 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Attribute Selection using Contranominal Scales
Jul 01, 2021
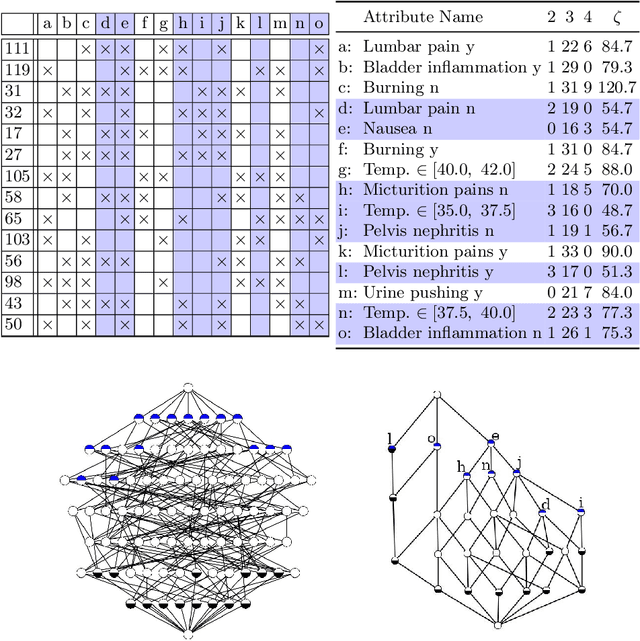
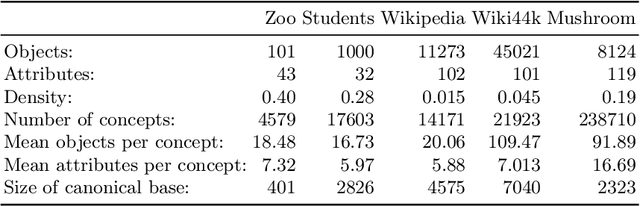
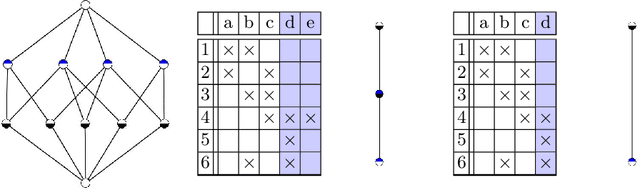
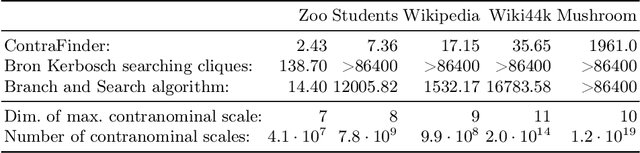
Formal Concept Analysis (FCA) allows to analyze binary data by deriving concepts and ordering them in lattices. One of the main goals of FCA is to enable humans to comprehend the information that is encapsulated in the data; however, the large size of concept lattices is a limiting factor for the feasibility of understanding the underlying structural properties. The size of such a lattice depends on the number of subcontexts in the corresponding formal context that are isomorphic to a contranominal scale of high dimension. In this work, we propose the algorithm ContraFinder that enables the computation of all contranominal scales of a given formal context. Leveraging this algorithm, we introduce delta-adjusting, a novel approach in order to decrease the number of contranominal scales in a formal context by the selection of an appropriate attribute subset. We demonstrate that delta-adjusting a context reduces the size of the hereby emerging sub-semilattice and that the implication set is restricted to meaningful implications. This is evaluated with respect to its associated knowledge by means of a classification task. Hence, our proposed technique strongly improves understandability while preserving important conceptual structures.
