 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Comparative evaluation of CNN architectures for Image Caption Generation
Feb 23, 2021
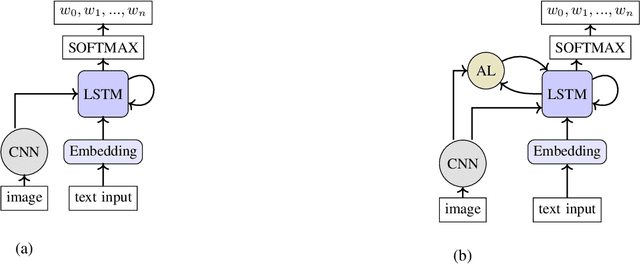
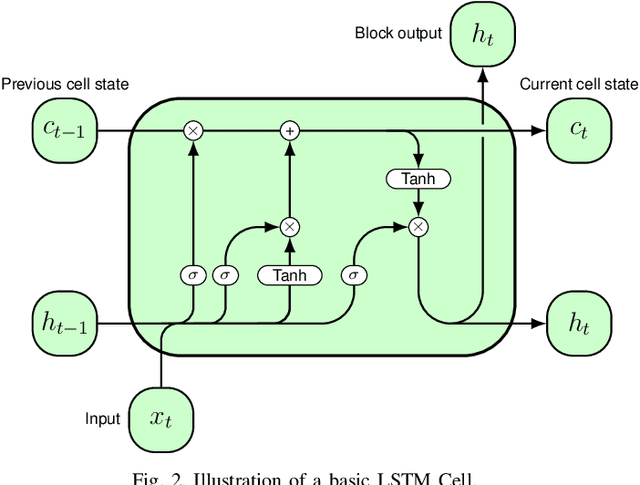
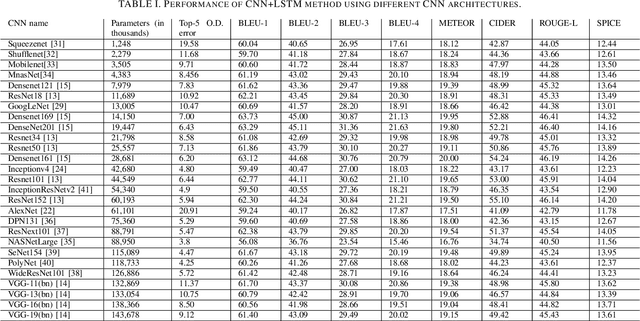
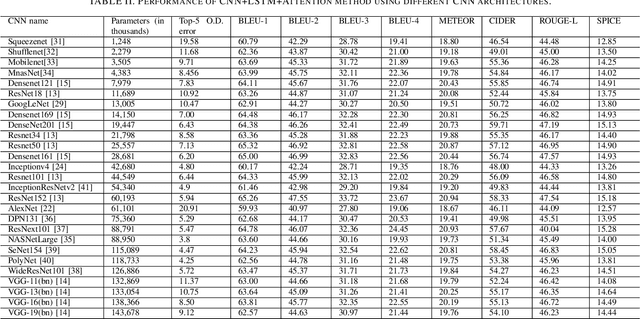
Aided by recent advances in Deep Learning, Image Caption Generation has seen tremendous progress over the last few years. Most methods use transfer learning to extract visual information, in the form of image features, with the help of pre-trained Convolutional Neural Network models followed by transformation of the visual information using a Caption Generator module to generate the output sentences. Different methods have used different Convolutional Neural Network Architectures and, to the best of our knowledge, there is no systematic study which compares the relative efficacy of different Convolutional Neural Network architectures for extracting the visual information. In this work, we have evaluated 17 different Convolutional Neural Networks on two popular Image Caption Generation frameworks: the first based on Neural Image Caption (NIC) generation model and the second based on Soft-Attention framework. We observe that model complexity of Convolutional Neural Network, as measured by number of parameters, and the accuracy of the model on Object Recognition task does not necessarily co-relate with its efficacy on feature extraction for Image Caption Generation task.
