 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Attentive Max Feature Map for Acoustic Scene Classification with Joint Learning considering the Abstraction of Classes
Apr 15, 2021


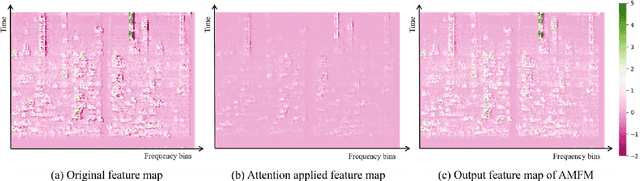
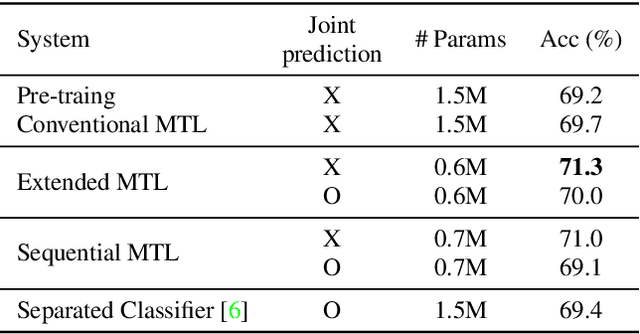
The attention mechanism has been widely adopted in acoustic scene classification. However, we find that during the process of attention exclusively emphasizing information, it tends to excessively discard information although improving the performance. We propose a mechanism referred to as the attentive max feature map which combines two effective techniques, attention and max feature map, to further elaborate the attention mechanism and mitigate the abovementioned phenomenon. Furthermore, we explore various joint learning methods that utilize additional labels originally generated for subtask B (3-classes) on top of existing labels for subtask A (10-classes) of the DCASE2020 challenge. We expect that using two kinds of labels simultaneously would be helpful because the labels of the two subtasks differ in their degree of abstraction. Applying two proposed techniques, our proposed system achieves state-of-the-art performance among single systems on subtask A. In addition, because the model has a complexity comparable to subtask B's requirement, it shows the possibility of developing a system that fulfills the requirements of both subtasks; generalization on multiple devices and low-complexity.
High-Frequency aware Perceptual Image Enhancement
May 25, 2021
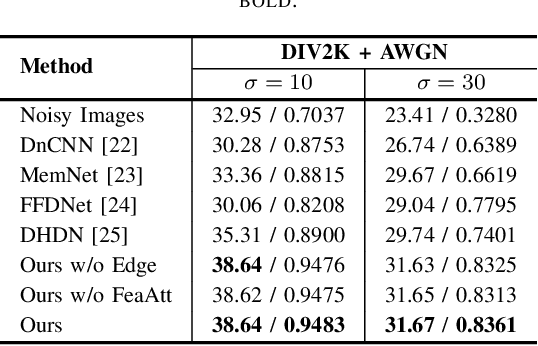
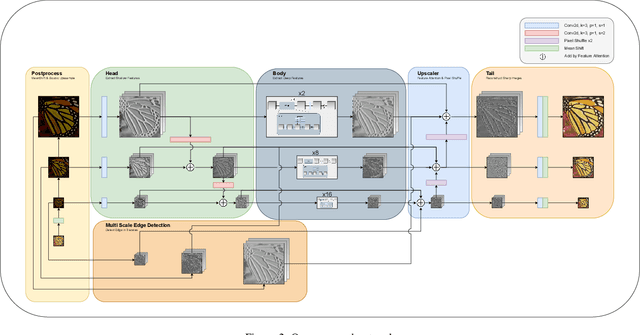
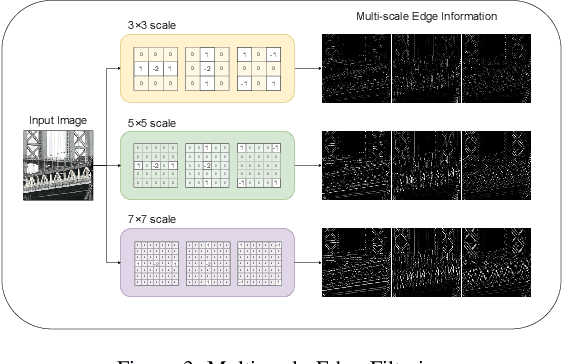
In this paper, we introduce a novel deep neural network suitable for multi-scale analysis and propose efficient model-agnostic methods that help the network extract information from high-frequency domains to reconstruct clearer images. Our model can be applied to multi-scale image enhancement problems including denoising, deblurring and single image super-resolution. Experiments on SIDD, Flickr2K, DIV2K, and REDS datasets show that our method achieves state-of-the-art performance on each task. Furthermore, we show that our model can overcome the over-smoothing problem commonly observed in existing PSNR-oriented methods and generate more natural high-resolution images by applying adversarial training.
