 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Preliminary study on using vector quantization latent spaces for TTS/VC systems with consistent performance
Jun 25, 2021
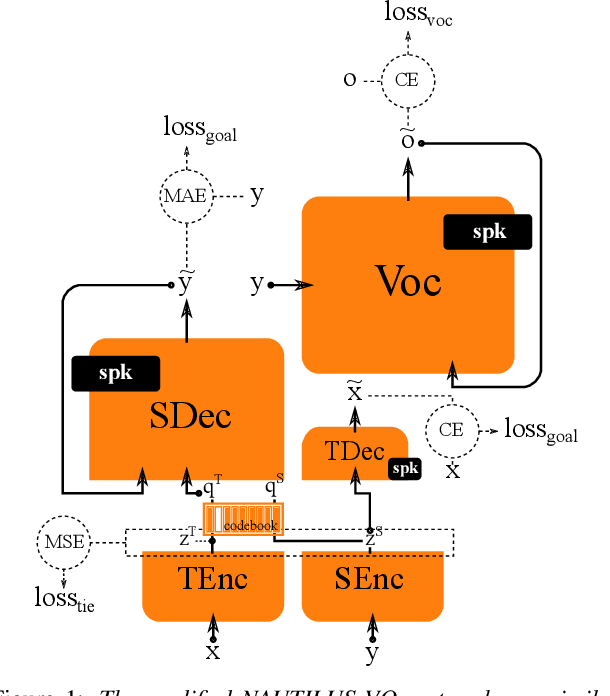
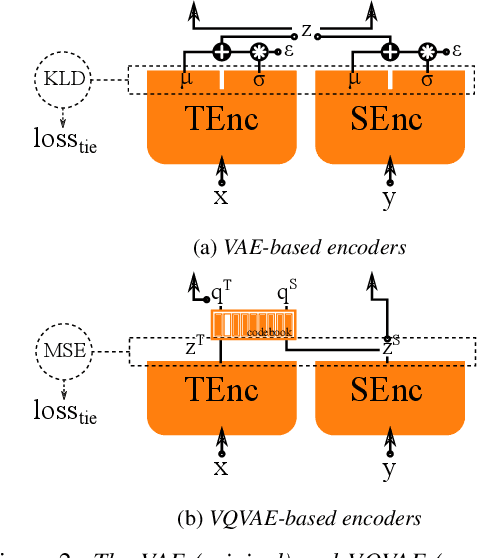
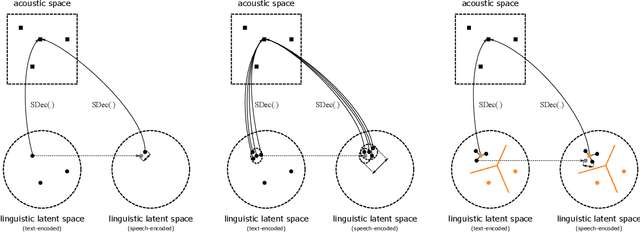
Generally speaking, the main objective when training a neural speech synthesis system is to synthesize natural and expressive speech from the output layer of the neural network without much attention given to the hidden layers. However, by learning useful latent representation, the system can be used for many more practical scenarios. In this paper, we investigate the use of quantized vectors to model the latent linguistic embedding and compare it with the continuous counterpart. By enforcing different policies over the latent spaces in the training, we are able to obtain a latent linguistic embedding that takes on different properties while having a similar performance in terms of quality and speaker similarity. Our experiments show that the voice cloning system built with vector quantization has only a small degradation in terms of perceptive evaluations, but has a discrete latent space that is useful for reducing the representation bit-rate, which is desirable for data transferring, or limiting the information leaking, which is important for speaker anonymization and other tasks of that nature.
