 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Complementary Relation Contrastive Distillation
Mar 29, 2021
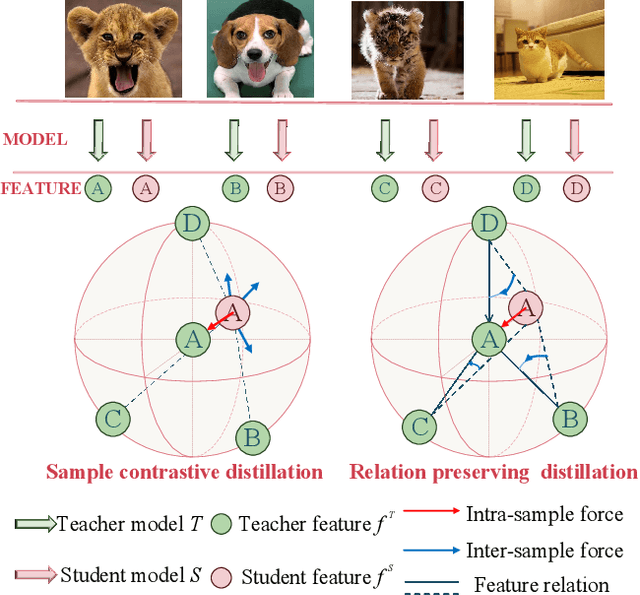
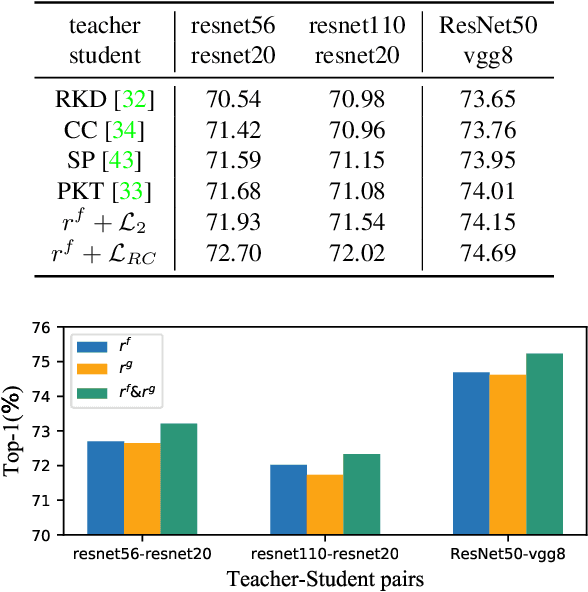
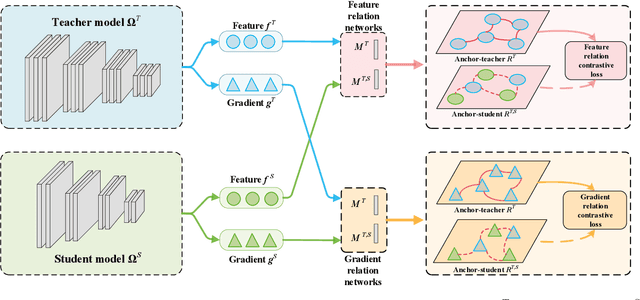

Knowledge distillation aims to transfer representation ability from a teacher model to a student model. Previous approaches focus on either individual representation distillation or inter-sample similarity preservation. While we argue that the inter-sample relation conveys abundant information and needs to be distilled in a more effective way. In this paper, we propose a novel knowledge distillation method, namely Complementary Relation Contrastive Distillation (CRCD), to transfer the structural knowledge from the teacher to the student. Specifically, we estimate the mutual relation in an anchor-based way and distill the anchor-student relation under the supervision of its corresponding anchor-teacher relation. To make it more robust, mutual relations are modeled by two complementary elements: the feature and its gradient. Furthermore, the low bound of mutual information between the anchor-teacher relation distribution and the anchor-student relation distribution is maximized via relation contrastive loss, which can distill both the sample representation and the inter-sample relations. Experiments on different benchmarks demonstrate the effectiveness of our proposed CRCD.
