 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving Neural Sequence Labelling using Additional Linguistic Information
Jul 27, 2018
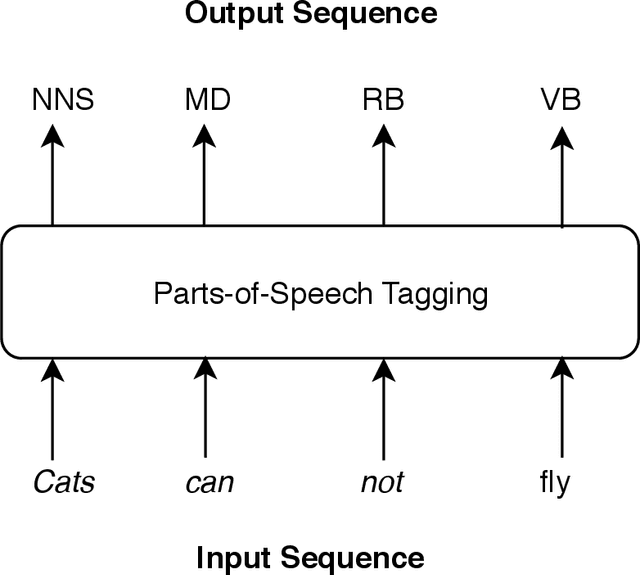
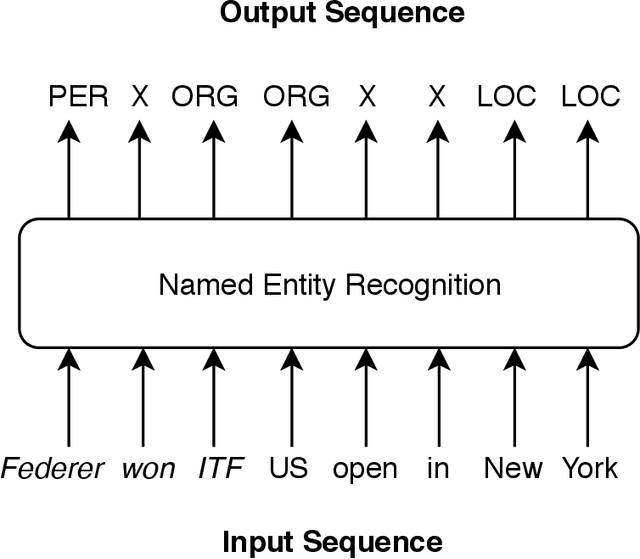
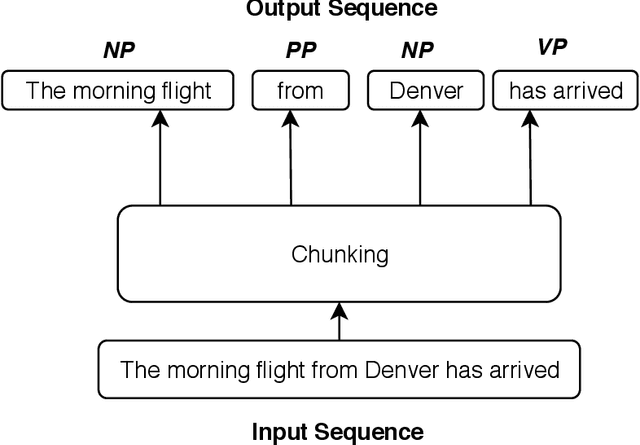
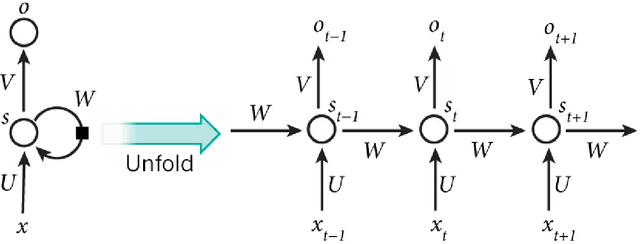
Sequence labelling is the task of assigning categorical labels to a data sequence. In Natural Language Processing, sequence labelling can be applied to various fundamental problems, such as Part of Speech (POS) tagging, Named Entity Recognition (NER), and Chunking. In this study, we propose a method to add various linguistic features to the neural sequence framework to improve sequence labelling. Besides word level knowledge, sense embeddings are added to provide semantic information. Additionally, selective readings of character embeddings are added to capture contextual as well as morphological features for each word in a sentence. Compared to previous methods, these added linguistic features allow us to design a more concise model and perform more efficient training. Our proposed architecture achieves state of the art results on the benchmark datasets of POS, NER, and chunking. Moreover, the convergence rate of our model is significantly better than the previous state of the art models.
