 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Learning-based Online Alternative Product Recommendations at Scale
Apr 15, 2021

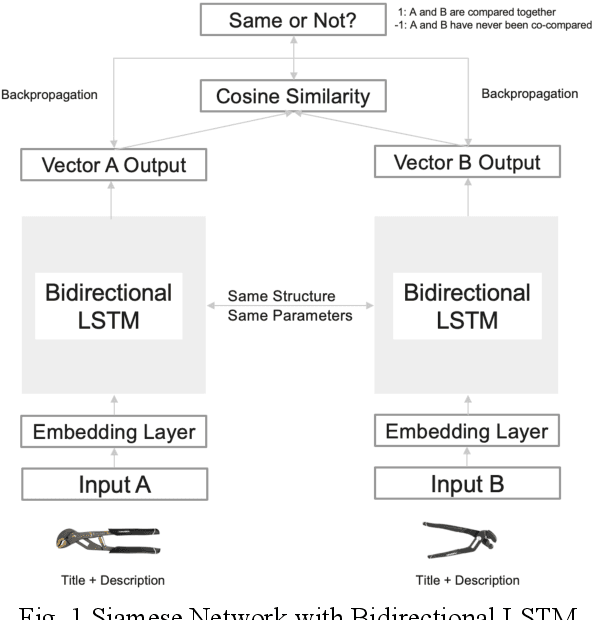

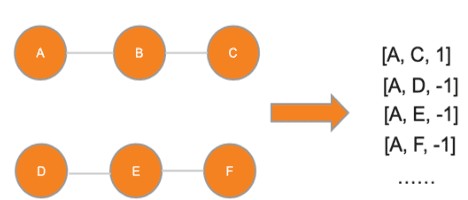
Alternative recommender systems are critical for ecommerce companies. They guide customers to explore a massive product catalog and assist customers to find the right products among an overwhelming number of options. However, it is a non-trivial task to recommend alternative products that fit customer needs. In this paper, we use both textual product information (e.g. product titles and descriptions) and customer behavior data to recommend alternative products. Our results show that the coverage of alternative products is significantly improved in offline evaluations as well as recall and precision. The final A/B test shows that our algorithm increases the conversion rate by 12 percent in a statistically significant way. In order to better capture the semantic meaning of product information, we build a Siamese Network with Bidirectional LSTM to learn product embeddings. In order to learn a similarity space that better matches the preference of real customers, we use co-compared data from historical customer behavior as labels to train the network. In addition, we use NMSLIB to accelerate the computationally expensive kNN computation for millions of products so that the alternative recommendation is able to scale across the entire catalog of a major ecommerce site.
Quantifying the amount of visual information used by neural caption generators
Oct 12, 2018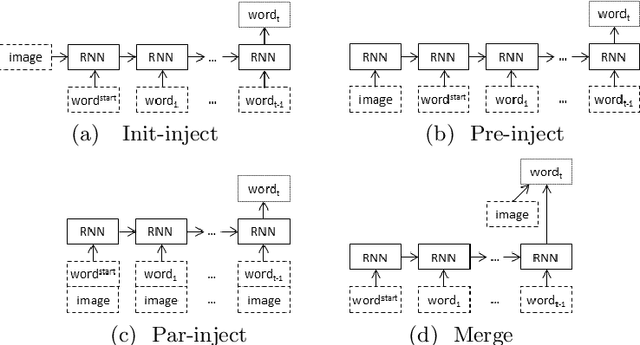
