 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards fully automated post-event data collection and analysis: pre-event and post-event information fusion
Jun 30, 2019
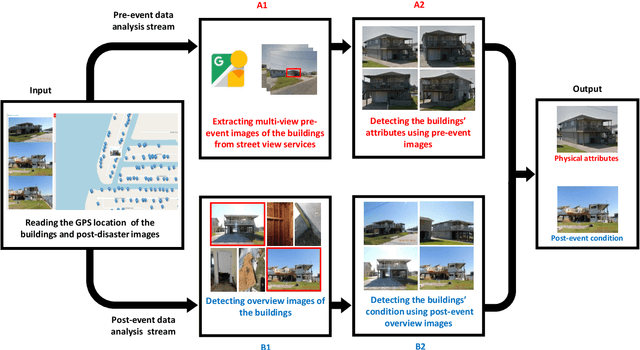
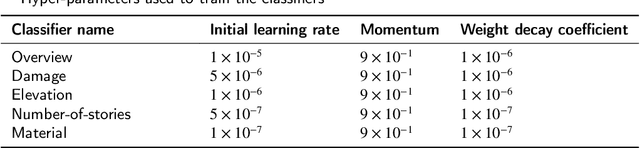
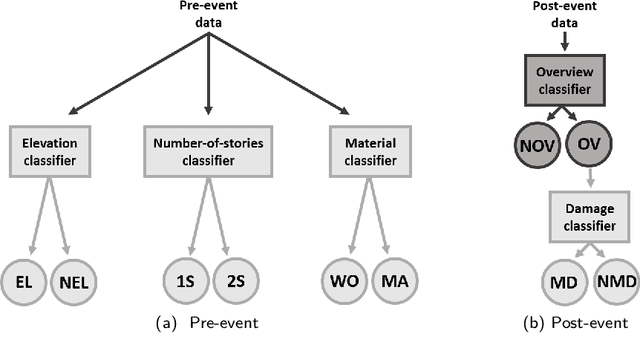

In post-event reconnaissance missions, engineers and researchers collect perishable information about damaged buildings in the affected geographical region to learn from the consequences of the event. A typical post-event reconnaissance mission is conducted by first doing a preliminary survey, followed by a detailed survey. The preliminary survey is typically conducted by driving slowly along a pre-determined route, observing the damage, and noting where further detailed data should be collected. This involves several manual, time-consuming steps that can be accelerated by exploiting recent advances in computer vision and artificial intelligence. The objective of this work is to develop and validate an automated technique to support post-event reconnaissance teams in the rapid collection of reliable and sufficiently comprehensive data, for planning the detailed survey. The technique incorporates several methods designed to automate the process of categorizing buildings based on their key physical attributes, and rapidly assessing their post-event structural condition. It is divided into pre-event and post-event streams, each intending to first extract all possible information about the target buildings using both pre-event and post-event images. Algorithms based on convolutional neural network (CNNs) are implemented for scene (image) classification. A probabilistic approach is developed to fuse the results obtained from analyzing several images to yield a robust decision regarding the attributes and condition of a target building. We validate the technique using post-event images captured during reconnaissance missions that took place after hurricanes Harvey and Irma. The validation data were collected by a structural wind and coastal engineering reconnaissance team, the National Science Foundation (NSF) funded Structural Extreme Events Reconnaissance (StEER) Network.
