 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AtrialGeneral: Domain Generalization for Left Atrial Segmentation of Multi-Center LGE MRIs
Jun 18, 2021
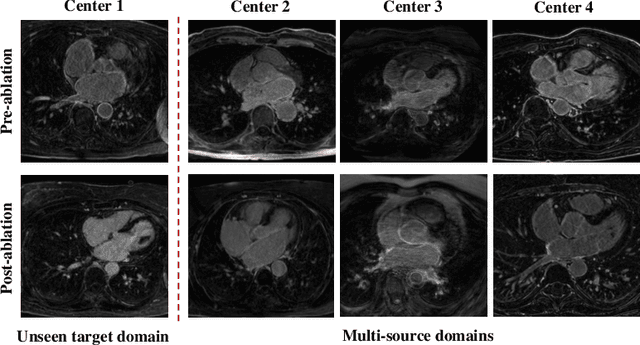

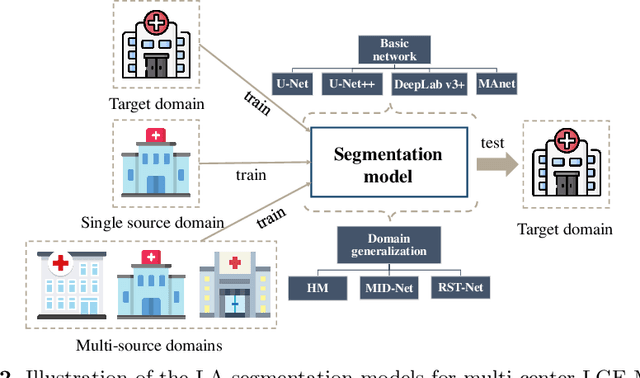
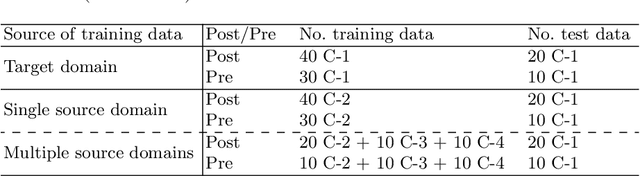
Left atrial (LA) segmentation from late gadolinium enhanced magnetic resonance imaging (LGE MRI) is a crucial step needed for planning the treatment of atrial fibrillation. However, automatic LA segmentation from LGE MRI is still challenging, due to the poor image quality, high variability in LA shapes, and unclear LA boundary. Though deep learning-based methods can provide promising LA segmentation results, they often generalize poorly to unseen domains, such as data from different scanners and/or sites. In this work, we collect 210 LGE MRIs from different centers with different levels of image quality. To evaluate the domain generalization ability of models on the LA segmentation task, we employ four commonly used semantic segmentation networks for the LA segmentation from multi-center LGE MRIs. Besides, we investigate three domain generalization strategies, i.e., histogram matching, mutual information based disentangled representation, and random style transfer, where a simple histogram matching is proved to be most effective.
General Data Analytics with Applications to Visual Information Analysis: A Provable Backward-Compatible Semisimple Paradigm over T-Algebra
Nov 16, 2020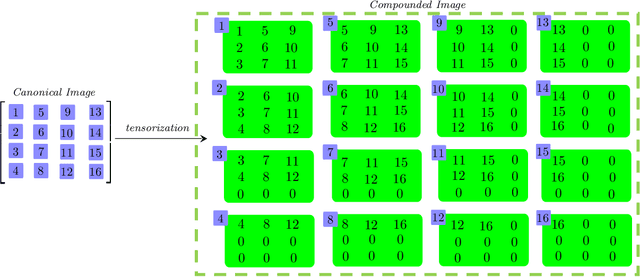
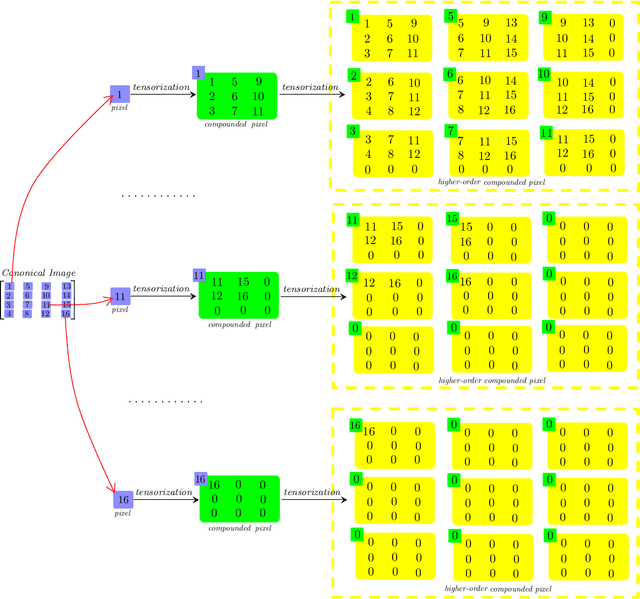

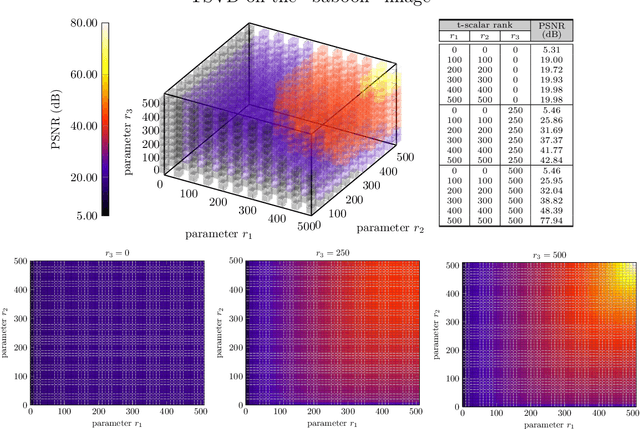