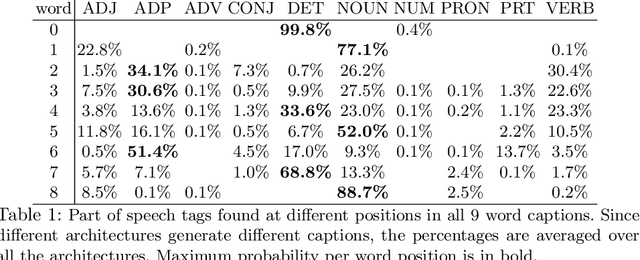
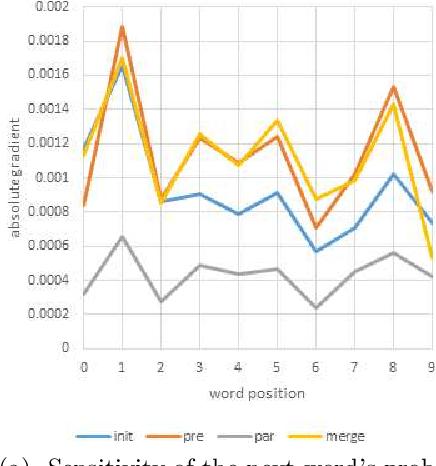
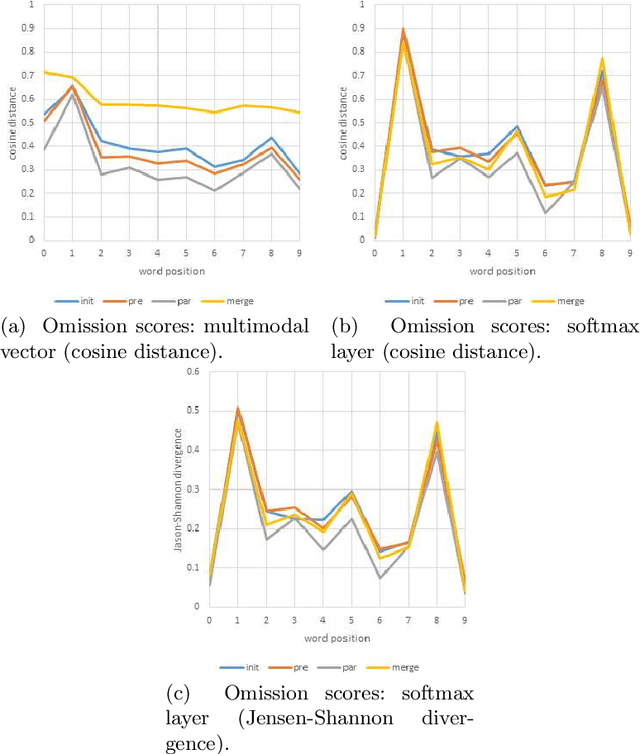
This paper addresses the sensitivity of neural image caption generators to their visual input. A sensitivity analysis and omission analysis based on image foils is reported, showing that the extent to which image captioning architectures retain and are sensitive to visual information varies depending on the type of word being generated and the position in the caption as a whole. We motivate this work in the context of broader goals in the field to achieve more explainability in AI.
E-DSSR: Efficient Dynamic Surgical Scene Reconstruction with Transformer-based Stereoscopic Depth Perception
Jul 01, 2021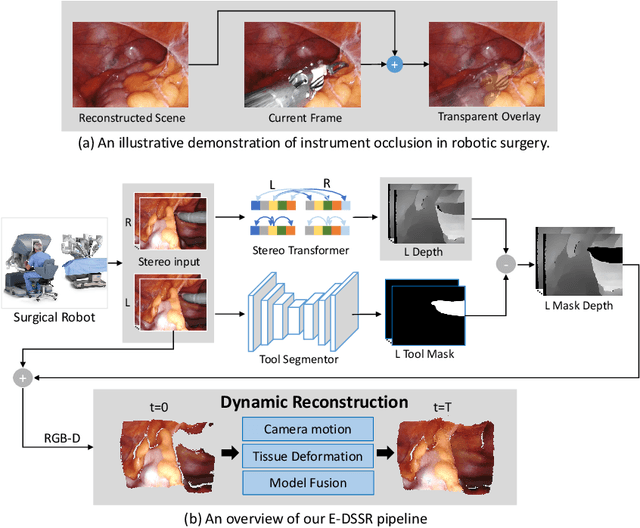
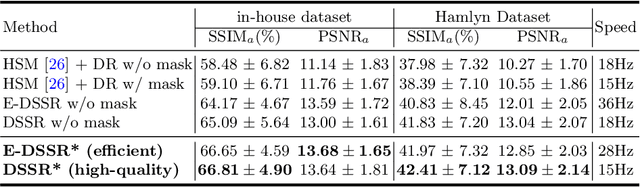
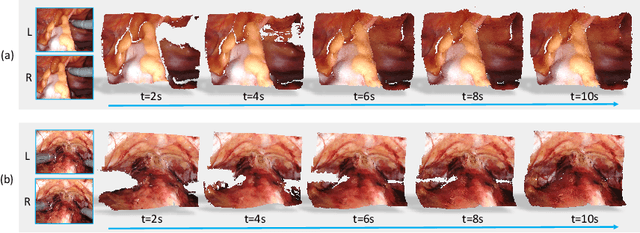
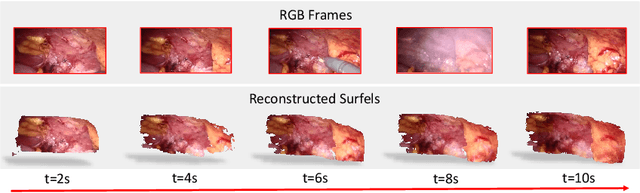
Reconstructing the scene of robotic surgery from the stereo endoscopic video is an important and promising topic in surgical data science, which potentially supports many applications such as surgical visual perception, robotic surgery education and intra-operative context awareness. However, current methods are mostly restricted to reconstructing static anatomy assuming no tissue deformation, tool occlusion and de-occlusion, and camera movement. However, these assumptions are not always satisfied in minimal invasive robotic surgeries. In this work, we present an efficient reconstruction pipeline for highly dynamic surgical scenes that runs at 28 fps. Specifically, we design a transformer-based