 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dual-Stream Reciprocal Disentanglement Learning for Domain Adaption Person Re-Identification
Jun 26, 2021
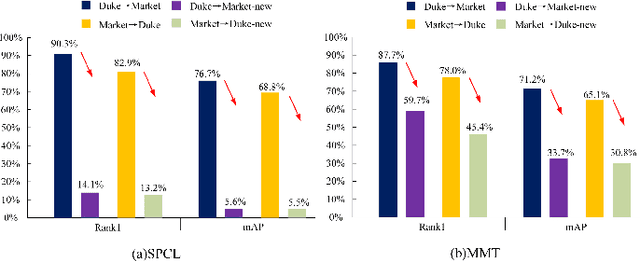
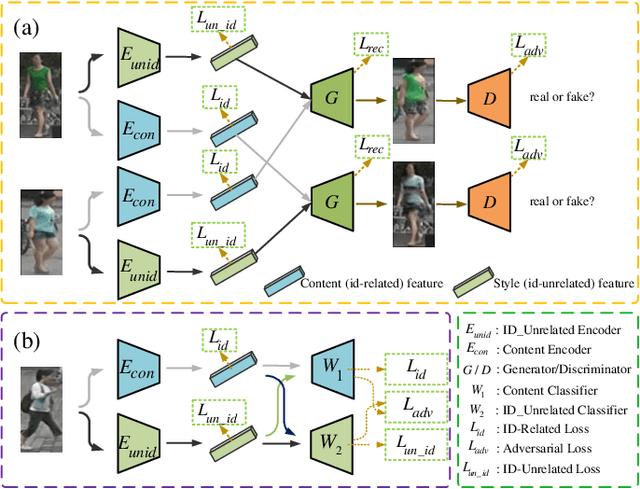
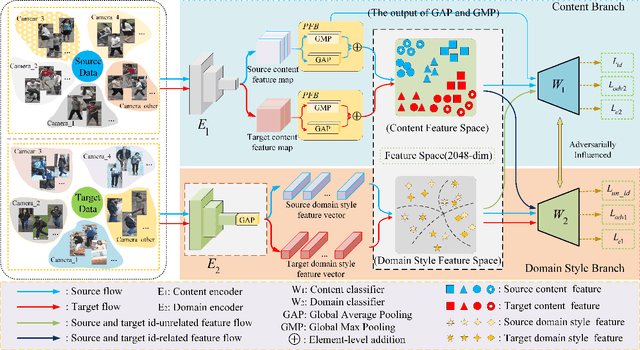
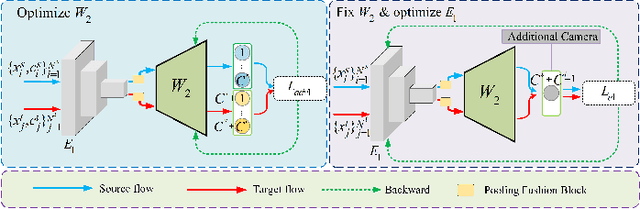
Since human-labeled samples are free for the target set, unsupervised person re-identification (Re-ID) has attracted much attention in recent years, by additionally exploiting the source set. However, due to the differences on camera styles, illumination and backgrounds, there exists a large gap between source domain and target domain, introducing a great challenge on cross-domain matching. To tackle this problem, in this paper we propose a novel method named Dual-stream Reciprocal Disentanglement Learning (DRDL), which is quite efficient in learning domain-invariant features. In DRDL, two encoders are first constructed for id-related and id-unrelated feature extractions, which are respectively measured by their associated classifiers. Furthermore, followed by an adversarial learning strategy, both streams reciprocally and positively effect each other, so that the id-related features and id-unrelated features are completely disentangled from a given image, allowing the encoder to be powerful enough to obtain the discriminative but domain-invariant features. In contrast to existing approaches, our proposed method is free from image generation, which not only reduces the computational complexity remarkably, but also removes redundant information from id-related features. Extensive experiments substantiate the superiority of our proposed method compared with the state-of-the-arts. The source code has been released in https://github.com/lhf12278/DRDL.
