 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Conversational Machine Reading Comprehension for Vietnamese Healthcare Texts
May 15, 2021
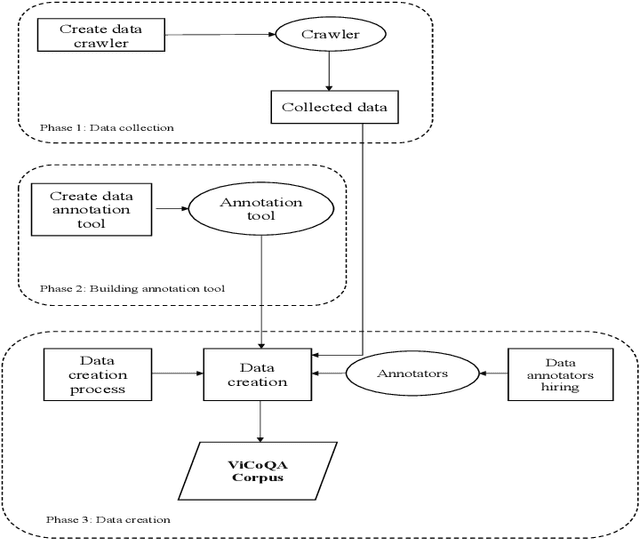
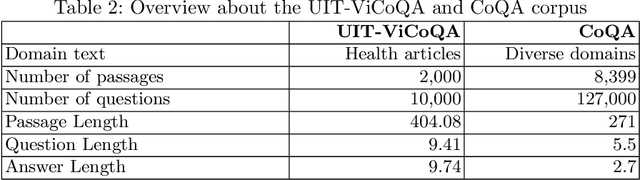
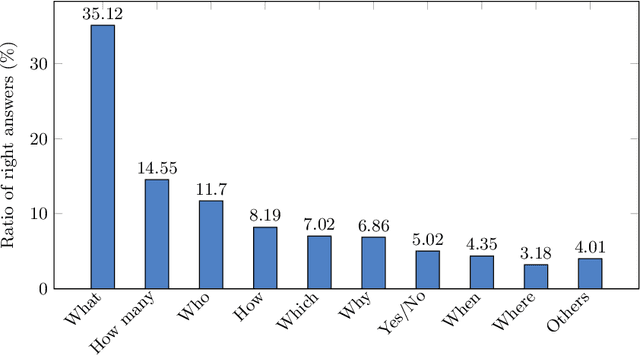

Machine reading comprehension (MRC) is a sub-field in natural language processing which aims to help computers understand unstructured texts and then answer questions related to them. In practice, conversation is an essential way to communicate and transfer information. To help machines understand conversation texts, we present UIT-ViCoQA - a new corpus for conversational machine reading comprehension in the Vietnamese language. This corpus consists of 10,000 questions with answers to over 2,000 conversations about health news articles. Then, we evaluate several baseline approaches for conversational machine comprehension on the UIT-ViCoQA corpus. The best model obtains an F1 score of 45.27%, which is 30.91 points behind human performance (76.18%), indicating that there is ample room for improvement.
