 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Video Super-Resolution with Long-Term Self-Exemplars
Jun 24, 2021
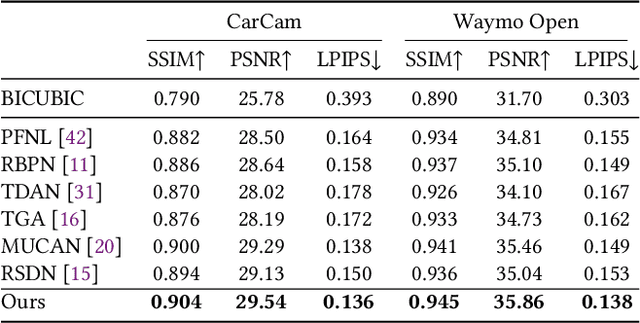
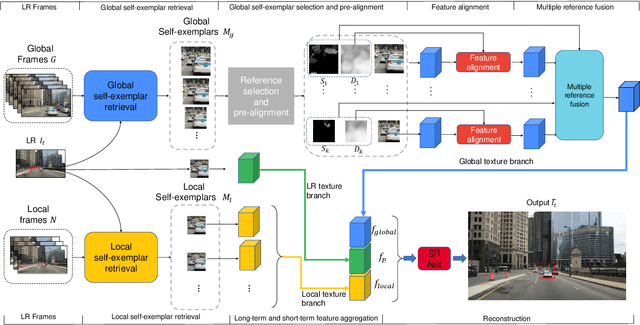
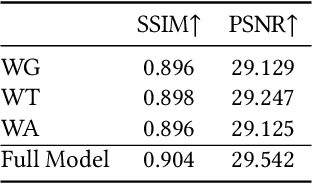

Existing video super-resolution methods often utilize a few neighboring frames to generate a higher-resolution image for each frame. However, the redundant information between distant frames has not been fully exploited in these methods: corresponding patches of the same instance appear across distant frames at different scales. Based on this observation, we propose a video super-resolution method with long-term cross-scale aggregation that leverages similar patches (self-exemplars) across distant frames. Our model also consists of a multi-reference alignment module to fuse the features derived from similar patches: we fuse the features of distant references to perform high-quality super-resolution. We also propose a novel and practical training strategy for referenced-based super-resolution. To evaluate the performance of our proposed method, we conduct extensive experiments on our collected CarCam dataset and the Waymo Open dataset, and the results demonstrate our method outperforms state-of-the-art methods. Our source code will be publicly available.
Arithmetic Distribution Neural Network for Background Subtraction
