 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Catchphrase: Automatic Detection of Cultural References
Jun 09, 2021


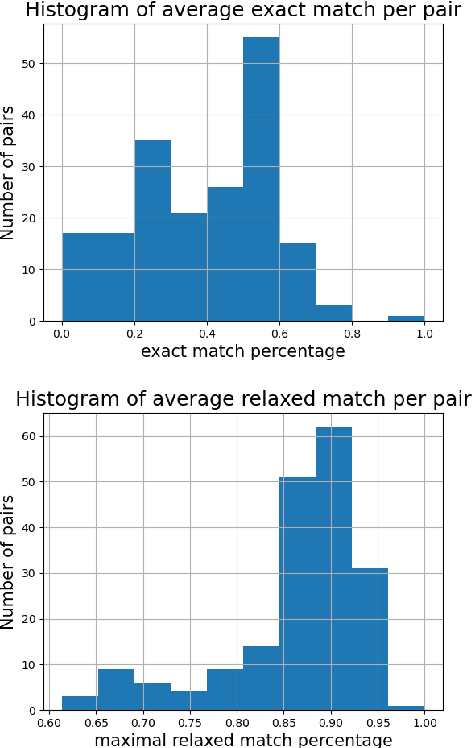

A snowclone is a customizable phrasal template that can be realized in multiple, instantly recognized variants. For example, ``* is the new *" (Orange is the new black, 40 is the new 30). Snowclones are extensively used in social media. In this paper, we study snowclones originating from pop-culture quotes; our goal is to automatically detect cultural references in text. We introduce a new, publicly available data set of pop-culture quotes and their corresponding snowclone usages and train models on them. We publish code for Catchphrase, an internet browser plugin to automatically detect and mark references in real-time, and examine its performance via a user study. Aside from assisting people to better comprehend cultural references, we hope that detecting snowclones can complement work on paraphrasing and help to tackle long-standing questions in social science about the dynamics of information propagation.
Composable Augmentation Encoding for Video Representation Learning
Apr 01, 2021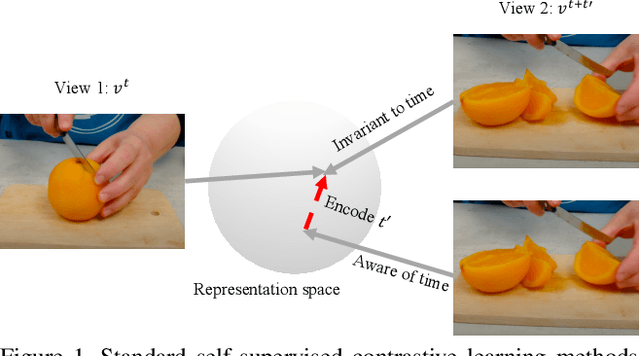

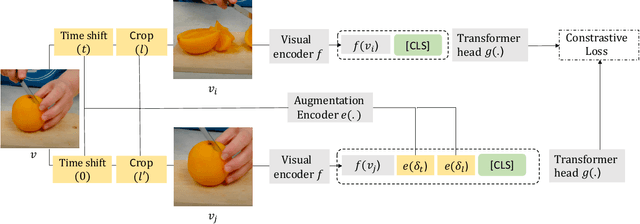

We focus on contrastive methods for self-supervised video representation learning. A common paradigm in contrastive learning is to construct positive pairs by sampling different data views for the same instance, with different data instances as negatives. These methods implicitly assume a set of representational invariances to the view selection mechanism (eg, sampling frames with temporal shifts), which may lead to poor performance on downstream tasks which violate these invariances (fine-grained video action recognition that would benefit from temporal information). To overcome this limitation, we propose an 'augmentation aware' contrastive learning framework, where we explicitly provide a sequence of augmentation parameterisations (such as the values of the time shifts used to create data views) as composable augmentation encodings (CATE) to our model when projecting the video representations for contrastive learning. We show that representations learned by our method encode valuable information about specified spatial or temporal augmentation, and in doing so also achieve state-of-the-art performance on a number of video benchmarks.