We consider a novel backward-compatible paradigm of general data analytics over a recently-reported semisimple algebra (called t-algebra). We study the abstract algebraic framework over the t-algebra by representing the elements of t-algebra by fix-sized multi-way arrays of complex numbers and the algebraic structure over the t-algebra by a collection of direct-product constituents. Over the t-algebra, many algorithms, if not all, are generalized in a straightforward manner using this new semisimple paradigm. To demonstrate the new paradigm's performance and its backward-compatibility, we generalize some canonical algorithms for visual pattern analysis. Experiments on public datasets show that the generalized algorithms compare favorably with their canonical counterparts.
Composable Augmentation Encoding for Video Representation Learning
Apr 01, 2021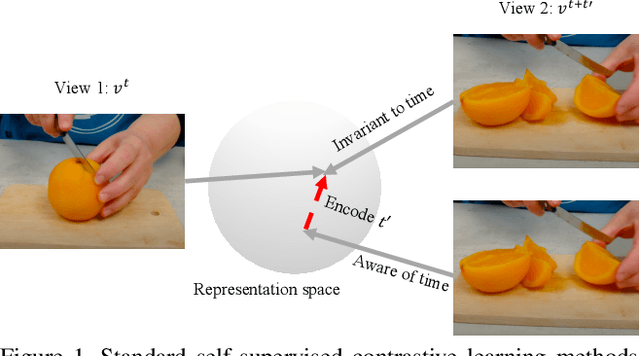

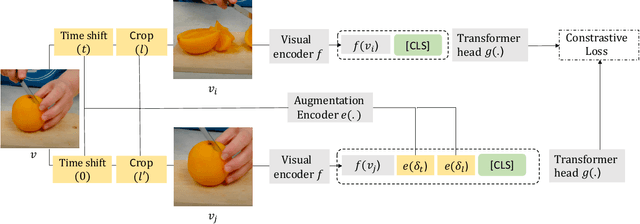

We focus on contrastive methods for self-supervised video representation learning. A common paradigm in contrastive learning is to construct positive pairs by sampling different data views for the same instance, with different data instances as negatives. These methods implicitly assume a set of representational invariances to the view selection mechanism (eg, sampling frames with temporal shifts), which may lead to poor performance on downstream tasks which violate these invariances (fine-grained video action recognition that would benefit from temporal information). To overcome this limitation, we propose an 'augmentation aware' contrastive learning framework, where we explicitly provide a sequence of augmentation parameterisations (such as the values of the time shifts used to create data views) as composable augmentation encodings (CATE) to our model when projecting the video representations for contrastive learning. We show that representations learned by our method encode valuable information about specified spatial or temporal augmentation, and in doing so also achieve state-of-the-art performance on a number of video benchmarks.
