 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-supervised Motion Learning from Static Images
Apr 01, 2021
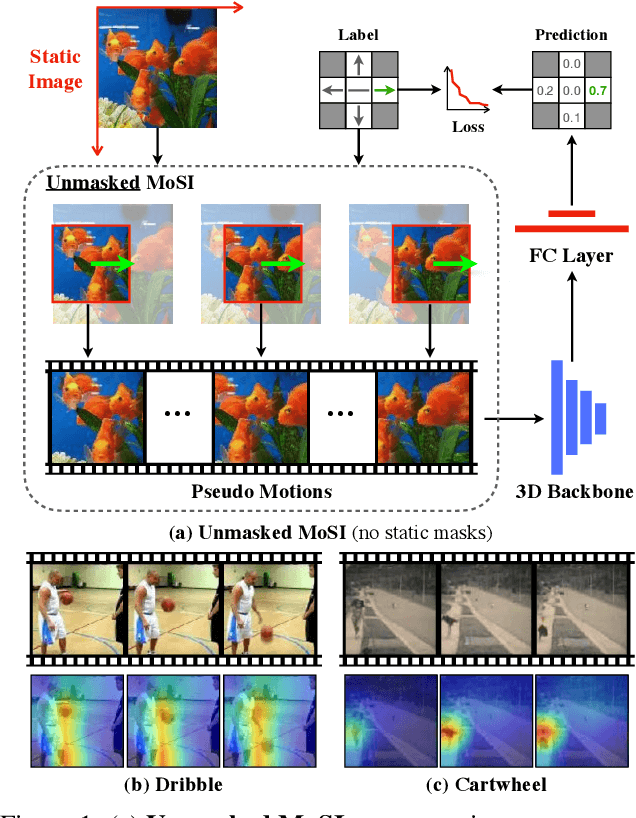
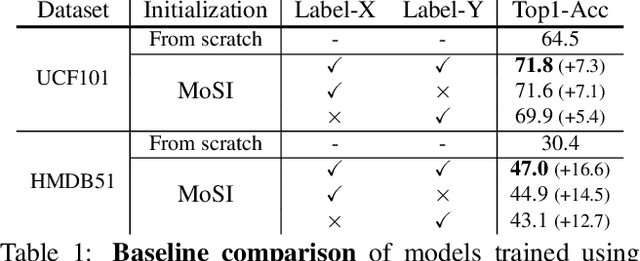
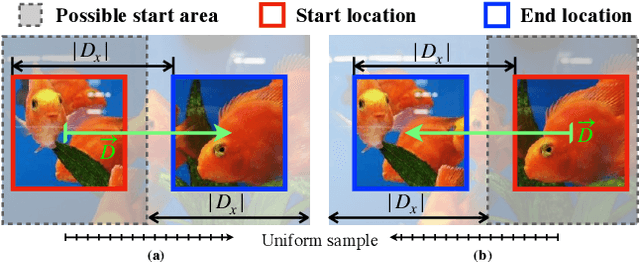
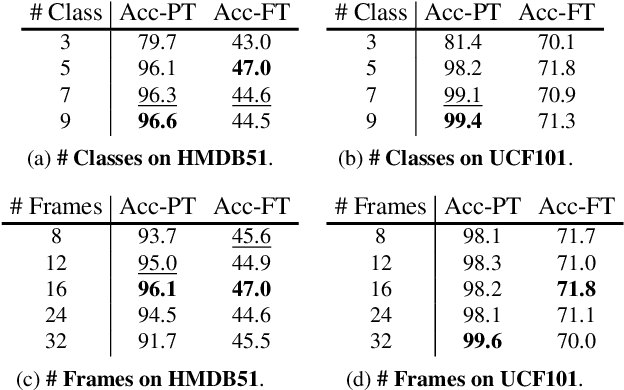
Motions are reflected in videos as the movement of pixels, and actions are essentially patterns of inconsistent motions between the foreground and the background. To well distinguish the actions, especially those with complicated spatio-temporal interactions, correctly locating the prominent motion areas is of crucial importance. However, most motion information in existing videos are difficult to label and training a model with good motion representations with supervision will thus require a large amount of human labour for annotation. In this paper, we address this problem by self-supervised learning. Specifically, we propose to learn Motion from Static Images (MoSI). The model learns to encode motion information by classifying pseudo motions generated by MoSI. We furthermore introduce a static mask in pseudo motions to create local motion patterns, which forces the model to additionally locate notable motion areas for the correct classification.We demonstrate that MoSI can discover regions with large motion even without fine-tuning on the downstream datasets. As a result, the learned motion representations boost the performance of tasks requiring understanding of complex scenes and motions, i.e., action recognition. Extensive experiments show the consistent and transferable improvements achieved by MoSI. Codes will be soon released.
