 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Set-Membership Estimation in Shared Situational Awareness for Automated Vehicles in Occluded Scenarios
Mar 02, 2021

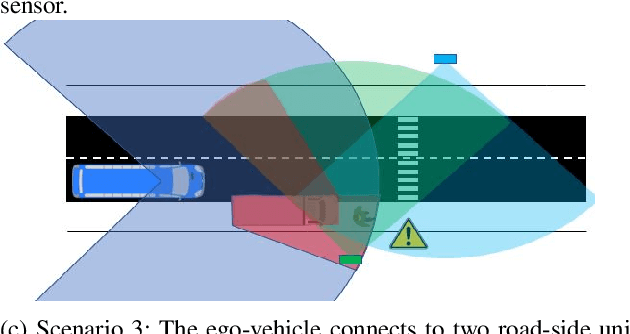
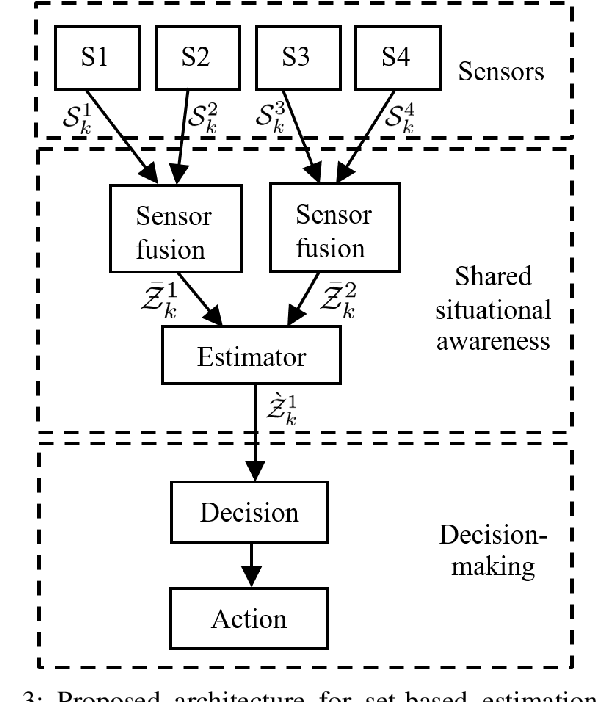
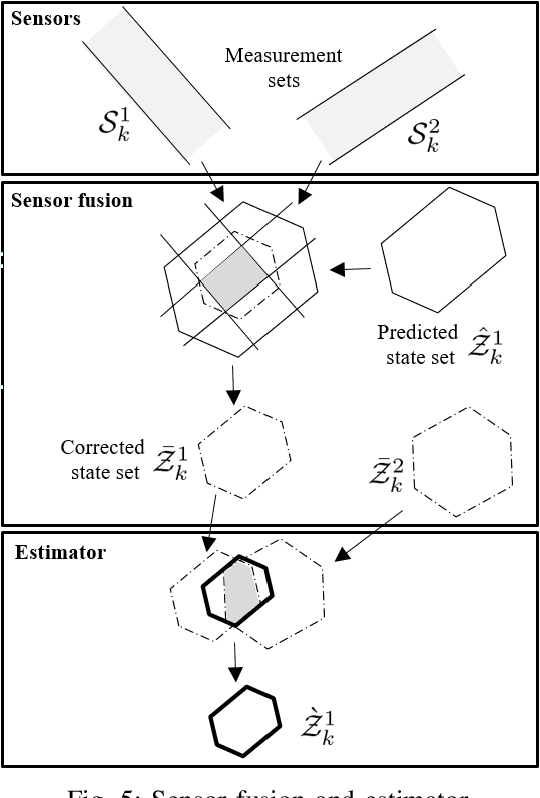
One of the main challenges in developing autonomous transport systems based on connected and automated vehicles is the comprehension and understanding of the environment around each vehicle. In many situations, the understanding is limited to the information gathered by the sensors mounted on the ego-vehicle, and it might be severely affected by occlusion caused by other vehicles or fixed obstacles along the road. Situational awareness is the ability to perceive and comprehend a traffic situation and to predict the intent of vehicles and road users in the surrounding of the ego-vehicle. The main objective of this paper is to propose a framework for how to automatically increase the situational awareness for an automatic bus in a realistic scenario when a pedestrian behind a parked truck might decide to walk across the road. Depending on the ego-vehicle's ability to fuse information from sensors in other vehicles or in the infrastructure, shared situational awareness is developed using a set-based estimation technique that provides robust guarantees for the location of the pedestrian. A two-level information fusion architecture is adopted, where sensor measurements are fused locally, and then the corresponding estimates are shared between vehicles and units in the infrastructure. Thanks to the provided safety guarantees, it is possible to appropriately adjust the ego-vehicle speed to maintain a proper safety margin. It is also argued that the framework is suitable for handling sensor failures and false detections in a systematic way. Three scenarios of growing information complexity are considered throughout the study. Simulations show how the increased situational awareness allows the ego-vehicle to maintain a reasonable speed without sacrificing safety.
