 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Robust and Guided Bayesian Reconstruction of Single-Photon 3D Lidar Data: Application to Multispectral and Underwater Imaging
Mar 18, 2021
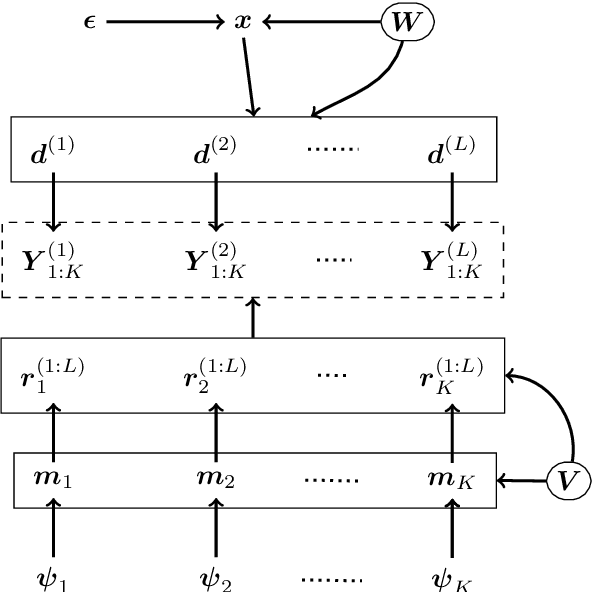
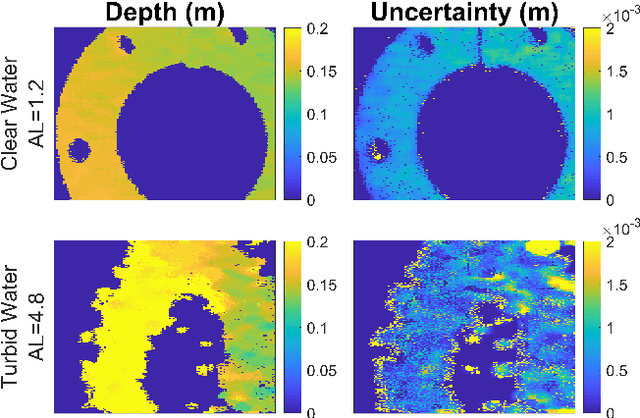

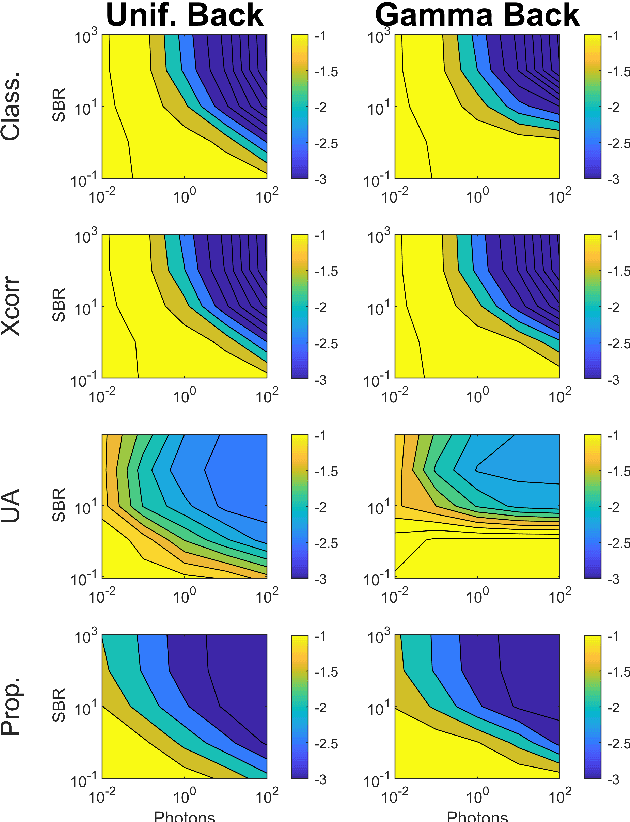
3D Lidar imaging can be a challenging modality when using multiple wavelengths, or when imaging in high noise environments (e.g., imaging through obscurants). This paper presents a hierarchical Bayesian algorithm for the robust reconstruction of multispectral single-photon Lidar data in such environments. The algorithm exploits multi-scale information to provide robust depth and reflectivity estimates together with their uncertainties to help with decision making. The proposed weight-based strategy allows the use of available guide information that can be obtained by using state-of-the-art learning based algorithms. The proposed Bayesian model and its estimation algorithm are validated on both synthetic and real images showing competitive results regarding the quality of the inferences and the computational complexity when compared to the state-of-the-art algorithms.