Context-Dependent Anomaly Detection for Low Altitude Traffic Surveillance
Apr 14, 2021
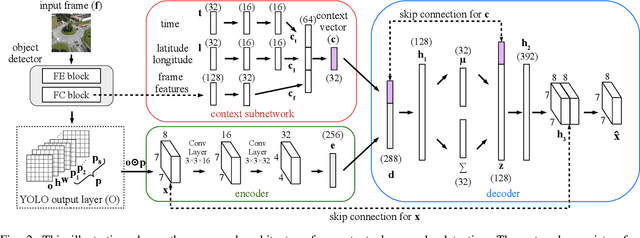
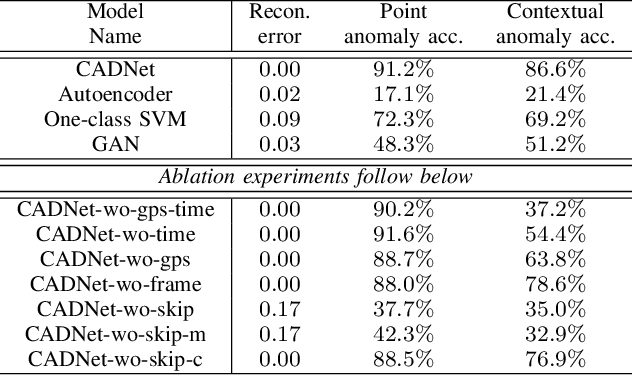
The detection of contextual anomalies is a challenging task for surveillance since an observation can be considered anomalous or normal in a specific environmental context. An unmanned aerial vehicle (UAV) can utilize its aerial monitoring capability and employ multiple sensors to gather contextual information about the environment and perform contextual anomaly detection. In this work, we introduce a deep neural network-based method (CADNet) to find point anomalies (i.e., single instance anomalous data) and contextual anomalies (i.e., context-specific abnormality) in an environment using a UAV. The method is based on a variational autoencoder (VAE) with a context sub-network. The context sub-network extracts contextual information regarding the environment using GPS and time data, then feeds it to the VAE to predict anomalies conditioned on the context. To the best of our knowledge, our method is the first contextual anomaly detection method for UAV-assisted aerial surveillance. We evaluate our method on the AU-AIR dataset in a traffic surveillance scenario. Quantitative comparisons against several baselines demonstrate the superiority of our approach in the anomaly detection tasks. The codes and data will be available at https://bozcani.github.io/cadnet.
Face Sketch Synthesis via Semantic-Driven Generative Adversarial Network
Jun 29, 2021
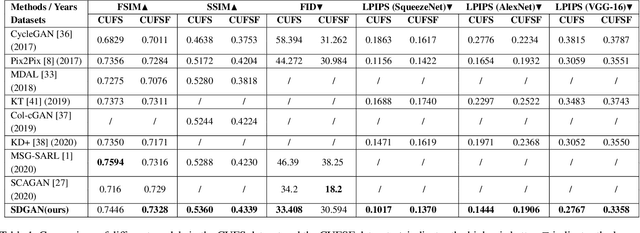
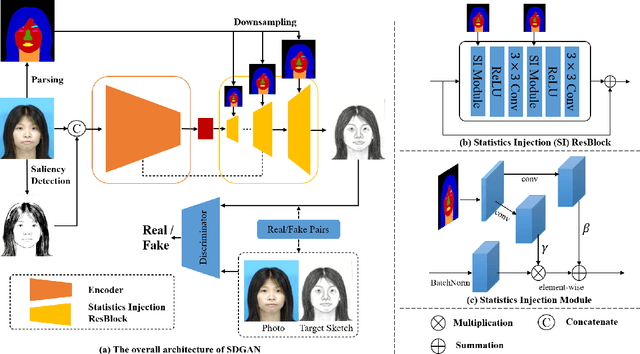
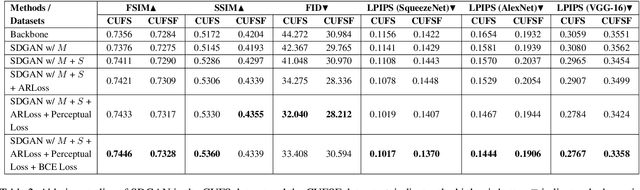
Face sketch synthesis has made significant progress with the development of deep neural networks in these years. The delicate depiction of sketch portraits facilitates a wide range of applications like digital entertainment and law enforcement. However, accurate and realistic face sketch generation is still a challenging task due to the illumination variations and complex backgrounds in the real scenes. To