Learning What To Do by Simulating the Past
Apr 08, 2021
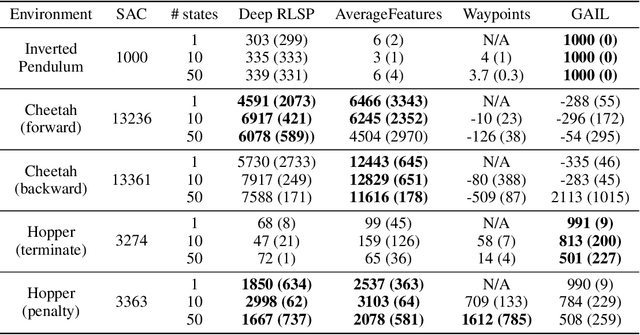

Since reward functions are hard to specify, recent work has focused on learning policies from human feedback. However, such approaches are impeded by the expense of acquiring such feedback. Recent work proposed that agents have access to a source of information that is effectively free: in any environment that humans have acted in, the state will already be optimized for human preferences, and thus an agent can extract information about what humans want from the state. Such learning is possible in principle, but requires simulating all possible past trajectories that could have led to the observed state. This is feasible in gridworlds, but how do we scale it to complex tasks? In this work, we show that by combining a learned feature encoder with learned inverse models, we can enable agents to simulate human actions backwards in time to infer what they must have done. The resulting algorithm is able to reproduce a specific skill in MuJoCo environments given a single state sampled from the optimal policy for that skill.
Factor Graphs for Heterogeneous Bayesian Decentralized Data Fusion
Jun 24, 2021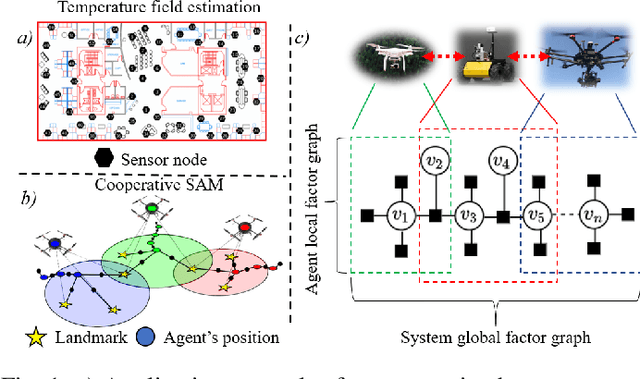
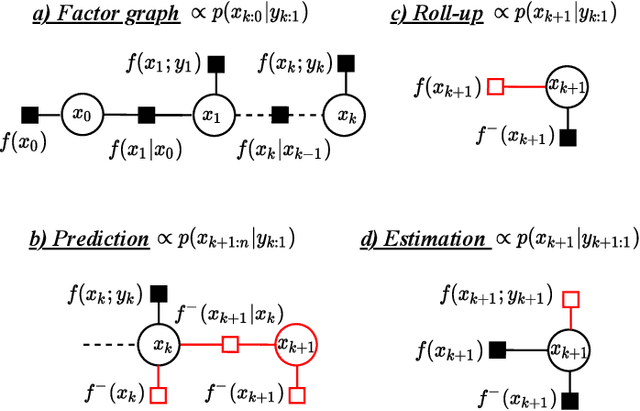
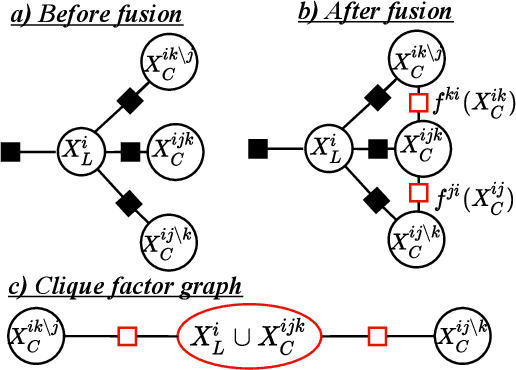

This paper explores the use of factor graphs as an inference and analysis tool for Bayesian peer-to-peer decentralized data fusion. We propose a framework by which agents can each use local factor graphs to represent relevant partitions of a complex global joint probability distribution, thus allowing them to avoid reasoning over the entirety of a more complex model and saving communication as well as computation cost. This allows heterogeneous multi-robot systems to cooperate on a variety of real world, task oriented missions, where scalability and modularity are key. To develop the initial theory and analyze the limits of this approach, we focus our attention on static linear Gaussian systems in