stereoscopic depth perception for efficient depth estimation and a light-weight tool segmentor to handle tool occlusion. After that, a dynamic reconstruction algorithm which can estimate the tissue deformation and camera movement, and aggregate the information over time is proposed for surgical scene reconstruction. We evaluate the proposed pipeline on two datasets, the public Hamlyn Centre Endoscopic Video Dataset and our in-house DaVinci robotic surgery dataset. The results demonstrate that our method can recover the scene obstructed by the surgical tool and handle the movement of camera in realistic surgical scenarios effectively at real-time speed.
An audiovisual and contextual approach for categorical and continuous emotion recognition in-the-wild
Jul 07, 2021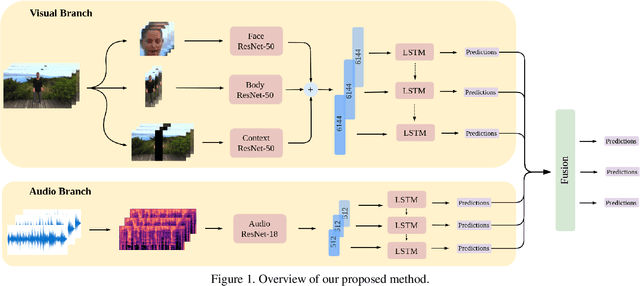
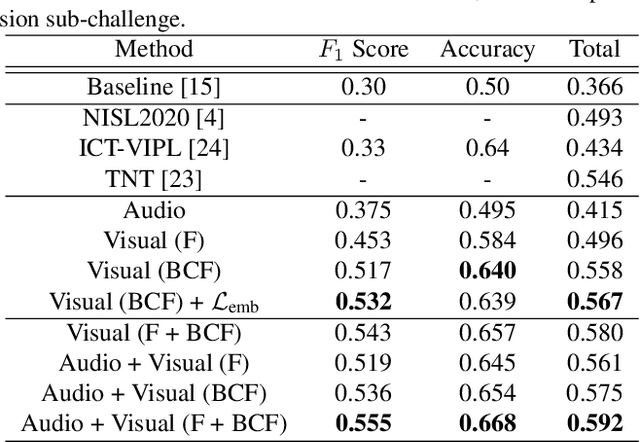
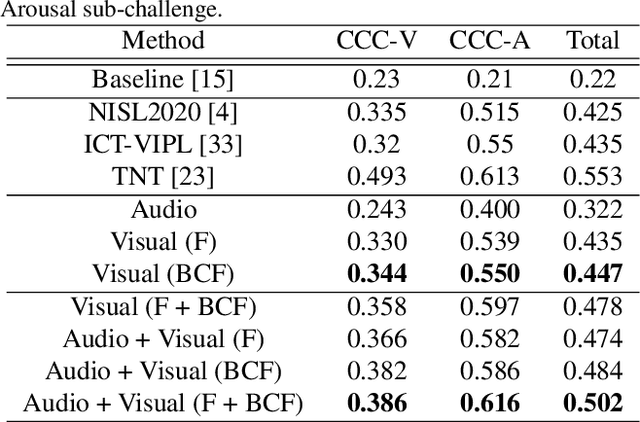
In this work we tackle the task of video-based audio-visual emotion recognition, within the premises of the 2nd Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW). Standard methodologies that rely solely on the extraction of facial features often fall short of accurate emotion prediction in cases where the aforementioned source of affective information is inaccessible due to head/body orientation, low resolution and poor illumination. We aspire to alleviate this problem by leveraging bodily as well as contextual features, as part of a broader emotion recognition framework. A standard CNN-RNN cascade constitutes the backbone of our proposed model for sequence-to-sequence (seq2seq) learning. Apart from learning through