 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Annotation of Chinese Predicate Heads and Relevant Elements
Apr 01, 2021
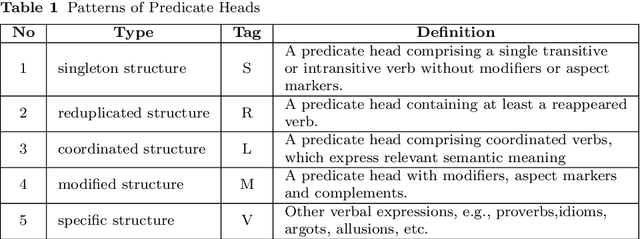
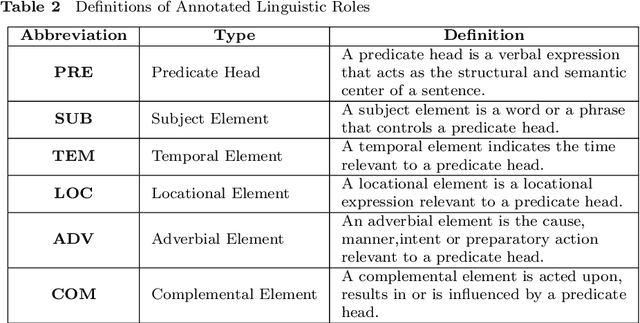
A predicate head is a verbal expression that plays a role as the structural center of a sentence. Identifying predicate heads is critical to understanding a sentence. It plays the leading role in organizing the relevant syntactic elements in a sentence, including subject elements, adverbial elements, etc. For some languages, such as English, word morphologies are valuable for identifying predicate heads. However, Chinese offers no morphological information to indicate words` grammatical roles. A Chinese sentence often contains several verbal expressions; identifying the expression that plays the role of the predicate head is not an easy task. Furthermore, Chinese sentences are inattentive to structure and provide no delimitation between words. Therefore, identifying Chinese predicate heads involves significant challenges. In Chinese information extraction, little work has been performed in predicate head recognition. No generally accepted evaluation dataset supports work in this important area. This paper presents the first attempt to develop an annotation guideline for Chinese predicate heads and their relevant syntactic elements. This annotation guideline emphasizes the role of the predicate as the structural center of a sentence. The design of relevant syntactic element annotation also follows this principle. Many considerations are proposed to achieve this goal, e.g., patterns of predicate heads, a flattened annotation structure, and a simpler syntactic unit type. Based on the proposed annotation guideline, more than 1,500 documents were manually annotated. The corpus will be available online for public access. With this guideline and annotated corpus, our goal is to broadly impact and advance the research in the area of Chinese information extraction and to provide the research community with a critical resource that has been lacking for a long time.
Unbiased Self-Play
Jun 06, 2021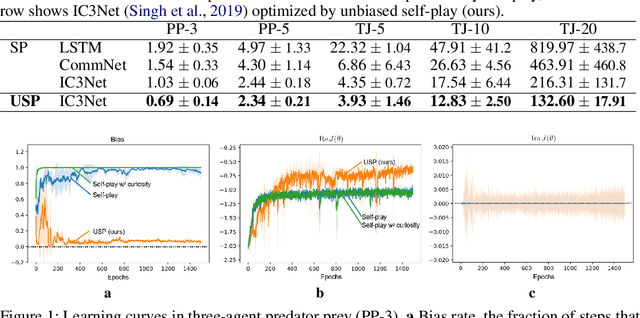
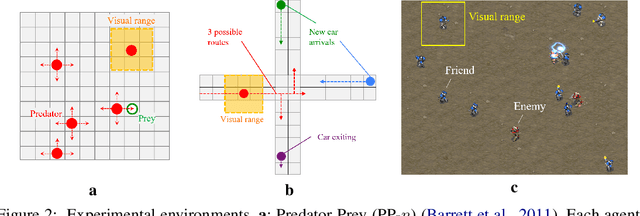

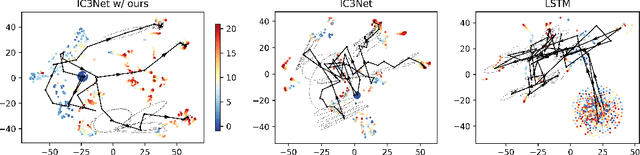
We present a general optimization framework for emergent belief-state representation without any supervision. We employed the common configuration of multiagent reinforcement learning and communication to improve exploration coverage over an environment by leveraging the knowledge of each agent. In this paper, we obtained that recurrent neural nets (RNNs) with shared weights are highly biased in partially observable environments because of their noncooperativity. To address this, we designated an unbiased version of self-play via mechanism design, also known as reverse game theory, to clarify unbiased knowledge at the Bayesian Nash equilibrium. The key idea is to add imaginary rewards using the peer prediction mechanism, i.e., a mechanism for mutually criticizing information in a decentralized environment. Numerical analyses, including StarCraft exploration tasks with up to 20 agents and off-the-shelf RNNs, demonstrate the state-of-the-art performance.
