 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adversarial Graph Augmentation to Improve Graph Contrastive Learning
Jun 25, 2021
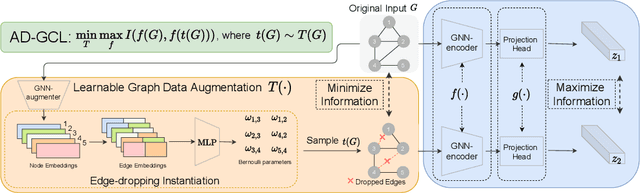
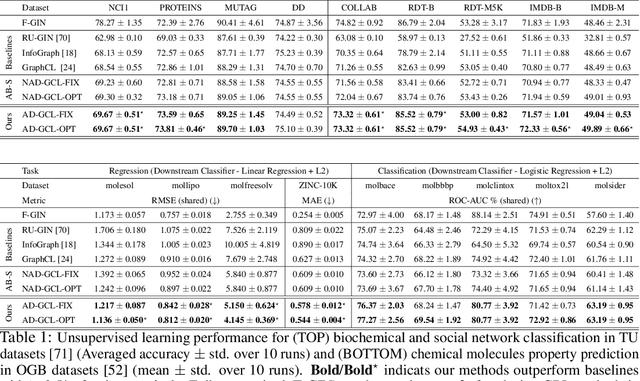
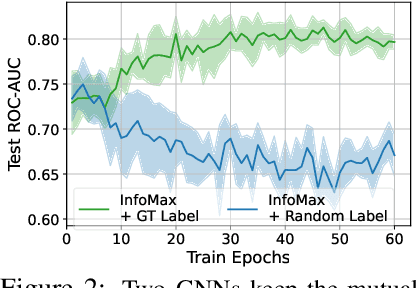
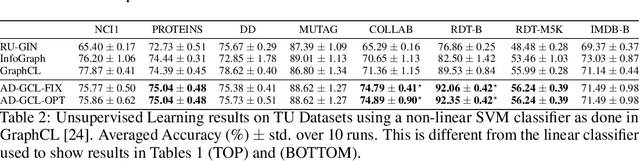
Self-supervised learning of graph neural networks (GNN) is in great need because of the widespread label scarcity issue in real-world graph/network data. Graph contrastive learning (GCL), by training GNNs to maximize the correspondence between the representations of the same graph in its different augmented forms, may yield robust and transferable GNNs even without using labels. However, GNNs trained by traditional GCL often risk capturing redundant graph features and thus may be brittle and provide sub-par performance in downstream tasks. Here, we propose a novel principle, termed adversarial-GCL (AD-GCL), which enables GNNs to avoid capturing redundant information during the training by optimizing adversarial graph augmentation strategies used in GCL. We pair AD-GCL with theoretical explanations and design a practical instantiation based on trainable edge-dropping graph augmentation. We experimentally validate AD-GCL by comparing with the state-of-the-art GCL methods and achieve performance gains of up-to $14\%$ in unsupervised, $6\%$ in transfer, and $3\%$ in semi-supervised learning settings overall with 18 different benchmark datasets for the tasks of molecule property regression and classification, and social network classification.
Attention-based Neural Beamforming Layers for Multi-channel Speech Recognition
May 12, 2021

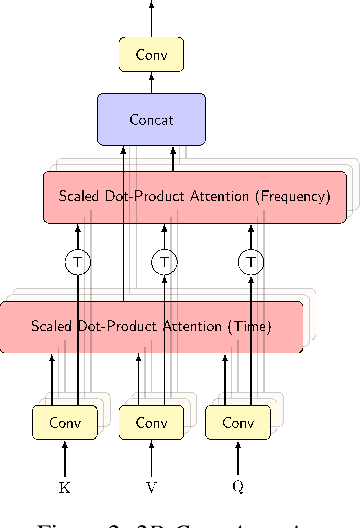

Attention-based beamformers have recently been shown to be effective for multi-channel speech recognition. However, they are less capable at capturing local information. In this work, we propose a 2D Conv-Attention module which combines convolution neural networks with attention for beamforming. We apply self- and cross-attention to explicitly model the correlations within and between the input channels. The end-to-end 2D Conv-Attention model is compared with a multi-head self-attention and superdirective-based neural beamformers. We train and evaluate on an in-house multi-channel dataset. The results show a relative improvement of 3.8% in WER by the proposed model over the baseline neural beamformer.
