 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
UVIP: Model-Free Approach to Evaluate Reinforcement Learning Algorithms
Jun 03, 2021
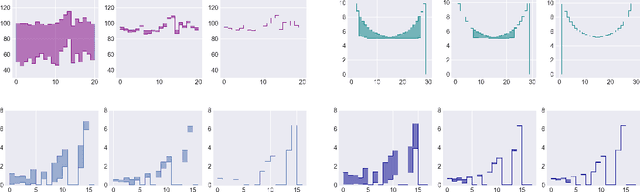
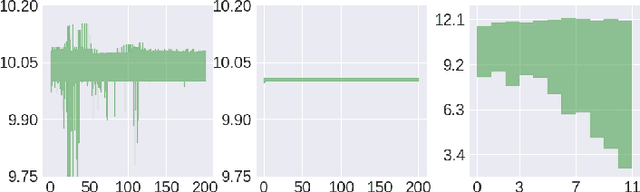
Policy evaluation is an important instrument for the comparison of different algorithms in Reinforcement Learning (RL). Yet even a precise knowledge of the value function $V^{\pi}$ corresponding to a policy $\pi$ does not provide reliable information on how far is the policy $\pi$ from the optimal one. We present a novel model-free upper value iteration procedure $({\sf UVIP})$ that allows us to estimate the suboptimality gap $V^{\star}(x) - V^{\pi}(x)$ from above and to construct confidence intervals for $V^\star$. Our approach relies on upper bounds to the solution of the Bellman optimality equation via martingale approach. We provide theoretical guarantees for ${\sf UVIP}$ under general assumptions and illustrate its performance on a number of benchmark RL problems.
Semantic-WER: A Unified Metric for the Evaluation of ASR Transcript for End Usability
Jun 03, 2021

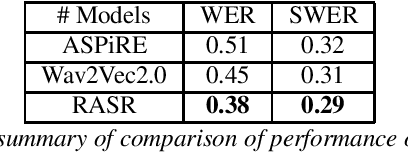
Recent advances in supervised, semi-supervised and self-supervised deep learning algorithms have shown significant improvement in the performance of automatic speech recognition(ASR) systems. The state-of-the-art systems have achieved a word error rate (WER) less than 5%. However, in the past, researchers have argued the non-suitability of the WER metric for the evaluation of ASR systems for downstream tasks such as spoken language understanding (SLU) and information retrieval. The reason is that the WER works at the surface level and does not include any syntactic and semantic knowledge.The current work proposes Semantic-WER (SWER), a metric to evaluate the ASR transcripts for downstream applications in general. The SWER can be easily customized for any down-stream task.