Unveiling the potential of Graph Neural Networks for robust Intrusion Detection
Jul 30, 2021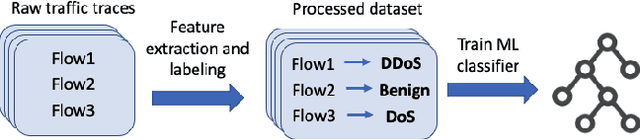
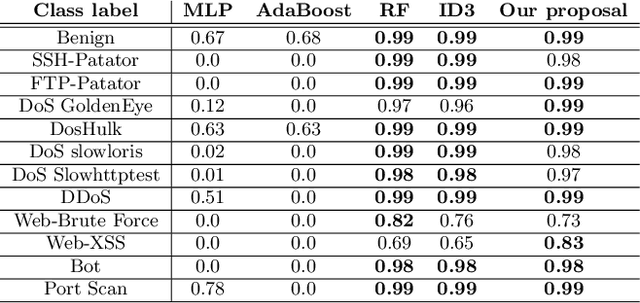
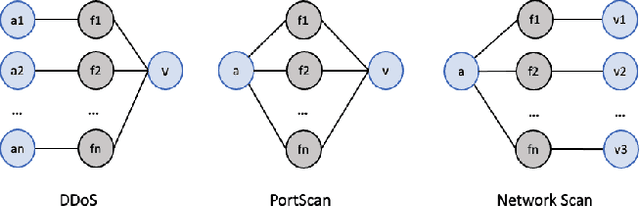
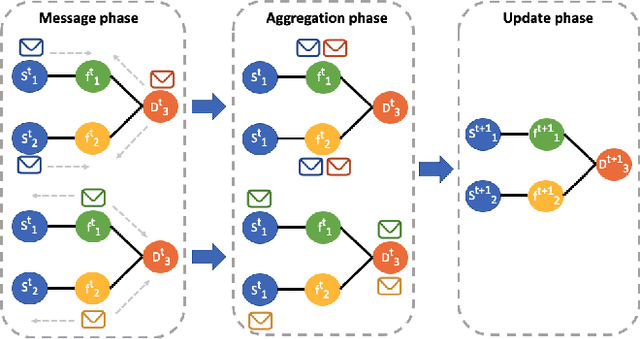
The last few years have seen an increasing wave of attacks with serious economic and privacy damages, which evinces the need for accurate Network Intrusion Detection Systems (NIDS). Recent works propose the use of Machine Learning (ML) techniques for building such systems (e.g., decision trees, neural networks). However, existing ML-based NIDS are barely robust to common adversarial attacks, which limits their applicability to real networks. A fundamental problem of these solutions is that they treat and classify flows independently. In contrast, in this paper we argue the importance of focusing on the structural patterns of attacks, by capturing not only the individual flow features, but also the relations between different flows (e.g., the source/destination hosts they share). To this end, we use a graph representation that keeps flow records and their relationships, and propose a novel Graph Neural Network (GNN) model tailored to process and learn from such graph-structured information. In our evaluation, we first show that the proposed GNN model achieves state-of-the-art results in the well-known CIC-IDS2017 dataset. Moreover, we assess the robustness of our solution under two common adversarial attacks, that intentionally modify the packet size and inter-arrival times to avoid detection. The results show that our model is able to maintain the same level of accuracy as in previous experiments, while state-of-the-art ML techniques degrade up to 50% their accuracy (F1-score) under these attacks. This unprecedented level of robustness is mainly induced by the capability of our GNN model to learn flow patterns of attacks structured as graphs.