Heterogeneous Data Fusion Considering Spatial Correlations using Graph Convolutional Networks and its Application in Air Quality Prediction
May 24, 2021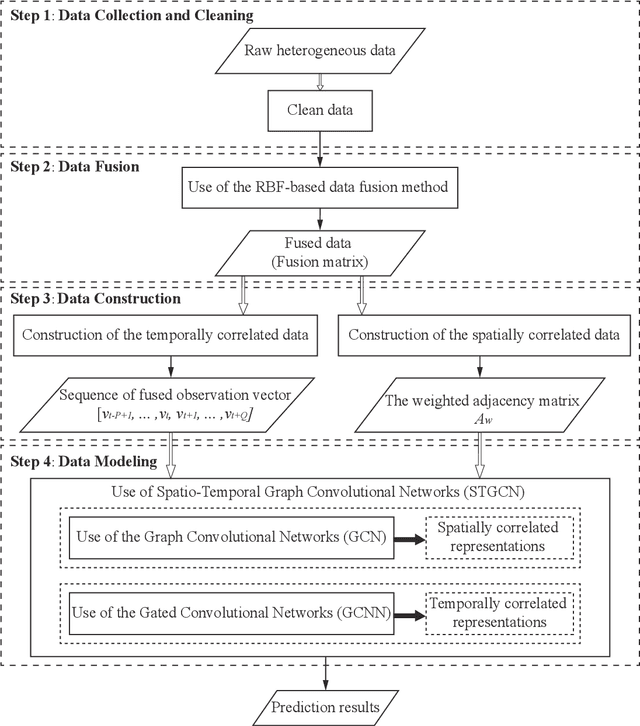
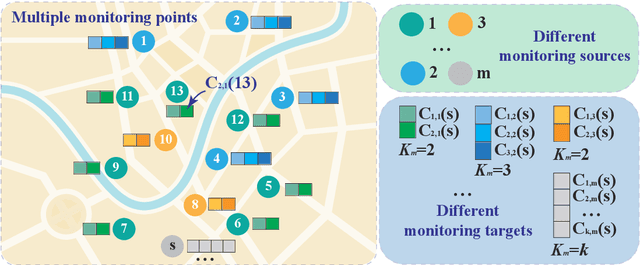

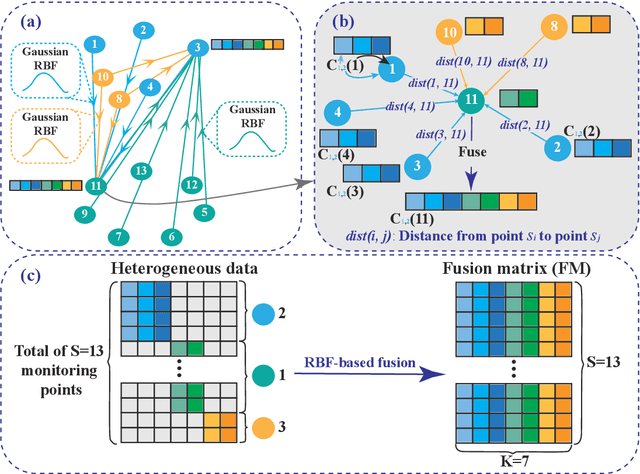
Heterogeneous data are commonly adopted as the inputs for some models that predict the future trends of some observations. Existing predictive models typically ignore the inconsistencies and imperfections in heterogeneous data while also failing to consider the (1) spatial correlations among monitoring points or (2) predictions for the entire study area. To address the above problems, this paper proposes a deep learning method for fusing heterogeneous data collected from multiple monitoring points using graph convolutional networks (GCNs) to predict the future trends of some observations and evaluates its effectiveness by applying it in an air quality predictions scenario. The essential idea behind the proposed method is to (1) fuse the collected heterogeneous data based on the locations of the monitoring points with regard to their spatial correlations and (2) perform prediction based on global information rather than local information. In the proposed method, first, we assemble a fusion matrix using the proposed RBF-based fusion approach; second, based on the fused data, we construct spatially and temporally correlated data as inputs for the predictive model; finally, we employ the spatiotemporal graph convolutional network (STGCN) to predict the future trends of some observations. In the application scenario of air quality prediction, it is observed that (1) the fused data derived from the RBF-based fusion approach achieve satisfactory consistency; (2) the performances of the prediction models based on fused data are better than those based on raw data; and (3) the STGCN model achieves the best performance when compared to those of all baseline models. The proposed method is applicable for similar scenarios where continuous heterogeneous data are collected from multiple monitoring points scattered across a study area.
