 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Survey on Graph-Based Deep Learning for Computational Histopathology
Jul 01, 2021
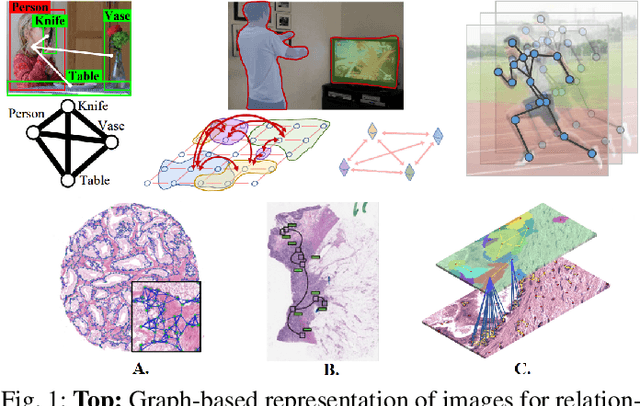
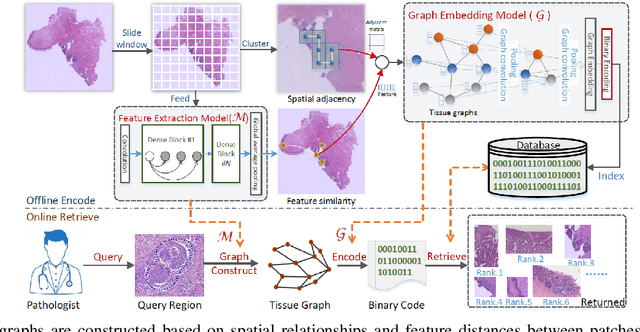
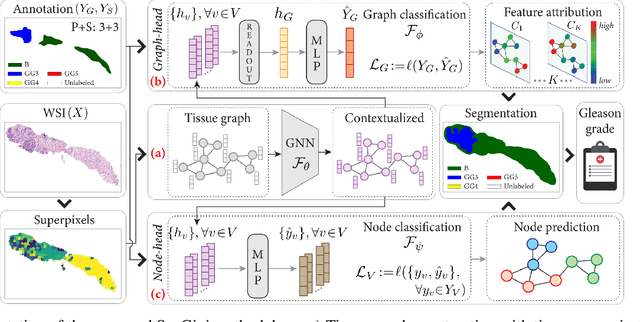
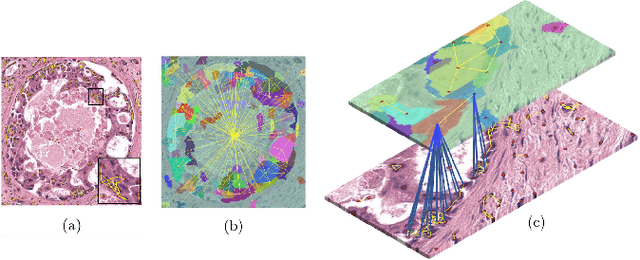
With the remarkable success of representation learning for prediction problems, we have witnessed a rapid expansion of the use of machine learning and deep learning for the analysis of digital pathology and biopsy image patches. However, traditional learning over patch-wise features using convolutional neural networks limits the model when attempting to capture global contextual information. The phenotypical and topological distribution of constituent histological entities play a critical role in tissue diagnosis. As such, graph data representations and deep learning have attracted significant attention for encoding tissue representations, and capturing intra- and inter- entity level interactions. In this review, we provide a conceptual grounding of graph-based deep learning and discuss its current success for tumor localization and classification, tumor invasion and staging, image retrieval, and survival prediction. We provide an overview of these methods in a systematic manner organized by the graph representation of the input image including whole slide images and tissue microarrays. We also outline the limitations of existing techniques, and suggest potential future advances in this domain.
