 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generalized Selection in Wireless Powered Networks with Non-Linear Energy Harvesting
May 05, 2021
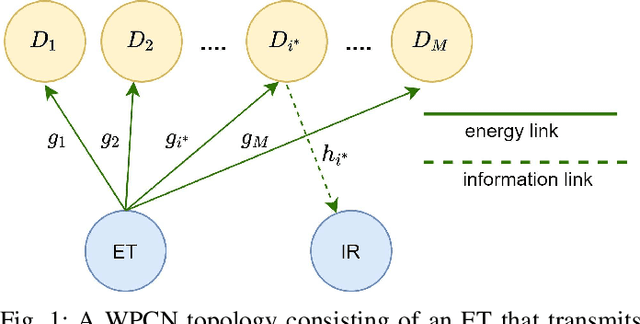
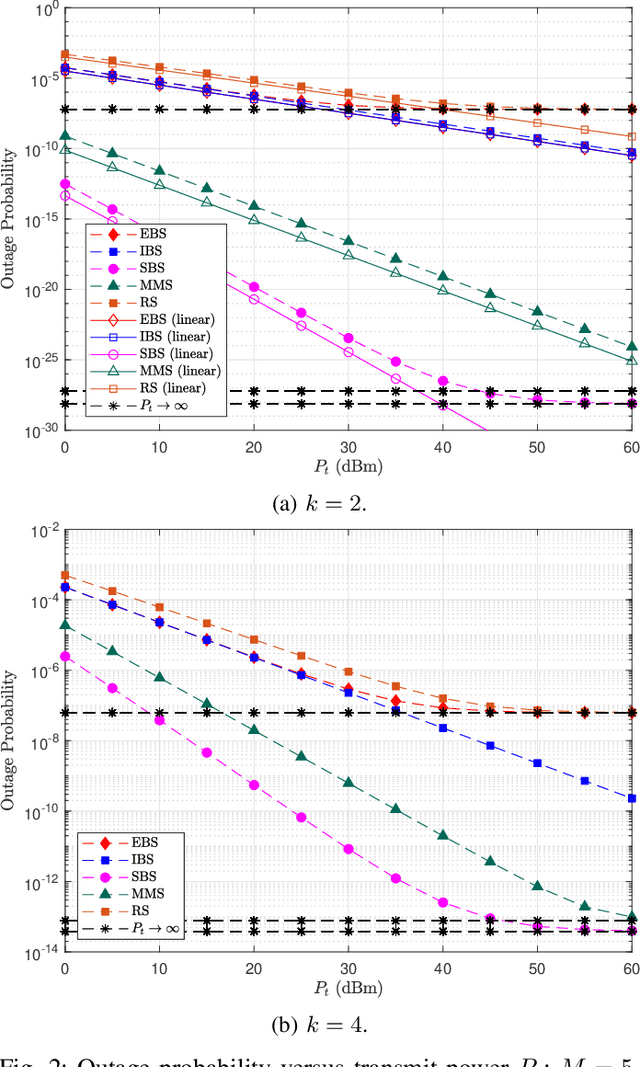
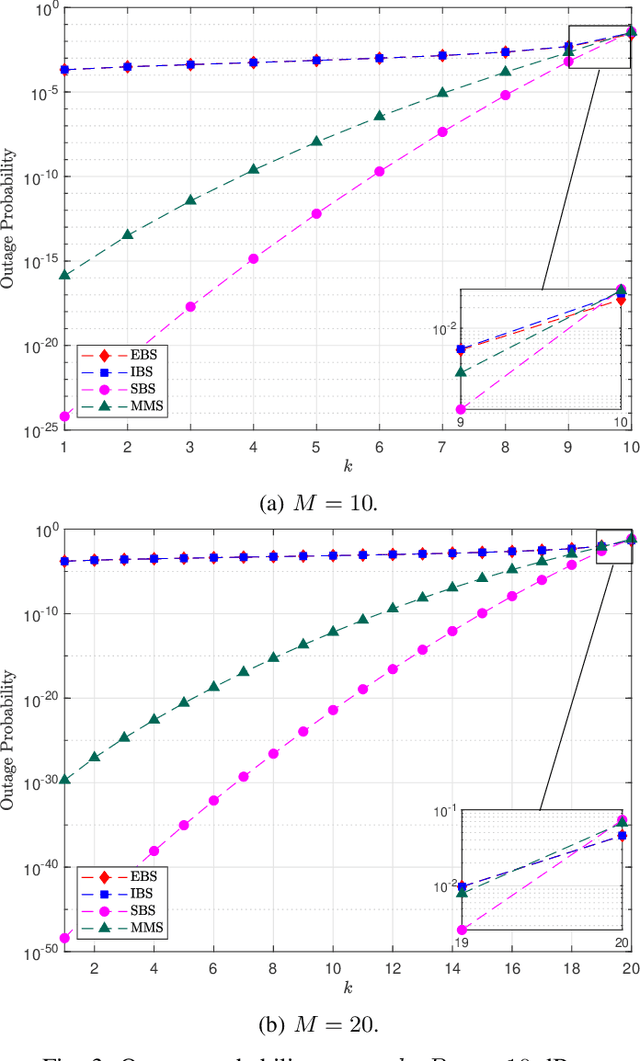
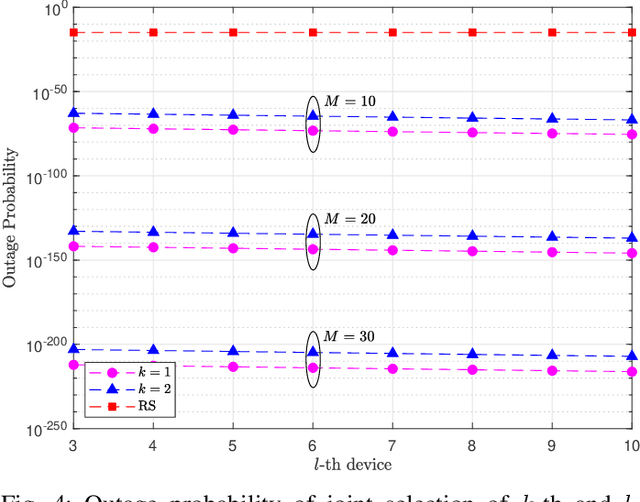
The rapid growth of the so-called Internet of Things is expected to significantly expand and support the deployment of resource-limited devices. Therefore, intelligent scheduling protocols and technologies such as wireless power transfer, are important for the efficient implementation of these massive low-powered networks. This paper studies the performance of a wireless powered communication network, where multiple batteryless devices harvest radio-frequency from a dedicated transmitter in order to communicate with a common information receiver (IR). We investigate several novel selection schemes, corresponding to different channel state information requirements and implementation complexities. In particular, each scheme schedules the $k$-th best device based on: a) the end-to-end (e2e) signal-to-noise ratio (SNR), b) the energy harvested at the devices, c) the uplink transmission to the IR, and d) the conventional/legacy max-min selection policy. We consider a non-linear energy harvesting (EH) model and derive analytical expressions for the outage probability of each selection scheme by using tools from high order statistics. %Our results show that, the performance of all the proposed schemes converges to an error floor due to the saturation effects of the considered EH model. Moreover, an asymptotic scenario in terms of the number of devices is considered and, by applying extreme value theory, the system's performance is evaluated. We derive a complete analytical framework that provides useful insights for the design and realization of such networks.