A Global to Local Double Embedding Method for Multi-person Pose Estimation
Feb 15, 2021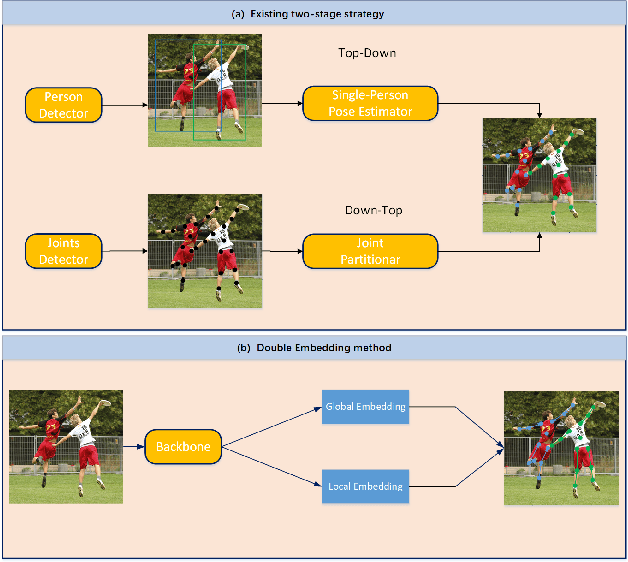
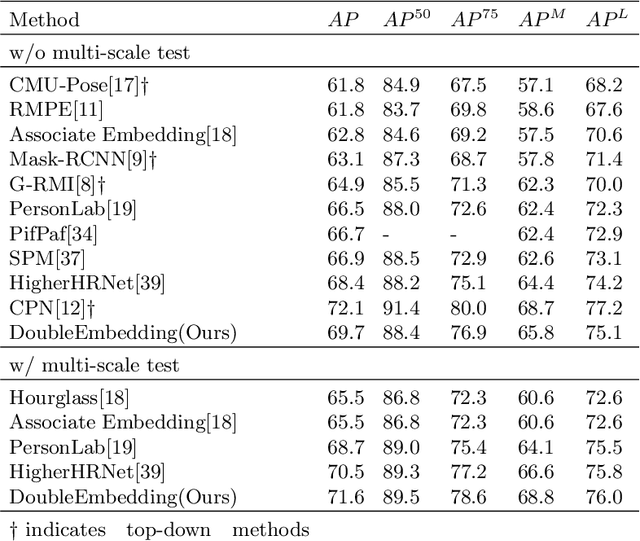
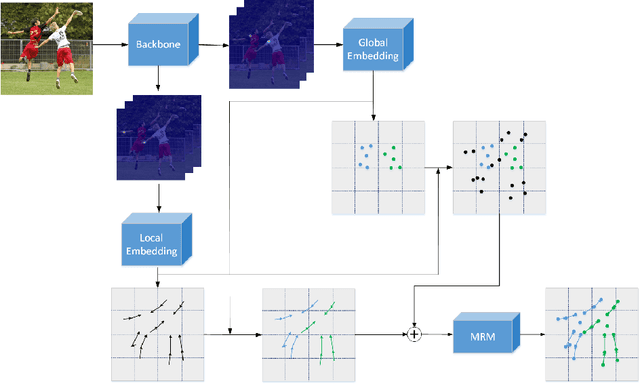
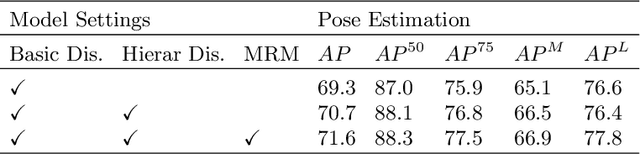
Multi-person pose estimation is a fundamental and challenging problem to many computer vision tasks. Most existing methods can be broadly categorized into two classes: top-down and bottom-up methods. Both of the two types of methods involve two stages, namely, person detection and joints detection. Conventionally, the two stages are implemented separately without considering their interactions between them, and this may inevitably cause some issue intrinsically. In this paper, we present a novel method to simplify the pipeline by implementing person detection and joints detection simultaneously. We propose a Double Embedding (DE) method to complete the multi-person pose estimation task in a global-to-local way. DE consists of Global Embedding (GE) and Local Embedding (LE). GE encodes different person instances and processes information covering the whole image and LE encodes the local limbs information. GE functions for the person detection in top-down strategy while LE connects the rest joints sequentially which functions for joint grouping and information processing in A bottom-up strategy. Based on LE, we design the Mutual Refine Machine (MRM) to reduce the prediction difficulty in complex scenarios. MRM can effectively realize the information communicating between keypoints and further improve the accuracy. We achieve the competitive results on benchmarks MSCOCO, MPII and CrowdPose, demonstrating the effectiveness and generalization ability of our method.