Innovations Autoencoder and its Application in Real-Time Anomaly Detection
Jun 23, 2021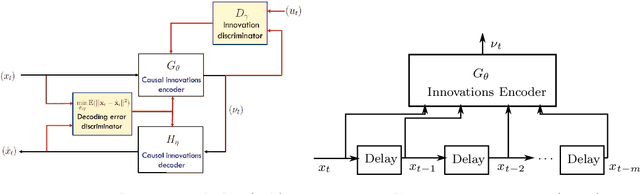


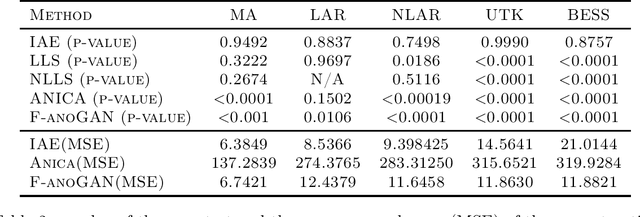
An innovations sequence of a time series is a sequence of independent and identically distributed random variables with which the original time series has a causal representation. The innovation at a time is statistically independent of the prior history of the time series. As such, it represents the new information contained at present but not in the past. Because of its simple probability structure, an innovations sequence is the most efficient signature of the original. Unlike the principle or independent analysis (PCA/ICA) representations, an innovations sequence preserves not only the complete statistical properties but also the temporal order of the original time series. An long-standing open problem is to find a computationally tractable way to extract an innovations sequence of non-Gaussian processes. This paper presents a deep learning approach, referred to as Innovations Autoencoder (IAE), that extracts innovations sequences using a causal convolutional neural network. An application of IAE to nonparametric anomaly detection with unknown anomaly and anomaly-free models is also presented.
Spatial-Phase Shallow Learning: Rethinking Face Forgery Detection in Frequency Domain
Mar 10, 2021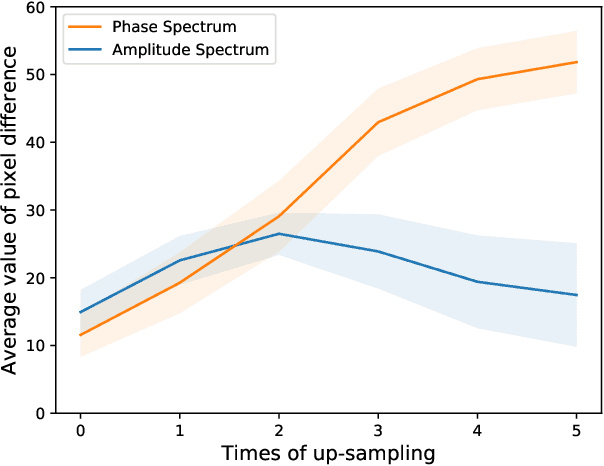
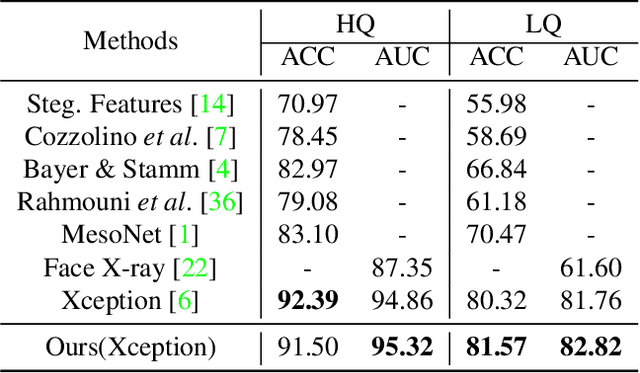
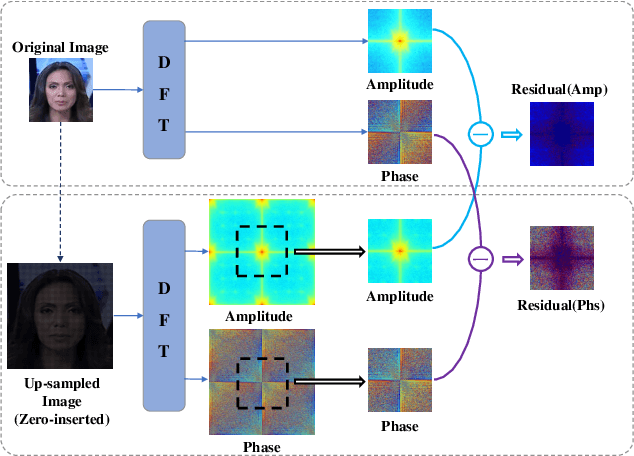
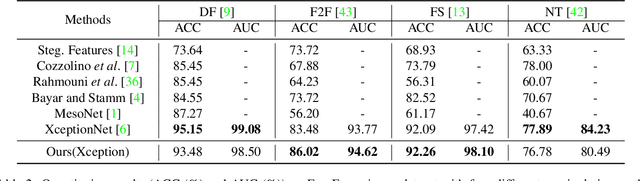
The remarkable success in face forgery techniques has received considerable attention in computer vision due to security concerns. We observe that up-sampling is a necessary step of most face forgery techniques, and cumulative up-sampling will result in obvious changes in the frequency domain, especially in the phase spectrum. According to the property of natural images, the phase spectrum preserves abundant frequency components that provide extra information and complement the loss of the amplitude spectrum. To this end, we present a novel Spatial-Phase Shallow Learning (SPSL) method, which combines spatial image and phase spectrum to capture the up-sampling artifacts of face forgery to improve the transferability, for face forgery detection. And we also theoretically analyze the validity of utilizing the phase spectrum. Moreover, we notice that local texture information is more crucial than high-level semantic information for the face forgery detection task. So we reduce the receptive fields by shallowing the network to suppress high-level features and focus on the local region. Extensive experiments show that SPSL can achieve the state-of-the-art performance on cross-datasets evaluation as well as multi-class classification and obtain comparable results on single dataset evaluation.