Retinal OCT Denoising with Pseudo-Multimodal Fusion Network
Jul 09, 2021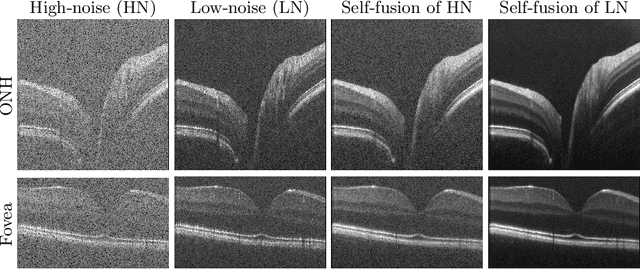
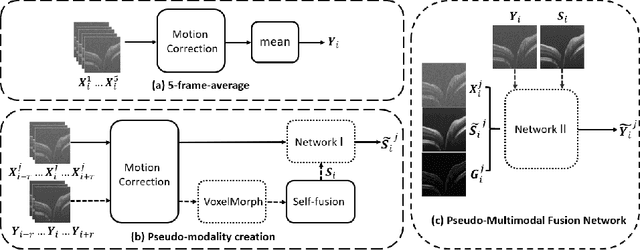
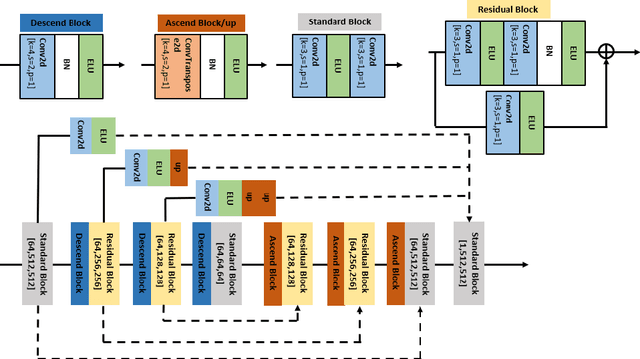
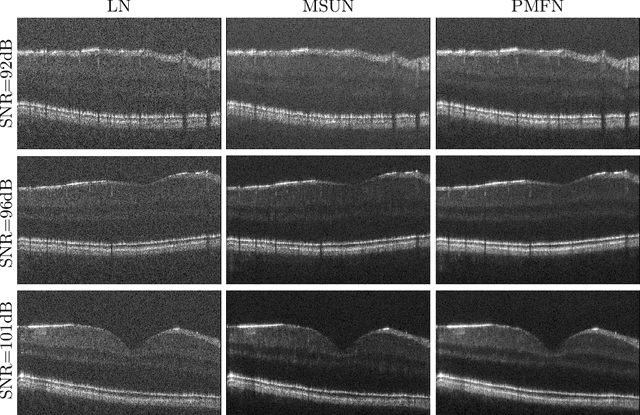
Optical coherence tomography (OCT) is a prevalent imaging technique for retina. However, it is affected by multiplicative speckle noise that can degrade the visibility of essential anatomical structures, including blood vessels and tissue layers. Although averaging repeated B-scan frames can significantly improve the signal-to-noise-ratio (SNR), this requires longer acquisition time, which can introduce motion artifacts and cause discomfort to patients. In this study, we propose a learning-based method that exploits information from the single-frame noisy B-scan and a pseudo-modality that is created with the aid of the self-fusion method. The pseudo-modality provides good SNR for layers that are barely perceptible in the noisy B-scan but can over-smooth fine features such as small vessels. By using a fusion network, desired features from each modality can be combined, and the weight of their contribution is adjustable. Evaluated by intensity-based and structural metrics, the result shows that our method can effectively suppress the speckle noise and enhance the contrast between retina layers while the overall structure and small blood vessels are preserved. Compared to the single modality network, our method improves the structural similarity with low noise B-scan from 0.559 +\- 0.033 to 0.576 +\- 0.031.
UrbanScene3D: A Large Scale Urban Scene Dataset and Simulator
Jul 09, 2021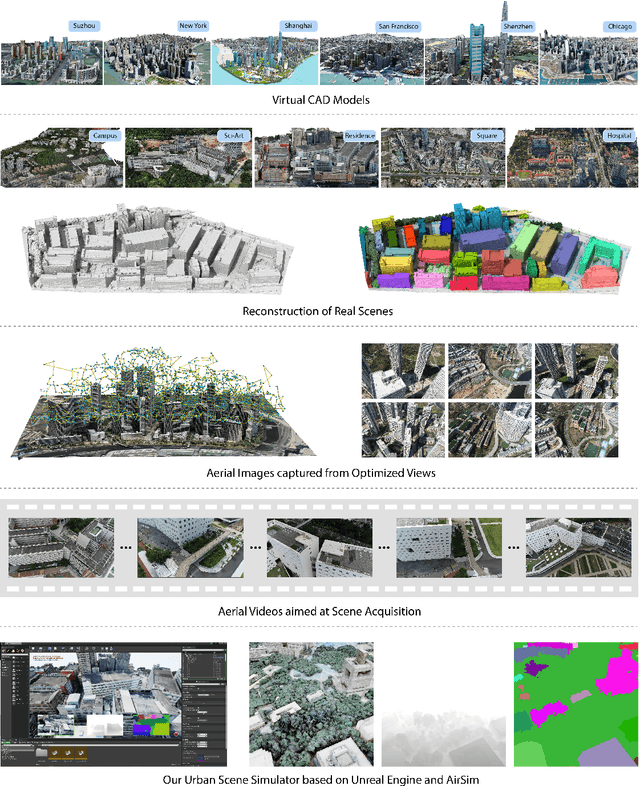
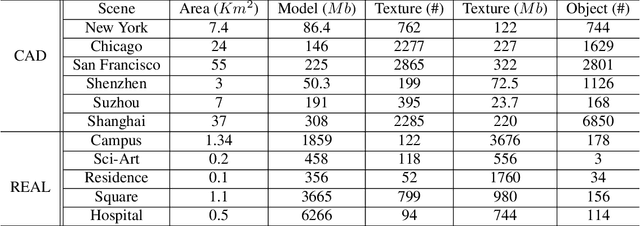
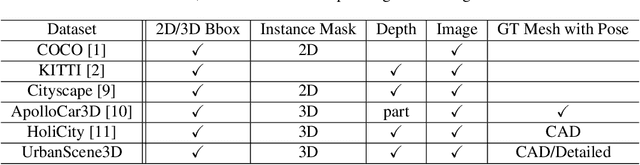
The ability to perceive the environments in different ways is essential to robotic research. This involves the analysis of both 2D and 3D data sources. We present a large scale urban scene dataset associated with a handy simulator based on Unreal Engine 4 and AirSim, which consists of both man-made and real-world reconstruction scenes in different scales, referred to as UrbanScene3D. Unlike previous works that purely based on 2D information or man-made 3D CAD models, UrbanScene3D contains both compact man-made models and detailed real-world models reconstructed by aerial images. Each building has been manually extracted from the entire scene model and then has been assigned with a unique label, forming an instance segmentation map. The provided 3D ground-truth textured models with instance segmentation labels in UrbanScene3D allow users to obtain all kinds of data they would like to have: instance segmentation map, depth map in arbitrary resolution, 3D point cloud/mesh in both visible and invisible places, etc. In addition, with the help of AirSim, users can also simulate the robots (cars/drones)to test a variety of autonomous tasks in the proposed city environment. Please refer to our paper and website(https://vcc.tech/UrbanScene3D/) for further details and applications.