tackle these challenges, we propose a novel Semantic-Driven Generative Adversarial Network (SDGAN) which embeds global structure-level style injection and local class-level knowledge re-weighting. Specifically, we conduct facial saliency detection on the input face photos to provide overall facial texture structure, which could be used as a global type of prior information. In addition, we exploit face parsing layouts as the semantic-level spatial prior to enforce globally structural style injection in the generator of SDGAN. Furthermore, to enhance the realistic effect of the details, we propose a novel Adaptive Re-weighting Loss (ARLoss) which dedicates to balance the contributions of different semantic classes. Experimentally, our extensive experiments on CUFS and CUFSF datasets show that our proposed algorithm achieves state-of-the-art performance.
Federated Myopic Community Detection with One-shot Communication
Jun 14, 2021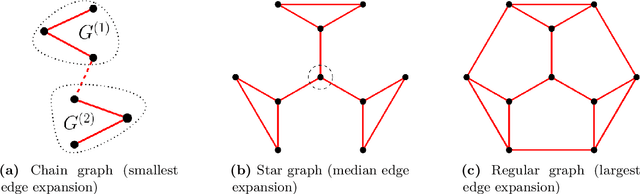
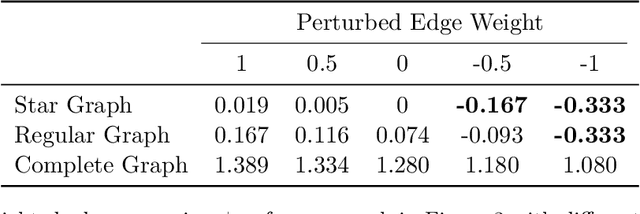
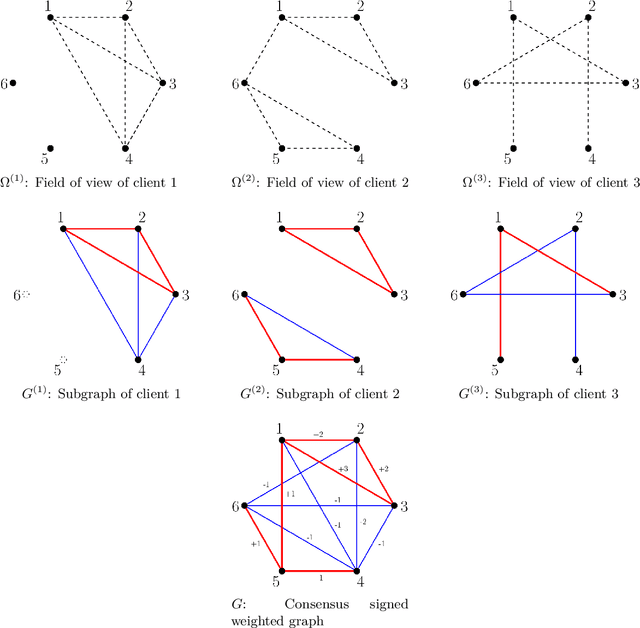
In this paper, we study the problem of recovering the community structure of a network under federated myopic learning. Under this paradigm, we have several clients, each of them having a myopic view, i.e., observing a small subgraph of the network. Each client sends a censored evidence graph to a central server. We provide an efficient algorithm, which computes a consensus signed weighted graph from clients evidence, and recovers the underlying network structure in the central server. We analyze the topological structure conditions of the network, as well as the signal and noise levels of the clients that allow for recovery of the network structure. Our analysis shows that exact recovery is possible and can be achieved in polynomial time. We also provide information-theoretic limits for the central server to recover the network structure from any single client evidence. Finally, as a byproduct of our analysis, we provide a novel Cheeger-type inequality for general signed weighted graphs.
