 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Resource-aware Online Parameter Adaptation for Computationally-constrained Visual-Inertial Navigation Systems
Jun 01, 2021
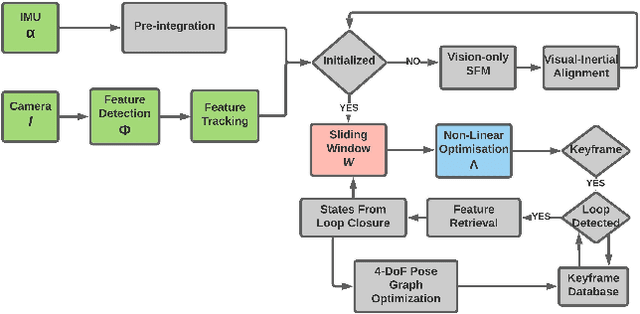
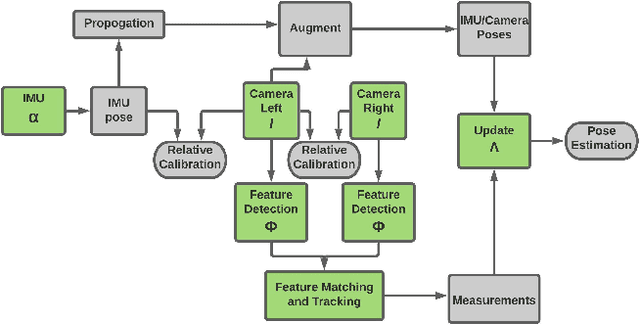
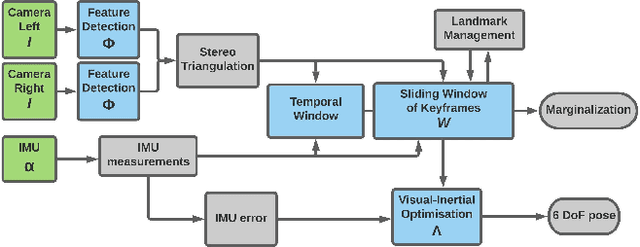
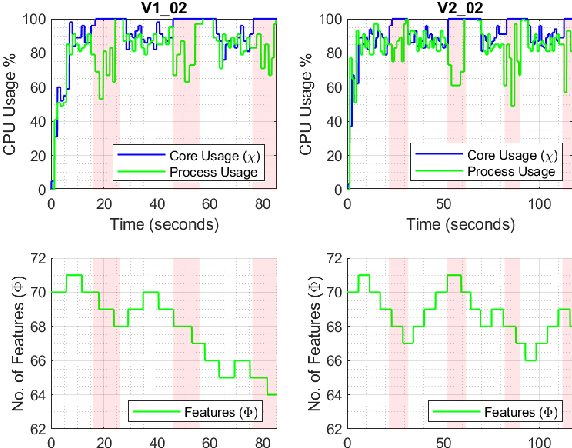
In this paper, a computational resources-aware parameter adaptation method for visual-inertial navigation systems is proposed with the goal of enabling the improved deployment of such algorithms on computationally constrained systems. Such a capacity can prove critical when employed on ultra-lightweight systems or alongside mission critical computationally expensive processes. To achieve this objective, the algorithm proposes selected changes in the vision front-end and optimization back-end of visual-inertial odometry algorithms, both prior to execution and in real-time based on an online profiling of available resources. The method also utilizes information from the motion dynamics experienced by the system to manipulate parameters online. The general policy is demonstrated on three established algorithms, namely S-MSCKF, VINS-Mono and OKVIS and has been verified experimentally on the EuRoC dataset. The proposed approach achieved comparable performance at a fraction of the original computational cost.