Auditing for Diversity using Representative Examples
Jul 15, 2021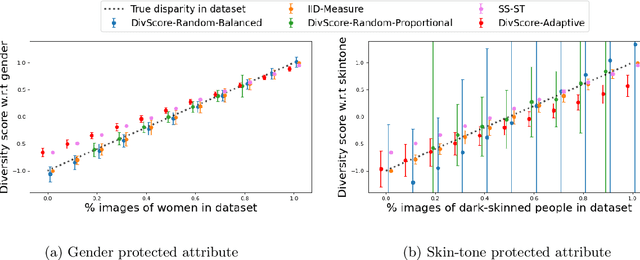
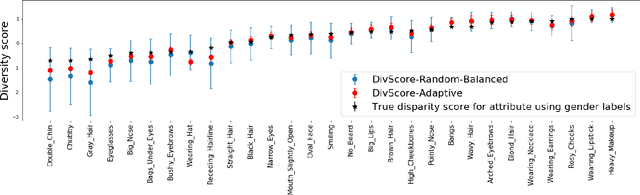
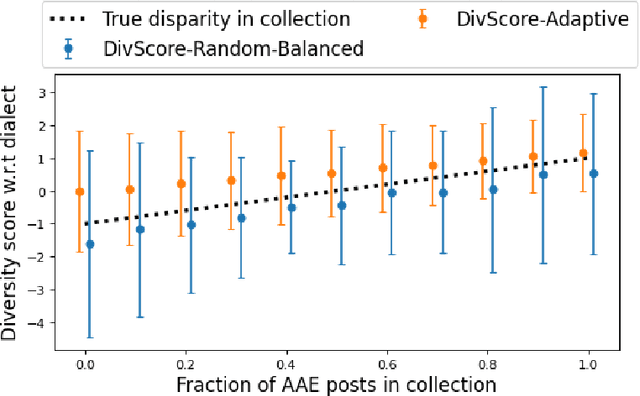
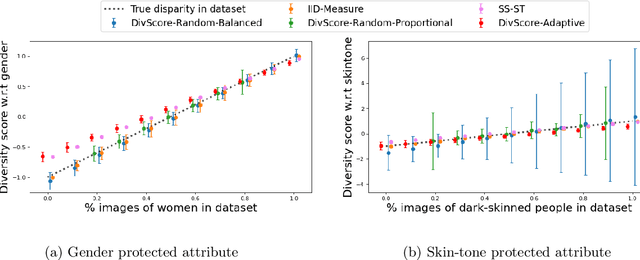
Assessing the diversity of a dataset of information associated with people is crucial before using such data for downstream applications. For a given dataset, this often involves computing the imbalance or disparity in the empirical marginal distribution of a protected attribute (e.g. gender, dialect, etc.). However, real-world datasets, such as images from Google Search or collections of Twitter posts, often do not have protected attributes labeled. Consequently, to derive disparity measures for such datasets, the elements need to hand-labeled or crowd-annotated, which are expensive processes. We propose a cost-effective approach to approximate the disparity of a given unlabeled dataset, with respect to a protected attribute, using a control set of labeled representative examples. Our proposed algorithm uses the pairwise similarity between elements in the dataset and elements in the control set to effectively bootstrap an approximation to the disparity of the dataset. Importantly, we show that using a control set whose size is much smaller than the size of the dataset is sufficient to achieve a small approximation error. Further, based on our theoretical framework, we also provide an algorithm to construct adaptive control sets that achieve smaller approximation errors than randomly chosen control sets. Simulations on two image datasets and one Twitter dataset demonstrate the efficacy of our approach (using random and adaptive control sets) in auditing the diversity of a wide variety of datasets.