tree-structured networks and use Channel Filters (also represented by factor graphs) to explicitly track common information. We discuss how this representation can be used to describe various multi-robot applications and to design and analyze new heterogeneous data fusion algorithms. We validate our method in simulations of a multi-agent multi-target tracking and cooperative multi-agent mapping problems, and discuss the computation and communication gains of this approach.
Data Sharing Markets
Jul 20, 2021With the growing use of distributed machine learning techniques, there is a growing need for data markets that allows agents to share data with each other. Nevertheless data has unique features that separates it from other commodities including replicability, cost of sharing, and ability to distort. We study a setup where each agent can be both buyer and seller of data. For this setup, we consider two cases: bilateral data exchange (trading data with data) and unilateral data exchange (trading data with money). We model bilateral sharing as a network formation game and show the existence of strongly stable outcome under the top agents property by allowing limited complementarity. We propose ordered match algorithm which can find the stable outcome in O(N^2) (N is the number of agents). For the unilateral sharing, under the assumption of additive cost structure, we construct competitive prices that can implement any social welfare maximizing outcome. Finally for this setup when agents have private information, we propose mixed-VCG mechanism which uses zero cost data distortion of data sharing with its isolated impact to achieve budget balance while truthfully implementing socially optimal outcomes to the exact level of budget imbalance of standard VCG mechanisms. Mixed-VCG uses data distortions as data money for this purpose. We further relax zero cost data distortion assumption by proposing distorted-mixed-VCG. We also extend our model and results to data sharing via incremental inquiries and differential privacy costs.