Fusion of Complex Networks-based Global and Local Features for Texture Classification
Jun 20, 2021
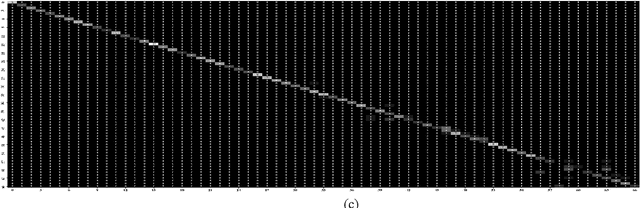
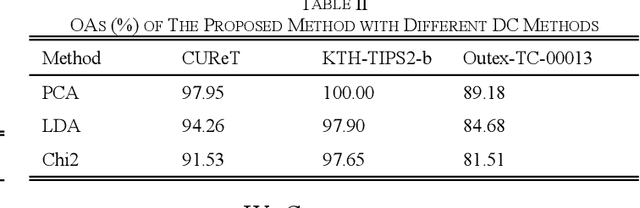
To realize accurate texture classification, this article proposes a complex networks (CN)-based multi-feature fusion method to recognize texture images. Specifically, we propose two feature extractors to detect the global and local features of texture images respectively. To capture the global features, we first map a texture image as an undirected graph based on pixel location and intensity, and three feature measurements are designed to further decipher the image features, which retains the image information as much as possible. Then, given the original band images (BI) and the generated feature images, we encode them based on the local binary patterns (LBP). Therefore, the global feature vector is obtained by concatenating four spatial histograms. To decipher the local features, we jointly transfer and fine-tune the pre-trained VGGNet-16 model. Next, we fuse and connect the middle outputs of max-pooling layers (MP), and generate the local feature vector by a global average pooling layer (GAP). Finally, the global and local feature vectors are concatenated to form the final feature representation of texture images. Experiment results show that the proposed method outperforms the state-of-the-art statistical descriptors and the deep convolutional neural networks (CNN) models.
Mutual Information Maximization for Simple and Accurate Part-Of-Speech Induction
Oct 30, 2018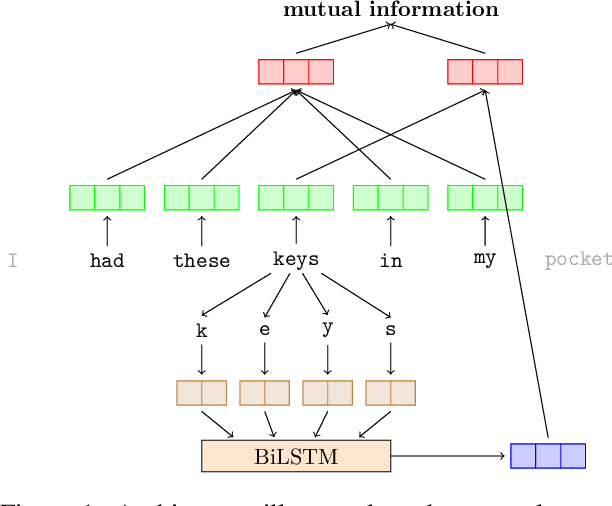
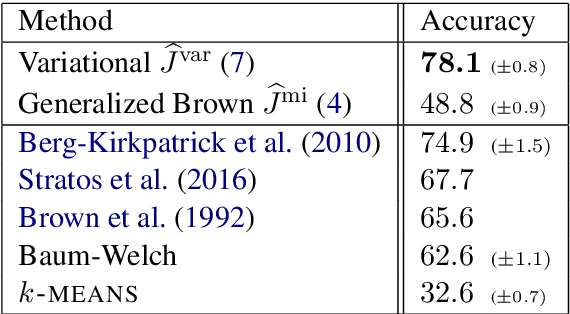

We address part-of-speech (POS) induction by maximizing the mutual information between the induced label and its context. We focus on two training objectives that are amenable to stochastic gradient descent (SGD): a novel generalization of the classical Brown clustering objective and a recently proposed variational lower bound. While both objectives are subject to noise in gradient updates, we show through analysis and experiments that the variational lower bound is robust whereas the generalized Brown objective is vulnerable. We obtain competitive performance on a multitude of datasets and languages with a simple architecture that encodes morphology and context.