Apr 16, 2021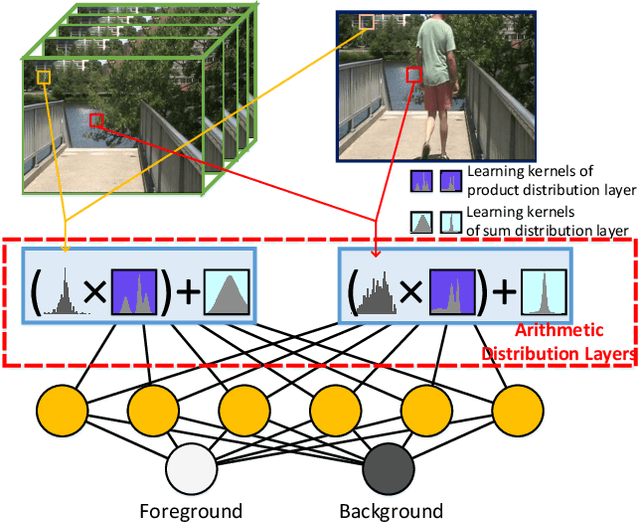
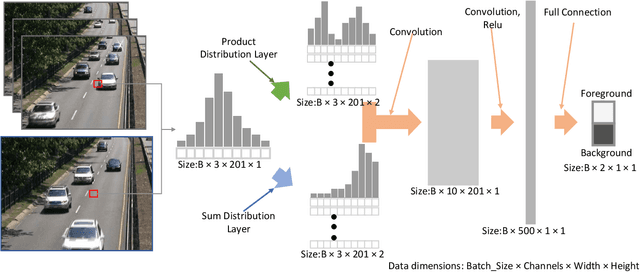
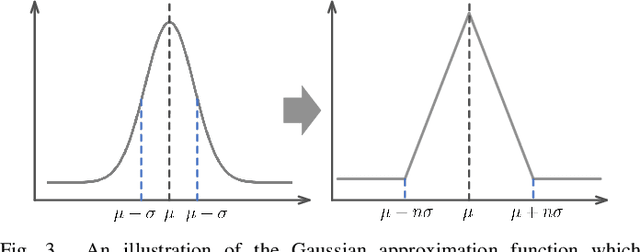
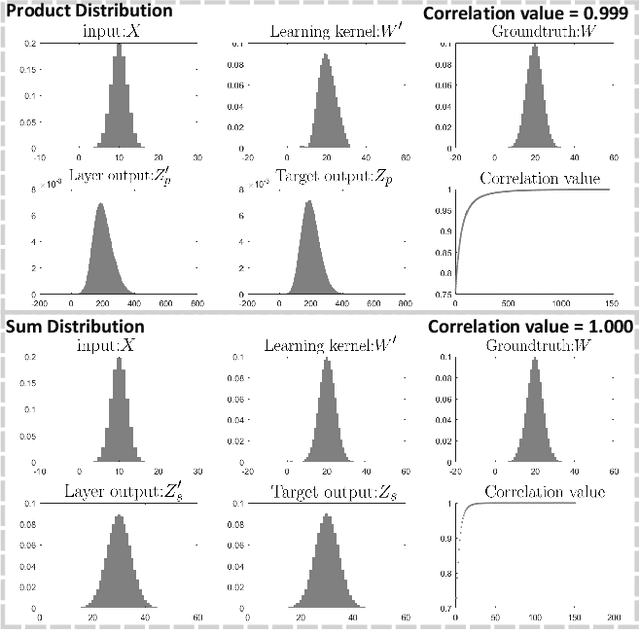
We propose a new Arithmetic Distribution Neural Network (ADNN) for learning the distributions of temporal pixels during background subtraction. In our ADNN, the arithmetic distribution operations are utilized to propose the arithmetic distribution layers, including the product distribution layer and the sum distribution layer. Furthermore, in order to improve the accuracy of the proposed approach, an improved Bayesian refinement model based on neighboring information, with a GPU implementation, is introduced. In the forward pass and backpropagation of the proposed arithmetic distribution layers, histograms are considered as probability density functions rather than matrices. Thus, the proposed approach is able to utilize the probability information of the histogram and achieve promising results with a very simple architecture compared to traditional convolutional neural networks. Evaluations using standard benchmarks demonstrate the superiority of the proposed approach compared to state-of-the-art traditional and deep learning methods. To the best of our knowledge, this is the first method to propose network layers based on arithmetic distribution operations for learning distributions during background subtraction.