NG+ : A Multi-Step Matrix-Product Natural Gradient Method for Deep Learning
Jun 14, 2021
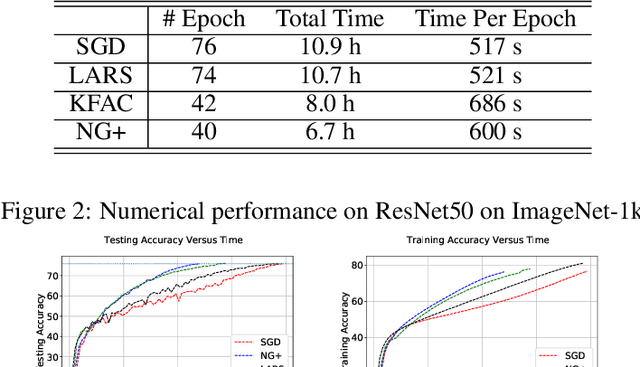

In this paper, a novel second-order method called NG+ is proposed. By following the rule ``the shape of the gradient equals the shape of the parameter", we define a generalized fisher information matrix (GFIM) using the products of gradients in the matrix form rather than the traditional vectorization. Then, our generalized natural gradient direction is simply the inverse of the GFIM multiplies the gradient in the matrix form. Moreover, the GFIM and its inverse keeps the same for multiple steps so that the computational cost can be controlled and is comparable with the first-order methods. A global convergence is established under some mild conditions and a regret bound is also given for the online learning setting. Numerical results on image classification with ResNet50, quantum chemistry modeling with Schnet, neural machine translation with Transformer and recommendation system with DLRM illustrate that GN+ is competitive with the state-of-the-art methods.