the \textit{RGB} input modality, we construct an aural stream which operates on sequences of extracted mel-spectrograms. Our extensive experiments on the challenging and newly assembled Affect-in-the-wild-2 (Aff-Wild2) dataset verify the superiority of our methods over existing approaches, while by properly incorporating all of the aforementioned modules in a network ensemble, we manage to surpass the previous best published recognition scores, in the official validation set. All the code was implemented using PyTorch\footnote{\url{https://pytorch.org/}} and is publicly available\footnote{\url{https://github.com/PanosAntoniadis/NTUA-ABAW2021}}.
Syntax-BERT: Improving Pre-trained Transformers with Syntax Trees
Mar 07, 2021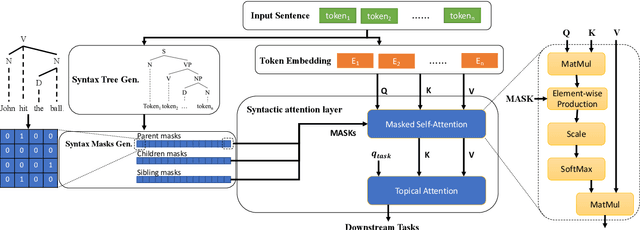

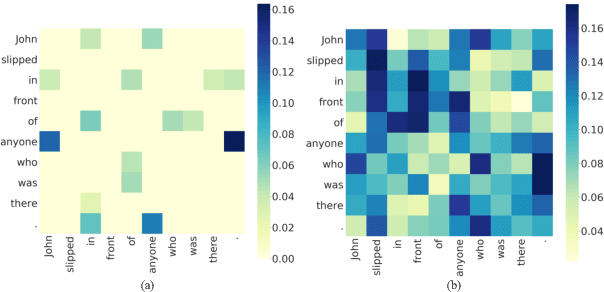
Pre-trained language models like BERT achieve superior performances in various NLP tasks without explicit consideration of syntactic information. Meanwhile, syntactic information has been proved to be crucial for the success of NLP applications. However, how to incorporate the syntax trees effectively and efficiently into pre-trained Transformers is still unsettled. In this paper, we address this problem by proposing a novel framework named Syntax-BERT. This framework works in a plug-and-play mode and is applicable to an arbitrary pre-trained checkpoint based on Transformer architecture. Experiments on various datasets of natural language understanding verify the effectiveness of syntax trees and achieve consistent improvement over multiple pre-trained models, including BERT, RoBERTa, and T5.