Semi-supervised Semantic Segmentation with Directional Context-aware Consistency
Jun 27, 2021
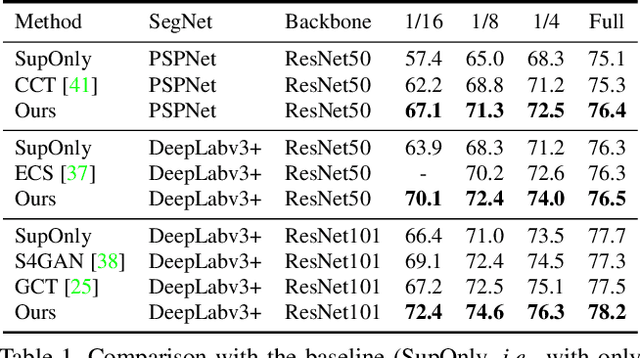
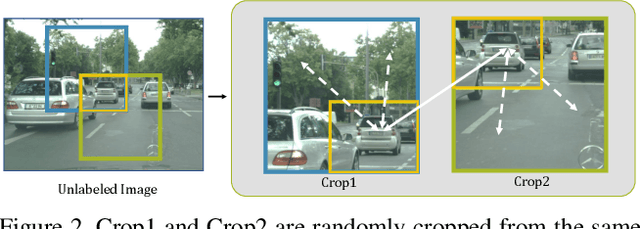
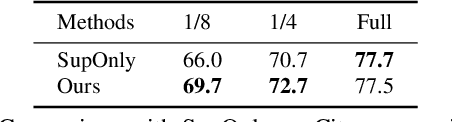
Semantic segmentation has made tremendous progress in recent years. However, satisfying performance highly depends on a large number of pixel-level annotations. Therefore, in this paper, we focus on the semi-supervised segmentation problem where only a small set of labeled data is provided with a much larger collection of totally unlabeled images. Nevertheless, due to the limited annotations, models may overly rely on the contexts available in the training data, which causes poor generalization to the scenes unseen before. A preferred high-level representation should capture the contextual information while not losing self-awareness. Therefore, we propose to maintain the context-aware consistency between features of the same identity but with different contexts, making the representations robust to the varying environments. Moreover, we present the Directional Contrastive Loss (DC Loss) to accomplish the consistency in a pixel-to-pixel manner, only requiring the feature with lower quality to be aligned towards its counterpart. In addition, to avoid the false-negative samples and filter the uncertain positive samples, we put forward two sampling strategies. Extensive experiments show that our simple yet effective method surpasses current state-of-the-art methods by a large margin and also generalizes well with extra image-level annotations.
Dynamic detection of mobile malware using smartphone data and machine learning
Jul 23, 2021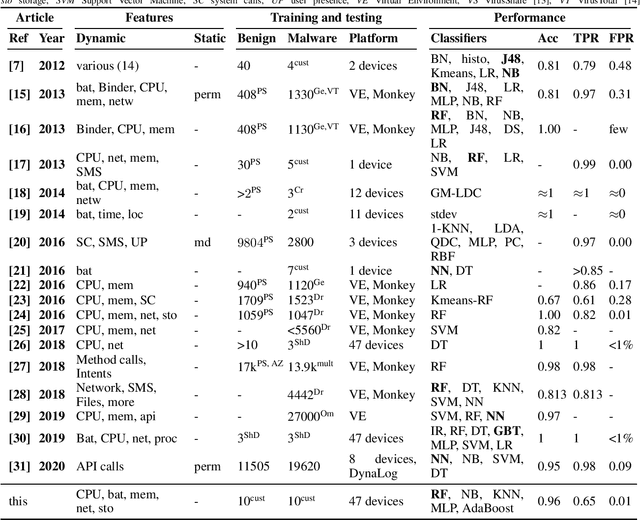
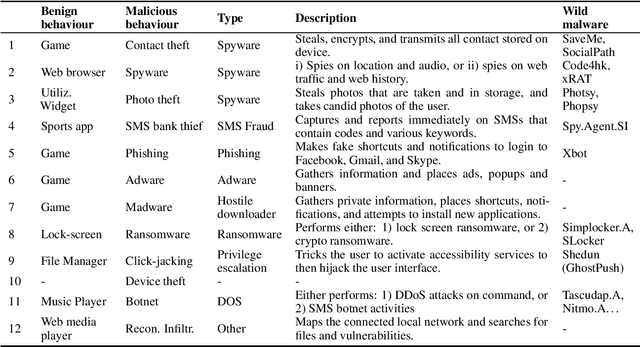
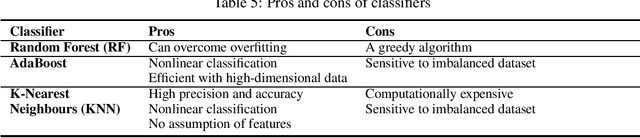
Mobile malware are malicious programs that target mobile devices. They are an increasing problem, as seen in the rise of detected mobile malware samples per year. The number of active smartphone users is expected to grow, stressing the importance of research on the detection of mobile malware. Detection methods for mobile malware exist but are still limited. In this paper, we provide an overview of the performance of machine learning (ML) techniques to detect malware on Android, without using privileged access. The ML-classifiers use device information such as the CPU usage, battery usage, and memory usage for the detection of 10 subtypes of Mobile Trojans on the Android Operating System (OS). We use a real-life dataset containing device and malware data from 47 users for a year (2016). We examine which features, i.e. aspects, of a device, are most important to monitor to detect (subtypes of) Mobile Trojans. The focus of this paper is on dynamic hardware features. Using these dynamic features we apply state-of-the-art machine learning classifiers: Random Forest, K-Nearest Neighbour, and AdaBoost. We show classification results on different feature sets, making a distinction between global device features, and specific app features. None of the measured feature sets require privileged access. Our results show that the Random Forest classifier performs best as a general malware classifier: across 10 subtypes of Mobile Trojans, it achieves an F1 score of 0.73 with a False Positive Rate (FPR) of 0.009 and a False Negative Rate (FNR) of 0.380. The Random Forest, K-Nearest Neighbours, and AdaBoost classifiers achieve F1 scores above 0.72, an FPR below 0.02 and, an FNR below 0.33, when trained separately to detect each subtype of Mobile Trojans.