SRF-Net: Selective Receptive Field Network for Anchor-Free Temporal Action Detection
Jun 29, 2021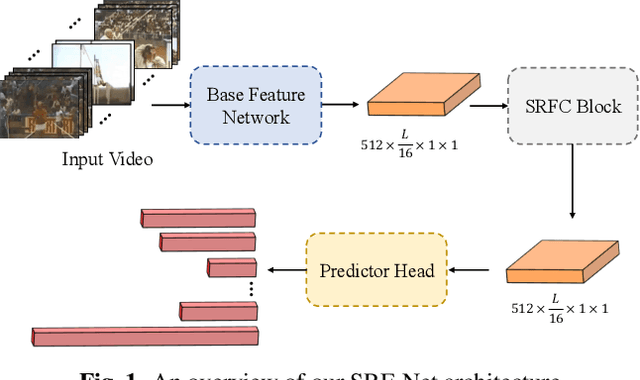
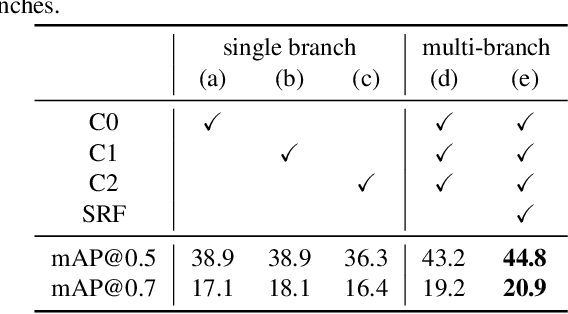
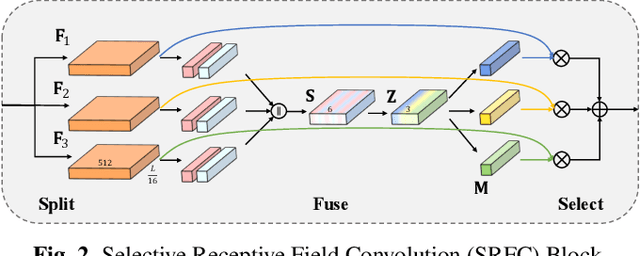
Temporal action detection (TAD) is a challenging task which aims to temporally localize and recognize the human action in untrimmed videos. Current mainstream one-stage TAD approaches localize and classify action proposals relying on pre-defined anchors, where the location and scale for action instances are set by designers. Obviously, such an anchor-based TAD method limits its generalization capability and will lead to performance degradation when videos contain rich action variation. In this study, we explore to remove the requirement of pre-defined anchors for TAD methods. A novel TAD model termed as Selective Receptive Field Network (SRF-Net) is developed, in which the location offsets and classification scores at each temporal location can be directly estimated in the feature map and SRF-Net is trained in an end-to-end manner. Innovatively, a building block called Selective Receptive Field Convolution (SRFC) is dedicatedly designed which is able to adaptively adjust its receptive field size according to multiple scales of input information at each temporal location in the feature map. Extensive experiments are conducted on the THUMOS14 dataset, and superior results are reported comparing to state-of-the-art TAD approaches.
Bayesian Optimisation for Constrained Problems
