 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Planning Multimodal Exploratory Actions for Online Robot Attribute Learning
Jun 06, 2021
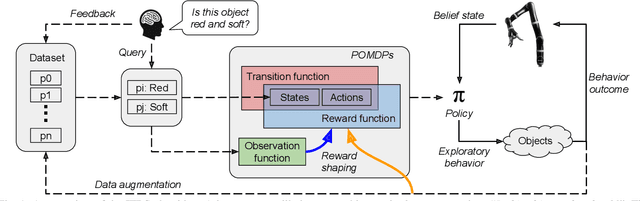

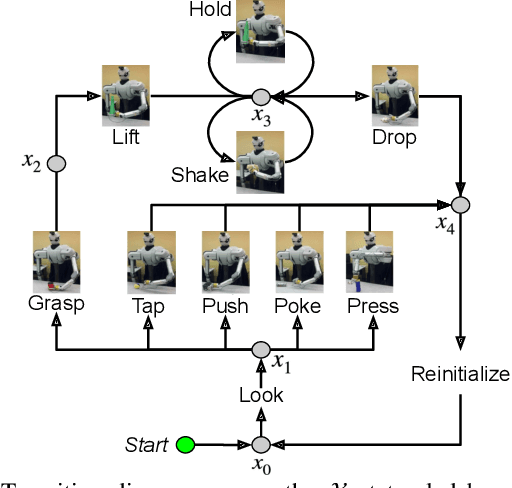
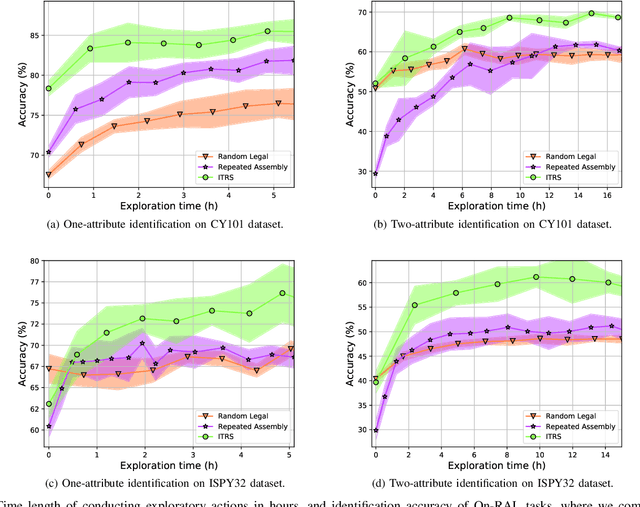
Robots frequently need to perceive object attributes, such as "red," "heavy," and "empty," using multimodal exploratory actions, such as "look," "lift," and "shake." Robot attribute learning algorithms aim to learn an observation model for each perceivable attribute given an exploratory action. Once the attribute models are learned, they can be used to identify attributes of new objects, answering questions, such as "Is this object red and empty?" Attribute learning and identification are being treated as two separate problems in the literature. In this paper, we first define a new problem called online robot attribute learning (On-RAL), where the robot works on attribute learning and attribute identification simultaneously. Then we develop an algorithm called information-theoretic reward shaping (ITRS) that actively addresses the trade-off between exploration and exploitation in On-RAL problems. ITRS was compared with competitive robot attribute learning baselines, and experimental results demonstrate ITRS' superiority in learning efficiency and identification accuracy.