AdaptCL: Efficient Collaborative Learning with Dynamic and Adaptive Pruning
Jun 27, 2021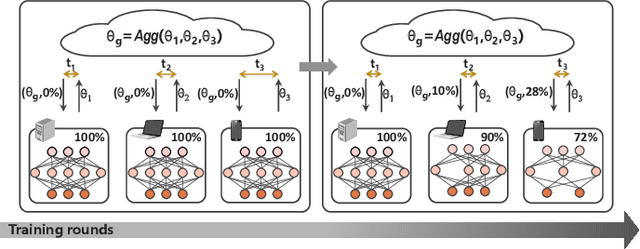
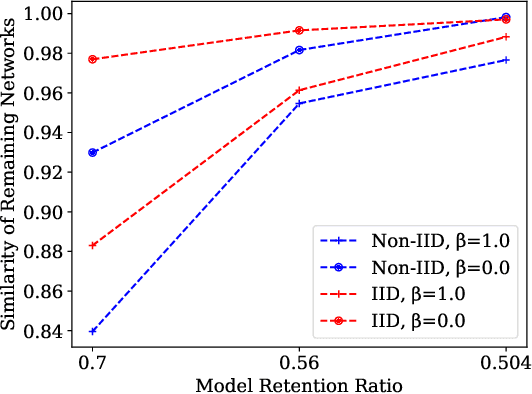
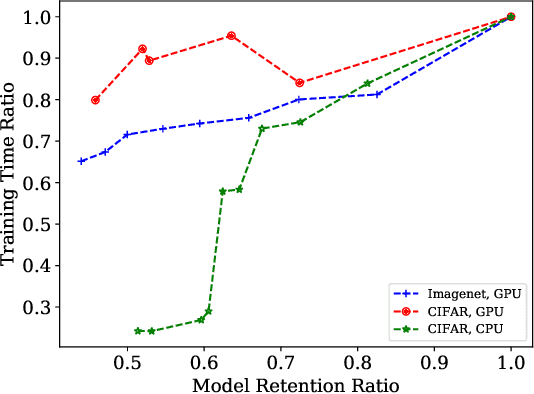

In multi-party collaborative learning, the parameter server sends a global model to each data holder for local training and then aggregates committed models globally to achieve privacy protection. However, both the dragger issue of synchronous collaborative learning and the staleness issue of asynchronous collaborative learning make collaborative learning inefficient in real-world heterogeneous environments. We propose a novel and efficient collaborative learning framework named AdaptCL, which generates an adaptive sub-model dynamically from the global base model for each data holder, without any prior information about worker capability. All workers (data holders) achieve approximately identical update time as the fastest worker by equipping them with capability-adapted pruned models. Thus the training process can be dramatically accelerated. Besides, we tailor the efficient pruned rate learning algorithm and pruning approach for AdaptCL. Meanwhile, AdaptCL provides a mechanism for handling the trade-off between accuracy and time overhead and can be combined with other techniques to accelerate training further. Empirical results show that AdaptCL introduces little computing and communication overhead. AdaptCL achieves time savings of more than 41\% on average and improves accuracy in a low heterogeneous environment. In a highly heterogeneous environment, AdaptCL achieves a training speedup of 6.2x with a slight loss of accuracy.
