 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Ill-posed Surface Emissivity Retrieval from Multi-Geometry HyperspectralImages using a Hybrid Deep Neural Network
Jul 09, 2021
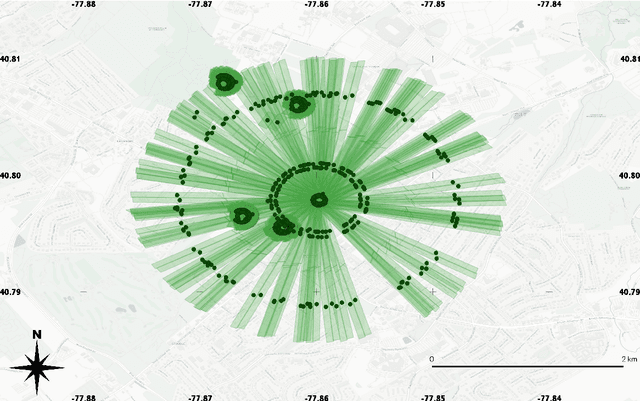
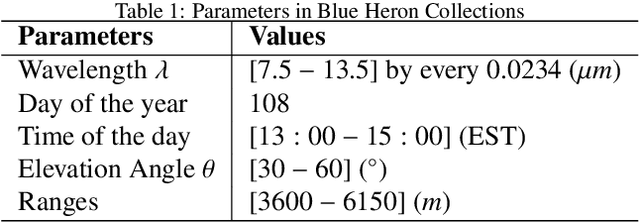
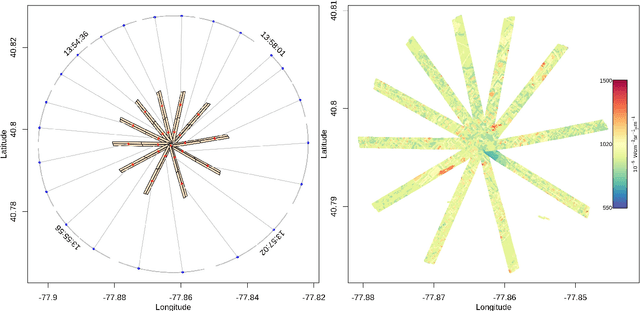
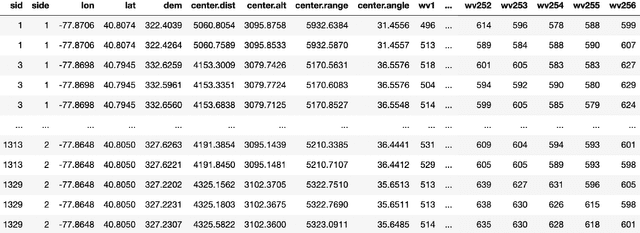
Atmospheric correction is a fundamental task in remote sensing because observations are taken either of the atmosphere or looking through the atmosphere. Atmospheric correction errors can significantly alter the spectral signature of the observations, and lead to invalid classifications or target detection. This is even more crucial when working with hyperspectral data, where a precise measurement of spectral properties is required. State-of-the-art physics-based atmospheric correction approaches require extensive prior knowledge about sensor characteristics, collection geometry, and environmental characteristics of the scene being collected. These approaches are computationally expensive, prone to inaccuracy due to lack of sufficient environmental and collection information, and often impossible for real-time applications. In this paper, a geometry-dependent hybrid neural network is proposed for automatic atmospheric correction using multi-scan hyperspectral data collected from different geometries. The proposed network can characterize the atmosphere without any additional meteorological data. A grid-search method is also proposed to solve the temperature emissivity separation problem. Results show that the proposed network has the capacity to accurately characterize the atmosphere and estimate target emissivity spectra with a Mean Absolute Error (MAE) under 0.02 for 29 different materials. This solution can lead to accurate atmospheric correction to improve target detection for real time applications.