Provably Secure Generative Linguistic Steganography
Jun 03, 2021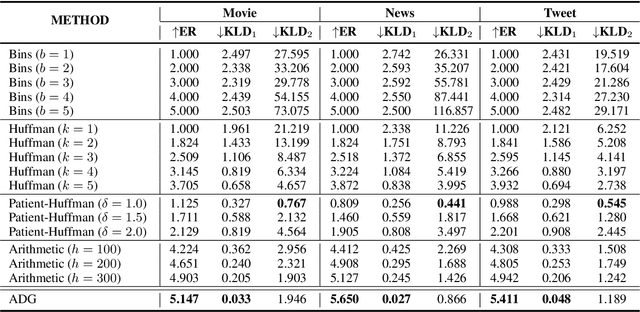
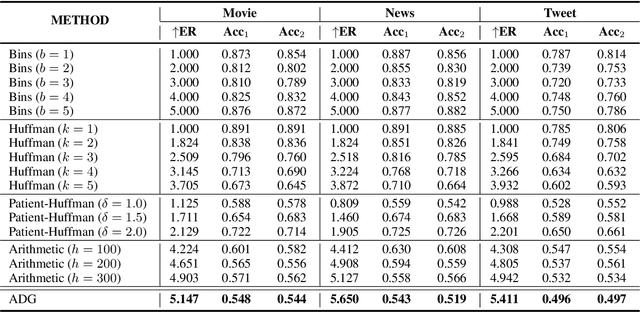
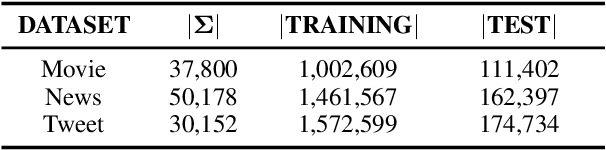
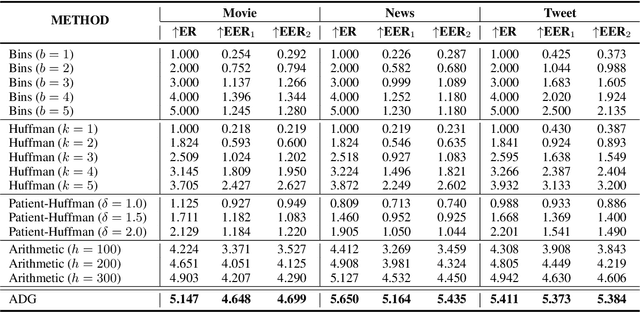
Generative linguistic steganography mainly utilized language models and applied steganographic sampling (stegosampling) to generate high-security steganographic text (stegotext). However, previous methods generally lead to statistical differences between the conditional probability distributions of stegotext and natural text, which brings about security risks. In this paper, to further ensure security, we present a novel provably secure generative linguistic steganographic method ADG, which recursively embeds secret information by Adaptive Dynamic Grouping of tokens according to their probability given by an off-the-shelf language model. We not only prove the security of ADG mathematically, but also conduct extensive experiments on three public corpora to further verify its imperceptibility. The experimental results reveal that the proposed method is able to generate stegotext with nearly perfect security.
Interaction Information for Causal Inference: The Case of Directed Triangle
Jan 30, 2017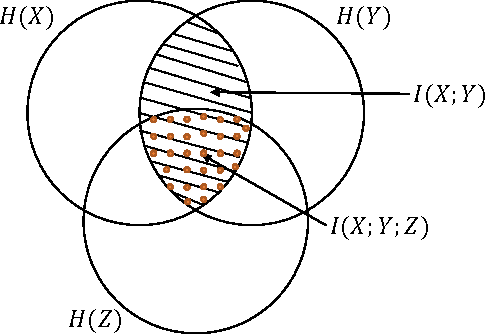
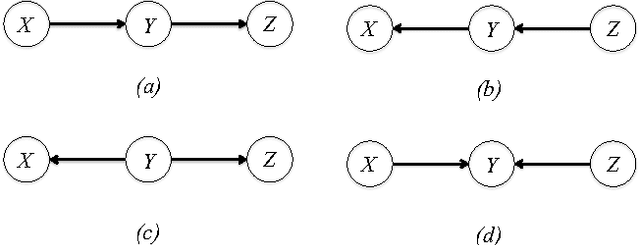
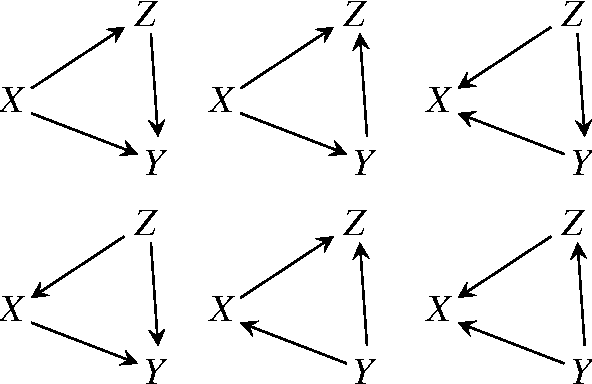
Interaction information is one of the multivariate generalizations of mutual information, which expresses the amount information shared among a set of variables, beyond the information, which is shared in any proper subset of those variables. Unlike (conditional) mutual information, which is always non-negative, interaction information can be negative. We utilize this property to find the direction of causal influences among variables in a triangle topology under some mild assumptions.