A Multi-task convolutional neural network for blind stereoscopic image quality assessment using naturalness analysis
Jun 21, 2021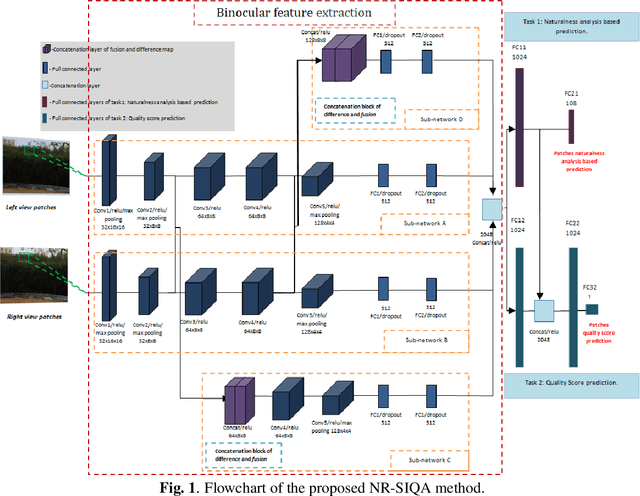
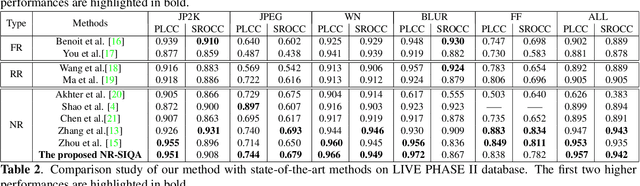
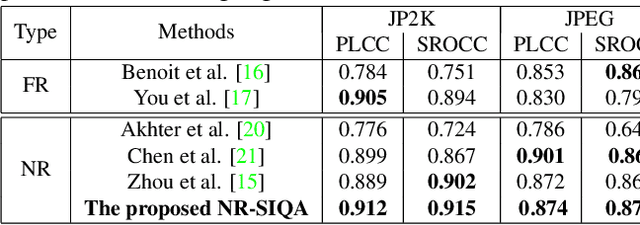
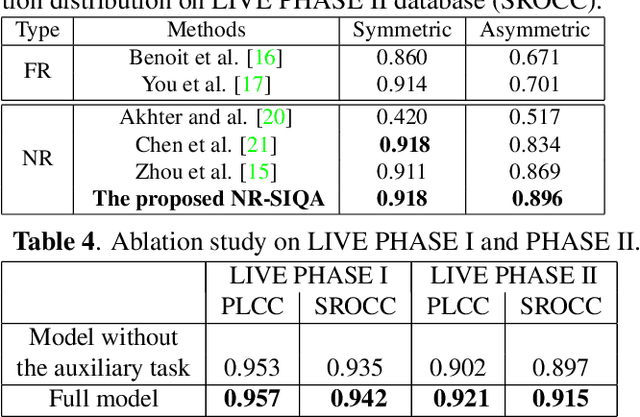
This paper addresses the problem of blind stereoscopic image quality assessment (NR-SIQA) using a new multi-task deep learning based-method. In the field of stereoscopic vision, the information is fairly distributed between the left and right views as well as the binocular phenomenon. In this work, we propose to integrate these characteristics to estimate the quality of stereoscopic images without reference through a convolutional neural network. Our method is based on two main tasks: the first task predicts naturalness analysis based features adapted to stereo images, while the second task predicts the quality of such images. The former, so-called auxiliary task, aims to find more robust and relevant features to improve the quality prediction. To do this, we compute naturalness-based features using a Natural Scene Statistics (NSS) model in the complex wavelet domain. It allows to capture the statistical dependency between pairs of the stereoscopic images. Experiments are conducted on the well known LIVE PHASE I and LIVE PHASE II databases. The results obtained show the relevance of our method when comparing with those of the state-of-the-art. Our code is available online on https://github.com/Bourbia-Salima/multitask-cnn-nrsiqa_2021.