Deep Learning for Market by Order Data
Feb 17, 2021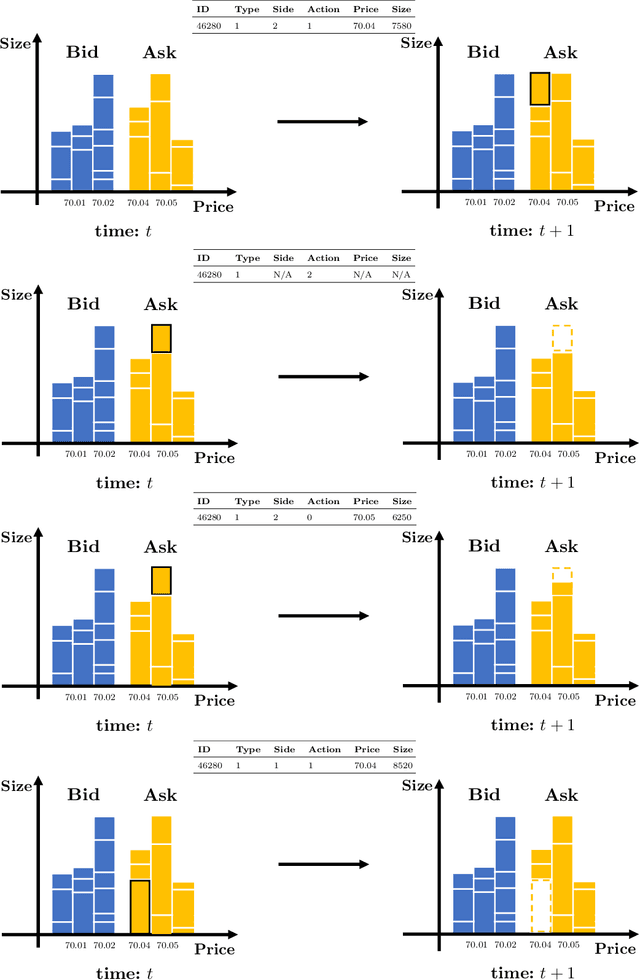
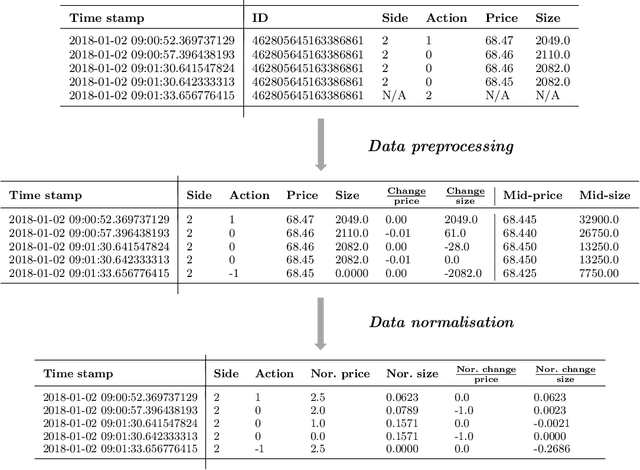
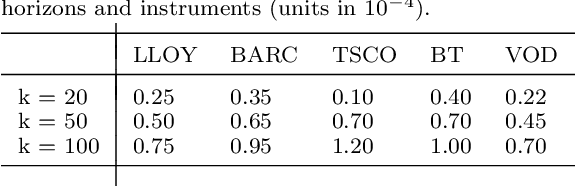
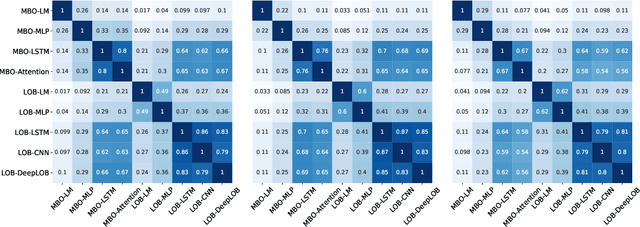
Market by order (MBO) data - a detailed feed of individual trade instructions for a given stock on an exchange - is arguably one of the most granular sources of microstructure information. While limit order books (LOBs) are implicitly derived from it, MBO data is largely neglected by current academic literature which focuses primarily on LOB modelling. In this paper, we demonstrate the utility of MBO data for forecasting high-frequency price movements, providing an orthogonal source of information to LOB snapshots. We provide the first predictive analysis on MBO data by carefully introducing the data structure and presenting a specific normalisation scheme to consider level information in order books and to allow model training with multiple instruments. Through forecasting experiments using deep neural networks, we show that while MBO-driven and LOB-driven models individually provide similar performance, ensembles of the two can lead to improvements in forecasting accuracy -- indicating that MBO data is additive to LOB-based features.