Structured Sentiment Analysis as Dependency Graph Parsing
May 30, 2021
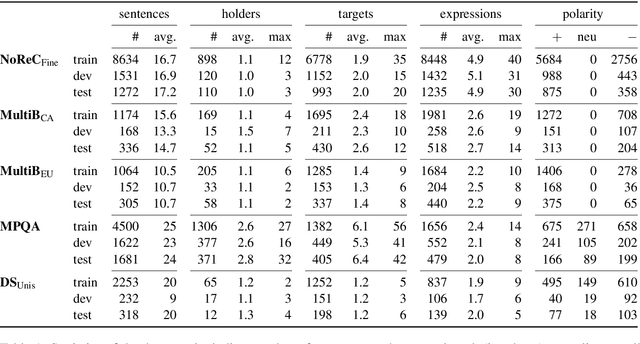
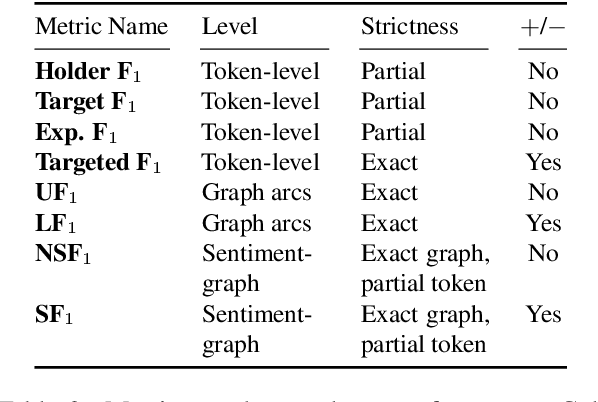
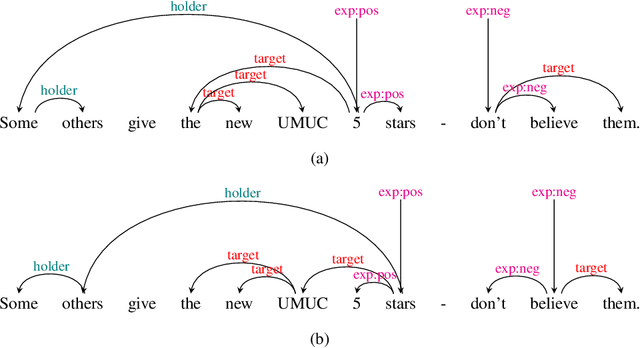
Structured sentiment analysis attempts to extract full opinion tuples from a text, but over time this task has been subdivided into smaller and smaller sub-tasks, e,g,, target extraction or targeted polarity classification. We argue that this division has become counterproductive and propose a new unified framework to remedy the situation. We cast the structured sentiment problem as dependency graph parsing, where the nodes are spans of sentiment holders, targets and expressions, and the arcs are the relations between them. We perform experiments on five datasets in four languages (English, Norwegian, Basque, and Catalan) and show that this approach leads to strong improvements over state-of-the-art baselines. Our analysis shows that refining the sentiment graphs with syntactic dependency information further improves results.
General Data Analytics with Applications to Visual Information Analysis: A Provable Backward-Compatible Semisimple Paradigm over T-Algebra
Nov 16, 2020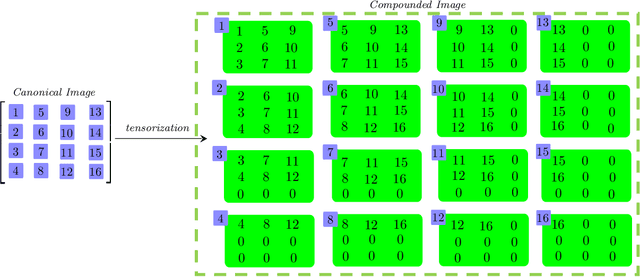
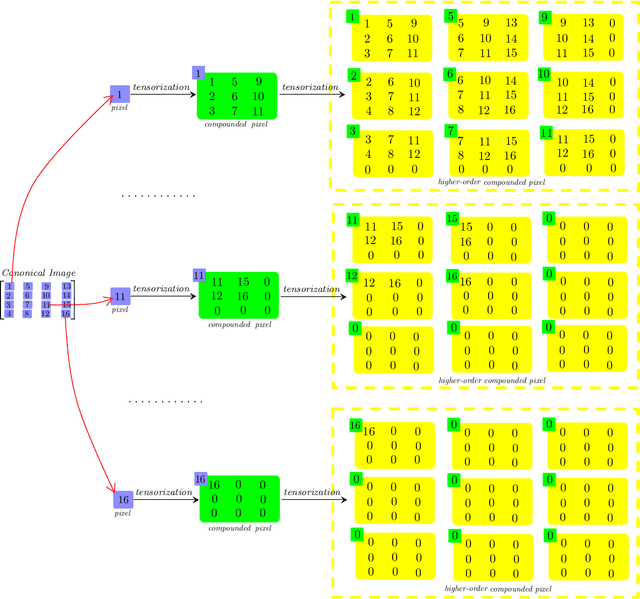

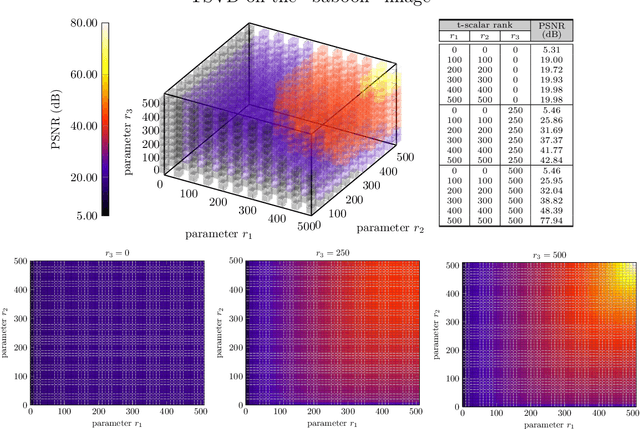
We consider a novel backward-compatible paradigm of general data analytics over a recently-reported semisimple algebra (called t-algebra). We study the abstract algebraic framework over the t-algebra by representing the elements of t-algebra by fix-sized multi-way arrays of complex numbers and the algebraic structure over the t-algebra by a collection of direct-product constituents. Over the t-algebra, many algorithms, if not all, are generalized in a straightforward manner using this new semisimple paradigm. To demonstrate the new paradigm's performance and its backward-compatibility, we generalize some canonical algorithms for visual pattern analysis. Experiments on public datasets show that the generalized algorithms compare favorably with their canonical counterparts.