Interventional Video Grounding with Dual Contrastive Learning
Jun 21, 2021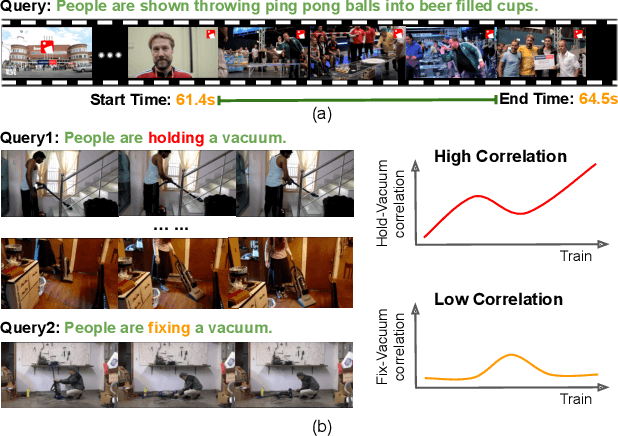
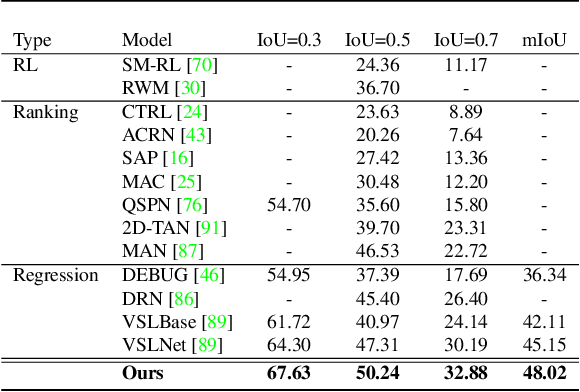
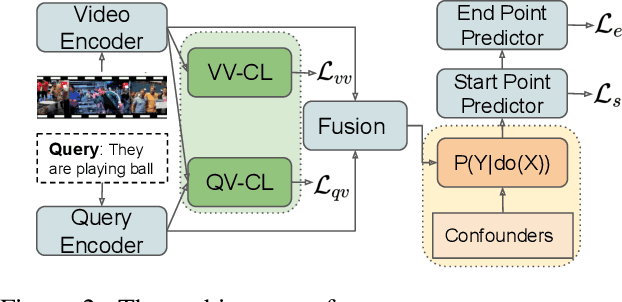
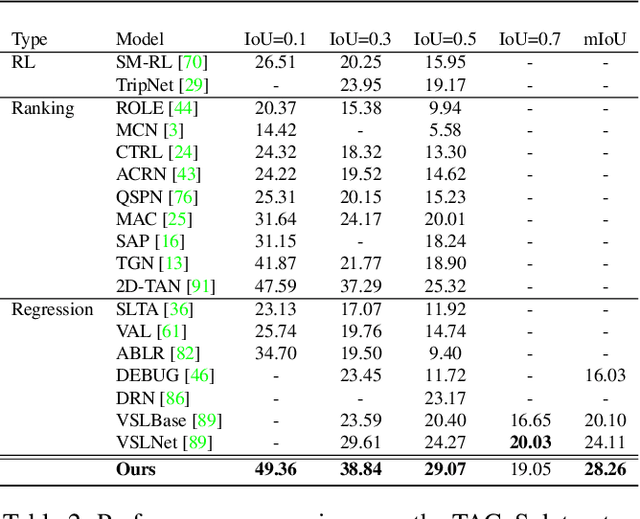
Video grounding aims to localize a moment from an untrimmed video for a given textual query. Existing approaches focus more on the alignment of visual and language stimuli with various likelihood-based matching or regression strategies, i.e., P(Y|X). Consequently, these models may suffer from spurious correlations between the language and video features due to the selection bias of the dataset. 1) To uncover the causality behind the model and data, we first propose a novel paradigm from the perspective of the causal inference, i.e., interventional video grounding (IVG) that leverages backdoor adjustment to deconfound the selection bias based on structured causal model (SCM) and do-calculus P(Y|do(X)). Then, we present a simple yet effective method to approximate the unobserved confounder as it cannot be directly sampled from the dataset. 2) Meanwhile, we introduce a dual contrastive learning approach (DCL) to better align the text and video by maximizing the mutual information (MI) between query and video clips, and the MI between start/end frames of a target moment and the others within a video to learn more informative visual representations. Experiments on three standard benchmarks show the effectiveness of our approaches.