No-Reference Quality Assessment for 3D Colored Point Cloud and Mesh Models
Jul 30, 2021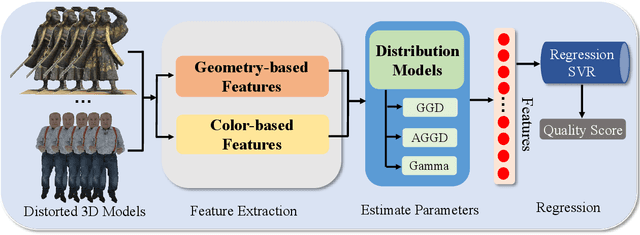
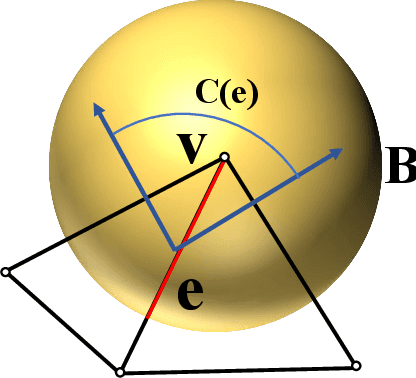
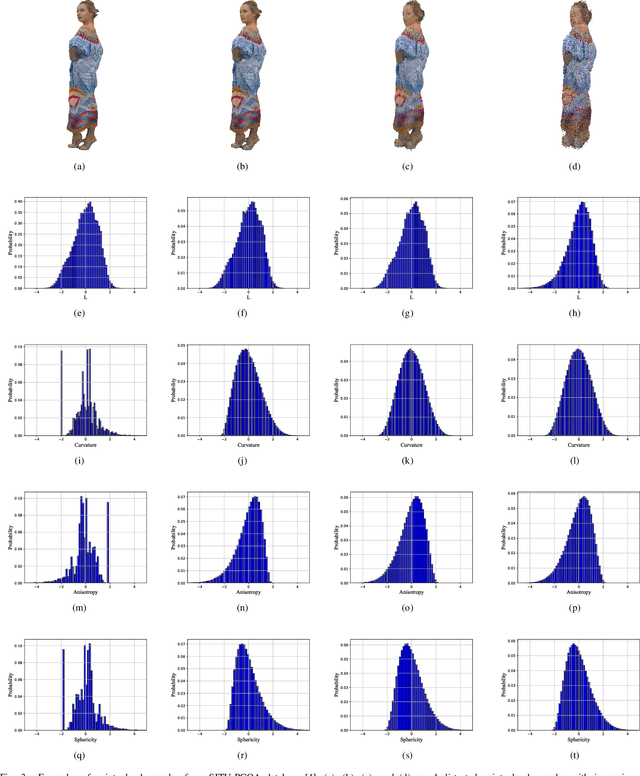
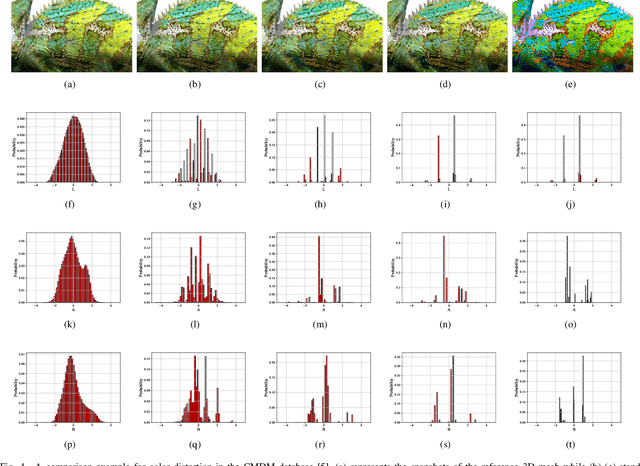
To improve the viewer's Quality of Experience (QoE) and optimize computer graphics applications, 3D model quality assessment (3D-QA) has become an important task in the multimedia area. Point cloud and mesh are the two most widely used digital representation formats of 3D models, the visual quality of which is quite sensitive to lossy operations like simplification and compression. Therefore, many related studies such as point cloud quality assessment (PCQA) and mesh quality assessment (MQA) have been carried out to measure the caused visual quality degradations. However, a large part of previous studies utilizes full-reference (FR) metrics, which means they may fail to predict the quality level with the absence of the reference 3D model. Furthermore, few 3D-QA metrics are carried out to consider color information, which significantly restricts the effectiveness and scope of application. In this paper, we propose a no-reference (NR) quality assessment metric for colored 3D models represented by both point cloud and mesh. First, we project the 3D models from 3D space into quality-related geometry and color feature domains. Then, the natural scene statistics (NSS) and entropy are utilized to extract quality-aware features. Finally, the Support Vector Regressor (SVR) is employed to regress the quality-aware features into quality scores. Our method is mainly validated on the colored point cloud quality assessment database (SJTU-PCQA) and the colored mesh quality assessment database (CMDM). The experimental results show that the proposed method outperforms all the state-of-art NR 3D-QA metrics and obtains an acceptable gap with the state-of-art FR 3D-QA metrics.