Interpreting and Predicting Tactile Signals for the SynTouch BioTac
Jan 14, 2021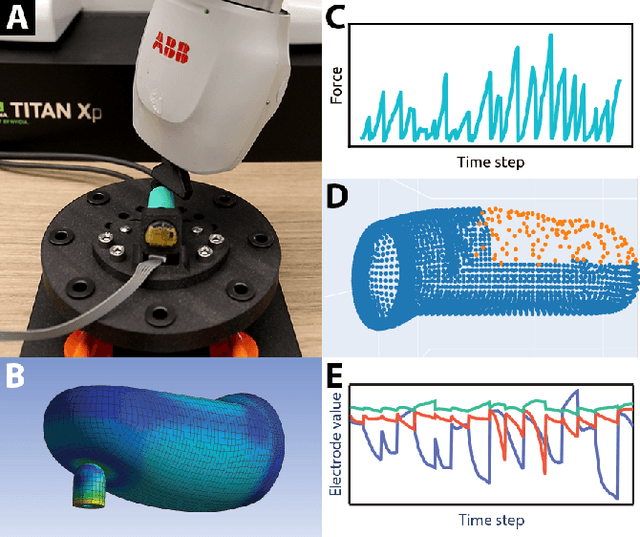
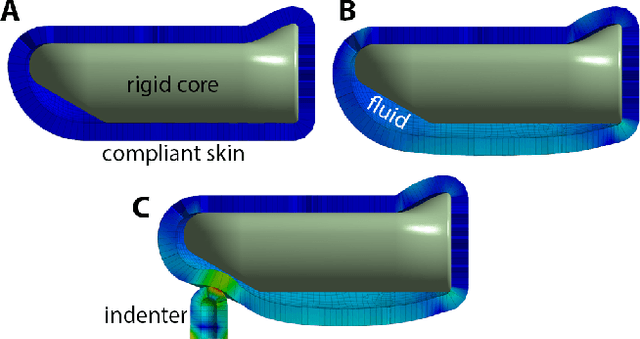

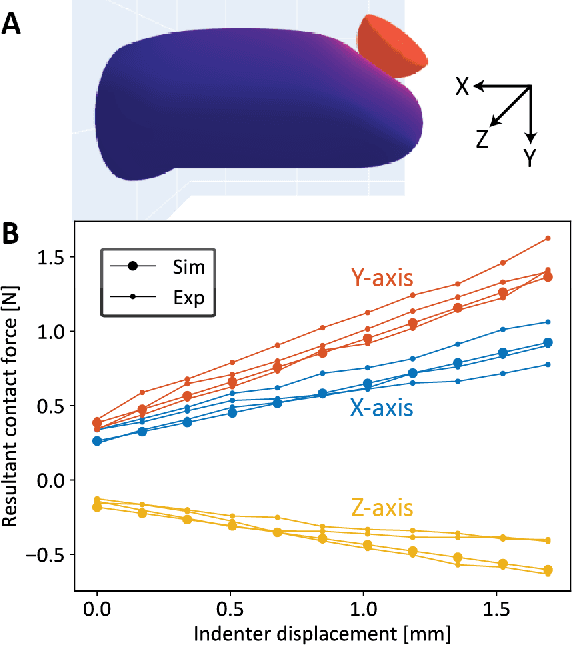
In the human hand, high-density contact information provided by afferent neurons is essential for many human grasping and manipulation capabilities. In contrast, robotic tactile sensors, including the state-of-the-art SynTouch BioTac, are typically used to provide low-density contact information, such as contact location, center of pressure, and net force. Although useful, these data do not convey or leverage the rich information content that some tactile sensors naturally measure. This research extends robotic tactile sensing beyond reduced-order models through 1) the automated creation of a precise experimental tactile dataset for the BioTac over a diverse range of physical interactions, 2) a 3D finite element (FE) model of the BioTac, which complements the experimental dataset with high-density, distributed contact data, 3) neural-network-based mappings from raw BioTac signals to not only low-dimensional experimental data, but also high-density FE deformation fields, and 4) mappings from the FE deformation fields to the raw signals themselves. The high-density data streams can provide a far greater quantity of interpretable information for grasping and manipulation algorithms than previously accessible.
Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better
Jun 21, 2021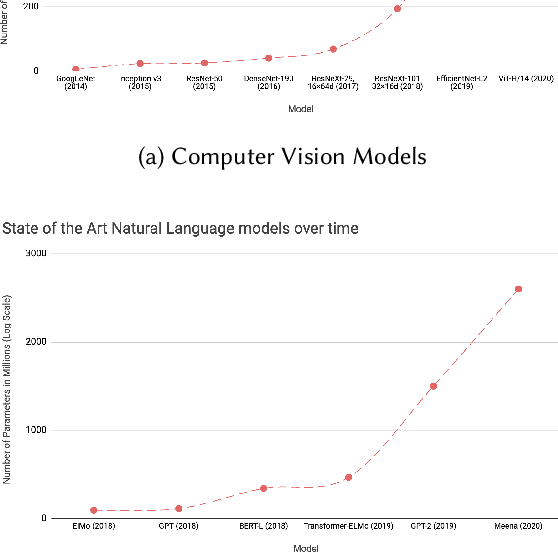
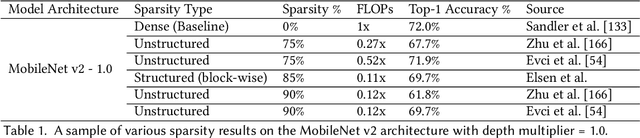
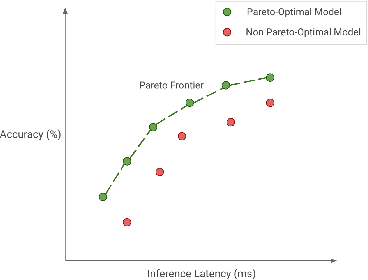

Deep Learning has revolutionized the fields of computer vision, natural language understanding, speech recognition, information retrieval and more. However, with the progressive improvements in deep learning models, their number of parameters, latency, resources required to train, etc. have all have increased significantly. Consequently, it has become important to pay attention to these footprint metrics of a model as well, not just its quality. We present and motivate the problem of efficiency in deep learning, followed by a thorough survey of the five core areas of model efficiency (spanning modeling techniques, infrastructure, and hardware) and the seminal work there. We also present an experiment-based guide along with code, for practitioners to optimize their model training and deployment. We believe this is the first comprehensive survey in the efficient deep learning space that covers the landscape of model efficiency from modeling techniques to hardware support. Our hope is that this survey would provide the reader with the mental model and the necessary understanding of the field to apply generic efficiency techniques to immediately get significant improvements, and also equip them with ideas for further research and experimentation to achieve additional gains.