MarsExplorer: Exploration of Unknown Terrains via Deep Reinforcement Learning and Procedurally Generated Environments
Jul 21, 2021
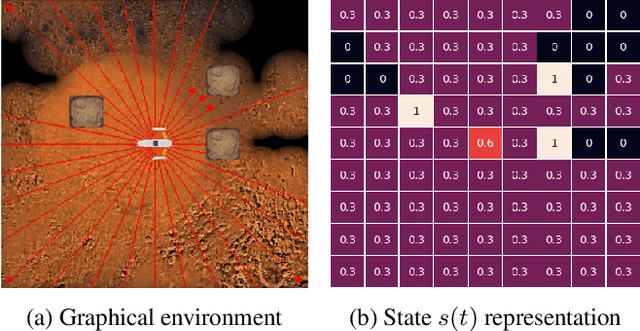
This paper is an initial endeavor to bridge the gap between powerful Deep Reinforcement Learning methodologies and the problem of exploration/coverage of unknown terrains. Within this scope, MarsExplorer, an openai-gym compatible environment tailored to exploration/coverage of unknown areas, is presented. MarsExplorer translates the original robotics problem into a Reinforcement Learning setup that various off-the-shelf algorithms can tackle. Any learned policy can be straightforwardly applied to a robotic platform without an elaborate simulation model of the robot's dynamics to apply a different learning/adaptation phase. One of its core features is the controllable multi-dimensional procedural generation of terrains, which is the key for producing policies with strong generalization capabilities. Four different state-of-the-art RL algorithms (A3C, PPO, Rainbow, and SAC) are trained on the MarsExplorer environment, and a proper evaluation of their results compared to the average human-level performance is reported. In the follow-up experimental analysis, the effect of the multi-dimensional difficulty setting on the learning capabilities of the best-performing algorithm (PPO) is analyzed. A milestone result is the generation of an exploration policy that follows the Hilbert curve without providing this information to the environment or rewarding directly or indirectly Hilbert-curve-like trajectories. The experimental analysis is concluded by comparing PPO learned policy results with frontier-based exploration context for extended terrain sizes. The source code can be found at: https://github.com/dimikout3/GeneralExplorationPolicy.
Estimating Disentangled Belief about Hidden State and Hidden Task for Meta-RL
May 14, 2021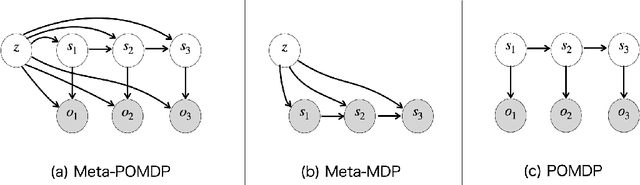
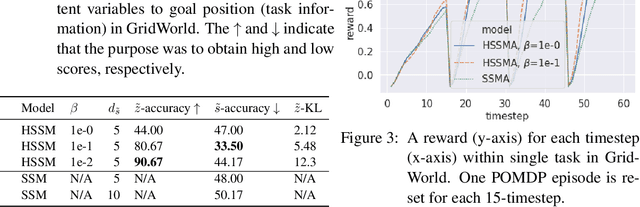
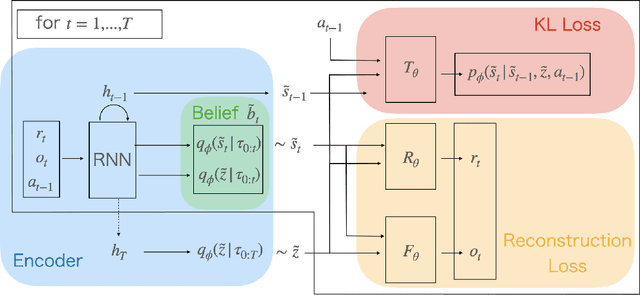
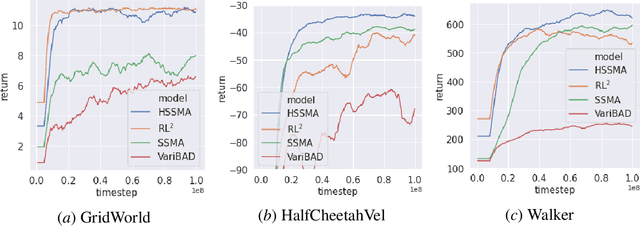