A Comprehensive Review on Non-Neural Networks Collaborative Filtering Recommendation Systems
Jun 20, 2021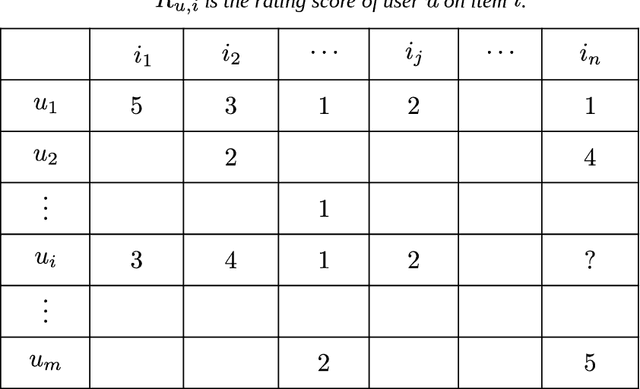
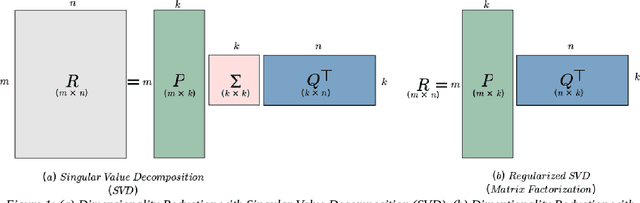
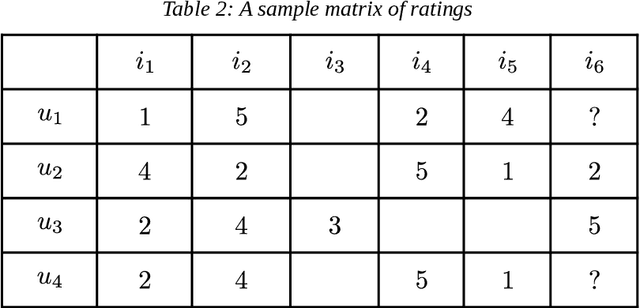
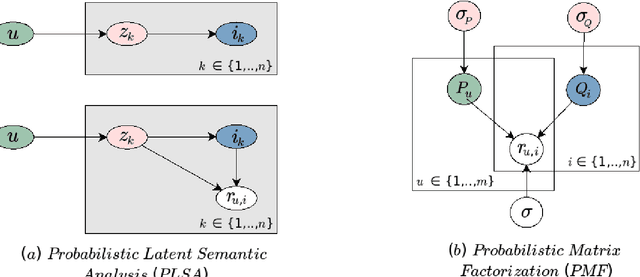
Over the past two decades, recommender systems have attracted a lot of interest due to the explosion in the amount of data in online applications. A particular attention has been paid to collaborative filtering, which is the most widely used in applications that involve information recommendations. Collaborative filtering (CF) uses the known preference of a group of users to make predictions and recommendations about the unknown preferences of other users (recommendations are made based on the past behavior of users). First introduced in the 1990s, a wide variety of increasingly successful models have been proposed. Due to the success of machine learning techniques in many areas, there has been a growing emphasis on the application of such algorithms in recommendation systems. In this article, we present an overview of the CF approaches for recommender systems, their two main categories, and their evaluation metrics. We focus on the application of classical Machine Learning algorithms to CF recommender systems by presenting their evolution from their first use-cases to advanced Machine Learning models. We attempt to provide a comprehensive and comparative overview of CF systems (with python implementations) that can serve as a guideline for research and practice in this area.
Gender Bias in Machine Translation
May 07, 2021
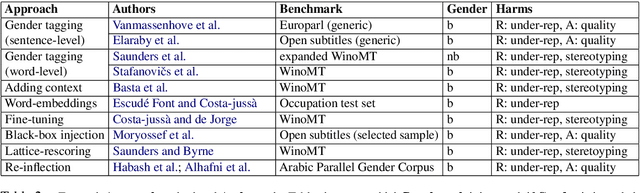
Machine translation (MT) technology has facilitated our daily tasks by providing accessible shortcuts for gathering, elaborating and communicating information. However, it can suffer from biases that harm users and society at large. As a relatively new field of inquiry, gender bias in MT still lacks internal cohesion, which advocates for a unified framework to ease future research. To this end, we: i) critically review current conceptualizations of bias in light of theoretical insights from related disciplines, ii) summarize previous analyses aimed at assessing gender bias in MT, iii) discuss the mitigating strategies proposed so far, and iv) point toward potential directions for future work.