DiffSVC: A Diffusion Probabilistic Model for Singing Voice Conversion
May 28, 2021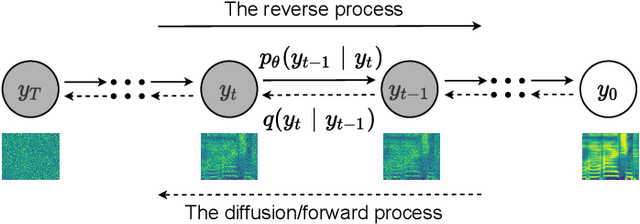
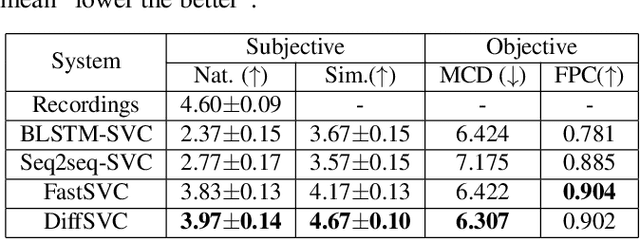
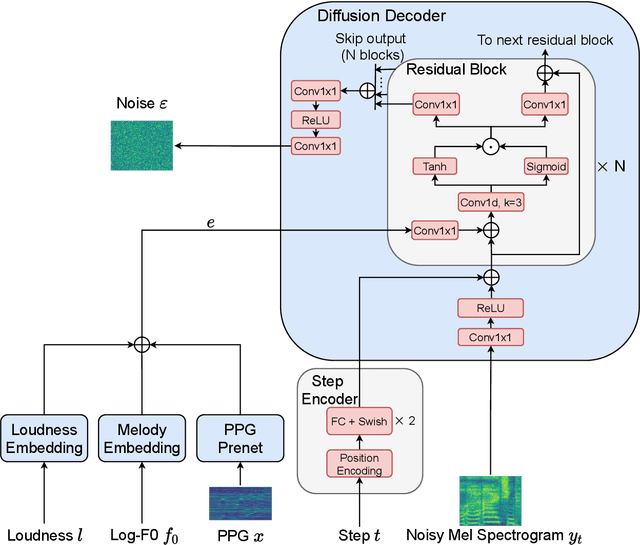
Singing voice conversion (SVC) is one promising technique which can enrich the way of human-computer interaction by endowing a computer the ability to produce high-fidelity and expressive singing voice. In this paper, we propose DiffSVC, an SVC system based on denoising diffusion probabilistic model. DiffSVC uses phonetic posteriorgrams (PPGs) as content features. A denoising module is trained in DiffSVC, which takes destroyed mel spectrogram produced by the diffusion/forward process and its corresponding step information as input to predict the added Gaussian noise. We use PPGs, fundamental frequency features and loudness features as auxiliary input to assist the denoising process. Experiments show that DiffSVC can achieve superior conversion performance in terms of naturalness and voice similarity to current state-of-the-art SVC approaches.
Federated Learning for Multi-Center Imaging Diagnostics: A Study in Cardiovascular Disease
Jul 07, 2021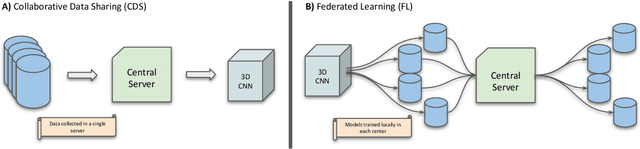

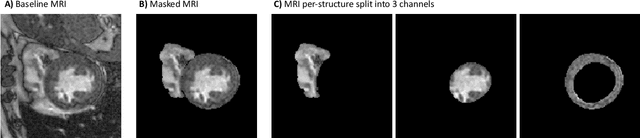

Deep learning models can enable accurate and efficient disease diagnosis, but have thus far been hampered by the data scarcity present in the medical world. Automated diagnosis studies have been constrained by underpowered single-center datasets, and although some results have shown promise, their generalizability to other institutions remains questionable as the data heterogeneity between institutions is not taken into account. By allowing models to be trained in a distributed manner that preserves patients' privacy, federated learning promises to alleviate these issues, by enabling diligent multi-center studies. We present the first federated learning study on the modality of cardiovascular magnetic resonance (CMR) and use four centers derived from subsets of the M\&M and ACDC datasets, focusing on the diagnosis of hypertrophic cardiomyopathy (HCM). We adapt a 3D-CNN network pretrained on action recognition and explore two different ways of incorporating shape prior information to the model, and four different data augmentation set-ups, systematically analyzing their impact on the different collaborative learning choices. We show that despite the small size of data (180 subjects derived from four centers), the privacy preserving federated learning achieves promising results that are competitive with traditional centralized learning. We further find that federatively trained models exhibit increased robustness and are more sensitive to domain shift effects.