Strategic Mitigation of Agent Inattention in Drivers with Open-Quantum Cognition Models
Jul 21, 2021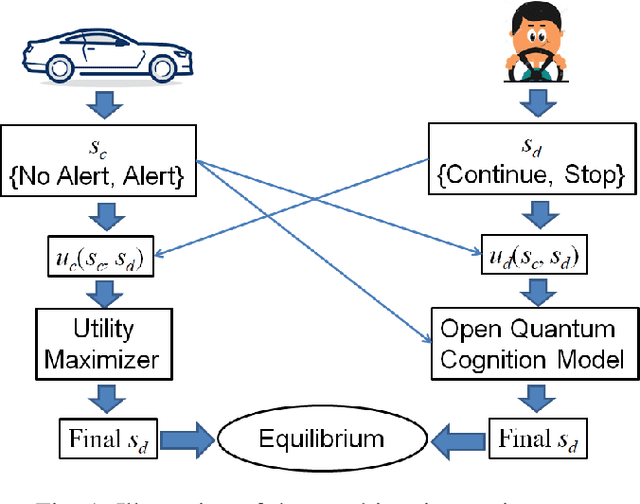
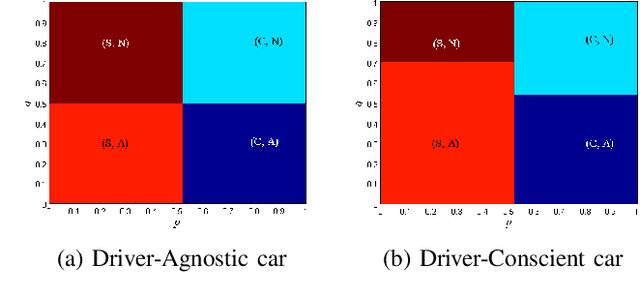
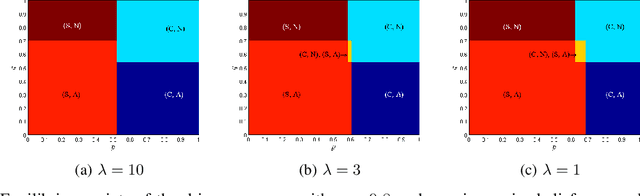

State-of-the-art driver-assist systems have failed to effectively mitigate driver inattention and had minimal impacts on the ever-growing number of road mishaps (e.g. life loss, physical injuries due to accidents caused by various factors that lead to driver inattention). This is because traditional human-machine interaction settings are modeled in classical and behavioral game-theoretic domains which are technically appropriate to characterize strategic interaction between either two utility maximizing agents, or human decision makers. Therefore, in an attempt to improve the persuasive effectiveness of driver-assist systems, we develop a novel strategic and personalized driver-assist system which adapts to the driver's mental state and choice behavior. First, we propose a novel equilibrium notion in human-system interaction games, where the system maximizes its expected utility and human decisions can be characterized using any general decision model. Then we use this novel equilibrium notion to investigate the strategic driver-vehicle interaction game where the car presents a persuasive recommendation to steer the driver towards safer driving decisions. We assume that the driver employs an open-quantum system cognition model, which captures complex aspects of human decision making such as violations to classical law of total probability and incompatibility of certain mental representations of information. We present closed-form expressions for players' final responses to each other's strategies so that we can numerically compute both pure and mixed equilibria. Numerical results are presented to illustrate both kinds of equilibria.
