 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Demystifying Information-Theoretic Clustering
Feb 05, 2014
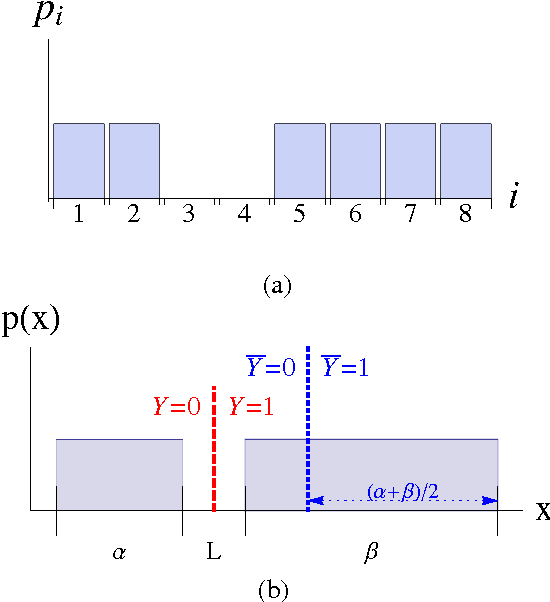
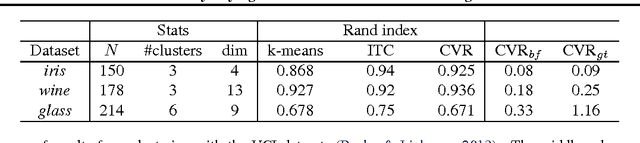
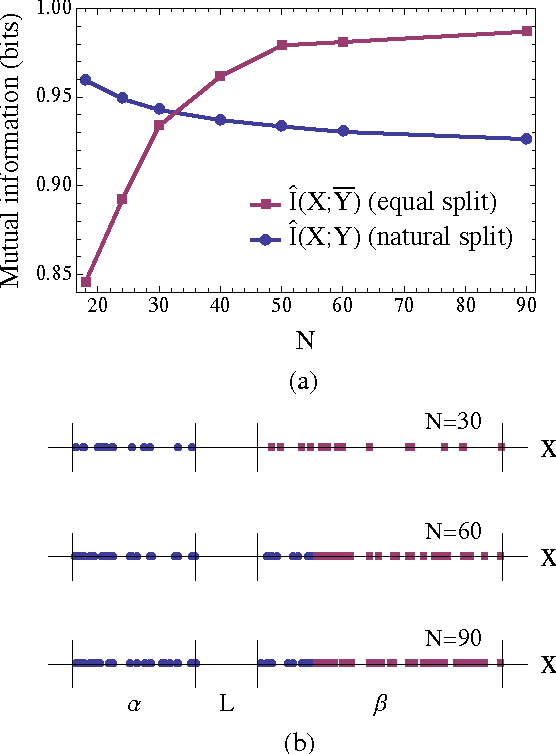
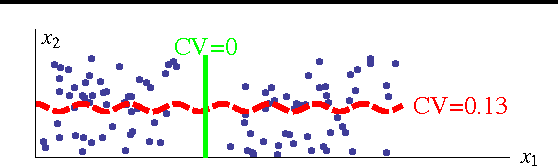
We propose a novel method for clustering data which is grounded in information-theoretic principles and requires no parametric assumptions. Previous attempts to use information theory to define clusters in an assumption-free way are based on maximizing mutual information between data and cluster labels. We demonstrate that this intuition suffers from a fundamental conceptual flaw that causes clustering performance to deteriorate as the amount of data increases. Instead, we return to the axiomatic foundations of information theory to define a meaningful clustering measure based on the notion of consistency under coarse-graining for finite data.