Complexity of Manipulation with Partial Information in Voting
Jul 13, 2017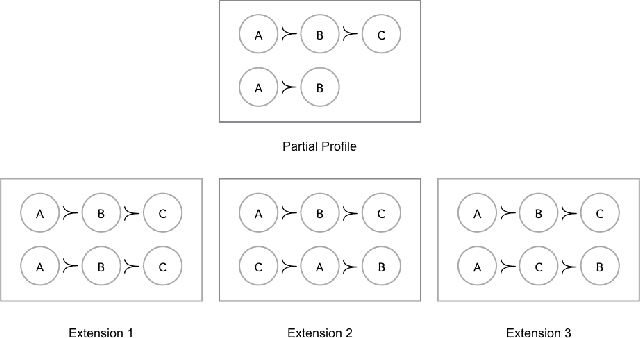
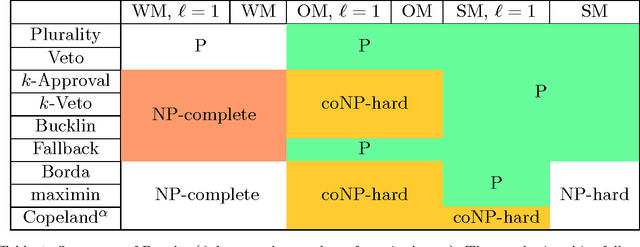

The Coalitional Manipulation problem has been studied extensively in the literature for many voting rules. However, most studies have focused on the complete information setting, wherein the manipulators know the votes of the non-manipulators. While this assumption is reasonable for purposes of showing intractability, it is unrealistic for algorithmic considerations. In most real-world scenarios, it is impractical for the manipulators to have accurate knowledge of all the other votes. In this paper, we investigate manipulation with incomplete information. In our framework, the manipulators know a partial order for each voter that is consistent with the true preference of that voter. In this setting, we formulate three natural computational notions of manipulation, namely weak, opportunistic, and strong manipulation. We say that an extension of a partial order is if there exists a manipulative vote for that extension. 1. Weak Manipulation (WM): the manipulators seek to vote in a way that makes their preferred candidate win in at least one extension of the partial votes of the non-manipulators. 2. Opportunistic Manipulation (OM): the manipulators seek to vote in a way that makes their preferred candidate win in every viable extension of the partial votes of the non-manipulators. 3. Strong Manipulation (SM): the manipulators seek to vote in a way that makes their preferred candidate win in every extension of the partial votes of the non-manipulators. We consider several scenarios for which the traditional manipulation problems are easy (for instance, Borda with a single manipulator). For many of them, the corresponding manipulative questions that we propose turn out to be computationally intractable. Our hardness results often hold even when very little information is missing, or in other words, even when the instances are quite close to the complete information setting.