Bib2vec: An Embedding-based Search System for Bibliographic Information
Apr 05, 2018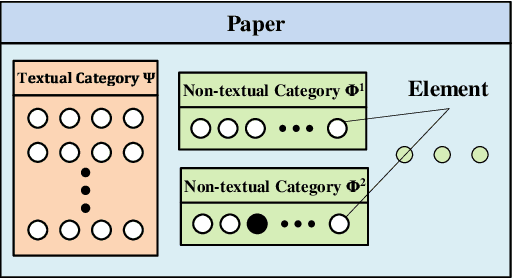
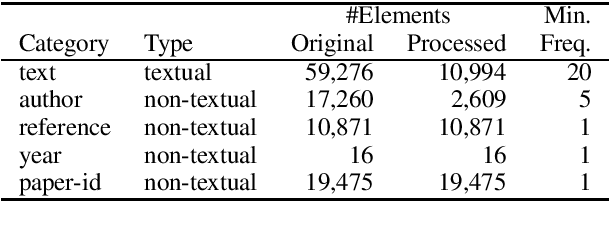
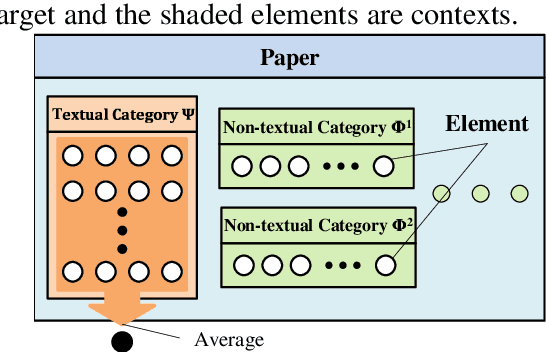
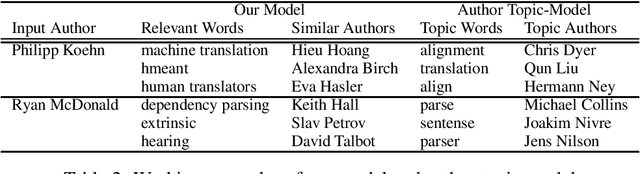
We propose a novel embedding model that represents relationships among several elements in bibliographic information with high representation ability and flexibility. Based on this model, we present a novel search system that shows the relationships among the elements in the ACL Anthology Reference Corpus. The evaluation results show that our model can achieve a high prediction ability and produce reasonable search results.
* EACL2017 extended version. The demonstration is available at http://tti-coin.jp/demo/bib2vec/
Low-dimensional Denoising Embedding Transformer for ECG Classification
Mar 31, 2021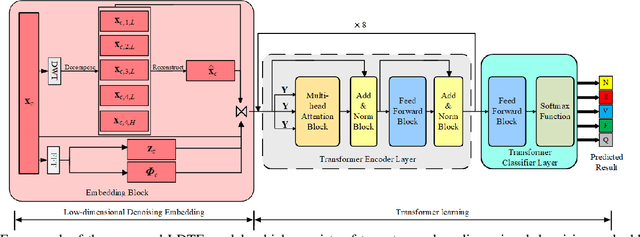

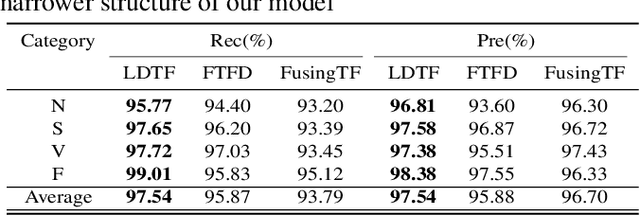
The transformer based model (e.g., FusingTF) has been employed recently for Electrocardiogram (ECG) signal classification. However, the high-dimensional embedding obtained via 1-D convolution and positional encoding can lead to the loss of the signal's own temporal information and a large amount of training parameters. In this paper, we propose a new method for ECG classification, called low-dimensional denoising embedding transformer (LDTF), which contains two components, i.e., low-dimensional denoising embedding (LDE) and transformer learning. In the LDE component, a low-dimensional representation of the signal is obtained in the time-frequency domain while preserving its own temporal information. And with the low dimensional embedding, the transformer learning is then used to obtain a deeper and narrower structure with fewer training parameters than that of the FusingTF. Experiments conducted on the MIT-BIH dataset demonstrates the effectiveness and the superior performance of our proposed method, as compared with state-of-the-art methods.