On the Importance of Subword Information for Morphological Tasks in Truly Low-Resource Languages
Sep 26, 2019
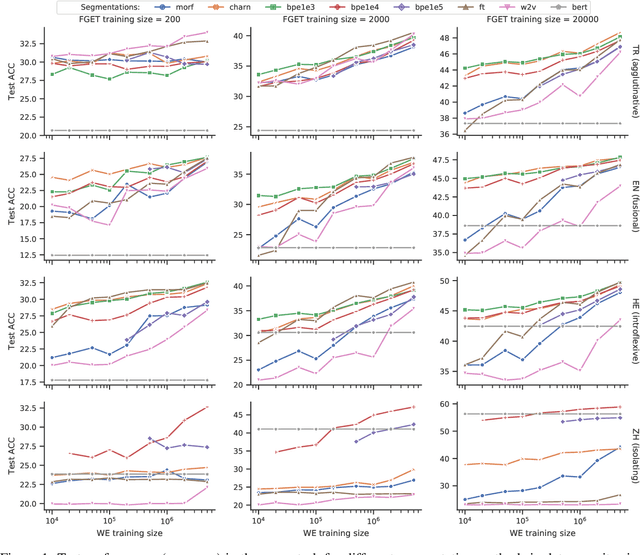
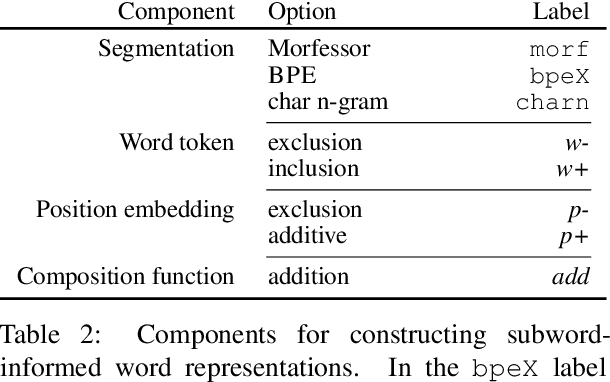
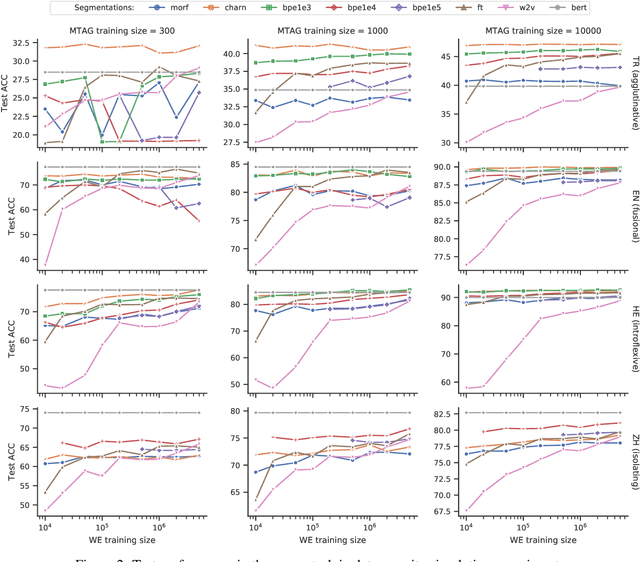
Recent work has validated the importance of subword information for word representation learning. Since subwords increase parameter sharing ability in neural models, their value should be even more pronounced in low-data regimes. In this work, we therefore provide a comprehensive analysis focused on the usefulness of subwords for word representation learning in truly low-resource scenarios and for three representative morphological tasks: fine-grained entity typing, morphological tagging, and named entity recognition. We conduct a systematic study that spans several dimensions of comparison: 1) type of data scarcity which can stem from the lack of task-specific training data, or even from the lack of unannotated data required to train word embeddings, or both; 2) language type by working with a sample of 16 typologically diverse languages including some truly low-resource ones (e.g. Rusyn, Buryat, and Zulu); 3) the choice of the subword-informed word representation method. Our main results show that subword-informed models are universally useful across all language types, with large gains over subword-agnostic embeddings. They also suggest that the effective use of subwords largely depends on the language (type) and the task at hand, as well as on the amount of available data for training the embeddings and task-based models, where having sufficient in-task data is a more critical requirement.