Confidence Conditioned Knowledge Distillation
Jul 06, 2021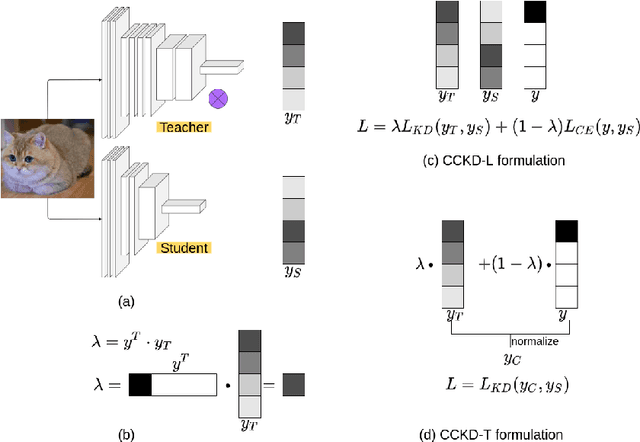
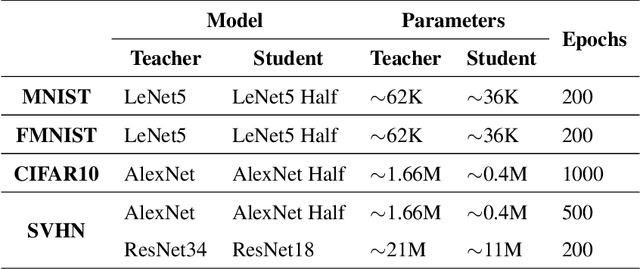
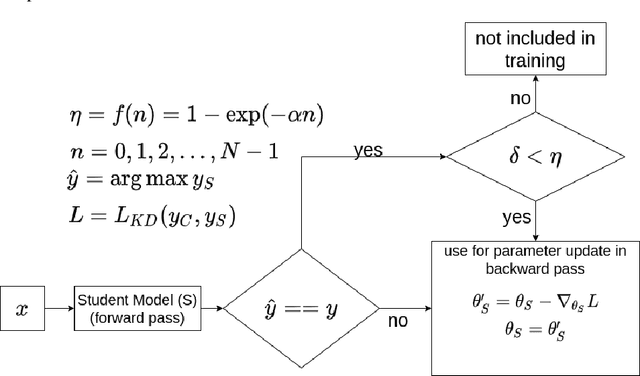
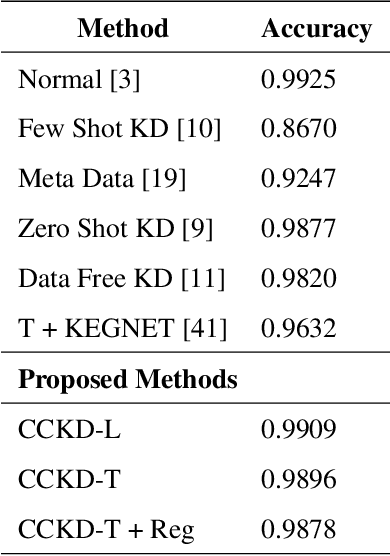
In this paper, a novel confidence conditioned knowledge distillation (CCKD) scheme for transferring the knowledge from a teacher model to a student model is proposed. Existing state-of-the-art methods employ fixed loss functions for this purpose and ignore the different levels of information that need to be transferred for different samples. In addition to that, these methods are also inefficient in terms of data usage. CCKD addresses these issues by leveraging the confidence assigned by the teacher model to the correct class to devise sample-specific loss functions (CCKD-L formulation) and targets (CCKD-T formulation). Further, CCKD improves the data efficiency by employing self-regulation to stop those samples from participating in the distillation process on which the student model learns faster. Empirical evaluations on several benchmark datasets show that CCKD methods achieve at least as much generalization performance levels as other state-of-the-art methods while being data efficient in the process. Student models trained through CCKD methods do not retain most of the misclassifications commited by the teacher model on the training set. Distillation through CCKD methods improves the resilience of the student models against adversarial attacks compared to the conventional KD method. Experiments show at least 3% increase in performance against adversarial attacks for the MNIST and the Fashion MNIST datasets, and at least 6% increase for the CIFAR10 dataset.