Sparsely Overlapped Speech Training in the Time Domain: Joint Learning of Target Speech Separation and Personal VAD Benefits
Jun 28, 2021
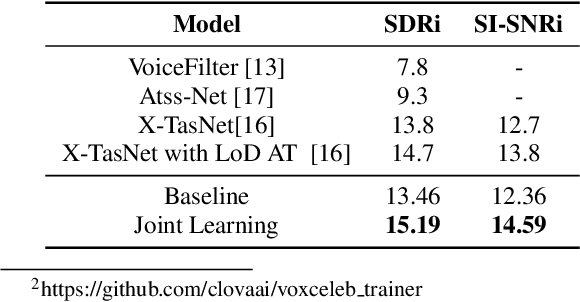
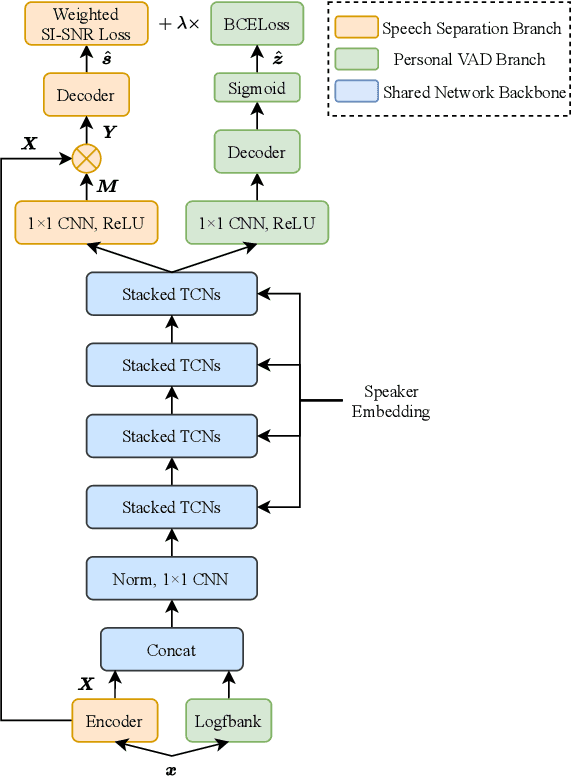
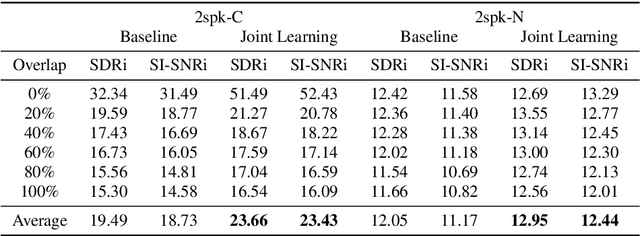
Target speech separation is the process of filtering a certain speaker's voice out of speech mixtures according to the additional speaker identity information provided. Recent works have made considerable improvement by processing signals in the time domain directly. The majority of them take fully overlapped speech mixtures for training. However, since most real-life conversations occur randomly and are sparsely overlapped, we argue that training with different overlap ratio data benefits. To do so, an unavoidable problem is that the popularly used SI-SNR loss has no definition for silent sources. This paper proposes the weighted SI-SNR loss, together with the joint learning of target speech separation and personal VAD. The weighted SI-SNR loss imposes a weight factor that is proportional to the target speaker's duration and returns zero when the target speaker is absent. Meanwhile, the personal VAD generates masks and sets non-target speech to silence. Experiments show that our proposed method outperforms the baseline by 1.73 dB in terms of SDR on fully overlapped speech, as well as by 4.17 dB and 0.9 dB on sparsely overlapped speech of clean and noisy conditions. Besides, with slight degradation in performance, our model could reduce the time costs in inference.
Neural Implicit 3D Shapes from Single Images with Spatial Patterns
Jun 06, 2021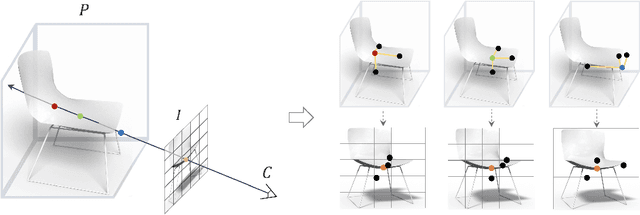
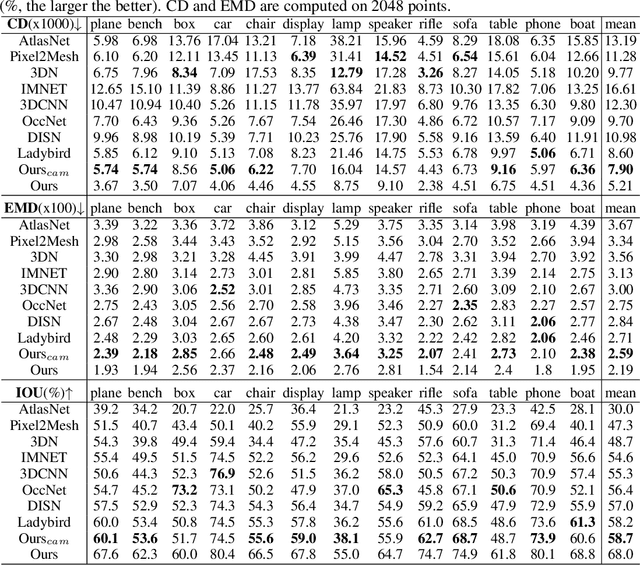
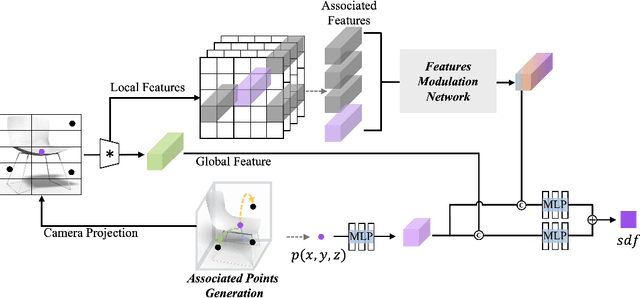
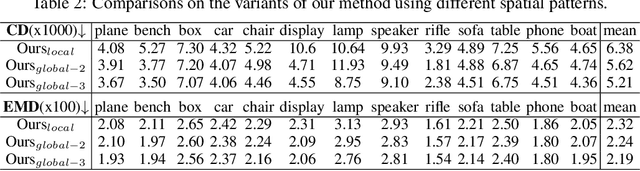
3D shape reconstruction from a single image has been a long-standing problem in computer vision. The problem is ill-posed and highly challenging due to the information loss and occlusion that occurred during the imagery capture. In contrast to previous methods that learn holistic shape priors, we propose a method to learn spatial pattern priors for inferring the invisible regions