Heterogeneous Graph Attention Network for Multi-hop Machine Reading Comprehension
Jul 02, 2021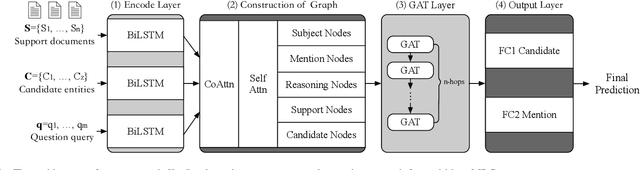
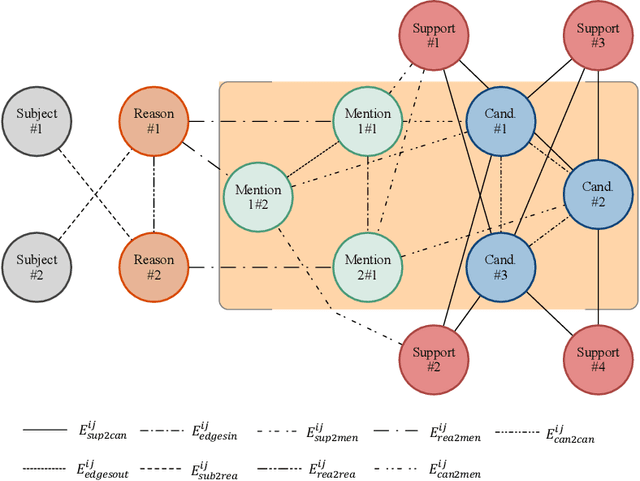


Multi-hop machine reading comprehension is a challenging task in natural language processing, which requires more reasoning ability and explainability. Spectral models based on graph convolutional networks grant the inferring abilities and lead to competitive results, however, part of them still face the challenge of analyzing the reasoning in a human-understandable way. Inspired by the concept of the Grandmother Cells in cognitive neuroscience, a spatial graph attention framework named crname, imitating the procedure was proposed. This model is designed to assemble the semantic features in multi-angle representations and automatically concentrate or alleviate the information for reasoning. The name "crname" is a metaphor for the pattern of the model: regard the subjects of queries as the start points of clues, take the reasoning entities as bridge points, and consider the latent candidate entities as the grandmother cells, and the clues end up in candidate entities. The proposed model allows us to visualize the reasoning graph and analyze the importance of edges connecting two entities and the selectivity in the mention and candidate nodes, which can be easier to be comprehended empirically. The official evaluations in open-domain multi-hop reading dataset WikiHop and Drug-drug Interactions dataset MedHop prove the validity of our approach and show the probability of the application of the model in the molecular biology domain.
AdaTag: Multi-Attribute Value Extraction from Product Profiles with Adaptive Decoding
Jun 04, 2021

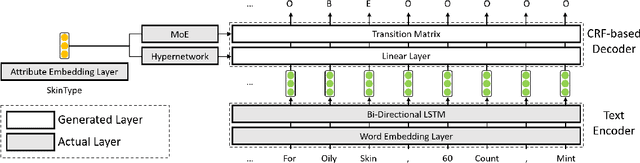
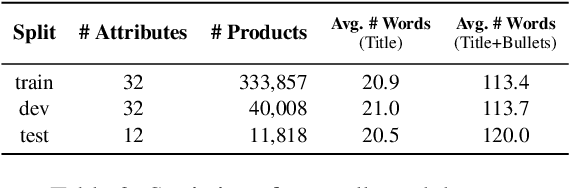
Automatic extraction of product attribute values is an important enabling technology in e-Commerce platforms. This task is usually modeled using sequence labeling architectures, with several extensions to handle multi-attribute extraction. One line of previous work constructs attribute-specific models, through separate decoders or entirely separate models. However, this approach constrains knowledge sharing across different attributes. Other contributions use a single multi-attribute model, with different techniques to embed attribute information. But sharing the entire network parameters across all attributes can limit the model's capacity to capture attribute-specific characteristics. In this paper we present AdaTag, which uses adaptive decoding to handle extraction. We parameterize the decoder with pretrained attribute embeddings, through a hypernetwork and a Mixture-of-Experts (MoE) module. This allows for separate, but semantically correlated, decoders to be generated on the fly for different attributes. This approach facilitates knowledge sharing, while maintaining the specificity of each attribute. Our experiments on a real-world e-Commerce dataset show marked improvements over previous methods.