Using spatial-temporal ensembles of convolutional neural networks for lumen segmentation in ureteroscopy
Apr 05, 2021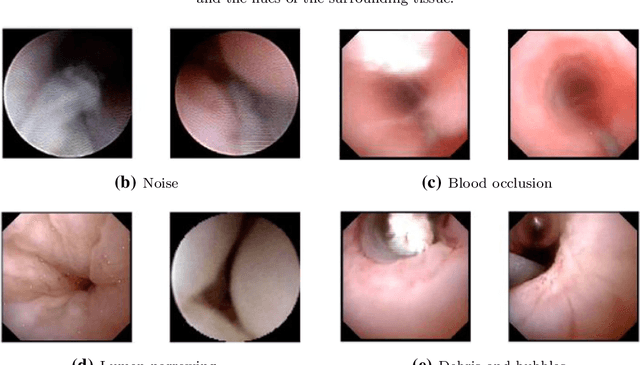
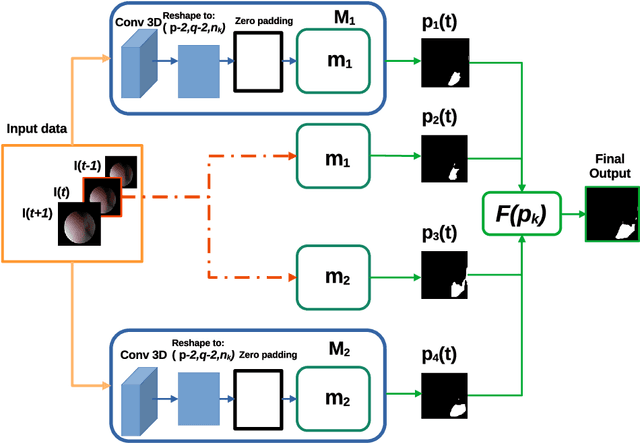
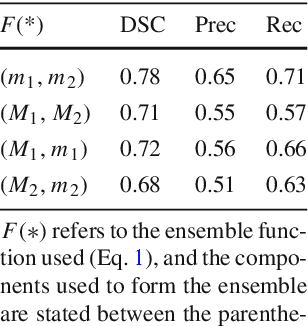
Purpose: Ureteroscopy is an efficient endoscopic minimally invasive technique for the diagnosis and treatment of upper tract urothelial carcinoma (UTUC). During ureteroscopy, the automatic segmentation of the hollow lumen is of primary importance, since it indicates the path that the endoscope should follow. In order to obtain an accurate segmentation of the hollow lumen, this paper presents an automatic method based on Convolutional Neural Networks (CNNs). Methods: The proposed method is based on an ensemble of 4 parallel CNNs to simultaneously process single and multi-frame information. Of these, two architectures are taken as core-models, namely U-Net based in residual blocks($m_1$) and Mask-RCNN($m_2$), which are fed with single still-frames $I(t)$. The other two models ($M_1$, $M_2$) are modifications of the former ones consisting on the addition of a stage which makes use of 3D Convolutions to process temporal information. $M_1$, $M_2$ are fed with triplets of frames ($I(t-1)$, $I(t)$, $I(t+1)$) to produce the segmentation for $I(t)$. Results: The proposed method was evaluated using a custom dataset of 11 videos (2,673 frames) which were collected and manually annotated from 6 patients. We obtain a Dice similarity coefficient of 0.80, outperforming previous state-of-the-art methods. Conclusion: The obtained results show that spatial-temporal information can be effectively exploited by the ensemble model to improve hollow lumen segmentation in ureteroscopic images. The method is effective also in presence of poor visibility, occasional bleeding, or specular reflections.
Visual Question Answering: which investigated applications?
Mar 04, 2021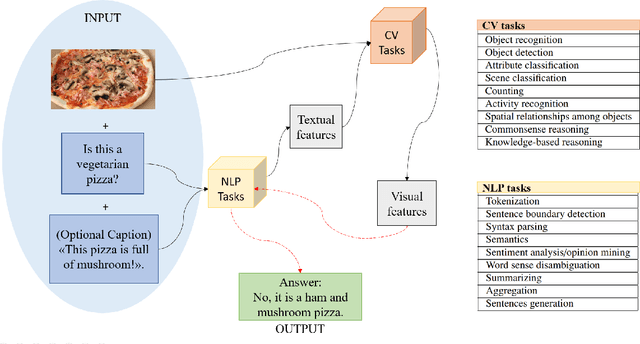
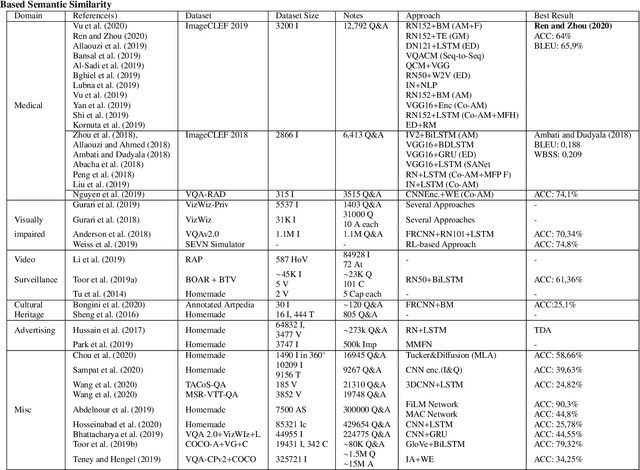

Visual Question Answering (VQA) is an extremely stimulating and challenging research area where Computer Vision (CV) and Natural Language Processig (NLP) have recently met. In image captioning and video summarization, the semantic information is completely contained in still images or video dynamics, and it has only to be mined and expressed in a human-consistent way. Differently from this, in VQA semantic information in the same media must be compared with the semantics implied by a question expressed in natural language, doubling the artificial intelligence-related effort. Some recent surveys about VQA approaches have focused on methods underlying either the image-related processing or the verbal-related one, or on the way to consistently fuse the conveyed information. Possible applications are only suggested, and, in fact, most cited works rely on general-purpose datasets that are used to assess the building blocks of a VQA system. This paper rather considers the proposals that focus on real-world applications, possibly using as benchmarks suitable data bound to the application domain. The paper also reports about some recent challenges in VQA research.