New/s/leak 2.0 - Multilingual Information Extraction and Visualization for Investigative Journalism
Jul 13, 2018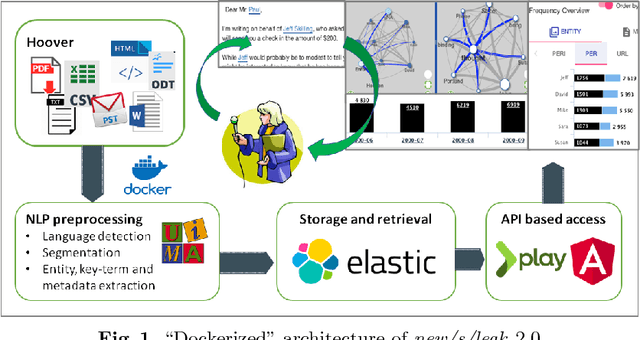
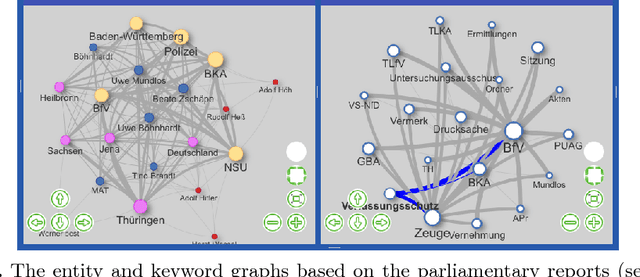
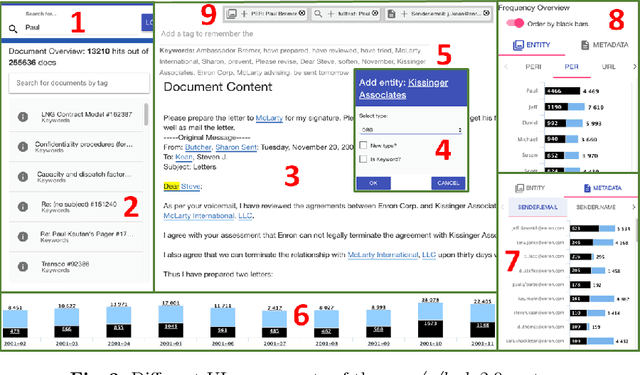
Investigative journalism in recent years is confronted with two major challenges: 1) vast amounts of unstructured data originating from large text collections such as leaks or answers to Freedom of Information requests, and 2) multi-lingual data due to intensified global cooperation and communication in politics, business and civil society. Faced with these challenges, journalists are increasingly cooperating in international networks. To support such collaborations, we present the new version of new/s/leak 2.0, our open-source software for content-based searching of leaks. It includes three novel main features: 1) automatic language detection and language-dependent information extraction for 40 languages, 2) entity and keyword visualization for efficient exploration, and 3) decentral deployment for analysis of confidential data from various formats. We illustrate the new analysis capabilities with an exemplary case study.
General Data Analytics With Applications To Visual Information Analysis: A Provable Backward-Compatible Semisimple Paradigm Over T-Algebra
Oct 31, 2020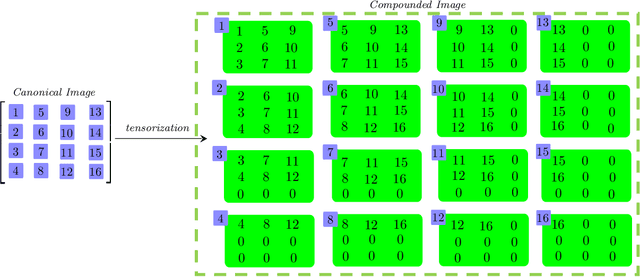
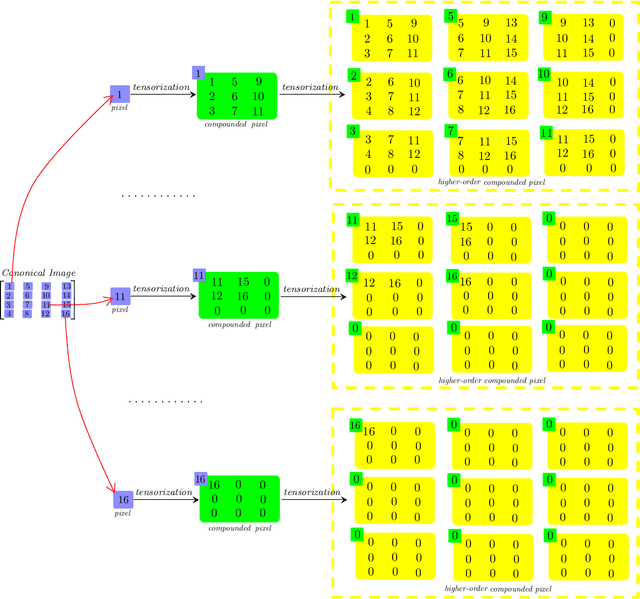

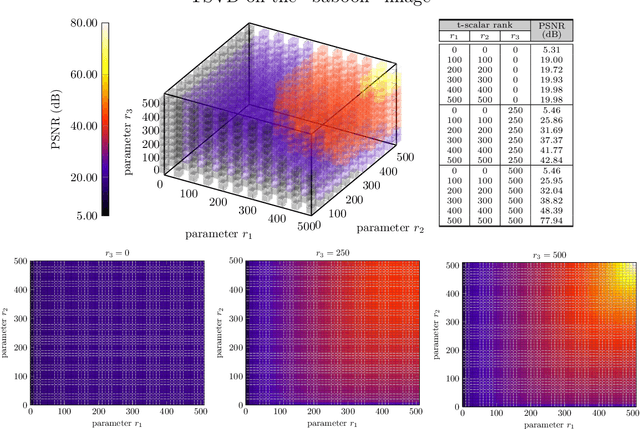
