with enhanced predictability. Experimental results show that SCINet achieves significant prediction accuracy improvement over existing solutions across various real-world time series forecasting datasets. In particular, it can achieve high fore-casting accuracy for those temporal-spatial datasets without using sophisticated spatial modeling techniques. Our codes and data are presented in the supplemental material.
Telling Stories through Multi-User Dialogue by Modeling Character Relations
May 31, 2021
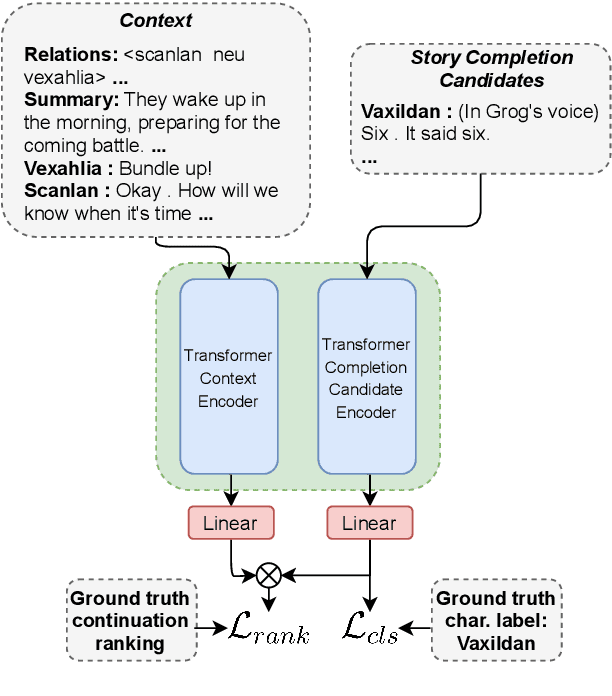
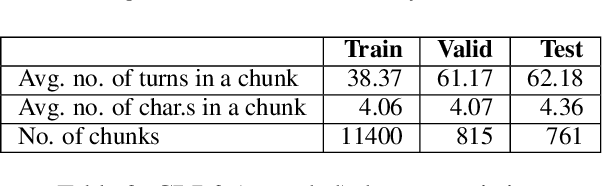
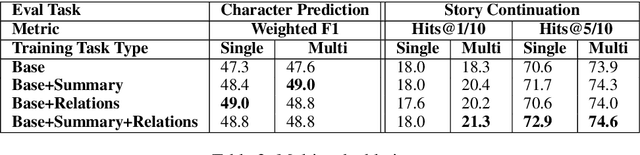
This paper explores character-driven story continuation, in which the story emerges through characters' first- and second-person narration as well as dialogue -- requiring models to select language that is consistent with a character's persona and their relationships with other characters while following and advancing the story. We hypothesize that a multi-task model that trains on character dialogue plus character relationship information improves transformer-based story continuation. To this end, we extend the Critical Role Dungeons and Dragons Dataset (Rameshkumar and Bailey, 2020) -- consisting of dialogue transcripts of people collaboratively telling a story while playing the role-playing game Dungeons and Dragons -- with automatically extracted relationships between each pair of interacting characters as well as their personas. A series of ablations lend evidence to our hypothesis, showing that our multi-task model using character relationships improves story continuation accuracy over strong baselines.