RFpredInterval: An R Package for Prediction Intervals with Random Forests and Boosted Forests
Jun 15, 2021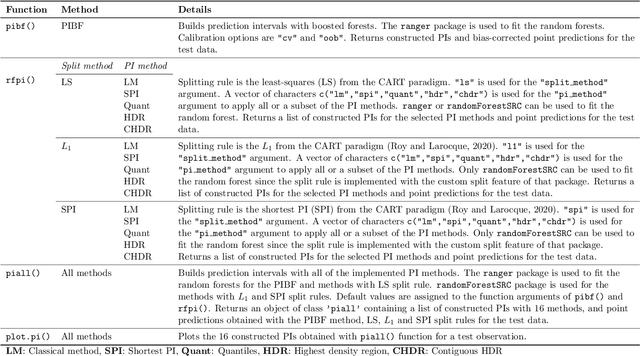
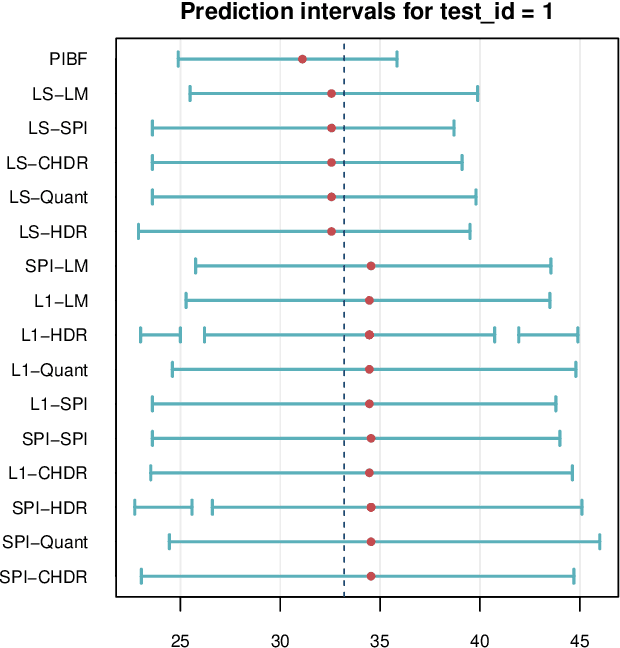
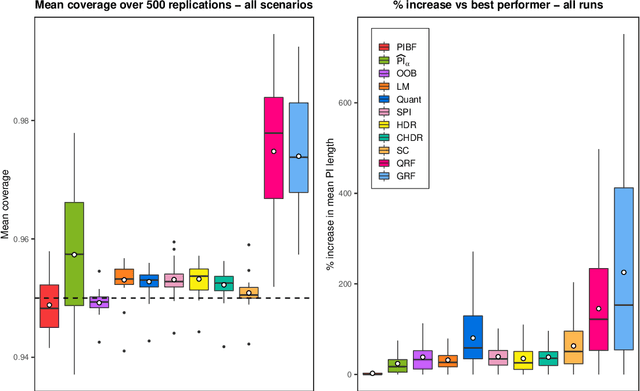
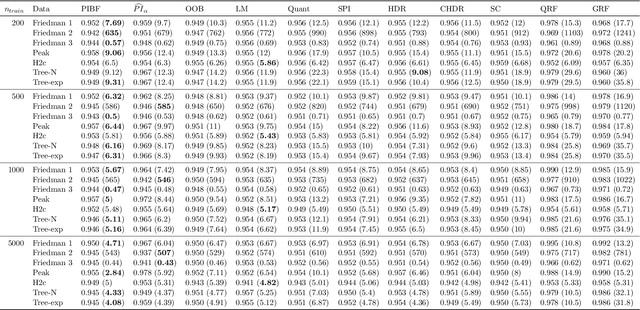
Like many predictive models, random forests provide a point prediction for a new observation. Besides the point prediction, it is important to quantify the uncertainty in the prediction. Prediction intervals provide information about the reliability of the point predictions. We have developed a comprehensive R package, RFpredInterval, that integrates 16 methods to build prediction intervals with random forests and boosted forests. The methods implemented in the package are a new method to build prediction intervals with boosted forests (PIBF) and 15 different variants to produce prediction intervals with random forests proposed by Roy and Larocque (2020). We perform an extensive simulation study and apply real data analyses to compare the performance of the proposed method to ten existing methods to build prediction intervals with random forests. The results show that the proposed method is very competitive and, globally, it outperforms the competing methods.
Multi-view Clustering with Deep Matrix Factorization and Global Graph Refinement
May 01, 2021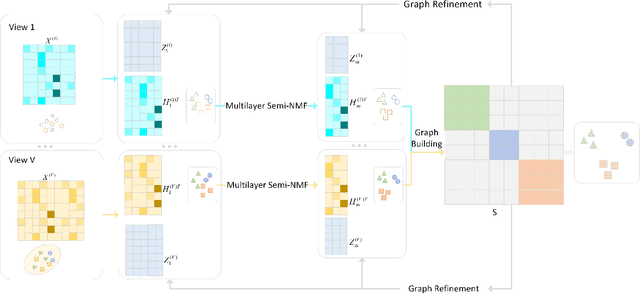

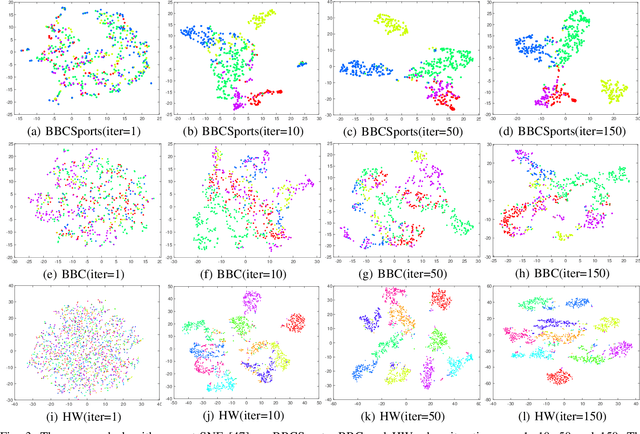
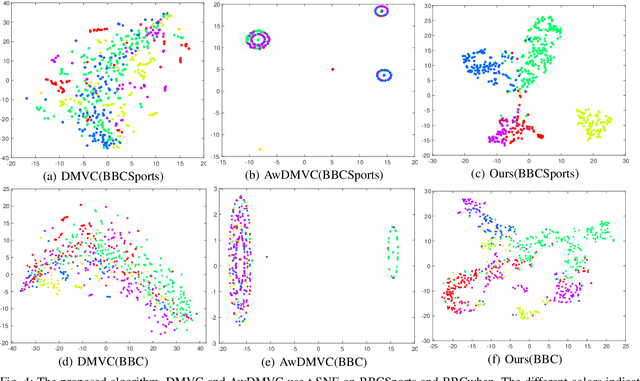
Multi-view clustering is an important yet challenging task in machine learning and data mining community. One popular strategy for multi-view clustering is matrix factorization which could explore useful feature representations at lower-dimensional space and therefore alleviate dimension curse. However, there are two major drawbacks in the existing work: i) most matrix factorization methods are limited to shadow depth, which leads to the inability to fully discover the rich hidden information of original data. Few deep matrix factorization methods provide a basis for the selection of the new representation's dimensions of different layers. ii) the majority of current approaches only concentrate on the view-shared information and ignore the specific local features in different views. To tackle the above issues, we propose a novel Multi-View Clustering method with Deep semi-NMF and Global Graph Refinement (MVC-DMF-GGR) in this paper. Firstly, we capture new representation matrices for each view by hierarchical decomposition, then learn a common graph by approximating a combination of graphs which are reconstructed from these new representations to refine the new representations in return. An alternate algorithm with proved convergence is then developed to solve the optimization problem and the results on six multi-view benchmarks demonstrate the effectiveness and superiority of our proposed algorithm.