Knowledge Graph Embedding using Graph Convolutional Networks with Relation-Aware Attention
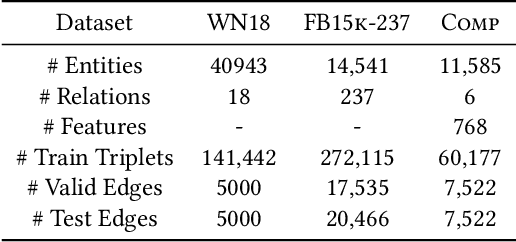
Feb 14, 2021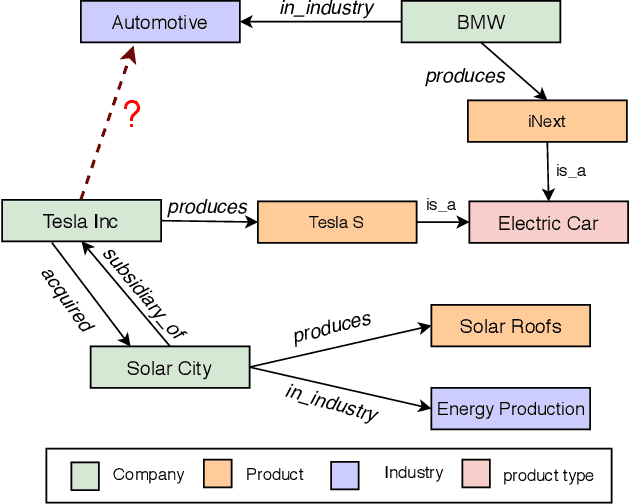
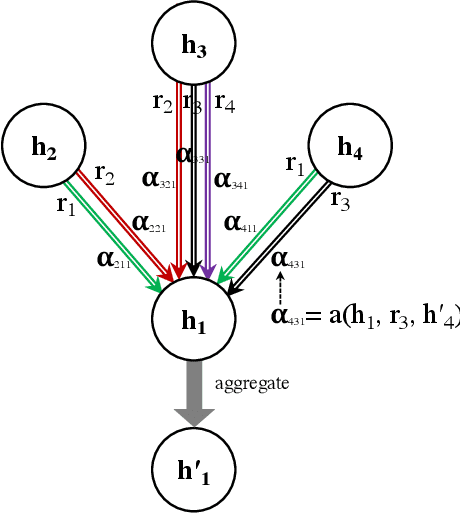
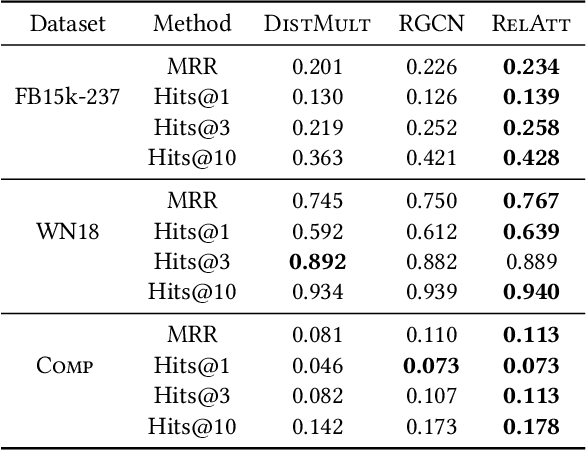
Knowledge graph embedding methods learn embeddings of entities and relations in a low dimensional space which can be used for various downstream machine learning tasks such as link prediction and entity matching. Various graph convolutional network methods have been proposed which use different types of information to learn the features of entities and relations. However, these methods assign the same weight (importance) to the neighbors when aggregating the information, ignoring the role of different relations with the neighboring entities. To this end, we propose a relation-aware graph attention model that leverages relation information to compute different weights to the neighboring nodes for learning embeddings of entities and relations. We evaluate our proposed approach on link prediction and entity matching tasks. Our experimental results on link prediction on three datasets (one proprietary and two public) and results on unsupervised entity matching on one proprietary dataset demonstrate the effectiveness of the relation-aware attention.