Towards Single Stage Weakly Supervised Semantic Segmentation
Jun 28, 2021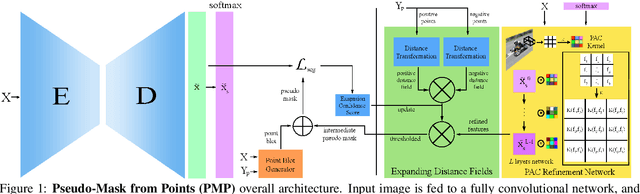
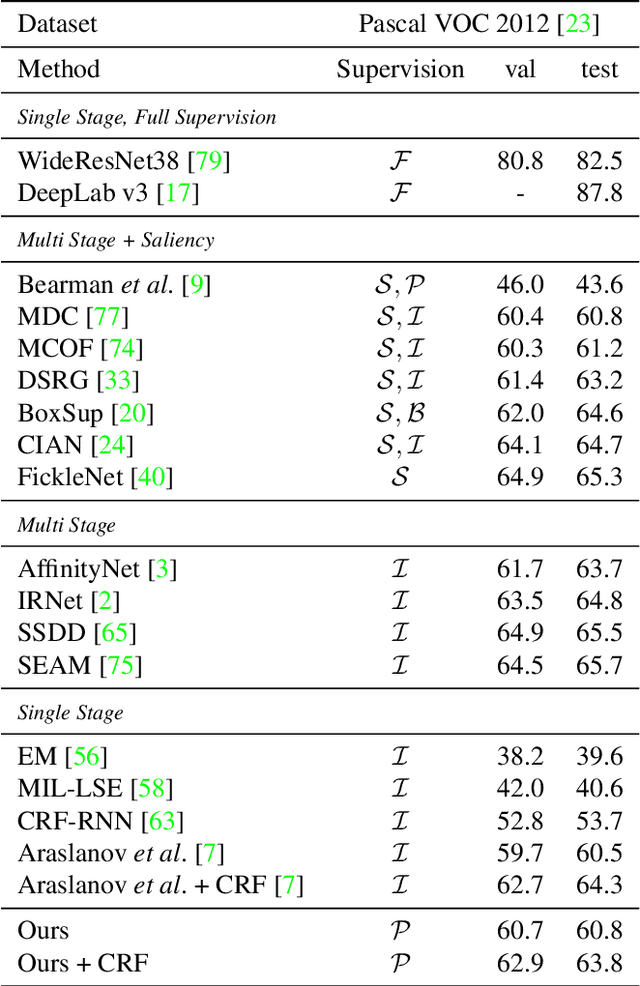
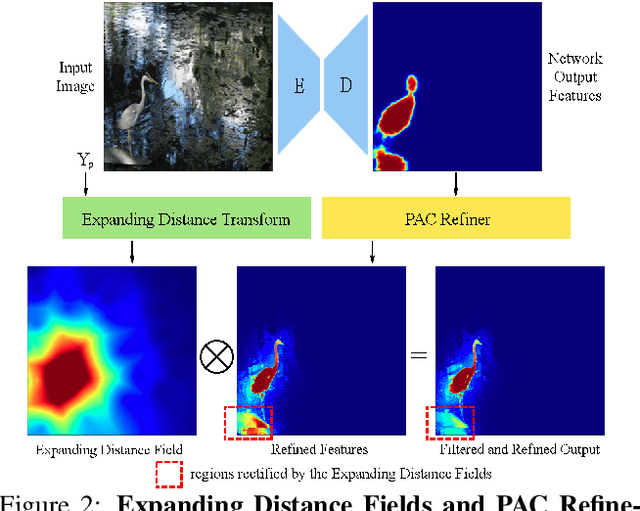
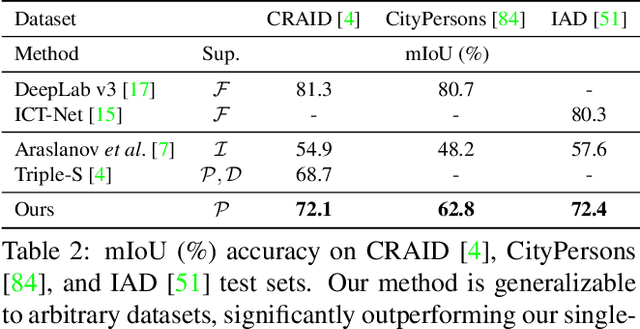
The costly process of obtaining semantic segmentation labels has driven research towards weakly supervised semantic segmentation (WSSS) methods, using only image-level, point, or box labels. The lack of dense scene representation requires methods to increase complexity to obtain additional semantic information about the scene, often done through multiple stages of training and refinement. Current state-of-the-art (SOTA) models leverage image-level labels to produce class activation maps (CAMs) which go through multiple stages of refinement before they are thresholded to make pseudo-masks for supervision. The multi-stage approach is computationally expensive, and dependency on image-level labels for CAMs generation lacks generalizability to more complex scenes. In contrary, our method offers a single-stage approach generalizable to arbitrary dataset, that is trainable from scratch, without any dependency on pre-trained backbones, classification, or separate refinement tasks. We utilize point annotations to generate reliable, on-the-fly pseudo-masks through refined and filtered features. While our method requires point annotations that are only slightly more expensive than image-level annotations, we are to demonstrate SOTA performance on benchmark datasets (PascalVOC 2012), as well as significantly outperform other SOTA WSSS methods on recent real-world datasets (CRAID, CityPersons, IAD).