High-Resolution Depth Maps Based on TOF-Stereo Fusion
Jul 30, 2021

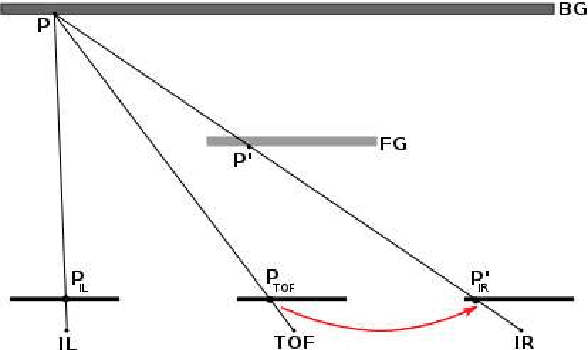

The combination of range sensors with color cameras can be very useful for robot navigation, semantic perception, manipulation, and telepresence. Several methods of combining range- and color-data have been investigated and successfully used in various robotic applications. Most of these systems suffer from the problems of noise in the range-data and resolution mismatch between the range sensor and the color cameras, since the resolution of current range sensors is much less than the resolution of color cameras. High-resolution depth maps can be obtained using stereo matching, but this often fails to construct accurate depth maps of weakly/repetitively textured scenes, or if the scene exhibits complex self-occlusions. Range sensors provide coarse depth information regardless of presence/absence of texture. The use of a calibrated system, composed of a time-of-flight (TOF) camera and of a stereoscopic camera pair, allows data fusion thus overcoming the weaknesses of both individual sensors. We propose a novel TOF-stereo fusion method based on an efficient seed-growing algorithm which uses the TOF data projected onto the stereo image pair as an initial set of correspondences. These initial "seeds" are then propagated based on a Bayesian model which combines an image similarity score with rough depth priors computed from the low-resolution range data. The overall result is a dense and accurate depth map at the resolution of the color cameras at hand. We show that the proposed algorithm outperforms 2D image-based stereo algorithms and that the results are of higher resolution than off-the-shelf color-range sensors, e.g., Kinect. Moreover, the algorithm potentially exhibits real-time performance on a single CPU.