Comparing merging behaviors observed in naturalistic data with behaviors generated by a machine learned model
Apr 21, 2021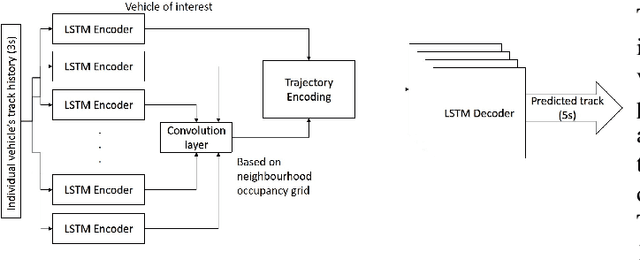
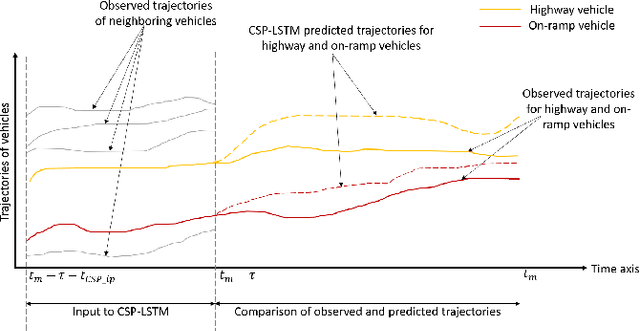
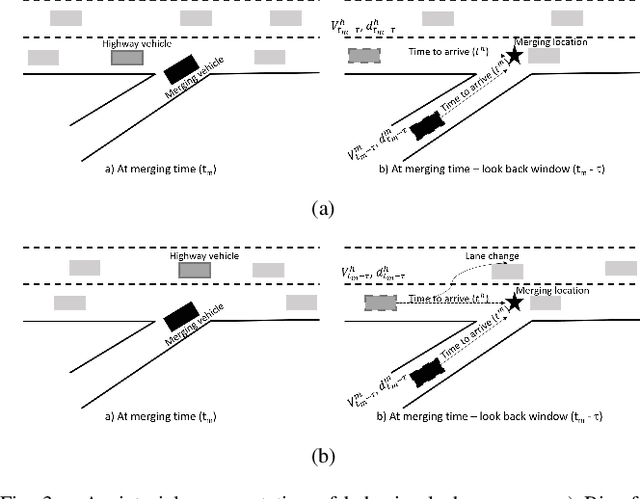
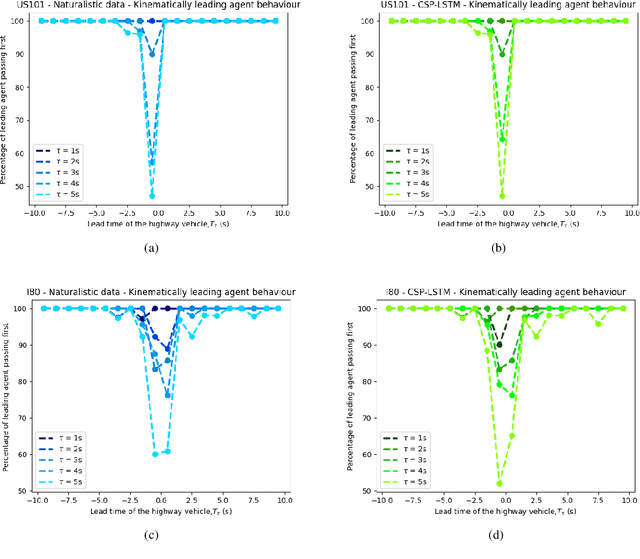
There is quickly growing literature on machine-learned models that predict human driving trajectories in road traffic. These models focus their learning on low-dimensional error metrics, for example average distance between model-generated and observed trajectories. Such metrics permit relative comparison of models, but do not provide clearly interpretable information on how close to human behavior the models actually come, for example in terms of higher-level behavior phenomena that are known to be present in human driving. We study highway driving as an example scenario, and introduce metrics to quantitatively demonstrate the presence, in a naturalistic dataset, of two familiar behavioral phenomena: (1) The kinematics-dependent contest, between on-highway and on-ramp vehicles, of who passes the merging point first. (2) Courtesy lane changes away from the outermost lane, to leave space for a merging vehicle. Applying the exact same metrics to the output of a state-of-the-art machine-learned model, we show that the model is capable of reproducing the former phenomenon, but not the latter. We argue that this type of behavioral analysis provides information that is not available from conventional model-fitting metrics, and that it may be useful to analyze (and possibly fit) models also based on these types of behavioral criteria.