Unequal Error Protection Achieves Threshold Gains on BEC and BSC via Higher Fidelity Messages
Jan 22, 2021



Because of their capacity-approaching performance, graph-based codes have a wide range of applications, including communications and storage. In these codes, unequal error protection (UEP) can offer performance gains with limited rate loss. Recent empirical results in magnetic recording (MR) systems show that extra protection for the parity bits of a low-density parity-check (LDPC) code via constrained coding results in significant density gains. In particular, when UEP is applied via more reliable parity bits, higher fidelity messages of parity bits are spread to all bits by message passing algorithm, enabling performance gains. Threshold analysis is a tool to measure the effectiveness of a graph-based code or coding scheme. In this paper, we provide a theoretical analysis of this UEP idea using extrinsic information transfer (EXIT) charts in the binary erasure channel (BEC) and the binary symmetric channel (BSC). We use EXIT functions to investigate the effect of change in mutual information of parity bits on the overall coding scheme. We propose a setup in which parity bits of a repeat-accumulate (RA) LDPC code have lower erasure or crossover probabilities than input information bits. We derive the a-priori and extrinsic mutual information functions for check nodes and variable nodes of the code. After applying our UEP setup to the information functions, we formulate a linear programming problem to find the optimal degree distribution that maximizes the code rate under the decoding convergence constraint. Results show that UEP via higher fidelity parity bits achieves up to about $17\%$ and $28\%$ threshold gains on BEC and BSC, respectively.
PAS-MEF: Multi-exposure image fusion based on principal component analysis, adaptive well-exposedness and saliency map
May 25, 2021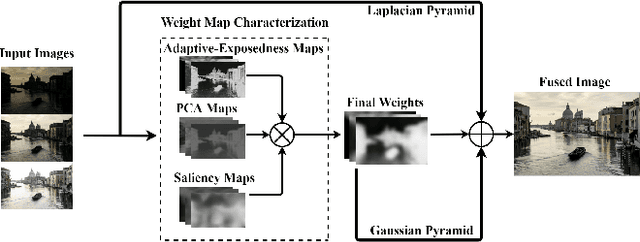
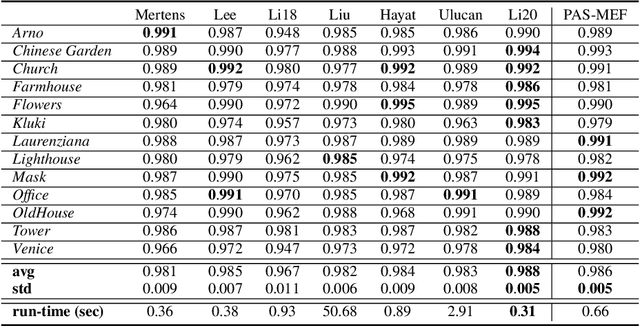


High dynamic range (HDR) imaging enables to immortalize natural scenes similar to the way that they are perceived by human observers. With regular low dynamic range (LDR) capture/display devices, significant details may not be preserved in images due to the huge dynamic range of natural scenes. To minimize the information loss and produce high quality HDR-like images for LDR screens, this study proposes an efficient multi-exposure fusion (MEF) approach with a simple yet effective weight extraction method relying on principal component analysis, adaptive well-exposedness and saliency maps. These weight maps are later refined through a guided filter and the fusion is carried out by employing a pyramidal decomposition. Experimental comparisons with existing techniques demonstrate that the proposed method produces very strong statistical and visual results.