Semi-Supervised Disentangled Framework for Transferable Named Entity Recognition
Dec 22, 2020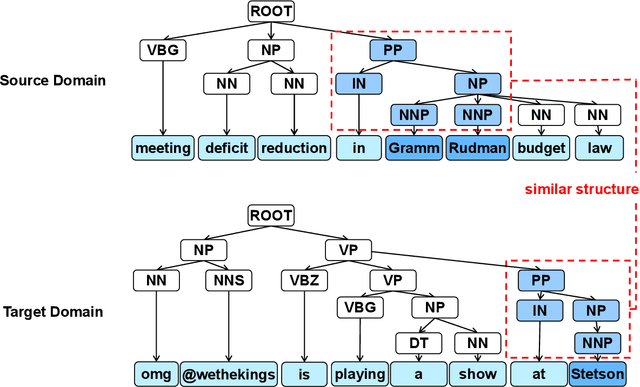
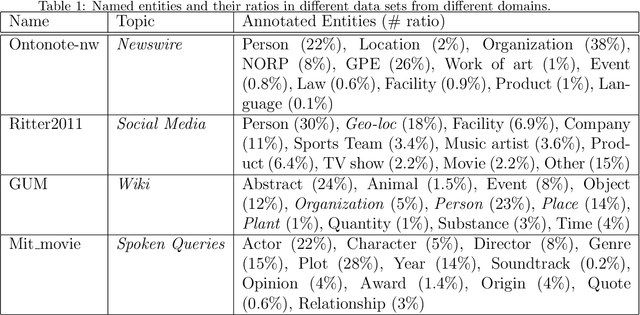
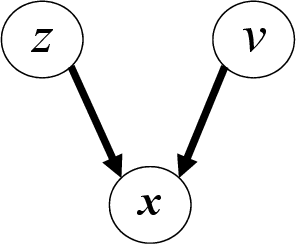
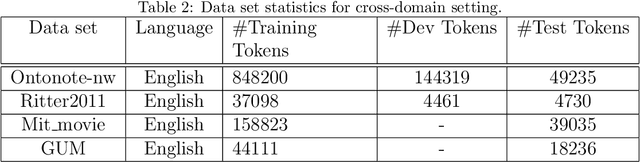
Named entity recognition (NER) for identifying proper nouns in unstructured text is one of the most important and fundamental tasks in natural language processing. However, despite the widespread use of NER models, they still require a large-scale labeled data set, which incurs a heavy burden due to manual annotation. Domain adaptation is one of the most promising solutions to this problem, where rich labeled data from the relevant source domain are utilized to strengthen the generalizability of a model based on the target domain. However, the mainstream cross-domain NER models are still affected by the following two challenges (1) Extracting domain-invariant information such as syntactic information for cross-domain transfer. (2) Integrating domain-specific information such as semantic information into the model to improve the performance of NER. In this study, we present a semi-supervised framework for transferable NER, which disentangles the domain-invariant latent variables and domain-specific latent variables. In the proposed framework, the domain-specific information is integrated with the domain-specific latent variables by using a domain predictor. The domain-specific and domain-invariant latent variables are disentangled using three mutual information regularization terms, i.e., maximizing the mutual information between the domain-specific latent variables and the original embedding, maximizing the mutual information between the domain-invariant latent variables and the original embedding, and minimizing the mutual information between the domain-specific and domain-invariant latent variables. Extensive experiments demonstrated that our model can obtain state-of-the-art performance with cross-domain and cross-lingual NER benchmark data sets.