Advanced Image Enhancement Method for Distant Vessels and Structures in Capsule Endoscopy
Apr 08, 2021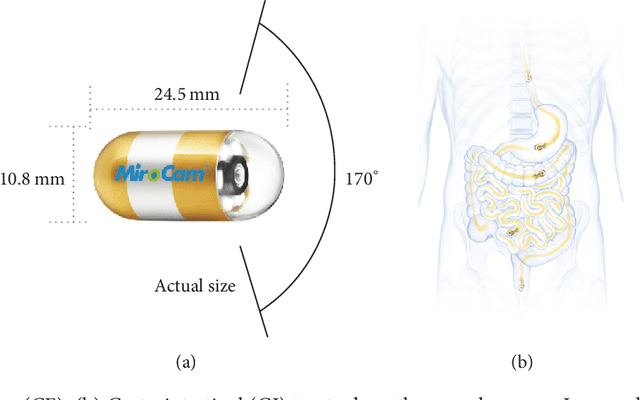
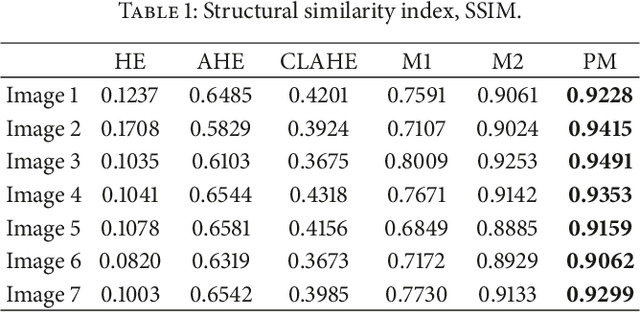
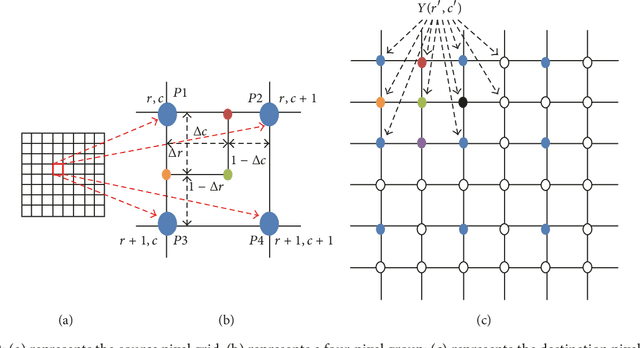
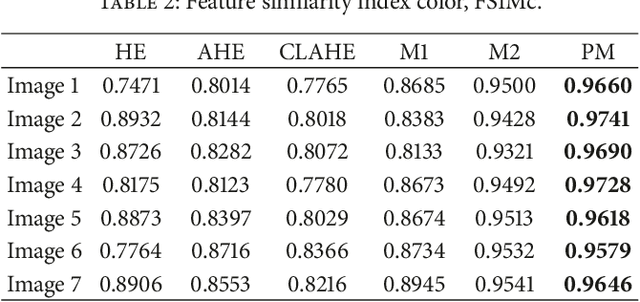
This paper proposes an advanced method for contrast enhancement of capsule endoscopic images, with the main objective to obtain sufficient information about the vessels and structures in more distant (or darker) parts of capsule endoscopic images. The proposed method (PM) combines two algorithms for the enhancement of darker and brighter areas of capsule endoscopic images, respectively. The half-unit weighted bilinear algorithm (HWB) proposed in our previous work is used to enhance darker areas according to the darker map content of its HSV's component V. Enhancement of brighter areas is achieved thanks to the novel thresholded weighted-bilinear algorithm (TWB) developed to avoid overexposure and enlargement of specular highlight spots while preserving the hue, in such areas. The TWB performs enhancement operations following a gradual increment of the brightness of the brighter map content of its HSV's component V. In other words, the TWB decreases its averaged-weights as the intensity content of the component V increases. Extensive experimental demonstrations were conducted, and based on evaluation of the reference and PM enhanced images, a gastroenterologist ({\O}H) concluded that the PM enhanced images were the best ones based on the information about the vessels, contrast in the images, and the view or visibility of the structures in more distant parts of the capsule endoscopy images.