of the underlying shape, wherein each 3D sample in the implicit shape representation is associated with a set of points generated by hand-crafted 3D mappings, along with their local image features. The proposed spatial pattern is significantly more informative and has distinctive descriptions on both visible and occluded locations. Most importantly, the key to our work is the ubiquitousness of the spatial patterns across shapes, which enables reasoning invisible parts of the underlying objects and thus greatly mitigates the occlusion issue. We devise a neural network that integrates spatial pattern representations and demonstrate the superiority of the proposed method on widely used metrics.
Attribute Selection using Contranominal Scales
Jun 21, 2021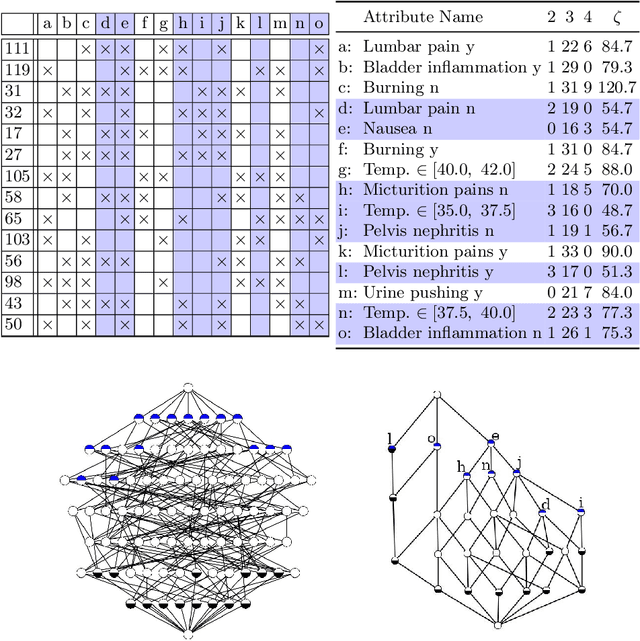
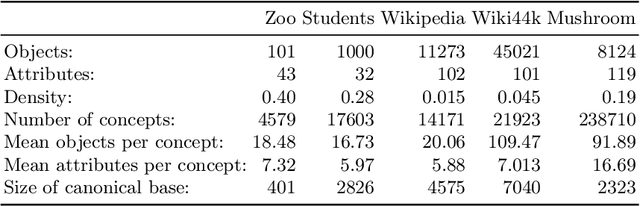
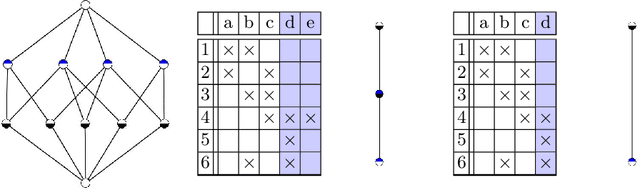
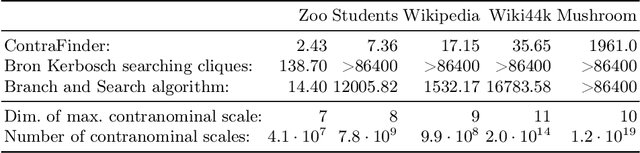
Formal Concept Analysis (FCA) allows to analyze binary data by deriving concepts and ordering them in lattices. One of the main goals of FCA is to enable humans to comprehend the information that is encapsulated in the data; however, the large size of concept lattices is a limiting factor for the feasibility of understanding the underlying structural properties. The size of such a lattice depends on the number of subcontexts in the corresponding formal context that are isomorphic to a contranominal scale of high dimension. In this work, we propose the algorithm ContraFinder that enables the computation of all contranominal scales of a given formal context. Leveraging this algorithm, we introduce delta-adjusting, a novel approach in order to decrease the number of contranominal scales in a formal context by the selection of an appropriate attribute subset. We demonstrate that delta-adjusting a context reduces the size of the hereby emerging sub-semilattice and that the implication set is restricted to meaningful implications. This is evaluated with respect to its associated knowledge by means of a classification task. Hence, our proposed technique strongly improves understandability while preserving important conceptual structures.