We consider a novel backward-compatible paradigm of general data analytics over a recently-reported semisimple algebra (called t-algebra). We study the abstract algebraic framework over the t-algebra by representing the elements of t-algebra by fix-sized multi-way arrays of complex numbers and the algebraic structure over the t-algebra by a collection of direct-product constituents. Over the t-algebra, many algorithms, if not all, are generalized in a straightforward manner using this new semisimple paradigm. To demonstrate the new paradigm's performance and its backward-compatibility, we generalize some canonical algorithms for visual pattern analysis. Experiments on public datasets show that the generalized algorithms compare favorably with their canonical counterparts.
A Multi-task convolutional neural network for blind stereoscopic image quality assessment using naturalness analysis
Jun 21, 2021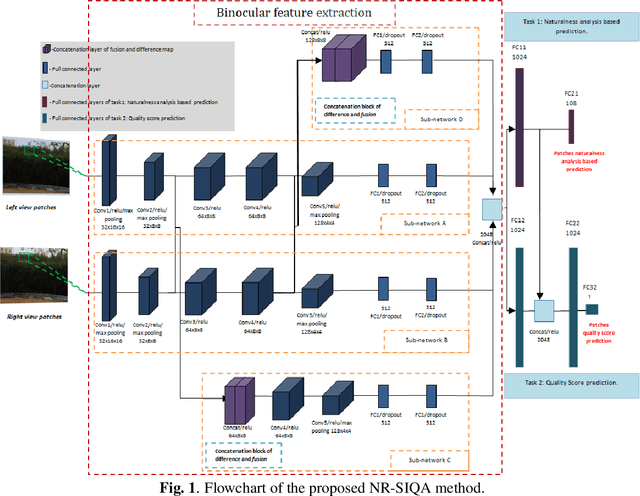
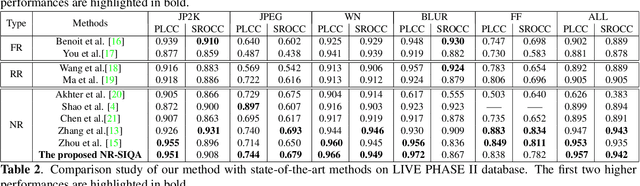
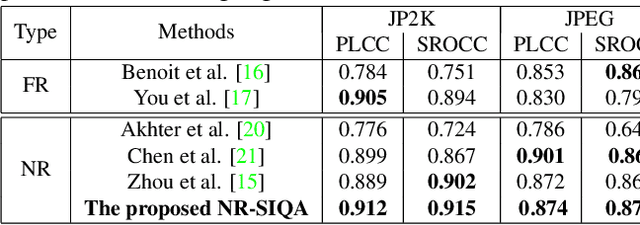
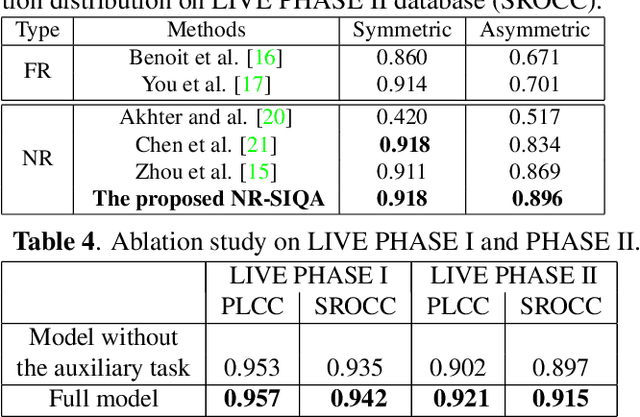
This paper addresses the problem of blind stereoscopic image quality assessment (NR-SIQA) using a new multi-task deep learning based-method. In the field of stereoscopic vision, the information is fairly distributed between the left and right views as well as the binocular phenomenon. In this work, we propose to integrate these characteristics to estimate the quality of stereoscopic images without reference through a convolutional neural network. Our method is based on two main tasks: the first task predicts naturalness analysis based features adapted to stereo images, while the second task predicts the quality of such images. The former, so-called