BRepNet: A topological message passing system for solid models
Apr 08, 2021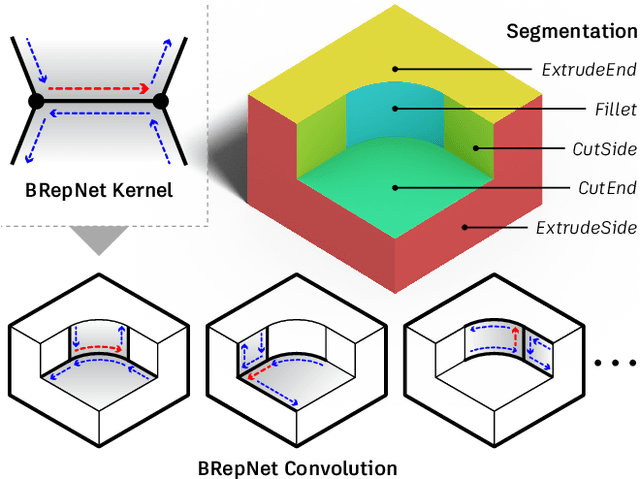


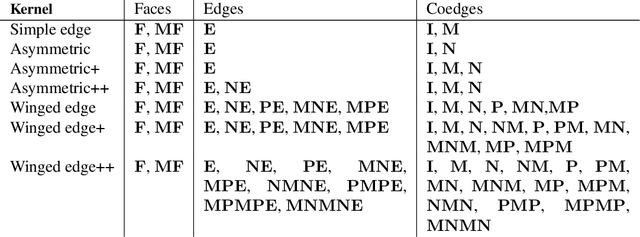
Boundary representation (B-rep) models are the standard way 3D shapes are described in Computer-Aided Design (CAD) applications. They combine lightweight parametric curves and surfaces with topological information which connects the geometric entities to describe manifolds. In this paper we introduce BRepNet, a neural network architecture designed to operate directly on B-rep data structures, avoiding the need to approximate the model as meshes or point clouds. BRepNet defines convolutional kernels with respect to oriented coedges in the data structure. In the neighborhood of each coedge, a small collection of faces, edges and coedges can be identified and patterns in the feature vectors from these entities detected by specific learnable parameters. In addition, to encourage further deep learning research with B-reps, we publish the Fusion 360 Gallery segmentation dataset. A collection of over 35,000 B-rep models annotated with information about the modeling operations which created each face. We demonstrate that BRepNet can segment these models with higher accuracy than methods working on meshes, and point clouds.
Cross-View Exocentric to Egocentric Video Synthesis
Jul 07, 2021
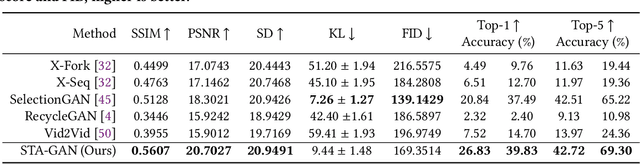
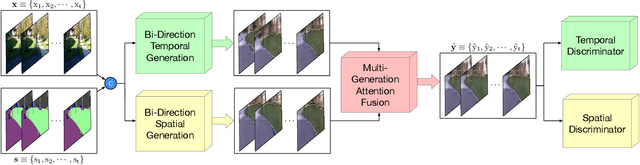
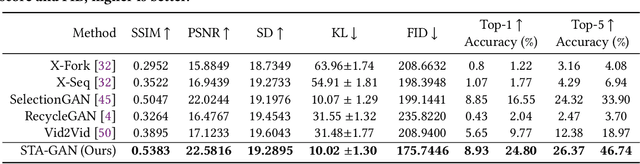
Cross-view video synthesis task seeks to generate video sequences of one view from another dramatically different view. In this paper, we investigate the exocentric (third-person) view to egocentric (first-person) view video generation task. This is challenging because egocentric view sometimes is remarkably different from the exocentric view. Thus, transforming the appearances across the two different views is a non-trivial task. Particularly, we propose a novel Bi-directional Spatial Temporal Attention Fusion Generative Adversarial Network (STA-GAN) to learn both spatial and temporal information to generate egocentric video sequences from the exocentric view. The proposed STA-GAN consists of three parts: temporal branch, spatial branch, and attention fusion. First, the temporal and spatial branches generate a sequence of fake frames and their corresponding features. The fake frames are generated in both downstream and upstream directions for both temporal and spatial branches. Next, the generated four different fake frames and their corresponding features (spatial and temporal branches in two directions) are fed into a novel multi-generation attention fusion module to produce the final video sequence. Meanwhile, we also propose a novel temporal and spatial dual-discriminator for more robust network optimization. Extensive experiments on the Side2Ego and Top2Ego datasets show that the proposed STA-GAN significantly outperforms the existing methods.