Retrieve & Memorize: Dialog Policy Learning with Multi-Action Memory
Jun 04, 2021
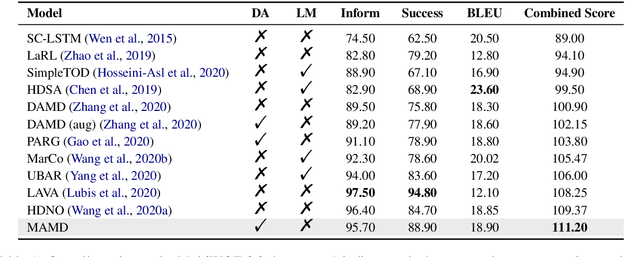
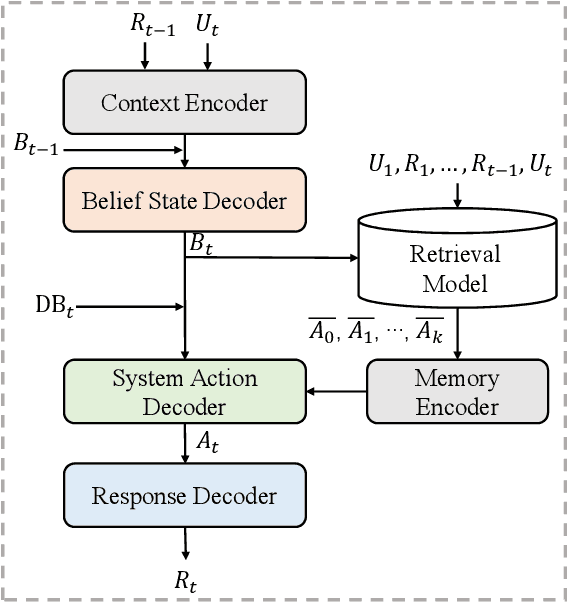
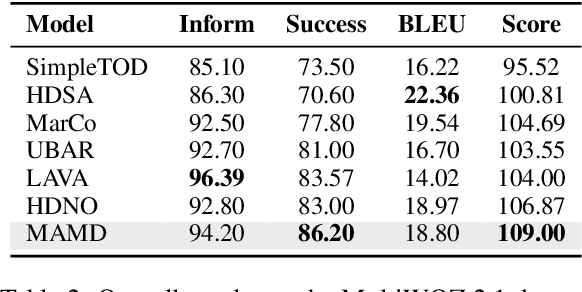
Dialogue policy learning, a subtask that determines the content of system response generation and then the degree of task completion, is essential for task-oriented dialogue systems. However, the unbalanced distribution of system actions in dialogue datasets often causes difficulty in learning to generate desired actions and responses. In this paper, we propose a retrieve-and-memorize framework to enhance the learning of system actions. Specially, we first design a neural context-aware retrieval module to retrieve multiple candidate system actions from the training set given a dialogue context. Then, we propose a memory-augmented multi-decoder network to generate the system actions conditioned on the candidate actions, which allows the network to adaptively select key information in the candidate actions and ignore noises. We conduct experiments on the large-scale multi-domain task-oriented dialogue dataset MultiWOZ 2.0 and MultiWOZ 2.1.~Experimental results show that our method achieves competitive performance among several state-of-the-art models in the context-to-response generation task.