auxiliary task, aims to find more robust and relevant features to improve the quality prediction. To do this, we compute naturalness-based features using a Natural Scene Statistics (NSS) model in the complex wavelet domain. It allows to capture the statistical dependency between pairs of the stereoscopic images. Experiments are conducted on the well known LIVE PHASE I and LIVE PHASE II databases. The results obtained show the relevance of our method when comparing with those of the state-of-the-art. Our code is available online on https://github.com/Bourbia-Salima/multitask-cnn-nrsiqa_2021.
EventPlus: A Temporal Event Understanding Pipeline
Jan 13, 2021
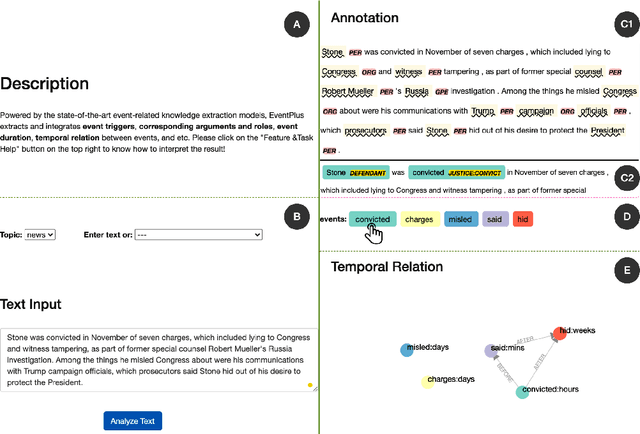


We present EventPlus, a temporal event understanding pipeline that integrates various state-of-the-art event understanding components including event trigger and type detection, event argument detection, event duration and temporal relation extraction. Event information, especially event temporal knowledge, is a type of common sense knowledge that helps people understand how stories evolve and provides predictive hints for future events. EventPlus as the first comprehensive temporal event understanding pipeline provides a convenient tool for users to quickly obtain annotations about events and their temporal information for any user-provided document. Furthermore, we show EventPlus can be easily adapted to other domains (e.g., biomedical domain). We make EventPlus publicly available to facilitate event-related information extraction and downstream applications.