Split, embed and merge: An accurate table structure recognizer
Jul 20, 2021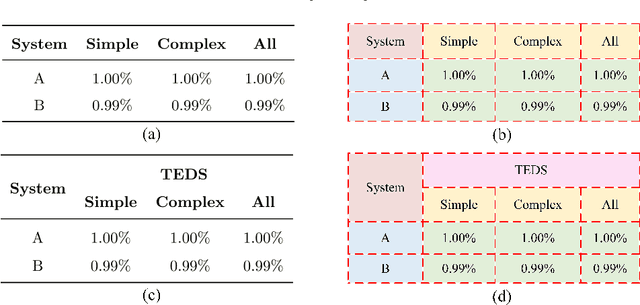

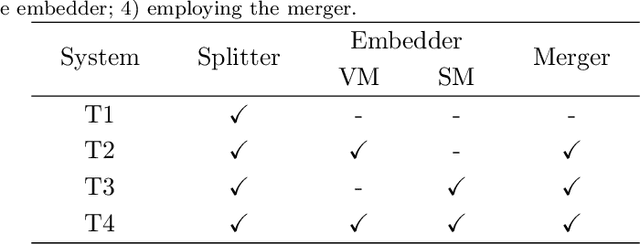
Table structure recognition is an essential part for making machines understand tables. Its main task is to recognize the internal structure of a table. However, due to the complexity and diversity in their structure and style, it is very difficult to parse the tabular data into the structured format which machines can understand easily, especially for complex tables. In this paper, we introduce Split, Embed and Merge (SEM), an accurate table structure recognizer. Our model takes table images as input and can correctly recognize the structure of tables, whether they are simple or a complex tables. SEM is mainly composed of three parts, splitter, embedder and merger. In the first stage, we apply the splitter to predict the potential regions of the table row (column) separators, and obtain the fine grid structure of the table. In the second stage, by taking a full consideration of the textual information in the table, we fuse the output features for each table grid from both vision and language modalities. Moreover, we achieve a higher precision in our experiments through adding additional semantic features. Finally, we process the merging of these basic table grids in a self-regression manner. The correspondent merging results is learned through the attention mechanism. In our experiments, SEM achieves an average F1-Measure of 97.11% on the SciTSR dataset which outperforms other methods by a large margin. We also won the first place in the complex table and third place in all tables in ICDAR 2021 Competition on Scientific Literature Parsing, Task-B. Extensive experiments on other publicly available datasets demonstrate that our model achieves state-of-the-art.
A Systematic Study of Leveraging Subword Information for Learning Word Representations
May 04, 2019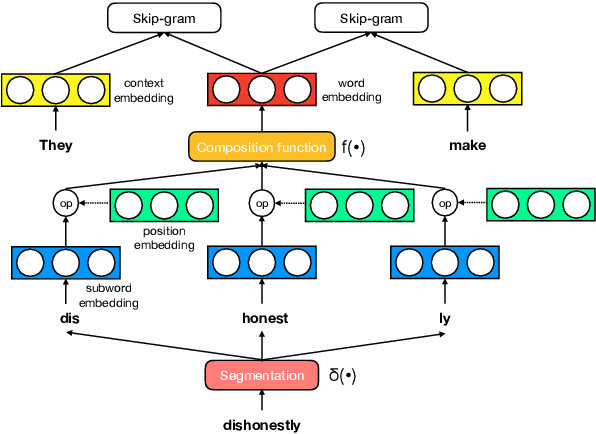
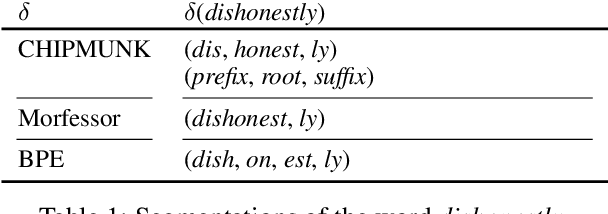
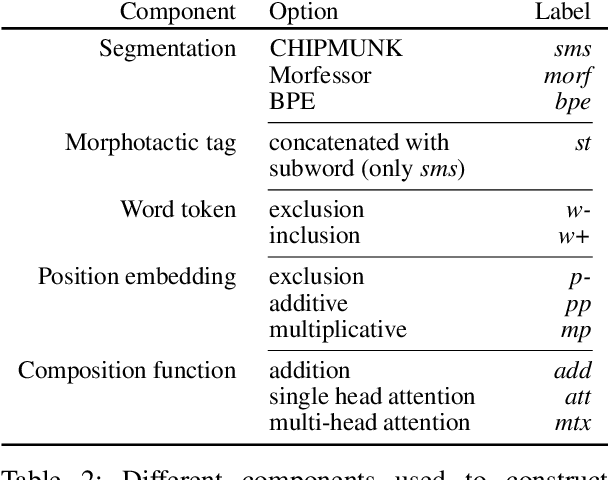
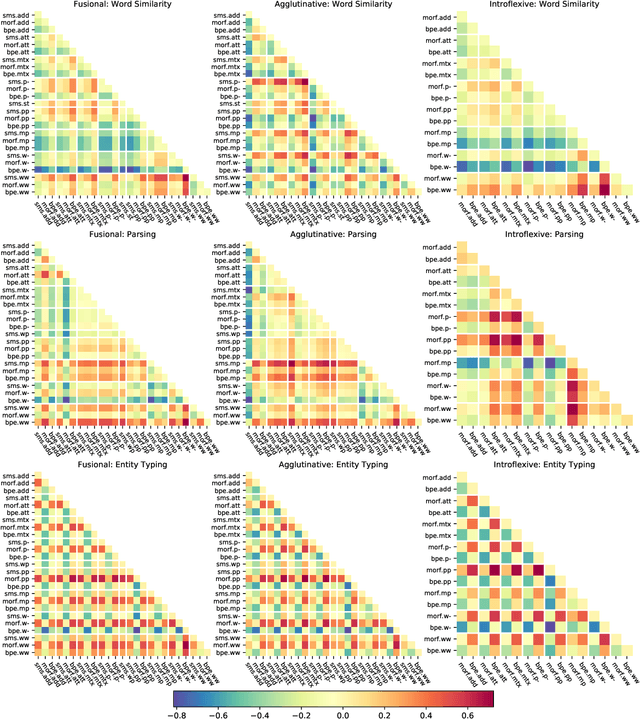