Learning the Next Best View for 3D Point Clouds via Topological Features
Mar 04, 2021
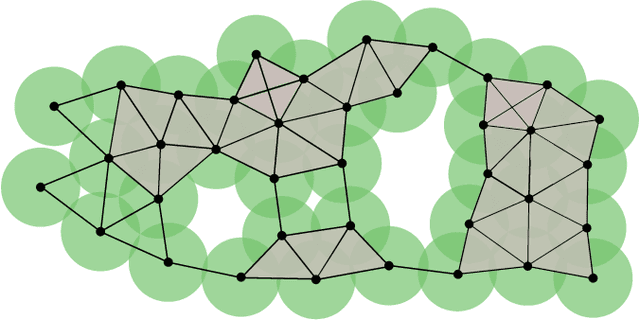
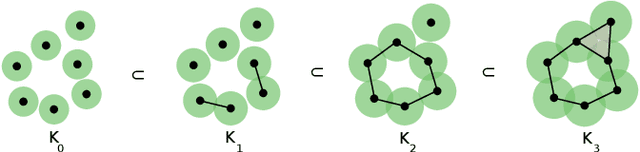

In this paper, we introduce a reinforcement learning approach utilizing a novel topology-based information gain metric for directing the next best view of a noisy 3D sensor. The metric combines the disjoint sections of an observed surface to focus on high-detail features such as holes and concave sections. Experimental results show that our approach can aid in establishing the placement of a robotic sensor to optimize the information provided by its streaming point cloud data. Furthermore, a labeled dataset of 3D objects, a CAD design for a custom robotic manipulator, and software for the transformation, union, and registration of point clouds has been publicly released to the research community.
Learning Comprehensive Motion Representation for Action Recognition
Mar 23, 2021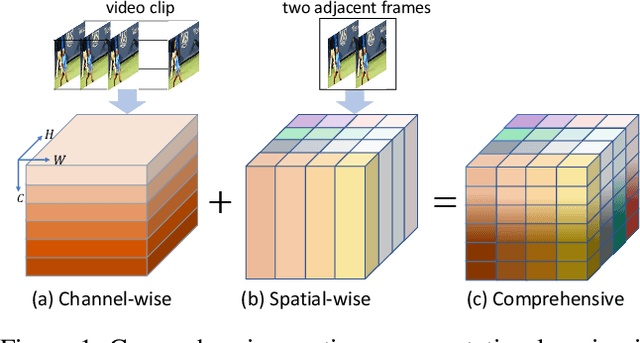
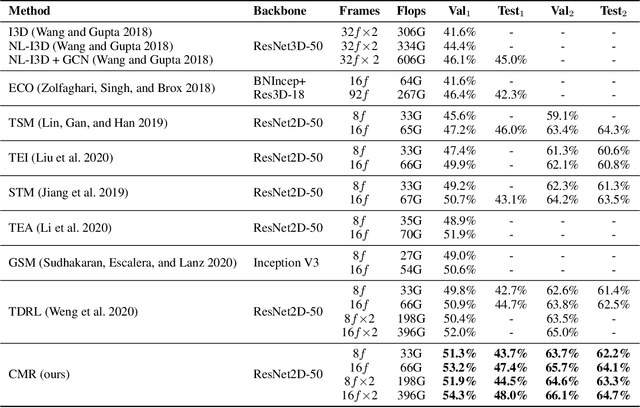
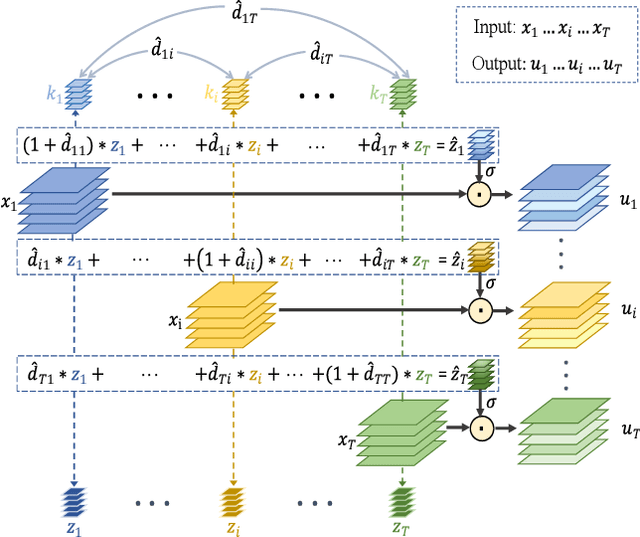
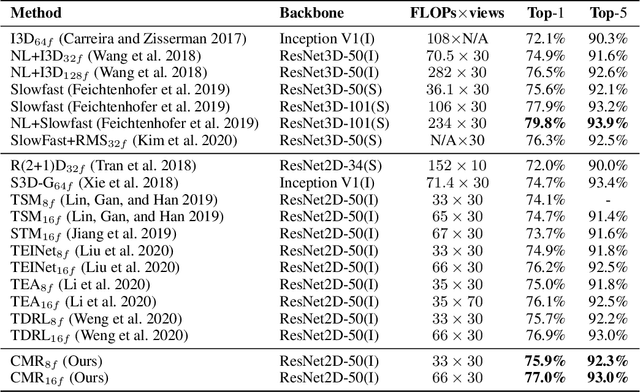
For action recognition learning, 2D CNN-based methods are efficient but may yield redundant features due to applying the same 2D convolution kernel to each frame. Recent efforts attempt to capture motion information by establishing inter-frame connections while still suffering the limited temporal receptive field or high latency. Moreover, the feature enhancement is often only performed by channel or space dimension in action recognition. To address these issues, we first devise a Channel-wise Motion Enhancement (CME) module to adaptively emphasize the channels related to dynamic information with a channel-wise gate vector. The