* Article Published in International Journal of Advanced Computer Science and Applications(IJACSA), Volume 11 Issue 12, 2020
Plot2API: Recommending Graphic API from Plot via Semantic Parsing Guided Neural Network
Apr 02, 2021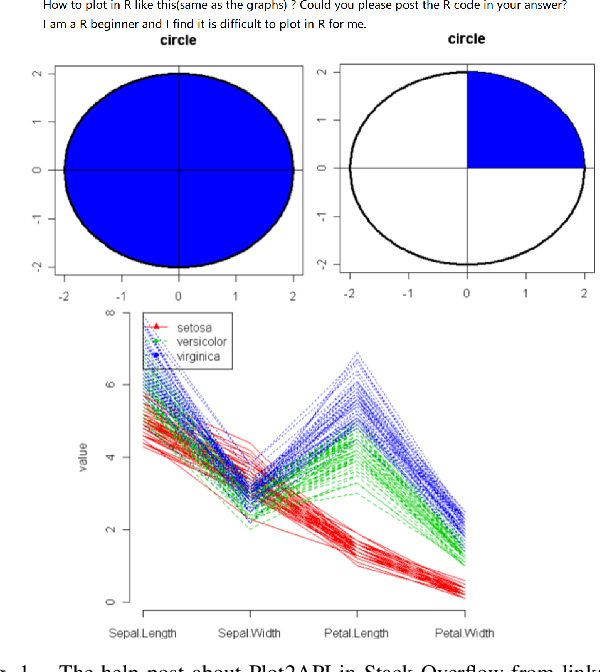
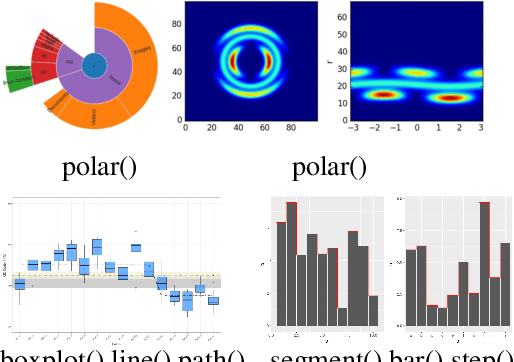
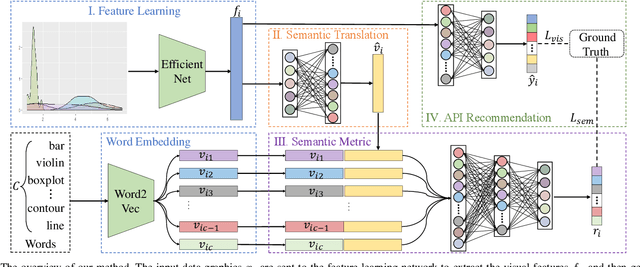
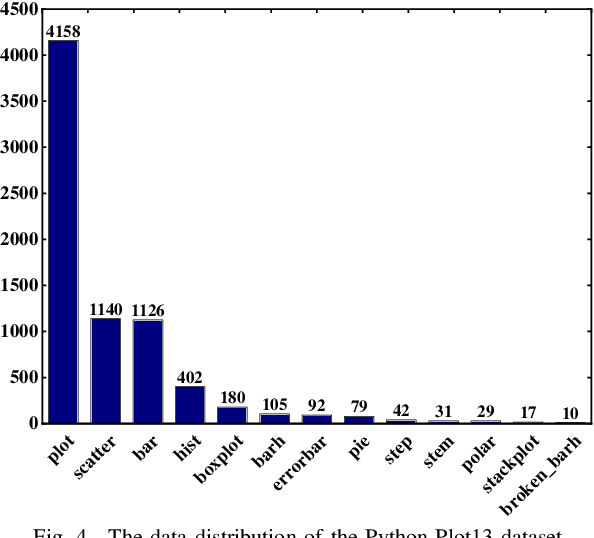
Plot-based Graphic API recommendation (Plot2API) is an unstudied but meaningful issue, which has several important applications in the context of software engineering and data visualization, such as the plotting guidance of the beginner, graphic API correlation analysis, and code conversion for plotting. Plot2API is a very challenging task, since each plot is often associated with multiple APIs and the appearances of the graphics drawn by the same API can be extremely varied due to the different settings of the parameters. Additionally, the samples of different APIs also suffer from extremely imbalanced. Considering the lack of technologies in Plot2API, we present a novel deep multi-task learning approach named Semantic Parsing Guided Neural Network (SPGNN) which translates the Plot2API issue as a multi-label image classification and an image semantic parsing tasks for the solution. In SPGNN, the recently advanced Convolutional Neural Network (CNN) named EfficientNet is employed as the backbone network for API recommendation. Meanwhile, a semantic parsing module is complemented to exploit the semantic relevant visual information in feature learning and eliminate the appearance-relevant visual information which may confuse the visual-information-based API recommendation. Moreover, the recent data augmentation technique named random erasing is also applied for alleviating the imbalance of API categories. We collect plots with the graphic APIs used to drawn them from Stack Overflow, and release three new Plot2API datasets corresponding to the graphic APIs of R and Python programming languages for evaluating the effectiveness of Plot2API techniques. Extensive experimental results not only demonstrate the superiority of our method over the recent deep learning baselines but also show the practicability of our method in the recommendation of graphic APIs.