Modelling Neuronal Behaviour with Time Series Regression: Recurrent Neural Networks on C. Elegans Data
Jul 01, 2021

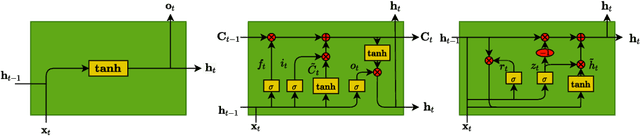
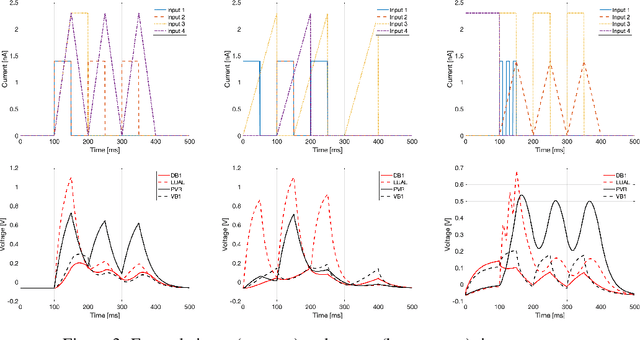
Given the inner complexity of the human nervous system, insight into the dynamics of brain activity can be gained from understanding smaller and simpler organisms, such as the nematode C. Elegans. The behavioural and structural biology of these organisms is well-known, making them prime candidates for benchmarking modelling and simulation techniques. In these complex neuronal collections, classical, white-box modelling techniques based on intrinsic structural or behavioural information are either unable to capture the profound nonlinearities of the neuronal response to different stimuli or generate extremely complex models, which are computationally intractable. In this paper we show how the nervous system of C. Elegans can be modelled and simulated with data-driven models using different neural network architectures. Specifically, we target the use of state of the art recurrent neural networks architectures such as LSTMs and GRUs and compare these architectures in terms of their properties and their accuracy as well as the complexity of the resulting models. We show that GRU models with a hidden layer size of 4 units are able to accurately reproduce with high accuracy the system's response to very different stimuli.
Is Sluice Resolution really just Question Answering?
May 29, 2021
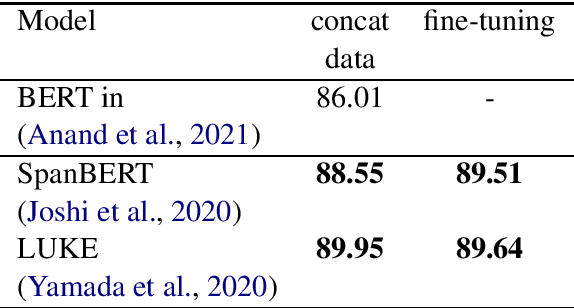
Sluice resolution is a problem where a system needs to output the corresponding antecedents of wh-ellipses. The antecedents are elided contents behind the wh-words but are implicitly referred to using contexts. Previous work frames sluice resolution as question answering where this setting outperforms all its preceding works by large margins. Ellipsis and questions are referentially dependent expressions (anaphoras) and retrieving the corresponding antecedents are like answering questions to output pieces of clarifying information. However, the task is not fully solved. Therefore, we want to further investigate what makes sluice resolution differ to question answering and fill in the error gaps. We also present some results using recent state-of-the-art question answering systems which improve the previous work (86.01 to 90.39 F1).