Fast Pixel-Matching for Video Object Segmentation
Jul 09, 2021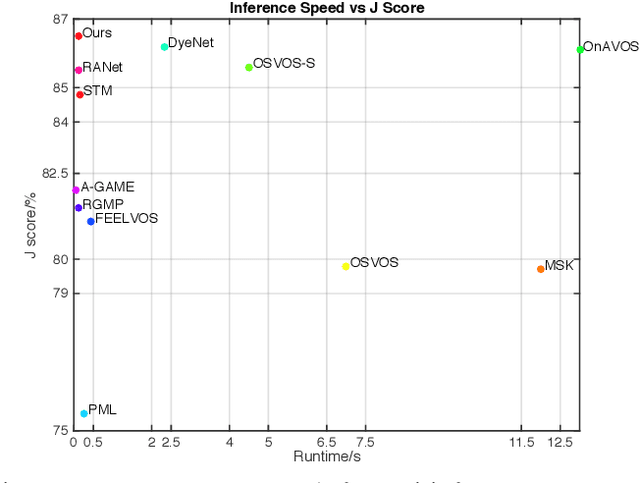
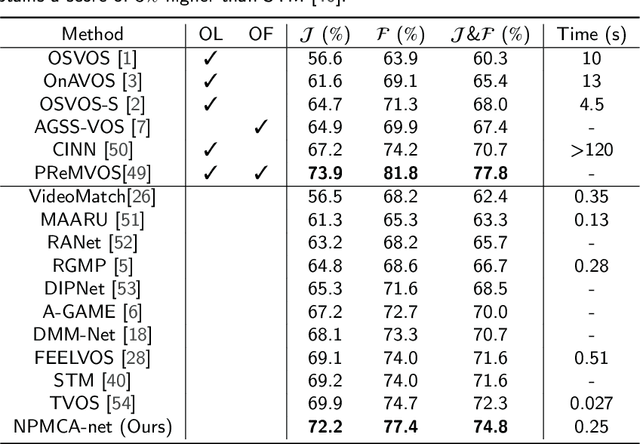
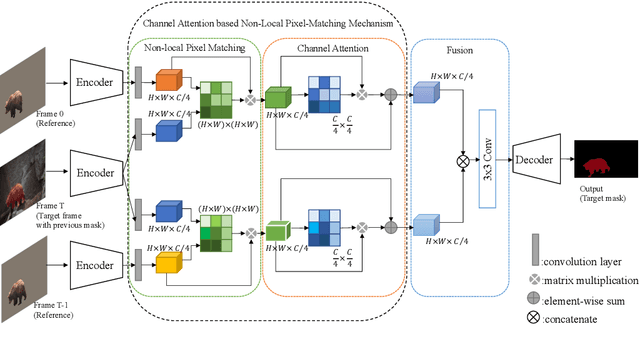
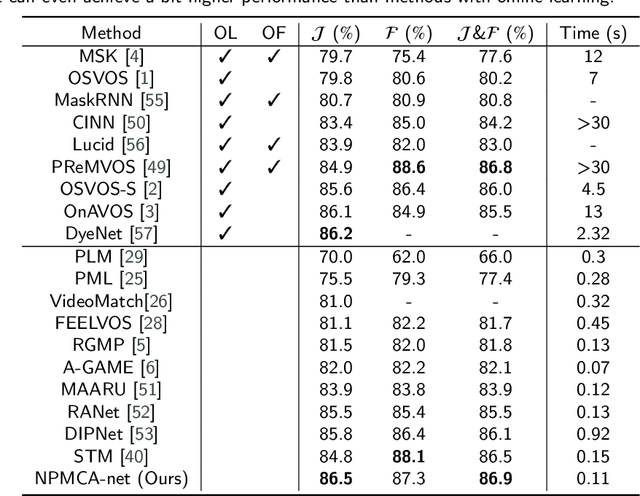
Video object segmentation, aiming to segment the foreground objects given the annotation of the first frame, has been attracting increasing attentions. Many state-of-the-art approaches have achieved great performance by relying on online model updating or mask-propagation techniques. However, most online models require high computational cost due to model fine-tuning during inference. Most mask-propagation based models are faster but with relatively low performance due to failure to adapt to object appearance variation. In this paper, we are aiming to design a new model to make a good balance between speed and performance. We propose a model, called NPMCA-net, which directly localizes foreground objects based on mask-propagation and non-local technique by matching pixels in reference and target frames. Since we bring in information of both first and previous frames, our network is robust to large object appearance variation, and can better adapt to occlusions. Extensive experiments show that our approach can achieve a new state-of-the-art performance with a fast speed at the same time (86.5% IoU on DAVIS-2016 and 72.2% IoU on DAVIS-2017, with speed of 0.11s per frame) under the same level comparison. Source code is available at https://github.com/siyueyu/NPMCA-net.
