 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Conversational Machine Reading Comprehension for Vietnamese Healthcare Texts
May 21, 2021
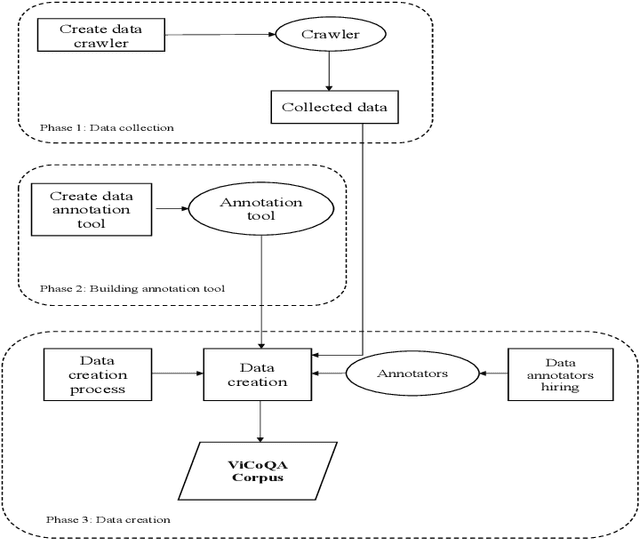
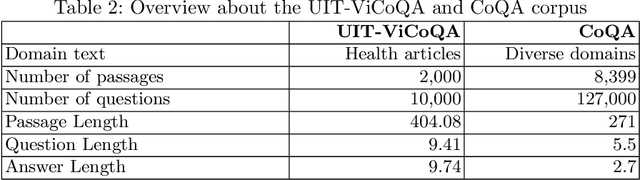
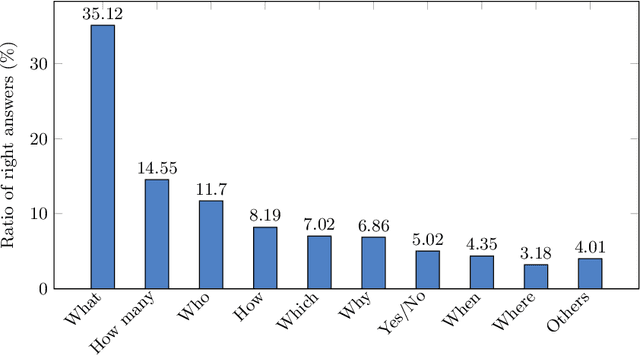

Machine reading comprehension (MRC) is a sub-field in natural language processing that aims to help computers understand unstructured texts and then answer questions related to them. In practice, conversation is an essential way to communicate and transfer information. To help machines understand conversation texts, we present UIT-ViCoQA - a new corpus for conversational machine reading comprehension in the Vietnamese language. This corpus consists of 10,000 questions with answers to over 2,000 conversations about health news articles. Then, we evaluate several baseline approaches for conversational machine comprehension on the UIT-ViCoQA corpus. The best model obtains an F1 score of 45.27%, which is 30.91 points behind human performance (76.18%), indicating that there is ample room for improvement.
Dependency Parsing based Semantic Representation Learning with Graph Neural Network for Enhancing Expressiveness of Text-to-Speech
Apr 20, 2021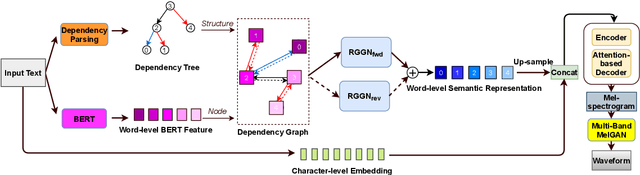

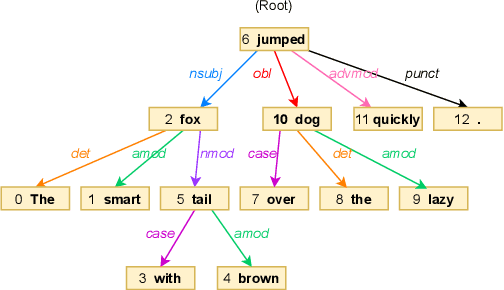
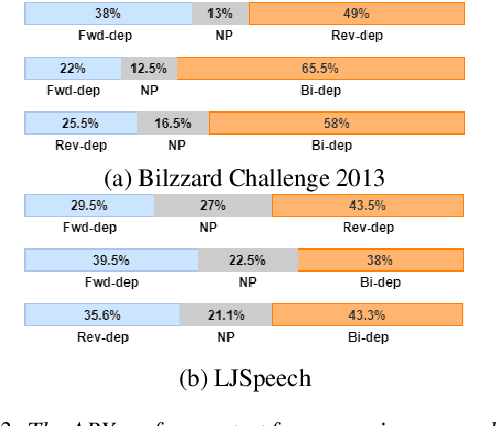
Semantic information of a sentence is crucial for improving the expressiveness of a text-to-speech (TTS) system, but can not be well learned from the limited training TTS dataset just by virtue of the nowadays encoder structures. As large scale pre-trained text representation develops, bidirectional encoder representations from transformers (BERT) has been proven to embody text-context semantic information and applied to TTS as additional input. However BERT can not explicitly associate semantic tokens from point of dependency relations in a sentence. In this paper, to enhance expressiveness, we propose a semantic representation learning method based on graph neural network, considering dependency relations of a sentence. Dependency graph of input text is composed of edges from dependency tree structure considering both the forward and the reverse directions. Semantic representations are then extracted at