The use of subword-level information (e.g., characters, character n-grams, morphemes) has become ubiquitous in modern word representation learning. Its importance is attested especially for morphologically rich languages which generate a large number of rare words. Despite a steadily increasing interest in such subword-informed word representations, their systematic comparative analysis across typologically diverse languages and different tasks is still missing. In this work, we deliver such a study focusing on the variation of two crucial components required for subword-level integration into word representation models: 1) segmentation of words into subword units, and 2) subword composition functions to obtain final word representations. We propose a general framework for learning subword-informed word representations that allows for easy experimentation with different segmentation and composition components, also including more advanced techniques based on position embeddings and self-attention. Using the unified framework, we run experiments over a large number of subword-informed word representation configurations (60 in total) on 3 tasks (general and rare word similarity, dependency parsing, fine-grained entity typing) for 5 languages representing 3 language types. Our main results clearly indicate that there is no "one-sizefits-all" configuration, as performance is both language- and task-dependent. We also show that configurations based on unsupervised segmentation (e.g., BPE, Morfessor) are sometimes comparable to or even outperform the ones based on supervised word segmentation.
Smart mobile microscopy: towards fully-automated digitization
May 24, 2021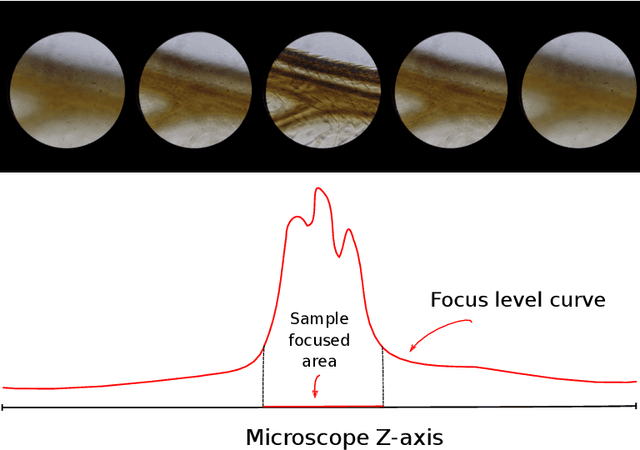
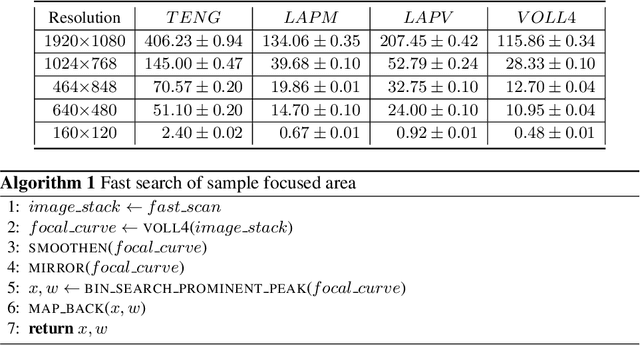
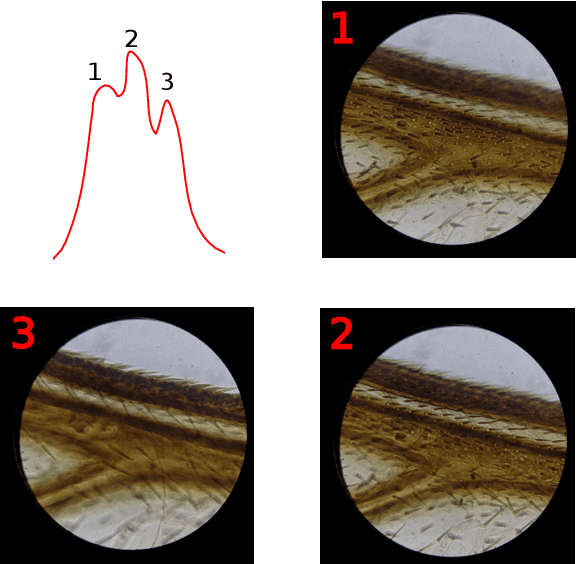
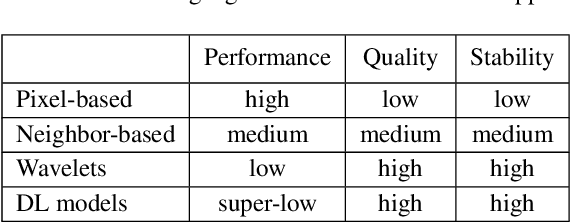