Lattice-BERT: Leveraging Multi-Granularity Representations in Chinese Pre-trained Language Models
Apr 15, 2021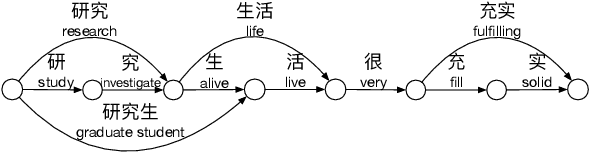
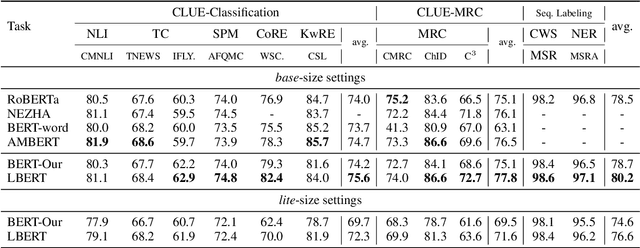
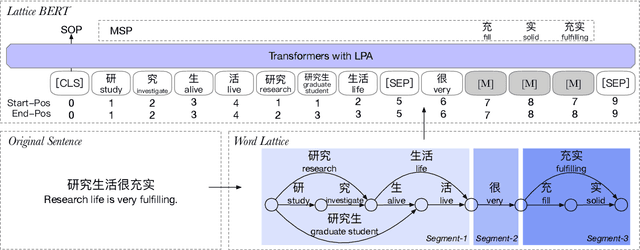
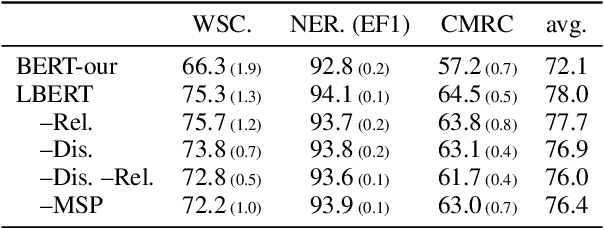
Chinese pre-trained language models usually process text as a sequence of characters, while ignoring more coarse granularity, e.g., words. In this work, we propose a novel pre-training paradigm for Chinese -- Lattice-BERT, which explicitly incorporates word representations along with characters, thus can model a sentence in a multi-granularity manner. Specifically, we construct a lattice graph from the characters and words in a sentence and feed all these text units into transformers. We design a lattice position attention mechanism to exploit the lattice structures in self-attention layers. We further propose a masked segment prediction task to push the model to learn from rich but redundant information inherent in lattices, while avoiding learning unexpected tricks. Experiments on 11 Chinese natural language understanding tasks show that our model can bring an average increase of 1.5% under the 12-layer setting, which achieves new state-of-the-art among base-size models on the CLUE benchmarks. Further analysis shows that Lattice-BERT can harness the lattice structures, and the improvement comes from the exploration of redundant information and multi-granularity representations. Our code will be available at https://github.com/alibaba/pretrained-language-models/LatticeBERT.
A Prospective Observational Study to Investigate Performance of a Chest X-ray Artificial Intelligence Diagnostic Support Tool Across 12 U.S. Hospitals
Jun 07, 2021Importance: An artificial intelligence (AI)-based model to predict COVID-19 likelihood from chest x-ray (CXR) findings can serve as an important adjunct to accelerate immediate clinical decision making and improve clinical decision making. Despite significant efforts, many limitations and biases exist in previously developed AI diagnostic models for COVID-19. Utilizing a large set of local and international CXR images, we developed an AI model with high performance on temporal and external validation. Conclusions and Relevance: AI-based diagnostic tools may serve as an adjunct, but not replacement, for clinical decision support of COVID-19 diagnosis, which largely hinges on exposure history, signs, and symptoms. While AI-based tools have not yet reached full diagnostic potential in COVID-19, they may still offer valuable information to clinicians taken into consideration along with clinical signs and symptoms.