End-to-end Alternating Optimization for Blind Super Resolution
May 14, 2021
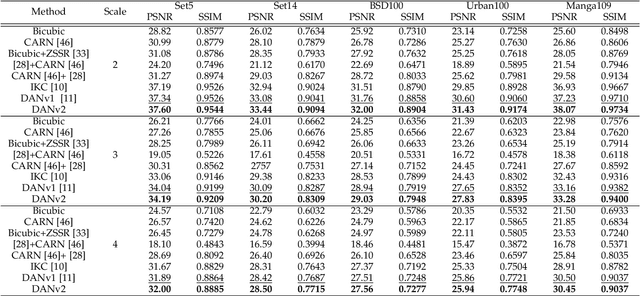
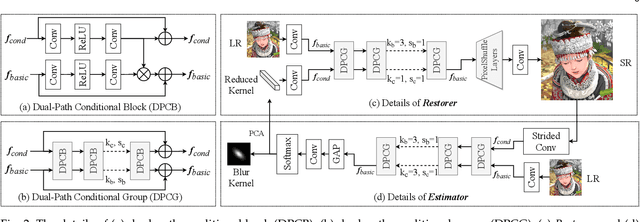

Previous methods decompose the blind super-resolution (SR) problem into two sequential steps: \textit{i}) estimating the blur kernel from given low-resolution (LR) image and \textit{ii}) restoring the SR image based on the estimated kernel. This two-step solution involves two independently trained models, which may not be well compatible with each other. A small estimation error of the first step could cause a severe performance drop of the second one. While on the other hand, the first step can only utilize limited information from the LR image, which makes it difficult to predict a highly accurate blur kernel. Towards these issues, instead of considering these two steps separately, we adopt an alternating optimization algorithm, which can estimate the blur kernel and restore the SR image in a single model. Specifically, we design two convolutional neural modules, namely \textit{Restorer} and \textit{Estimator}. \textit{Restorer} restores the SR image based on the predicted kernel, and \textit{Estimator} estimates the blur kernel with the help of the restored SR image. We alternate these two modules repeatedly and unfold this process to form an end-to-end trainable network. In this way, \textit{Estimator} utilizes information from both LR and SR images, which makes the estimation of the blur kernel easier. More importantly, \textit{Restorer} is trained with the kernel estimated by \textit{Estimator}, instead of the ground-truth kernel, thus \textit{Restorer} could be more tolerant to the estimation error of \textit{Estimator}. Extensive experiments on synthetic datasets and real-world images show that our model can largely outperform state-of-the-art methods and produce more visually favorable results at a much higher speed. The source code is available at \url{https://github.com/greatlog/DAN.git}.
The Emergence of Abstract and Episodic Neurons in Episodic Meta-RL
Apr 07, 2021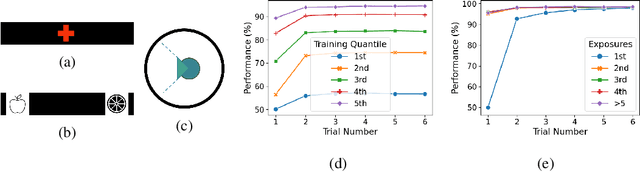
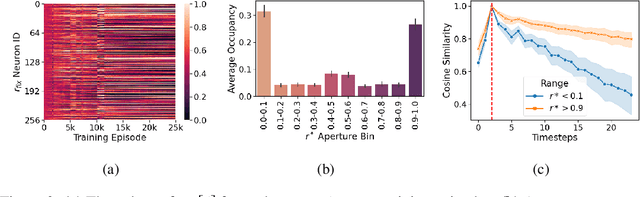
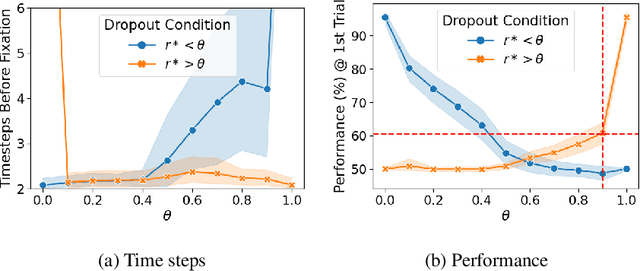
In this work, we analyze the reinstatement mechanism introduced by Ritter et al. (2018) to reveal two classes of neurons that emerge in the agent's working memory (an epLSTM cell) when trained using episodic meta-RL on an episodic variant of the Harlow visual fixation task. Specifically, Abstract neurons encode knowledge shared across tasks, while Episodic neurons carry information relevant for a specific episode's task.
