 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Under the Hood: Using Diagnostic Classifiers to Investigate and Improve how Language Models Track Agreement Information
Sep 07, 2018
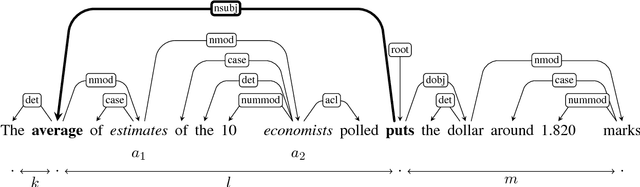


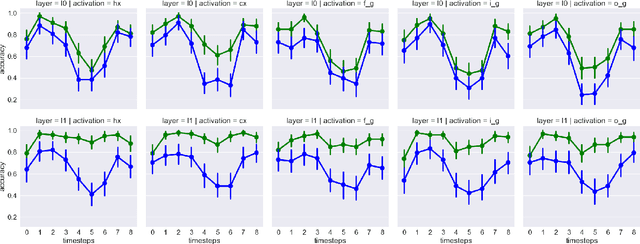
How do neural language models keep track of number agreement between subject and verb? We show that `diagnostic classifiers', trained to predict number from the internal states of a language model, provide a detailed understanding of how, when, and where this information is represented. Moreover, they give us insight into when and where number information is corrupted in cases where the language model ends up making agreement errors. To demonstrate the causal role played by the representations we find, we then use agreement information to influence the course of the LSTM during the processing of difficult sentences. Results from such an intervention reveal a large increase in the language model's accuracy. Together, these results show that diagnostic classifiers give us an unrivalled detailed look into the representation of linguistic information in neural models, and demonstrate that this knowledge can be used to improve their performance.
A survey on VQA_Datasets and Approaches
May 02, 2021Visual question answering (VQA) is a task that combines both the techniques of computer vision and natural language processing. It requires models to answer a text-based question according to the information contained in a visual. In recent years, the research field of VQA has been expanded. Research that focuses on the VQA, examining the reasoning ability and VQA on scientific diagrams, has also been explored more. Meanwhile, more multimodal feature fusion mechanisms have been proposed. This paper will review and analyze existing datasets, metrics, and models proposed for the VQA task.
1st Place Solution for YouTubeVOS Challenge 2021:Video Instance Segmentation
Jun 12, 2021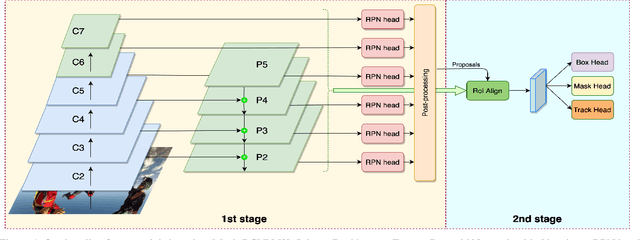

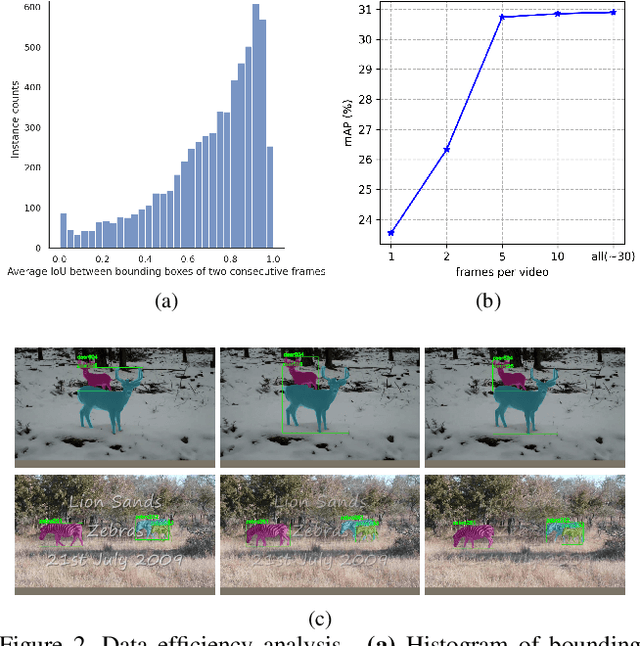
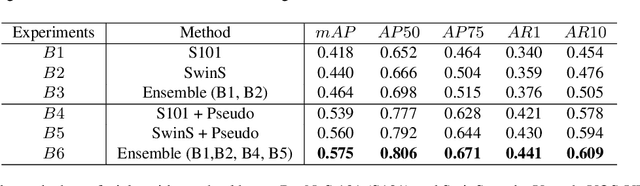