Hierarchical Associative Memory
Jul 14, 2021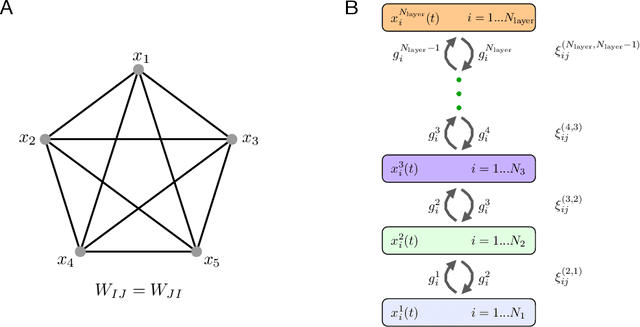
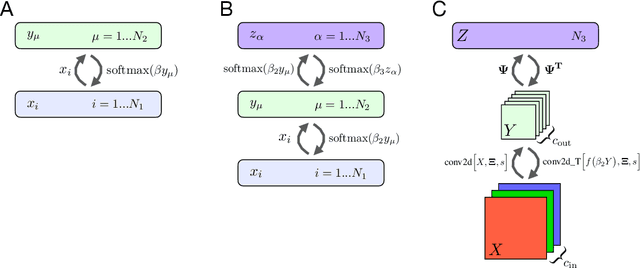
Dense Associative Memories or Modern Hopfield Networks have many appealing properties of associative memory. They can do pattern completion, store a large number of memories, and can be described using a recurrent neural network with a degree of biological plausibility and rich feedback between the neurons. At the same time, up until now all the models of this class have had only one hidden layer, and have only been formulated with densely connected network architectures, two aspects that hinder their machine learning applications. This paper tackles this gap and describes a fully recurrent model of associative memory with an arbitrary large number of layers, some of which can be locally connected (convolutional), and a corresponding energy function that decreases on the dynamical trajectory of the neurons' activations. The memories of the full network are dynamically "assembled" using primitives encoded in the synaptic weights of the lower layers, with the "assembling rules" encoded in the synaptic weights of the higher layers. In addition to the bottom-up propagation of information, typical of commonly used feedforward neural networks, the model described has rich top-down feedback from higher layers that help the lower-layer neurons to decide on their response to the input stimuli.