A Global to Local Double Embedding Method for Multi-person Pose Estimation
Feb 15, 2021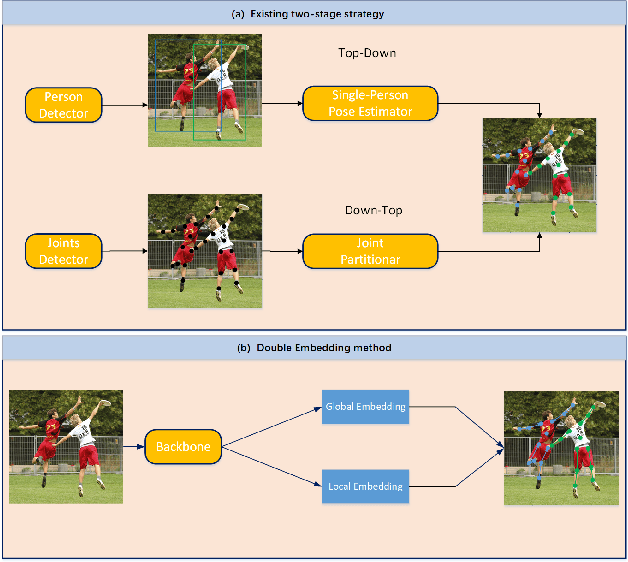
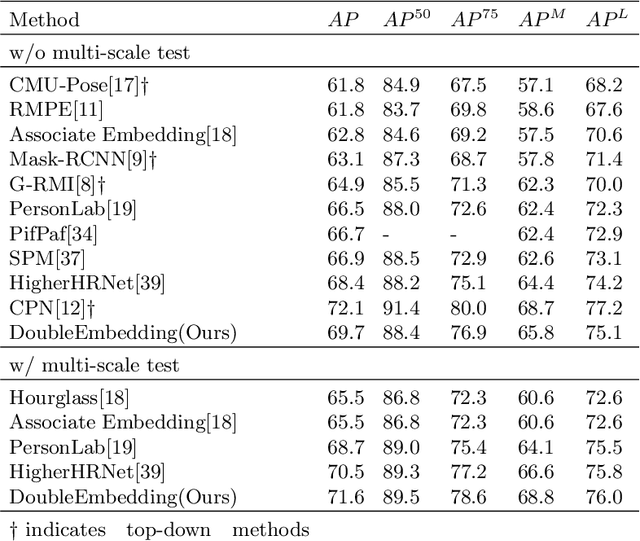
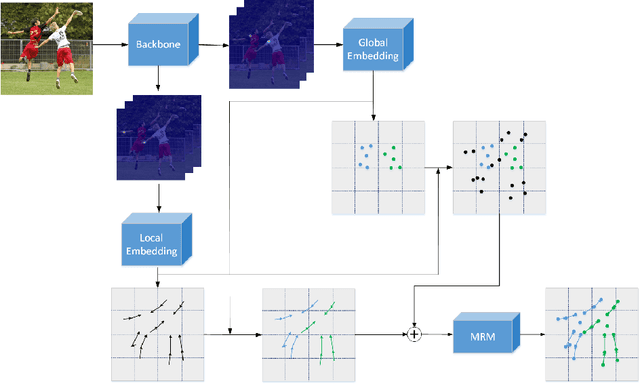
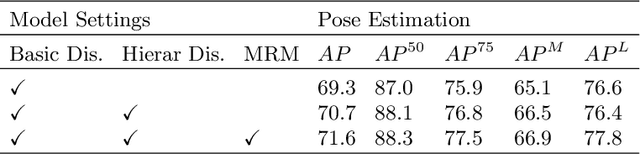
Multi-person pose estimation is a fundamental and challenging problem to many computer vision tasks. Most existing methods can be broadly categorized into two classes: top-down and bottom-up methods. Both of the two types of methods involve two stages, namely, person detection and joints detection. Conventionally, the two stages are implemented separately without considering their interactions between them, and this may inevitably cause some issue intrinsically. In this paper, we present a novel method to simplify the pipeline by implementing person detection and joints detection simultaneously. We propose a Double Embedding (DE) method to complete the multi-person pose estimation task in a global-to-local way. DE consists of Global Embedding (GE) and Local Embedding (LE). GE encodes different person instances and processes information covering the whole image and LE encodes the local limbs information. GE functions for the person detection in top-down strategy while LE connects the rest joints sequentially which functions for joint grouping and information processing in A bottom-up strategy. Based on LE, we design the Mutual Refine Machine (MRM) to reduce the prediction difficulty in complex scenarios. MRM can effectively realize the information communicating between keypoints and further improve the accuracy. We achieve the competitive results on benchmarks MSCOCO, MPII and CrowdPose, demonstrating the effectiveness and generalization ability of our method.