Deep Learning-Based Active User Detection for Grant-free SCMA Systems
Jun 21, 2021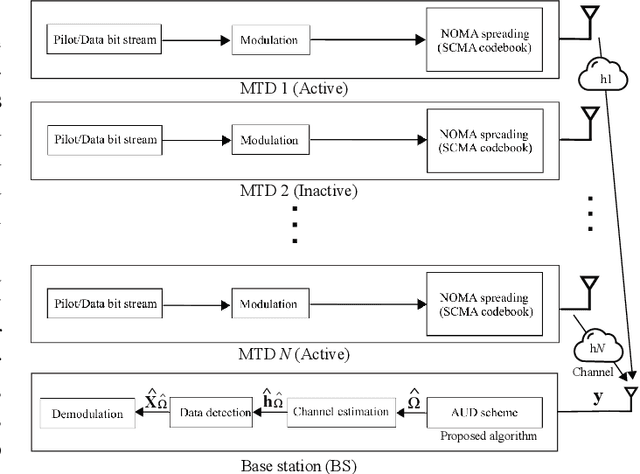
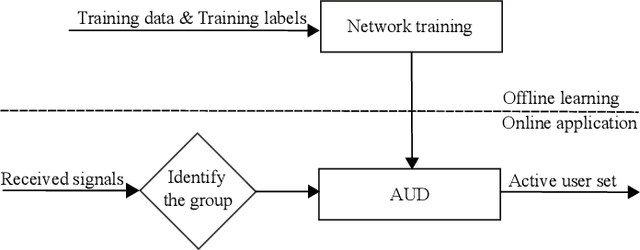

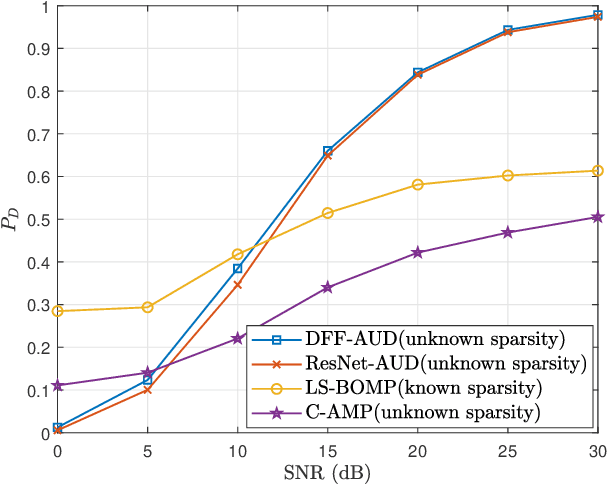
Grant-free random access and uplink non-orthogonal multiple access (NOMA) have been introduced to reduce transmission latency and signaling overhead in massive machine-type communication (mMTC). In this paper, we propose two novel group-based deep neural network active user detection (AUD) schemes for the grant-free sparse code multiple access (SCMA) system in mMTC uplink framework. The proposed AUD schemes learn the nonlinear mapping, i.e., multi-dimensional codebook structure and the channel characteristic. This is accomplished through the received signal which incorporates the sparse structure of device activity with the training dataset. Moreover, the offline pre-trained model is able to detect the active devices without any channel state information and prior knowledge of the device sparsity level. Simulation results show that with several active devices, the proposed schemes obtain more than twice the probability of detection compared to the conventional AUD schemes over the signal to noise ratio range of interest.
Lost in Interpreting: Speech Translation from Source or Interpreter?