Combining pre-trained language models and structured knowledge
Jan 28, 2021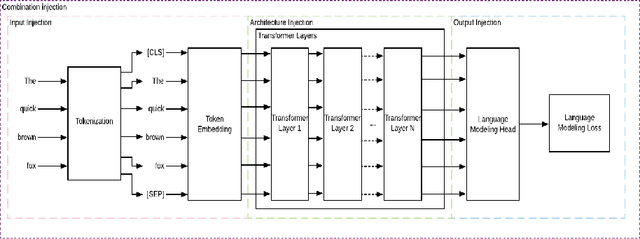
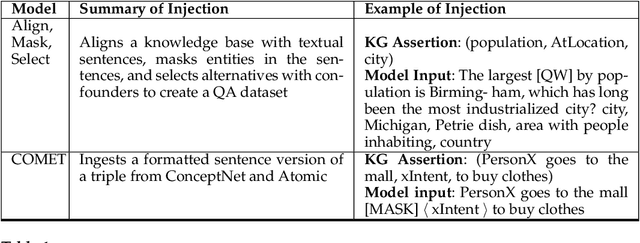
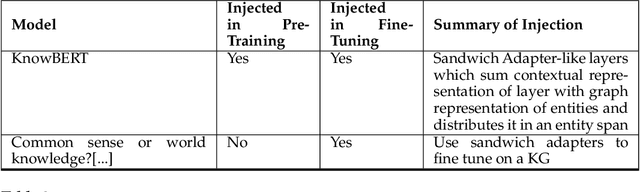
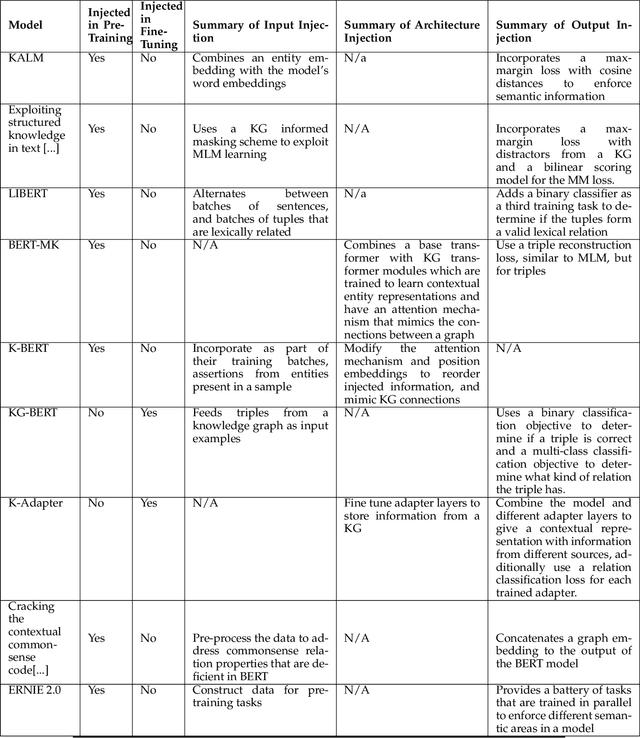
In recent years, transformer-based language models have achieved state of the art performance in various NLP benchmarks. These models are able to extract mostly distributional information with some semantics from unstructured text, however it has proven challenging to integrate structured information, such as knowledge graphs into these models. We examine a variety of approaches to integrate structured knowledge into current language models and determine challenges, and possible opportunities to leverage both structured and unstructured information sources. From our survey, we find that there are still opportunities at exploiting adapter-based injections and that it may be possible to further combine various of the explored approaches into one system.
Deep Conditional Gaussian Mixture Model for Constrained Clustering
Jun 22, 2021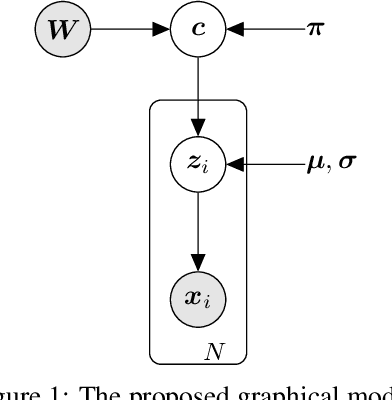
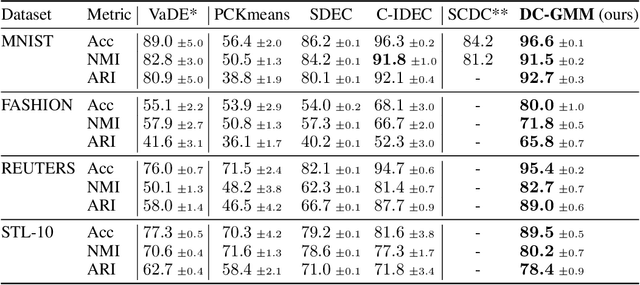
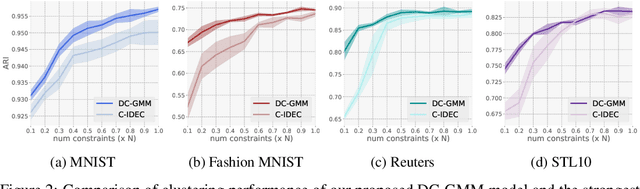
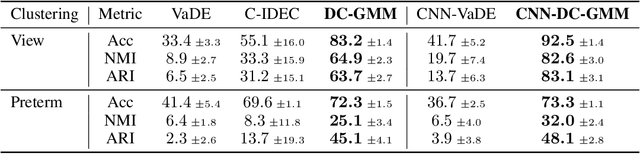
Constrained clustering has gained significant attention in the field of machine learning as it can leverage prior information on a growing amount of only partially labeled data. Following recent advances in deep generative models, we propose a novel framework for constrained clustering that is intuitive, interpretable, and can be trained efficiently in the framework of stochastic gradient variational inference. By explicitly integrating domain knowledge in the form of probabilistic relations, our proposed model (DC-GMM) uncovers the underlying distribution of data conditioned on prior clustering