channel gates generated by CME incorporate the information from all the other frames in the video. We further propose a Spatial-wise Motion Enhancement (SME) module to focus on the regions with the critical target in motion, according to the point-to-point similarity between adjacent feature maps. The intuition is that the change of background is typically slower than the motion area. Both CME and SME have clear physical meaning in capturing action clues. By integrating the two modules into the off-the-shelf 2D network, we finally obtain a Comprehensive Motion Representation (CMR) learning method for action recognition, which achieves competitive performance on Something-Something V1 & V2 and Kinetics-400. On the temporal reasoning datasets Something-Something V1 and V2, our method outperforms the current state-of-the-art by 2.3% and 1.9% when using 16 frames as input, respectively.
Spectral Clustering Revisited: Information Hidden in the Fiedler Vector
Mar 22, 2020
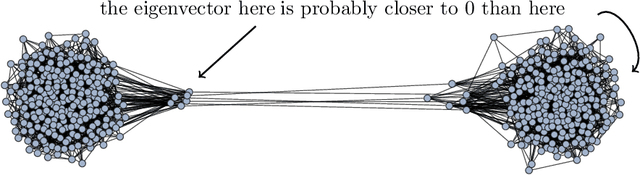
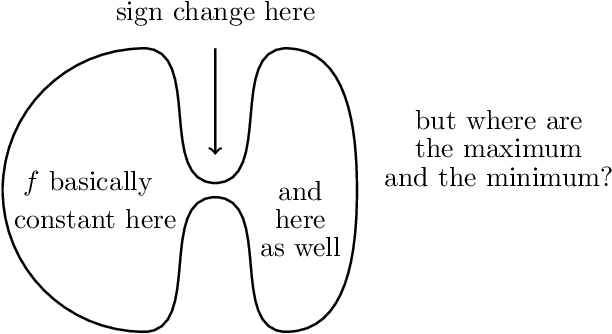
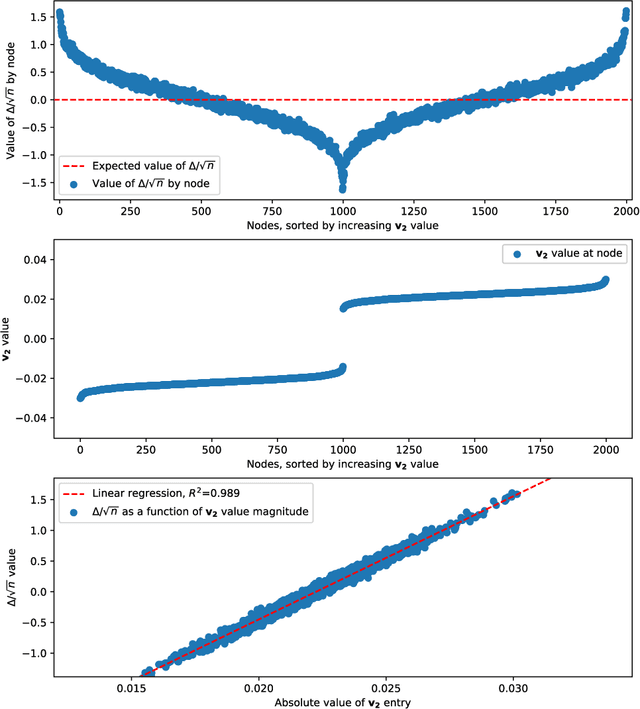
We are interested in the clustering problem on graphs: it is known that if there are two underlying clusters, then the signs of the eigenvector corresponding to the second largest eigenvalue of the adjacency matrix can reliably reconstruct the two clusters. We argue that the vertices for which the eigenvector has the largest and the smallest entries, respectively, are unusually strongly connected to their own cluster and more reliably classified than the rest. This can be regarded as a discrete version of the Hot Spots conjecture and should be useful in applications. We give a rigorous proof for the stochastic block model and several examples.