Total Generate: Cycle in Cycle Generative Adversarial Networks for Generating Human Faces, Hands, Bodies, and Natural Scenes
Jun 21, 2021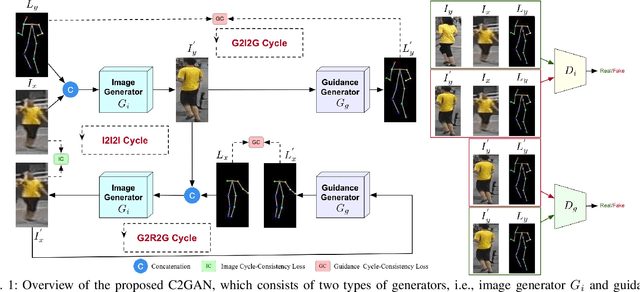

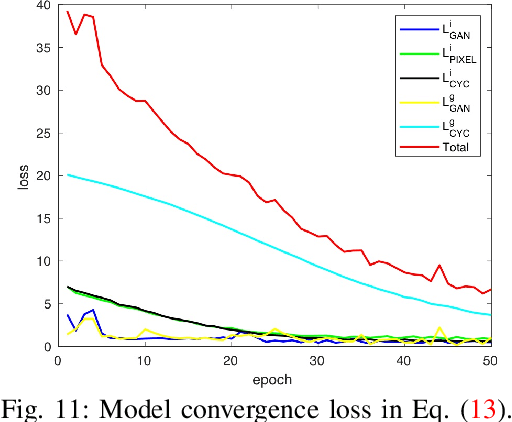
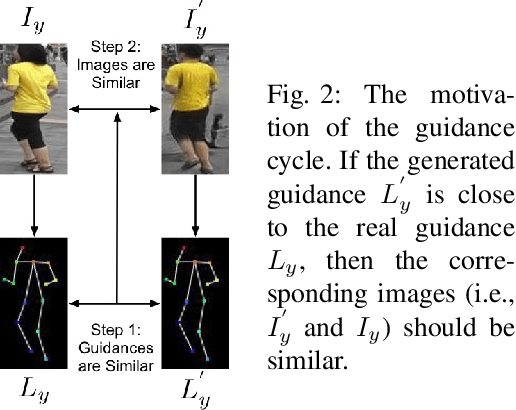
We propose a novel and unified Cycle in Cycle Generative Adversarial Network (C2GAN) for generating human faces, hands, bodies, and natural scenes. Our proposed C2GAN is a cross-modal model exploring the joint exploitation of the input image data and guidance data in an interactive manner. C2GAN contains two different generators, i.e., an image-generation generator and a guidance-generation generator. Both generators are mutually connected and trained in an end-to-end fashion and explicitly form three cycled subnets, i.e., one image generation cycle and two guidance generation cycles. Each cycle aims at reconstructing the input domain and simultaneously produces a useful output involved in the generation of another cycle. In this way, the cycles constrain each other implicitly providing complementary information from both image and guidance modalities and bringing an extra supervision gradient across the cycles, facilitating a more robust optimization of the whole model. Extensive results on four guided image-to-image translation subtasks demonstrate that the proposed C2GAN is effective in generating more realistic images compared with state-of-the-art models. The code is available at https://github.com/Ha0Tang/C2GAN.
A Continuous Information Gain Measure to Find the Most Discriminatory Problems for AI Benchmarking
Sep 11, 2018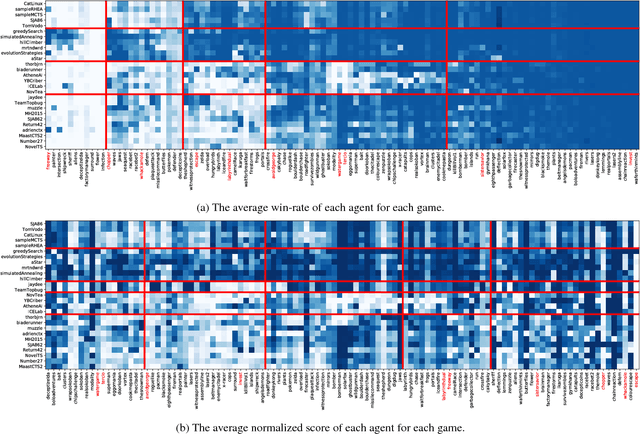

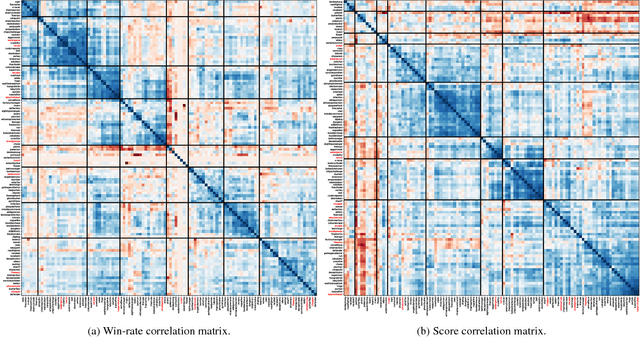
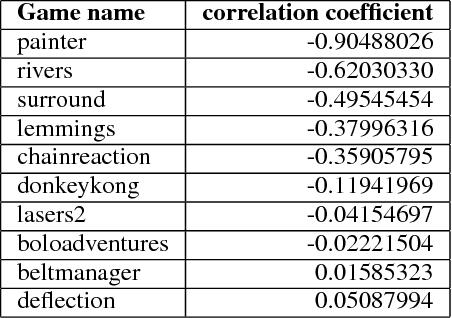
This paper introduces an information-theoretic method for selecting a small subset of problems which gives us the most information about a group of problem-solving algorithms. This method was tested on the games in the General Video Game AI (GVGAI) framework, allowing us to identify a smaller set of games that still