 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CUDA-GR: Controllable Unsupervised Domain Adaptation for Gaze Redirection
Jun 21, 2021
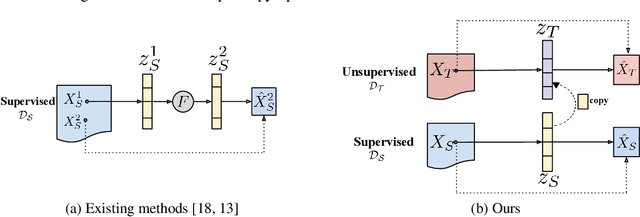
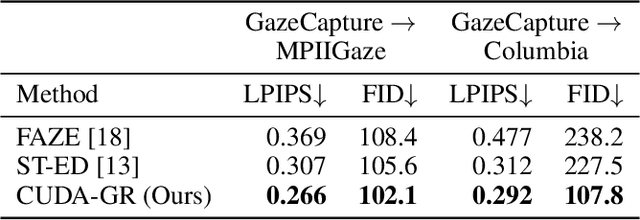
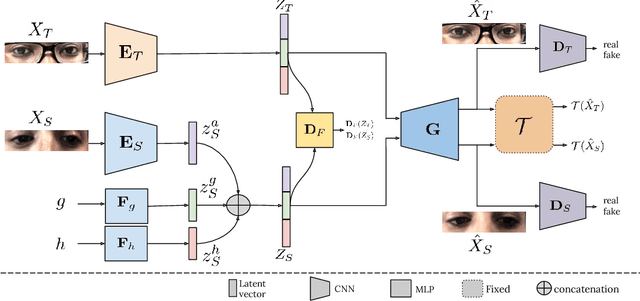

The aim of gaze redirection is to manipulate the gaze in an image to the desired direction. However, existing methods are inadequate in generating perceptually reasonable images. Advancement in generative adversarial networks has shown excellent results in generating photo-realistic images. Though, they still lack the ability to provide finer control over different image attributes. To enable such fine-tuned control, one needs to obtain ground truth annotations for the training data which can be very expensive. In this paper, we propose an unsupervised domain adaptation framework, called CUDA-GR, that learns to disentangle gaze representations from the labeled source domain and transfers them to an unlabeled target domain. Our method enables fine-grained control over gaze directions while preserving the appearance information of the person. We show that the generated image-labels pairs in the target domain are effective in knowledge transfer and can boost the performance of the downstream tasks. Extensive experiments on the benchmarking datasets show that the proposed method can outperform state-of-the-art techniques in both quantitative and qualitative evaluation.
Pay Better Attention to Attention: Head Selection in Multilingual and Multi-Domain Sequence Modeling
Jun 21, 2021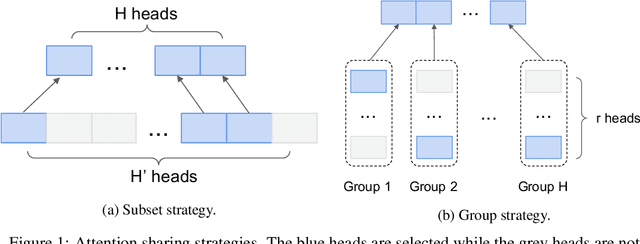
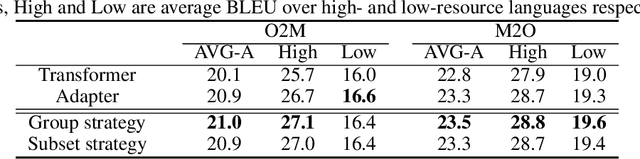

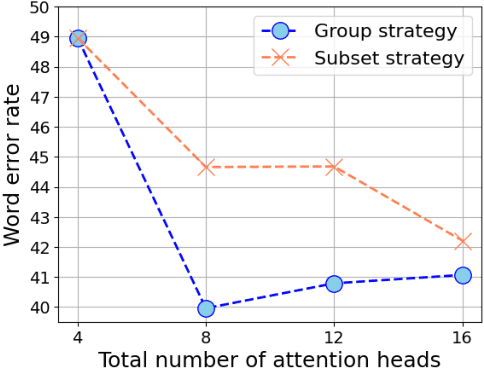
Multi-head attention has each of the attention heads collect salient information from different parts of an input sequence, making it a powerful mechanism for sequence modeling. Multilingual and multi-domain learning are common scenarios for sequence modeling, where the key challenge is to maximize positive transfer and mitigate negative transfer across languages and domains. In this paper, we find that non-selective attention sharing is sub-optimal for achieving good generalization across all languages and domains. We further propose attention sharing strategies to facilitate parameter sharing and specialization in multilingual and multi-domain sequence modeling. Our approach automatically learns shared and specialized attention heads for different languages and domains to mitigate their interference. Evaluated in various tasks including speech recognition, text-to-text and speech-to-text translation, the proposed attention sharing strategies consistently bring gains to sequence models built upon multi-head attention. For speech-to-text translation, our approach yields an average of $+2.0$ BLEU over $13$ language directions in multilingual setting and $+2.0$ BLEU over $3$ domains in multi-domain setting.