General Data Analytics With Applications To Visual Information Analysis: A Provable Backward-Compatible Semisimple Paradigm Over T-Algebra
Nov 04, 2020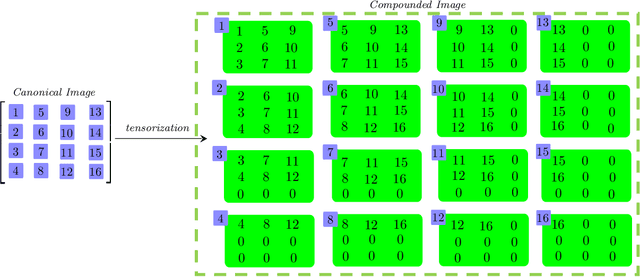
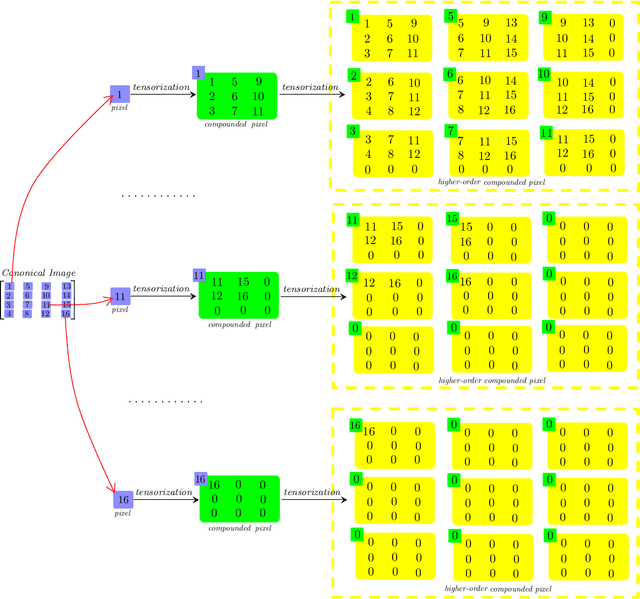

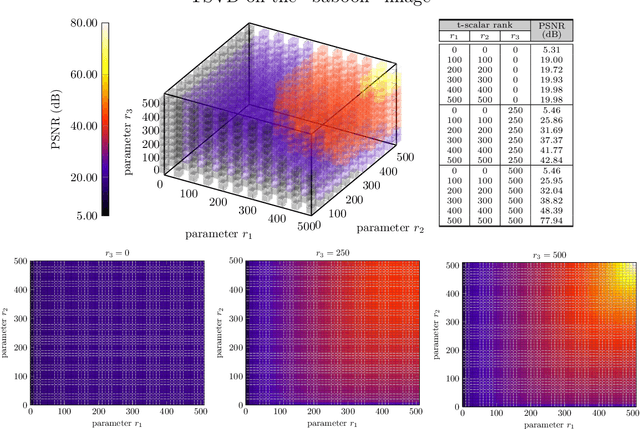
We consider a novel backward-compatible paradigm of general data analytics over a recently-reported semisimple algebra (called t-algebra). We study the abstract algebraic framework over the t-algebra by representing the elements of t-algebra by fix-sized multi-way arrays of complex numbers and the algebraic structure over the t-algebra by a collection of direct-product constituents. Over the t-algebra, many algorithms, if not all, are generalized in a straightforward manner using this new semisimple paradigm. To demonstrate the new paradigm's performance and its backward-compatibility, we generalize some canonical algorithms for visual pattern analysis. Experiments on public datasets show that the generalized algorithms compare favorably with their canonical counterparts.