Learning to Adversarially Blur Visual Object Tracking
Jul 26, 2021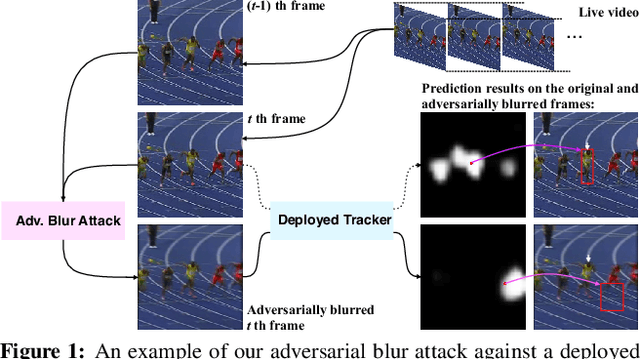
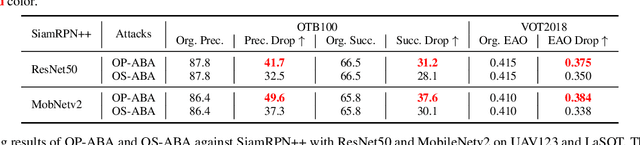
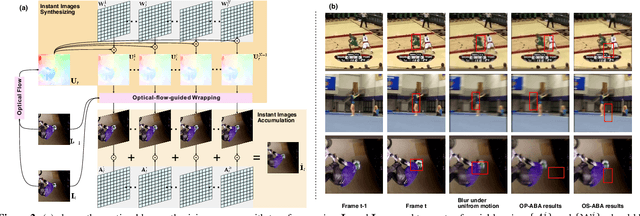

Motion blur caused by the moving of the object or camera during the exposure can be a key challenge for visual object tracking, affecting tracking accuracy significantly. In this work, we explore the robustness of visual object trackers against motion blur from a new angle, i.e., adversarial blur attack (ABA). Our main objective is to online transfer input frames to their natural motion-blurred counterparts while misleading the state-of-the-art trackers during the tracking process. To this end, we first design the motion blur synthesizing method for visual tracking based on the generation principle of motion blur, considering the motion information and the light accumulation process. With this synthetic method, we propose \textit{optimization-based ABA (OP-ABA)} by iteratively optimizing an adversarial objective function against the tracking w.r.t. the motion and light accumulation parameters. The OP-ABA is able to produce natural adversarial examples but the iteration can cause heavy time cost, making it unsuitable for attacking real-time trackers. To alleviate this issue, we further propose \textit{one-step ABA (OS-ABA)} where we design and train a joint adversarial motion and accumulation predictive network (JAMANet) with the guidance of OP-ABA, which is able to efficiently estimate the adversarial motion and accumulation parameters in a one-step way. The experiments on four popular datasets (\eg, OTB100, VOT2018, UAV123, and LaSOT) demonstrate that our methods are able to cause significant accuracy drops on four state-of-the-art trackers with high transferability. Please find the source code at https://github.com/tsingqguo/ABA
Multi-Modal Association based Grouping for Form Structure Extraction
Jul 09, 2021
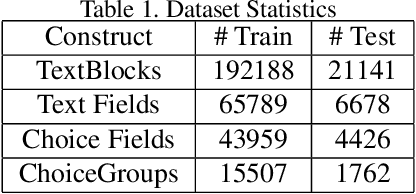

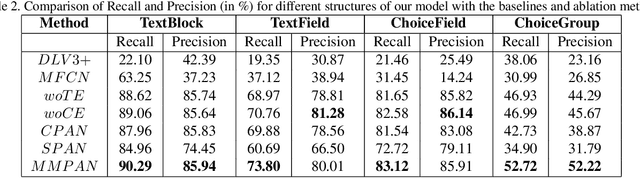
Document structure extraction has been a widely researched area for decades. Recent work in this direction has been deep learning-based, mostly focusing on extracting structure using fully convolution NN through semantic segmentation. In this work, we present a novel multi-modal approach for form structure extraction. Given simple elements such as textruns and widgets, we extract higher-order structures such as TextBlocks, Text Fields, Choice Fields, and Choice Groups, which are essential for information collection in forms. To achieve this, we obtain a local image patch around each low-level element (reference) by identifying candidate elements closest to it. We process textual and spatial representation of candidates sequentially through a BiLSTM to obtain context-aware representations and fuse them with image patch features obtained by processing it through a CNN. Subsequently, the sequential decoder takes this fused feature vector to predict the association type between reference and candidates. These predicted associations are utilized to determine larger structures through connected components analysis. Experimental results show the effectiveness of our approach achieving a recall of 90.29%, 73.80%, 83.12%, and 52.72% for the above structures, respectively, outperforming semantic segmentation baselines significantly. We show the efficacy of our method through ablations, comparing it against using individual modalities. We also introduce our new rich human-annotated Forms Dataset.