An audiovisual and contextual approach for categorical and continuous emotion recognition in-the-wild
Jul 07, 2021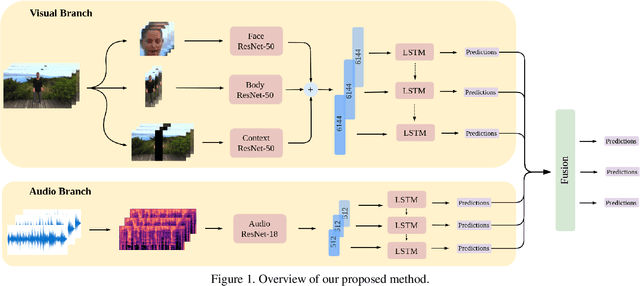
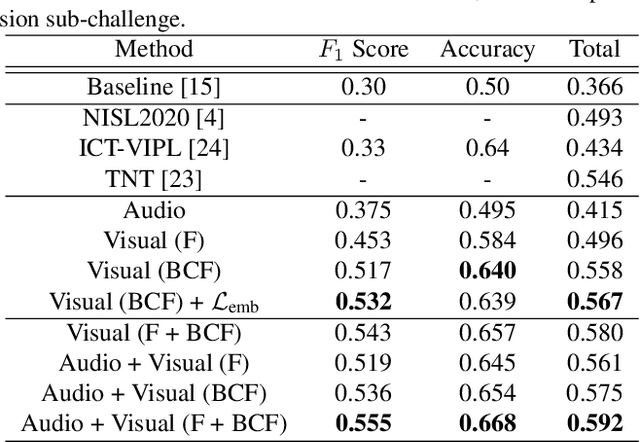
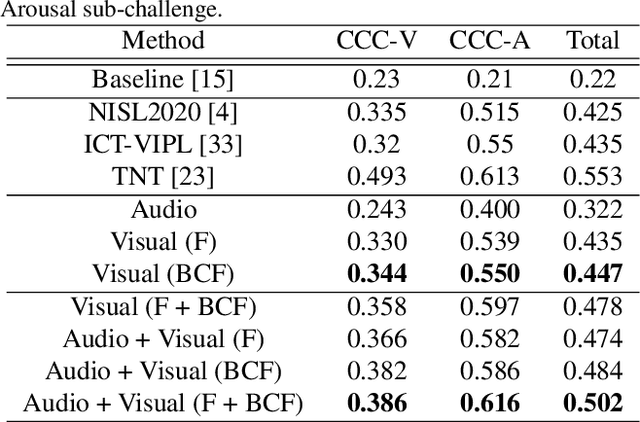
In this work we tackle the task of video-based audio-visual emotion recognition, within the premises of the 2nd Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW). Standard methodologies that rely solely on the extraction of facial features often fall short of accurate emotion prediction in cases where the aforementioned source of affective information is inaccessible due to head/body orientation, low resolution and poor illumination. We aspire to alleviate this problem by leveraging bodily as well as contextual features, as part of a broader emotion recognition framework. A standard CNN-RNN cascade constitutes the backbone of our proposed model for sequence-to-sequence (seq2seq) learning. Apart from learning through the \textit{RGB} input modality, we construct an aural stream which operates on sequences of extracted mel-spectrograms. Our extensive experiments on the challenging and newly assembled Affect-in-the-wild-2 (Aff-Wild2) dataset verify the superiority of our methods over existing approaches, while by properly incorporating all of the aforementioned modules in a network ensemble, we manage to surpass the previous best published recognition scores, in the official validation set. All the code was implemented using PyTorch\footnote{\url{https://pytorch.org/}} and is publicly available\footnote{\url{https://github.com/PanosAntoniadis/NTUA-ABAW2021}}.