Three-dimensional multimodal medical imaging system based on free-hand ultrasound and structured light
May 29, 2021We propose a three-dimensional (3D) multimodal medical imaging system that combines freehand ultrasound and structured light 3D reconstruction in a single coordinate system without requiring registration. To the best of our knowledge, these techniques have not been combined before as a multimodal imaging technique. The system complements the internal 3D information acquired with ultrasound, with the external surface measured with the structure light technique. Moreover, the ultrasound probe's optical tracking for pose estimation was implemented based on a convolutional neural network. Experimental results show the system's high accuracy and reproducibility, as well as its potential for preoperative and intraoperative applications. The experimental multimodal error, or the distance from two surfaces obtained with different modalities, was 0.12 mm. The code is available as a Github repository.
Personalized PercepNet: Real-time, Low-complexity Target Voice Separation and Enhancement
Jun 08, 2021



The presence of multiple talkers in the surrounding environment poses a difficult challenge for real-time speech communication systems considering the constraints on network size and complexity. In this paper, we present Personalized PercepNet, a real-time speech enhancement model that separates a target speaker from a noisy multi-talker mixture without compromising on complexity of the recently proposed PercepNet. To enable speaker-dependent speech enhancement, we first show how we can train a perceptually motivated speaker embedder network to produce a representative embedding vector for the given speaker. Personalized PercepNet uses the target speaker embedding as additional information to pick out and enhance only the target speaker while suppressing all other competing sounds. Our experiments show that the proposed model significantly outperforms PercepNet and other baselines, both in terms of objective speech enhancement metrics and human opinion scores.
GL-GIN: Fast and Accurate Non-Autoregressive Model for Joint Multiple Intent Detection and Slot Filling
Jun 03, 2021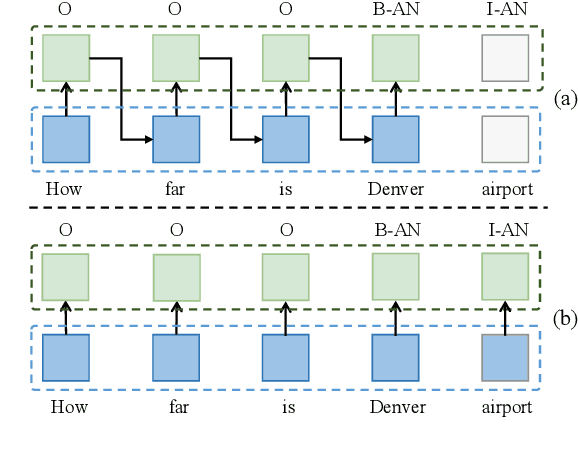
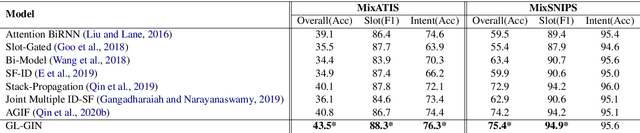
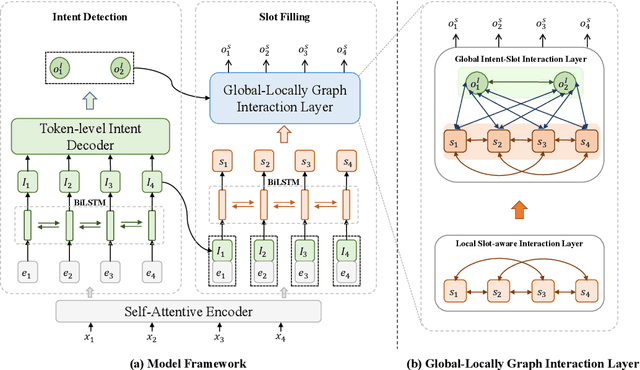
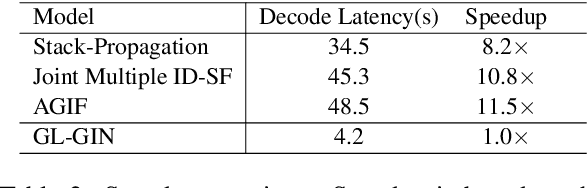
Multi-intent SLU can handle multiple intents in an utterance, which has attracted increasing attention. However, the state-of-the-art joint models heavily rely on autoregressive approaches, resulting in two issues: slow inference speed and information leakage. In this paper, we explore a non-autoregressive model for joint multiple intent detection and slot filling, achieving more fast and accurate. Specifically, we propose a Global-Locally Graph Interaction Network (GL-GIN) where a local slot-aware graph interaction layer is proposed to model slot dependency for alleviating uncoordinated slots problem while a global intent-slot graph interaction layer is introduced to model the interaction between multiple intents and all slots in the utterance. Experimental results on two public datasets show that our framework achieves state-of-the-art performance while being 11.5 times faster.