MusCaps: Generating Captions for Music Audio
Apr 24, 2021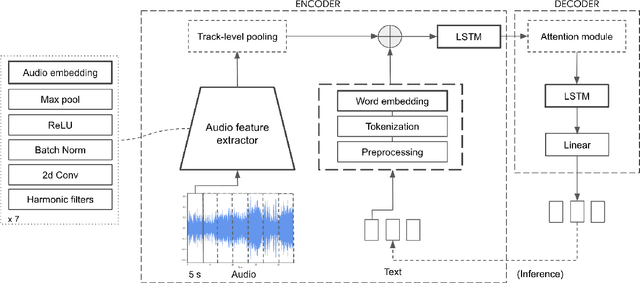
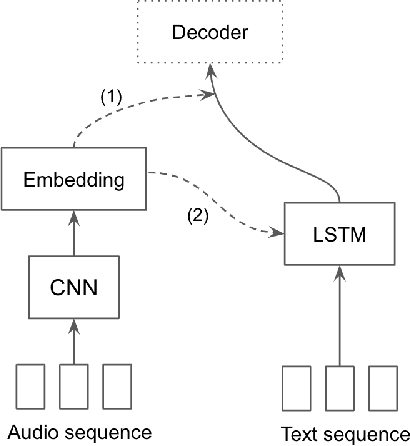
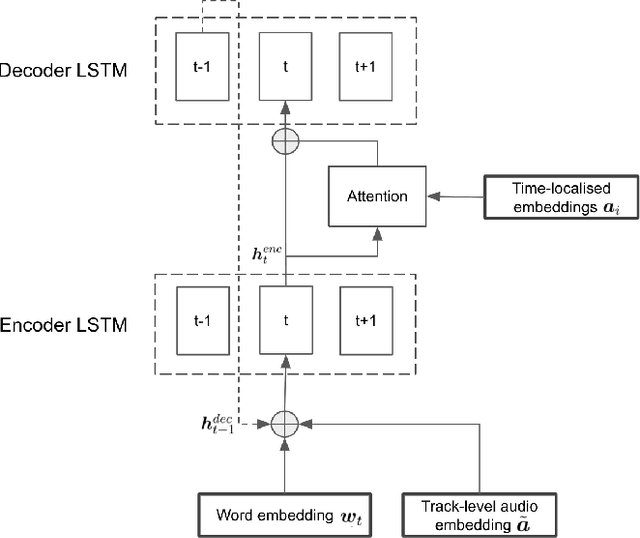

Content-based music information retrieval has seen rapid progress with the adoption of deep learning. Current approaches to high-level music description typically make use of classification models, such as in auto-tagging or genre and mood classification. In this work, we propose to address music description via audio captioning, defined as the task of generating a natural language description of music audio content in a human-like manner. To this end, we present the first music audio captioning model, MusCaps, consisting of an encoder-decoder with temporal attention. Our method combines convolutional and recurrent neural network architectures to jointly process audio-text inputs through a multimodal encoder and leverages pre-training on audio data to obtain representations that effectively capture and summarise musical features in the input. Evaluation of the generated captions through automatic metrics shows that our method outperforms a baseline designed for non-music audio captioning. Through an ablation study, we unveil that this performance boost can be mainly attributed to pre-training of the audio encoder, while other design choices - modality fusion, decoding strategy and the use of attention - contribute only marginally. Our model represents a shift away from classification-based music description and combines tasks requiring both auditory and linguistic understanding to bridge the semantic gap in music information retrieval.