There is considerable interest in designing meta-reinforcement learning (meta-RL) algorithms, which enable autonomous agents to adapt new tasks from small amount of experience. In meta-RL, the specification (such as reward function) of current task is hidden from the agent. In addition, states are hidden within each task owing to sensor noise or limitations in realistic environments. Therefore, the meta-RL agent faces the challenge of specifying both the hidden task and states based on small amount of experience. To address this, we propose estimating disentangled belief about task and states, leveraging an inductive bias that the task and states can be regarded as global and local features of each task. Specifically, we train a hierarchical state-space model (HSSM) parameterized by deep neural networks as an environment model, whose global and local latent variables correspond to task and states, respectively. Because the HSSM does not allow analytical computation of posterior distribution, i.e., belief, we employ amortized inference to approximate it. After the belief is obtained, we can augment observations of a model-free policy with the belief to efficiently train the policy. Moreover, because task and state information are factorized and interpretable, the downstream policy training is facilitated compared with the prior methods that did not consider the hierarchical nature. Empirical validations on a GridWorld environment confirm that the HSSM can separate the hidden task and states information. Then, we compare the meta-RL agent with the HSSM to prior meta-RL methods in MuJoCo environments, and confirm that our agent requires less training data and reaches higher final performance.
Spectral Clustering Revisited: Information Hidden in the Fiedler Vector
Mar 22, 2020
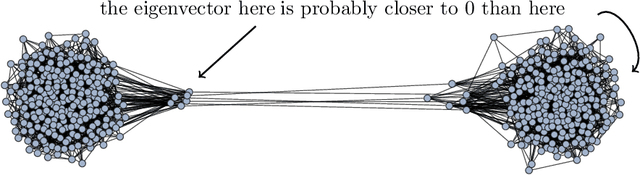
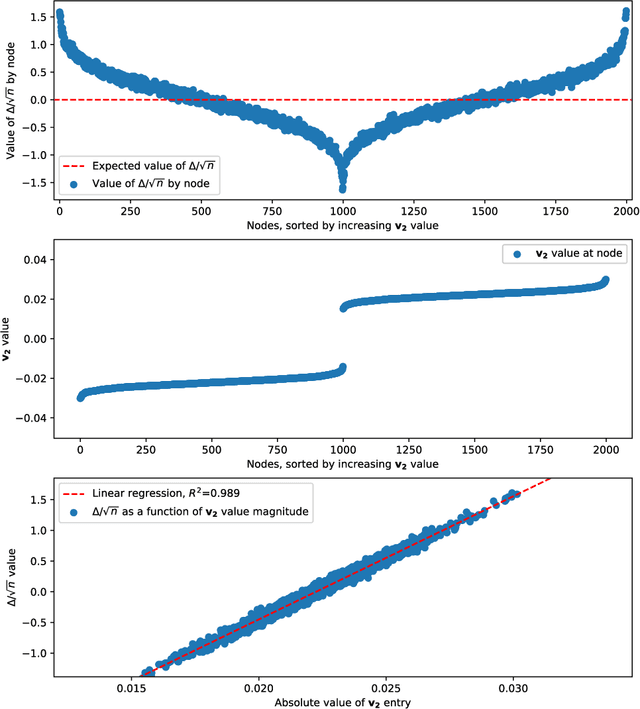
We are interested in the clustering problem on graphs: it is known that if there are two underlying clusters, then the signs of the eigenvector corresponding to the second largest eigenvalue of the adjacency matrix can reliably reconstruct the two clusters. We argue that the vertices for which the eigenvector has the largest and the smallest entries, respectively, are unusually strongly connected to their own cluster and more reliably classified than the rest. This can be regarded as a discrete version of the Hot Spots conjecture and should be useful in applications. We give a rigorous proof for the stochastic block model and several examples.