Effects of Quantization on the Multiple-Round Secret-Key Capacity
May 06, 2021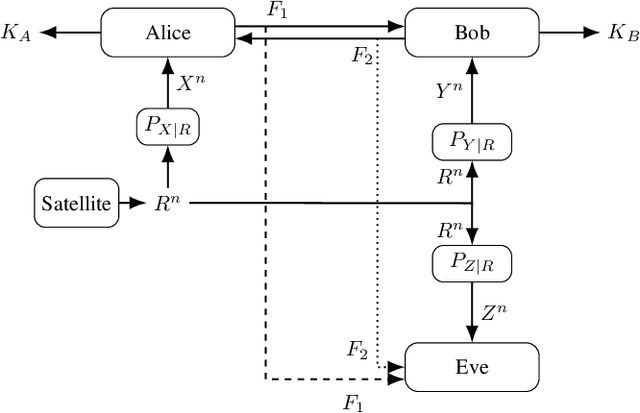
We consider the strong secret key (SK) agreement problem for the satellite communication setting, where a remote source (a satellite) chooses a common binary phase shift keying (BPSK) modulated input for three statistically independent additive white Gaussian noise (AWGN) channels whose outputs are observed by, respectively, two legitimate receivers (Alice and Bob) and an eavesdropper (Eve). Legitimate receivers have access to an authenticated, noiseless, two-way, and public communication link, so they can exchange multiple rounds of public messages to agree on a SK hidden from Eve. Without loss of essential generality, the noise variances for Alice's and Bob's measurement channels are both fixed to a value $Q>1$, whereas the noise over Eve's measurement channel has a unit variance, so $Q$ represents a channel quality ratio. The significant and not necessarily expected effect of quantizations at all receivers on the scaling of the SK capacity with respect to a sufficiently large and finite channel quality ratio $Q$ is illustrated by showing 1) the achievability of a constant SK for any finite BPSK modulated satellite output by proposing a thresholding algorithm as an advantage distillation protocol for AWGN channels and 2) the converse (i.e., unachievability) bound for the case when all receivers apply a one-bit uniform quantizer to their noisy observations before SK agreement, for which the SK capacity is shown to decrease quadratically in $Q$. Our results prove that soft information increases not only the reliability and the achieved SK rate but also the scaling of the SK capacity at least quadratically in $Q$ as compared to hard information.
Decoupling Shape and Density for Liver Lesion Synthesis Using Conditional Generative Adversarial Networks
Jun 01, 2021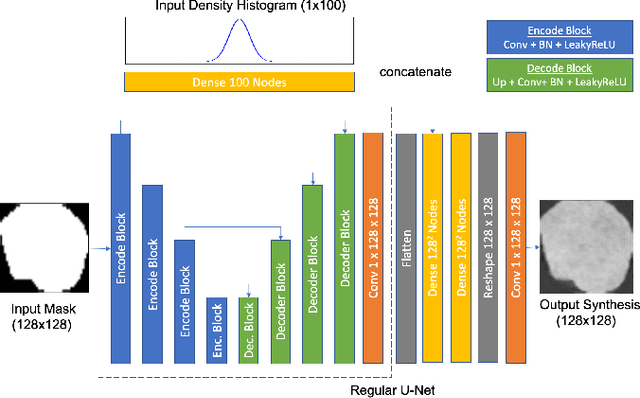

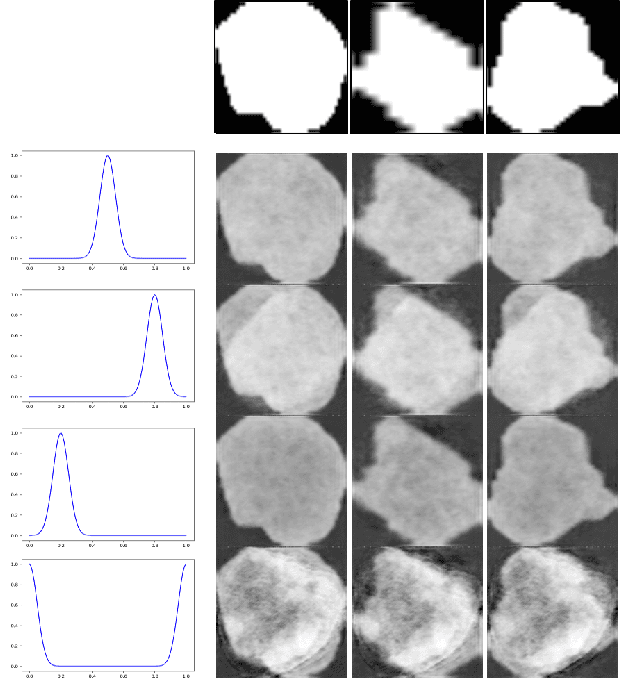
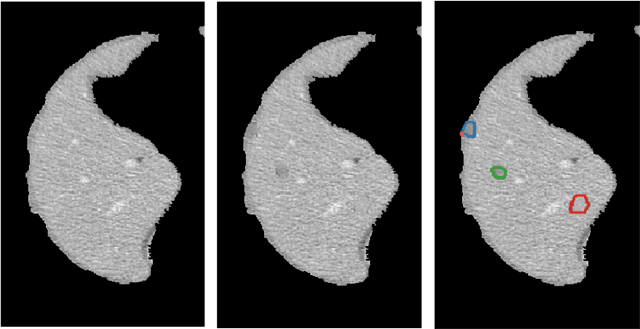
Lesion synthesis received much attention with the rise of efficient generative models for augmenting training data, drawing lesion evolution scenarios, or aiding expert training. The quality and diversity of synthesized data are highly dependent on the annotated data used to train the models, which not rarely struggle to derive very different yet realistic samples from the training ones. That adds an inherent bias to lesion segmentation algorithms and limits synthesizing lesion evolution scenarios efficiently. This paper presents a method for decoupling shape and density for liver lesion synthesis, creating a framework that allows straight-forwardly driving the synthesis. We offer qualitative results that show the synthesis control by modifying shape and density individually, and quantitative results that demonstrate that embedding the density information in the generator model helps to increase lesion segmentation performance compared to using the shape solely.