Gradient Forward-Propagation for Large-Scale Temporal Video Modelling
Jun 15, 2021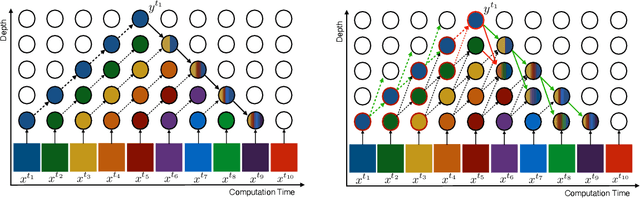
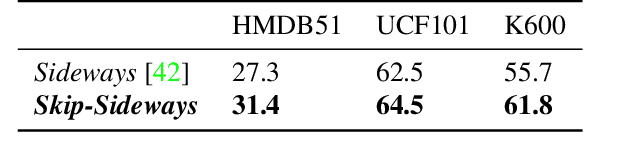
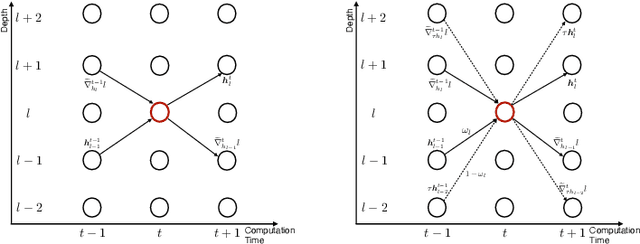

How can neural networks be trained on large-volume temporal data efficiently? To compute the gradients required to update parameters, backpropagation blocks computations until the forward and backward passes are completed. For temporal signals, this introduces high latency and hinders real-time learning. It also creates a coupling between consecutive layers, which limits model parallelism and increases memory consumption. In this paper, we build upon Sideways, which avoids blocking by propagating approximate gradients forward in time, and we propose mechanisms for temporal integration of information based on different variants of skip connections. We also show how to decouple computation and delegate individual neural modules to different devices, allowing distributed and parallel training. The proposed Skip-Sideways achieves low latency training, model parallelism, and, importantly, is capable of extracting temporal features, leading to more stable training and improved performance on real-world action recognition video datasets such as HMDB51, UCF101, and the large-scale Kinetics-600. Finally, we also show that models trained with Skip-Sideways generate better future frames than Sideways models, and hence they can better utilize motion cues.
StockBabble: A Conversational Financial Agent to support Stock Market Investors
Jun 15, 2021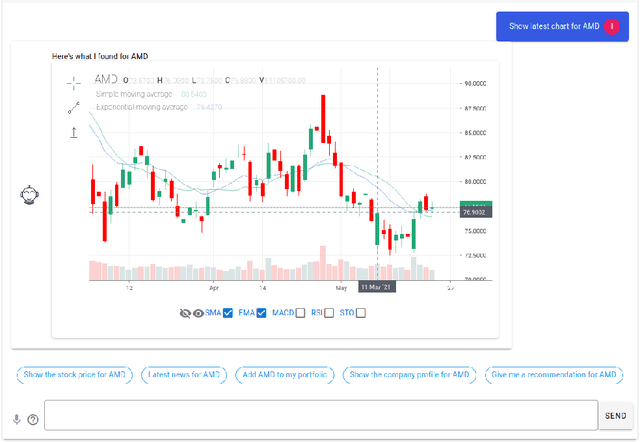
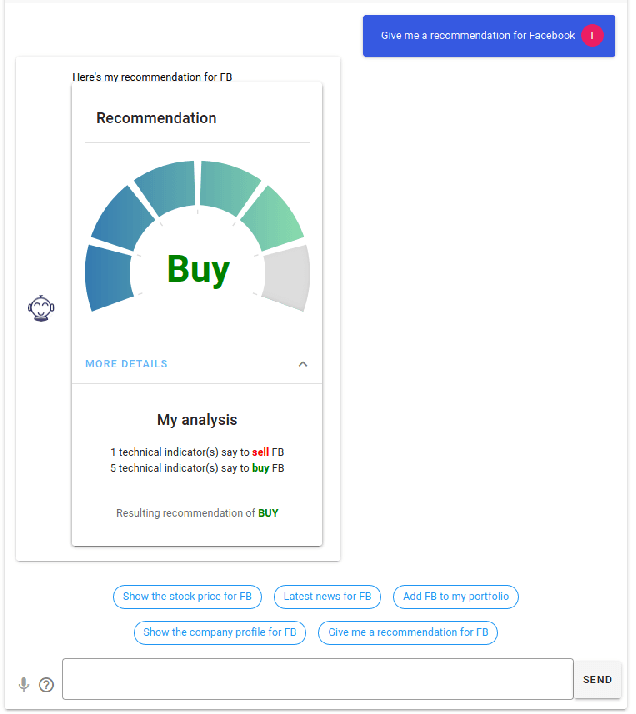
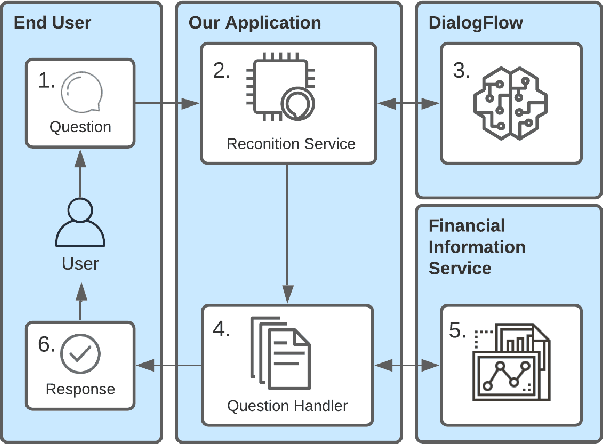
We introduce StockBabble, a conversational agent designed to support understanding and engagement with the stock market. StockBabble's value and novelty is in its ability to empower retail investors -- many of which may be new to investing -- and supplement their informational needs using a user-friendly agent. Users have the ability to query information on companies to retrieve a general and financial overview of a stock, including accessing the latest news and trading recommendations. They