Spatial-Phase Shallow Learning: Rethinking Face Forgery Detection in Frequency Domain
Mar 02, 2021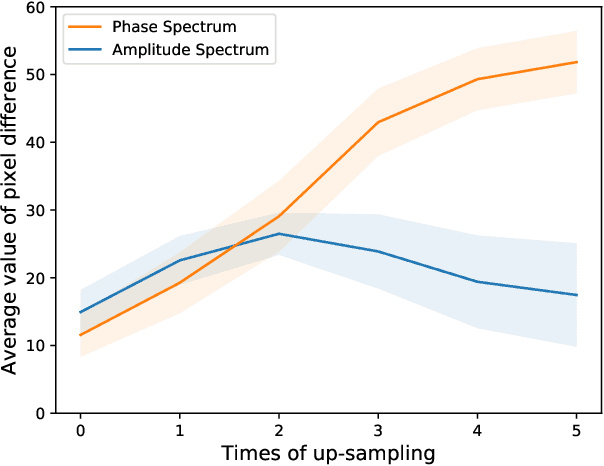
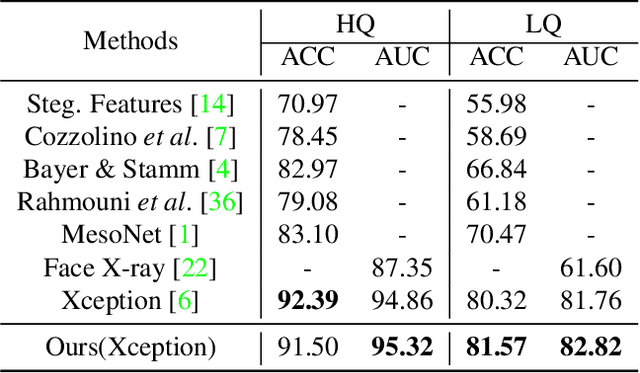
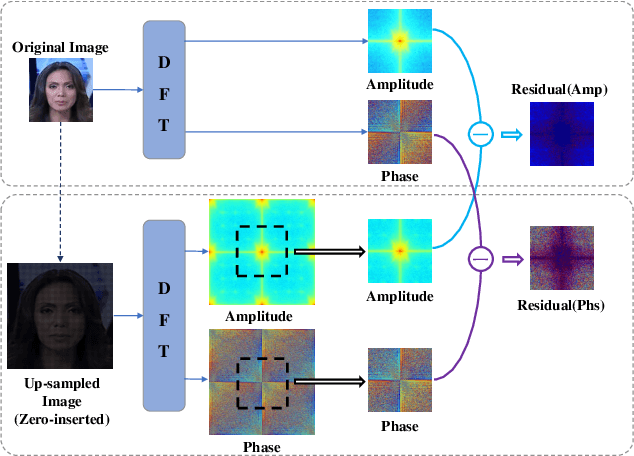
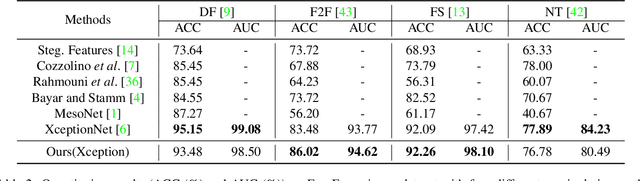
The remarkable success in face forgery techniques has received considerable attention in computer vision due to security concerns. We observe that up-sampling is a necessary step of most face forgery techniques, and cumulative up-sampling will result in obvious changes in the frequency domain, especially in the phase spectrum. According to the property of natural images, the phase spectrum preserves abundant frequency components that provide extra information and complement the loss of the amplitude spectrum. To this end, we present a novel Spatial-Phase Shallow Learning (SPSL) method, which combines spatial image and phase spectrum to capture the up-sampling artifacts of face forgery to improve the transferability, for face forgery detection. And we also theoretically analyze the validity of utilizing the phase spectrum. Moreover, we notice that local texture information is more crucial than high-level semantic information for the face forgery detection task. So we reduce the receptive fields by shallowing the network to suppress high-level features and focus on the local region. Extensive experiments show that SPSL can achieve the state-of-the-art performance on cross-datasets evaluation as well as multi-class classification and obtain comparable results on single dataset evaluation.