Graph-Embedded Multi-Agent Learning for Smart Reconfigurable THz MIMO-NOMA Networks
Jul 15, 2021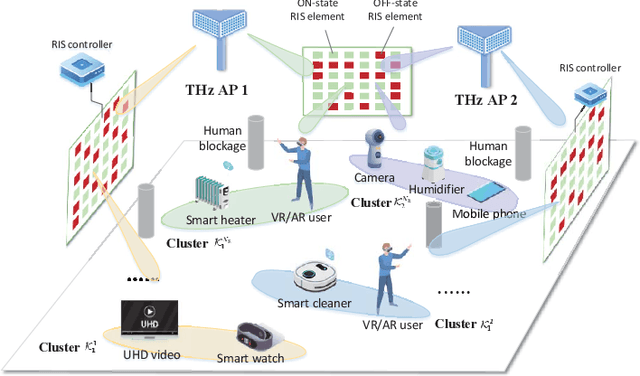
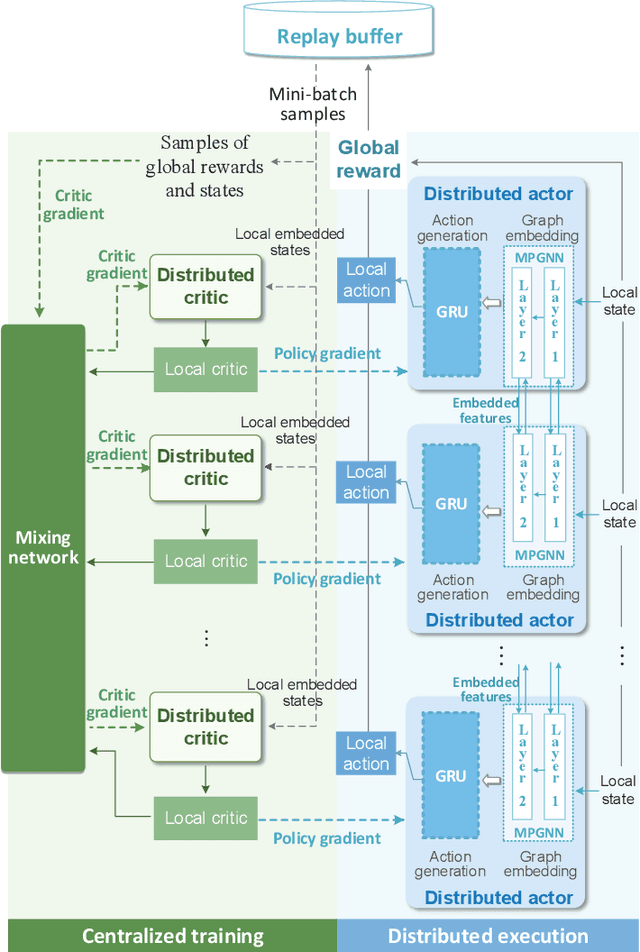
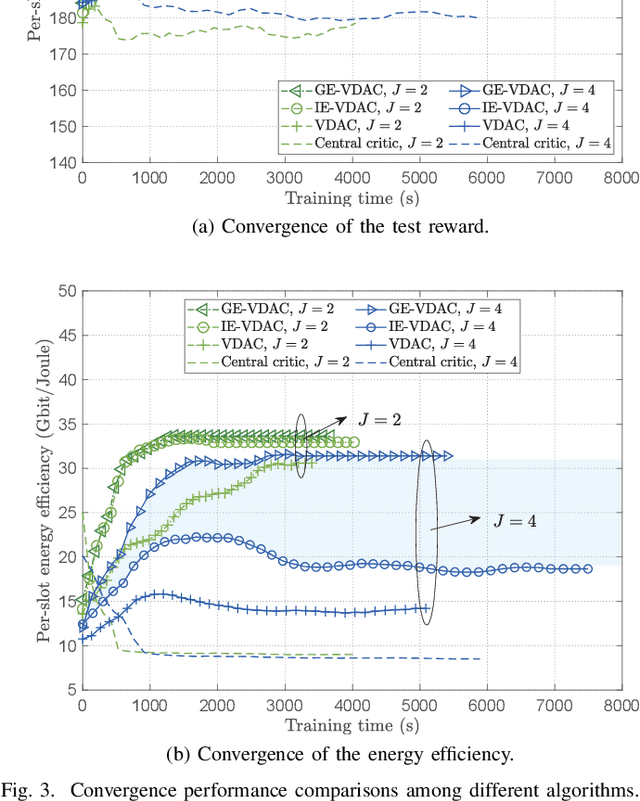
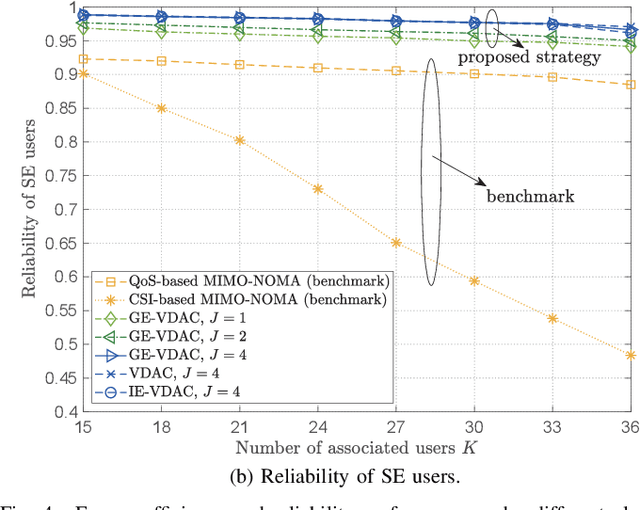
With the accelerated development of immersive applications and the explosive increment of internet-of-things (IoT) terminals, 6G would introduce terahertz (THz) massive multiple-input multiple-output non-orthogonal multiple access (MIMO-NOMA) technologies to meet the ultra-high-speed transmission and massive connectivity requirements. Nevertheless, the unreliability of THz transmissions and the extreme heterogeneity of device requirements pose critical challenges for practical applications. To address these challenges, we propose a novel smart reconfigurable THz MIMO-NOMA framework, which can realize customizable and intelligent communications by flexibly and coordinately reconfiguring hybrid beams through the cooperation between access points (APs) and reconfigurable intelligent surfaces (RISs). The optimization problem is formulated as a decentralized partially-observable Markov decision process (Dec-POMDP) to maximize the network energy efficiency, while guaranteeing the diversified users' performance, via a joint RIS element selection, coordinated discrete phase-shift control, and power allocation strategy. To solve the above non-convex, strongly coupled, and highly complex mixed integer nonlinear programming (MINLP) problem, we propose a novel multi-agent deep reinforcement learning (MADRL) algorithm, namely graph-embedded value-decomposition actor-critic (GE-VDAC), that embeds the interaction information of agents, and learns a locally optimal solution through a distributed policy. Numerical results demonstrate that the proposed algorithm achieves highly customized communications and outperforms traditional MADRL algorithms.