Online learning of windmill time series using Long Short-term Cognitive Networks
Jul 01, 2021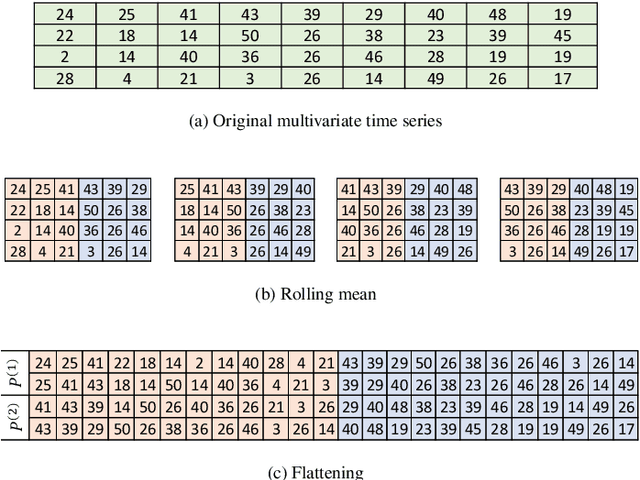
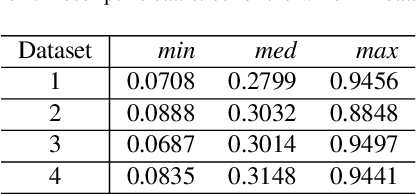
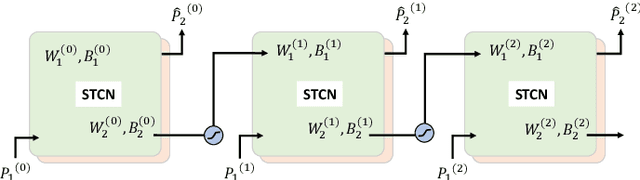
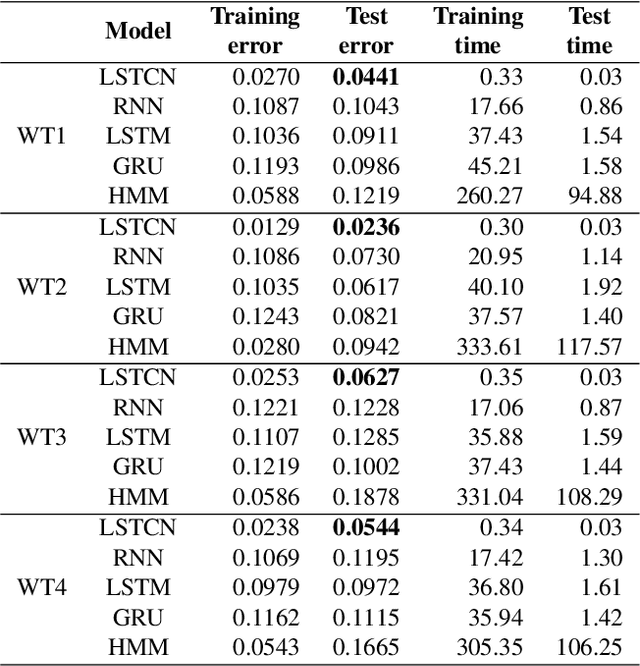
Forecasting windmill time series is often the basis of other processes such as anomaly detection, health monitoring, or maintenance scheduling. The amount of data generated on windmill farms makes online learning the most viable strategy to follow. Such settings require retraining the model each time a new batch of data is available. However, update the model with the new information is often very expensive to perform using traditional Recurrent Neural Networks (RNNs). In this paper, we use Long Short-term Cognitive Networks (LSTCNs) to forecast windmill time series in online settings. These recently introduced neural systems consist of chained Short-term Cognitive Network blocks, each processing a temporal data chunk. The learning algorithm of these blocks is based on a very fast, deterministic learning rule that makes LSTCNs suitable for online learning tasks. The numerical simulations using a case study with four windmills showed that our approach reported the lowest forecasting errors with respect to a simple RNN, a Long Short-term Memory, a Gated Recurrent Unit, and a Hidden Markov Model. What is perhaps more important is that the LSTCN approach is significantly faster than these state-of-the-art models.