Adaptively Optimize Content Recommendation Using Multi Armed Bandit Algorithms in E-commerce
Jul 30, 2021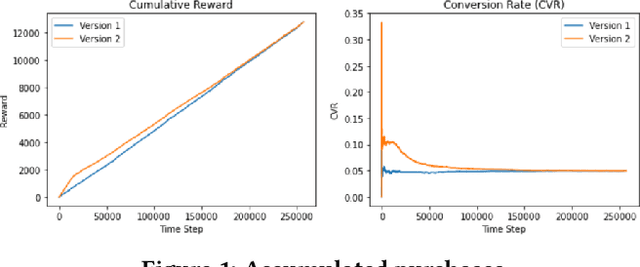
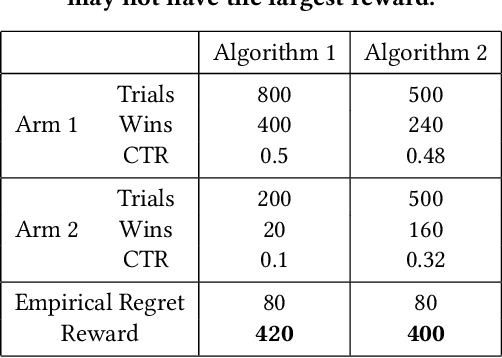
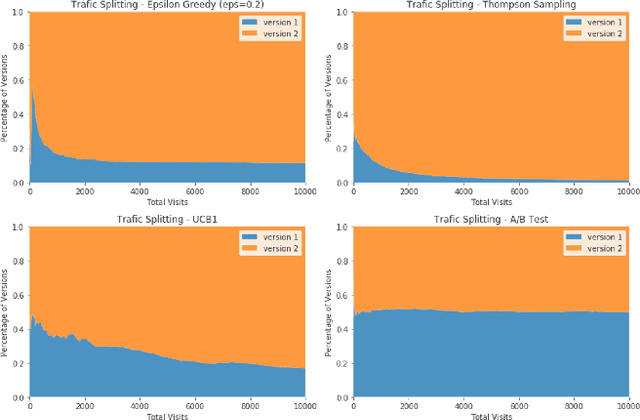
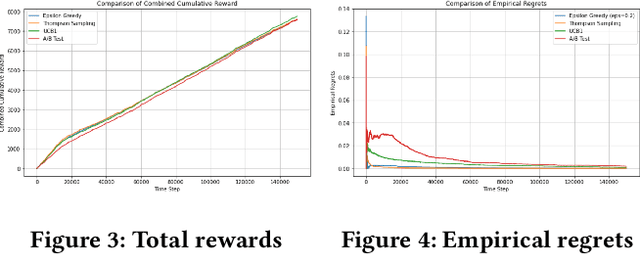
E-commerce sites strive to provide users the most timely relevant information in order to reduce shopping frictions and increase customer satisfaction. Multi armed bandit models (MAB) as a type of adaptive optimization algorithms provide possible approaches for such purposes. In this paper, we analyze using three classic MAB algorithms, epsilon-greedy, Thompson sampling (TS), and upper confidence bound 1 (UCB1) for dynamic content recommendations, and walk through the process of developing these algorithms internally to solve a real world e-commerce use case. First, we analyze the three MAB algorithms using simulated purchasing datasets with non-stationary reward distributions to simulate the possible time-varying customer preferences, where the traffic allocation dynamics and the accumulative rewards of different algorithms are studied. Second, we compare the accumulative rewards of the three MAB algorithms with more than 1,000 trials using actual historical A/B test datasets. We find that the larger difference between the success rates of competing recommendations the more accumulative rewards the MAB algorithms can achieve. In addition, we find that TS shows the highest average accumulative rewards under different testing scenarios. Third, we develop a batch-updated MAB algorithm to overcome the delayed reward issue in e-commerce and enable an online content optimization on our App homepage. For a state-of-the-art comparison, a real A/B test among our batch-updated MAB algorithm, a third-party MAB solution, and the default business logic are conducted. The result shows that our batch-updated MAB algorithm outperforms the counterparts and achieves 6.13% relative click-through rate (CTR) increase and 16.1% relative conversion rate (CVR) increase compared to the default experience, and 2.9% relative CTR increase and 1.4% relative CVR increase compared to the external MAB service.