NNCFR: Minimize Counterfactual Regret with Neural Networks
May 26, 2021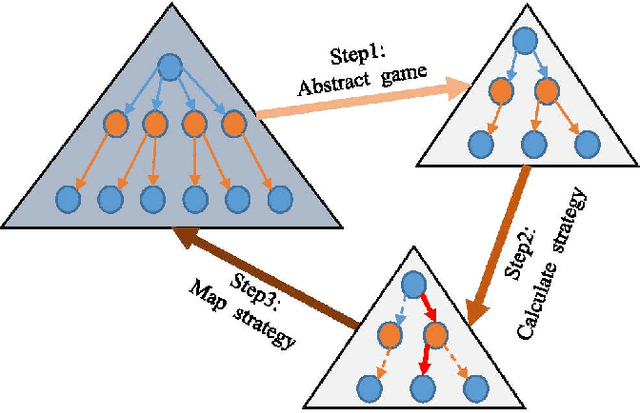
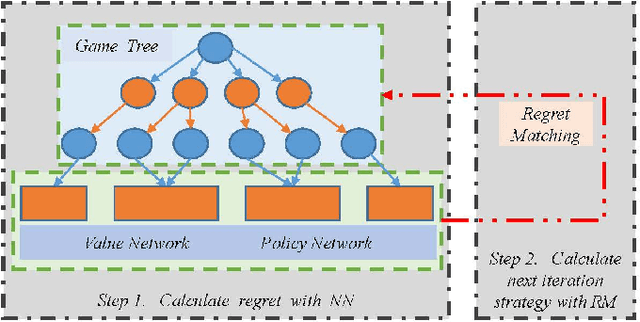
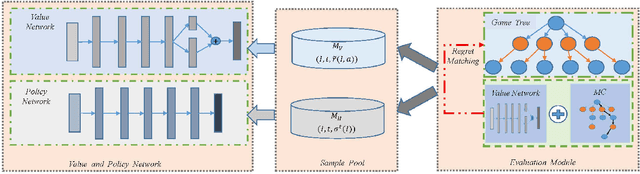
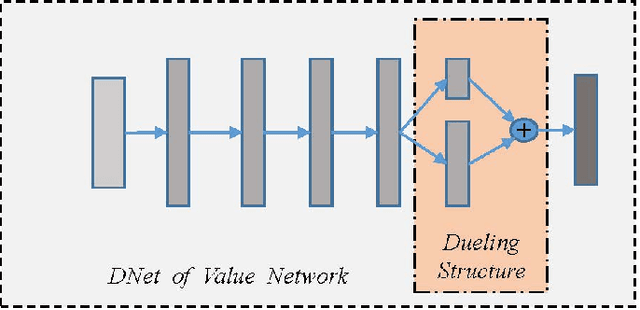
Counterfactual Regret Minimization (CFR)} is the popular method for finding approximate Nash equilibrium in two-player zero-sum games with imperfect information. CFR solves games by travsersing the full game tree iteratively, which limits its scalability in larger games. When applying CFR to solve large-scale games in previously, large-scale games are abstracted into small-scale games firstly. Secondly, CFR is used to solve the abstract game. And finally, the solution strategy is mapped back to the original large-scale game. However, this process requires considerable expert knowledge, and the accuracy of abstraction is closely related to expert knowledge. In addition, the abstraction also loses certain information, which will eventually affect the accuracy of the solution strategy. Towards this problem, a recent method, \textit{Deep CFR} alleviates the need for abstraction and expert knowledge by applying deep neural networks directly to CFR in full games. In this paper, we introduces \textit{Neural Network Counterfactual Regret Minimization (NNCFR)}, an improved variant of \textit{Deep CFR} that has a faster convergence by constructing a dueling netwok as the value network. Moreover, an evaluation module is designed by combining the value network and Monte Carlo, which reduces the approximation error of the value network. In addition, a new loss function is designed in the procedure of training policy network in the proposed \textit{NNCFR}, which can be good to make the policy network more stable. The extensive experimental tests are conducted to show that the \textit{NNCFR} converges faster and performs more stable than \textit{Deep CFR}, and outperforms \textit{Deep CFR} with respect to exploitability and head-to-head performance on test games.