Learning Abstract Representations through Lossy Compression of Multi-Modal Signals
Jan 27, 2021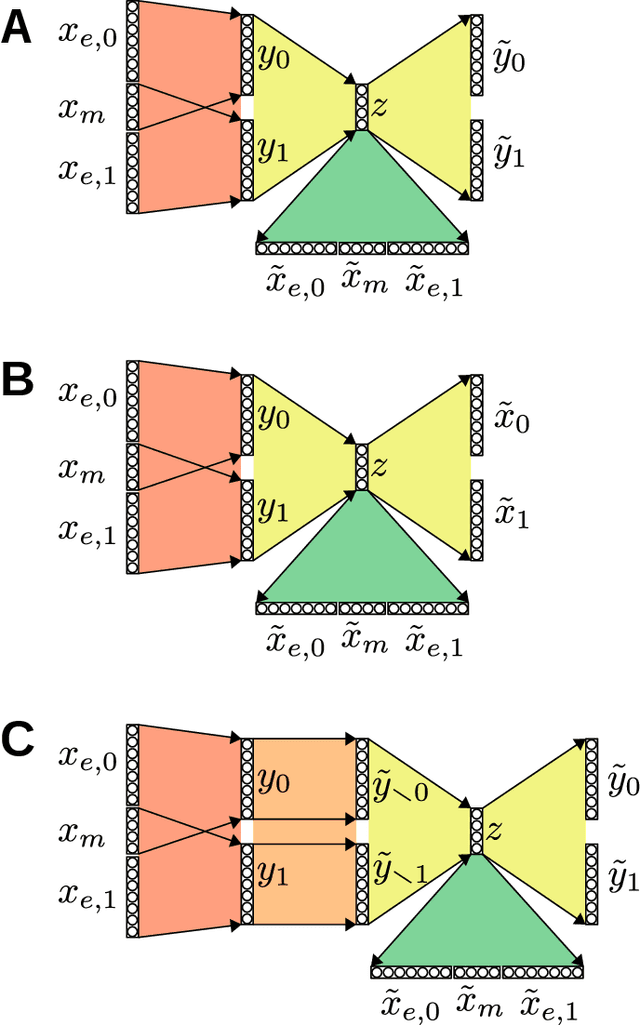
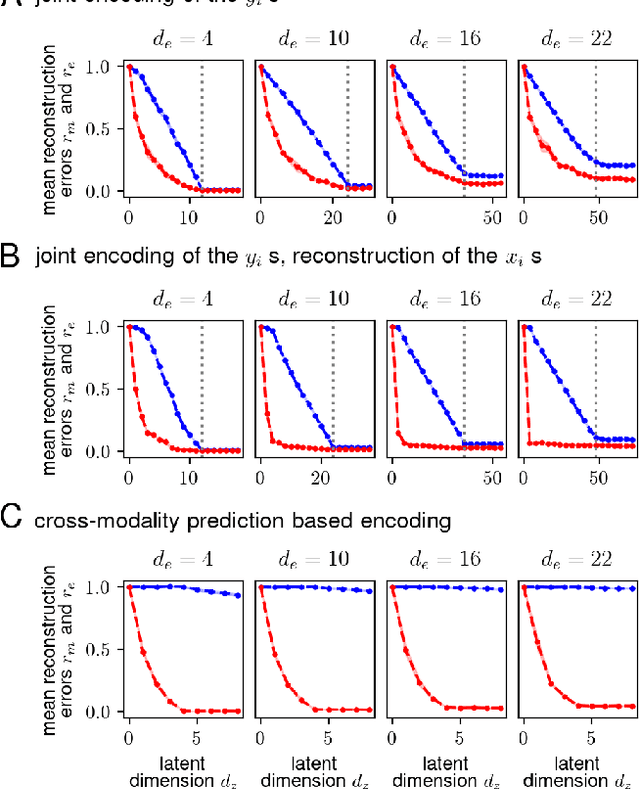
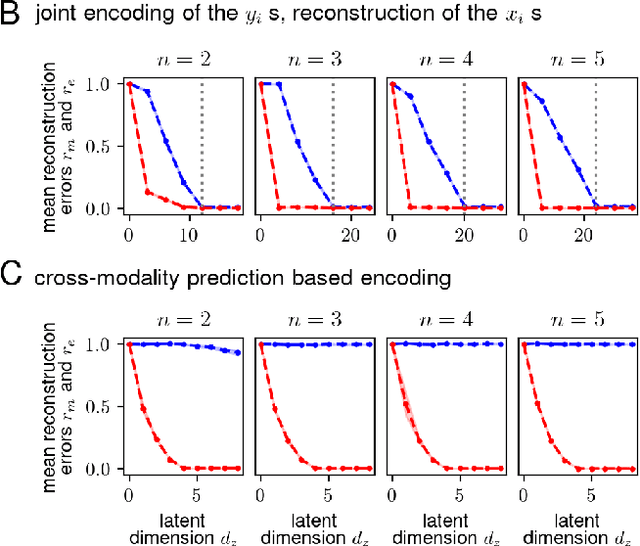
A key competence for open-ended learning is the formation of increasingly abstract representations useful for driving complex behavior. Abstract representations ignore specific details and facilitate generalization. Here we consider the learning of abstract representations in a multi-modal setting with two or more input modalities. We treat the problem as a lossy compression problem and show that generic lossy compression of multimodal sensory input naturally extracts abstract representations that tend to strip away modalitiy specific details and preferentially retain information that is shared across the different modalities. Furthermore, we propose an architecture to learn abstract representations by identifying and retaining only the information that is shared across multiple modalities while discarding any modality specific information.