Interventional Video Grounding with Dual Contrastive Learning
Jun 21, 2021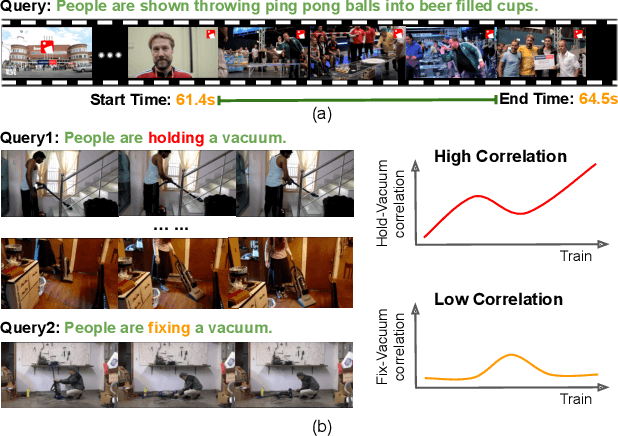
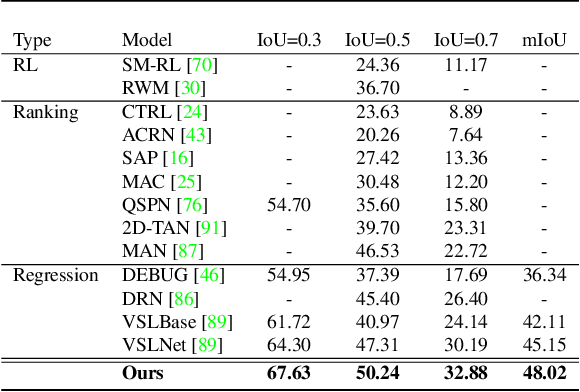
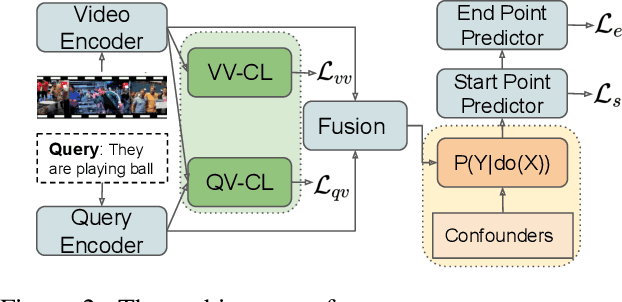
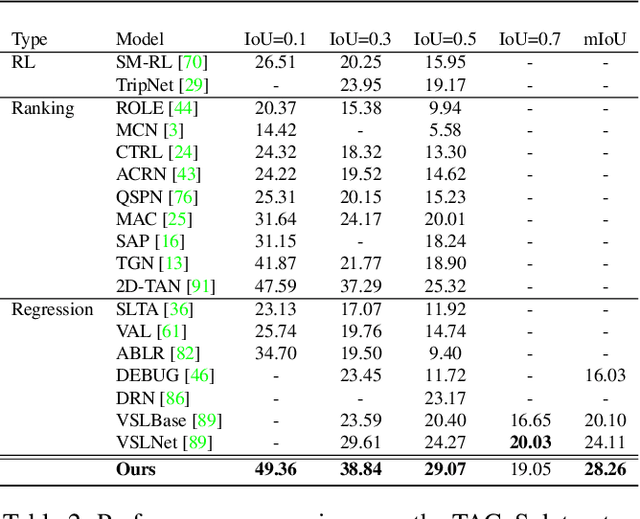
Video grounding aims to localize a moment from an untrimmed video for a given textual query. Existing approaches focus more on the alignment of visual and language stimuli with various likelihood-based matching or regression strategies, i.e., P(Y|X). Consequently, these models may suffer from spurious correlations between the language and video features due to the selection bias of the dataset. 1) To uncover the causality behind the model and data, we first propose a novel paradigm from the perspective of the causal inference, i.e., interventional video grounding (IVG) that leverages backdoor adjustment to deconfound the selection bias based on structured causal model (SCM) and do-calculus P(Y|do(X)). Then, we present a simple yet effective method to approximate the unobserved confounder as it cannot be directly sampled from the dataset. 2) Meanwhile, we introduce a dual contrastive learning approach (DCL) to better align the text and video by maximizing the mutual information (MI) between query and video clips, and the MI between start/end frames of a target moment and the others within a video to learn more informative visual representations. Experiments on three standard benchmarks show the effectiveness of our approaches.