Mobile microscopy is a newly formed field that emerged from a combination of optical microscopy capabilities and spread, functionality, and ever-increasing computing resources of mobile devices. Despite the idea of creating a system that would successfully merge a microscope, numerous computer vision methods, and a mobile device is regularly examined, the resulting implementations still require the presence of a qualified operator to control specimen digitization. In this paper, we address the task of surpassing this constraint and present a ``smart'' mobile microscope concept aimed at automatic digitization of the most valuable visual information about the specimen. We perform this through combining automated microscope setup control and classic techniques such as auto-focusing, in-focus filtering, and focus-stacking -- adapted and optimized as parts of a mobile cross-platform library.
What's in a Measurement? Using GPT-3 on SemEval 2021 Task 8 -- MeasEval
Jun 28, 2021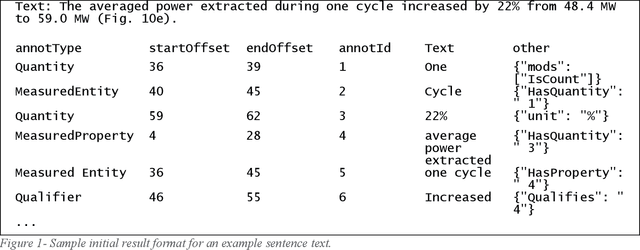



In the summer of 2020 OpenAI released its GPT-3 autoregressive language model to much fanfare. While the model has shown promise on tasks in several areas, it has not always been clear when the results were cherry-picked or when they were the unvarnished output. We were particularly interested in what benefits GPT-3 could bring to the SemEval 2021 MeasEval task - identifying measurements and their associated attributes in scientific literature. We had already experimented with multi-turn questions answering as a solution to this task. We wanted to see if we could use GPT-3's few-shot learning capabilities to more easily develop a solution that would have better performance than our prior work. Unfortunately, we have not been successful in that effort. This paper discusses the approach we used, challenges we encountered, and results we observed. Some of the problems we encountered were simply due to the state of the art. For example, the limits on the size of the prompt and answer limited the amount of the training signal that could be offered. Others are more fundamental. We are unaware of generative models that excel in retaining factual information. Also, the impact of changes in the prompts is unpredictable, making it hard to reliably improve performance.