Federated Learning for Multi-Center Imaging Diagnostics: A Study in Cardiovascular Disease
Jul 07, 2021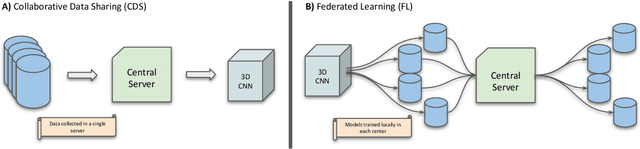

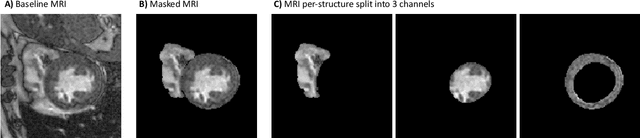

Deep learning models can enable accurate and efficient disease diagnosis, but have thus far been hampered by the data scarcity present in the medical world. Automated diagnosis studies have been constrained by underpowered single-center datasets, and although some results have shown promise, their generalizability to other institutions remains questionable as the data heterogeneity between institutions is not taken into account. By allowing models to be trained in a distributed manner that preserves patients' privacy, federated learning promises to alleviate these issues, by enabling diligent multi-center studies. We present the first federated learning study on the modality of cardiovascular magnetic resonance (CMR) and use four centers derived from subsets of the M\&M and ACDC datasets, focusing on the diagnosis of hypertrophic cardiomyopathy (HCM). We adapt a 3D-CNN network pretrained on action recognition and explore two different ways of incorporating shape prior information to the model, and four different data augmentation set-ups, systematically analyzing their impact on the different collaborative learning choices. We show that despite the small size of data (180 subjects derived from four centers), the privacy preserving federated learning achieves promising results that are competitive with traditional centralized learning. We further find that federatively trained models exhibit increased robustness and are more sensitive to domain shift effects.
Can Less be More? When Increasing-to-Balancing Label Noise Rates Considered Beneficial
Jul 13, 2021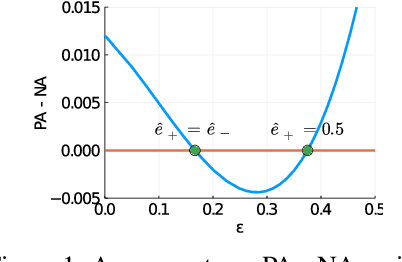
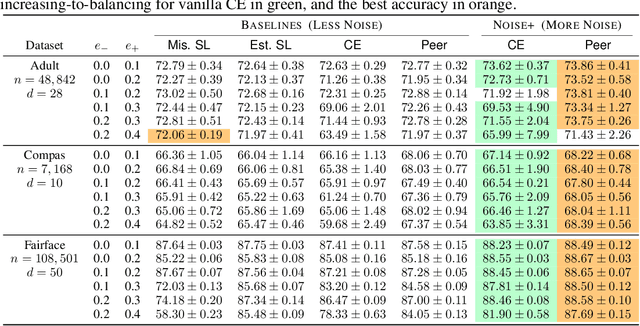

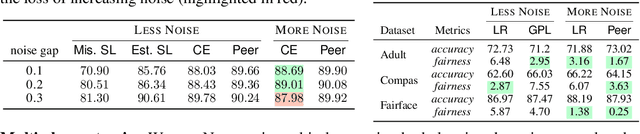
In this paper, we answer the question when inserting label noise (less informative labels) can instead return us more accurate and fair models. We are primarily inspired by two observations that 1) increasing a certain class of instances' label noise to balance the noise rates (increasing-to-balancing) results in an easier learning problem; 2) Increasing-to-balancing improves fairness guarantees against label bias. In this paper, we will first quantify the trade-offs introduced by increasing a certain group of instances' label noise rate w.r.t. the learning difficulties and performance guarantees. We analytically demonstrate when such an increase proves to be beneficial, in terms of either improved generalization errors or the fairness guarantees. Then we present a method to leverage our idea of inserting label noise for the task of learning with noisy labels, either without or with a fairness constraint. The primary technical challenge we face is due to the fact that we would not know which data instances are suffering from higher noise, and we would not have the ground truth labels to verify any possible hypothesis. We propose a detection method that informs us which group of labels might suffer from higher noise, without using ground truth information. We formally establish the effectiveness of the proposed solution and demonstrate it with extensive experiments.