Generic Attention-model Explainability for Interpreting Bi-Modal and Encoder-Decoder Transformers
Mar 29, 2021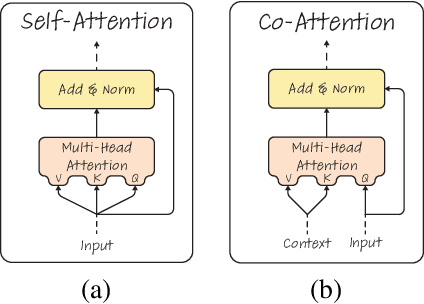
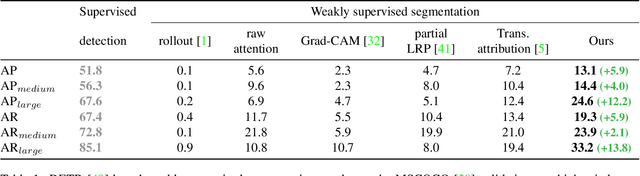
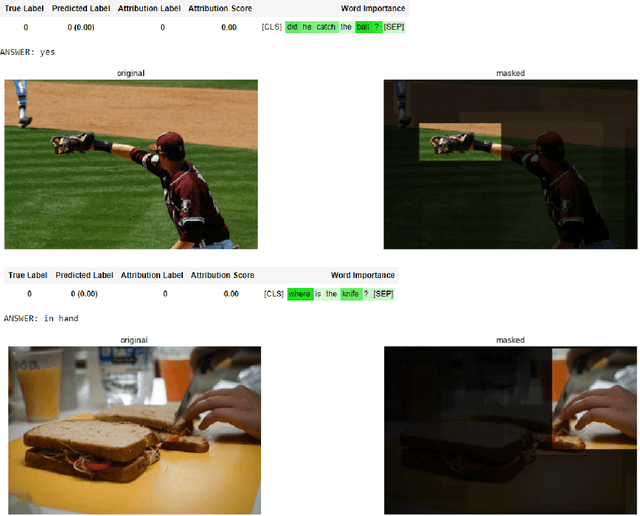
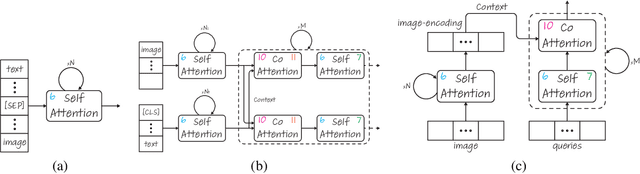
Transformers are increasingly dominating multi-modal reasoning tasks, such as visual question answering, achieving state-of-the-art results thanks to their ability to contextualize information using the self-attention and co-attention mechanisms. These attention modules also play a role in other computer vision tasks including object detection and image segmentation. Unlike Transformers that only use self-attention, Transformers with co-attention require to consider multiple attention maps in parallel in order to highlight the information that is relevant to the prediction in the model's input. In this work, we propose the first method to explain prediction by any Transformer-based architecture, including bi-modal Transformers and Transformers with co-attentions. We provide generic solutions and apply these to the three most commonly used of these architectures: (i) pure self-attention, (ii) self-attention combined with co-attention, and (iii) encoder-decoder attention. We show that our method is superior to all existing methods which are adapted from single modality explainability.