Deep learning for temporal data representation in electronic health records: A systematic review of challenges and methodologies
Jul 21, 2021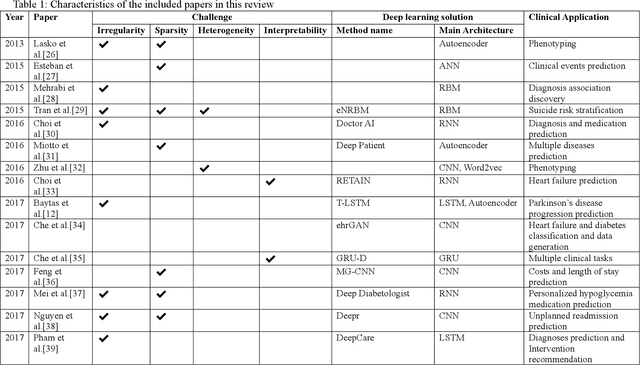
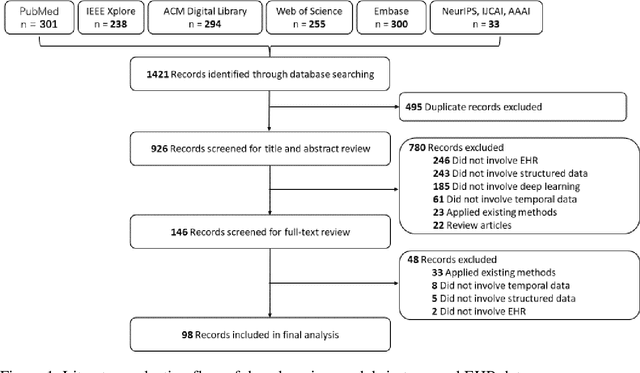
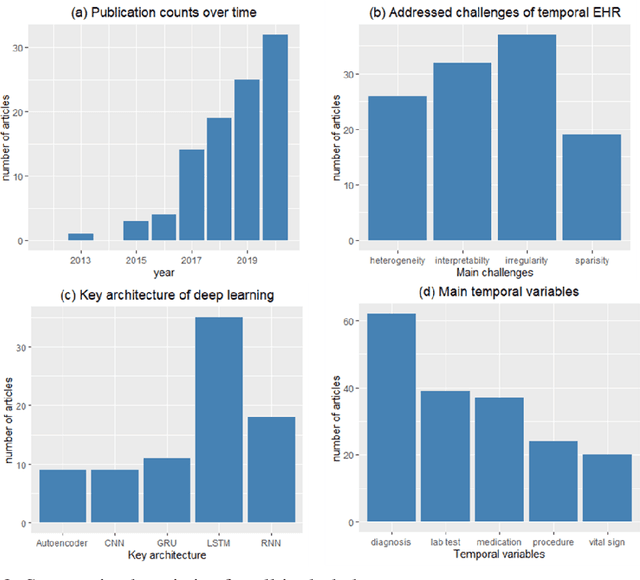
Objective: Temporal electronic health records (EHRs) can be a wealth of information for secondary uses, such as clinical events prediction or chronic disease management. However, challenges exist for temporal data representation. We therefore sought to identify these challenges and evaluate novel methodologies for addressing them through a systematic examination of deep learning solutions. Methods: We searched five databases (PubMed, EMBASE, the Institute of Electrical and Electronics Engineers [IEEE] Xplore Digital Library, the Association for Computing Machinery [ACM] digital library, and Web of Science) complemented with hand-searching in several prestigious computer science conference proceedings. We sought articles that reported deep learning methodologies on temporal data representation in structured EHR data from January 1, 2010, to August 30, 2020. We summarized and analyzed the selected articles from three perspectives: nature of time series, methodology, and model implementation. Results: We included 98 articles related to temporal data representation using deep learning. Four major challenges were identified, including data irregularity, data heterogeneity, data sparsity, and model opacity. We then studied how deep learning techniques were applied to address these challenges. Finally, we discuss some open challenges arising from deep learning. Conclusion: Temporal EHR data present several major challenges for clinical prediction modeling and data utilization. To some extent, current deep learning solutions can address these challenges. Future studies can consider designing comprehensive and integrated solutions. Moreover, researchers should incorporate additional clinical domain knowledge into study designs and enhance the interpretability of the model to facilitate its implementation in clinical practice.