Jun 17, 2021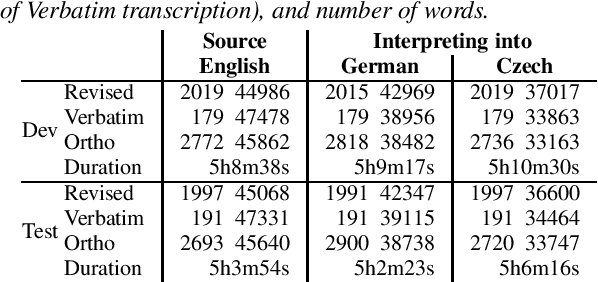
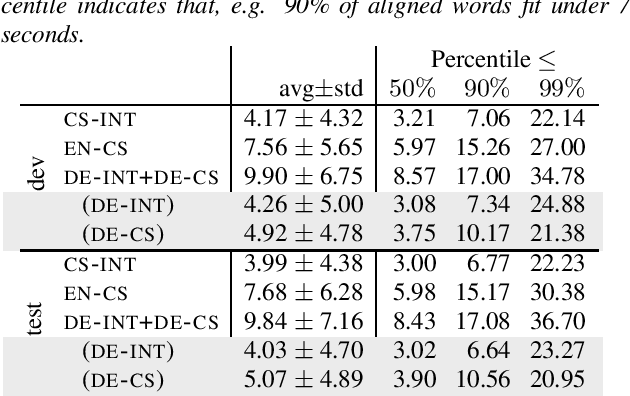

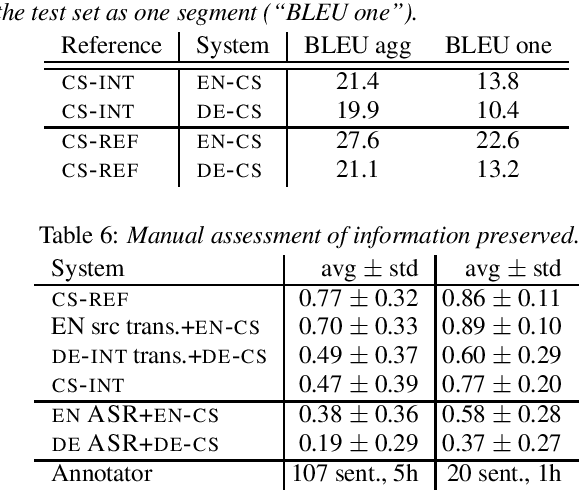
Interpreters facilitate multi-lingual meetings but the affordable set of languages is often smaller than what is needed. Automatic simultaneous speech translation can extend the set of provided languages. We investigate if such an automatic system should rather follow the original speaker, or an interpreter to achieve better translation quality at the cost of increased delay. To answer the question, we release Europarl Simultaneous Interpreting Corpus (ESIC), 10 hours of recordings and transcripts of European Parliament speeches in English, with simultaneous interpreting into Czech and German. We evaluate quality and latency of speaker-based and interpreter-based spoken translation systems from English to Czech. We study the differences in implicit simplification and summarization of the human interpreter compared to a machine translation system trained to shorten the output to some extent. Finally, we perform human evaluation to measure information loss of each of these approaches.
Targeted Active Learning for Bayesian Decision-Making
Jun 08, 2021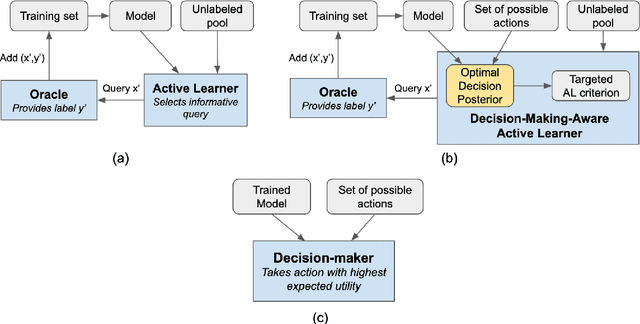
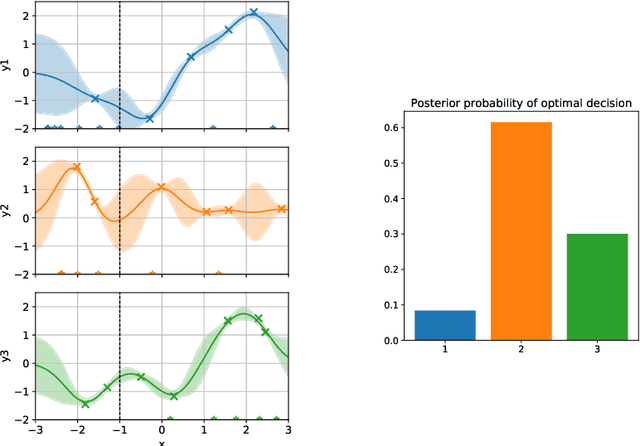
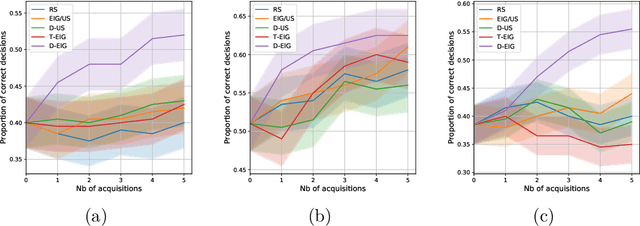
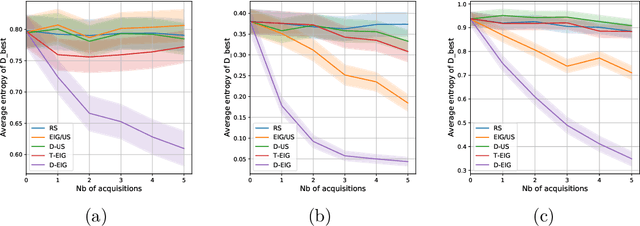
Active learning is usually applied to acquire labels of informative data points in supervised learning, to maximize accuracy in a sample-efficient way. However, maximizing the accuracy is not the end goal when the results are used for decision-making, for example in personalized medicine or economics. We argue that when acquiring samples sequentially, separating learning and decision-making is sub-optimal, and