Sentiment Analysis of Covid-19 Tweets using Evolutionary Classification-Based LSTM Model
Jun 13, 2021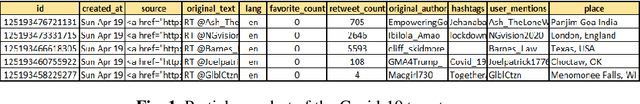



As the Covid-19 outbreaks rapidly all over the world day by day and also affects the lives of million, a number of countries declared complete lock-down to check its intensity. During this lockdown period, social media plat-forms have played an important role to spread information about this pandemic across the world, as people used to express their feelings through the social networks. Considering this catastrophic situation, we developed an experimental approach to analyze the reactions of people on Twitter taking into ac-count the popular words either directly or indirectly based on this pandemic. This paper represents the sentiment analysis on collected large number of tweets on Coronavirus or Covid-19. At first, we analyze the trend of public sentiment on the topics related to Covid-19 epidemic using an evolutionary classification followed by the n-gram analysis. Then we calculated the sentiment ratings on collected tweet based on their class. Finally, we trained the long-short term network using two types of rated tweets to predict sentiment on Covid-19 data and obtained an overall accuracy of 84.46%.
* 11 pages, 8 figures, 5 tables
An Efficient Cervical Whole Slide Image Analysis Framework Based on Multi-scale Semantic and Spatial Deep Features
Jul 03, 2021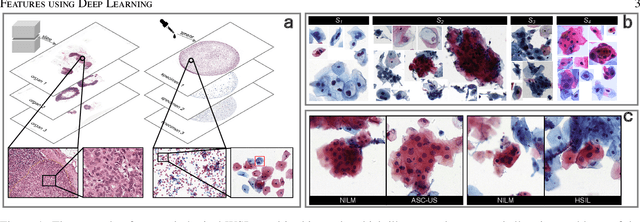
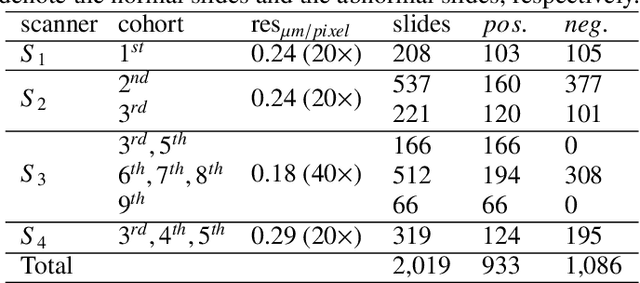
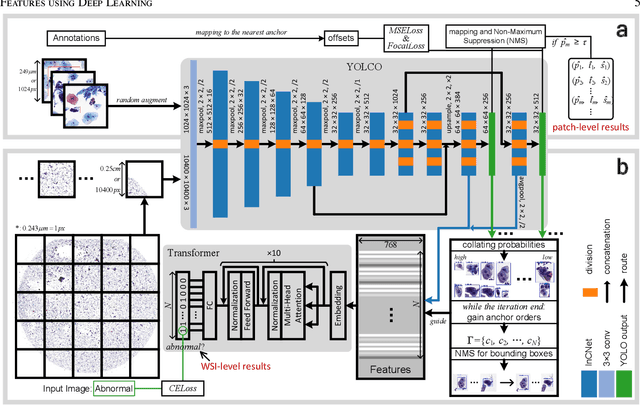
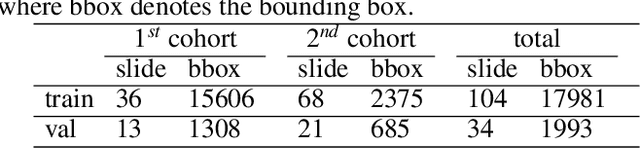
Digital gigapixel whole slide image (WSI) is widely used in clinical diagnosis, and automated WSI analysis is key for computer-aided diagnosis. Currently, analyzing the integrated descriptor of probabilities or feature maps from massive local patches encoded by ResNet classifier is the main manner for WSI-level prediction. Feature representations of the sparse and tiny lesion cells in cervical slides, however, are still challengeable for the under-promoted upstream encoders, while the unused spatial representations of cervical cells are the available features to supply the semantics analysis. As well as patches sampling with overlap and repetitive processing incur the inefficiency and the unpredictable side effect. This study designs a novel inline connection network (InCNet) by enriching the multi-scale connectivity to build the lightweight model named You Only Look Cytopathology Once (YOLCO) with the additional supervision of spatial information. The proposed model allows the input size enlarged to megapixel that can stitch the WSI without any overlap by the average repeats decreased from $10^3\sim10^4$ to $10^1\sim10^2$ for collecting features and predictions at two scales. Based on Transformer for classifying the integrated multi-scale multi-task features, the experimental results appear $0.872$ AUC score better and $2.51\times$ faster than the best conventional method in WSI classification on multicohort datasets of 2,019 slides from four scanning devices.