Computation Rate Maximization for Multiuser Mobile Edge Computing Systems With Dynamic Energy Arrivals
Jun 23, 2021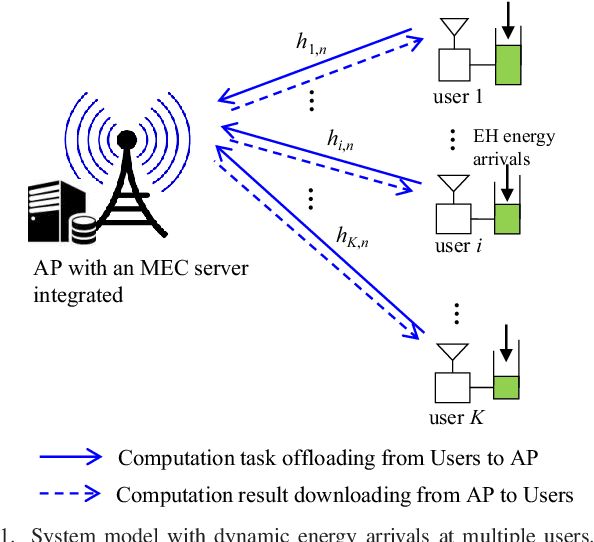
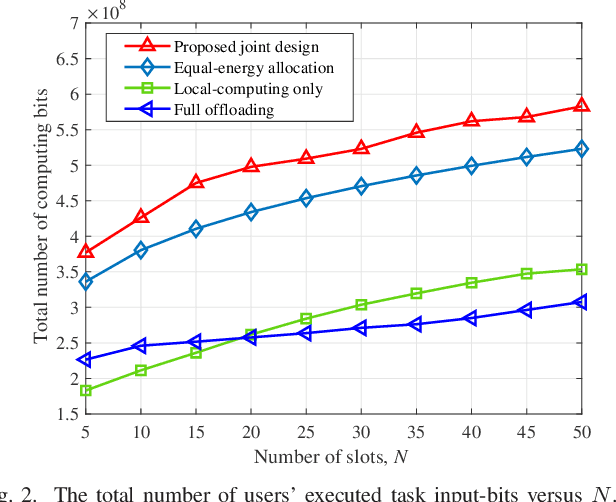
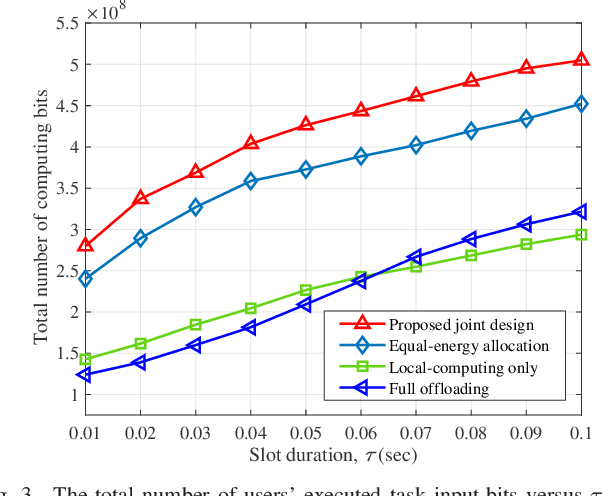
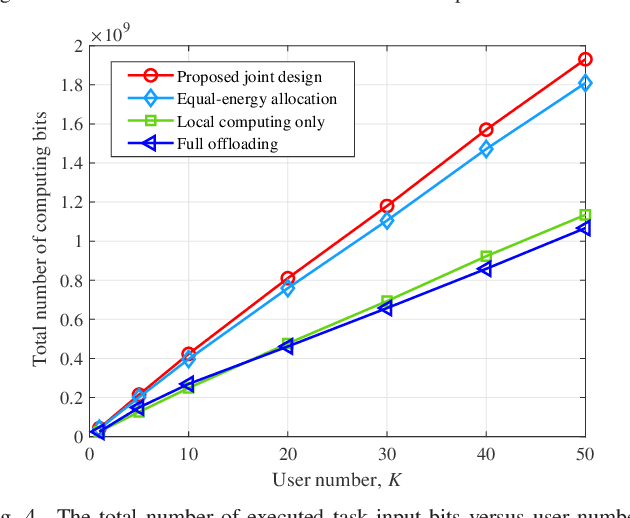
This paper considers an energy harvesting (EH) based multiuser mobile edge computing (MEC) system, where each user utilizes the harvested energy from renewable energy sources to execute its computation tasks via computation offloading and local computing. Towards maximizing the system's weighted computation rate (i.e., the number of weighted users' computing bits within a finite time horizon) subject to the users' energy causality constraints due to dynamic energy arrivals, the decision for joint computation offloading and local computing over time is optimized {\em over time}. Assuming that the profile of channel state information and dynamic task arrivals at the users is known in advance, the weighted computation rate maximization problem becomes a convex optimization problem. Building on the Lagrange duality method, the well-structured optimal solution is analytically obtained. Both the users' local computing and offloading rates are shown to have a monotonically increasing structure. Numerical results show that the proposed design scheme can achieve a significant performance gain over the alternative benchmark schemes.