U-GAT: Multimodal Graph Attention Network for COVID-19 Outcome Prediction
Jul 29, 2021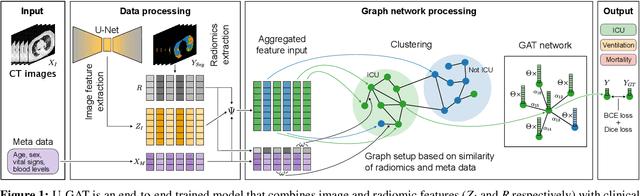
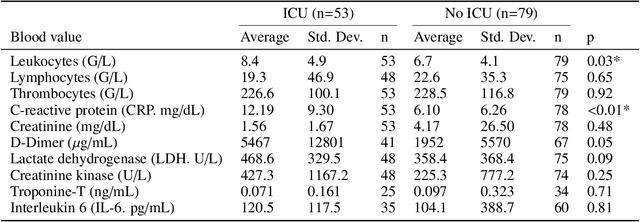
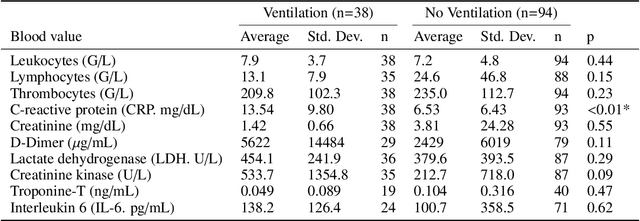
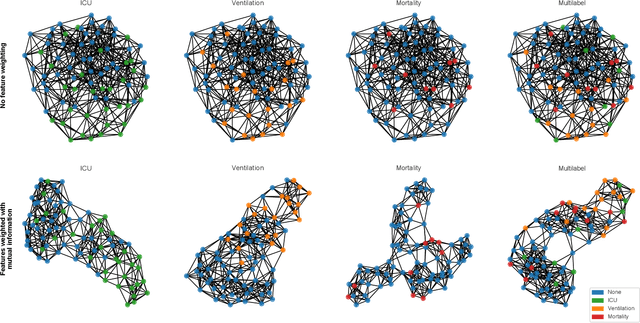
During the first wave of COVID-19, hospitals were overwhelmed with the high number of admitted patients. An accurate prediction of the most likely individual disease progression can improve the planning of limited resources and finding the optimal treatment for patients. However, when dealing with a newly emerging disease such as COVID-19, the impact of patient- and disease-specific factors (e.g. body weight or known co-morbidities) on the immediate course of disease is by and large unknown. In the case of COVID-19, the need for intensive care unit (ICU) admission of pneumonia patients is often determined only by acute indicators such as vital signs (e.g. breathing rate, blood oxygen levels), whereas statistical analysis and decision support systems that integrate all of the available data could enable an earlier prognosis. To this end, we propose a holistic graph-based approach combining both imaging and non-imaging information. Specifically, we introduce a multimodal similarity metric to build a population graph for clustering patients and an image-based end-to-end Graph Attention Network to process this graph and predict the COVID-19 patient outcomes: admission to ICU, need for ventilation and mortality. Additionally, the network segments chest CT images as an auxiliary task and extracts image features and radiomics for feature fusion with the available metadata. Results on a dataset collected in Klinikum rechts der Isar in Munich, Germany show that our approach outperforms single modality and non-graph baselines. Moreover, our clustering and graph attention allow for increased understanding of the patient relationships within the population graph and provide insight into the network's decision-making process.