we introduce a novel active learning strategy which takes the down-the-line decision problem into account. Specifically, we introduce a novel active learning criterion which maximizes the expected information gain on the posterior distribution of the optimal decision. We compare our decision-making-aware active learning strategy to existing alternatives on both simulated and real data, and show improved performance in decision-making accuracy.
Channel Estimation for IRS-Assisted Millimeter-Wave MIMO Systems: Sparsity-Inspired Approaches
Jul 24, 2021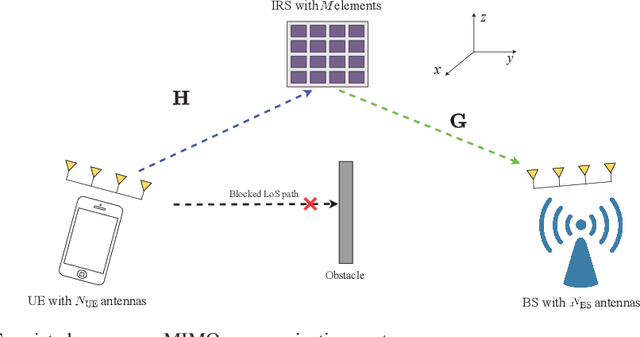
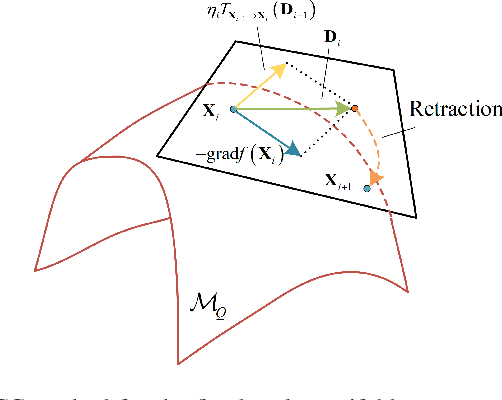
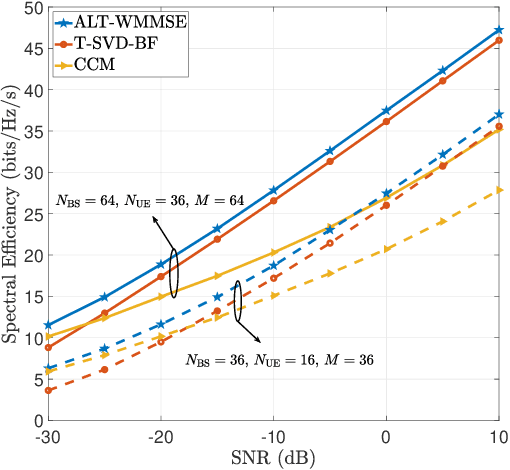
Due to their ability to create favorable line-of-sight (LoS) propagation environments, intelligent reflecting surfaces (IRSs) are regarded as promising enablers for future millimeter-wave (mm-wave) wireless communication. In this paper, we investigate channel estimation for IRS-assisted mm-wave multiple-input multiple-output (MIMO) {\color{black}wireles}s systems. By leveraging the sparsity of mm-wave channels in the angular domain, we formulate the channel estimation problem as an $\ell_1$-norm regularized optimization problem with fixed-rank constraints. To tackle the non-convexity of the formulated problem, an efficient algorithm is proposed by capitalizing on alternating minimization and manifold optimization (MO), which yields a locally optimal solution. To further reduce the computational complexity of the estimation algorithm, we propose a compressive sensing- (CS-) based channel estimation approach. In particular, a three-stage estimation protocol is put forward where the subproblem in each stage can be solved via low-complexity CS methods. Furthermore, based on the