May 27, 2021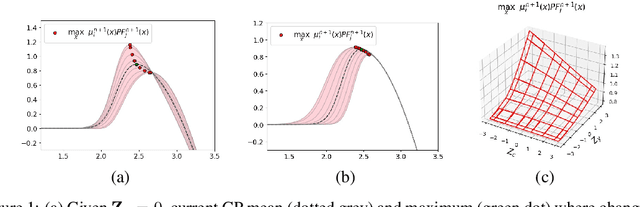
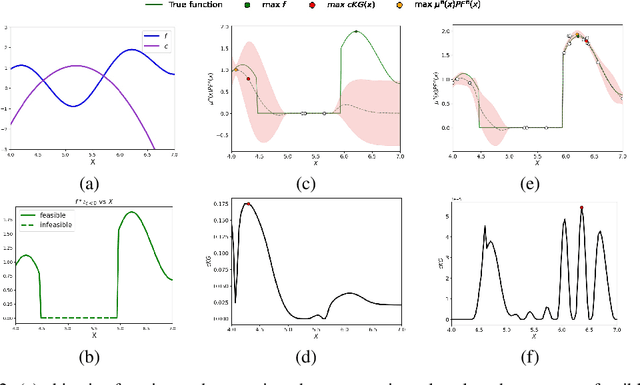
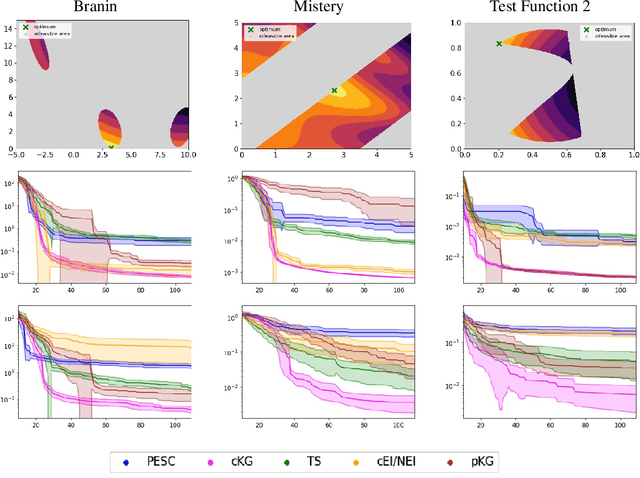
Many real-world optimisation problems such as hyperparameter tuning in machine learning or simulation-based optimisation can be formulated as expensive-to-evaluate black-box functions. A popular approach to tackle such problems is Bayesian optimisation (BO), which builds a response surface model based on the data collected so far, and uses the mean and uncertainty predicted by the model to decide what information to collect next. In this paper, we propose a novel variant of the well-known Knowledge Gradient acquisition function that allows it to handle constraints. We empirically compare the new algorithm with four other state-of-the-art constrained Bayesian optimisation algorithms and demonstrate its superior performance. We also prove theoretical convergence in the infinite budget limit.
Improving Sequential Recommendation Consistency with Self-Supervised Imitation
Jun 29, 2021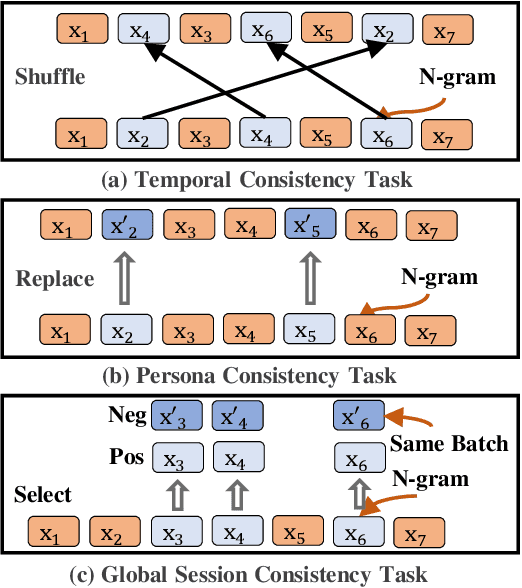
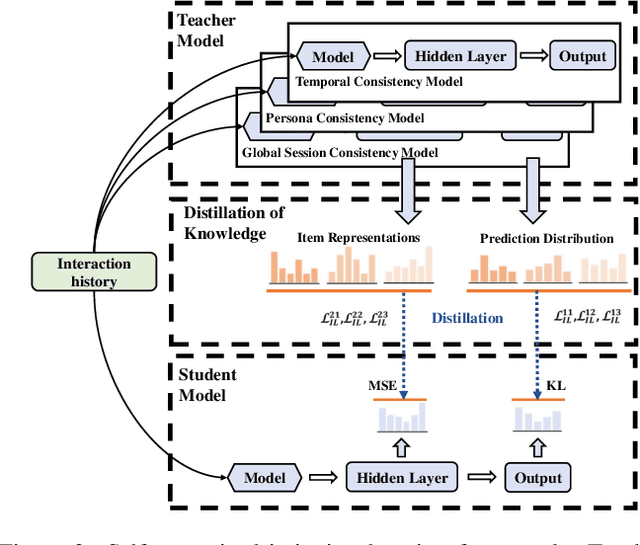
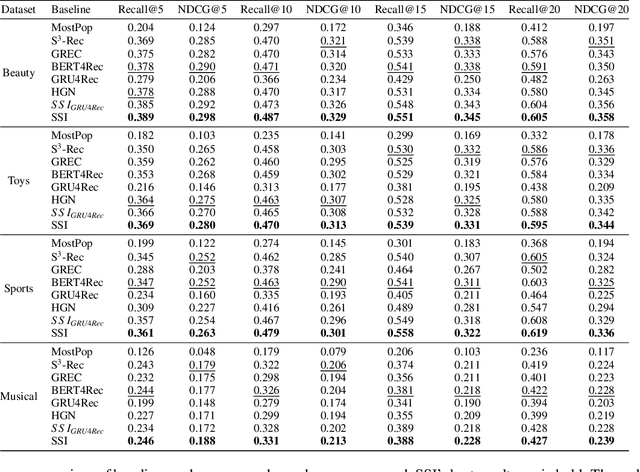
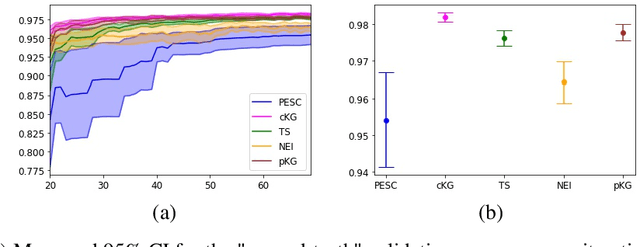
Most sequential recommendation models capture the features of consecutive items in a user-item interaction history. Though effective, their representation expressiveness is still hindered by the sparse learning signals. As a result, the sequential recommender is prone to make inconsistent predictions. In this paper, we propose a model, SSI, to improve sequential recommendation