BRepNet: A topological message passing system for solid models
Apr 08, 2021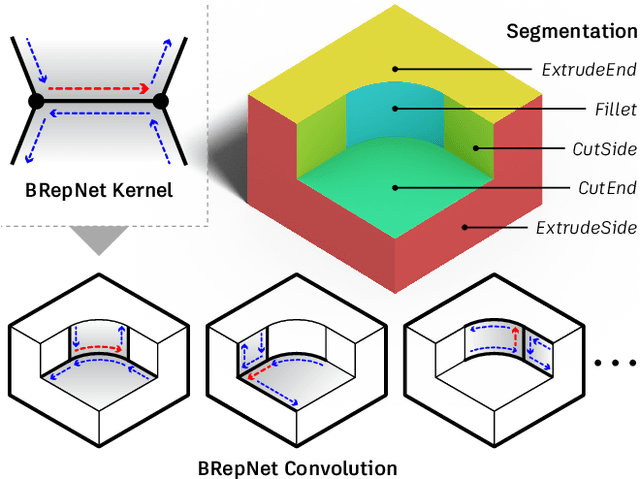


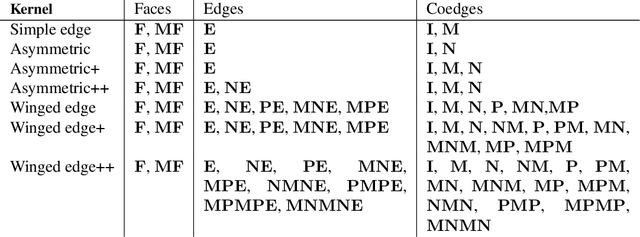
Boundary representation (B-rep) models are the standard way 3D shapes are described in Computer-Aided Design (CAD) applications. They combine lightweight parametric curves and surfaces with topological information which connects the geometric entities to describe manifolds. In this paper we introduce BRepNet, a neural network architecture designed to operate directly on B-rep data structures, avoiding the need to approximate the model as meshes or point clouds. BRepNet defines convolutional kernels with respect to oriented coedges in the data structure. In the neighborhood of each coedge, a small collection of faces, edges and coedges can be identified and patterns in the feature vectors from these entities detected by specific learnable parameters. In addition, to encourage further deep learning research with B-reps, we publish the Fusion 360 Gallery segmentation dataset. A collection of over 35,000 B-rep models annotated with information about the modeling operations which created each face. We demonstrate that BRepNet can segment these models with higher accuracy than methods working on meshes, and point clouds.