The principles of adaptation in organisms and machines I: machine learning, information theory, and thermodynamics
Feb 28, 2019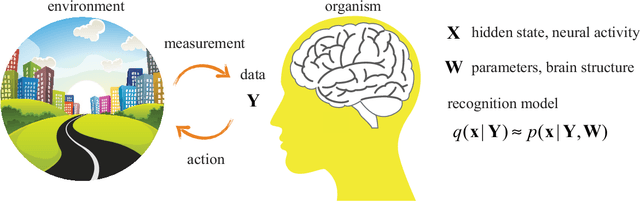
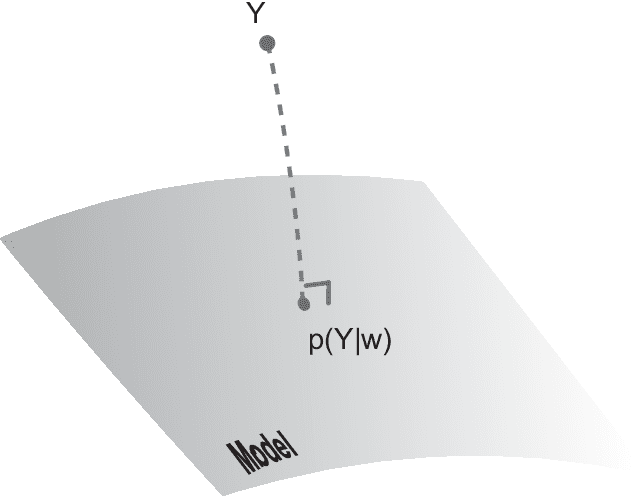
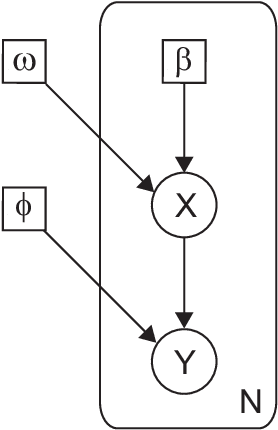
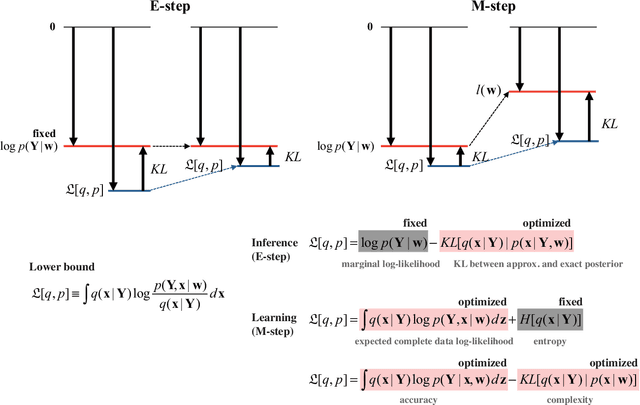
How do organisms recognize their environment by acquiring knowledge about the world, and what actions do they take based on this knowledge? This article examines hypotheses about organisms' adaptation to the environment from machine learning, information-theoretic, and thermodynamic perspectives. We start with constructing a hierarchical model of the world as an internal model in the brain, and review standard machine learning methods to infer causes by approximately learning the model under the maximum likelihood principle. This in turn provides an overview of the free energy principle for an organism, a hypothesis to explain perception and action from the principle of least surprise. Treating this statistical learning as communication between the world and brain, learning is interpreted as a process to maximize information about the world. We investigate how the classical theories of perception such as the infomax principle relates to learning the hierarchical model. We then present an approach to the recognition and learning based on thermodynamics, showing that adaptation by causal learning results in the second law of thermodynamics whereas inference dynamics that fuses observation with prior knowledge forms a thermodynamic process. These provide a unified view on the adaptation of organisms to the environment.