Fundamental Limits of Reinforcement Learning in Environment with Endogeneous and Exogeneous Uncertainty
Jun 15, 2021Online reinforcement learning (RL) has been widely applied in information processing scenarios, which usually exhibit much uncertainty due to the intrinsic randomness of channels and service demands. In this paper, we consider an un-discounted RL in general Markov decision processes (MDPs) with both endogeneous and exogeneous uncertainty, where both the rewards and state transition probability are unknown to the RL agent and evolve with the time as long as their respective variations do not exceed certain dynamic budget (i.e., upper bound). We first develop a variation-aware Bernstein-based upper confidence reinforcement learning (VB-UCRL), which we allow to restart according to a schedule dependent on the variations. We successfully overcome the challenges due to the exogeneous uncertainty and establish a regret bound of saving at most $\sqrt{S}$ or $S^{\frac{1}{6}}T^{\frac{1}{12}}$ compared with the latest results in the literature, where $S$ denotes the state size of the MDP and $T$ indicates the iteration index of learning steps.
Rate and Power Adaptation for Multihop Regenerative Relaying Systems
Jun 15, 2021
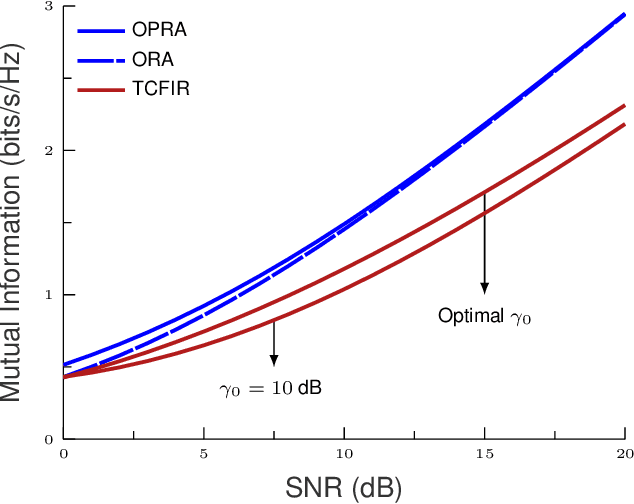
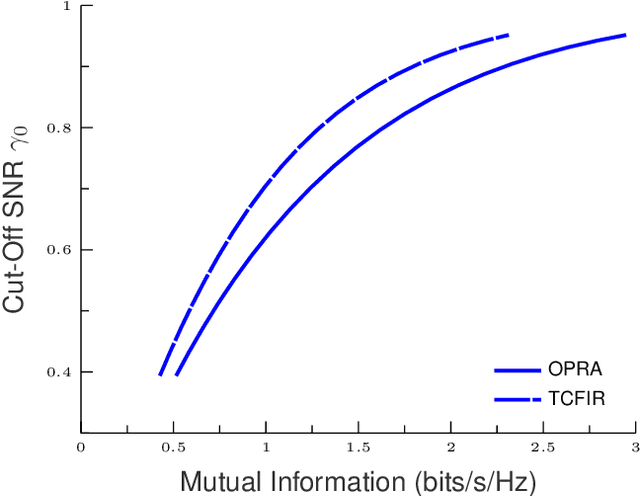
In this work, we provide a global framework analysis of a multi-hop relaying systems wherein the transmitter (TX) communicates with the receiver (RX) through a set of intermediary relays deployed either in series or in parallel. Regenerative based relaying scheme is assumed such as the repetition-coded decoded-and-forward (DF) wherein the decoding is threshold-based. To reflect a wide range of fading, we introduce the generalized $H$-function (also termed as Fox-$H$ function) distribution model which enables the modeling of radio-frequency (RF) fading like Weibull and Gamma, as well as the free-space optic (FSO) such as the Double Generalized Gamma and M\'alaga fading. In this context, we introduce various power and rate adaptation policies based on the channel state information (CSI) availability at TX and RX. Finally, we address the effects of relaying topology, number of relays and fading model, etc, on the performance reliability of each link adaptation policy.