word level by the relational gated graph network (RGGN) fed with features from BERT as nodes input. Upsampled semantic representations and character-level embeddings are concatenated to serve as the encoder input of Tacotron-2. Experimental results show that our proposed method outperforms the baseline using vanilla BERT features both in LJSpeech and Blizzard Challenge 2013 datasets, and semantic representations learned from the reverse direction are more effective for enhancing expressiveness.
Physics-Informed Deep Reversible Regression Model for Temperature Field Reconstruction of Heat-Source Systems
Jul 05, 2021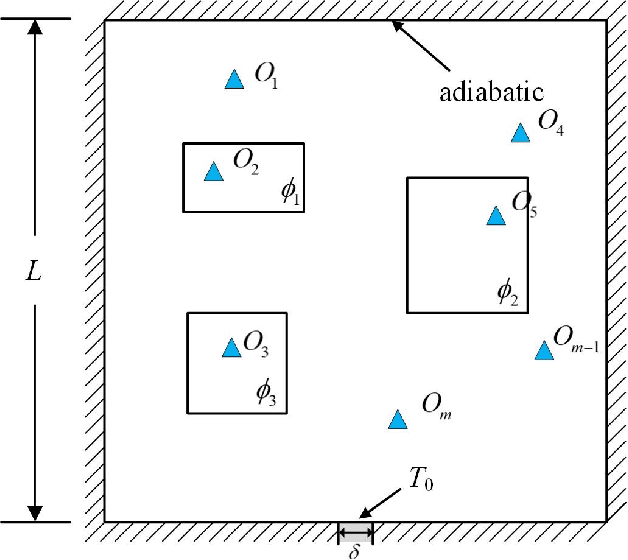
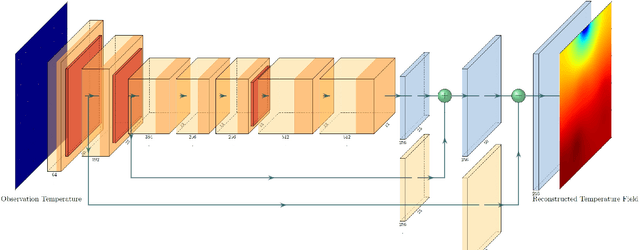
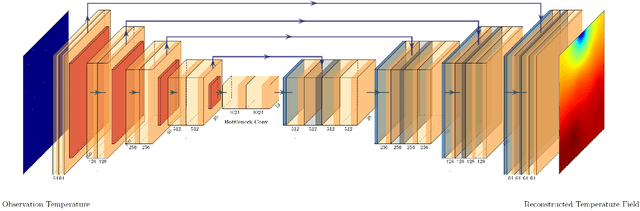
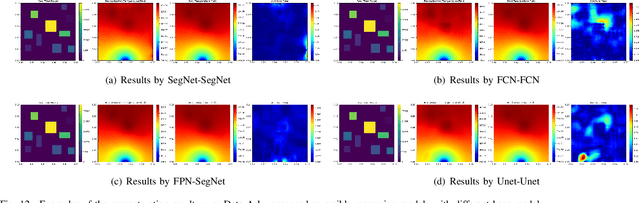
Temperature monitoring during the life time of heat source components in engineering systems becomes essential to guarantee the normal work and the working life of these components. However, prior methods, which mainly use the interpolate estimation to reconstruct the temperature field from limited monitoring points, require large amounts of temperature tensors for an accurate estimation. This may decrease the availability and reliability of the system and sharply increase the monitoring cost. To solve this problem, this work develops a novel physics-informed deep reversible regression models for temperature field reconstruction of heat-source systems (TFR-HSS), which can better reconstruct the temperature field with limited monitoring points unsupervisedly. First, we define the TFR-HSS task mathematically, and numerically model the task, and hence transform the task as an image-to-image regression problem. Then this work develops the deep reversible regression model which can better learn the physical information, especially over the boundary. Finally, considering the physical characteristics of heat conduction as well as the boundary conditions, this work proposes the physics-informed reconstruction loss including four training losses and jointly learns the deep surrogate model with these losses unsupervisedly. Experimental studies have conducted over typical two-dimensional heat-source systems to demonstrate the effectiveness of the proposed method.