acquired channel state information (CSI) of the cascaded channel, we design a passive beamforming algorithm for maximization of the spectral efficiency. Simulation results reveal that the proposed MO-based estimation (MO-EST) and beamforming algorithms significantly outperform two benchmark schemes while the CS-based estimation (CS-EST) algorithm strikes a balance between performance and complexity. In addition, we demonstrate the robustness of the MO-EST algorithm with respect to imperfect knowledge of the sparsity level of the channels, which is crucial for practical implementations.
Mining Customers' Opinions for Online Reputation Generation and Visualization in e-Commerce Platforms
Apr 05, 2021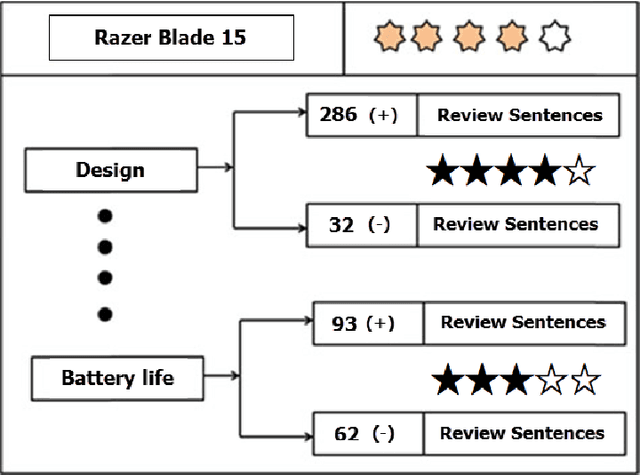
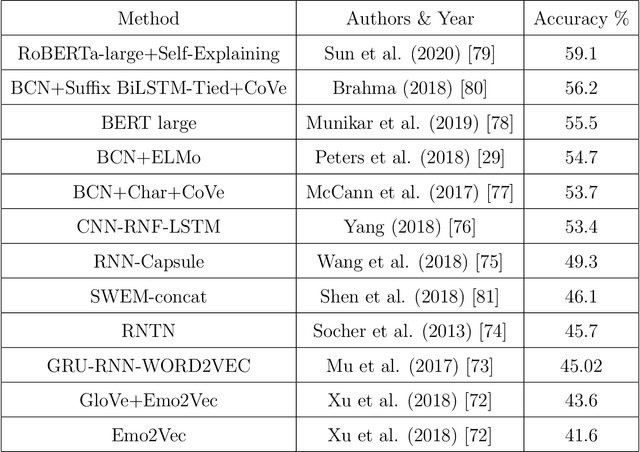

Customer reviews represent a very rich data source from which we can extract very valuable information about different online shopping experiences. The amount of the collected data may be very large especially for trendy items (products, movies, TV shows, hotels, services...), where the number of available customers' opinions could easily surpass thousands. In fact, while a good number of reviews could indeed give a hint about the quality of an item, a potential customer may not have time or effort to read all reviews for the purpose of making an informed decision (buying, renting, booking...). Thus, the need for the right tools and technologies to help in such a task becomes a necessity for the buyer as for the seller. My research goal in this thesis is to develop reputation systems that can automatically provide E-commerce customers with valuable information to support them during their online decision-making process by mining online reviews expressed in natural language.