* 8 pages, 12 figures, 4 tables
Using Deep Neural Network to Analyze Travel Mode Choice With Interpretable Economic Information: An Empirical Example
Dec 11, 2018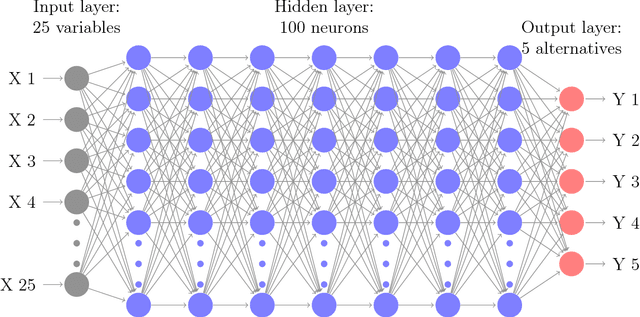

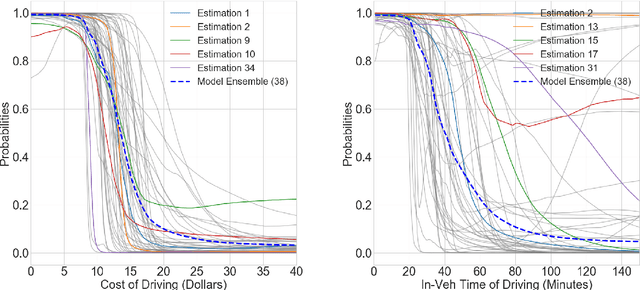
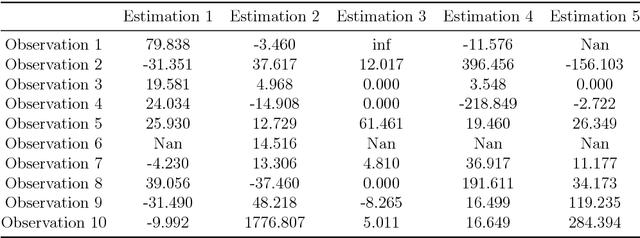
Deep neural network (DNN) has been increasingly applied to microscopic demand analysis. While DNN often outperforms traditional multinomial logit (MNL) model, it is unclear whether we can obtain interpretable economic information from DNN-based choice model beyond prediction accuracy. This paper provides an empirical method of numerically extracting valuable economic information such as choice probability, probability derivatives (or elasticities), and marginal rates of substitution. Using a survey collected in Singapore, we find that when the economic information is aggregated over population or models, DNN models can reveal roughly S-shaped choice probability curves, inverse bell-shaped driving probability derivatives regarding costs and time, and reasonable median value of time (VOT). However at the disaggregate level, choice probability curves of DNN models can be non-monotonically decreasing with costs and highly sensitive to the particular estimation; derivatives of choice probabilities regarding costs and time can be positive at some region; VOT can be infinite, undefined, zero, or arbitrarily large. Some of these patterns can be seen as counter-intuitive, while others can potentially be regarded as advantages of DNN for its flexibility to reflect certain behavior peculiarities. These patterns broadly relate to two theoretical challenges of DNN, irregularity of its probability space and large estimation errors. Overall, this study provides a practical guidance of using DNN for demand analysis with two suggestions: First, researchers can use numerical methods to obtain behaviorally intuitive choice probabilities, probability derivatives, and reasonable VOT. Second, given the large estimation errors and irregularity of the probability space of DNN, researchers should always ensemble either over population or individual models to obtain stable economic information.