Comparing ML based Segmentation Models on Jet Fire Radiation Zone
Jul 07, 2021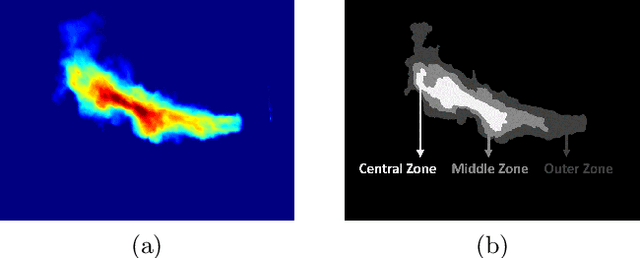
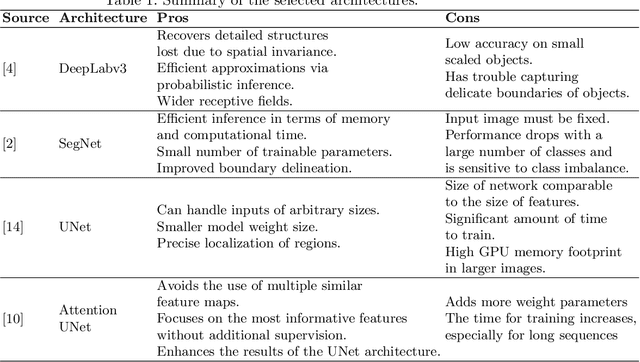
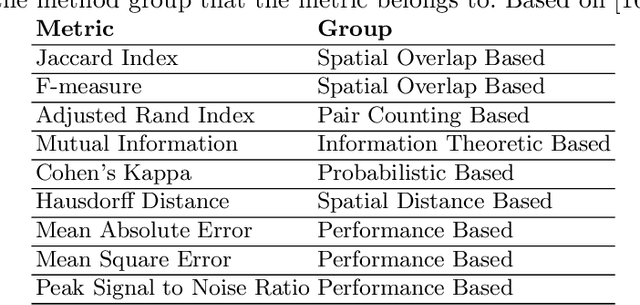
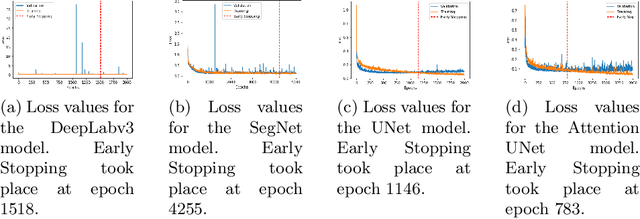
Risk assessment is relevant in any workplace, however there is a degree of unpredictability when dealing with flammable or hazardous materials so that detection of fire accidents by itself may not be enough. An example of this is the impingement of jet fires, where the heat fluxes of the flame could reach nearby equipment and dramatically increase the probability of a domino effect with catastrophic results. Because of this, the characterization of such fire accidents is important from a risk management point of view. One such characterization would be the segmentation of different radiation zones within the flame, so this paper presents an exploratory research regarding several traditional computer vision and Deep Learning segmentation approaches to solve this specific problem. A data set of propane jet fires is used to train and evaluate the different approaches and given the difference in the distribution of the zones and background of the images, different loss functions, that seek to alleviate data imbalance, are also explored. Additionally, different metrics are correlated to a manual ranking performed by experts to make an evaluation that closely resembles the expert's criteria. The Hausdorff Distance and Adjsted Random Index were the metrics with the highest correlation and the best results were obtained from the UNet architecture with a Weighted Cross-Entropy Loss. These results can be used in future research to extract more geometric information from the segmentation masks or could even be implemented on other types of fire accidents.
AgreeSum: Agreement-Oriented Multi-Document Summarization
Jun 04, 2021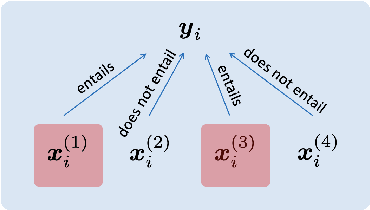

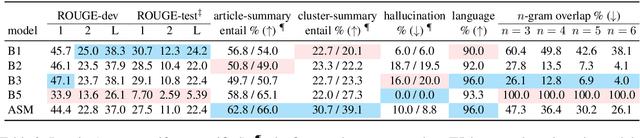
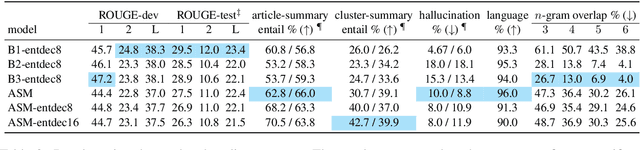
We aim to renew interest in a particular multi-document summarization (MDS) task which we call AgreeSum: agreement-oriented multi-document summarization. Given a cluster of articles, the goal is to provide abstractive summaries that represent information common and faithful to all input articles. Given the lack of existing datasets, we create a dataset for AgreeSum, and provide annotations on article-summary entailment relations for a subset of the clusters in the dataset. We aim to create strong baselines for the task by applying the top-performing pretrained single-document summarization model PEGASUS onto AgreeSum, leveraging both annotated clusters by supervised losses, and unannotated clusters by T5-based entailment-related and language-related losses. Compared to other baselines, both automatic evaluation and human evaluation show better article-summary and cluster-summary entailment in generated summaries. On a separate note, we hope that our article-summary entailment annotations contribute to the community's effort in improving abstractive summarization faithfulness.