Benchmarking Modern Named Entity Recognition Techniques for Free-text Health Record De-identification
Mar 25, 2021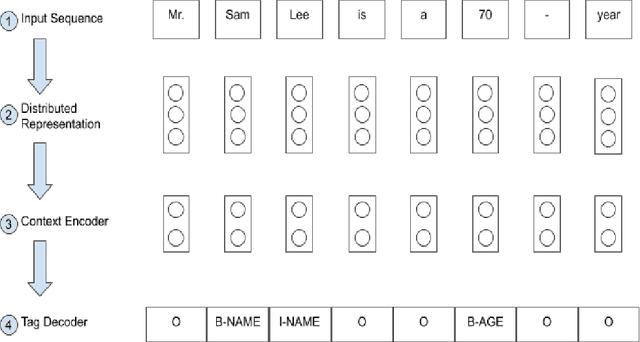
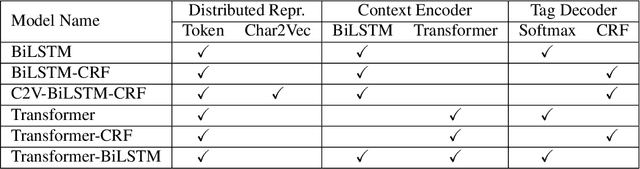
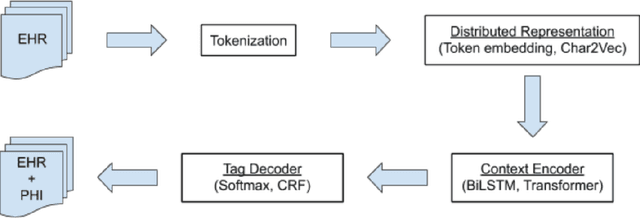
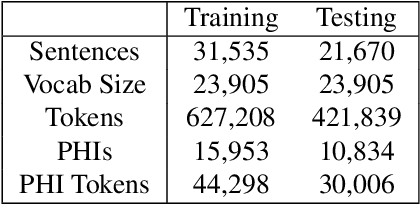
Electronic Health Records (EHRs) have become the primary form of medical data-keeping across the United States. Federal law restricts the sharing of any EHR data that contains protected health information (PHI). De-identification, the process of identifying and removing all PHI, is crucial for making EHR data publicly available for scientific research. This project explores several deep learning-based named entity recognition (NER) methods to determine which method(s) perform better on the de-identification task. We trained and tested our models on the i2b2 training dataset, and qualitatively assessed their performance using EHR data collected from a local hospital. We found that 1) BiLSTM-CRF represents the best-performing encoder/decoder combination, 2) character-embeddings and CRFs tend to improve precision at the price of recall, and 3) transformers alone under-perform as context encoders. Future work focused on structuring medical text may improve the extraction of semantic and syntactic information for the purposes of EHR de-identification.