Brittle AI, Causal Confusion, and Bad Mental Models: Challenges and Successes in the XAI Program
Jun 10, 2021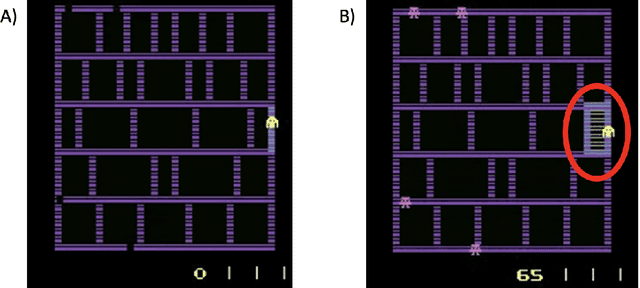
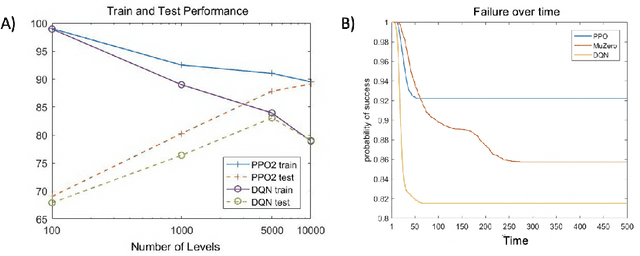
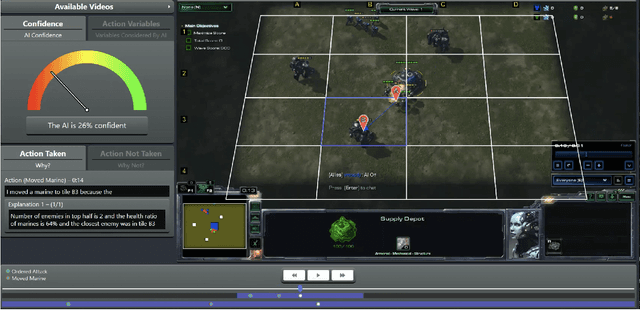

The advances in artificial intelligence enabled by deep learning architectures are undeniable. In several cases, deep neural network driven models have surpassed human level performance in benchmark autonomy tasks. The underlying policies for these agents, however, are not easily interpretable. In fact, given their underlying deep models, it is impossible to directly understand the mapping from observations to actions for any reasonably complex agent. Producing this supporting technology to "open the black box" of these AI systems, while not sacrificing performance, was the fundamental goal of the DARPA XAI program. In our journey through this program, we have several "big picture" takeaways: 1) Explanations need to be highly tailored to their scenario; 2) many seemingly high performing RL agents are extremely brittle and are not amendable to explanation; 3) causal models allow for rich explanations, but how to present them isn't always straightforward; and 4) human subjects conjure fantastically wrong mental models for AIs, and these models are often hard to break. This paper discusses the origins of these takeaways, provides amplifying information, and suggestions for future work.