Segmentation of cell-level anomalies in electroluminescence images of photovoltaic modules
Jun 21, 2021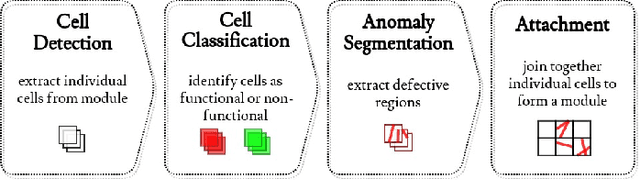
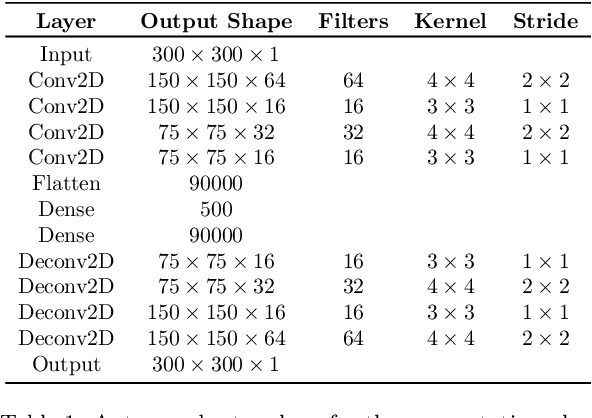
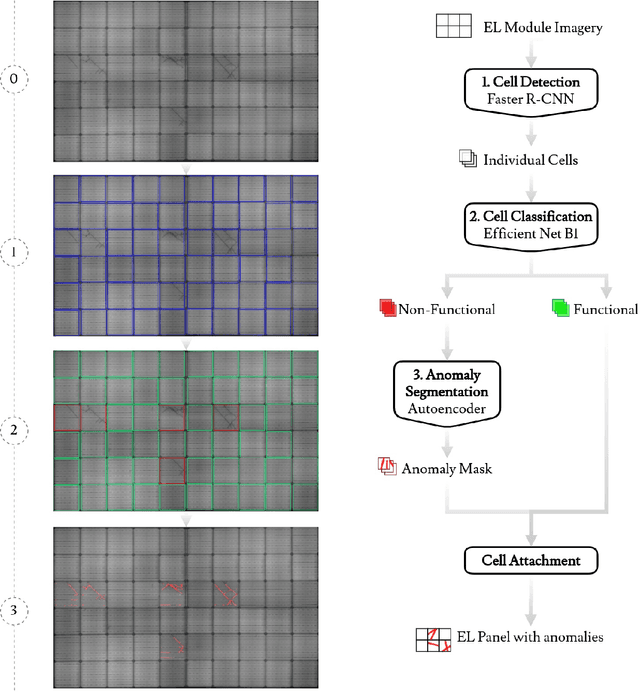
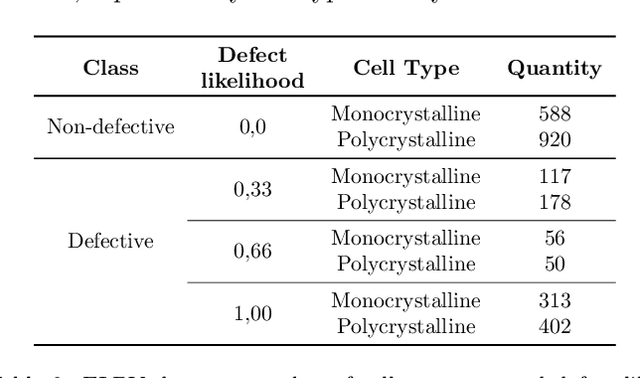
In the operation & maintenance (O&M) of photovoltaic (PV) plants, the early identification of failures has become crucial to maintain productivity and prolong components' life. Of all defects, cell-level anomalies can lead to serious failures and may affect surrounding PV modules in the long run. These fine defects are usually captured with high spatial resolution electroluminescence (EL) imaging. The difficulty of acquiring such images has limited the availability of data. For this work, multiple data resources and augmentation techniques have been used to surpass this limitation. Current state-of-the-art detection methods extract barely low-level information from individual PV cell images, and their performance is conditioned by the available training data. In this article, we propose an end-to-end deep learning pipeline that detects, locates and segments cell-level anomalies from entire photovoltaic modules via EL