can also request charts which contain live prices and technical investment indicators, and add shares to a personal portfolio to allow performance monitoring over time. To evaluate our agent's potential, we conducted a user study with 15 participants. In total, 73% (11/15) of respondents said that they felt more confident in investing after using StockBabble, and all 15 would consider recommending it to others. These results are encouraging and suggest a wider appeal for such agents. Moreover, we believe this research can help to inform the design and development of future intelligent, financial personal assistants.
Augmented Tensor Decomposition with Stochastic Optimization
Jun 22, 2021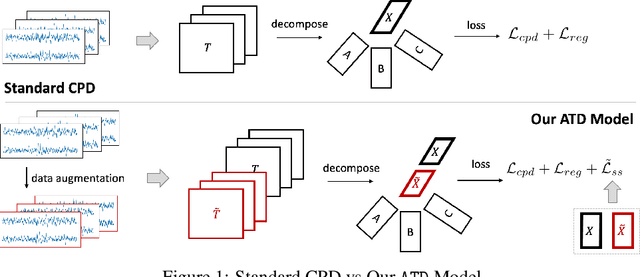

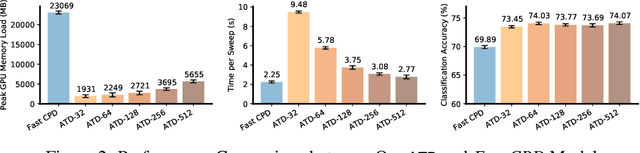
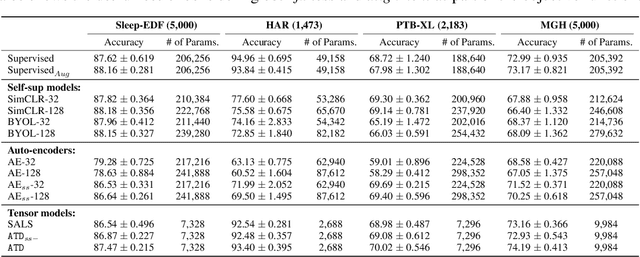
Tensor decompositions are powerful tools for dimensionality reduction and feature interpretation of multidimensional data such as signals. Existing tensor decomposition objectives (e.g., Frobenius norm) are designed for fitting raw data under statistical assumptions, which may not align with downstream classification tasks. Also, real-world tensor data are usually high-ordered and have large dimensions with millions or billions of entries. Thus, it is expensive to decompose the whole tensor with traditional algorithms. In practice, raw tensor data also contains redundant information while data augmentation techniques may be used to smooth out noise in samples. This paper addresses the above challenges by proposing augmented tensor decomposition (ATD), which effectively incorporates data augmentations to boost downstream classification. To reduce the memory footprint of the decomposition, we propose a stochastic algorithm that updates the factor matrices in a batch fashion. We evaluate ATD on multiple signal datasets. It shows comparable or better performance (e.g., up to 15% in accuracy) over self-supervised and autoencoder baselines with less than 5% of model parameters, achieves 0.6% ~ 1.3% accuracy gain over other tensor-based baselines, and reduces the memory footprint by 9X when compared to standard tensor decomposition algorithms.