Towards Defending against Adversarial Examples via Attack-Invariant Features
Jun 09, 2021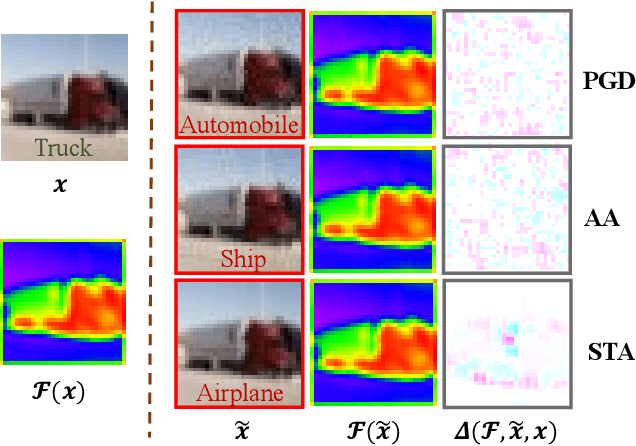
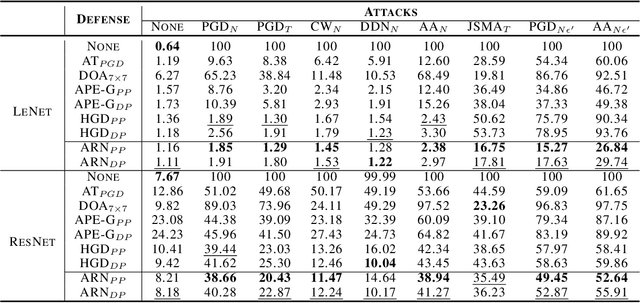
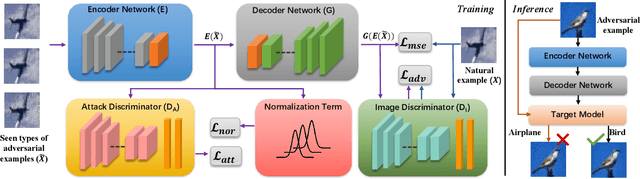
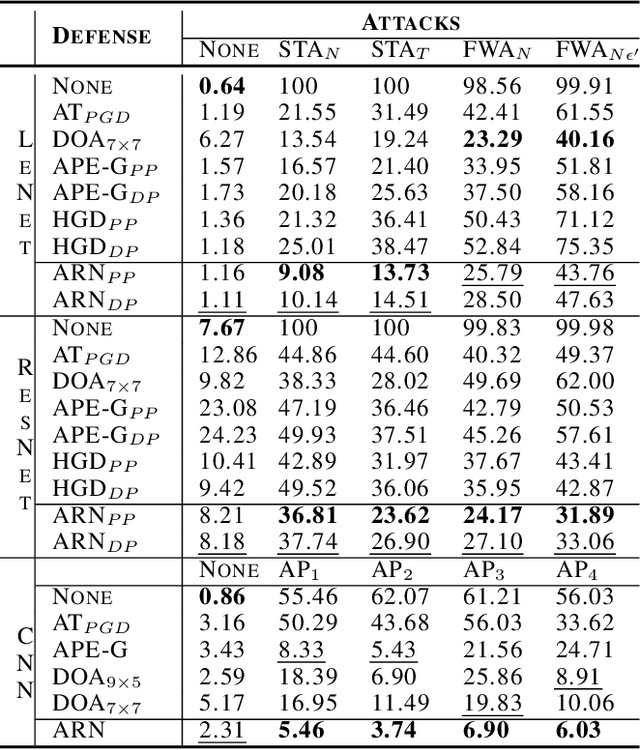
Deep neural networks (DNNs) are vulnerable to adversarial noise. Their adversarial robustness can be improved by exploiting adversarial examples. However, given the continuously evolving attacks, models trained on seen types of adversarial examples generally cannot generalize well to unseen types of adversarial examples. To solve this problem, in this paper, we propose to remove adversarial noise by learning generalizable invariant features across attacks which maintain semantic classification information. Specifically, we introduce an adversarial feature learning mechanism to disentangle invariant features from adversarial noise. A normalization term has been proposed in the encoded space of the attack-invariant features to address the bias issue between the seen and unseen types of attacks. Empirical evaluations demonstrate that our method could provide better protection in comparison to previous state-of-the-art approaches, especially against unseen types of attacks and adaptive attacks.