The Struggle with Academic Plagiarism: Approaches based on Semantic Similarity
Jun 02, 2021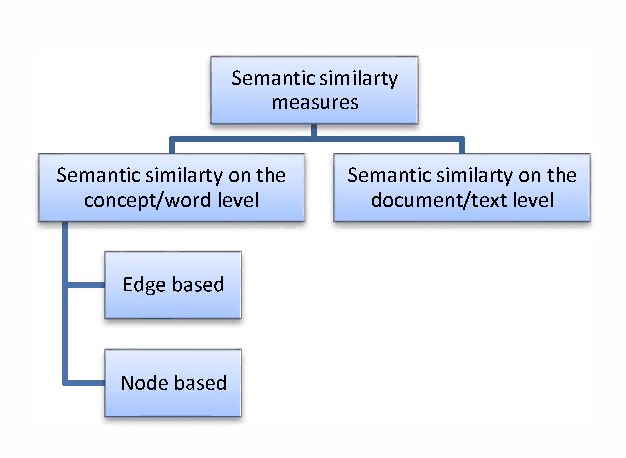
Academic plagiarism is a serious problem nowadays. Due to the existence of inexhaustible sources of digital information, today it is easier to plagiarize more than ever before. The good thing is that plagiarism detection techniques have improved and are powerful enough to detect attempts of plagiarism in education. We are now witnessing efficient plagiarism detection software in action, such as Turnitin, iThenticate or SafeAssign. In the introduction we explore software that is used within the Croatian academic community for plagiarism detection in universities and/or in scientific journals. The question is: is this enough? Current software has proven to be successful, however the problem of identifying paraphrasing or obfuscation plagiarism remains unresolved. In this paper we present a report of how semantic similarity measures can be used in the plagiarism detection task.
* 6 pages, 1 figure, 34 references
Parallelizing Thompson Sampling
Jun 02, 2021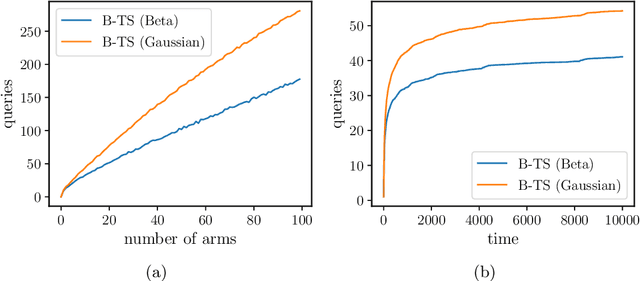
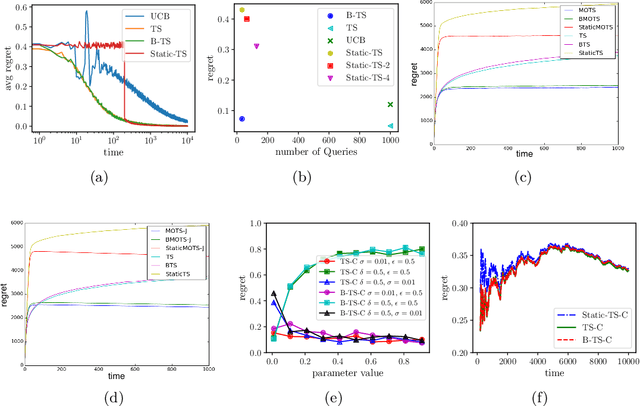
How can we make use of information parallelism in online decision making problems while efficiently balancing the exploration-exploitation trade-off? In this paper, we introduce a batch Thompson Sampling framework for two canonical online decision making problems, namely, stochastic multi-arm bandit and linear contextual bandit with finitely many arms. Over a time horizon $T$, our \textit{batch} Thompson Sampling policy achieves the same (asymptotic) regret bound of a fully sequential one while carrying out only $O(\log T)$ batch queries. To achieve this exponential reduction, i.e., reducing the number of interactions from $T$ to $O(\log T)$, our batch policy dynamically determines the duration of each batch in order to balance the exploration-exploitation trade-off. We also demonstrate experimentally that dynamic batch allocation dramatically outperforms natural baselines such as static batch allocations.