Machine learning based iterative learning control for non-repetitive time-varying systems
Jul 01, 2021
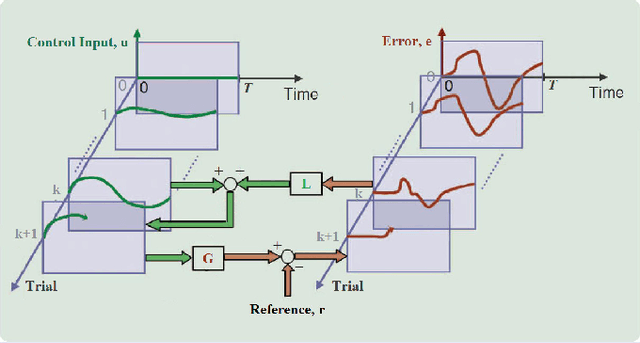
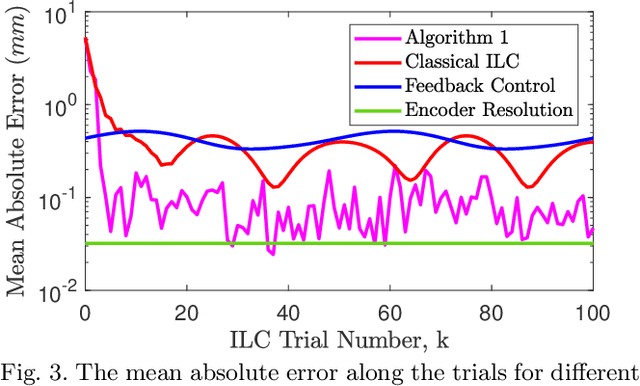
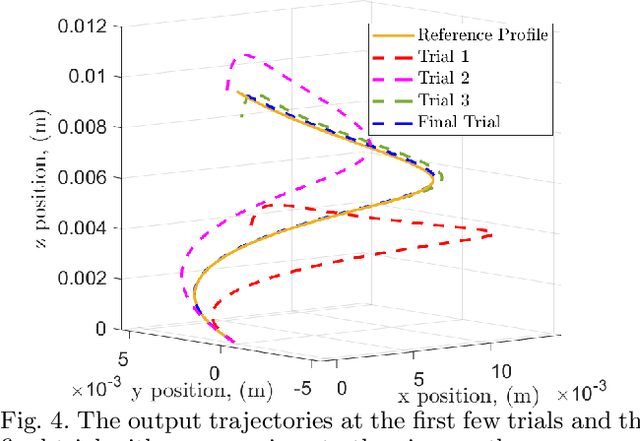
The repetitive tracking task for time-varying systems (TVSs) with non-repetitive time-varying parameters, which is also called non-repetitive TVSs, is realized in this paper using iterative learning control (ILC). A machine learning (ML) based nominal model update mechanism, which utilizes the linear regression technique to update the nominal model at each ILC trial only using the current trial information, is proposed for non-repetitive TVSs in order to enhance the ILC performance. Given that the ML mechanism forces the model uncertainties to remain within the ILC robust tolerance, an ILC update law is proposed to deal with non-repetitive TVSs. How to tune parameters inside ML and ILC algorithms to achieve the desired aggregate performance is also provided. The robustness and reliability of the proposed method are verified by simulations. Comparison with current state-of-the-art demonstrates its superior control performance in terms of controlling precision. This paper broadens ILC applications from time-invariant systems to non-repetitive TVSs, adopts ML regression technique to estimate non-repetitive time-varying parameters between two ILC trials and proposes a detailed parameter tuning mechanism to achieve desired performance, which are the main contributions.