UNIFY: Multi-Belief Bayesian Grid Framework based on Automotive Radar
Apr 24, 2021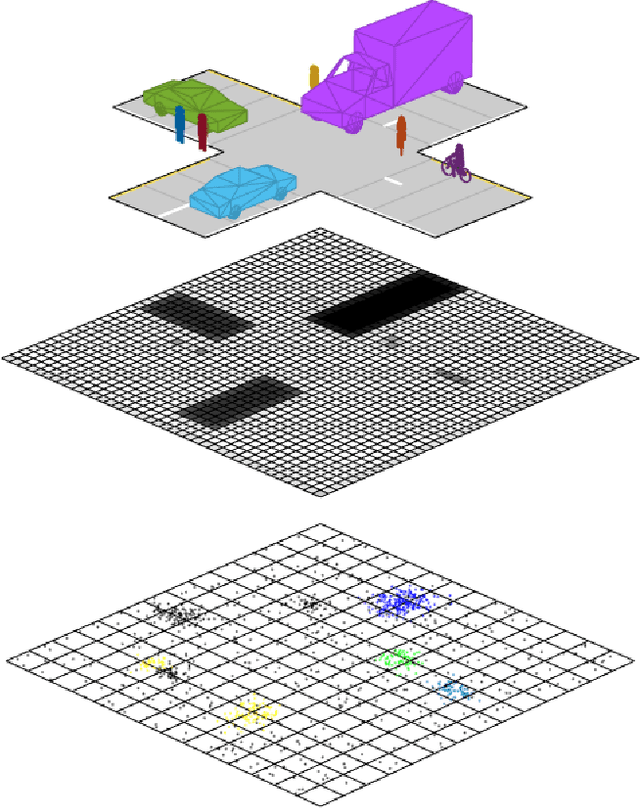
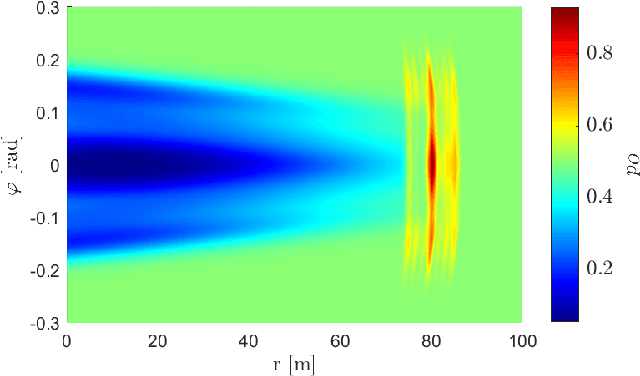
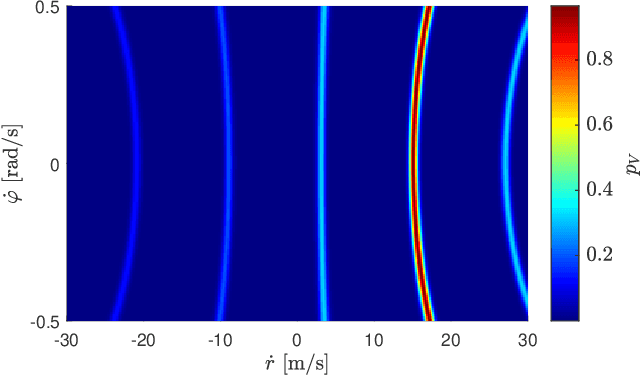
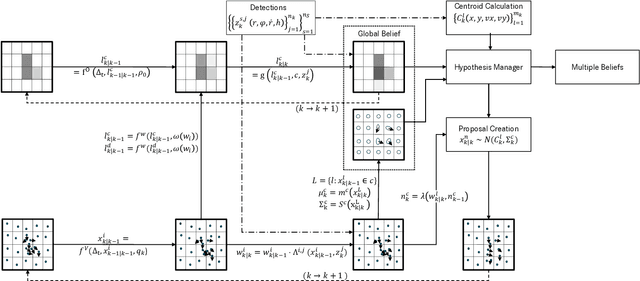
Grid maps are widely established for the representation of static objects in robotics and automotive applications. Though, incorporating velocity information is still widely examined because of the increased complexity of dynamic grids concerning both velocity measurement models for radar sensors and the representation of velocity in a grid framework. In this paper, both issues are addressed: sensor models and an efficient grid framework, which are required to ensure efficient and robust environment perception with radar. To that, we introduce new inverse radar sensor models covering radar sensor artifacts such as measurement ambiguities to integrate automotive radar sensors for improved velocity estimation. Furthermore, we introduce UNIFY, a multiple belief Bayesian grid map framework for static occupancy and velocity estimation with independent layers. The proposed UNIFY framework utilizes a grid-cell-based layer to provide occupancy information and a particle-based velocity layer for motion state estimation in an autonomous vehicle's environment. Each UNIFY layer allows individual execution as well as simultaneous execution of both layers for optimal adaption to varying environments in autonomous driving applications. UNIFY was tested and evaluated in terms of plausibility and efficiency on a large real-world radar data-set in challenging traffic scenarios covering different densities in urban and rural sceneries.