gives a large amount of information about the game-playing agents. This approach can be used to make agent testing more efficient in the future. We can achieve almost as good discriminatory accuracy when testing on only a handful of games as when testing on more than a hundred games, something which is often computationally infeasible. Furthermore, this method can be extended to study the dimensions of effective variance in game design between these games, allowing us to identify which games differentiate between agents in the most complementary ways. As a side effect of this investigation, we provide an up-to-date comparison on agent performance for all GVGAI games, and an analysis of correlations between scores and win-rates across both games and agents.
DYPLOC: Dynamic Planning of Content Using Mixed Language Models for Text Generation
Jun 01, 2021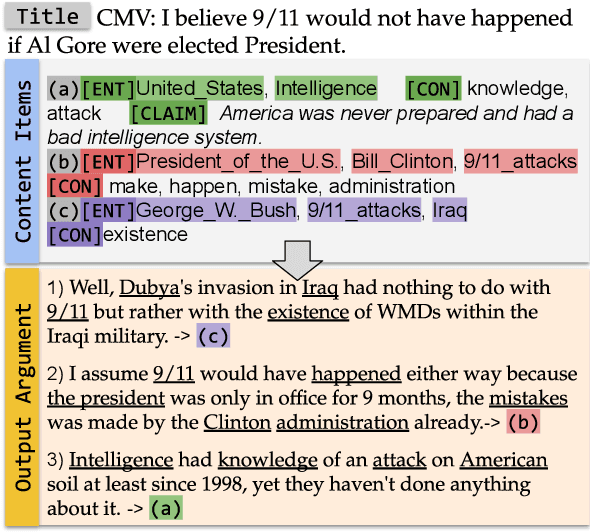
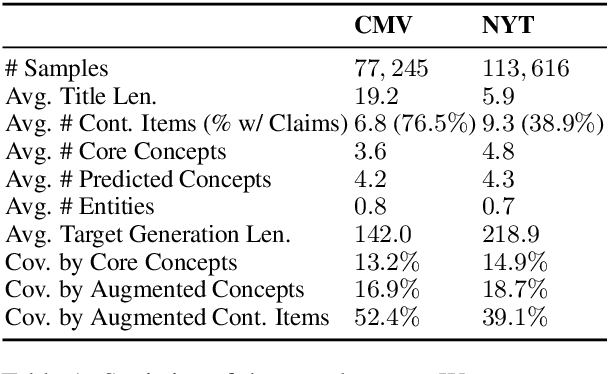
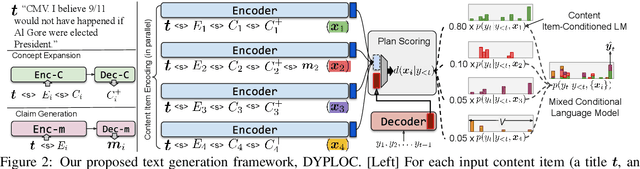
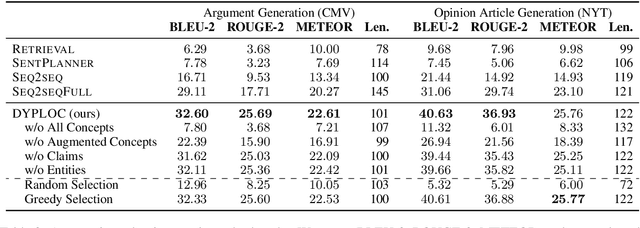
We study the task of long-form opinion text generation, which faces at least two distinct challenges. First, existing neural generation models fall short of coherence, thus requiring efficient content planning. Second, diverse types of information are needed to guide the generator to cover both subjective and objective content. To this end, we propose DYPLOC, a generation framework that conducts dynamic planning of content while generating the output based on a novel design of mixed language models. To enrich the generation with diverse content, we further propose to use large pre-trained models to predict relevant concepts and to generate claims. We experiment with two challenging tasks on newly collected datasets: (1) argument generation with Reddit ChangeMyView, and (2) writing articles using New York Times' Opinion section. Automatic evaluation shows that our model significantly outperforms competitive comparisons. Human judges further confirm that our generations are more coherent with richer content.