FaceController: Controllable Attribute Editing for Face in the Wild
Feb 23, 2021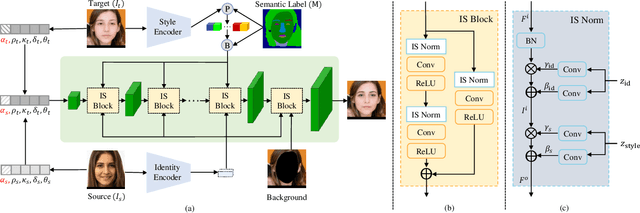
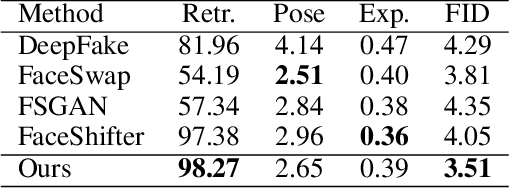
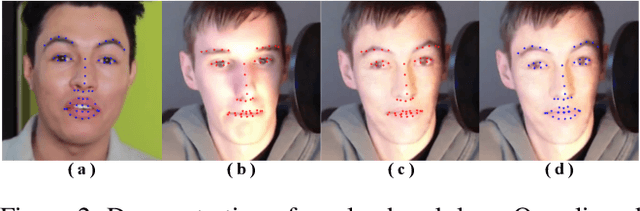
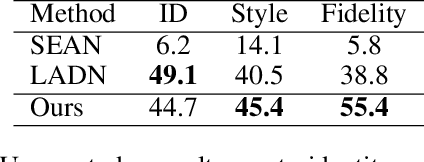
Face attribute editing aims to generate faces with one or multiple desired face attributes manipulated while other details are preserved. Unlike prior works such as GAN inversion, which has an expensive reverse mapping process, we propose a simple feed-forward network to generate high-fidelity manipulated faces. By simply employing some existing and easy-obtainable prior information, our method can control, transfer, and edit diverse attributes of faces in the wild. The proposed method can consequently be applied to various applications such as face swapping, face relighting, and makeup transfer. In our method, we decouple identity, expression, pose, and illumination using 3D priors; separate texture and colors by using region-wise style codes. All the information is embedded into adversarial learning by our identity-style normalization module. Disentanglement losses are proposed to enhance the generator to extract information independently from each attribute. Comprehensive quantitative and qualitative evaluations have been conducted. In a single framework, our method achieves the best or competitive scores on a variety of face applications.
Attribute Selection using Contranominal Scales
Jul 01, 2021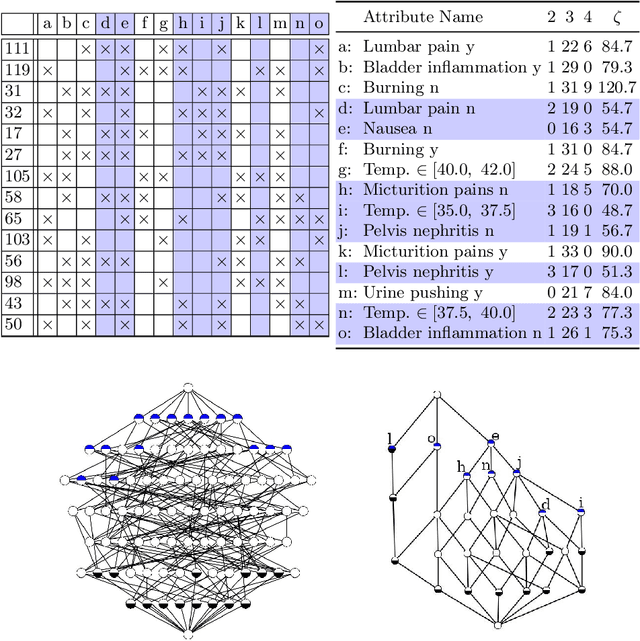
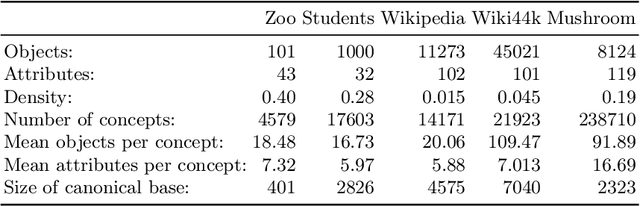
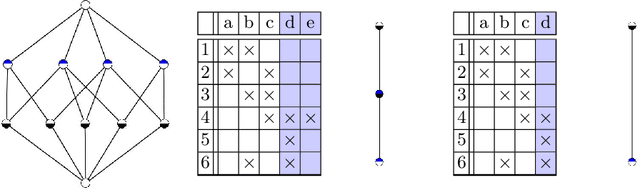
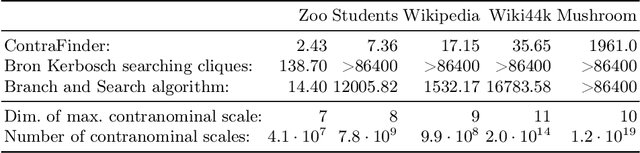
Formal Concept Analysis (FCA) allows to analyze binary data by deriving concepts and ordering them in lattices. One of the main goals of FCA is to enable humans to comprehend the information that is encapsulated in the data; however, the large size of concept lattices is a limiting factor for the feasibility of understanding the underlying structural properties. The size of such a lattice depends on the number of subcontexts in the corresponding formal context that are isomorphic to a contranominal scale of high dimension. In this work, we propose the algorithm ContraFinder that enables the computation of all contranominal scales of a given formal context. Leveraging this algorithm, we introduce delta-adjusting, a novel approach in order to decrease the number of contranominal scales in a formal context by the selection of an appropriate attribute subset. We demonstrate that delta-adjusting a context reduces the size of the hereby emerging sub-semilattice and that the implication set is restricted to meaningful implications. This is evaluated with respect to its associated knowledge by means of a classification task. Hence, our proposed technique strongly improves understandability while preserving important conceptual structures.