Conversational Machine Reading Comprehension for Vietnamese Healthcare Texts
May 21, 2021
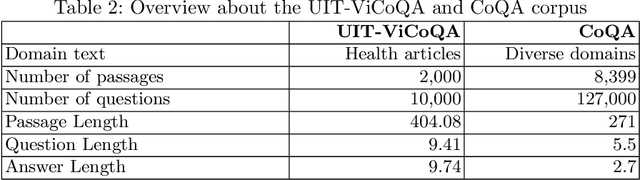
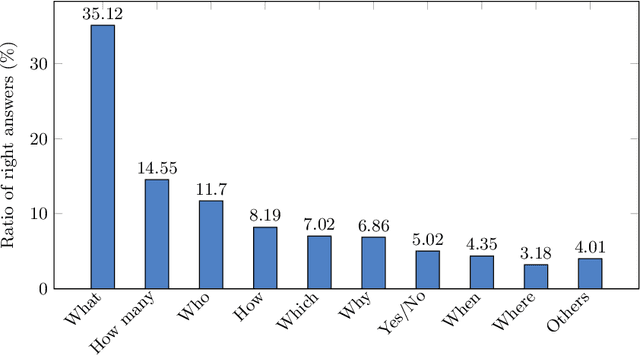

Machine reading comprehension (MRC) is a sub-field in natural language processing that aims to help computers understand unstructured texts and then answer questions related to them. In practice, conversation is an essential way to communicate and transfer information. To help machines understand conversation texts, we present UIT-ViCoQA - a new corpus for conversational machine reading comprehension in the Vietnamese language. This corpus consists of 10,000 questions with answers to over 2,000 conversations about health news articles. Then, we evaluate several baseline approaches for conversational machine comprehension on the UIT-ViCoQA corpus. The best model obtains an F1 score of 45.27%, which is 30.91 points behind human performance (76.18%), indicating that there is ample room for improvement.
Reducing the dilution: An analysis of the information sensitiveness of capsule network with a practical solution
Mar 27, 2019
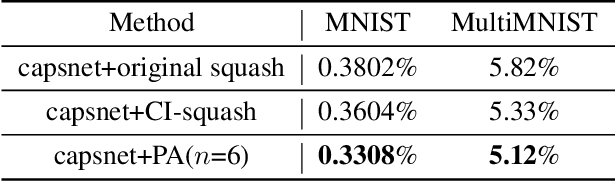

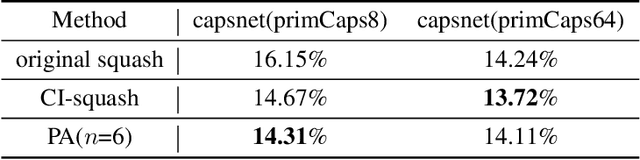
Capsule network has shown various advantages over convolutional neural network (CNN). It keeps more precise spatial information than CNN and uses equivariance instead of invariance during inference and highly potential to be a new effective tool for visual tasks. However, the current capsule networks have incompatible performance with CNN when facing datasets with background and complex target objects and are lacking in universal and efficient regularization method. We analyze the main reason of the incompatible performance as the conflict between information sensitiveness of capsule network and unreasonably higher activation value distribution of capsules in primary capsule layer. Correspondingly, we propose sparsified capsule network by sparsifying and restraining the activation value of capsules in primary capsule layer to suppress non-informative capsules and highlight discriminative capsules. In the experiments, the sparsified capsule network has achieved better performances on various mainstream datasets. In addition, the proposed sparsifying methods can be seen as a suitable, simple and efficient regularization method that can be generally used in capsule network.