Rethinking Positive Aggregation and Propagation of Gradients in Gradient-based Saliency Methods
Dec 01, 2020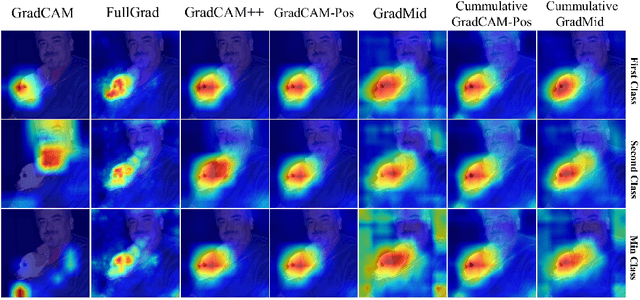
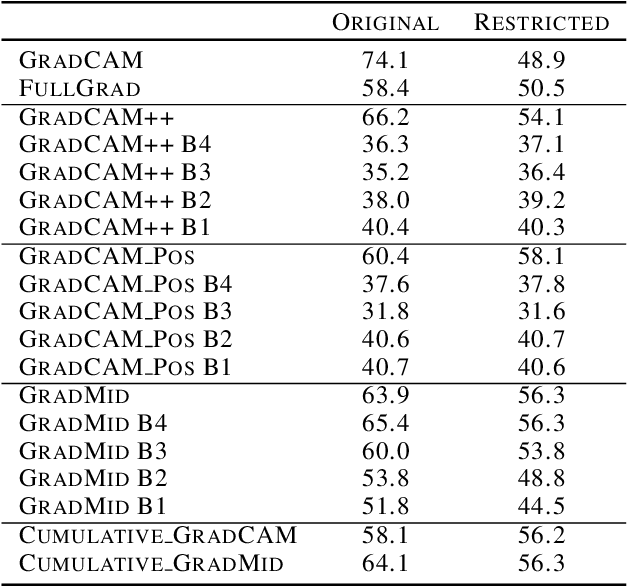

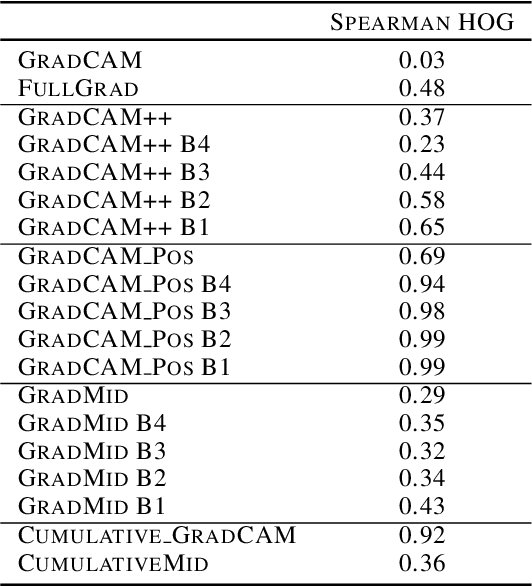
Saliency methods interpret the prediction of a neural network by showing the importance of input elements for that prediction. A popular family of saliency methods utilize gradient information. In this work, we empirically show that two approaches for handling the gradient information, namely positive aggregation, and positive propagation, break these methods. Though these methods reflect visually salient information in the input, they do not explain the model prediction anymore as the generated saliency maps are insensitive to the predicted output and are insensitive to model parameter randomization. Specifically for methods that aggregate the gradients of a chosen layer such as GradCAM++ and FullGrad, exclusively aggregating positive gradients is detrimental. We further support this by proposing several variants of aggregation methods with positive handling of gradient information. For methods that backpropagate gradient information such as LRP, RectGrad, and Guided Backpropagation, we show the destructive effect of exclusively propagating positive gradient information.