Passive attention in artificial neural networks predicts human visual selectivity
Jul 14, 2021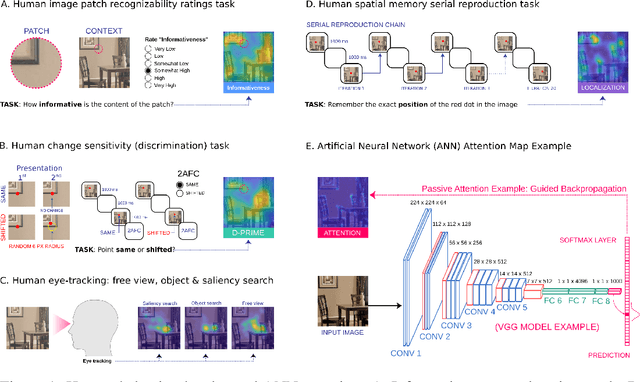
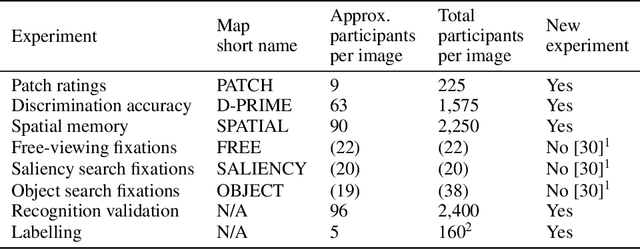
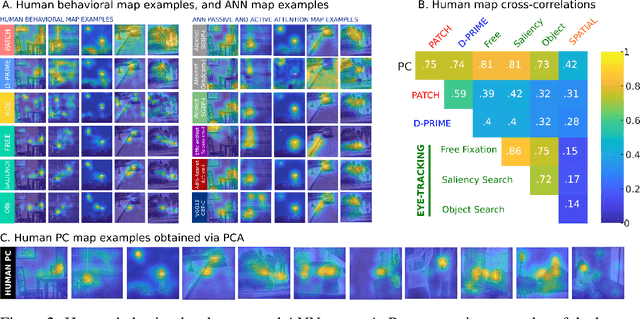
Developments in machine learning interpretability techniques over the past decade have provided new tools to observe the image regions that are most informative for classification and localization in artificial neural networks (ANNs). Are the same regions similarly informative to human observers? Using data from 78 new experiments and 6,610 participants, we show that passive attention techniques reveal a significant overlap with human visual selectivity estimates derived from 6 distinct behavioral tasks including visual discrimination, spatial localization, recognizability, free-viewing, cued-object search, and saliency search fixations. We find that input visualizations derived from relatively simple ANN architectures probed using guided backpropagation methods are the best predictors of a shared component in the joint variability of the human measures. We validate these correlational results with causal manipulations using recognition experiments. We show that images masked with ANN attention maps were easier for humans to classify than control masks in a speeded recognition experiment. Similarly, we find that recognition performance in the same ANN models was likewise influenced by masking input images using human visual selectivity maps. This work contributes a new approach to evaluating the biological and psychological validity of leading ANNs as models of human vision: by examining their similarities and differences in terms of their visual selectivity to the information contained in images.