Multi-VFL: A Vertical Federated Learning System for Multiple Data and Label Owners
Jun 10, 2021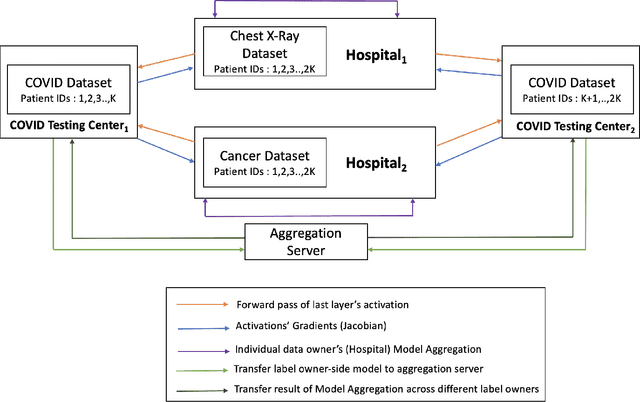


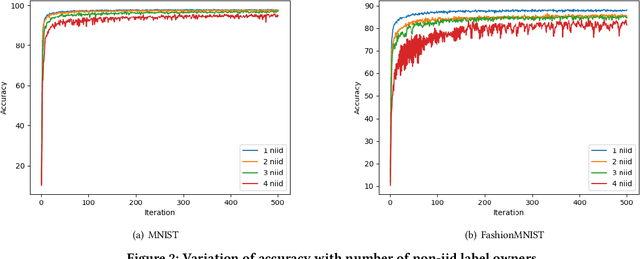
Vertical Federated Learning (VFL) refers to the collaborative training of a model on a dataset where the features of the dataset are split among multiple data owners, while label information is owned by a single data owner. In this paper, we propose a novel method, Multi Vertical Federated Learning (Multi-VFL), to train VFL models when there are multiple data and label owners. Our approach is the first to consider the setting where $D$-data owners (across which features are distributed) and $K$-label owners (across which labels are distributed) exist. This proposed configuration allows different entities to train and learn optimal models without having to share their data. Our framework makes use of split learning and adaptive federated optimizers to solve this problem. For empirical evaluation, we run experiments on the MNIST and FashionMNIST datasets. Our results show that using adaptive optimizers for model aggregation fastens convergence and improves accuracy.
Moving Towards Centers: Re-ranking with Attention and Memory for Re-identification
May 04, 2021
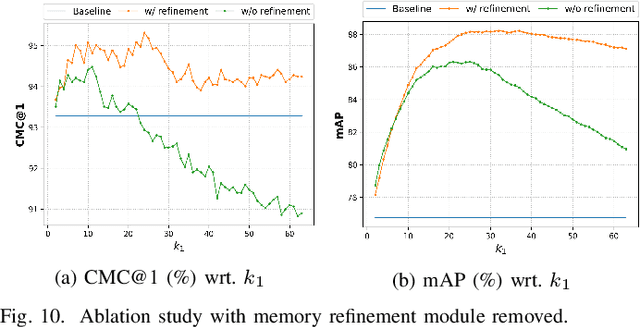
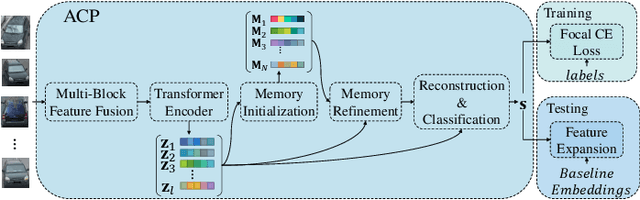
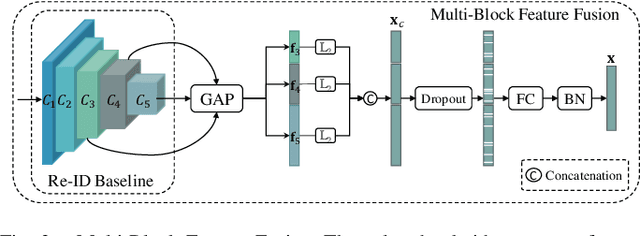
Re-ranking utilizes contextual information to optimize the initial ranking list of person or vehicle re-identification (re-ID), which boosts the retrieval performance at post-processing steps. This paper proposes a re-ranking network to predict the correlations between the probe and top-ranked neighbor samples. Specifically, all the feature embeddings of query and gallery images are expanded and enhanced by a linear combination of their neighbors, with the correlation prediction serves as discriminative combination weights. The combination process is equivalent to moving independent embeddings toward the identity centers, improving cluster compactness. For correlation prediction, we first aggregate the contextual information for probe's k-nearest neighbors via the Transformer encoder. Then, we distill and refine the probe-related features into the Contextual Memory cell via attention mechanism. Like humans that retrieve images by not only considering probe images but also memorizing the retrieved ones, the Contextual Memory produces multi-view descriptions for each instance. Finally, the neighbors are reconstructed with features fetched from the Contextual Memory, and a binary classifier predicts their correlations with the probe. Experiments on six widely-used person and vehicle re-ID benchmarks demonstrate the effectiveness of the proposed method. Especially, our method surpasses the state-of-the-art re-ranking approaches on large-scale datasets by a significant margin, i.e., with an average 3.08% CMC@1 and 7.46% mAP improvements on VERI-Wild, MSMT17, and VehicleID datasets.