More Robust Dense Retrieval with Contrastive Dual Learning
Jul 16, 2021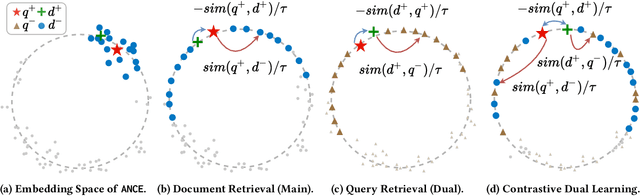

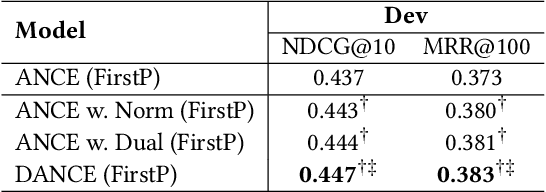
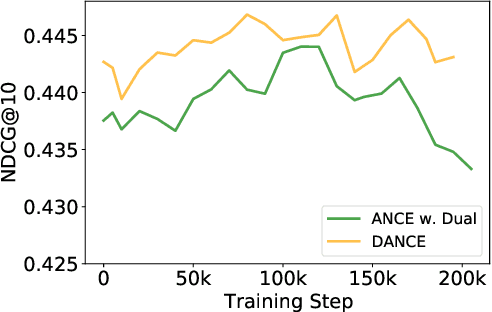
Dense retrieval conducts text retrieval in the embedding space and has shown many advantages compared to sparse retrieval. Existing dense retrievers optimize representations of queries and documents with contrastive training and map them to the embedding space. The embedding space is optimized by aligning the matched query-document pairs and pushing the negative documents away from the query. However, in such training paradigm, the queries are only optimized to align to the documents and are coarsely positioned, leading to an anisotropic query embedding space. In this paper, we analyze the embedding space distributions and propose an effective training paradigm, Contrastive Dual Learning for Approximate Nearest Neighbor (DANCE) to learn fine-grained query representations for dense retrieval. DANCE incorporates an additional dual training object of query retrieval, inspired by the classic information retrieval training axiom, query likelihood. With contrastive learning, the dual training object of DANCE learns more tailored representations for queries and documents to keep the embedding space smooth and uniform, thriving on the ranking performance of DANCE on the MS MARCO document retrieval task. Different from ANCE that only optimized with the document retrieval task, DANCE concentrates the query embeddings closer to document representations while making the document distribution more discriminative. Such concentrated query embedding distribution assigns more uniform negative sampling probabilities to queries and helps to sufficiently optimize query representations in the query retrieval task. Our codes are released at https://github.com/thunlp/DANCE.
Discrete-Valued Neural Communication
Jul 10, 2021

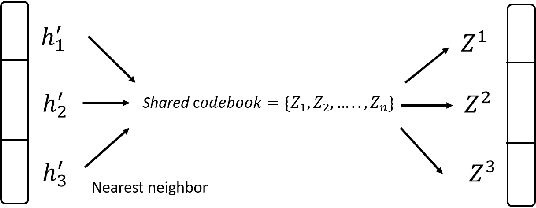
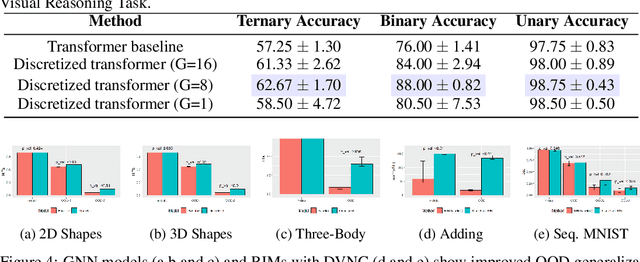
Deep learning has advanced from fully connected architectures to structured models organized into components, e.g., the transformer composed of positional elements, modular architectures divided into slots, and graph neural nets made up of nodes. In structured models, an interesting question is how to conduct dynamic and possibly sparse communication among the separate components. Here, we explore the hypothesis that restricting the transmitted information among components to discrete representations is a beneficial bottleneck. The motivating intuition is human language in which communication occurs through discrete symbols. Even though individuals have different understandings of what a "cat" is based on their specific experiences, the shared discrete token makes it possible for communication among individuals to be unimpeded by individual differences in internal representation. To discretize the values of concepts dynamically communicated among specialist components, we extend the quantization mechanism from the Vector-Quantized Variational Autoencoder to multi-headed discretization with shared codebooks and use it for discrete-valued neural communication (DVNC). Our experiments show that DVNC substantially improves systematic generalization in a variety of architectures -- transformers, modular architectures, and graph neural networks. We also show that the DVNC is robust to the choice of hyperparameters, making the method very useful in practice. Moreover, we establish a theoretical justification of our discretization process, proving that it has the ability to increase noise robustness and reduce the underlying dimensionality of the model.