Video Instance Segmentation (VIS) is a multi-task problem performing detection, segmentation, and tracking simultaneously. Extended from image set applications, video data additionally induces the temporal information, which, if handled appropriately, is very useful to identify and predict object motions. In this work, we design a unified model to mutually learn these tasks. Specifically, we propose two modules, named Temporally Correlated Instance Segmentation (TCIS) and Bidirectional Tracking (BiTrack), to take the benefit of the temporal correlation between the object's instance masks across adjacent frames. On the other hand, video data is often redundant due to the frame's overlap. Our analysis shows that this problem is particularly severe for the YoutubeVOS-VIS2021 data. Therefore, we propose a Multi-Source Data (MSD) training mechanism to compensate for the data deficiency. By combining these techniques with a bag of tricks, the network performance is significantly boosted compared to the baseline, and outperforms other methods by a considerable margin on the YoutubeVOS-VIS 2019 and 2021 datasets.
Transfer Learning under High-dimensional Generalized Linear Models
May 29, 2021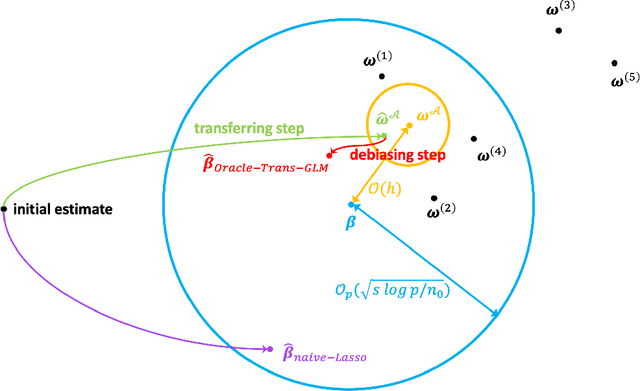
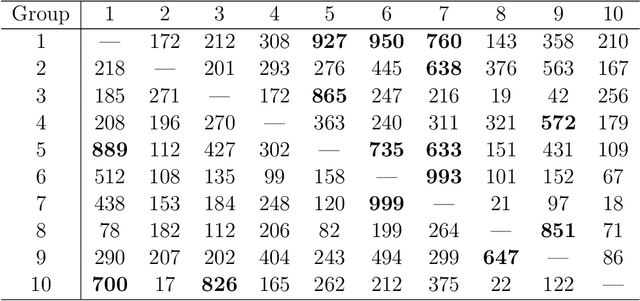
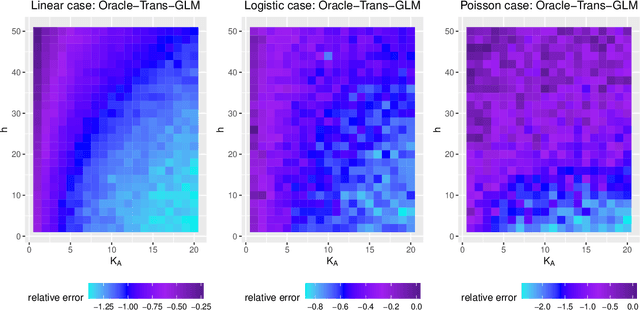
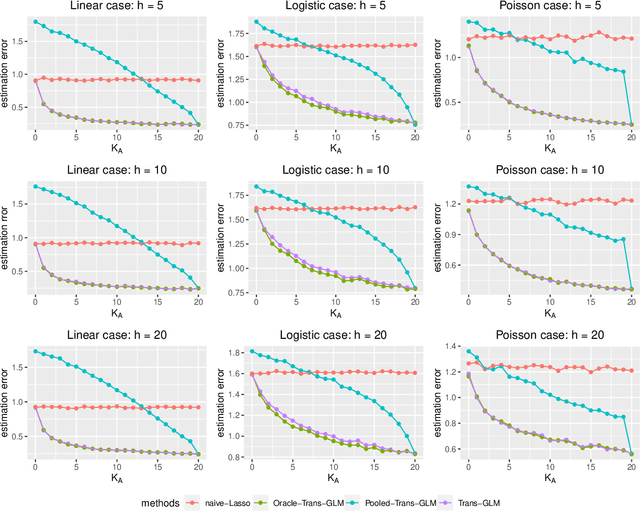
In this work, we study the transfer learning problem under high-dimensional generalized linear models (GLMs), which aim to improve the fit on target data by borrowing information from useful source data. Given which sources to transfer, we propose an oracle algorithm and derive its $\ell_2$-estimation error bounds. The theoretical analysis shows that under certain conditions, when the target and source are sufficiently close to each other, the estimation error bound could be improved over that of the classical penalized estimator using only target data. When we don't know which sources to transfer, an algorithm-free transferable source detection approach is introduced to detect informative sources. The detection consistency is proved under the high-dimensional GLM transfer learning setting. Extensive simulations and a real-data experiment verify the effectiveness of our algorithms.