A Multilingual African Embedding for FAQ Chatbots
Mar 16, 2021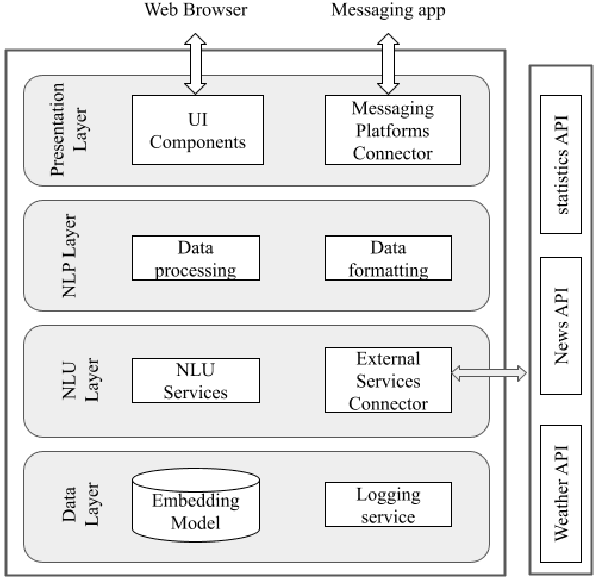
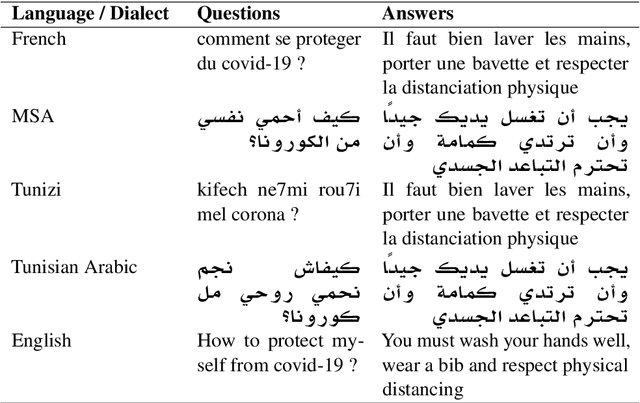

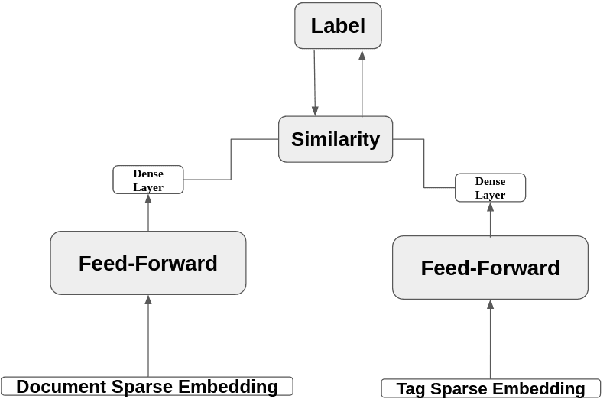
Searching for an available, reliable, official, and understandable information is not a trivial task due to scattered information across the internet, and the availability lack of governmental communication channels communicating with African dialects and languages. In this paper, we introduce an Artificial Intelligence Powered chatbot for crisis communication that would be omnichannel, multilingual and multi dialectal. We present our work on modified StarSpace embedding tailored for African dialects for the question-answering task along with the architecture of the proposed chatbot system and a description of the different layers. English, French, Arabic, Tunisian, Igbo,Yor\`ub\'a, and Hausa are used as languages and dialects. Quantitative and qualitative evaluation results are obtained for our real deployed Covid-19 chatbot. Results show that users are satisfied and the conversation with the chatbot is meeting customer needs.