MusCaps: Generating Captions for Music Audio
Apr 24, 2021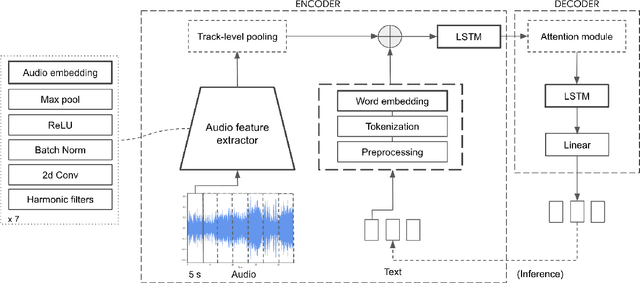
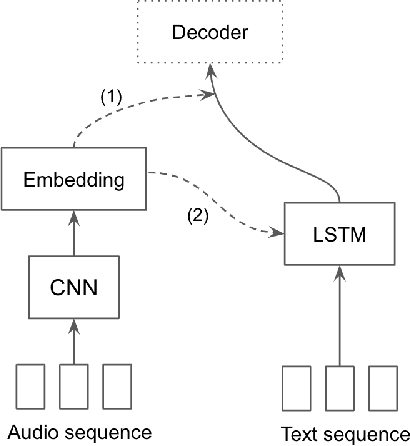
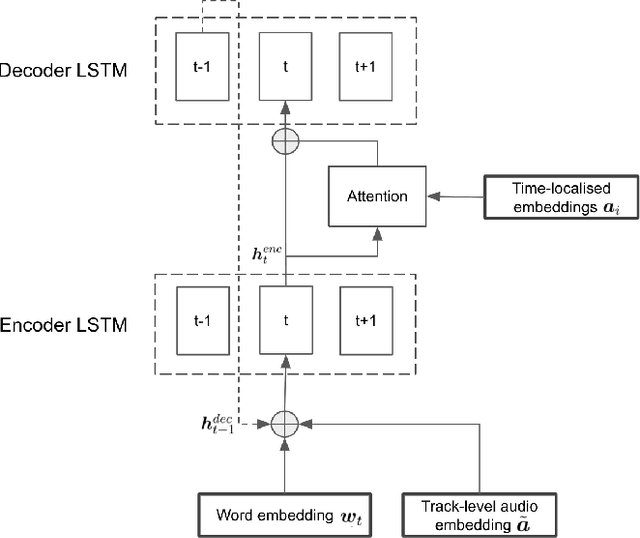

Content-based music information retrieval has seen rapid progress with the adoption of deep learning. Current approaches to high-level music description typically make use of classification models, such as in auto-tagging or genre and mood classification. In this work, we propose to address music description via audio captioning, defined as the task of generating a natural language description of music audio content in a human-like manner. To this end, we present the first music audio captioning model, MusCaps, consisting of an encoder-decoder with temporal attention. Our method combines convolutional and recurrent neural network architectures to jointly process audio-text inputs through a multimodal encoder and leverages pre-training on audio data to obtain representations that effectively capture and summarise musical features in the input. Evaluation of the generated captions through automatic metrics shows that our method outperforms a baseline designed for non-music audio captioning. Through an ablation study, we unveil that this performance boost can be mainly attributed to pre-training of the audio encoder, while other design choices - modality fusion, decoding strategy and the use of attention - contribute only marginally. Our model represents a shift away from classification-based music description and combines tasks requiring both auditory and linguistic understanding to bridge the semantic gap in music information retrieval.