Node2Seq: Towards Trainable Convolutions in Graph Neural Networks
Jan 06, 2021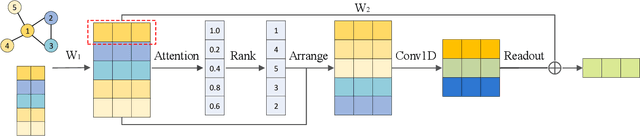

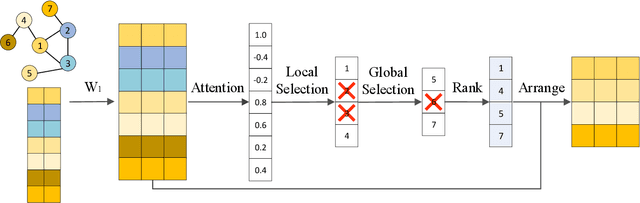
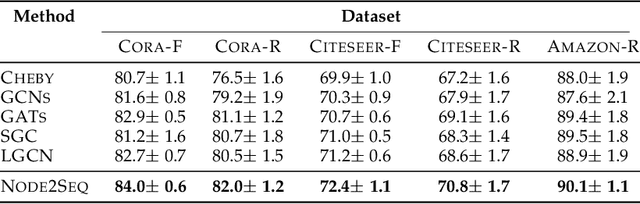
Investigating graph feature learning becomes essentially important with the emergence of graph data in many real-world applications. Several graph neural network approaches are proposed for node feature learning and they generally follow a neighboring information aggregation scheme to learn node features. While great performance has been achieved, the weights learning for different neighboring nodes is still less explored. In this work, we propose a novel graph network layer, known as Node2Seq, to learn node embeddings with explicitly trainable weights for different neighboring nodes. For a target node, our method sorts its neighboring nodes via attention mechanism and then employs 1D convolutional neural networks (CNNs) to enable explicit weights for information aggregation. In addition, we propose to incorporate non-local information for feature learning in an adaptive manner based on the attention scores. Experimental results demonstrate the effectiveness of our proposed Node2Seq layer and show that the proposed adaptively non-local information learning can improve the performance of feature learning.
Iterative Methods for Private Synthetic Data: Unifying Framework and New Methods
Jun 14, 2021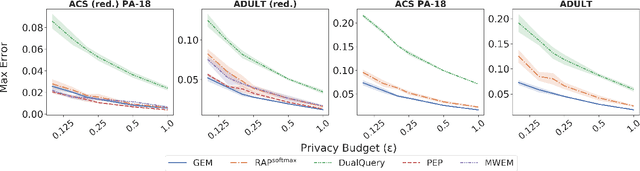
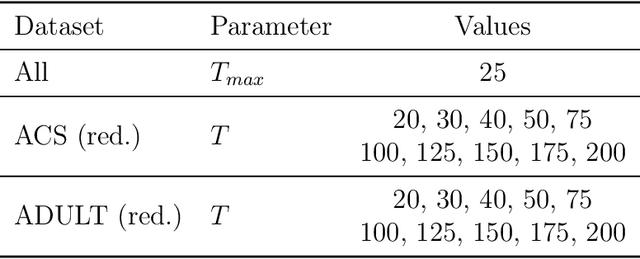
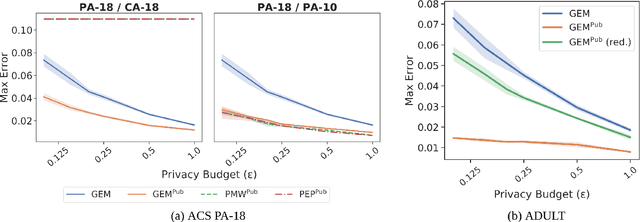
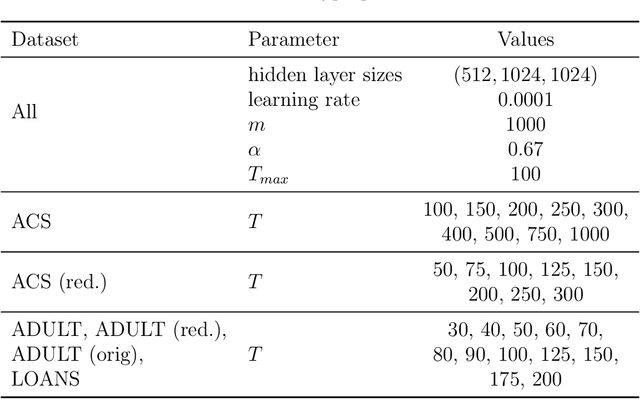
We study private synthetic data generation for query release, where the goal is to construct a sanitized version of a sensitive dataset, subject to differential privacy, that approximately preserves the answers to a large collection of statistical queries. We first present an algorithmic framework that unifies a long line of iterative algorithms in the literature. Under this framework, we propose two new methods. The first method, private entropy projection (PEP), can be viewed as an advanced variant of MWEM that adaptively reuses past query measurements to boost accuracy. Our second method, generative networks with the exponential mechanism (GEM), circumvents computational bottlenecks in algorithms such as MWEM and PEP by optimizing over generative models parameterized by neural networks, which capture a rich family of distributions while enabling fast gradient-based optimization. We demonstrate that PEP and GEM empirically outperform existing algorithms. Furthermore, we show that GEM nicely incorporates prior information from public data while overcoming limitations of PMW^Pub, the existing state-of-the-art method that also leverages public data.