Modality Completion via Gaussian Process Prior Variational Autoencoders for Multi-Modal Glioma Segmentation
Jul 07, 2021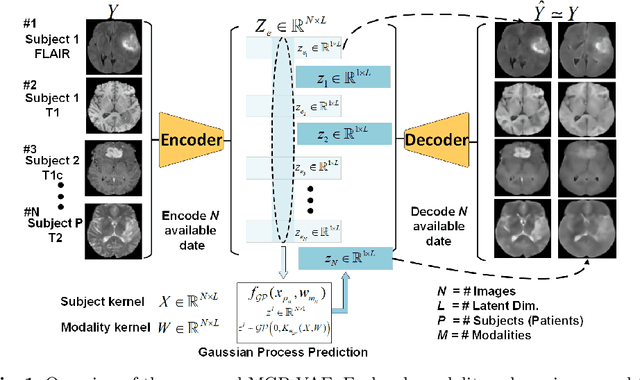
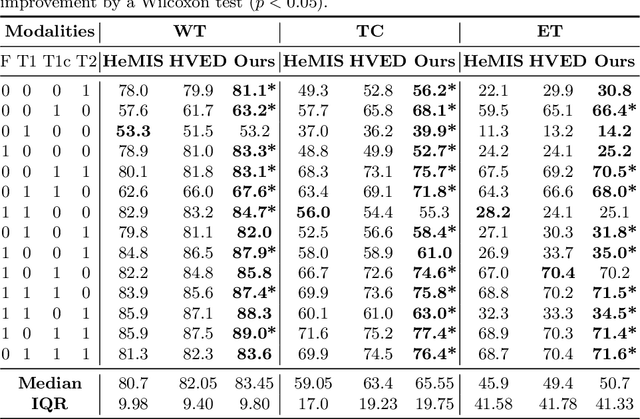
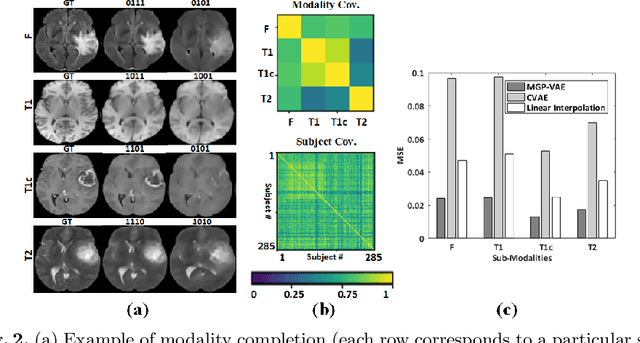
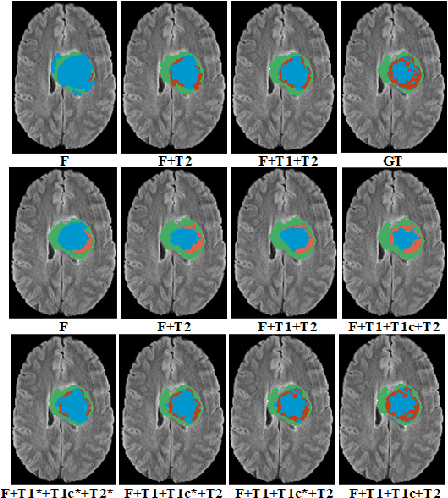
In large studies involving multi protocol Magnetic Resonance Imaging (MRI), it can occur to miss one or more sub-modalities for a given patient owing to poor quality (e.g. imaging artifacts), failed acquisitions, or hallway interrupted imaging examinations. In some cases, certain protocols are unavailable due to limited scan time or to retrospectively harmonise the imaging protocols of two independent studies. Missing image modalities pose a challenge to segmentation frameworks as complementary information contributed by the missing scans is then lost. In this paper, we propose a novel model, Multi-modal Gaussian Process Prior Variational Autoencoder (MGP-VAE), to impute one or more missing sub-modalities for a patient scan. MGP-VAE can leverage the Gaussian Process (GP) prior on the Variational Autoencoder (VAE) to utilize the subjects/patients and sub-modalities correlations. Instead of designing one network for each possible subset of present sub-modalities or using frameworks to mix feature maps, missing data can be generated from a single model based on all the available samples. We show the applicability of MGP-VAE on brain tumor segmentation where either, two, or three of four sub-modalities may be missing. Our experiments against competitive segmentation baselines with missing sub-modality on BraTS'19 dataset indicate the effectiveness of the MGP-VAE model for segmentation tasks.