LSTM-Based Predictions for Proactive Information Retrieval
Jun 20, 2016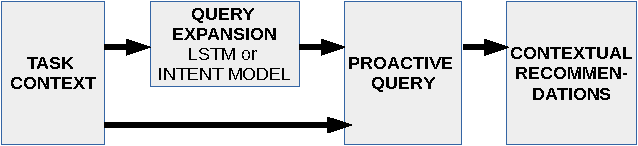

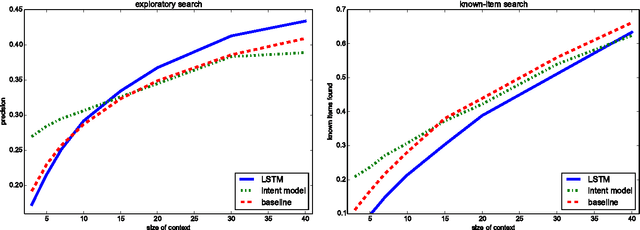
We describe a method for proactive information retrieval targeted at retrieving relevant information during a writing task. In our method, the current task and the needs of the user are estimated, and the potential next steps are unobtrusively predicted based on the user's past actions. We focus on the task of writing, in which the user is coalescing previously collected information into a text. Our proactive system automatically recommends the user relevant background information. The proposed system incorporates text input prediction using a long short-term memory (LSTM) network. We present simulations, which show that the system is able to reach higher precision values in an exploratory search setting compared to both a baseline and a comparison system.
Learning the Next Best View for 3D Point Clouds via Topological Features
Mar 04, 2021

In this paper, we introduce a reinforcement learning approach utilizing a novel topology-based information gain metric for directing the next best view of a noisy 3D sensor. The metric combines the disjoint sections of an observed surface to focus on high-detail features such as holes and concave sections. Experimental results show that our approach can aid in establishing the placement of a robotic sensor to optimize the information provided by its streaming point cloud data. Furthermore, a labeled dataset of 3D objects, a CAD design for a custom robotic manipulator, and software for the transformation, union, and registration of point clouds has been publicly released to the research community.
E-DSSR: Efficient Dynamic Surgical Scene Reconstruction with Transformer-based Stereoscopic Depth Perception
Jul 01, 2021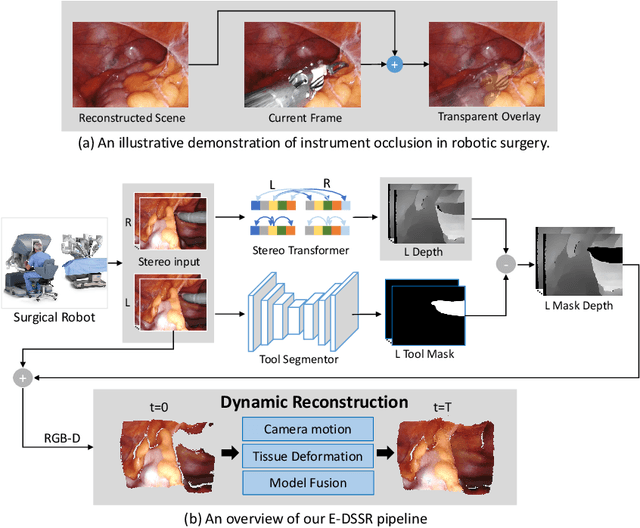
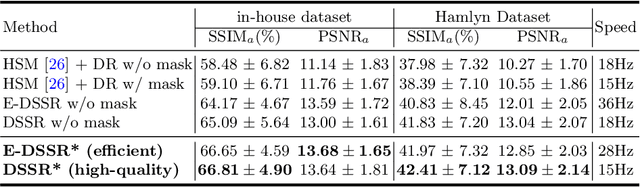
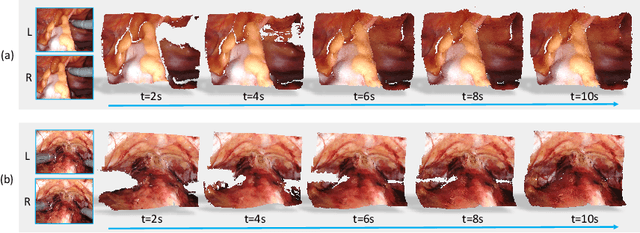
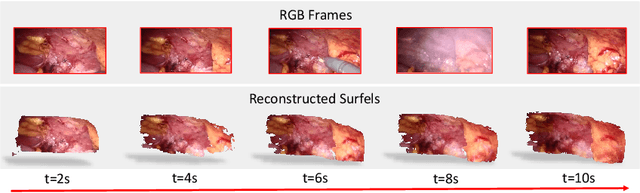
Reconstructing the scene of robotic surgery from the stereo endoscopic video is an important and promising topic in surgical data science, which potentially supports many applications such as surgical visual perception, robotic surgery education and intra-operative context awareness. However, current methods are mostly restricted to reconstructing static anatomy assuming no tissue deformation, tool occlusion and de-occlusion, and camera movement. However, these assumptions are not always