A Systematic Study of Leveraging Subword Information for Learning Word Representations
Apr 16, 2019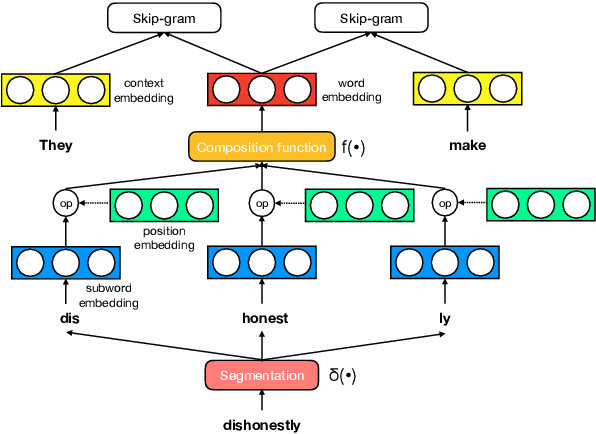
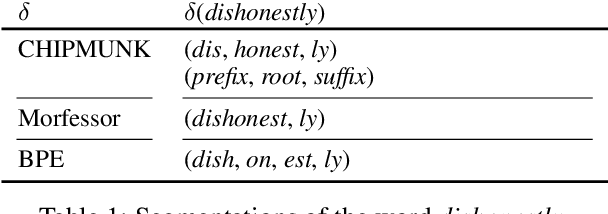
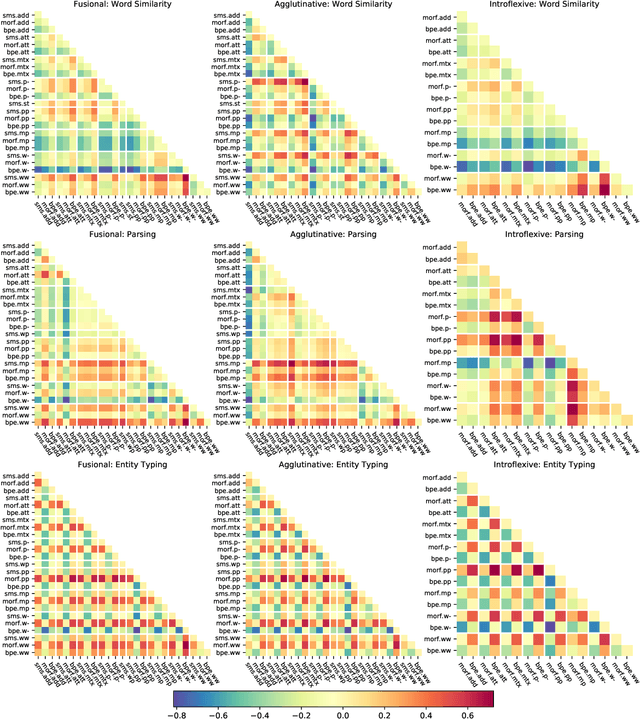
The use of subword-level information (e.g., characters, character n-grams, morphemes) has become ubiquitous in modern word representation learning. Its importance is attested especially for morphologically rich languages which generate a large number of rare words. Despite a steadily increasing interest in such subword-informed word representations, their systematic comparative analysis across typologically diverse languages and different tasks is still missing. In this work, we deliver such a study focusing on the variation of two crucial components required for subword-level integration into word representation models: 1) segmentation of words into subword units, and 2) subword composition functions to obtain final word representations. We propose a general framework for learning subword-informed word representations that allows for easy experimentation with different segmentation and composition components, also including more advanced techniques based on position embeddings and self-attention. Using the unified framework, we run experiments over a large number of subword-informed word representation configurations (60 in total) on 3 tasks (general and rare word similarity, dependency parsing, fine-grained entity typing) for 5 languages representing 3 language types. Our main results clearly indicate that there is no "one-sizefits-all" configuration, as performance is both language- and task-dependent. We also show that configurations based on unsupervised segmentation (e.g., BPE, Morfessor) are sometimes comparable to or even outperform the ones based on supervised word segmentation.
Morphological Classification of Galaxies in S-PLUS using an Ensemble of Convolutional Networks
Jul 05, 2021The universe is composed of galaxies that have diverse shapes. Once the structure of a galaxy is determined, it is possible to obtain important information about its formation and evolution. Morphologically classifying galaxies means cataloging them according to their visual appearance and the classification is linked to the physical properties of the galaxy. A morphological classification made through visual inspection is subject to biases introduced by subjective observations made by human volunteers. For this reason, systematic, objective and easily reproducible classification of galaxies has been gaining importance since the astronomer Edwin Hubble created his famous classification method. In this work, we combine accurate visual classifications of the Galaxy Zoo project with \emph {Deep Learning} methods. The goal is to find an efficient technique at human performance level classification, but in a systematic and automatic way, for classification of elliptical and spiral galaxies. For this, a neural network model was created through an Ensemble of four other convolutional models, allowing a greater accuracy in the classification than what would be obtained with any one individual. Details of the individual models and improvements made are also described. The present work is entirely based on the analysis of images (not parameter tables) from DR1 (www.datalab.noao.edu) of the Southern Photometric Local Universe Survey (S-PLUS). In terms of classification, we achieved, with the Ensemble, an accuracy of $\approx 99 \%$ in the test sample (using pre-trained networks).