consistency with Self-Supervised Imitation. Precisely, we extract the consistency knowledge by utilizing three self-supervised pre-training tasks, where temporal consistency and persona consistency capture user-interaction dynamics in terms of the chronological order and persona sensitivities, respectively. Furthermore, to provide the model with a global perspective, global session consistency is introduced by maximizing the mutual information among global and local interaction sequences. Finally, to comprehensively take advantage of all three independent aspects of consistency-enhanced knowledge, we establish an integrated imitation learning framework. The consistency knowledge is effectively internalized and transferred to the student model by imitating the conventional prediction logit as well as the consistency-enhanced item representations. In addition, the flexible self-supervised imitation framework can also benefit other student recommenders. Experiments on four real-world datasets show that SSI effectively outperforms the state-of-the-art sequential recommendation methods.
Improving the Authentication with Built-in Camera Protocol Using Built-in Motion Sensors: A Deep Learning Solution
Jul 27, 2021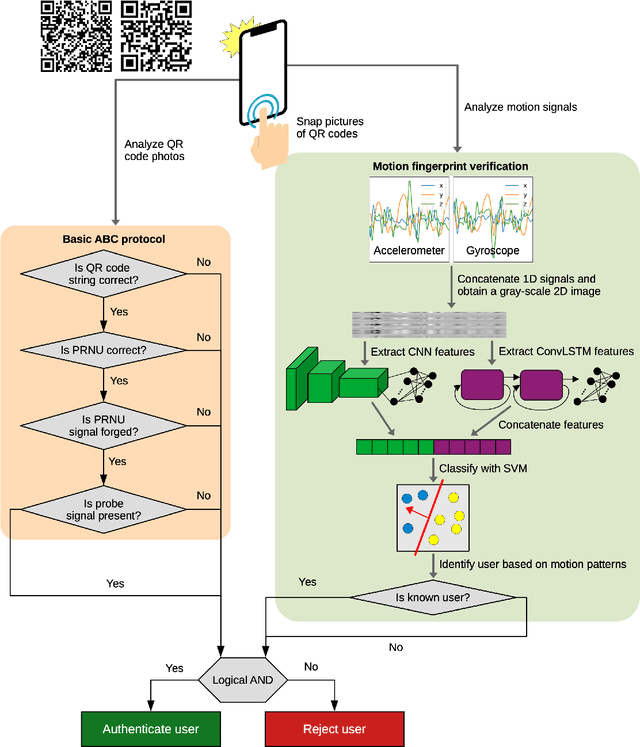
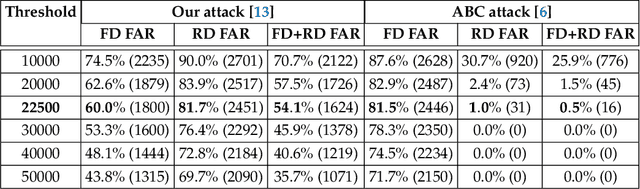
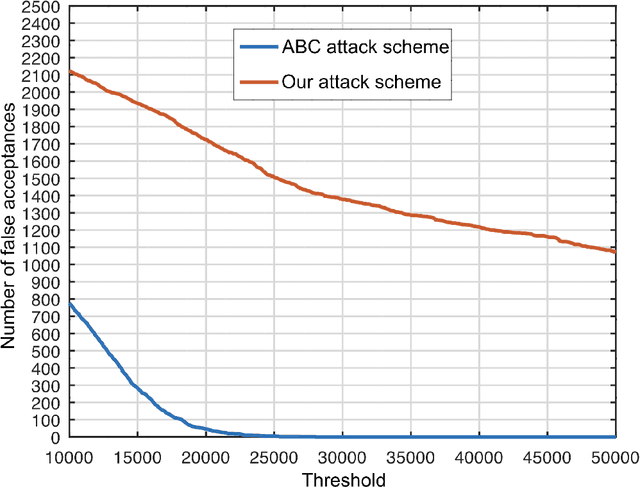
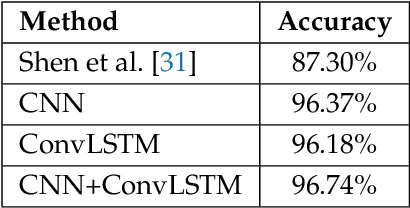
We propose an enhanced version of the Authentication with Built-in Camera (ABC) protocol by employing a deep learning solution based on built-in motion sensors. The standard ABC protocol identifies mobile devices based on the photo-response non-uniformity (PRNU) of the camera sensor, while also considering QR-code-based meta-information. During authentication, the user is required to take two photos that contain two QR codes presented on a screen. The presented QR code images also contain a unique probe signal, similar to a camera fingerprint, generated by the protocol. During verification, the server computes the fingerprint of the received photos and authenticates the user if (i) the probe signal is present, (ii) the metadata embedded in the QR codes is correct and (iii) the camera fingerprint is identified correctly. However, the protocol is vulnerable to forgery attacks when the attacker can compute the camera fingerprint from external photos, as shown in our preliminary work. In this context, we propose an enhancement for the ABC protocol based on motion sensor data, as an additional and passive authentication layer. Smartphones can be identified through their motion sensor data, which, unlike photos, is never posted by users on social media platforms, thus being more secure than using photographs alone. To this end, we transform motion signals into embedding vectors produced by deep neural networks, applying Support Vector Machines for the smartphone identification task. Our change to the ABC protocol results in a multi-modal protocol that lowers the false acceptance rate for the attack proposed in our previous work to a percentage as low as 0.07%.