satisfied in minimal invasive robotic surgeries. In this work, we present an efficient reconstruction pipeline for highly dynamic surgical scenes that runs at 28 fps. Specifically, we design a transformer-based stereoscopic depth perception for efficient depth estimation and a light-weight tool segmentor to handle tool occlusion. After that, a dynamic reconstruction algorithm which can estimate the tissue deformation and camera movement, and aggregate the information over time is proposed for surgical scene reconstruction. We evaluate the proposed pipeline on two datasets, the public Hamlyn Centre Endoscopic Video Dataset and our in-house DaVinci robotic surgery dataset. The results demonstrate that our method can recover the scene obstructed by the surgical tool and handle the movement of camera in realistic surgical scenarios effectively at real-time speed.
Exploiting temporal information for 3D pose estimation
Sep 12, 2018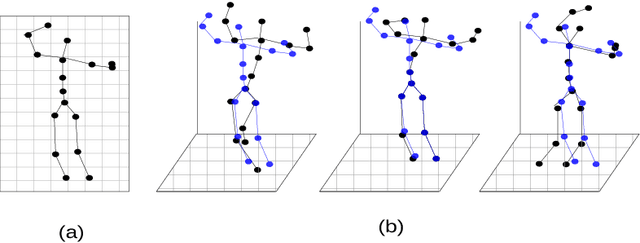
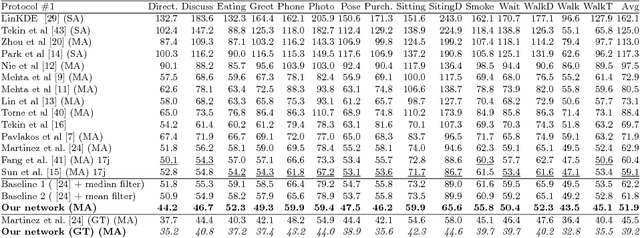
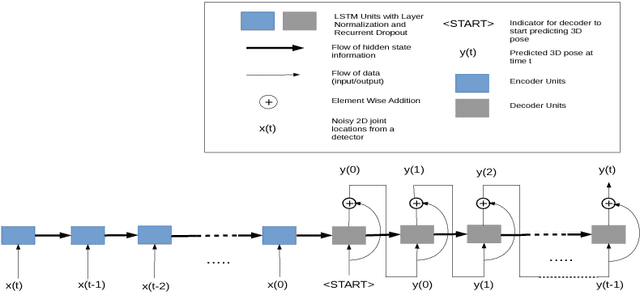
In this work, we address the problem of 3D human pose estimation from a sequence of 2D human poses. Although the recent success of deep networks has led many state-of-the-art methods for 3D pose estimation to train deep networks end-to-end to predict from images directly, the top-performing approaches have shown the effectiveness of dividing the task of 3D pose estimation into two steps: using a state-of-the-art 2D pose estimator to estimate the 2D pose from images and then mapping them into 3D space. They also showed that a low-dimensional representation like 2D locations of a set of joints can be discriminative enough to estimate 3D pose with high accuracy. However, estimation of 3D pose for individual frames leads to temporally incoherent estimates due to independent error in each frame causing jitter. Therefore, in this work we utilize the temporal information across a sequence of 2D joint locations to estimate a sequence of 3D poses. We designed a sequence-to-sequence network composed of layer-normalized LSTM units with shortcut connections connecting the input to the output on the decoder side and imposed temporal smoothness constraint during training. We found that the knowledge of temporal consistency improves the best reported result on Human3.6M dataset by approximately $12.2\%$ and helps our network to recover temporally consistent 3D poses over a sequence of images even when the 2D pose detector fails.