images. The proposed modular pipeline combines three deep learning techniques: 1. object detection (modified Faster-RNN), 2. image classification (EfficientNet) and 3. weakly supervised segmentation (autoencoder). The modular nature of the pipeline allows to upgrade the deep learning models to the further improvements in the state-of-the-art and also extend the pipeline towards new functionalities.
* 16 pages, 14 figures
Generating abstractive summaries of Lithuanian news articles using a transformer model
Apr 23, 2021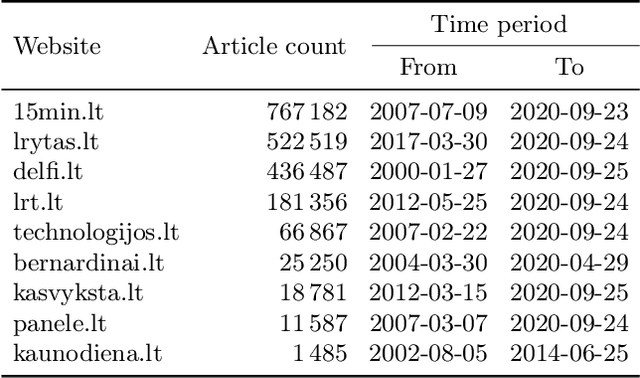
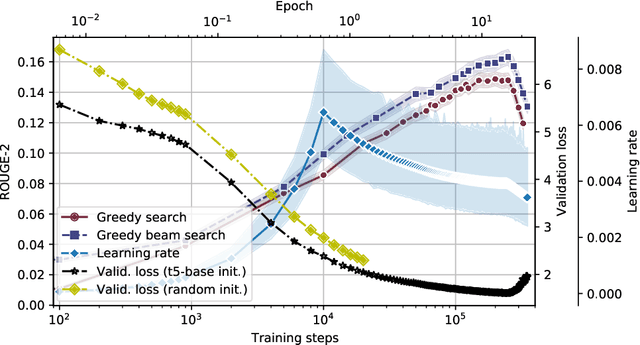
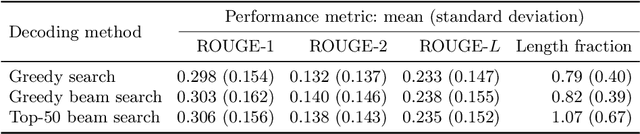
In this work, we train the first monolingual Lithuanian transformer model on a relatively large corpus of Lithuanian news articles and compare various output decoding algorithms for abstractive news summarization. Generated summaries are coherent and look impressive at the first glance. However, some of them contain misleading information that is not so easy to spot. We describe all the technical details and share our trained model and accompanying code in an online open-source repository, as well as some characteristic samples of the generated summaries.