preferences, expressed as pairwise constraints. These constraints guide the clustering process towards a desirable partition of the data by indicating which samples should or should not belong to the same cluster. We provide extensive experiments to demonstrate that DC-GMM shows superior clustering performances and robustness compared to state-of-the-art deep constrained clustering methods on a wide range of data sets. We further demonstrate the usefulness of our approach on two challenging real-world applications.
Active Learning under Pool Set Distribution Shift and Noisy Data
Jun 22, 2021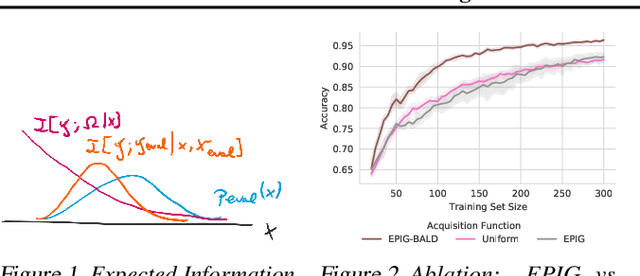
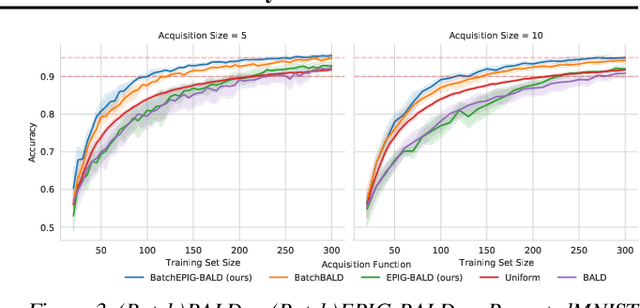
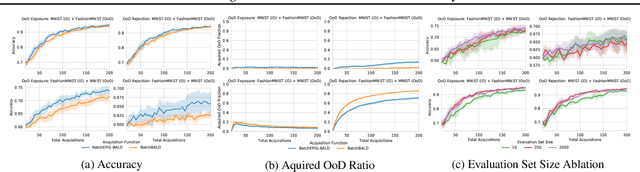
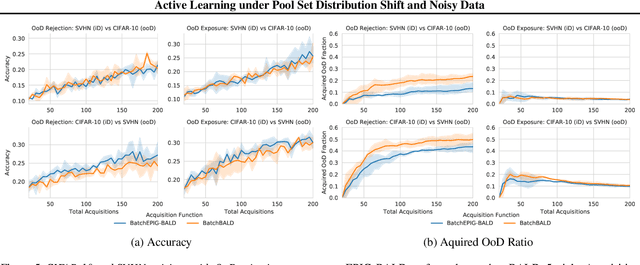
Active Learning is essential for more label-efficient deep learning. Bayesian Active Learning has focused on BALD, which reduces model parameter uncertainty. However, we show that BALD gets stuck on out-of-distribution or junk data that is not relevant for the task. We examine a novel *Expected Predictive Information Gain (EPIG)* to deal with distribution shifts of the pool set. EPIG reduces the uncertainty of *predictions* on an unlabelled *evaluation set* sampled from the test data distribution whose distribution might be different to the pool set distribution. Based on this, our new EPIG-BALD acquisition function for Bayesian Neural Networks selects samples to improve the performance on the test data distribution instead of selecting samples that reduce model uncertainty everywhere, including for out-of-distribution regions with low density in the test data distribution. Our method outperforms state-of-the-art Bayesian active learning methods on high-dimensional datasets and avoids out-of-distribution junk data in cases where current state-of-the-art methods fail.