JS Fake Chorales: a Synthetic Dataset of Polyphonic Music with Human Annotation
Jul 21, 2021
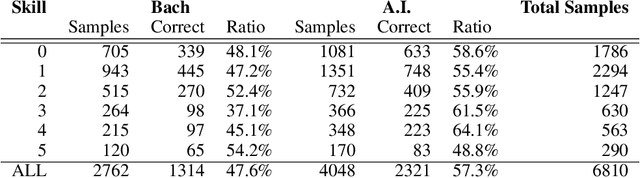
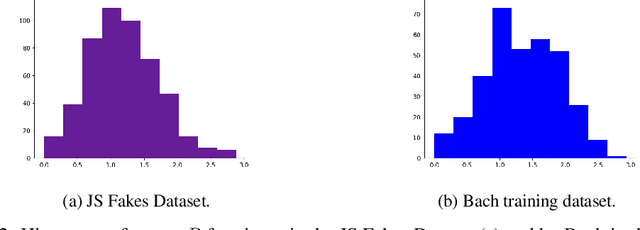
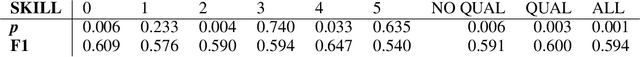
High quality datasets for learning-based modelling of polyphonic symbolic music remain less readily-accessible at scale than in other domains, such as language modelling or image classification. In particular, datasets which contain information revealing insights about human responses to the given music samples are rare. The issue of scale persists as a general hindrance towards breakthroughs in the field, while the lack of listener evaluation is especially relevant to the generative modelling problem-space, where clear objective metrics correlating strongly with qualitative success remain elusive. We propose the JS Fake Chorales, a dataset of 500 pieces generated by a new learning-based algorithm, provided in MIDI form. We take consecutive outputs from the algorithm and avoid cherry-picking in order to validate the potential to further scale this dataset on-demand. We conduct an online experiment for human evaluation, designed to be as fair to the listener as possible, and find that respondents were on average only 7\% better than random guessing at distinguishing JS Fake Chorales from real chorales composed by JS Bach. Furthermore, we make anonymised data collected from experiments available along with the MIDI samples, such as the respondents' musical experience and how long they took to submit their response for each sample. Finally, we conduct ablation studies to demonstrate the effectiveness of using the synthetic pieces for research in polyphonic music modelling, and find that we can improve on state-of-the-art validation set loss for the canonical JSB Chorales dataset, using a known algorithm, by simply augmenting the training set with the JS Fake Chorales.