Modelling Neuronal Behaviour with Time Series Regression: Recurrent Neural Networks on C. Elegans Data
Jul 01, 2021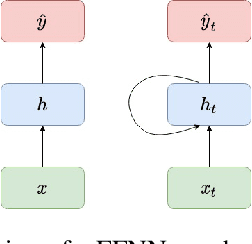

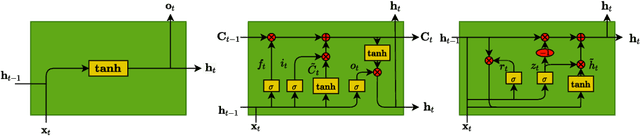
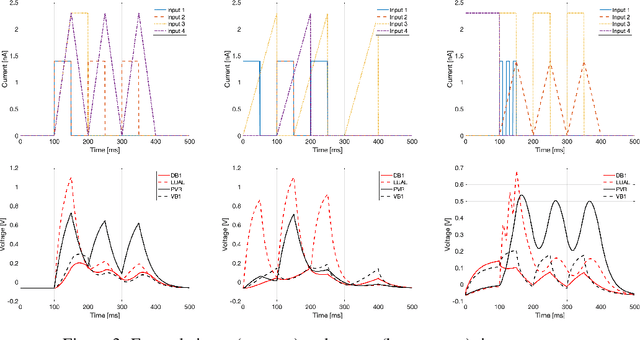
Given the inner complexity of the human nervous system, insight into the dynamics of brain activity can be gained from understanding smaller and simpler organisms, such as the nematode C. Elegans. The behavioural and structural biology of these organisms is well-known, making them prime candidates for benchmarking modelling and simulation techniques. In these complex neuronal collections, classical, white-box modelling techniques based on intrinsic structural or behavioural information are either unable to capture the profound nonlinearities of the neuronal response to different stimuli or generate extremely complex models, which are computationally intractable. In this paper we show how the nervous system of C. Elegans can be modelled and simulated with data-driven models using different neural network architectures. Specifically, we target the use of state of the art recurrent neural networks architectures such as LSTMs and GRUs and compare these architectures in terms of their properties and their accuracy as well as the complexity of the resulting models. We show that GRU models with a hidden layer size of 4 units are able to accurately reproduce with high accuracy the system's response to very different stimuli.