OntoEnricher: A Deep Learning Approach for Ontology Enrichment from Unstructured Text
Feb 08, 2021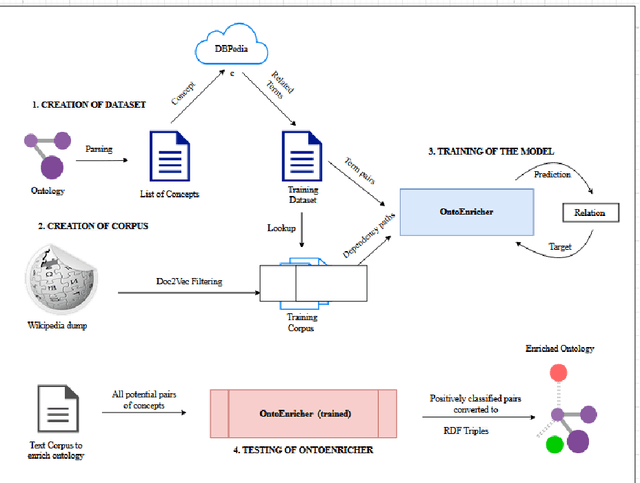
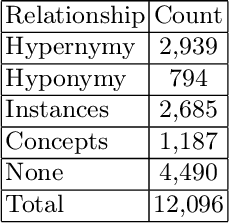
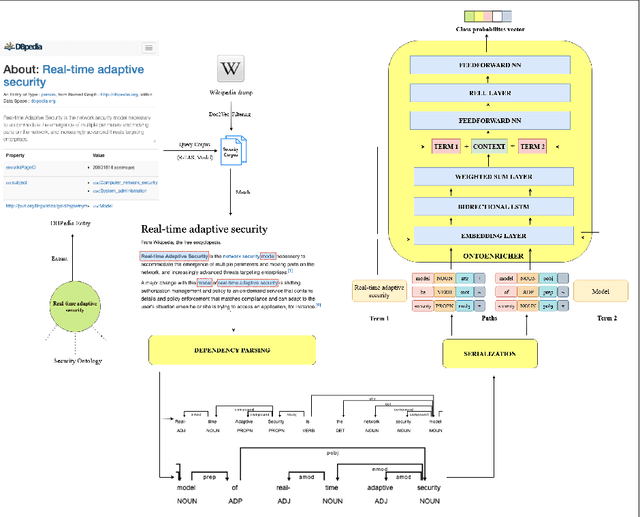
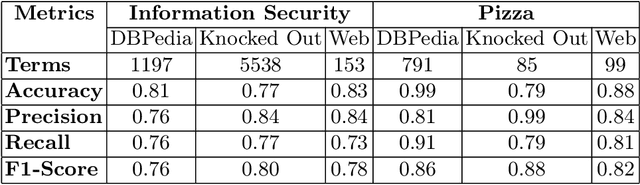
Information Security in the cyber world is a major cause for concern, with significant increase in the number of attack surfaces. Existing information on vulnerabilities, attacks, controls, and advisories available on the web provides an opportunity to represent knowledge and perform security analytics to mitigate some of the concerns. Representing security knowledge in the form of ontology facilitates anomaly detection, threat intelligence, reasoning and relevance attribution of attacks, and many more. This necessitates dynamic and automated enrichment of information security ontologies. However, existing ontology enrichment algorithms based on natural language processing and ML models have issues with the contextual extraction of concepts in words, phrases and sentences. This motivates the need for sequential Deep Learning architectures that traverse through dependency paths in text and extract embedded vulnerabilities, threats, controls, products and other security related concepts and instances from learned path representations. In the proposed approach, Bidirectional LSTMs trained on a large DBpedia dataset and Wikipedia corpus of 2.8 GB along with Universal Sentence Encoder was deployed to enrich ISO 27001 based information security ontology. The approach yielded a test accuracy of over 80\% when tested with knocked out concepts from ontology and web page instances to validate the robustness.