Unsupervised Learning of Adaptive Codebooks for Deep Feedback Encoding in FDD Systems
May 19, 2021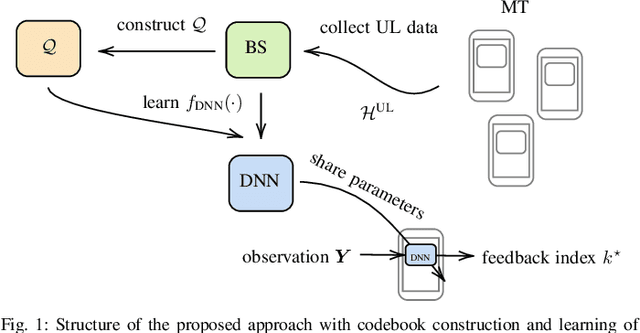
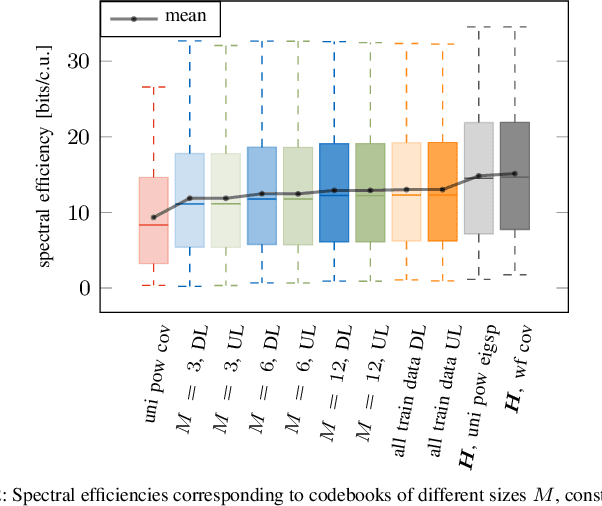
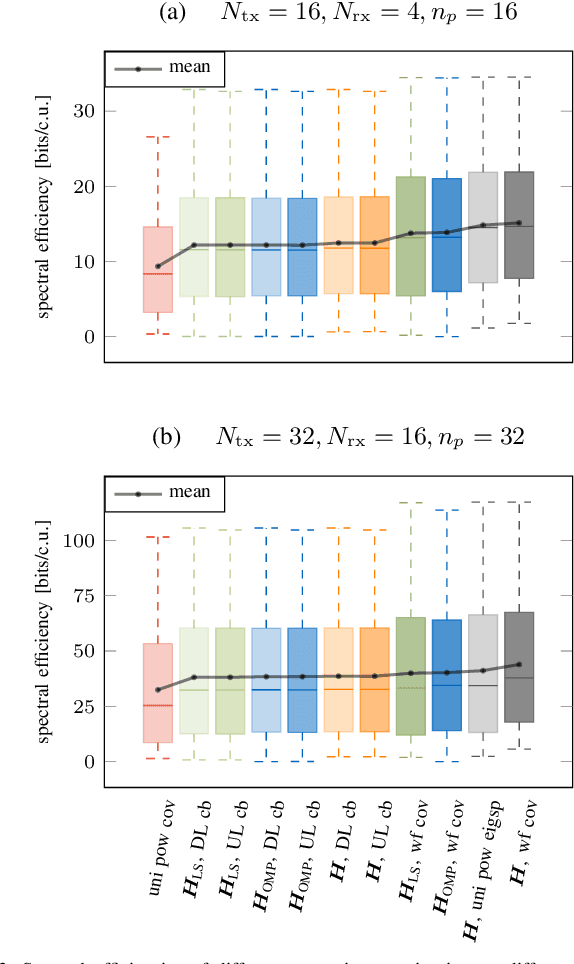
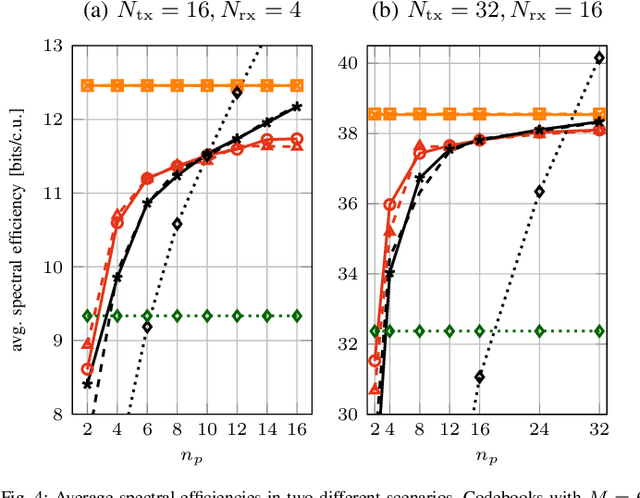
In this work, we propose a joint adaptive codebook construction and feedback generation scheme in frequency division duplex (FDD) systems. Both unsupervised and supervised deep learning techniques are used for this purpose. Based on a recently discovered equivalence of uplink (UL) and downlink (DL) channel state information (CSI) in terms of neural network learning, the codebook and associated deep encoder for feedback signaling is based on UL data only. Subsequently, the feedback encoder can be offloaded to the mobile terminals (MTs) to generate channel feedback there as efficiently as possible, without any training effort at the terminals or corresponding transfer of training and codebook data. Numerical simulations demonstrate the promising performance of the proposed method.
LSTM Based Sentiment Analysis for Cryptocurrency Prediction
Apr 03, 2021

Recent studies in big data analytics and natural language processing develop automatic techniques in analyzing sentiment in the social media information. In addition, the growing user base of social media and the high volume of posts also provide valuable sentiment information to predict the price fluctuation of the cryptocurrency. This research is directed to predicting the volatile price movement of cryptocurrency by analyzing the sentiment in social media and finding the correlation between them. While previous work has been developed to analyze sentiment in English social media posts, we propose a method to identify the sentiment of the Chinese social media posts from the most popular Chinese social media platform Sina-Weibo. We develop the pipeline to capture Weibo posts, describe the creation of the crypto-specific sentiment dictionary, and propose a long short-term memory (LSTM) based recurrent neural network along with the historical cryptocurrency price movement to predict the price trend for future time frames. The conducted experiments demonstrate the proposed approach outperforms the state of the art auto regressive based model by 18.5% in precision and 15.4% in recall.