Can Less be More? When Increasing-to-Balancing Label Noise Rates Considered Beneficial
Jul 13, 2021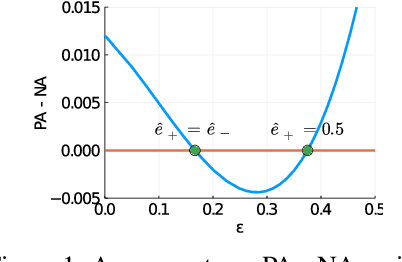
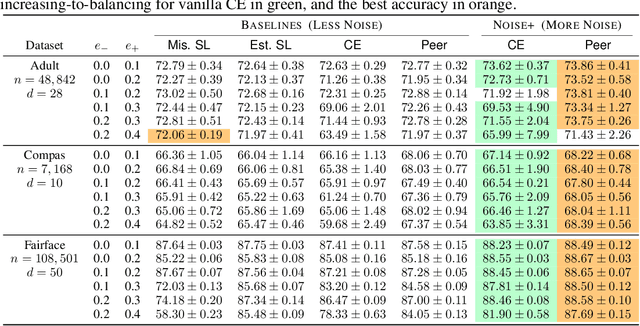

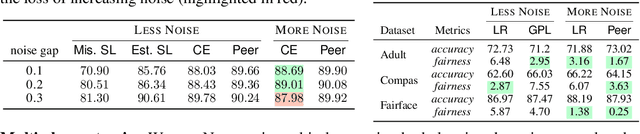
In this paper, we answer the question when inserting label noise (less informative labels) can instead return us more accurate and fair models. We are primarily inspired by two observations that 1) increasing a certain class of instances' label noise to balance the noise rates (increasing-to-balancing) results in an easier learning problem; 2) Increasing-to-balancing improves fairness guarantees against label bias. In this paper, we will first quantify the trade-offs introduced by increasing a certain group of instances' label noise rate w.r.t. the learning difficulties and performance guarantees. We analytically demonstrate when such an increase proves to be beneficial, in terms of either improved generalization errors or the fairness guarantees. Then we present a method to leverage our idea of inserting label noise for the task of learning with noisy labels, either without or with a fairness constraint. The primary technical challenge we face is due to the fact that we would not know which data instances are suffering from higher noise, and we would not have the ground truth labels to verify any possible hypothesis. We propose a detection method that informs us which group of labels might suffer from higher noise, without using ground truth information. We formally establish the effectiveness of the proposed solution and demonstrate it with extensive experiments.
LPF: A Language-Prior Feedback Objective Function for De-biased Visual Question Answering
Jun 23, 2021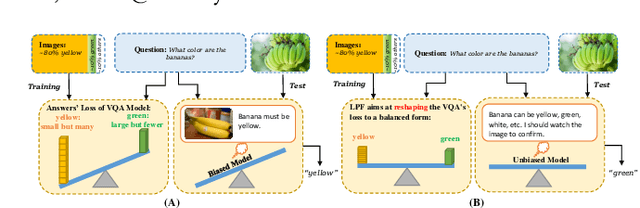
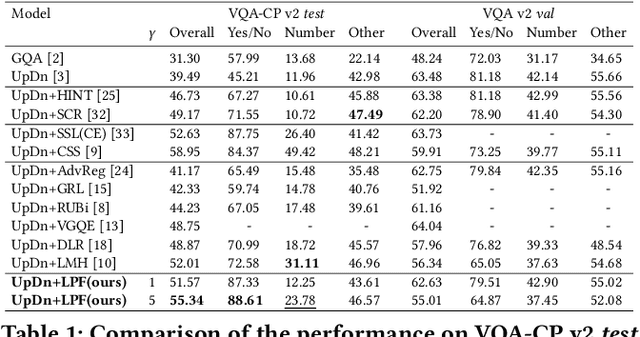
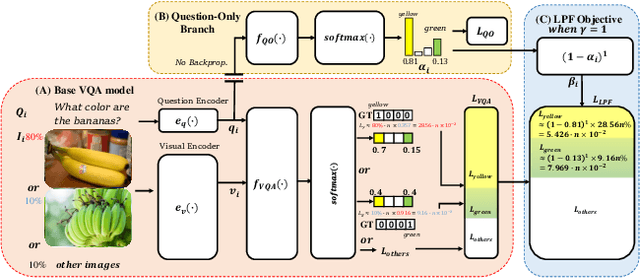
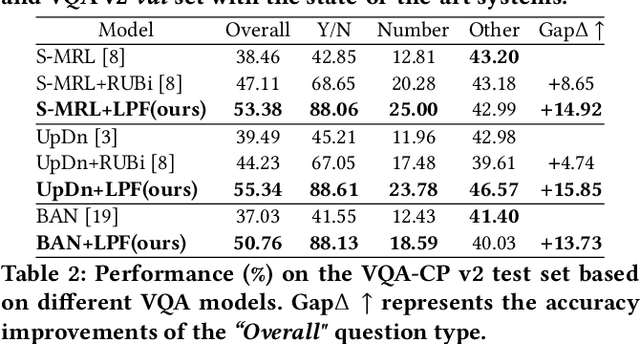
Most existing Visual Question Answering (VQA) systems tend to overly rely on language bias and hence fail to reason from the visual clue. To address this issue, we propose a novel Language-Prior Feedback (LPF) objective function, to re-balance the proportion of each answer's loss value in the total VQA loss. The LPF firstly calculates a modulating factor to determine the language bias using a question-only branch. Then, the LPF assigns a self-adaptive weight to each training sample in the training process. With this reweighting mechanism, the LPF ensures that the total VQA loss can be reshaped to a more balanced form. By this means, the samples that require certain visual information to predict will be efficiently used during training. Our method is simple to implement, model-agnostic, and end-to-end trainable. We conduct extensive experiments and the results show that the LPF (1) brings a significant improvement over various VQA models, (2) achieves competitive performance on the bias-sensitive VQA-CP v2 benchmark.