A LiDAR-Guided Framework for Video Enhancement
Mar 15, 2021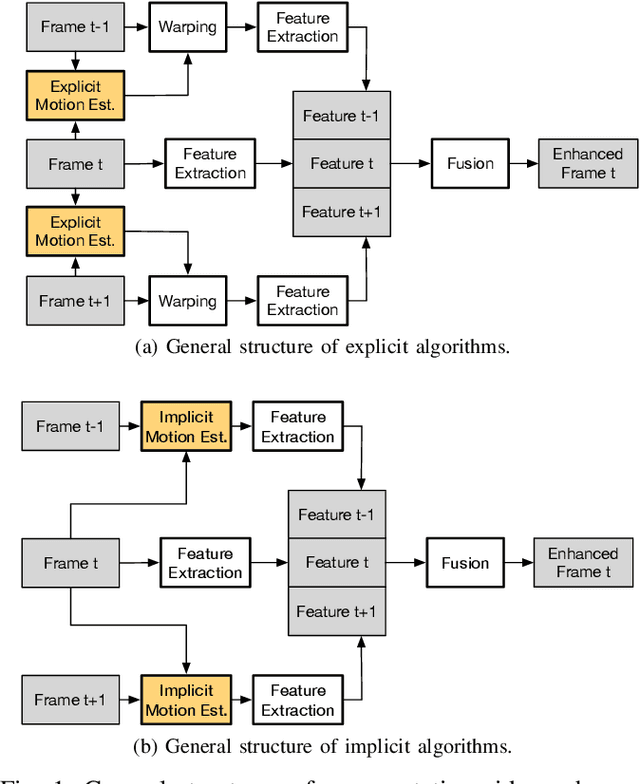

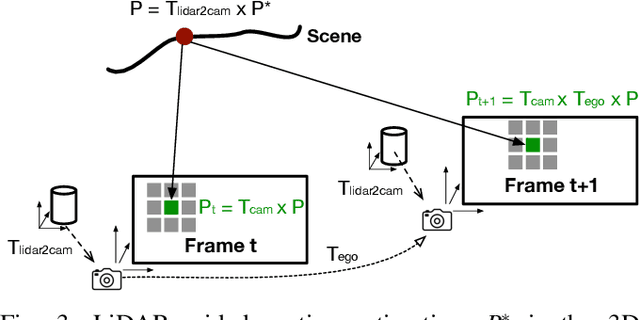

This paper presents a general framework that simultaneously improves the quality and the execution speed of a range of video enhancement tasks, such as super-sampling, deblurring, and denoising. The key to our framework is a pixel motion estimation algorithm that generates accurate motion from low-quality videos while being computationally very lightweight. Our motion estimation algorithm leverages point cloud information, which is readily available in today's autonomous devices and will only become more common in the future. We demonstrate a generic framework that leverages the motion information to guide high-quality image reconstruction. Experiments show that our framework consistently outperforms the state-of-the-art video enhancement algorithms while improving the execution speed by an order of magnitude.
An Analysis of the Value of Information when Exploring Stochastic, Discrete Multi-Armed Bandits