MeGA-CDA: Memory Guided Attention for Category-Aware Unsupervised Domain Adaptive Object Detection
Mar 07, 2021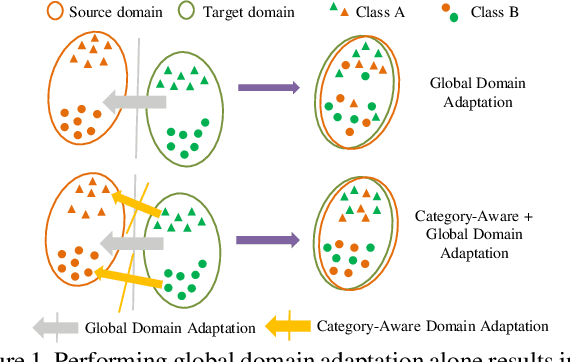
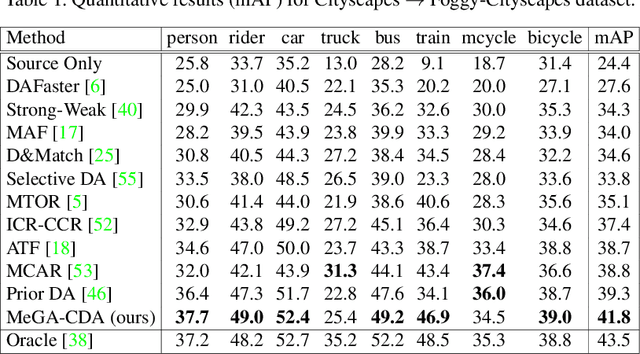
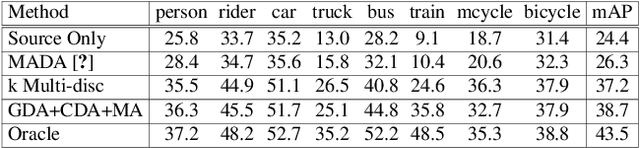
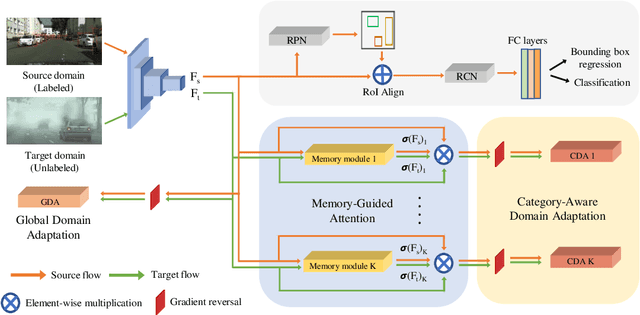
Existing approaches for unsupervised domain adaptive object detection perform feature alignment via adversarial training. While these methods achieve reasonable improvements in performance, they typically perform category-agnostic domain alignment, thereby resulting in negative transfer of features. To overcome this issue, in this work, we attempt to incorporate category information into the domain adaptation process by proposing Memory Guided Attention for Category-Aware Domain Adaptation (MeGA-CDA). The proposed method consists of employing category-wise discriminators to ensure category-aware feature alignment for learning domain-invariant discriminative features. However, since the category information is not available for the target samples, we propose to generate memory-guided category-specific attention maps which are then used to route the features appropriately to the corresponding category discriminator. The proposed method is evaluated on several benchmark datasets and is shown to outperform existing approaches.