Dependency Parsing based Semantic Representation Learning with Graph Neural Network for Enhancing Expressiveness of Text-to-Speech
Apr 20, 2021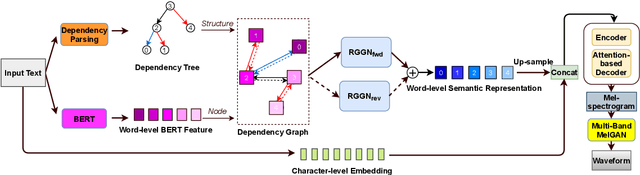

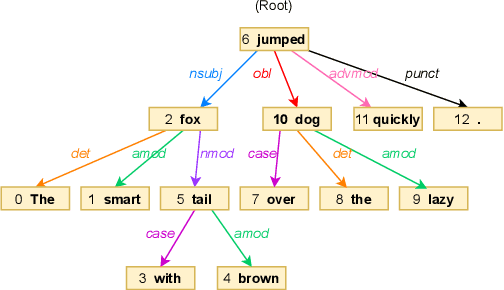
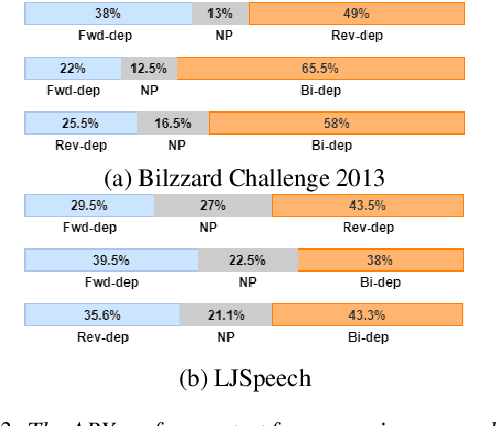
Semantic information of a sentence is crucial for improving the expressiveness of a text-to-speech (TTS) system, but can not be well learned from the limited training TTS dataset just by virtue of the nowadays encoder structures. As large scale pre-trained text representation develops, bidirectional encoder representations from transformers (BERT) has been proven to embody text-context semantic information and applied to TTS as additional input. However BERT can not explicitly associate semantic tokens from point of dependency relations in a sentence. In this paper, to enhance expressiveness, we propose a semantic representation learning method based on graph neural network, considering dependency relations of a sentence. Dependency graph of input text is composed of edges from dependency tree structure considering both the forward and the reverse directions. Semantic representations are then extracted at word level by the relational gated graph network (RGGN) fed with features from BERT as nodes input. Upsampled semantic representations and character-level embeddings are concatenated to serve as the encoder input of Tacotron-2. Experimental results show that our proposed method outperforms the baseline using vanilla BERT features both in LJSpeech and Blizzard Challenge 2013 datasets, and semantic representations learned from the reverse direction are more effective for enhancing expressiveness.