A Survey on Complex Knowledge Base Question Answering: Methods, Challenges and Solutions
May 25, 2021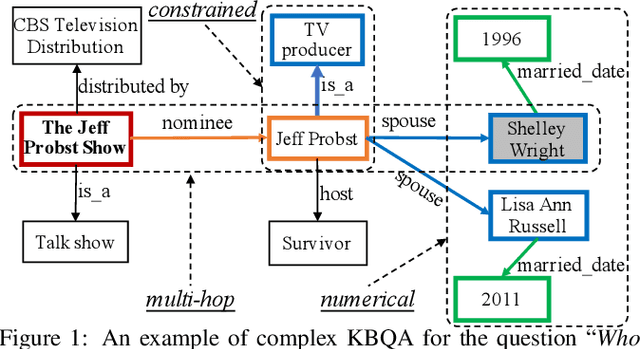
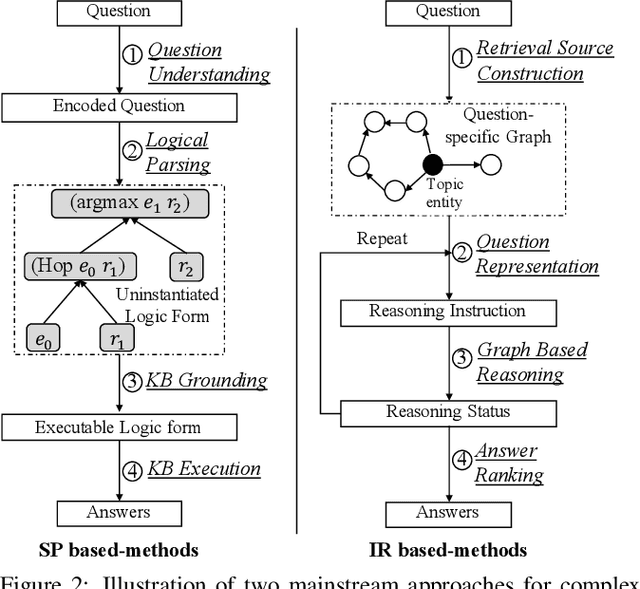
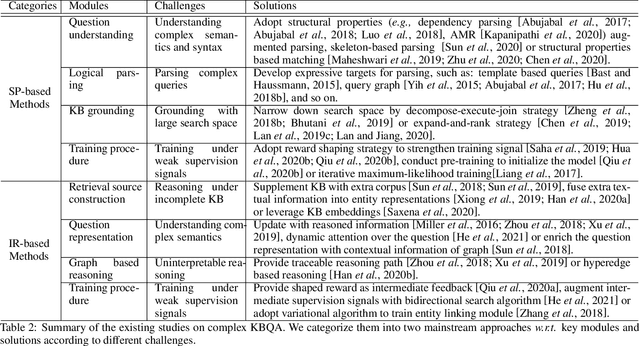
Knowledge base question answering (KBQA) aims to answer a question over a knowledge base (KB). Recently, a large number of studies focus on semantically or syntactically complicated questions. In this paper, we elaborately summarize the typical challenges and solutions for complex KBQA. We begin with introducing the background about the KBQA task. Next, we present the two mainstream categories of methods for complex KBQA, namely semantic parsing-based (SP-based) methods and information retrieval-based (IR-based) methods. We then review the advanced methods comprehensively from the perspective of the two categories. Specifically, we explicate their solutions to the typical challenges. Finally, we conclude and discuss some promising directions for future research.