On the Importance of Subword Information for Morphological Tasks in Truly Low-Resource Languages
Sep 26, 2019
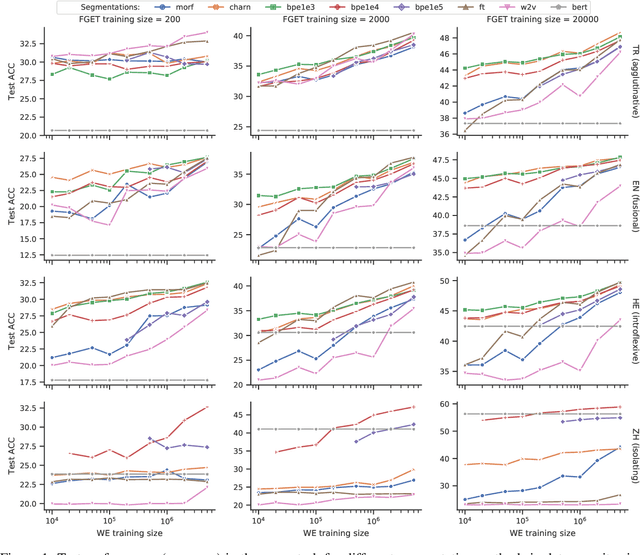
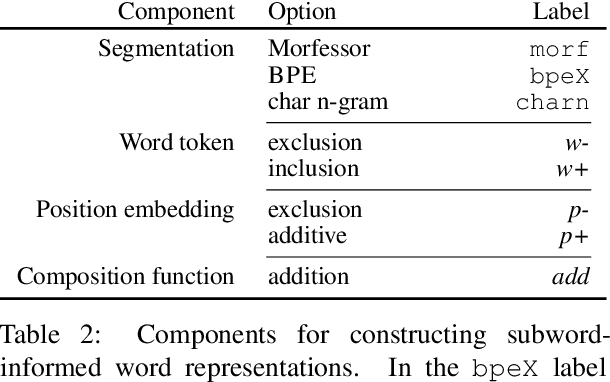
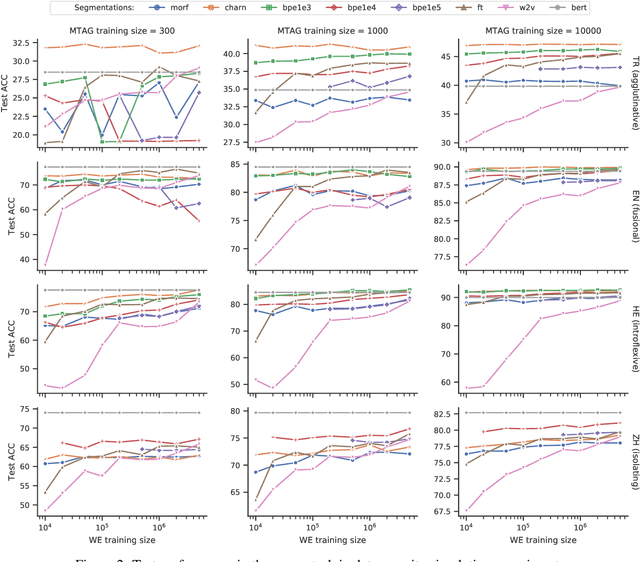
Recent work has validated the importance of subword information for word representation learning. Since subwords increase parameter sharing ability in neural models, their value should be even more pronounced in low-data regimes. In this work, we therefore provide a comprehensive analysis focused on the usefulness of subwords for word representation learning in truly low-resource scenarios and for three representative morphological tasks: fine-grained entity typing, morphological tagging, and named entity recognition. We conduct a systematic study that spans several dimensions of comparison: 1) type of data scarcity which can stem from the lack of task-specific training data, or even from the lack of unannotated data required to train word embeddings, or both; 2) language type by working with a sample of 16 typologically diverse languages including some truly low-resource ones (e.g. Rusyn, Buryat, and Zulu); 3) the choice of the subword-informed word representation method. Our main results show that subword-informed models are universally useful across all language types, with large gains over subword-agnostic embeddings. They also suggest that the effective use of subwords largely depends on the language (type) and the task at hand, as well as on the amount of available data for training the embeddings and task-based models, where having sufficient in-task data is a more critical requirement.