INADVERT: An Interactive and Adaptive Counterdeception Platform for Attention Enhancement and Phishing Prevention
Jun 13, 2021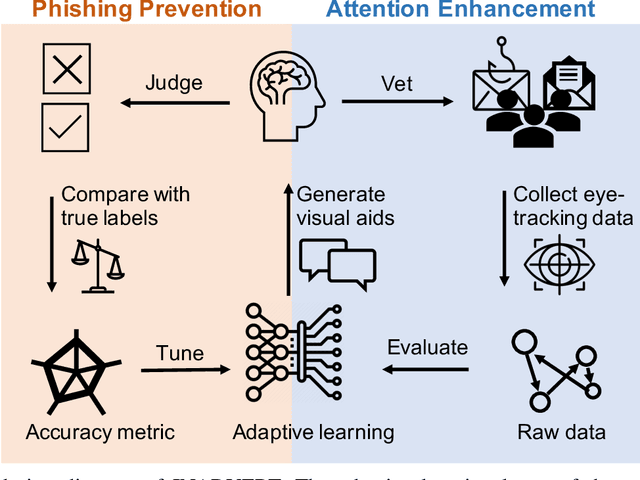

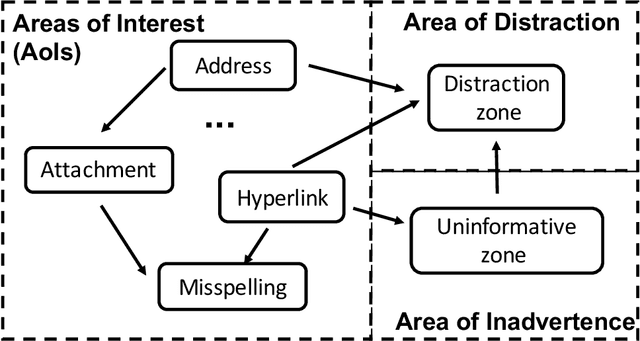
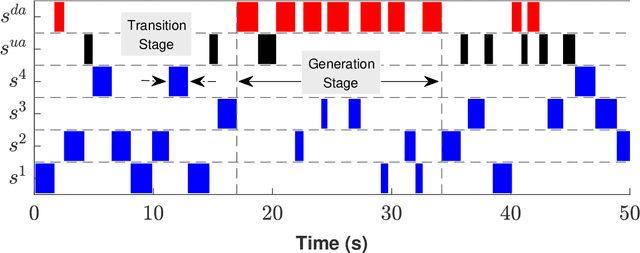
Deceptive attacks exploiting the innate and the acquired vulnerabilities of human users have posed severe threats to information and infrastructure security. This work proposes INADVERT, a systematic solution that generates interactive visual aids in real-time to prevent users from inadvertence and counter visual-deception attacks. Based on the eye-tracking outcomes and proper data compression, the INADVERT platform automatically adapts the visual aids to the user's varying attention status captured by the gaze location and duration. We extract system-level metrics to evaluate the user's average attention level and characterize the magnitude and frequency of the user's mind-wandering behaviors. These metrics contribute to an adaptive enhancement of the user's attention through reinforcement learning. To determine the optimal hyper-parameters in the attention enhancement mechanism, we develop an algorithm based on Bayesian optimization to efficiently update the design of the INADVERT platform and maximize the accuracy of the users' phishing recognition.
Characterizing Residential Load Patterns by Household Demographic and Socioeconomic Factors
Jun 04, 2021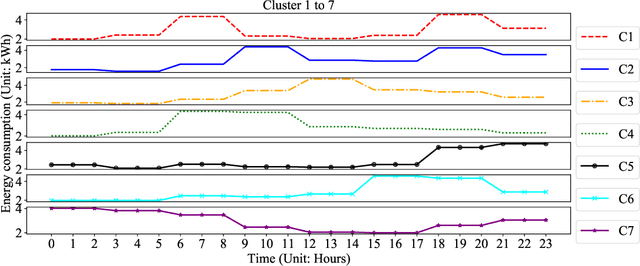
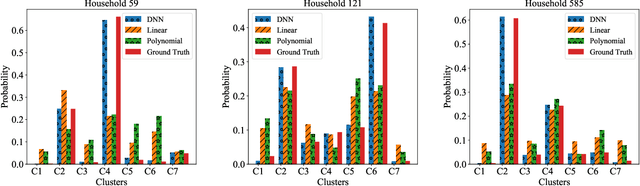
The wide adoption of smart meters makes residential load data available and thus improves the understanding of the energy consumption behavior. Many existing studies have focused on smart-meter data analysis, but the drivers of energy consumption behaviors are not well understood. This paper aims to characterize and estimate users' load patterns based on their demographic and socioeconomic information. We adopt the symbolic aggregate approximation (SAX) method to process the load data and use the K-Means method to extract key load patterns. We develop a deep neural network (DNN) to analyze the relationship between users' load patterns and their demographic and socioeconomic features. Using real-world load data, we validate our framework and demonstrate the connections between load patterns and household demographic and socioeconomic features. We also take two regression models as benchmarks for comparisons.