Mar 03, 2018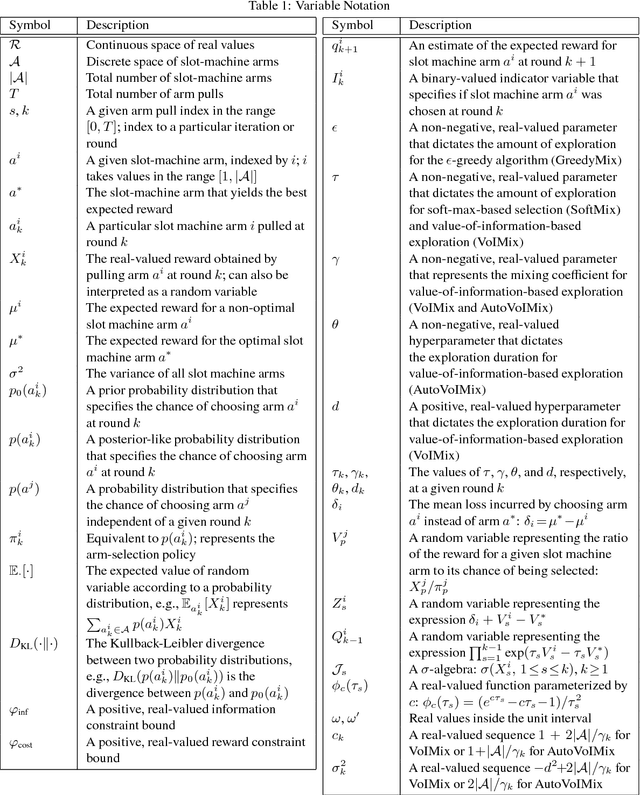
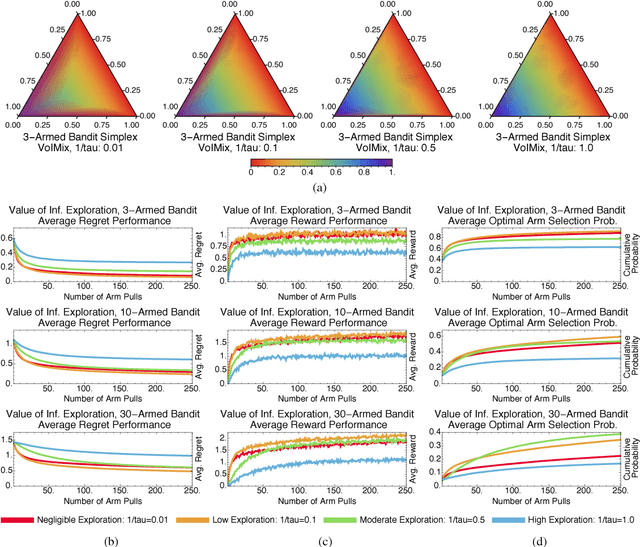
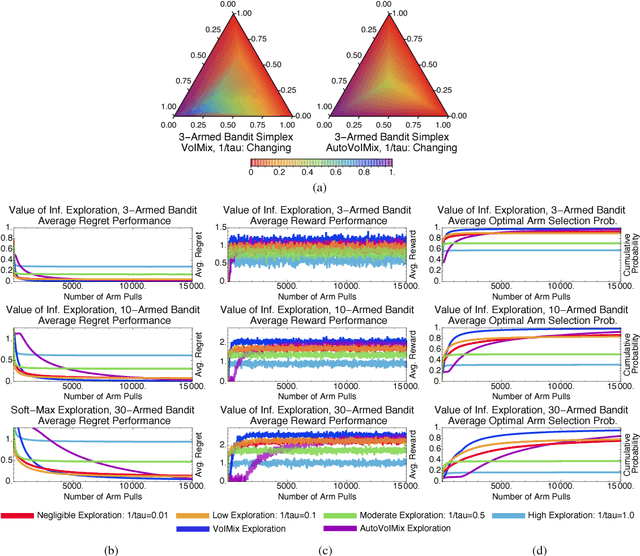
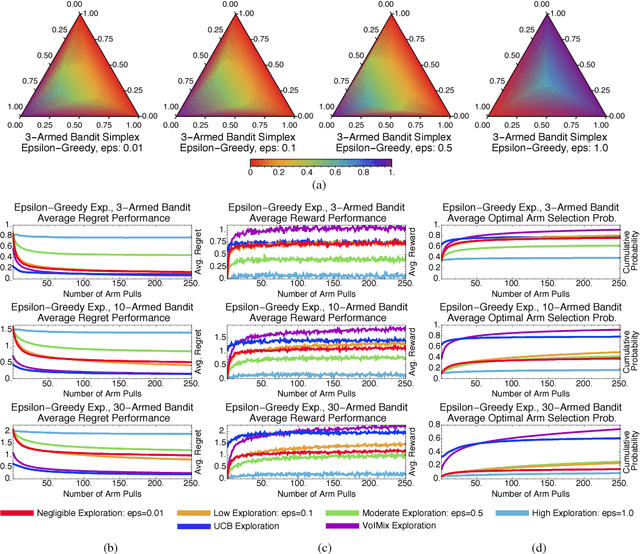
In this paper, we propose an information-theoretic exploration strategy for stochastic, discrete multi-armed bandits that achieves optimal regret. Our strategy is based on the value of information criterion. This criterion measures the trade-off between policy information and obtainable rewards. High amounts of policy information are associated with exploration-dominant searches of the space and yield high rewards. Low amounts of policy information favor the exploitation of existing knowledge. Information, in this criterion, is quantified by a parameter that can be varied during search. We demonstrate that a simulated-annealing-like update of this parameter, with a sufficiently fast cooling schedule, leads to an optimal regret that is logarithmic with respect to the number of episodes.