Learning Cascaded Detection Tasks with Weakly-Supervised Domain Adaptation
Jul 09, 2021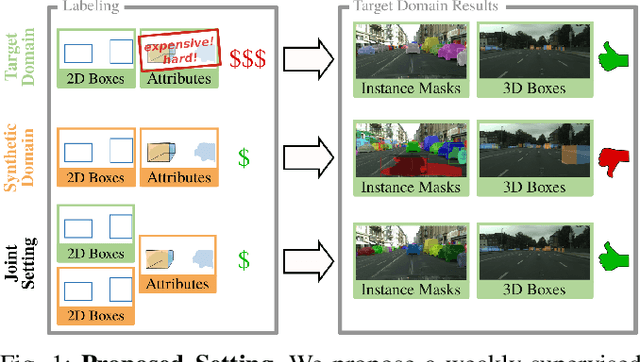
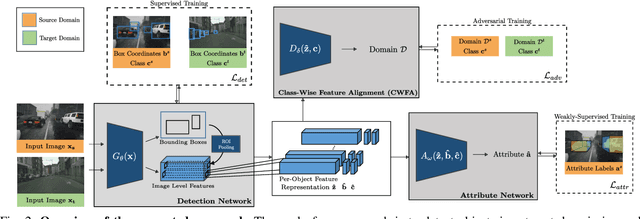


In order to handle the challenges of autonomous driving, deep learning has proven to be crucial in tackling increasingly complex tasks, such as 3D detection or instance segmentation. State-of-the-art approaches for image-based detection tasks tackle this complexity by operating in a cascaded fashion: they first extract a 2D bounding box based on which additional attributes, e.g. instance masks, are inferred. While these methods perform well, a key challenge remains the lack of accurate and cheap annotations for the growing variety of tasks. Synthetic data presents a promising solution but, despite the effort in domain adaptation research, the gap between synthetic and real data remains an open problem. In this work, we propose a weakly supervised domain adaptation setting which exploits the structure of cascaded detection tasks. In particular, we learn to infer the attributes solely from the source domain while leveraging 2D bounding boxes as weak labels in both domains to explain the domain shift. We further encourage domain-invariant features through class-wise feature alignment using ground-truth class information, which is not available in the unsupervised setting. As our experiments demonstrate, the approach is competitive with fully supervised settings while outperforming unsupervised adaptation approaches by a large margin.
A Case Study on Pros and Cons of Regular Expression Detection and Dependency Parsing for Negation Extraction from German Medical Documents. Technical Report
May 20, 2021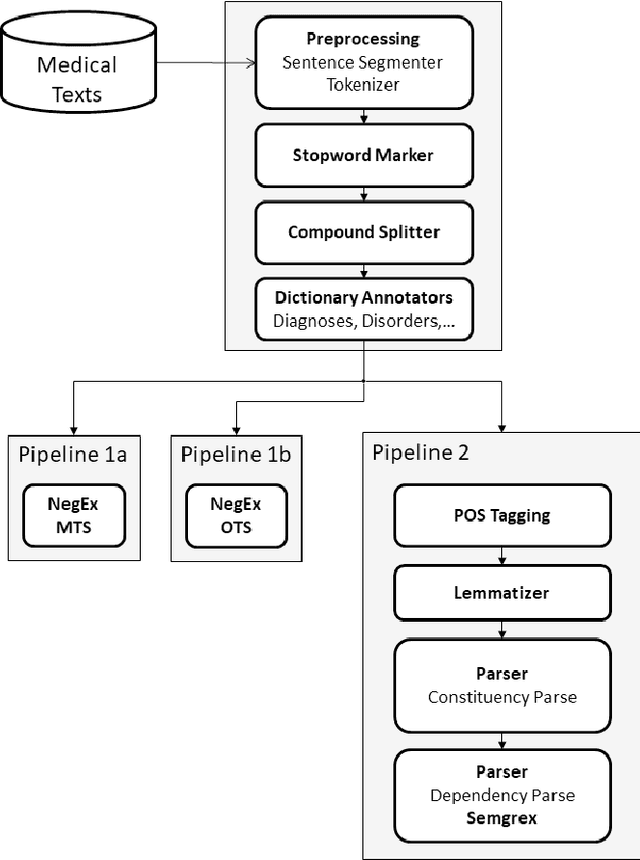