Form2Seq : A Framework for Higher-Order Form Structure Extraction
Jul 09, 2021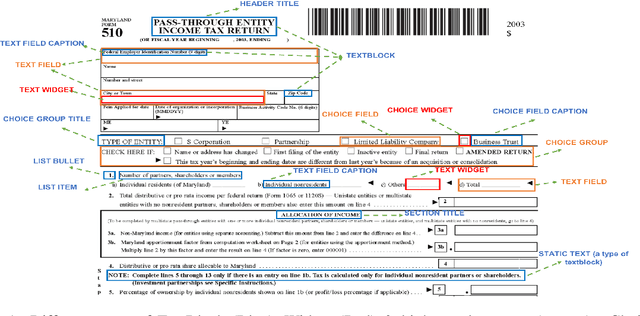
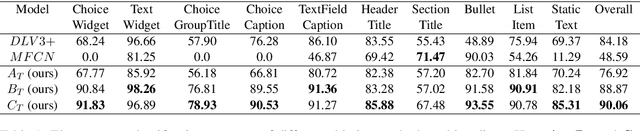
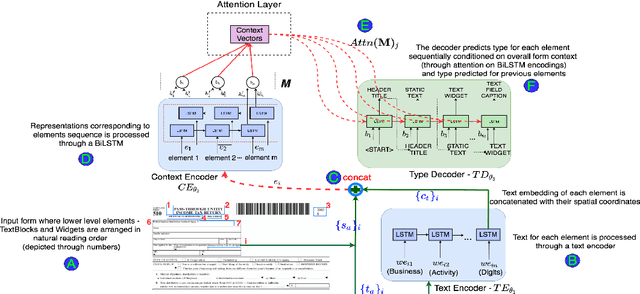
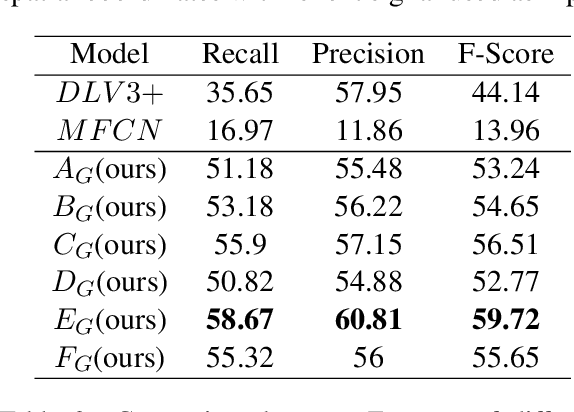
Document structure extraction has been a widely researched area for decades with recent works performing it as a semantic segmentation task over document images using fully-convolution networks. Such methods are limited by image resolution due to which they fail to disambiguate structures in dense regions which appear commonly in forms. To mitigate this, we propose Form2Seq, a novel sequence-to-sequence (Seq2Seq) inspired framework for structure extraction using text, with a specific focus on forms, which leverages relative spatial arrangement of structures. We discuss two tasks; 1) Classification of low-level constituent elements (TextBlock and empty fillable Widget) into ten types such as field captions, list items, and others; 2) Grouping lower-level elements into higher-order constructs, such as Text Fields, ChoiceFields and ChoiceGroups, used as information collection mechanism in forms. To achieve this, we arrange the constituent elements linearly in natural reading order, feed their spatial and textual representations to Seq2Seq framework, which sequentially outputs prediction of each element depending on the final task. We modify Seq2Seq for grouping task and discuss improvements obtained through cascaded end-to-end training of two tasks versus training in isolation. Experimental results show the effectiveness of our text-based approach achieving an accuracy of 90% on classification task and an F1 of 75.82, 86.01, 61.63 on groups discussed above respectively, outperforming segmentation baselines. Further we show our framework achieves state of the results for table structure recognition on ICDAR 2013 dataset.