Deep Learning for Network Traffic Classification
Jun 02, 2021
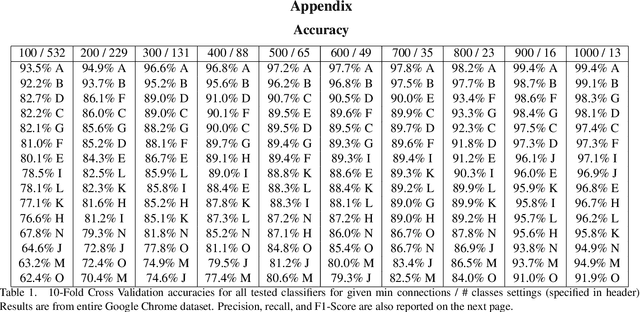
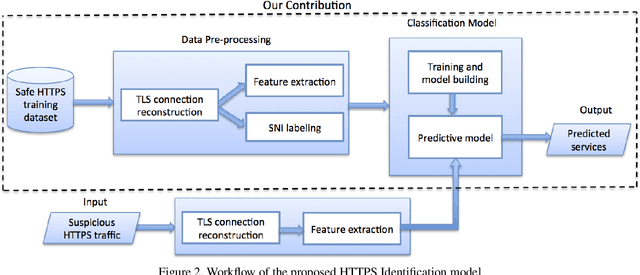
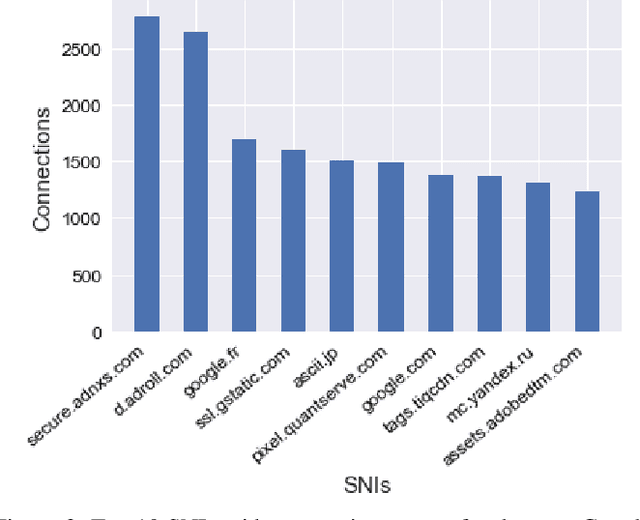
Monitoring network traffic to identify content, services, and applications is an active research topic in network traffic control systems. While modern firewalls provide the capability to decrypt packets, this is not appealing for privacy advocates. Hence, identifying any information from encrypted traffic is a challenging task. Nonetheless, previous work has identified machine learning methods that may enable application and service identification. The process involves high level feature extraction from network packet data then training a robust machine learning classifier for traffic identification. We propose a classification technique using an ensemble of deep learning architectures on packet, payload, and inter-arrival time sequences. To our knowledge, this is the first time such deep learning architectures have been applied to the Server Name Indication (SNI) classification problem. Our ensemble model beats the state of the art machine learning methods and our up-to-date model can be found on github: \url{https://github.com/niloofarbayat/NetworkClassification}
Efficient First-Order Contextual Bandits: Prediction, Allocation, and Triangular Discrimination
Jul 05, 2021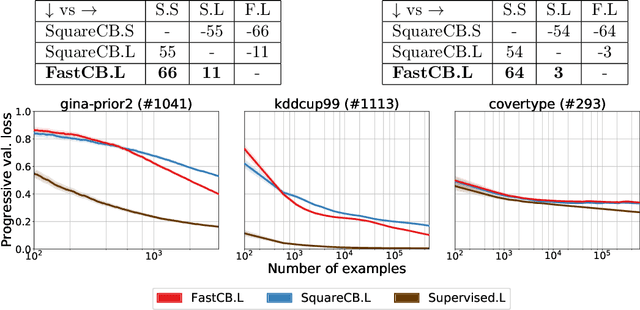
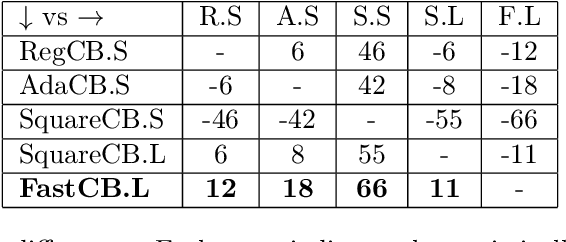
A recurring theme in statistical learning, online learning, and beyond is that faster convergence rates are possible for problems with low noise, often quantified by the performance of the best hypothesis; such results are known as first-order or small-loss guarantees. While first-order guarantees are relatively well understood in statistical and online learning, adapting to low noise in contextual bandits (and more broadly, decision making) presents major algorithmic challenges. In a COLT 2017 open problem, Agarwal, Krishnamurthy, Langford, Luo, and Schapire asked whether first-order guarantees are even possible for contextual bandits and -- if so -- whether they can be attained by efficient algorithms. We give a resolution to this question by providing an