CRFL: Certifiably Robust Federated Learning against Backdoor Attacks
Jun 15, 2021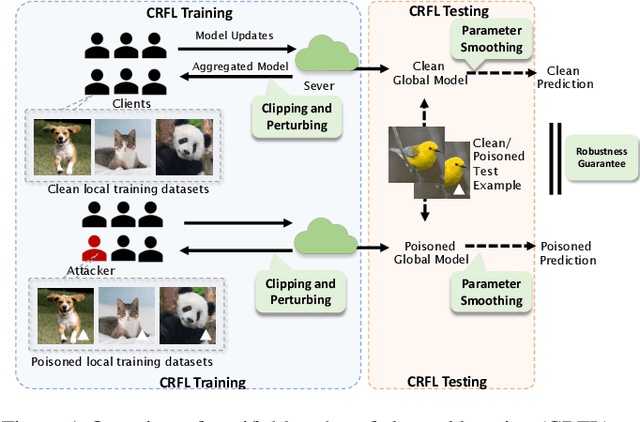

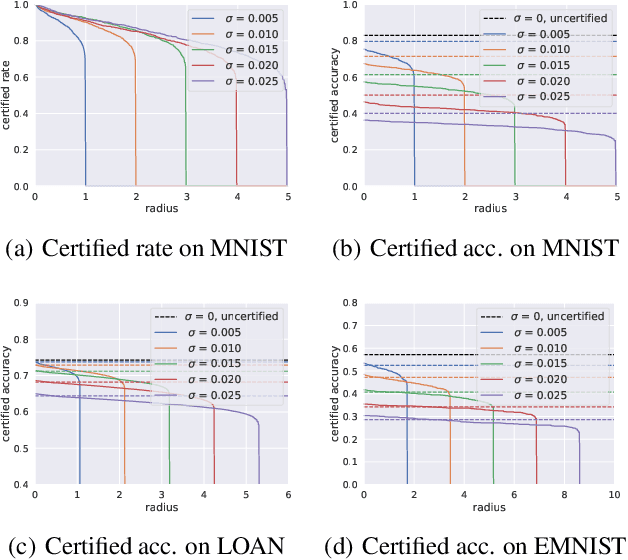
Federated Learning (FL) as a distributed learning paradigm that aggregates information from diverse clients to train a shared global model, has demonstrated great success. However, malicious clients can perform poisoning attacks and model replacement to introduce backdoors into the trained global model. Although there have been intensive studies designing robust aggregation methods and empirical robust federated training protocols against backdoors, existing approaches lack robustness certification. This paper provides the first general framework, Certifiably Robust Federated Learning (CRFL), to train certifiably robust FL models against backdoors. Our method exploits clipping and smoothing on model parameters to control the global model smoothness, which yields a sample-wise robustness certification on backdoors with limited magnitude. Our certification also specifies the relation to federated learning parameters, such as poisoning ratio on instance level, number of attackers, and training iterations. Practically, we conduct comprehensive experiments across a range of federated datasets, and provide the first benchmark for certified robustness against backdoor attacks in federated learning. Our code is available at https://github.com/AI-secure/CRFL.