Multi-Pretext Attention Network for Few-shot Learning with Self-supervision
Mar 10, 2021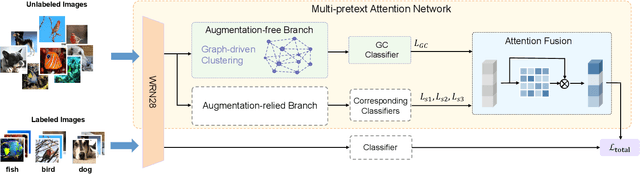
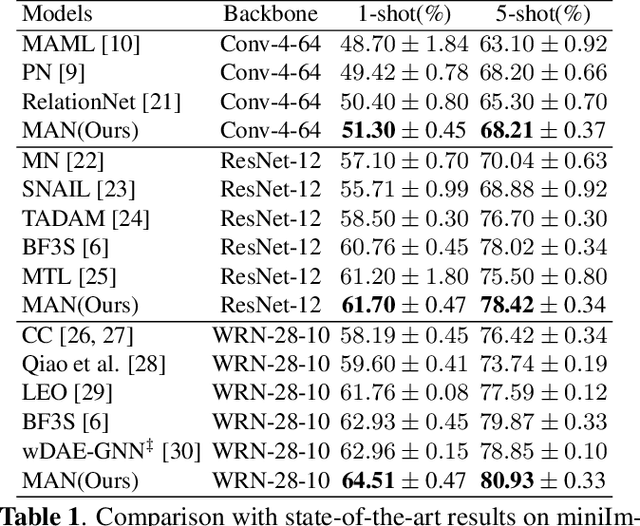
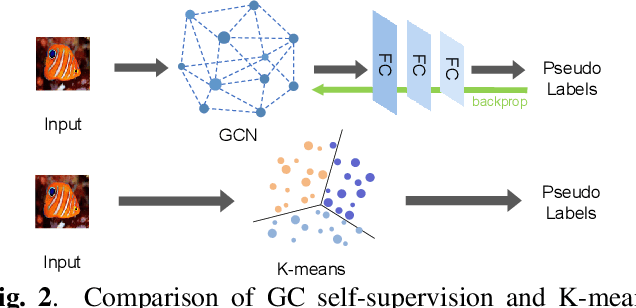
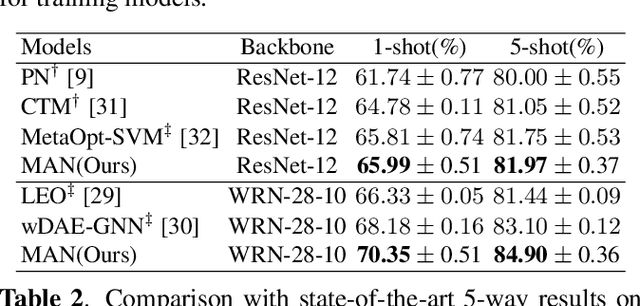
Few-shot learning is an interesting and challenging study, which enables machines to learn from few samples like humans. Existing studies rarely exploit auxiliary information from large amount of unlabeled data. Self-supervised learning is emerged as an efficient method to utilize unlabeled data. Existing self-supervised learning methods always rely on the combination of geometric transformations for the single sample by augmentation, while seriously neglect the endogenous correlation information among different samples that is the same important for the task. In this work, we propose a Graph-driven Clustering (GC), a novel augmentation-free method for self-supervised learning, which does not rely on any auxiliary sample and utilizes the endogenous correlation information among input samples. Besides, we propose Multi-pretext Attention Network (MAN), which exploits a specific attention mechanism to combine the traditional augmentation-relied methods and our GC, adaptively learning their optimized weights to improve the performance and enabling the feature extractor to obtain more universal representations. We evaluate our MAN extensively on miniImageNet and tieredImageNet datasets and the results demonstrate that the proposed method outperforms the state-of-the-art (SOTA) relevant methods.