LAMPRET: Layout-Aware Multimodal PreTraining for Document Understanding
Apr 16, 2021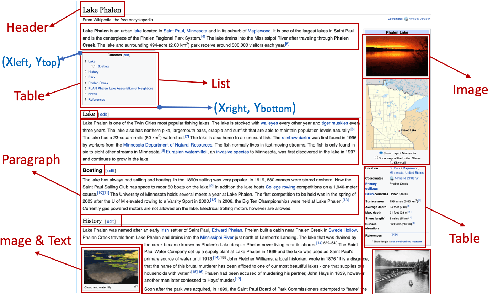
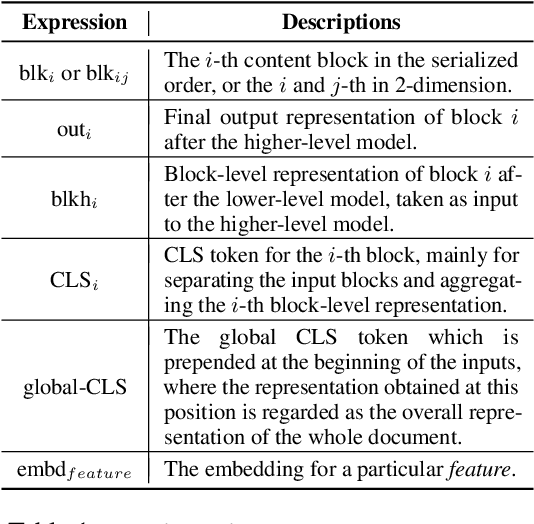
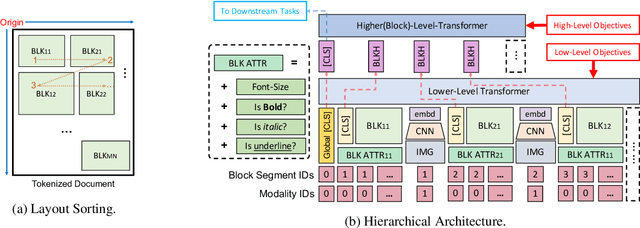
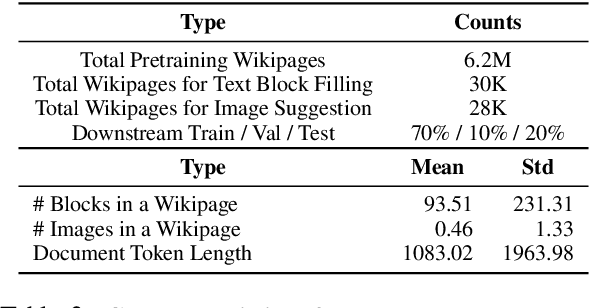
Document layout comprises both structural and visual (eg. font-sizes) information that is vital but often ignored by machine learning models. The few existing models which do use layout information only consider textual contents, and overlook the existence of contents in other modalities such as images. Additionally, spatial interactions of presented contents in a layout were never really fully exploited. To bridge this gap, we parse a document into content blocks (eg. text, table, image) and propose a novel layout-aware multimodal hierarchical framework, LAMPreT, to model the blocks and the whole document. Our LAMPreT encodes each block with a multimodal transformer in the lower-level and aggregates the block-level representations and connections utilizing a specifically designed transformer at the higher-level. We design hierarchical pretraining objectives where the lower-level model is trained similarly to multimodal grounding models, and the higher-level model is trained with our proposed novel layout-aware objectives. We evaluate the proposed model on two layout-aware tasks -- text block filling and image suggestion and show the effectiveness of our proposed hierarchical architecture as well as pretraining techniques.