Parsimonious Inference
Mar 03, 2021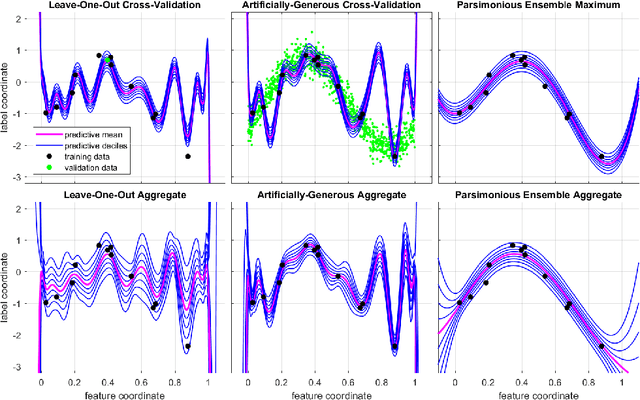

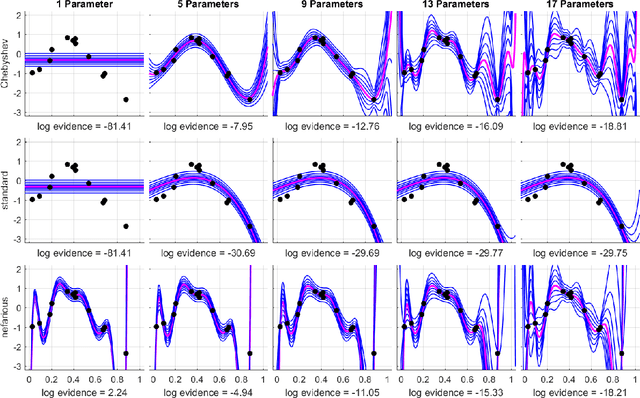
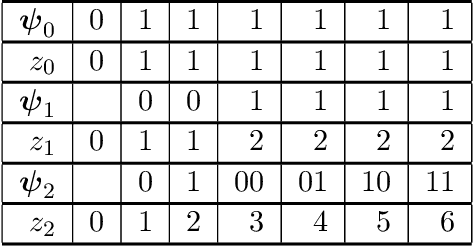
Bayesian inference provides a uniquely rigorous approach to obtain principled justification for uncertainty in predictions, yet it is difficult to articulate suitably general prior belief in the machine learning context, where computational architectures are pure abstractions subject to frequent modifications by practitioners attempting to improve results. Parsimonious inference is an information-theoretic formulation of inference over arbitrary architectures that formalizes Occam's Razor; we prefer simple and sufficient explanations. Our universal hyperprior assigns plausibility to prior descriptions, encoded as sequences of symbols, by expanding on the core relationships between program length, Kolmogorov complexity, and Solomonoff's algorithmic probability. We then cast learning as information minimization over our composite change in belief when an architecture is specified, training data are observed, and model parameters are inferred. By distinguishing model complexity from prediction information, our framework also quantifies the phenomenon of memorization. Although our theory is general, it is most critical when datasets are limited, e.g. small or skewed. We develop novel algorithms for polynomial regression and random forests that are suitable for such data, as demonstrated by our experiments. Our approaches combine efficient encodings with prudent sampling strategies to construct predictive ensembles without cross-validation, thus addressing a fundamental challenge in how to efficiently obtain predictions from data.
Dual-Teacher Class-Incremental Learning With Data-Free Generative Replay
Jun 17, 2021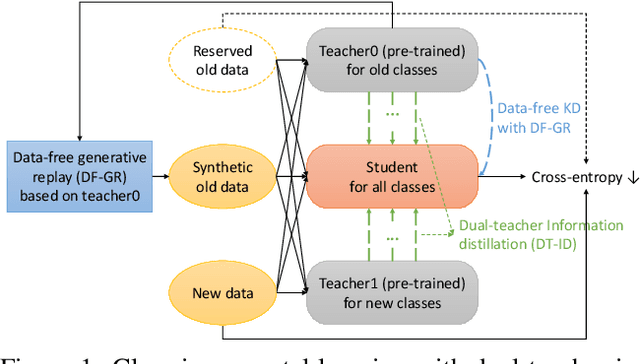

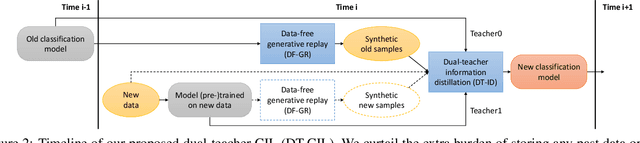

This paper proposes two novel knowledge transfer techniques for class-incremental learning (CIL). First, we propose data-free generative replay (DF-GR) to mitigate catastrophic forgetting in CIL by using synthetic samples from a generative model. In the conventional generative replay, the generative model is pre-trained for old data and shared in extra memory for later incremental learning. In our proposed DF-GR, we train a generative model from scratch without using any training data, based on the pre-trained classification model from the past, so we curtail the cost of sharing pre-trained generative models. Second, we introduce dual-teacher information distillation (DT-ID) for knowledge distillation from two teachers to one student. In CIL, we use DT-ID to learn new classes incrementally based on the pre-trained model for old classes and another model (pre-)trained on the new data for new classes. We implemented the proposed schemes on top of one of the state-of-the-art CIL methods and showed the performance improvement on CIFAR-100 and ImageNet datasets.