Realtime Robust Malicious Traffic Detection via Frequency Domain Analysis
Jun 28, 2021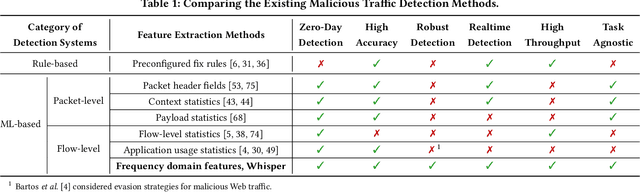
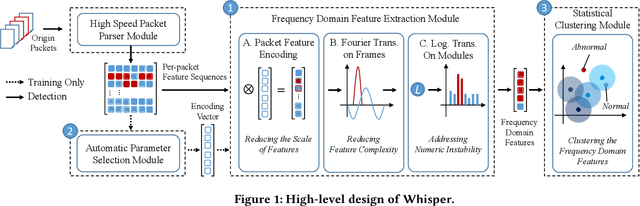

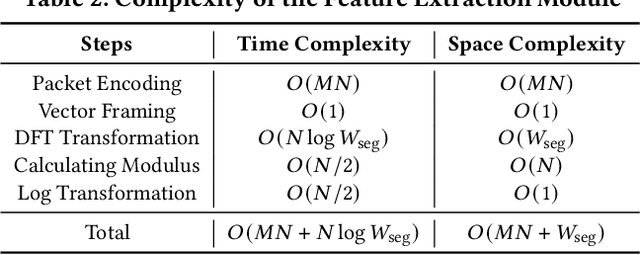
Machine learning (ML) based malicious traffic detection is an emerging security paradigm, particularly for zero-day attack detection, which is complementary to existing rule based detection. However, the existing ML based detection has low detection accuracy and low throughput incurred by inefficient traffic features extraction. Thus, they cannot detect attacks in realtime especially in high throughput networks. Particularly, these detection systems similar to the existing rule based detection can be easily evaded by sophisticated attacks. To this end, we propose Whisper, a realtime ML based malicious traffic detection system that achieves both high accuracy and high throughput by utilizing frequency domain features. It utilizes sequential features represented by the frequency domain features to achieve bounded information loss, which ensures high detection accuracy, and meanwhile constrains the scale of features to achieve high detection throughput. Particularly, attackers cannot easily interfere with the frequency domain features and thus Whisper is robust against various evasion attacks. Our experiments with 42 types of attacks demonstrate that, compared with the state-of-theart systems, Whisper can accurately detect various sophisticated and stealthy attacks, achieving at most 18.36% improvement, while achieving two orders of magnitude throughput. Even under various evasion attacks, Whisper is still able to maintain around 90% detection accuracy.
Efficient Human Pose Estimation by Learning Deeply Aggregated Representations
Dec 13, 2020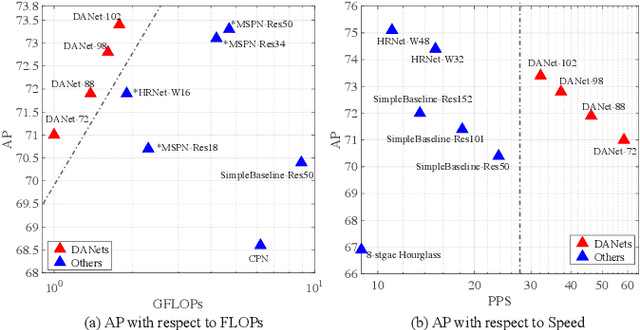
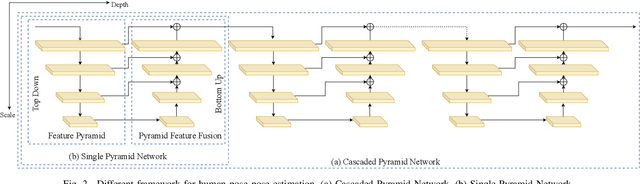
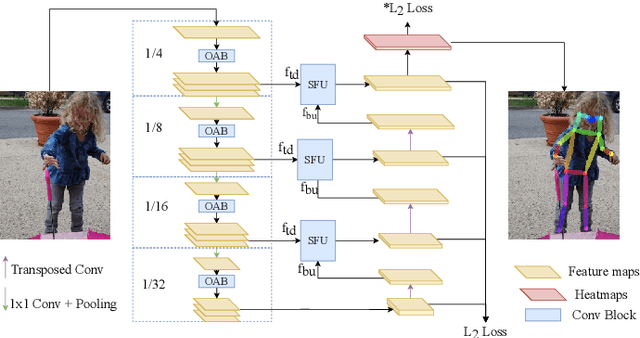
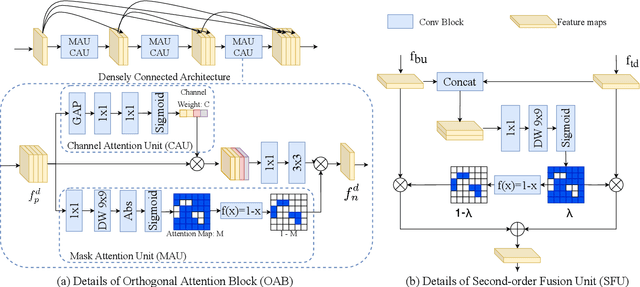
In this paper, we propose an efficient human pose estimation network (DANet) by learning deeply aggregated representations. Most existing models explore multi-scale information mainly from features with different spatial sizes. Powerful multi-scale representations usually rely on the cascaded pyramid framework. This framework largely boosts the performance but in the meanwhile makes networks very deep and complex. Instead, we focus on exploiting multi-scale information from layers with different receptive-field sizes and then making full of use this information by improving the fusion method. Specifically, we propose an orthogonal attention block (OAB) and a second-order fusion unit (SFU). The OAB learns multi-scale information from different layers and enhances them by encouraging them to be diverse. The SFU adaptively selects and fuses diverse multi-scale information and suppress the redundant ones. This could maximize the effective information in final fused representations. With the help of OAB and SFU, our single pyramid network may be able to generate deeply aggregated representations that contain even richer multi-scale information and have a larger representing capacity than that of cascaded networks. Thus, our networks could achieve comparable or even better accuracy with much smaller model complexity. Specifically, our \mbox{DANet-72} achieves $70.5$ in AP score on COCO test-dev set with only $1.0G$ FLOPs. Its speed on a CPU platform achieves $58$ Persons-Per-Second~(PPS).