Self-supervised Video Representation Learning with Cross-Stream Prototypical Contrasting
Jun 21, 2021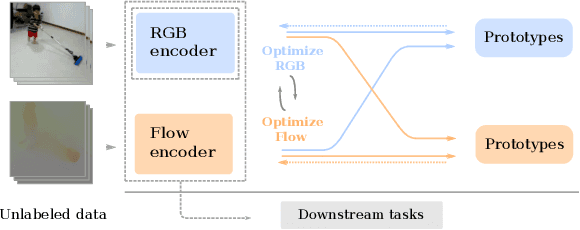
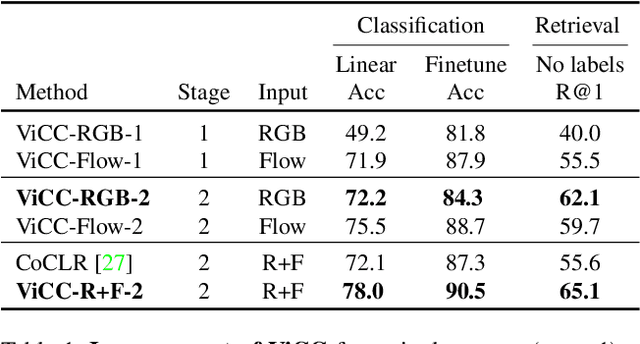
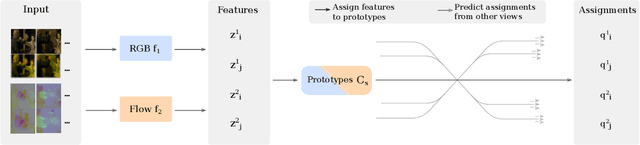
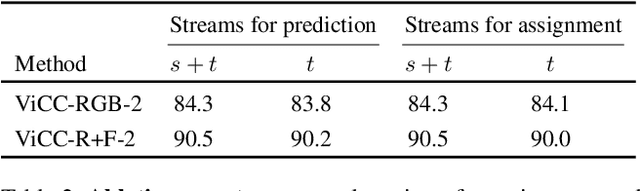
Instance-level contrastive learning techniques, which rely on data augmentation and a contrastive loss function, have found great success in the domain of visual representation learning. They are not suitable for exploiting the rich dynamical structure of video however, as operations are done on many augmented instances. In this paper we propose "Video Cross-Stream Prototypical Contrasting", a novel method which predicts consistent prototype assignments from both RGB and optical flow views, operating on sets of samples. Specifically, we alternate the optimization process; while optimizing one of the streams, all views are mapped to one set of stream prototype vectors. Each of the assignments is predicted with all views except the one matching the prediction, pushing representations closer to their assigned prototypes. As a result, more efficient video embeddings with ingrained motion information are learned, without the explicit need for optical flow computation during inference. We obtain state-of-the-art results on nearest neighbour video retrieval and action recognition, outperforming previous best by +3.2% on UCF101 using the S3D backbone (90.5% Top-1 acc), and by +7.2% on UCF101 and +15.1% on HMDB51 using the R(2+1)D backbone.
Iterative Methods for Private Synthetic Data: Unifying Framework and New Methods
Jun 14, 2021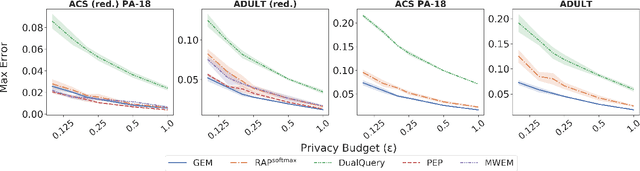
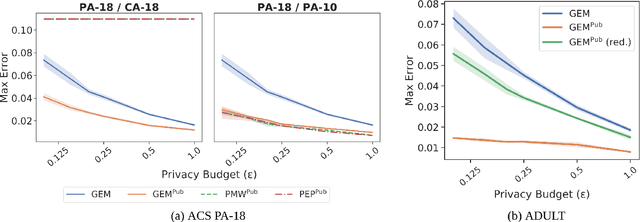
We study private synthetic data generation for query release, where the goal is to construct a sanitized version of a sensitive dataset, subject to differential privacy, that approximately preserves the answers to a large collection of statistical queries. We first present an algorithmic framework that unifies a long line of iterative algorithms in the literature. Under this framework, we propose two new methods. The first method, private entropy projection (PEP), can be viewed as an advanced variant of MWEM that adaptively reuses past query measurements to boost accuracy. Our second method, generative networks with the exponential mechanism (GEM), circumvents computational bottlenecks in algorithms such as MWEM and PEP by optimizing over generative models parameterized by neural networks, which capture a rich family of distributions while enabling fast gradient-based optimization. We demonstrate that PEP and GEM empirically outperform existing algorithms. Furthermore, we show that GEM nicely incorporates prior information from public data while overcoming limitations of PMW^Pub, the existing state-of-the-art method that also leverages public data.