An Embedding-based Joint Sentiment-Topic Model for Short Texts
Mar 26, 2021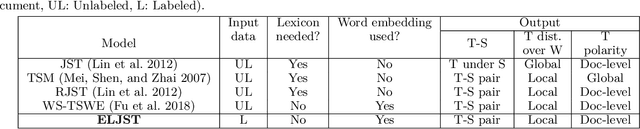
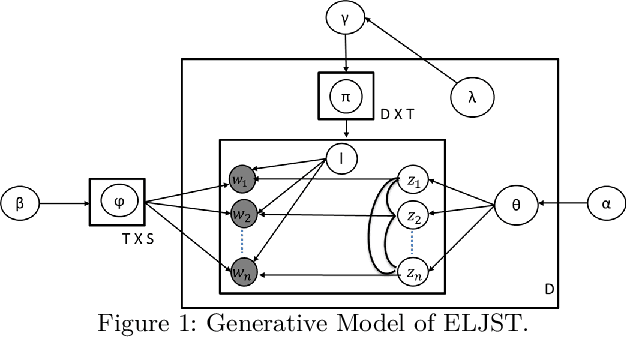

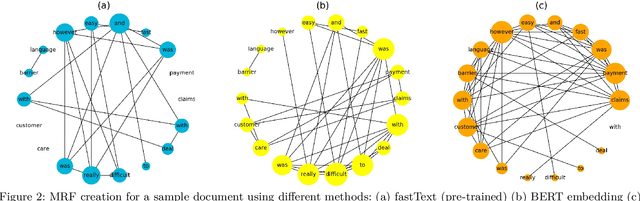
Short text is a popular avenue of sharing feedback, opinions and reviews on social media, e-commerce platforms, etc. Many companies need to extract meaningful information (which may include thematic content as well as semantic polarity) out of such short texts to understand users' behaviour. However, obtaining high quality sentiment-associated and human interpretable themes still remains a challenge for short texts. In this paper we develop ELJST, an embedding enhanced generative joint sentiment-topic model that can discover more coherent and diverse topics from short texts. It uses Markov Random Field Regularizer that can be seen as a generalisation of skip-gram based models. Further, it can leverage higher-order semantic information appearing in word embedding, such as self-attention weights in graphical models. Our results show an average improvement of 10% in topic coherence and 5% in topic diversification over baselines. Finally, ELJST helps understand users' behaviour at more granular levels which can be explained. All these can bring significant values to the service and healthcare industries often dealing with customers.