Learning-Based UAV Trajectory Optimization with Collision Avoidance and Connectivity Constraints
Apr 15, 2021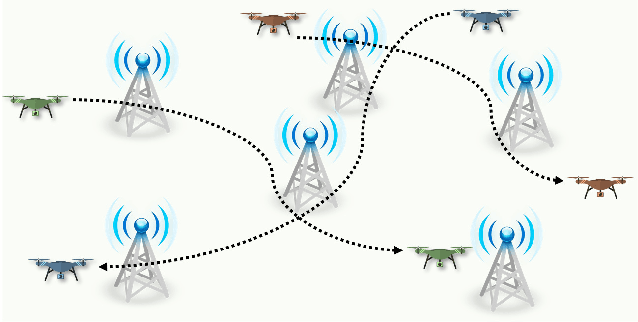
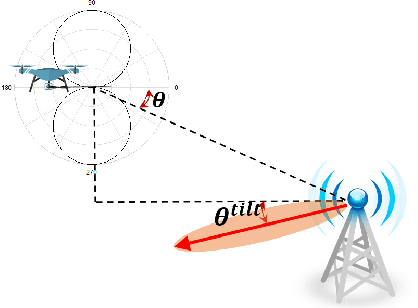
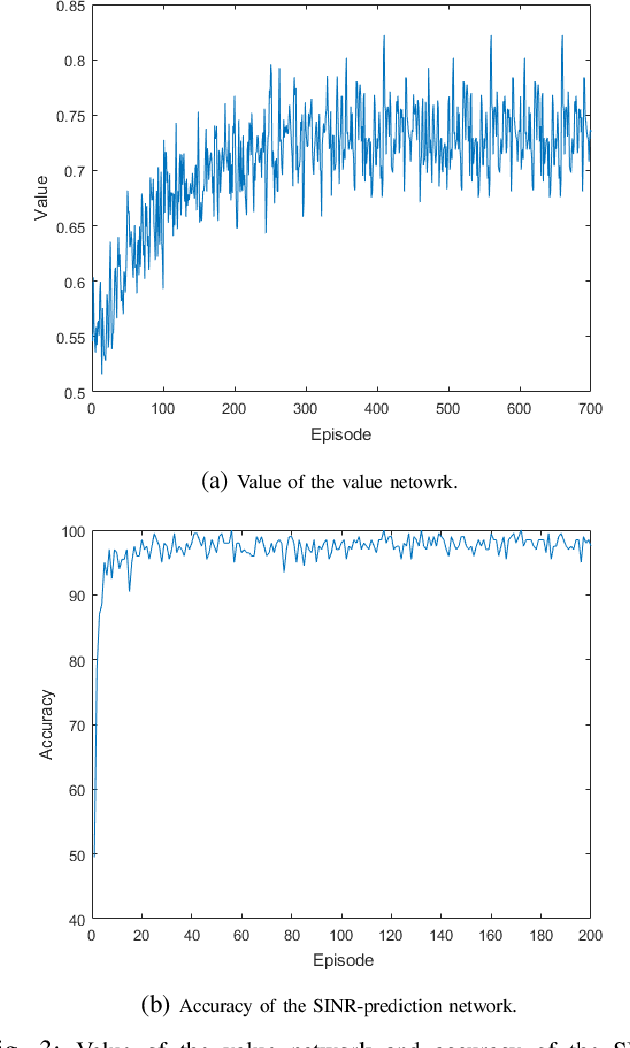
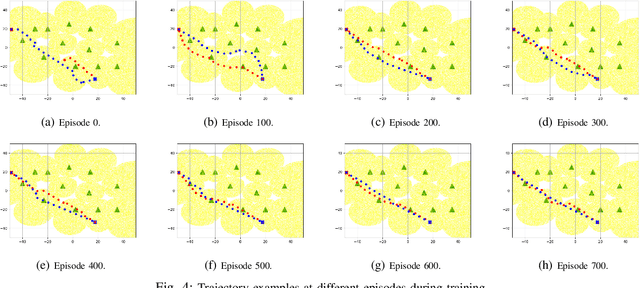
Unmanned aerial vehicles (UAVs) are expected to be an integral part of wireless networks, and determining collision-free trajectories for multiple UAVs while satisfying requirements of connectivity with ground base stations (GBSs) is a challenging task. In this paper, we first reformulate the multi-UAV trajectory optimization problem with collision avoidance and wireless connectivity constraints as a sequential decision making problem in the discrete time domain. We, then, propose a decentralized deep reinforcement learning approach to solve the problem. More specifically, a value network is developed to encode the expected time to destination given the agent's joint state (including the agent's information, the nearby agents' observable information, and the locations of the nearby GBSs). A signal-to-interference-plus-noise ratio (SINR)-prediction neural network is also designed, using accumulated SINR measurements obtained when interacting with the cellular network, to map the GBSs' locations into the SINR levels in order to predict the UAV's SINR. Numerical results show that with the value network and SINR-prediction network, real-time navigation for multi-UAVs can be efficiently performed in various environments with high success rate.