supervised adptive threshold network for instance segmentation
Jun 07, 2021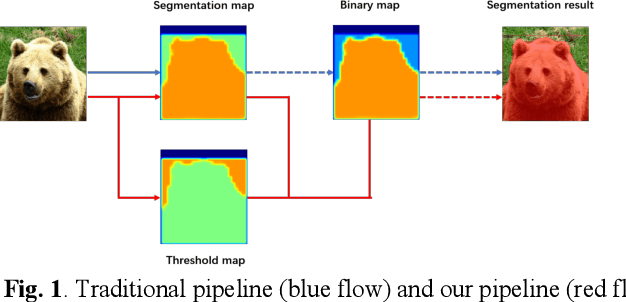
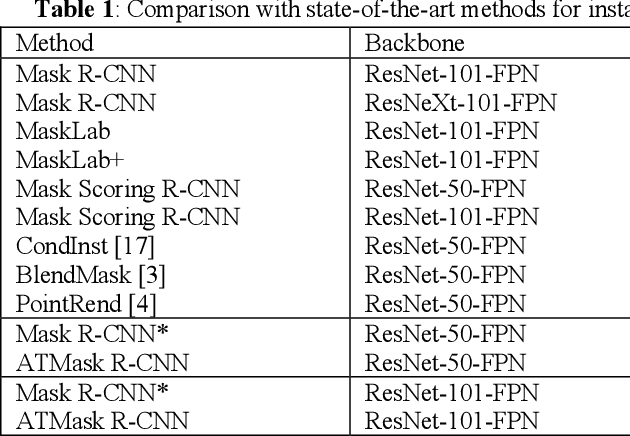

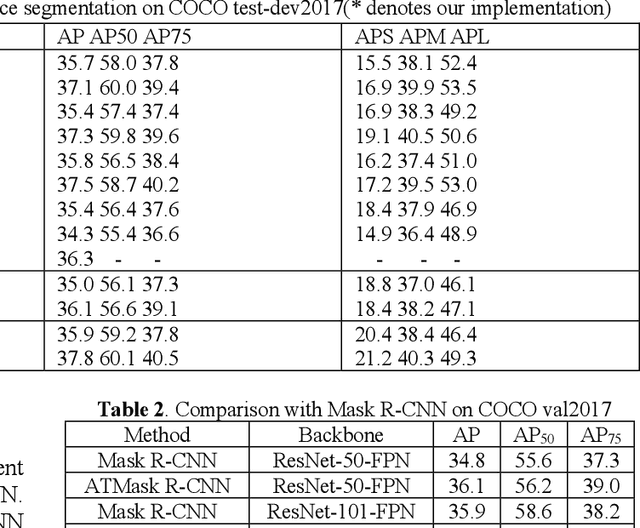
Currently, instance segmentation is attracting more and more attention in machine learning region. However, there exists some defects on the information propagation in previous Mask R-CNN and other network models. In this paper, we propose supervised adaptive threshold network for instance segmentation. Specifically, we adopt the Mask R-CNN method based on adaptive threshold, and by establishing a layered adaptive network structure, it performs adaptive binarization on the probability graph generated by Mask RCNN to obtain better segmentation effect and reduce the error rate. At the same time, an adaptive feature pool is designed to make the transmission between different layers of the network more accurate and effective, reduce the loss in the process of feature transmission, and further improve the mask method. Experiments on benchmark data sets indicate that the effectiveness of the proposed model