MoDist: Motion Distillation for Self-supervised Video Representation Learning
Jun 17, 2021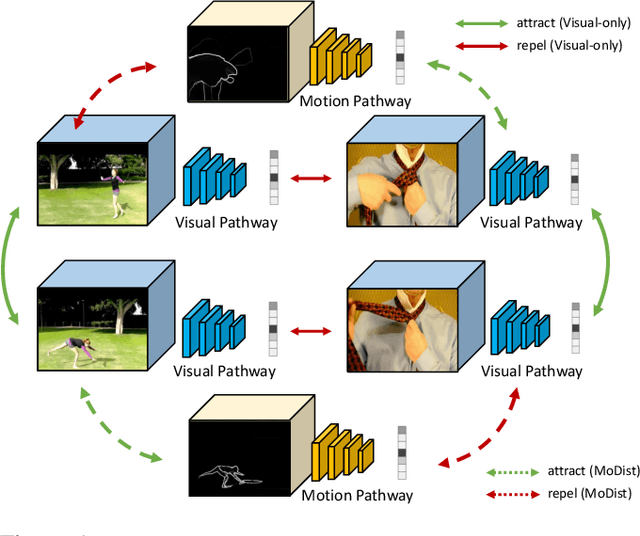
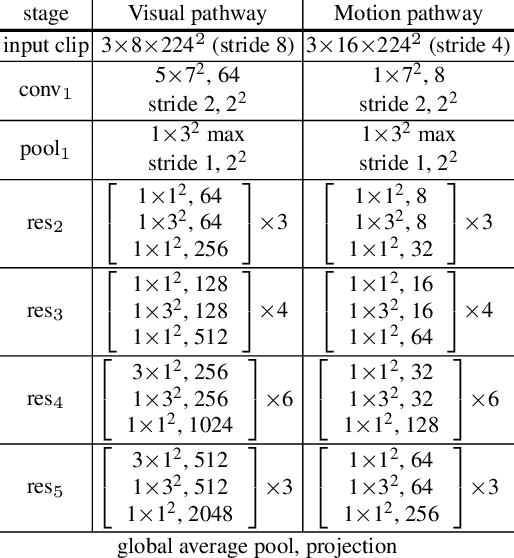

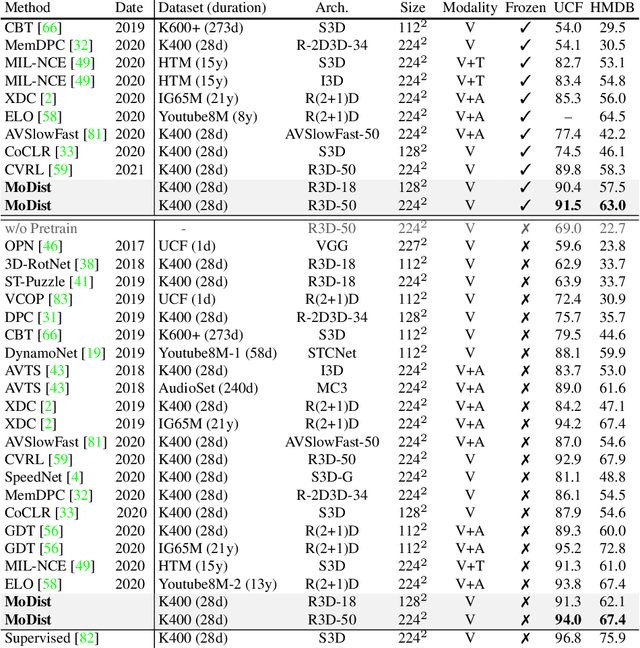
We present MoDist as a novel method to explicitly distill motion information into self-supervised video representations. Compared to previous video representation learning methods that mostly focus on learning motion cues implicitly from RGB inputs, we show that the representation learned with our MoDist method focus more on foreground motion regions and thus generalizes better to downstream tasks. To achieve this, MoDist enriches standard contrastive learning objectives for RGB video clips with a cross-modal learning objective between a Motion pathway and a Visual pathway. We evaluate MoDist on several datasets for both action recognition (UCF101/HMDB51/SSv2) as well as action detection (AVA), and demonstrate state-of-the-art self-supervised performance on all datasets. Furthermore, we show that MoDist representation can be as effective as (in some cases even better than) representations learned with full supervision. Given its simplicity, we hope MoDist could serve as a strong baseline for future research in self-supervised video representation learning.