A Neural Passage Model for Ad-hoc Document Retrieval
Mar 16, 2021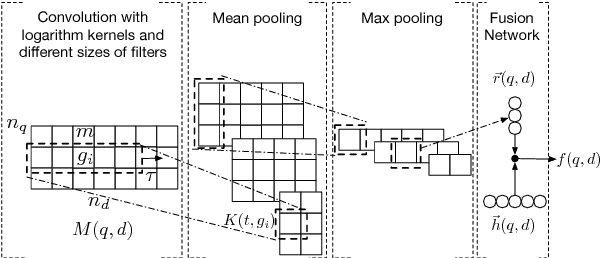
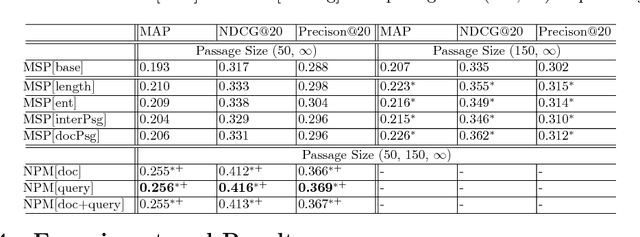
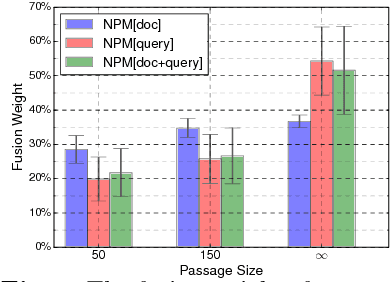
Traditional statistical retrieval models often treat each document as a whole. In many cases, however, a document is relevant to a query only because a small part of it contain the targeted information. In this work, we propose a neural passage model (NPM) that uses passage-level information to improve the performance of ad-hoc retrieval. Instead of using a single window to extract passages, our model automatically learns to weight passages with different granularities in the training process. We show that the passage-based document ranking paradigm from previous studies can be directly derived from our neural framework. Also, our experiments on a TREC collection showed that the NPM can significantly outperform the existing passage-based retrieval models.