Planning Multimodal Exploratory Actions for Online Robot Attribute Learning
Jun 06, 2021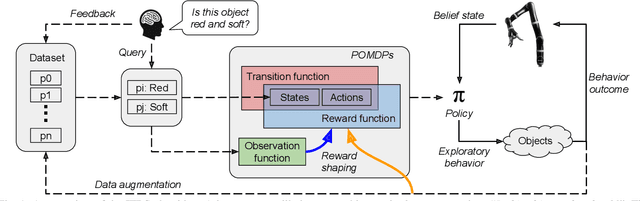

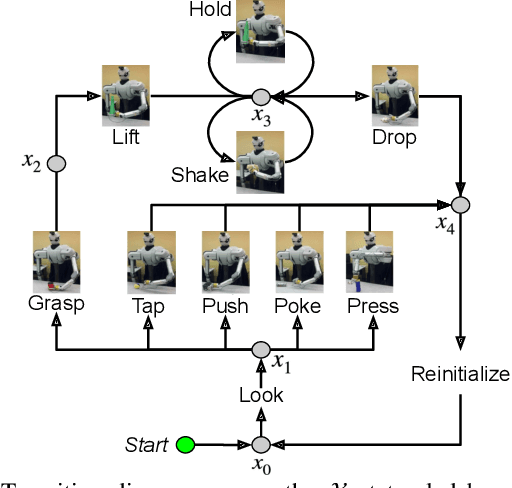
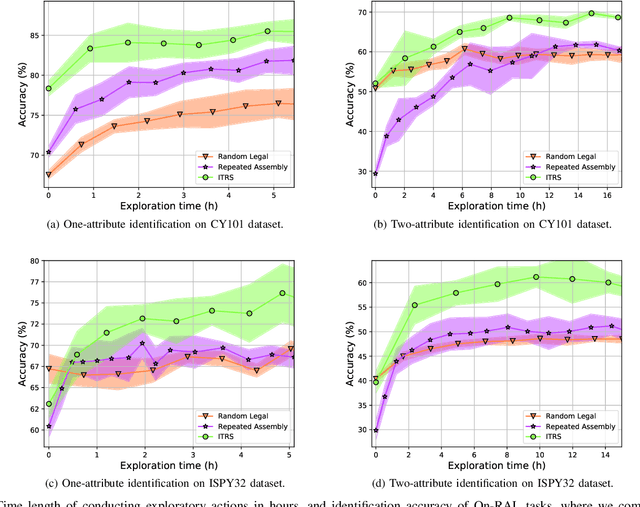
Robots frequently need to perceive object attributes, such as "red," "heavy," and "empty," using multimodal exploratory actions, such as "look," "lift," and "shake." Robot attribute learning algorithms aim to learn an observation model for each perceivable attribute given an exploratory action. Once the attribute models are learned, they can be used to identify attributes of new objects, answering questions, such as "Is this object red and empty?" Attribute learning and identification are being treated as two separate problems in the literature. In this paper, we first define a new problem called online robot attribute learning (On-RAL), where the robot works on attribute learning and attribute identification simultaneously. Then we develop an algorithm called information-theoretic reward shaping (ITRS) that actively addresses the trade-off between exploration and exploitation in On-RAL problems. ITRS was compared with competitive robot attribute learning baselines, and experimental results demonstrate ITRS' superiority in learning efficiency and identification accuracy.