Generating abstractive summaries of Lithuanian news articles using a transformer model
Apr 23, 2021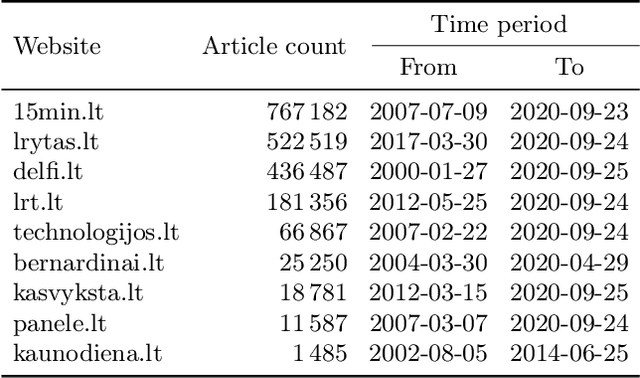
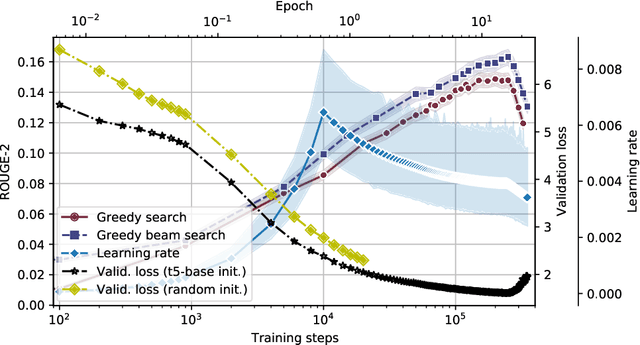
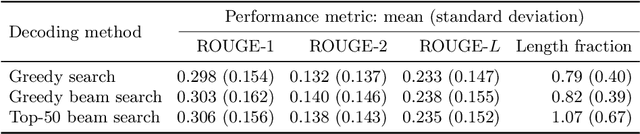
In this work, we train the first monolingual Lithuanian transformer model on a relatively large corpus of Lithuanian news articles and compare various output decoding algorithms for abstractive news summarization. Generated summaries are coherent and look impressive at the first glance. However, some of them contain misleading information that is not so easy to spot. We describe all the technical details and share our trained model and accompanying code in an online open-source repository, as well as some characteristic samples of the generated summaries.