A Systematic Study of Leveraging Subword Information for Learning Word Representations
May 04, 2019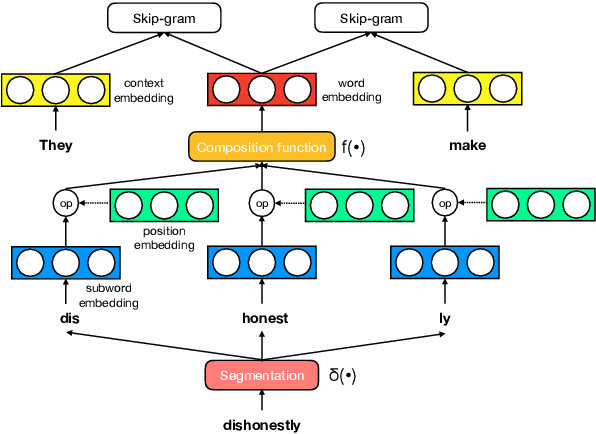
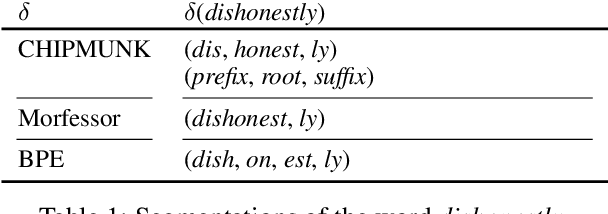
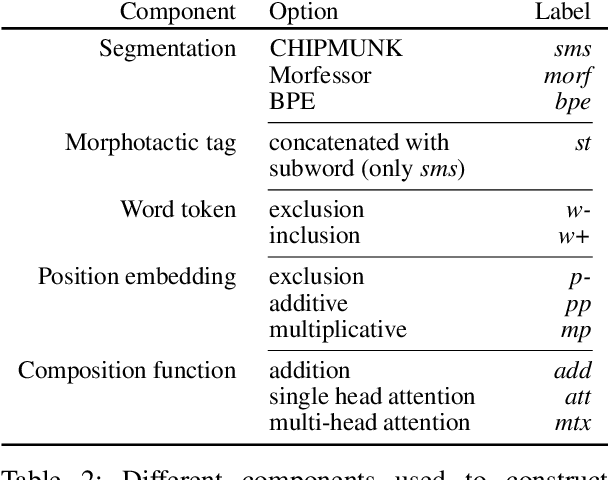
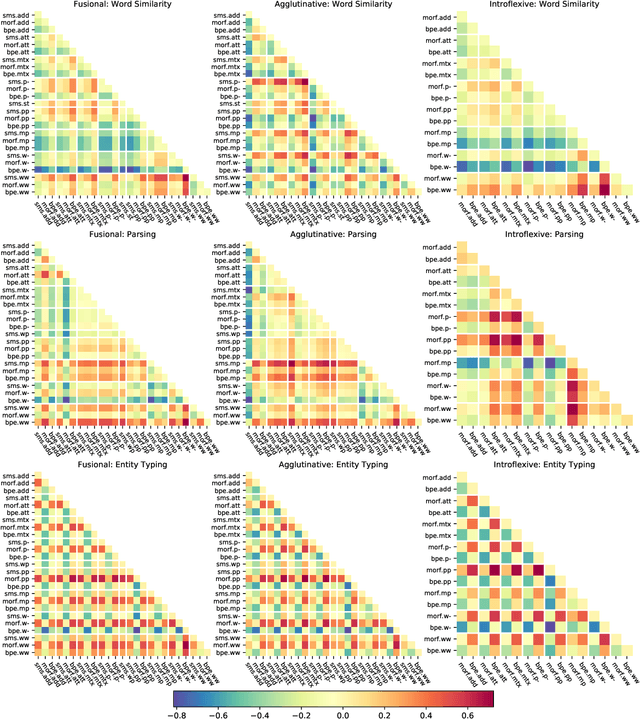
The use of subword-level information (e.g., characters, character n-grams, morphemes) has become ubiquitous in modern word representation learning. Its importance is attested especially for morphologically rich languages which generate a large number of rare words. Despite a steadily increasing interest in such subword-informed word representations, their systematic comparative analysis across typologically diverse languages and different tasks is still missing. In this work, we deliver such a study focusing on the variation of two crucial components required for subword-level integration into word representation models: 1) segmentation of words into subword units, and 2) subword composition functions to obtain final word representations. We propose a general framework for learning subword-informed word representations that allows for easy experimentation with different segmentation and composition components, also including more advanced techniques based on position embeddings and self-attention. Using the unified framework, we run experiments over a large number of subword-informed word representation configurations (60 in total) on 3 tasks (general and rare word similarity, dependency parsing, fine-grained entity typing) for 5 languages representing 3 language types. Our main results clearly indicate that there is no "one-sizefits-all" configuration, as performance is both language- and task-dependent. We also show that configurations based on unsupervised segmentation (e.g., BPE, Morfessor) are sometimes comparable to or even outperform the ones based on supervised word segmentation.