Subsentence Extraction from Text Using Coverage-Based Deep Learning Language Models
Apr 20, 2021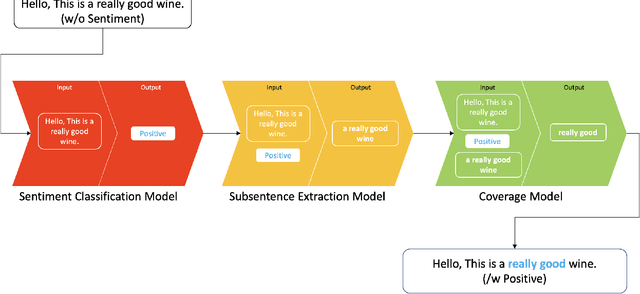
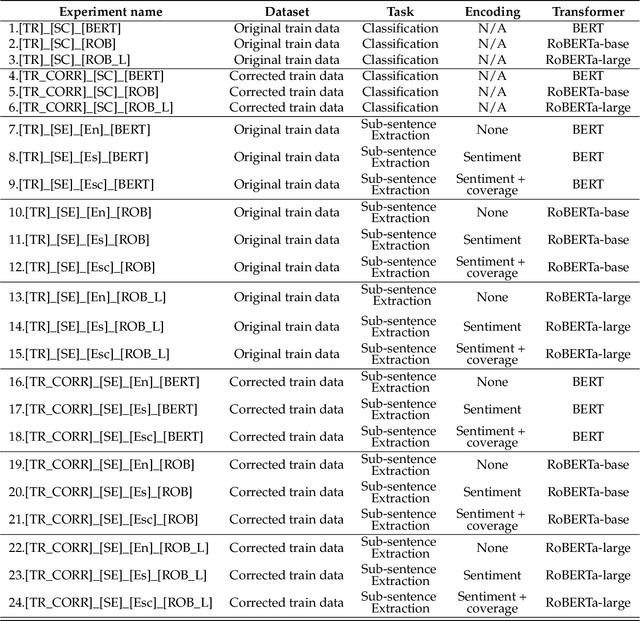
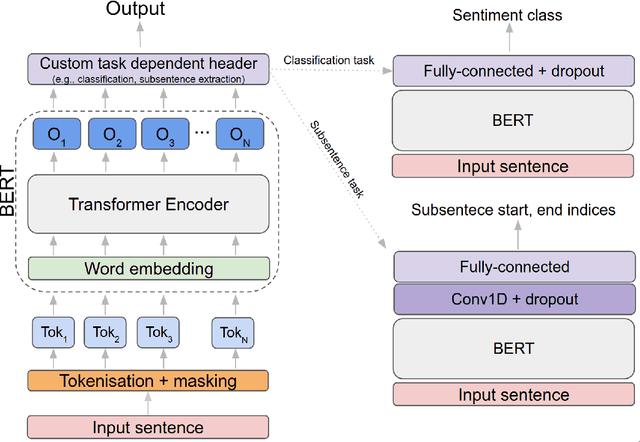
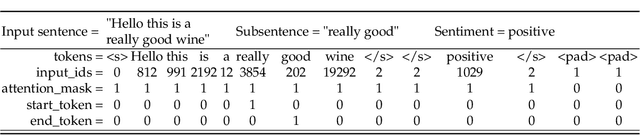
Sentiment prediction remains a challenging and unresolved task in various research fields, including psychology, neuroscience, and computer science. This stems from its high degree of subjectivity and limited input sources that can effectively capture the actual sentiment. This can be even more challenging with only text-based input. Meanwhile, the rise of deep learning and an unprecedented large volume of data have paved the way for artificial intelligence to perform impressively accurate predictions or even human-level reasoning. Drawing inspiration from this, we propose a coverage-based sentiment and subsentence extraction system that estimates a span of input text and recursively feeds this information back to the networks. The predicted subsentence consists of auxiliary information expressing a sentiment. This is an important building block for enabling vivid and epic sentiment delivery (within the scope of this paper) and for other natural language processing tasks such as text summarisation and Q&A. Our approach outperforms the state-of-the-art approaches by a large margin in subsentence prediction (i.e., Average Jaccard scores from 0.72 to 0.89). For the evaluation, we designed rigorous experiments consisting of 24 ablation studies. Finally, our learned lessons are returned to the community by sharing software packages and a public dataset that can reproduce the results presented in this paper.