Summarizing Situational and Topical Information During Crises
Oct 05, 2016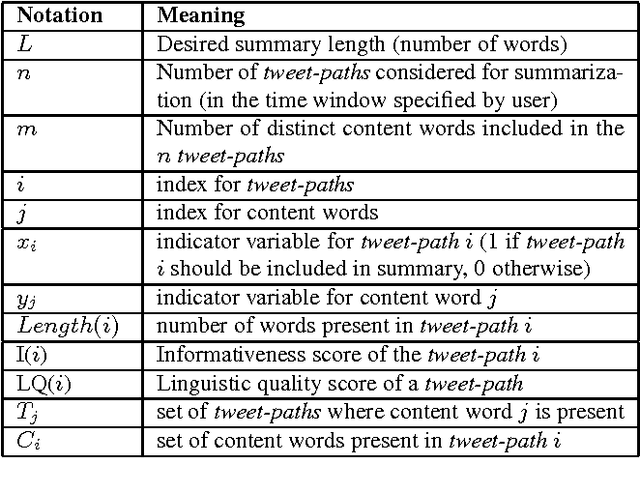
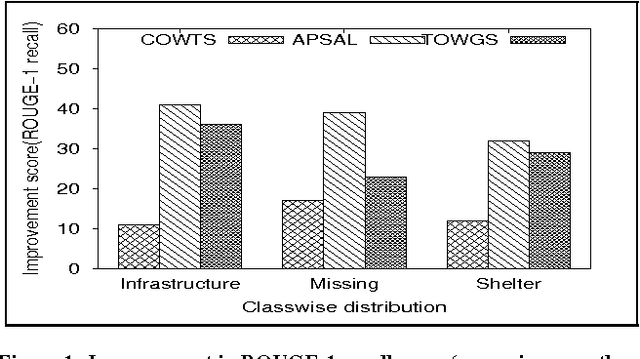
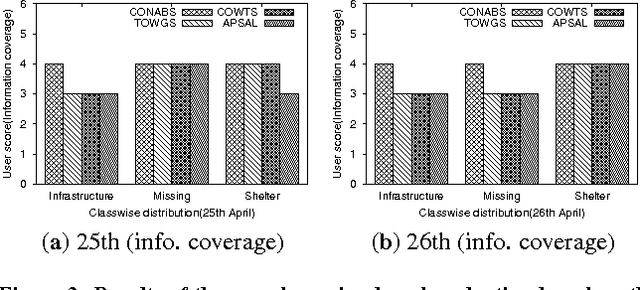

The use of microblogging platforms such as Twitter during crises has become widespread. More importantly, information disseminated by affected people contains useful information like reports of missing and found people, requests for urgent needs etc. For rapid crisis response, humanitarian organizations look for situational awareness information to understand and assess the severity of the crisis. In this paper, we present a novel framework (i) to generate abstractive summaries useful for situational awareness, and (ii) to capture sub-topics and present a short informative summary for each of these topics. A summary is generated using a two stage framework that first extracts a set of important tweets from the whole set of information through an Integer-linear programming (ILP) based optimization technique and then follows a word graph and concept event based abstractive summarization technique to produce the final summary. High accuracies obtained for all the tasks show the effectiveness of the proposed framework.