DTGAN: Differential Private Training for Tabular GANs
Aug 02, 2021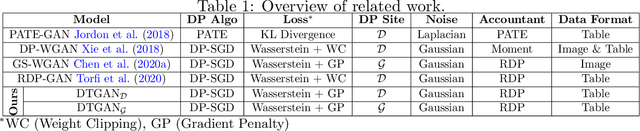
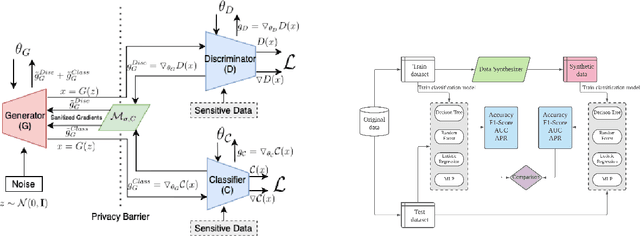

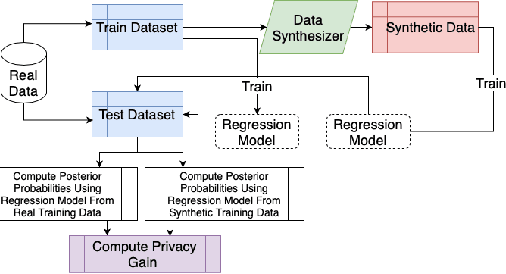
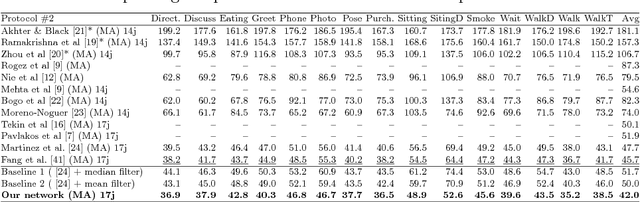
Tabular generative adversarial networks (TGAN) have recently emerged to cater to the need of synthesizing tabular data -- the most widely used data format. While synthetic tabular data offers the advantage of complying with privacy regulations, there still exists a risk of privacy leakage via inference attacks due to interpolating the properties of real data during training. Differential private (DP) training algorithms provide theoretical guarantees for training machine learning models by injecting statistical noise to prevent privacy leaks. However, the challenges of applying DP on TGAN are to determine the most optimal framework (i.e., PATE/DP-SGD) and neural network (i.e., Generator/Discriminator)to inject noise such that the data utility is well maintained under a given privacy guarantee. In this paper, we propose DTGAN, a novel conditional Wasserstein tabular GAN that comes in two variants DTGAN_G and DTGAN_D, for providing a detailed comparison of tabular GANs trained using DP-SGD for the generator vs discriminator, respectively. We elicit the privacy analysis associated with training the generator with complex loss functions (i.e., classification and information losses) needed for high quality tabular data synthesis. Additionally, we rigorously evaluate the theoretical privacy guarantees offered by DP empirically against membership and attribute inference attacks. Our results on 3 datasets show that the DP-SGD framework is superior to PATE and that a DP discriminator is more optimal for training convergence. Thus, we find (i) DTGAN_D is capable of maintaining the highest data utility across 4 ML models by up to 18% in terms of the average precision score for a strict privacy budget, epsilon = 1, as compared to the prior studies and (ii) DP effectively prevents privacy loss against inference attacks by restricting the success probability of membership attacks to be close to 50%.