* 27 pages, 16 figures
Jittering Effects Analysis and Beam Training Design for UAV Millimeter Wave Communications
Apr 13, 2021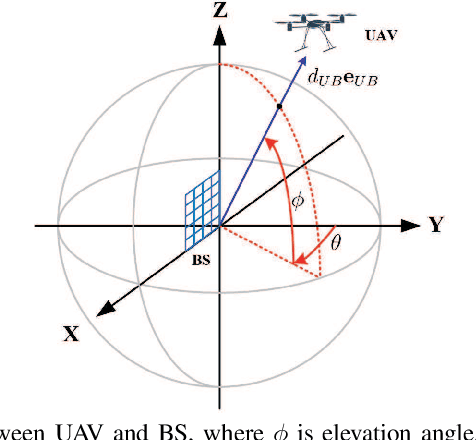
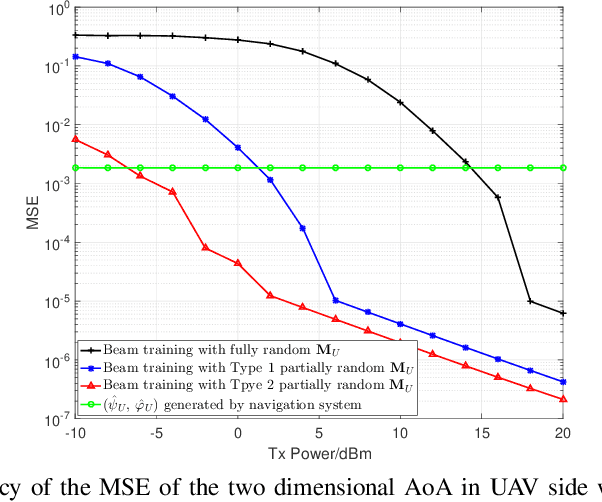
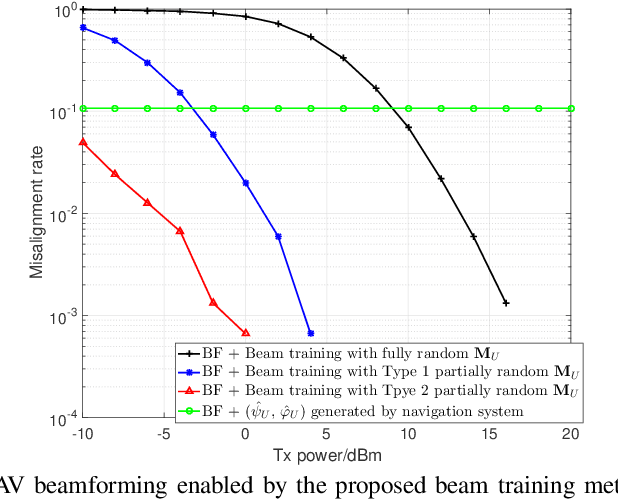
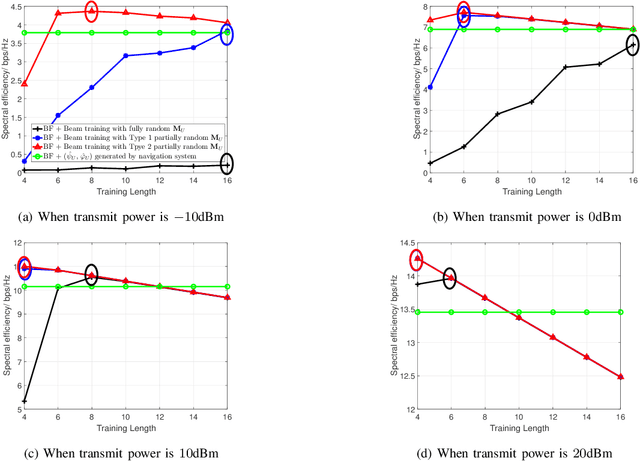
Jittering effects significantly degrade the performance of UAV communications especially in millimeter-wave (mmWave) band. To investigate and mitigate the impacts of UAV jitter to mmWave communications, we firstly model UAV mmWave channel based on the geometric relationship between element antennas of the uniform planar arrays (UPAs) in receiver side and transmitter side, and we incorporate the jittering effects to our channel model through extracting the relationship between UAV attitude & position and angle of arrival (AoA) & angle of departure (AoD) of the UPAs. Then, based on the extracted relationship, we propose to utilize UAV navigation information to obtain a rough estimation of AoA and AoD, and we also analyze the impact of AoA and AoD estimation error to UAV beamforming. Finally, we propose a direction-constrained beam training scheme to refine the AoA/AoD estimation. Particularly, we construct a partially random sensing matrix to measure the channel within a narrow angle range that is centered at the aforementioned rough estimate of AoA/AoD. Numerical results show that our proposed UAV beam training scheme with navigation information is able to fast and accurately estimate the AoA/AoD fluctuation caused by UAV jitter.