End-to-End Hierarchical Relation Extraction for Generic Form Understanding
Jun 02, 2021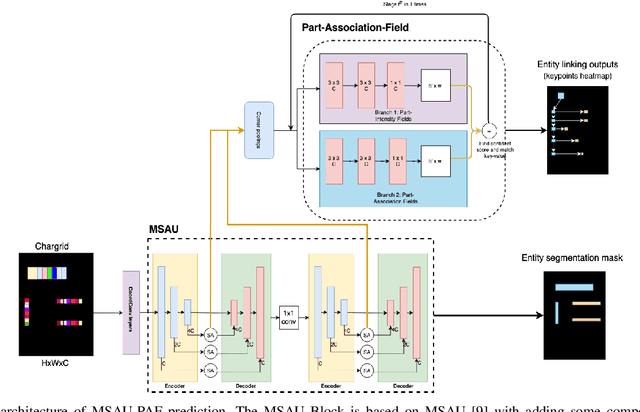
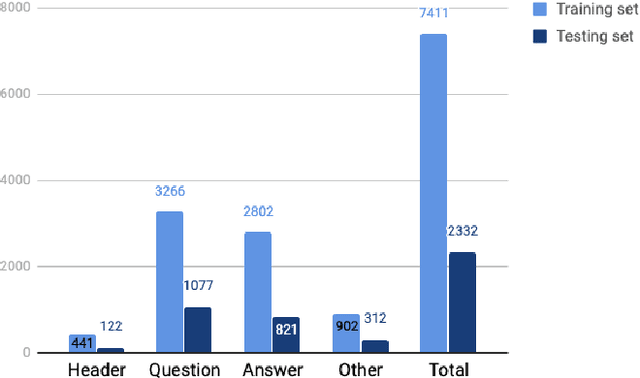
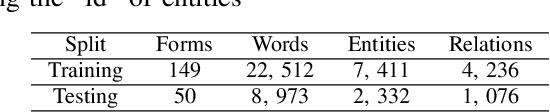

Form understanding is a challenging problem which aims to recognize semantic entities from the input document and their hierarchical relations. Previous approaches face significant difficulty dealing with the complexity of the task, thus treat these objectives separately. To this end, we present a novel deep neural network to jointly perform both entity detection and link prediction in an end-to-end fashion. Our model extends the Multi-stage Attentional U-Net architecture with the Part-Intensity Fields and Part-Association Fields for link prediction, enriching the spatial information flow with the additional supervision from entity linking. We demonstrate the effectiveness of the model on the Form Understanding in Noisy Scanned Documents (FUNSD) dataset, where our method substantially outperforms the original model and state-of-the-art baselines in both Entity Labeling and Entity Linking task.
* Accepted to ICPR 2020
Open Challenges on Generating Referring Expressions for Human-Robot Interaction
Apr 19, 2021
Effective verbal communication is crucial in human-robot collaboration. When a robot helps its human partner to complete a task with verbal instructions, referring expressions are commonly employed during the interaction. Despite many studies on generating referring expressions, crucial open challenges still remain for effective interaction. In this work, we discuss some of these challenges (i.e., using contextual information, taking users' perspectives, and handling misinterpretations in an autonomous manner).