Learning Synergistic Attention for Light Field Salient Object Detection
May 16, 2021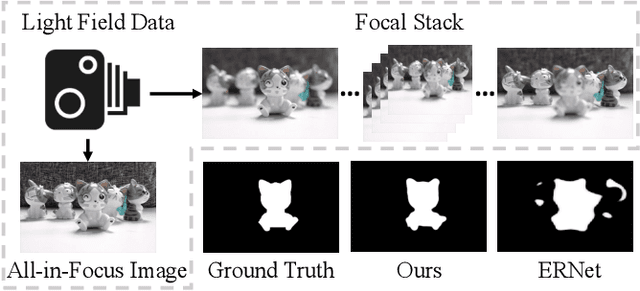
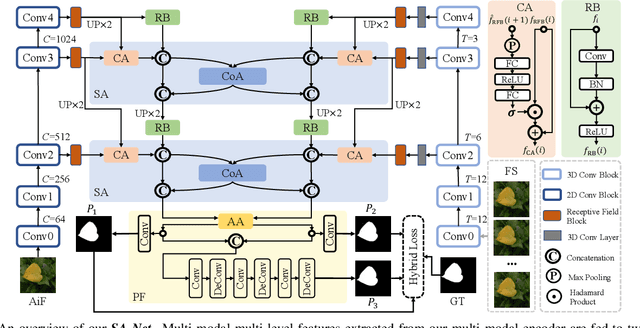
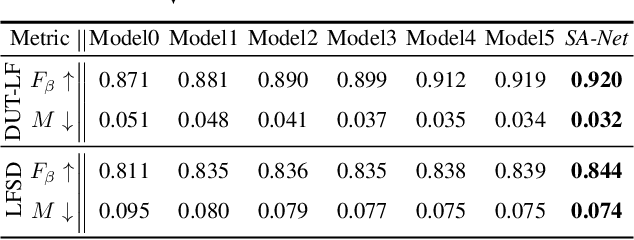
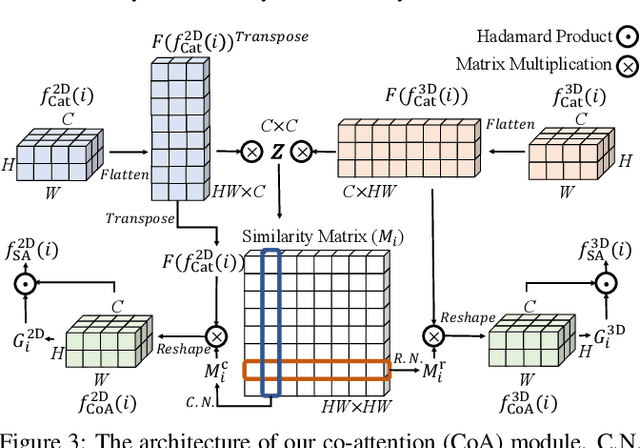
We propose a novel Synergistic Attention Network (SA-Net) to address the light field salient object detection by establishing a synergistic effect between multi-modal features with advanced attention mechanisms. Our SA-Net exploits the rich information of focal stacks via 3D convolutional neural networks, decodes the high-level features of multi-modal light field data with two cascaded synergistic attention modules, and predicts the saliency map using an effective feature fusion module in a progressive manner. Extensive experiments on three widely-used benchmark datasets show that our SA-Net outperforms 28 state-of-the-art models, sufficiently demonstrating its effectiveness and superiority. Our code will be made publicly available.