ESAI: Efficient Split Artificial Intelligence via Early Exiting Using Neural Architecture Search
Jun 21, 2021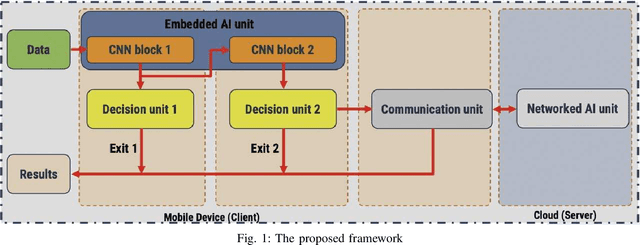
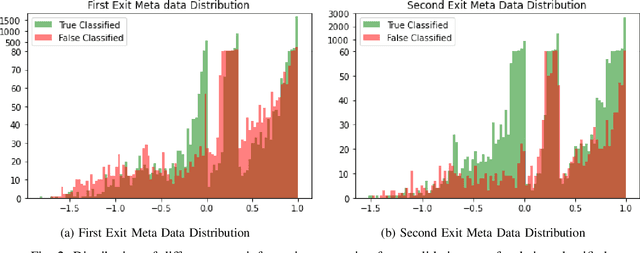
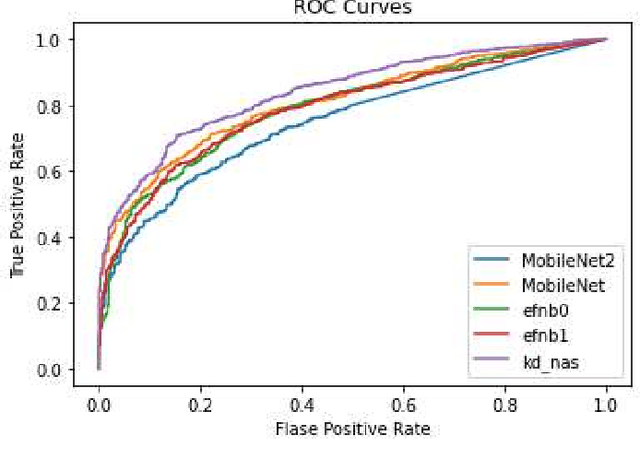
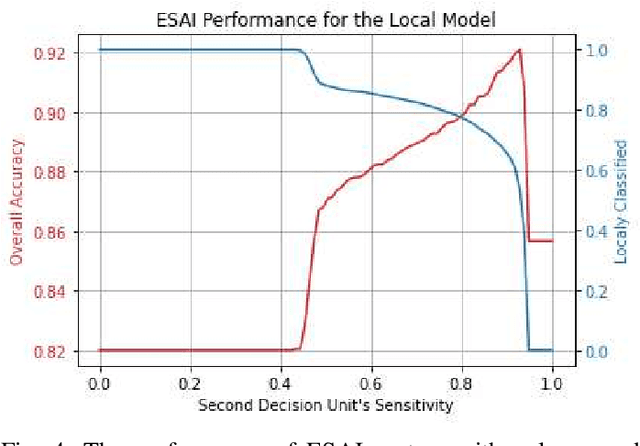
Recently, deep neural networks have been outperforming conventional machine learning algorithms in many computer vision-related tasks. However, it is not computationally acceptable to implement these models on mobile and IoT devices and the majority of devices are harnessing the cloud computing methodology in which outstanding deep learning models are responsible for analyzing the data on the server. This can bring the communication cost for the devices and make the whole system useless in those times where the communication is not available. In this paper, a new framework for deploying on IoT devices has been proposed which can take advantage of both the cloud and the on-device models by extracting the meta-information from each sample's classification result and evaluating the classification's performance for the necessity of sending the sample to the server. Experimental results show that only 40 percent of the test data should be sent to the server using this technique and the overall accuracy of the framework is 92 percent which improves the accuracy of both client and server models.
Siamese Labels Auxiliary Network(SiLaNet)
Feb 27, 2021
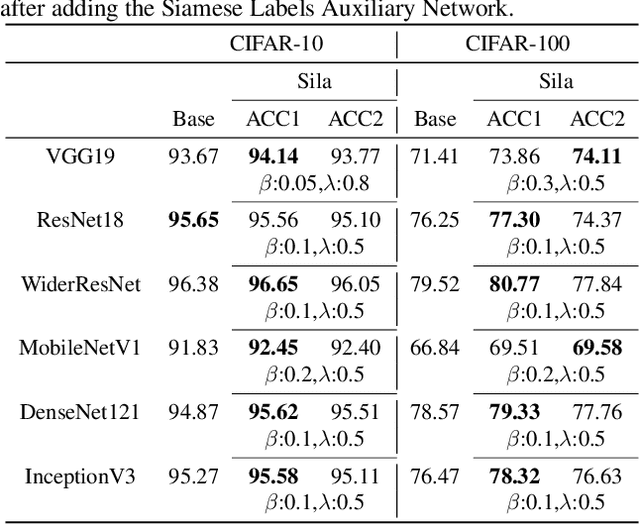
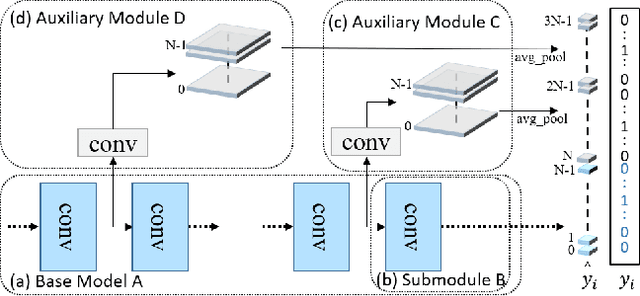
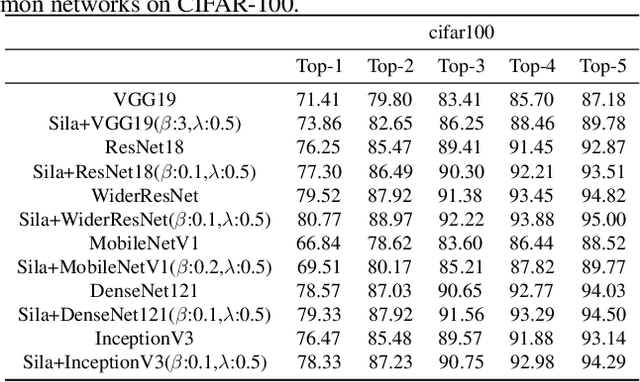
Auxiliary information attracts more and more attention in the area of machine learning. Attempts so far to include such auxiliary information in state-of-the-art learning process have often been based on simply appending these auxiliary features to the data level or feature level. In this paper, we intend to propose a novel training method with new options and architectures. Siamese labels, which were used in the training phase as auxiliary modules. While in the testing phase, the auxiliary module should be removed. Siamese