Interactive GIS Web-Atlas for Twelve Pacific Islands Countries
Jul 15, 2021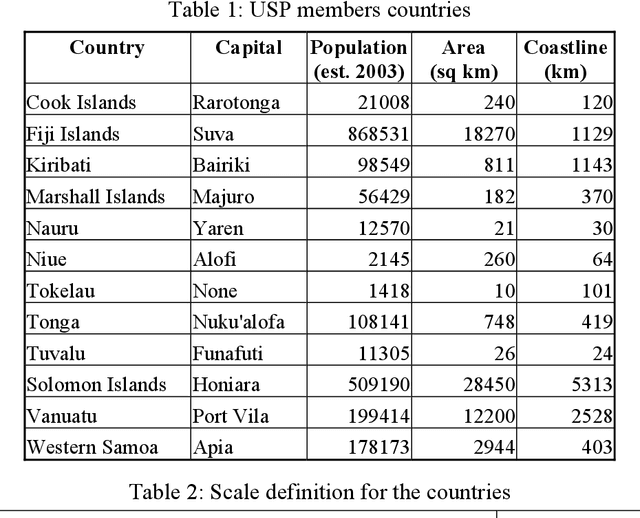
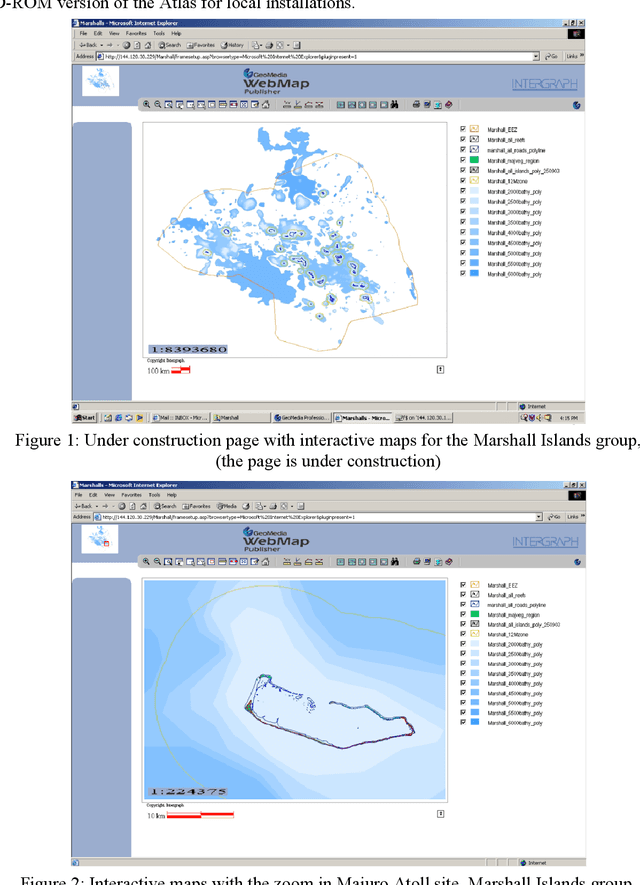
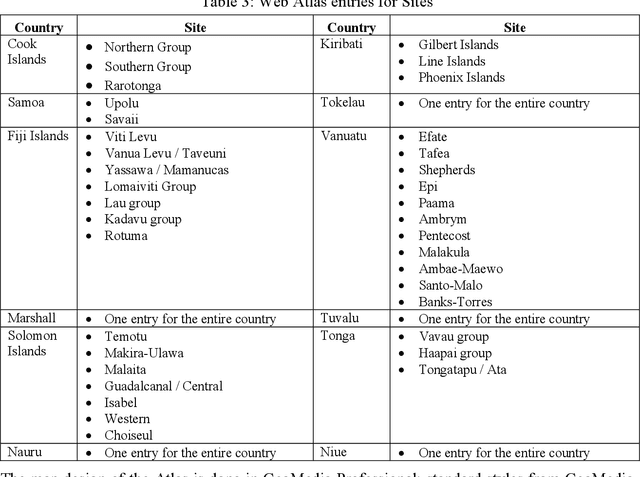
This article deals with the development of an interactive up-to-date Pacific Islands Web GIS Atlas. It focuses on the compilation of spatial data from the twelve member countries of the University of the South Pacific (Cook Islands, Fiji Islands, Kiribati Islands, Marshall Islands, Nauru, Niue, Tonga, Tuvalu, Tokelau, Solomon Islands, Vanuatu, and Western Samoa). A previous bitmap web Atlas was created in 1996, and was a pilot activity investigating the potential for using Geographical Information Systems (GIS) in the South Pacific. The objective of the new atlas is to provide sets of spatial and attributive data and maps for use of educators, students, researchers, policy makers and other relevant user groups and the public. GIS is a highly flexible and dynamic technology that allows the construction and analysis of maps and data sets from a variety of sources and formats. Nowadays, GIS application has moved from local and client-server applications to a three-tier architecture: Client (Web Browser) -- Application Web Map Server -- Spatial Data Warehouses. The objective of this project is to produce an Atlas that will include interactive maps and data on an Application Web Map Server. Intergraph products such as GeoMedia Professional, Web Map and Web Publisher have been selected for the web atlas production and design. In an interactive environment, an atlas will be composed from a series of maps and data profiles, which will be based on legend entries, queries, hot spots and cartographic tools. Only the first stage of development of the atlas and related technological solutions are outlined in this article.