On the Importance of Subword Information for Morphological Tasks in Truly Low-Resource Languages
Sep 26, 2019
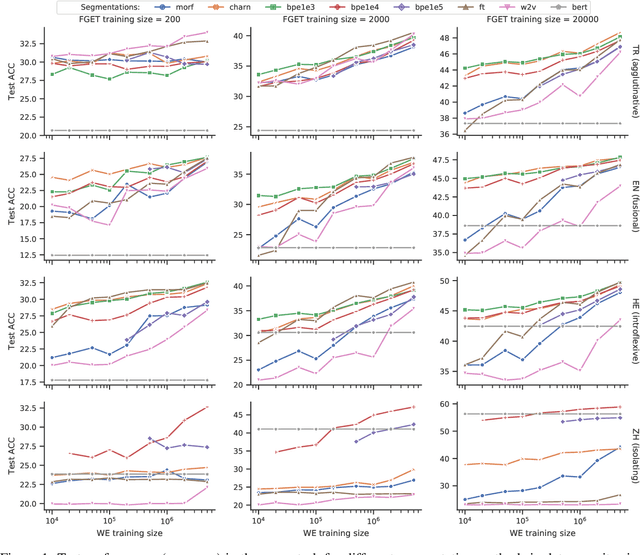
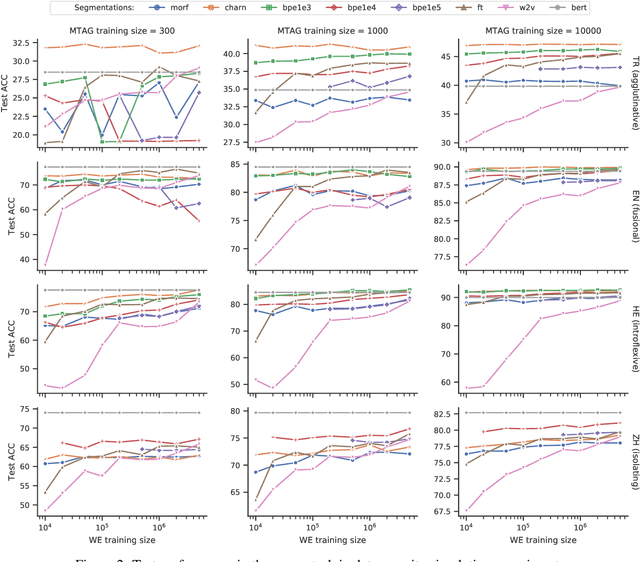
Recent work has validated the importance of subword information for word representation learning. Since subwords increase parameter sharing ability in neural models, their value should be even more pronounced in low-data regimes. In this work, we therefore provide a comprehensive analysis focused on the usefulness of subwords for word representation learning in truly low-resource scenarios and for three representative morphological tasks: fine-grained entity typing, morphological tagging, and named entity recognition. We conduct a systematic study that spans several dimensions of comparison: 1) type of data scarcity which can stem from the lack of task-specific training data, or even from the lack of unannotated data required to train word embeddings, or both; 2) language type by working with a sample of 16 typologically diverse languages including some truly low-resource ones (e.g. Rusyn, Buryat, and Zulu); 3) the choice of the subword-informed word representation method. Our main results show that subword-informed models are universally useful across all language types, with large gains over subword-agnostic embeddings. They also suggest that the effective use of subwords largely depends on the language (type) and the task at hand, as well as on the amount of available data for training the embeddings and task-based models, where having sufficient in-task data is a more critical requirement.