Data Mining and Visualization to Understand Accident-prone Areas
Mar 11, 2021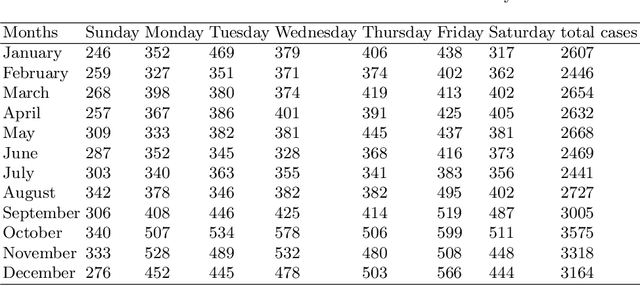
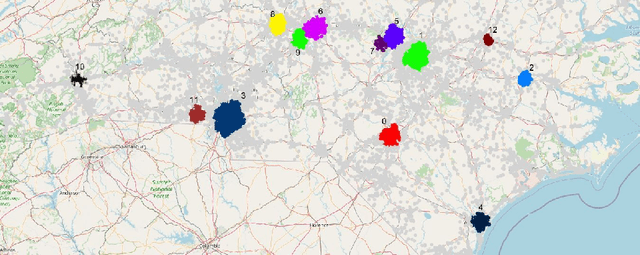
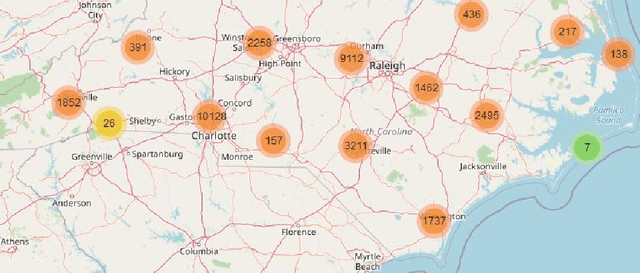
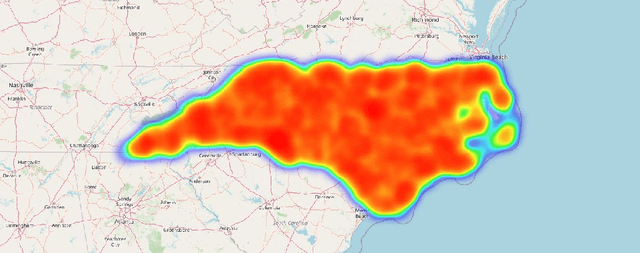
In this study, we present both data mining and information visualization techniques to identify accident-prone areas, most accident-prone time, day, and month. Also, we surveyed among volunteers to understand which visualization techniques help non-expert users to understand the findings better. Findings of this study suggest that most accidents occur in the dusk (i.e., between 6 to 7 pm), and on Fridays. Results also suggest that most accidents occurred in October, which is a popular month for tourism. These findings are consistent with social information and can help policymakers, residents, tourists, and other law enforcement agencies. This study can be extended to draw broader implications.
Improving Information Extraction from Images with Learned Semantic Models
Aug 27, 2018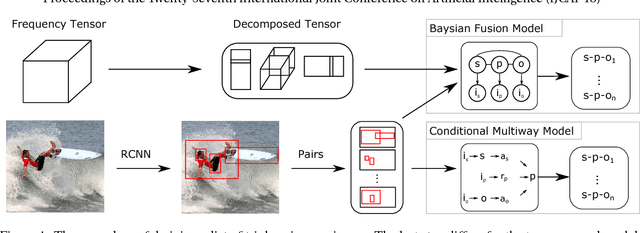
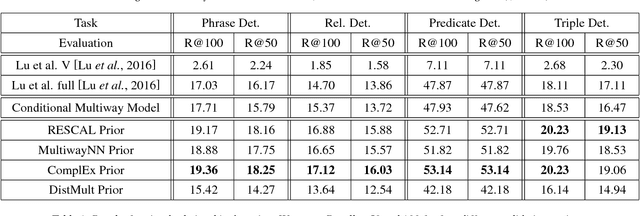
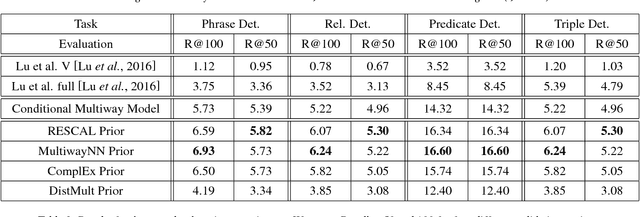
Many applications require an understanding of an image that goes beyond the simple detection and classification of its objects. In particular, a great deal of semantic information is carried in the relationships between objects. We have previously shown that the combination of a visual model and a statistical semantic prior model can improve on the task of mapping images to their associated scene description. In this paper, we review the model and compare it to a novel conditional multi-way model for visual relationship detection, which does not include an explicitly trained visual prior model. We also discuss potential relationships between the proposed methods and memory models of the human brain.