CMF: Cascaded Multi-model Fusion for Referring Image Segmentation
Jun 16, 2021
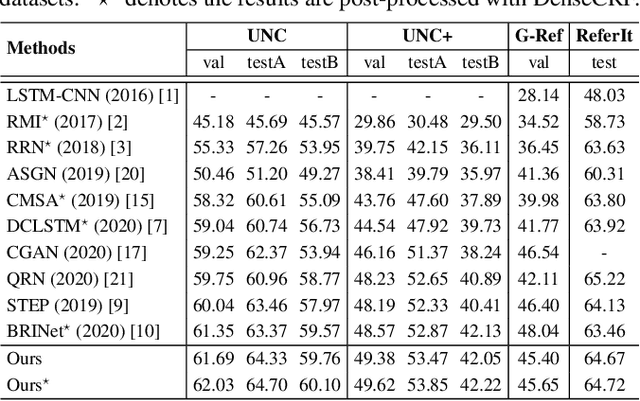
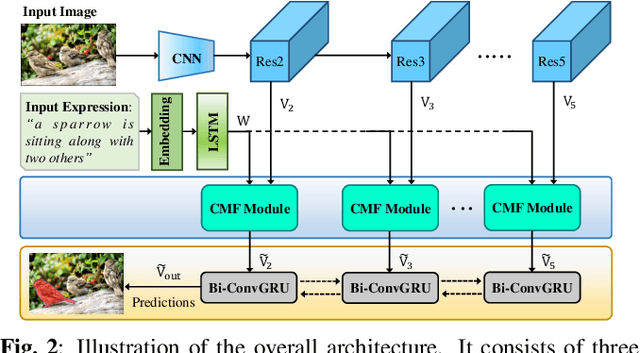
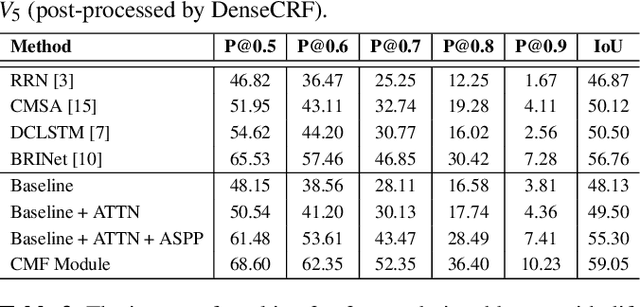
In this work, we address the task of referring image segmentation (RIS), which aims at predicting a segmentation mask for the object described by a natural language expression. Most existing methods focus on establishing unidirectional or directional relationships between visual and linguistic features to associate two modalities together, while the multi-scale context is ignored or insufficiently modeled. Multi-scale context is crucial to localize and segment those objects that have large scale variations during the multi-modal fusion process. To solve this problem, we propose a simple yet effective Cascaded Multi-modal Fusion (CMF) module, which stacks multiple atrous convolutional layers in parallel and further introduces a cascaded branch to fuse visual and linguistic features. The cascaded branch can progressively integrate multi-scale contextual information and facilitate the alignment of two modalities during the multi-modal fusion process. Experimental results on four benchmark datasets demonstrate that our method outperforms most state-of-the-art methods. Code is available at https://github.com/jianhua2022/CMF-Refseg.
Digital Taxonomist: Identifying Plant Species in Citizen Scientists' Photographs
Jun 07, 2021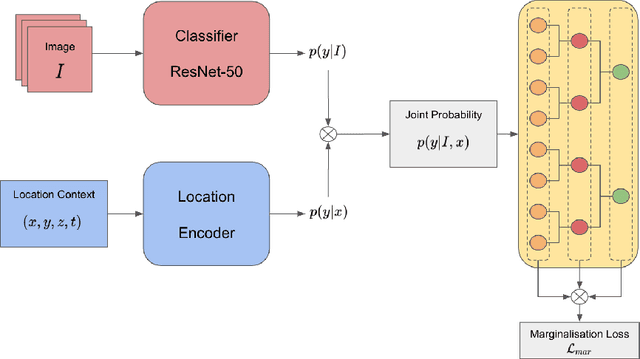
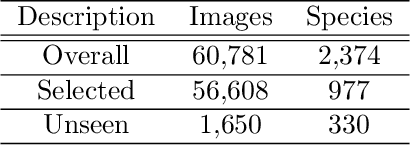


Automatic identification of plant specimens from amateur photographs could improve species range maps, thus supporting ecosystems research as well as conservation efforts. However, classifying plant specimens based on image data alone is challenging: some species exhibit large variations in visual appearance, while at the same time different species are often visually similar; additionally, species observations follow a highly imbalanced, long-tailed distribution due to differences in abundance as well as observer biases. On the other hand, most species observations are accompanied by side information about the spatial, temporal and ecological context. Moreover, biological species are not an unordered list of classes but embedded in a hierarchical taxonomic structure. We propose a machine learning model that takes into account these additional cues in a unified framework. Our Digital Taxonomist is able to identify plant species in photographs more correctly.