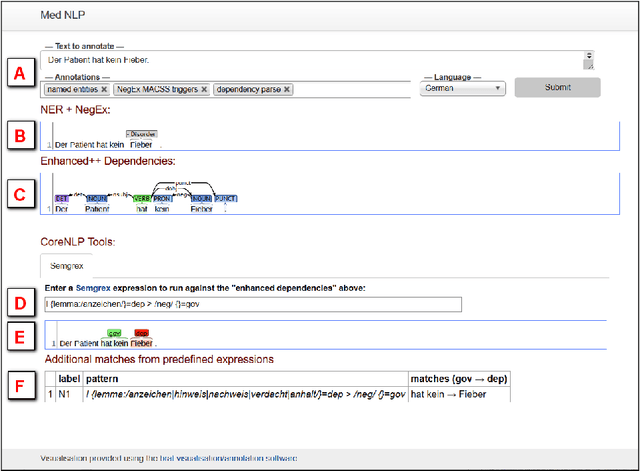
We describe our work on information extraction in medical documents written in German, especially detecting negations using an architecture based on the UIMA pipeline. Based on our previous work on software modules to cover medical concepts like diagnoses, examinations, etc. we employ a version of the NegEx regular expression algorithm with a large set of triggers as a baseline. We show how a significantly smaller trigger set is sufficient to achieve similar results, in order to reduce adaptation times to new text types. We elaborate on the question whether dependency parsing (based on the Stanford CoreNLP model) is a good alternative and describe the potentials and shortcomings of both approaches.
PROVED: A Tool for Graph Representation and Analysis of Uncertain Event Data
Mar 09, 2021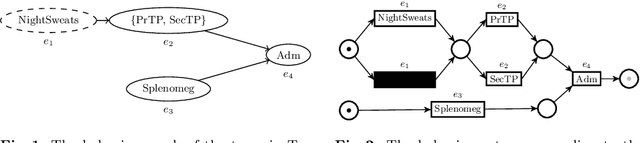
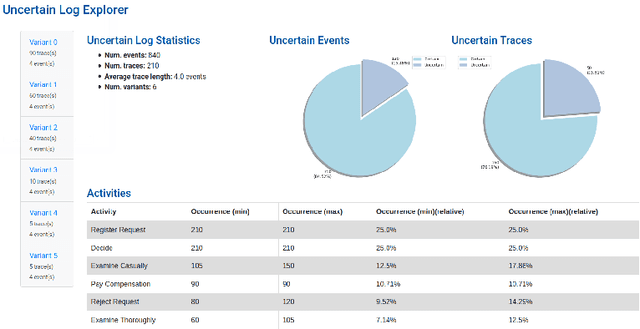

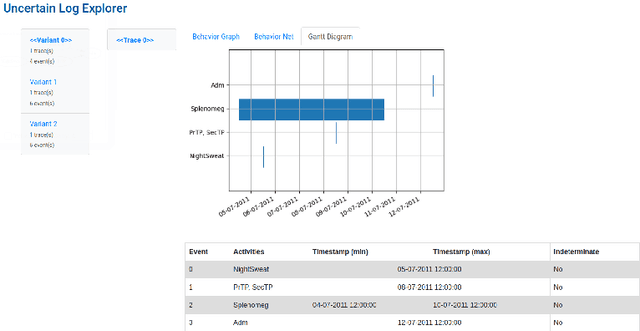
The discipline of process mining aims to study processes in a data-driven manner by analyzing historical process executions, often employing Petri nets. Event data, extracted from information systems (e.g. SAP), serve as the starting point for process mining. Recently, novel types of event data have gathered interest among the process mining community, including uncertain event data. Uncertain events, process traces and logs contain attributes that are characterized by quantified imprecisions, e.g., a set of possible attribute values. The PROVED tool helps to explore, navigate and analyze such uncertain event data by abstracting the uncertain information using behavior graphs and nets, which have Petri nets semantics. Based on these constructs, the tool enables discovery and conformance checking.