OpenCoS: Contrastive Semi-supervised Learning for Handling Open-set Unlabeled Data
Jun 29, 2021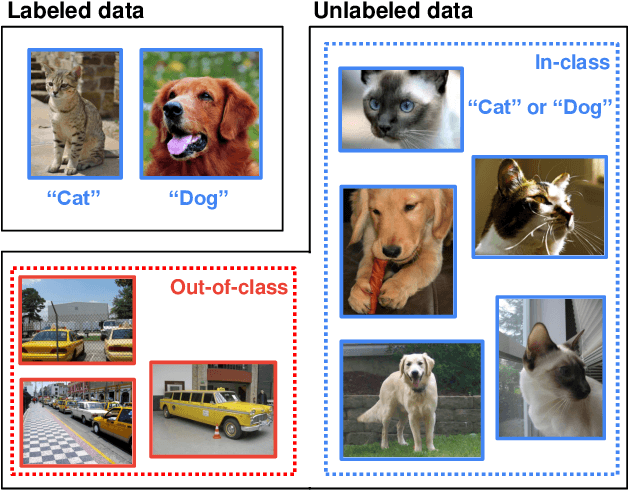
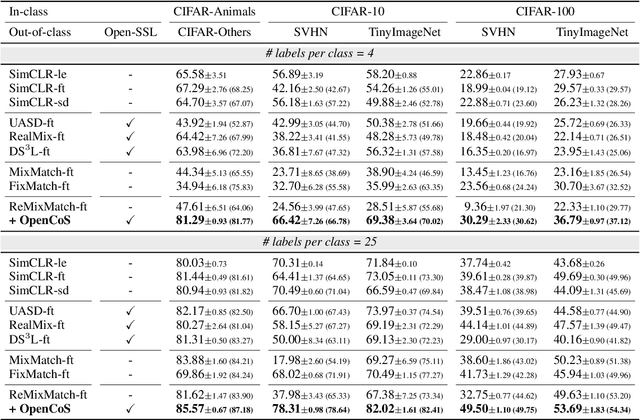
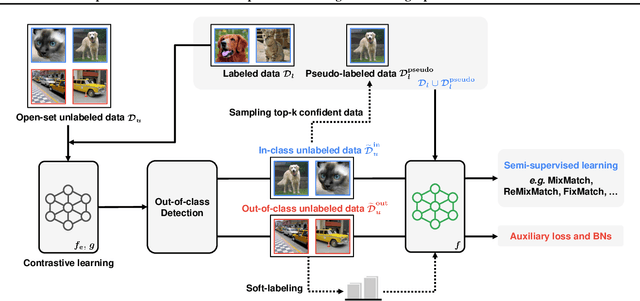
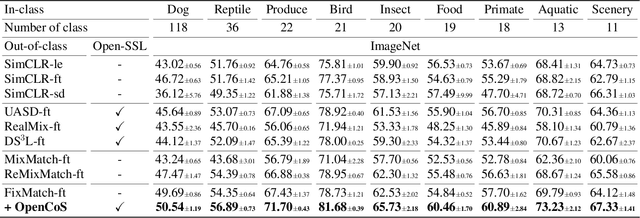
Modern semi-supervised learning methods conventionally assume both labeled and unlabeled data have the same class distribution. However, unlabeled data may include out-of-class samples in practice; those that cannot have one-hot encoded labels from a closed-set of classes in label data, i.e., unlabeled data is an open-set. In this paper, we introduce OpenCoS, a method for handling this realistic semi-supervised learning scenario based on a recent framework of contrastive learning. One of our key findings is that out-of-class samples in the unlabeled dataset can be identified effectively via (unsupervised) contrastive learning. OpenCoS utilizes this information to overcome the failure modes in the existing state-of-the-art semi-supervised methods, e.g., ReMixMatch or FixMatch. It further improves the semi-supervised performance by utilizing soft- and pseudo-labels on open-set unlabeled data, learned from contrastive learning. Our extensive experimental results show the effectiveness of OpenCoS, fixing the state-of-the-art semi-supervised methods to be suitable for diverse scenarios involving open-set unlabeled data.