Interpretable Mixture Density Estimation by use of Differentiable Tree-module
May 08, 2021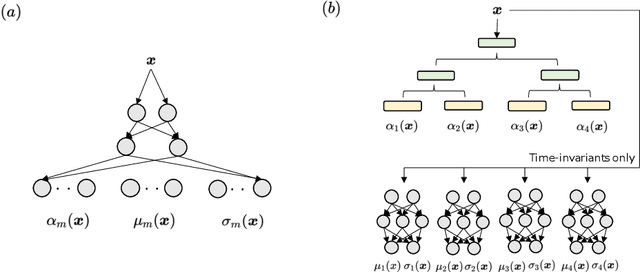

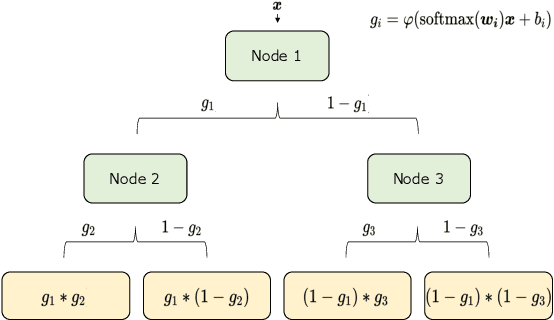

In order to develop reliable services using machine learning, it is important to understand the uncertainty of the model outputs. Often the probability distribution that the prediction target follows has a complex shape, and a mixture distribution is assumed as a distribution that uncertainty follows. Since the output of mixture density estimation is complicated, its interpretability becomes important when considering its use in real services. In this paper, we propose a method for mixture density estimation that utilizes an interpretable tree structure. Further, a fast inference procedure based on time-invariant information cache achieves both high speed and interpretability.
Neural Sentence Ordering Based on Constraint Graphs
Jan 28, 2021
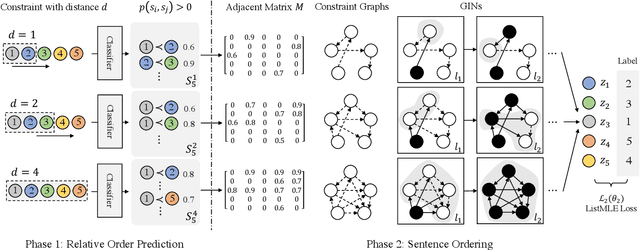
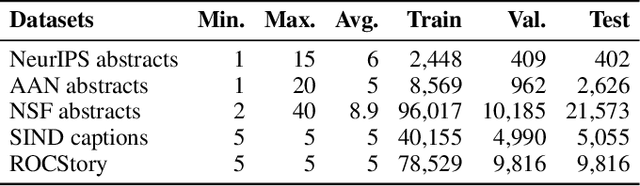

Sentence ordering aims at arranging a list of sentences in the correct order. Based on the observation that sentence order at different distances may rely on different types of information, we devise a new approach based on multi-granular orders between sentences. These orders form multiple constraint graphs, which are then encoded by Graph Isomorphism Networks and fused into sentence representations. Finally, sentence order is determined using the order-enhanced sentence representations. Our experiments on five benchmark datasets show that our method outperforms all the existing baselines significantly, achieving a new state-of-the-art performance. The results demonstrate the advantage of considering multiple types of order information and using graph neural networks to integrate sentence content and order information for the task. Our code is available at https://github.com/DaoD/ConstraintGraph4NSO.
Step-Wise Hierarchical Alignment Network for Image-Text Matching
Jun 11, 2021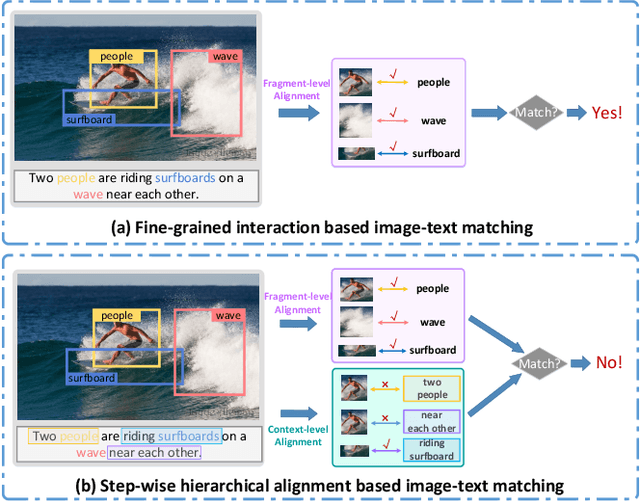
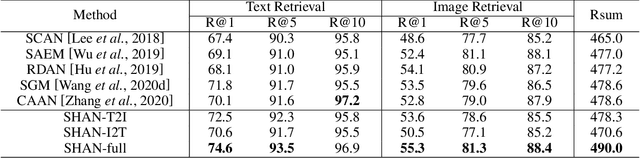
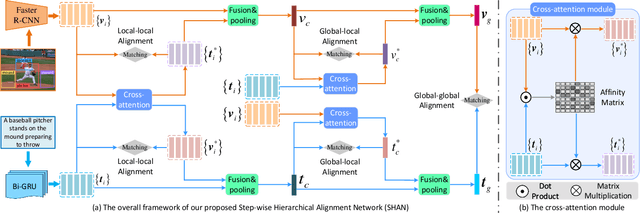
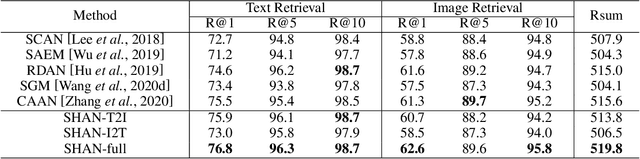