Speech Disorder Classification Using Extended Factorized Hierarchical Variational Auto-encoders
Jun 14, 2021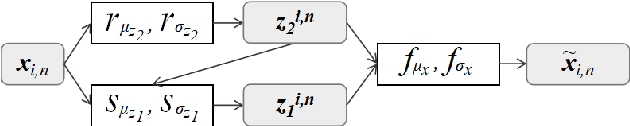

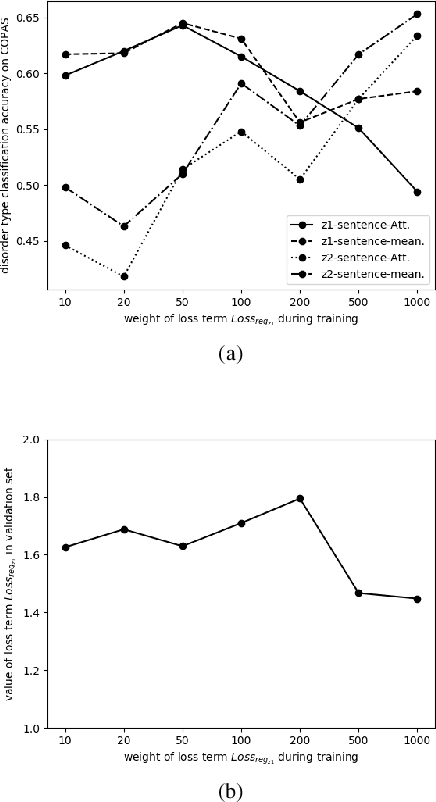
Objective speech disorder classification for speakers with communication difficulty is desirable for diagnosis and administering therapy. With the current state of speech technology, it is evident to propose neural networks for this application. But neural network model training is hampered by a lack of labeled disordered speech data. In this research, we apply an extended version of Factorized Hierarchical Variational Auto-encoders (FHVAE) for representation learning on disordered speech. The FHVAE model extracts both content-related and sequence-related latent variables from speech data, and we utilize the extracted variables to explore how disorder type information is represented in the latent variables. For better classification performance, the latent variables are aggregated at the word and sentence level. We show that an extension of the FHVAE model succeeds in the better disentanglement of the content-related and sequence-related related representations, but both representations are still required for best results on disorder type classification.
SENT: Sentence-level Distant Relation Extraction via Negative Training
Jun 22, 2021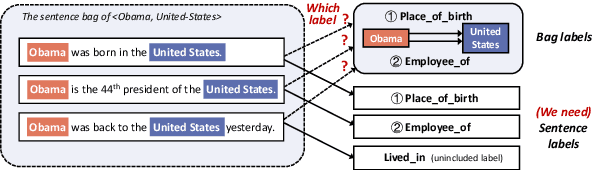
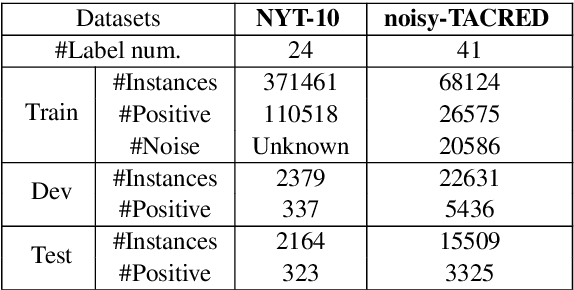
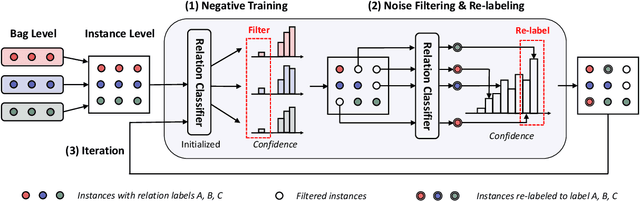
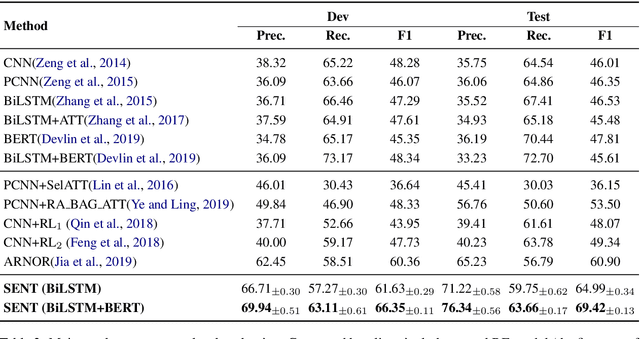
Distant supervision for relation extraction provides uniform bag labels for each sentence inside the bag, while accurate sentence labels are important for downstream applications that need the exact relation type. Directly using bag labels for sentence-level training will introduce much noise, thus severely degrading performance. In this work, we propose the use of negative training (NT), in which a model is trained using complementary labels regarding that ``the instance does not belong to these complementary labels". Since the probability of selecting a true label as a complementary label is low, NT provides less noisy information. Furthermore, the model trained with NT is able to separate the noisy data from the training data. Based on NT, we propose a sentence-level framework, SENT, for distant relation extraction. SENT not only filters the noisy data to construct a cleaner dataset, but also performs a re-labeling process to transform the noisy data into useful training data, thus further benefiting the model's performance. Experimental results show the significant improvement of the proposed method over previous methods on sentence-level evaluation and de-noise effect.