A Global to Local Double Embedding Method for Multi-person Pose Estimation
Feb 15, 2021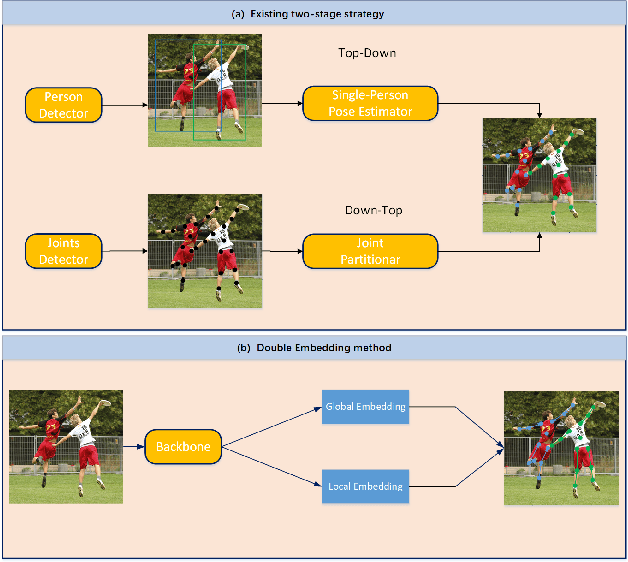
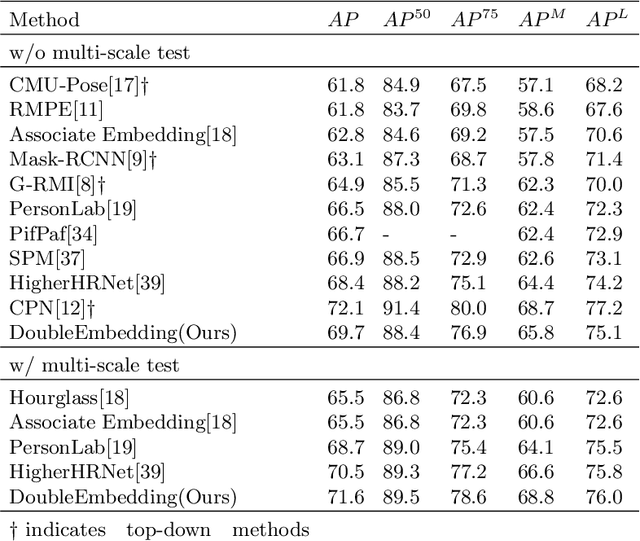
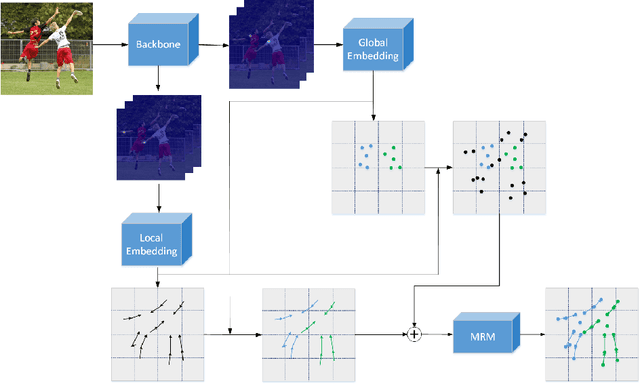
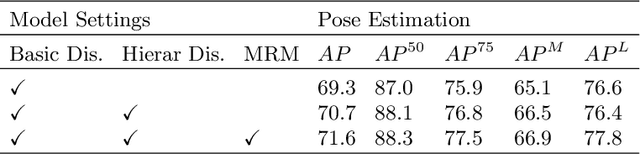
Multi-person pose estimation is a fundamental and challenging problem to many computer vision tasks. Most existing methods can be broadly categorized into two classes: top-down and bottom-up methods. Both of the two types of methods involve two stages, namely, person detection and joints detection. Conventionally, the two stages are implemented separately without considering their interactions between them, and this may inevitably cause some issue intrinsically. In this paper, we present a novel method to simplify the pipeline by implementing person detection and joints detection simultaneously. We propose a Double Embedding (DE) method to complete the multi-person pose estimation task in a global-to-local way. DE consists of Global Embedding (GE) and Local Embedding (LE). GE encodes different person instances and processes information covering the whole image and LE encodes the local limbs information. GE functions for the person detection in top-down strategy while LE connects the rest joints sequentially which functions for joint grouping and information processing in A bottom-up strategy. Based on LE, we design the Mutual Refine Machine (MRM) to reduce the prediction difficulty in complex scenarios. MRM can effectively realize the information communicating between keypoints and further improve the accuracy. We achieve the competitive results on benchmarks MSCOCO, MPII and CrowdPose, demonstrating the effectiveness and generalization ability of our method.