Image-text matching plays a central role in bridging the semantic gap between vision and language. The key point to achieve precise visual-semantic alignment lies in capturing the fine-grained cross-modal correspondence between image and text. Most previous methods rely on single-step reasoning to discover the visual-semantic interactions, which lacks the ability of exploiting the multi-level information to locate the hierarchical fine-grained relevance. Different from them, in this work, we propose a step-wise hierarchical alignment network (SHAN) that decomposes image-text matching into multi-step cross-modal reasoning process. Specifically, we first achieve local-to-local alignment at fragment level, following by performing global-to-local and global-to-global alignment at context level sequentially. This progressive alignment strategy supplies our model with more complementary and sufficient semantic clues to understand the hierarchical correlations between image and text. The experimental results on two benchmark datasets demonstrate the superiority of our proposed method.
Generalized Zero-Shot Learning using Multimodal Variational Auto-Encoder with Semantic Concepts
Jun 26, 2021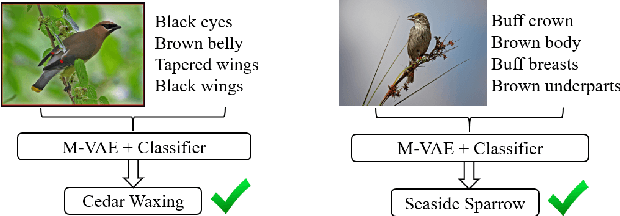
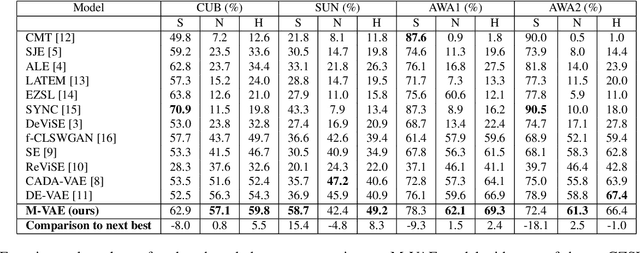
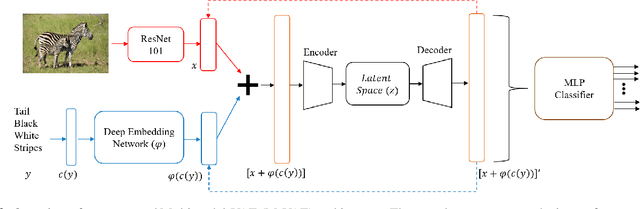

With the ever-increasing amount of data, the central challenge in multimodal learning involves limitations of labelled samples. For the task of classification, techniques such as meta-learning, zero-shot learning, and few-shot learning showcase the ability to learn information about novel classes based on prior knowledge. Recent techniques try to learn a cross-modal mapping between the semantic space and the image space. However, they tend to ignore the local and global semantic knowledge. To overcome this problem, we propose a Multimodal Variational Auto-Encoder (M-VAE) which can learn the shared latent space of image features and the semantic space. In our approach we concatenate multimodal data to a single embedding before passing it to the VAE for learning the latent space. We propose the use of a multi-modal loss during the reconstruction of the feature embedding through the decoder. Our approach is capable to correlating modalities and exploit the local and global semantic knowledge for novel sample predictions. Our experimental results using a MLP classifier on four benchmark datasets show that our proposed model outperforms the current state-of-the-art approaches for generalized zero-shot learning.