Centroid Transformers: Learning to Abstract with Attention
Feb 17, 2021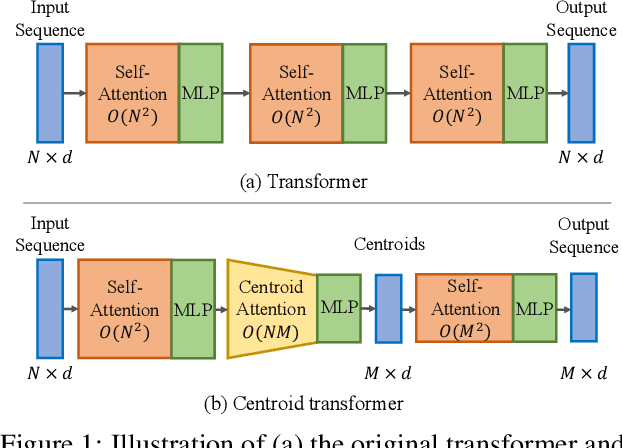

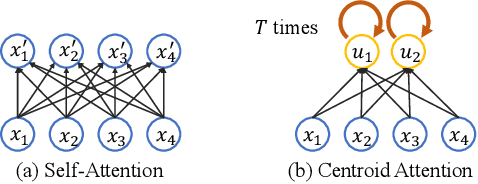
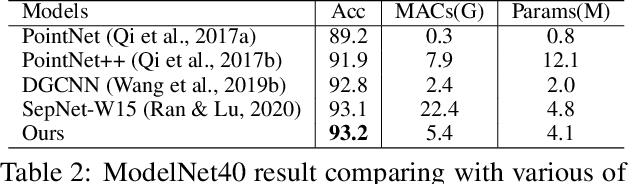
Self-attention, as the key block of transformers, is a powerful mechanism for extracting features from the inputs. In essence, what self-attention does to infer the pairwise relations between the elements of the inputs, and modify the inputs by propagating information between input pairs. As a result, it maps inputs to N outputs and casts a quadratic $O(N^2)$ memory and time complexity. We propose centroid attention, a generalization of self-attention that maps N inputs to M outputs $(M\leq N)$, such that the key information in the inputs are summarized in the smaller number of outputs (called centroids). We design centroid attention by amortizing the gradient descent update rule of a clustering objective function on the inputs, which reveals an underlying connection between attention and clustering. By compressing the inputs to the centroids, we extract the key information useful for prediction and also reduce the computation of the attention module and the subsequent layers. We apply our method to various applications, including abstractive text summarization, 3D vision, and image processing. Empirical results demonstrate the effectiveness of our method over the standard transformers.
Visual Question Rewriting for Increasing Response Rate
Jun 04, 2021
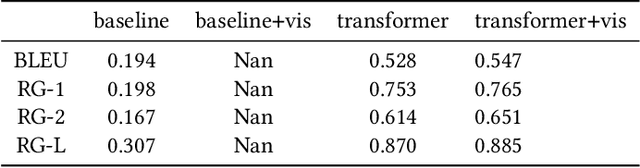
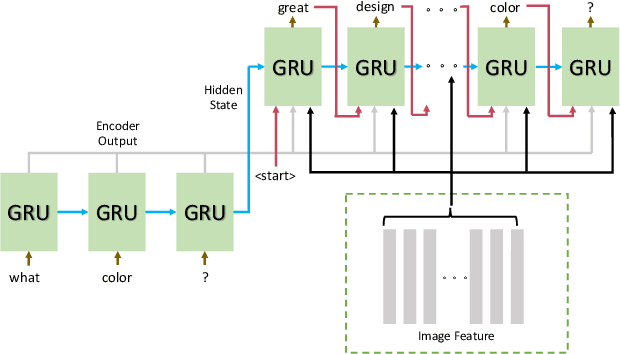
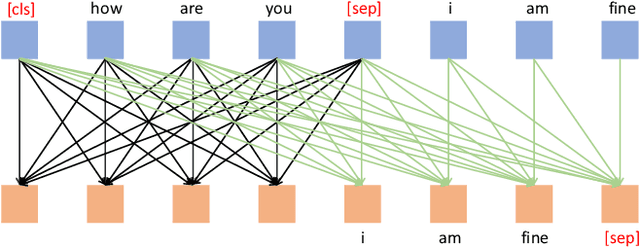
When a human asks questions online, or when a conversational virtual agent asks human questions, questions triggering emotions or with details might more likely to get responses or answers. we explore how to automatically rewrite natural language questions to improve the response rate from people. In particular, a new task of Visual Question Rewriting(VQR) task is introduced to explore how visual information can be used to improve the new questions. A data set containing around 4K bland questions, attractive questions and images triples is collected. We developed some baseline sequence to sequence models and more advanced transformer based models, which take a bland question and a related image as input and output a rewritten question that is expected to be more attractive. Offline experiments and mechanical Turk based evaluations show that it is possible to rewrite bland questions in a more detailed and attractive way to increase the response rate, and images can be helpful.