label module makes it easier to train and improves the performance in testing process. In general, the main contributions can be summarized as, 1) Siamese Labels are firstly proposed as auxiliary information to improve the learning efficiency; 2) We establish a new architecture, Siamese Labels Auxiliary Network (SilaNet), which is to assist the training of the model; 3) Siamese Labels Auxiliary Network is applied to compress the model parameters by 50% and ensure the high accuracy at the same time. For the purpose of comparison, we tested the network on CIFAR-10 and CIFAR100 using some common models. The proposed SilaNet performs excellent efficiency both on the accuracy and robustness.
CUDA-GR: Controllable Unsupervised Domain Adaptation for Gaze Redirection
Jun 21, 2021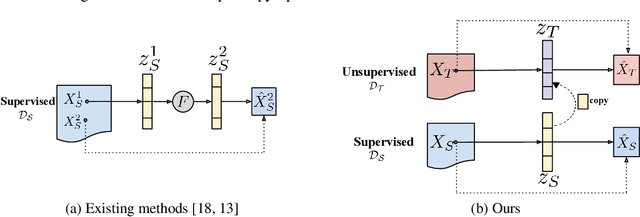
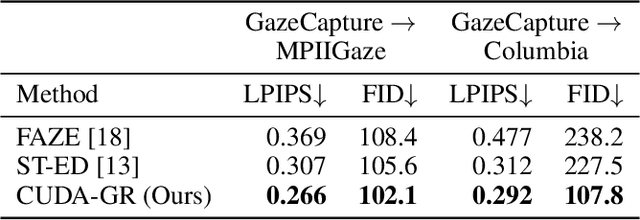
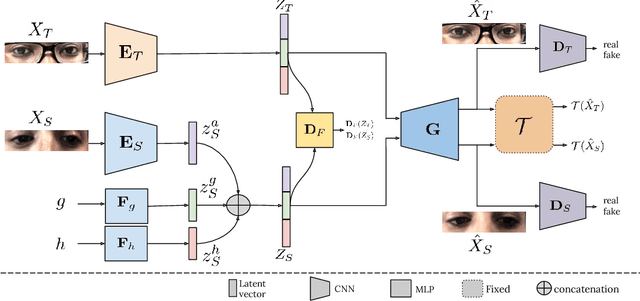

The aim of gaze redirection is to manipulate the gaze in an image to the desired direction. However, existing methods are inadequate in generating perceptually reasonable images. Advancement in generative adversarial networks has shown excellent results in generating photo-realistic images. Though, they still lack the ability to provide finer control over different image attributes. To enable such fine-tuned control, one needs to obtain ground truth annotations for the training data which can be very expensive. In this paper, we propose an unsupervised domain adaptation framework, called CUDA-GR, that learns to disentangle gaze representations from the labeled source domain and transfers them to an unlabeled target domain. Our method enables fine-grained control over gaze directions while preserving the appearance information of the person. We show that the generated image-labels pairs in the target domain are effective in knowledge transfer and can boost the performance of the downstream tasks. Extensive experiments on the benchmarking datasets show that the proposed method can outperform state-of-the-art techniques in both quantitative and qualitative evaluation.