Active Bayesian Multi-class Mapping from Range and Semantic Segmentation Observation
Jan 06, 2021
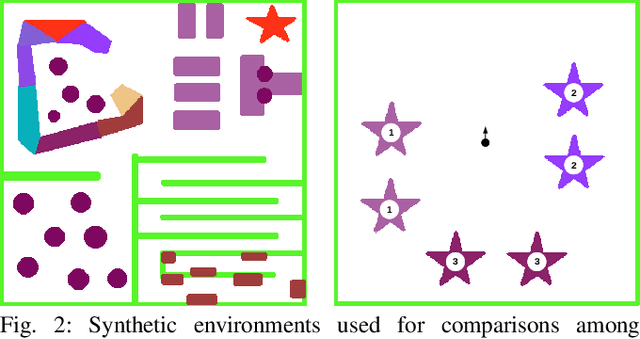
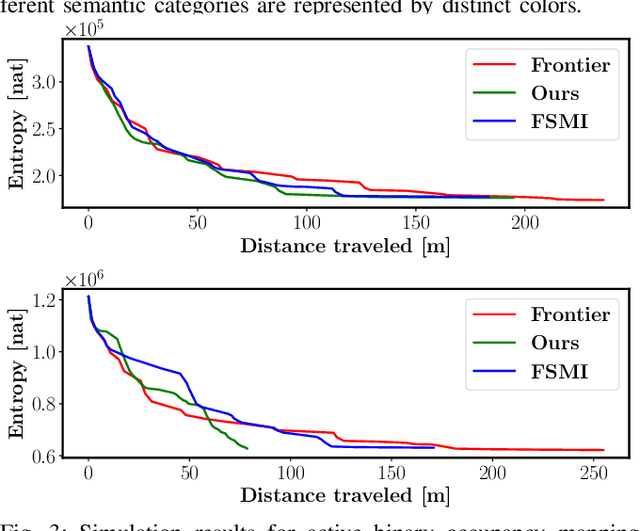
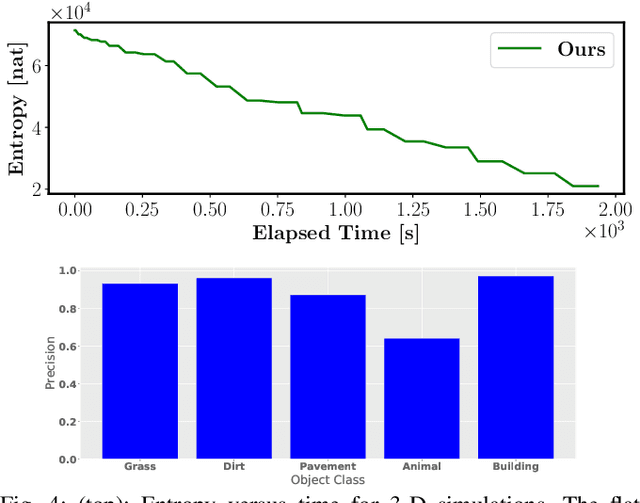
Many robot applications call for autonomous exploration and mapping of unknown and unstructured environments. Information-based exploration techniques, such as Cauchy-Schwarz quadratic mutual information (CSQMI) and fast Shannon mutual information (FSMI), have successfully achieved active binary occupancy mapping with range measurements. However, as we envision robots performing complex tasks specified with semantically meaningful objects, it is necessary to capture semantic categories in the measurements, map representation, and exploration objective. This work develops a Bayesian multi-class mapping algorithm utilizing range-category measurements. We derive a closed-form efficiently computable lower bound for the Shannon mutual information between the multi-class map and the measurements. The bound allows rapid evaluation of many potential robot trajectories for autonomous exploration and mapping. We compare our method against frontier-based and FSMI exploration and apply it in a 3-D photo-realistic simulation environment.