Attribute Selection using Contranominal Scales
Jun 21, 2021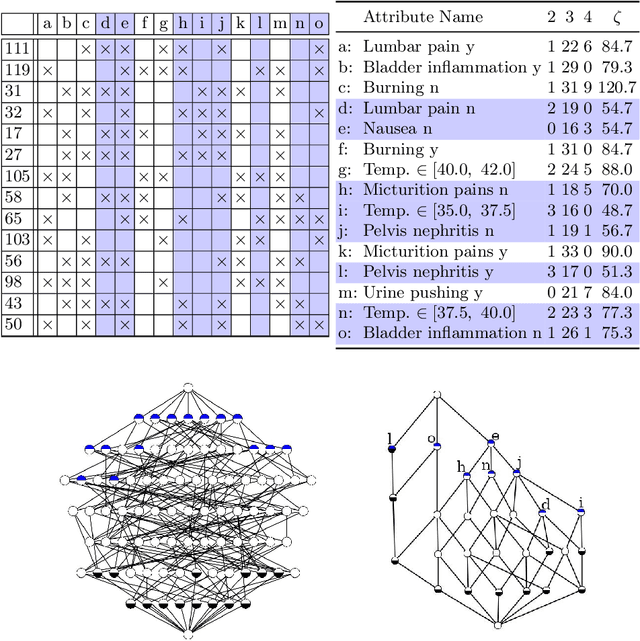
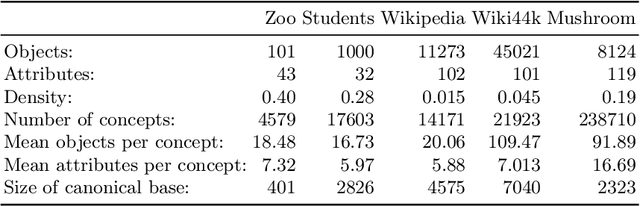
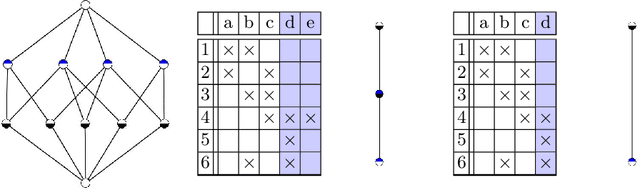
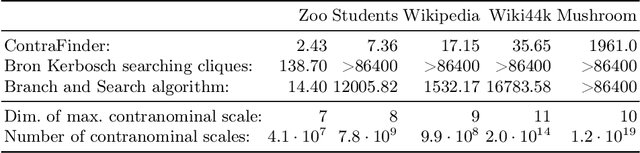
Formal Concept Analysis (FCA) allows to analyze binary data by deriving concepts and ordering them in lattices. One of the main goals of FCA is to enable humans to comprehend the information that is encapsulated in the data; however, the large size of concept lattices is a limiting factor for the feasibility of understanding the underlying structural properties. The size of such a lattice depends on the number of subcontexts in the corresponding formal context that are isomorphic to a contranominal scale of high dimension. In this work, we propose the algorithm ContraFinder that enables the computation of all contranominal scales of a given formal context. Leveraging this algorithm, we introduce delta-adjusting, a novel approach in order to decrease the number of contranominal scales in a formal context by the selection of an appropriate attribute subset. We demonstrate that delta-adjusting a context reduces the size of the hereby emerging sub-semilattice and that the implication set is restricted to meaningful implications. This is evaluated with respect to its associated knowledge by means of a classification task. Hence, our proposed technique strongly improves understandability while preserving important conceptual structures.