optimal and efficient reduction from contextual bandits to online regression with the logarithmic (or, cross-entropy) loss. Our algorithm is simple and practical, readily accommodates rich function classes, and requires no distributional assumptions beyond realizability. In a large-scale empirical evaluation, we find that our approach typically outperforms comparable non-first-order methods. On the technical side, we show that the logarithmic loss and an information-theoretic quantity called the triangular discrimination play a fundamental role in obtaining first-order guarantees, and we combine this observation with new refinements to the regression oracle reduction framework of Foster and Rakhlin. The use of triangular discrimination yields novel results even for the classical statistical learning model, and we anticipate that it will find broader use.
TransMIL: Transformer based Correlated Multiple Instance Learning for Whole Slide Image Classication
Jun 02, 2021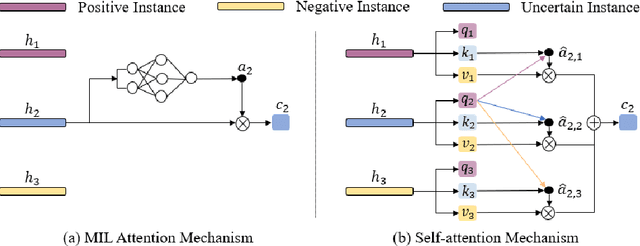
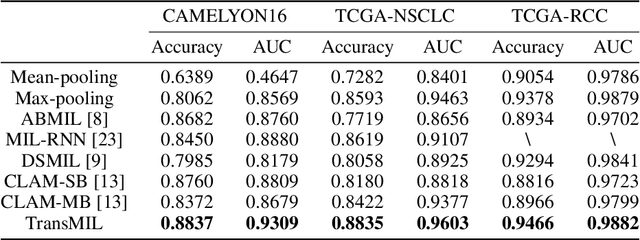

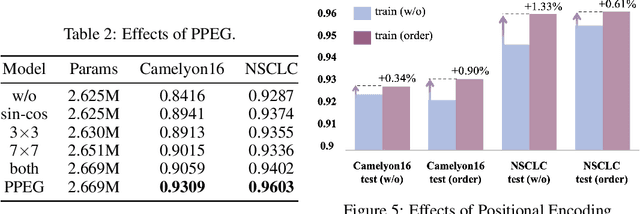
Multiple instance learning (MIL) is a powerful tool to solve the weakly supervised classification in whole slide image (WSI) based pathology diagnosis. However, the current MIL methods are usually based on independent and identical distribution hypothesis, thus neglect the correlation among different instances. To address this problem, we proposed a new framework, called correlated MIL, and provided a proof for convergence. Based on this framework, we devised a Transformer based MIL (TransMIL), which explored both morphological and spatial information. The proposed TransMIL can effectively deal with unbalanced/balanced and binary/multiple classification with great visualization and interpretability. We conducted various experiments for three different computational pathology problems and achieved better performance and faster convergence compared with state-of-the-art methods. The test AUC for the binary tumor classification can be up to 93.09% over CAMELYON16 dataset. And the AUC over the cancer subtypes classification can be up to 96.03% and 98.82% over TCGA-NSCLC dataset and TCGA-RCC dataset, respectively.