Random Embeddings and Linear Regression can Predict Protein Function
Apr 25, 2021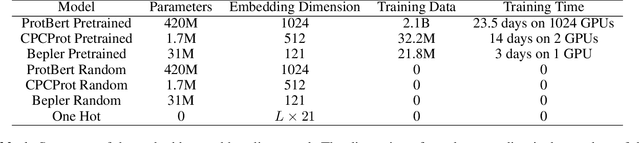
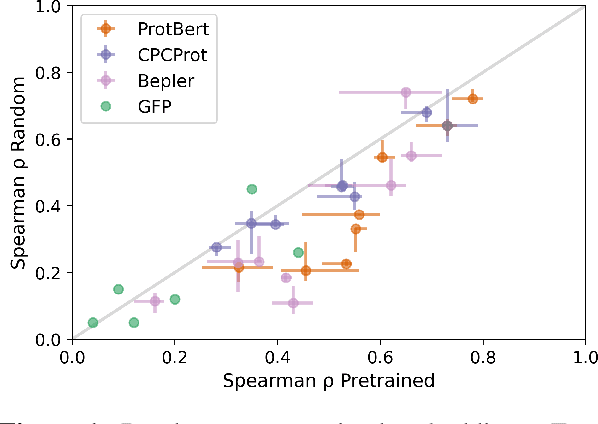
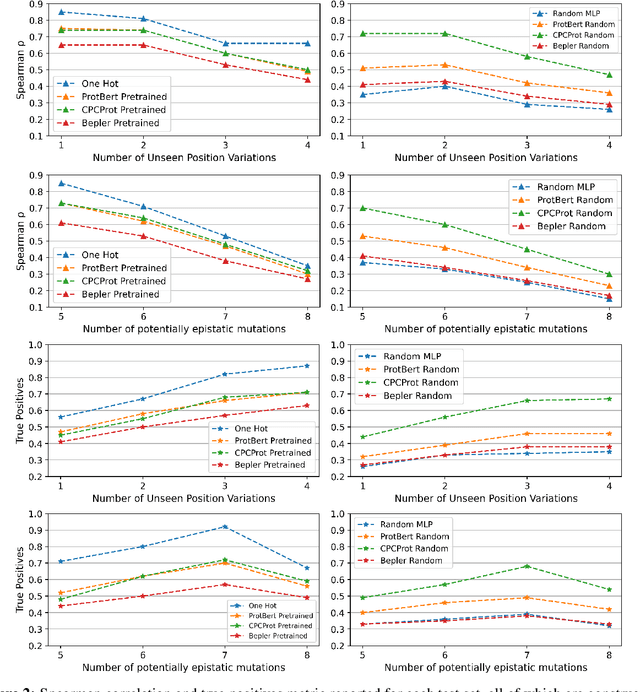

Large self-supervised models pretrained on millions of protein sequences have recently gained popularity in generating embeddings of protein sequences for protein function prediction. However, the absence of random baselines makes it difficult to conclude whether pretraining has learned useful information for protein function prediction. Here we show that one-hot encoding and random embeddings, both of which do not require any pretraining, are strong baselines for protein function prediction across 14 diverse sequence-to-function tasks.