Disentanglement for audio-visual emotion recognition using multitask setup
Feb 11, 2021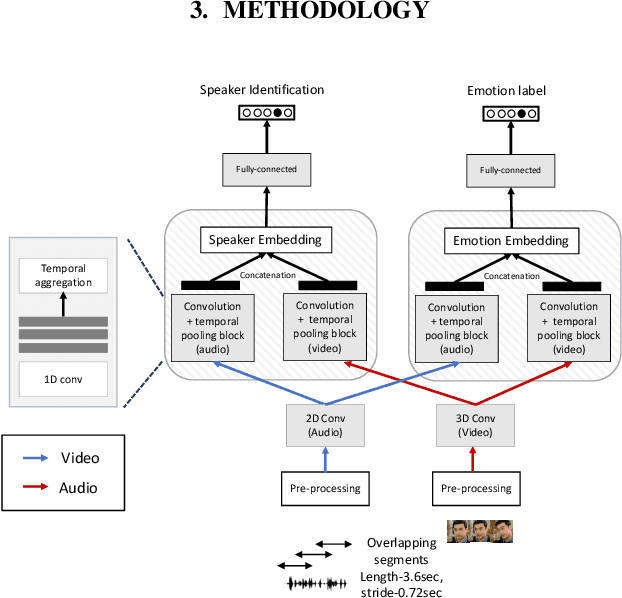
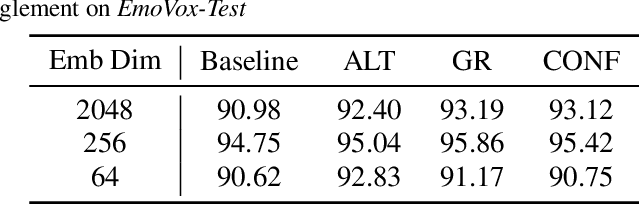
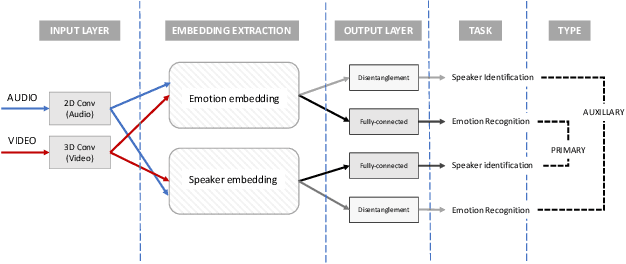
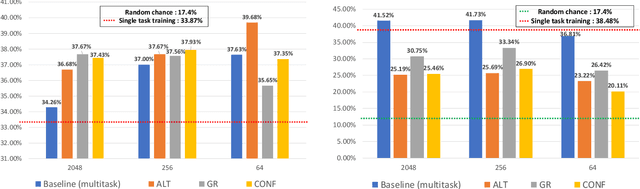
Deep learning models trained on audio-visual data have been successfully used to achieve state-of-the-art performance for emotion recognition. In particular, models trained with multitask learning have shown additional performance improvements. However, such multitask models entangle information between the tasks, encoding the mutual dependencies present in label distributions in the real world data used for training. This work explores the disentanglement of multimodal signal representations for the primary task of emotion recognition and a secondary person identification task. In particular, we developed a multitask framework to extract low-dimensional embeddings that aim to capture emotion specific information, while containing minimal information related to person identity. We evaluate three different techniques for disentanglement and report results of up to 13% disentanglement while maintaining emotion recognition performance.
Progressive Stage-wise Learning for Unsupervised Feature Representation Enhancement
Jun 10, 2021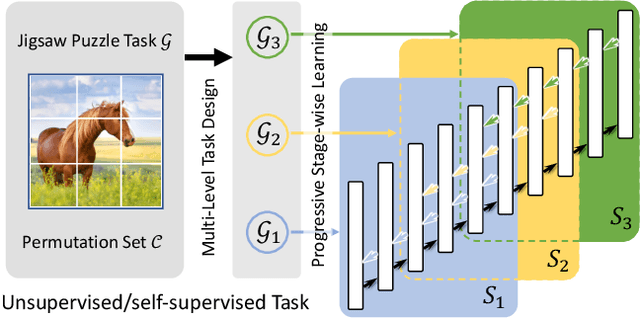

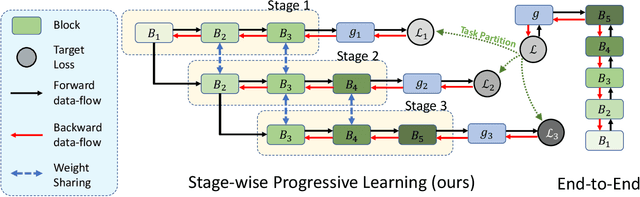
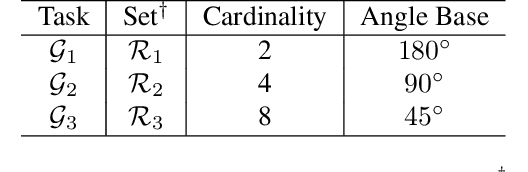
Unsupervised learning methods have recently shown their competitiveness against supervised training. Typically, these methods use a single objective to train the entire network. But one distinct advantage of unsupervised over supervised learning is that the former possesses more variety and freedom in designing the objective. In this work, we explore new dimensions of unsupervised learning by proposing the Progressive Stage-wise Learning (PSL) framework. For a given unsupervised task, we design multilevel tasks and define different learning stages for the deep network. Early learning stages are forced to focus on lowlevel tasks while late stages are guided to extract deeper information through harder tasks. We discover that by progressive stage-wise learning, unsupervised feature representation can be effectively enhanced. Our extensive experiments show that PSL consistently improves results for the leading unsupervised learning methods.