 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pedestrian Detection in 3D Point Clouds using Deep Neural Networks
May 03, 2021

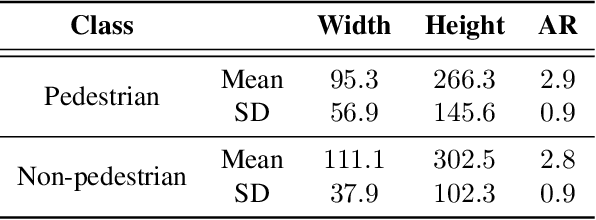
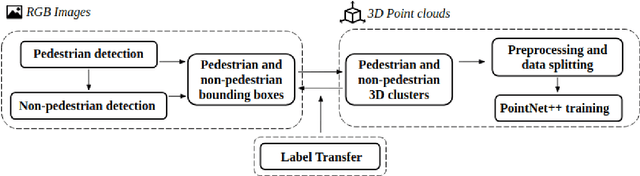
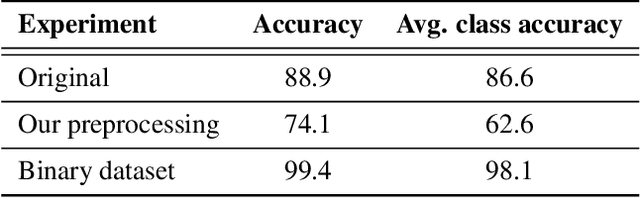
Detecting pedestrians is a crucial task in autonomous driving systems to ensure the safety of drivers and pedestrians. The technologies involved in these algorithms must be precise and reliable, regardless of environment conditions. Relying solely on RGB cameras may not be enough to recognize road environments in situations where cameras cannot capture scenes properly. Some approaches aim to compensate for these limitations by combining RGB cameras with TOF sensors, such as LIDARs. However, there are few works that address this problem using exclusively the 3D geometric information provided by LIDARs. In this paper, we propose a PointNet++ based architecture to detect pedestrians in dense 3D point clouds. The aim is to explore the potential contribution of geometric information alone in pedestrian detection systems. We also present a semi-automatic labeling system that transfers pedestrian and non-pedestrian labels from RGB images onto the 3D domain. The fact that our datasets have RGB registered with point clouds enables label transferring by back projection from 2D bounding boxes to point clouds, with only a light manual supervision to validate results. We train PointNet++ with the geometry of the resulting 3D labelled clusters. The evaluation confirms the effectiveness of the proposed method, yielding precision and recall values around 98%.
Bilingual Alignment Pre-training for Zero-shot Cross-lingual Transfer
Jun 03, 2021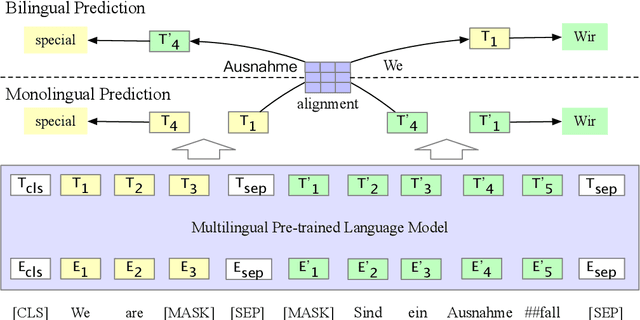
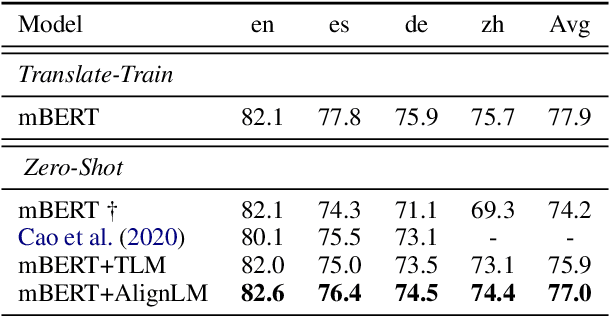
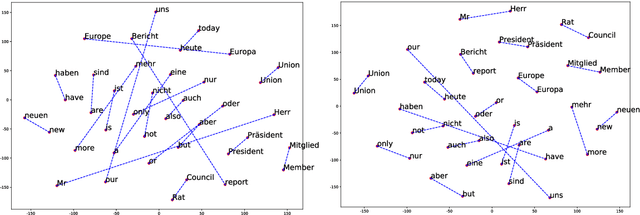
Multilingual pre-trained models have achieved remarkable transfer performance by pre-trained on rich kinds of languages. Most of the models such as mBERT are pre-trained on unlabeled corpora. The static and contextual embeddings from the models could not be aligned very well. In this paper, we aim to improve the zero-shot cross-lingual transfer performance by aligning the embeddings better. We propose a pre-training task named Alignment Language Model (AlignLM), which uses the statistical alignment information as the prior knowledge to guide bilingual word prediction. We evaluate our method on multilingual machine reading comprehension and natural language interface tasks. The results show AlignLM can improve the zero-shot performance significantly on MLQA and XNLI datasets.
Standardized Max Logits: A Simple yet Effective Approach for Identifying Unexpected Road Obstacles in Urban-Scene Segmentation
Jul 23, 2021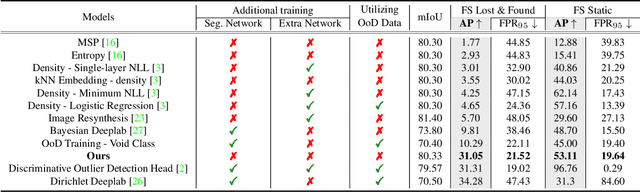
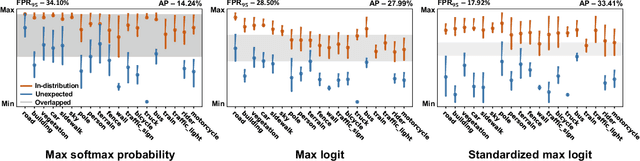


Identifying unexpected objects on roads in semantic segmentation (e.g., identifying dogs on roads) is crucial in safety-critical applications. Existing approaches use images of unexpected objects from external datasets or require additional training (e.g., retraining segmentation networks or training an extra network), which necessitate a non-trivial amount of labor intensity or lengthy inference time. One possible alternative is to use prediction scores of a pre-trained network such as the max logits (i.e., maximum values among classes before the final softmax layer) for detecting such objects. However, the distribution of max logits of each predicted class is significantly different from each other, which degrades the performance of identifying unexpected objects in urban-scene segmentation. To address this issue, we propose a simple yet effective approach that standardizes the max logits in order to align the different distributions and reflect the relative meanings of max logits within each predicted class. Moreover, we consider the local regions from two different perspectives based on the intuition that neighboring pixels share similar semantic information. In contrast to previous approaches, our method does not utilize any external datasets or require additional training, which makes our method widely applicable to existing pre-trained segmentation models. Such a straightforward approach achieves a new state-of-the-art performance on the publicly available Fishyscapes Lost & Found leaderboard with a large margin.
Adapting the Function Approximation Architecture in Online Reinforcement Learning
Jun 17, 2021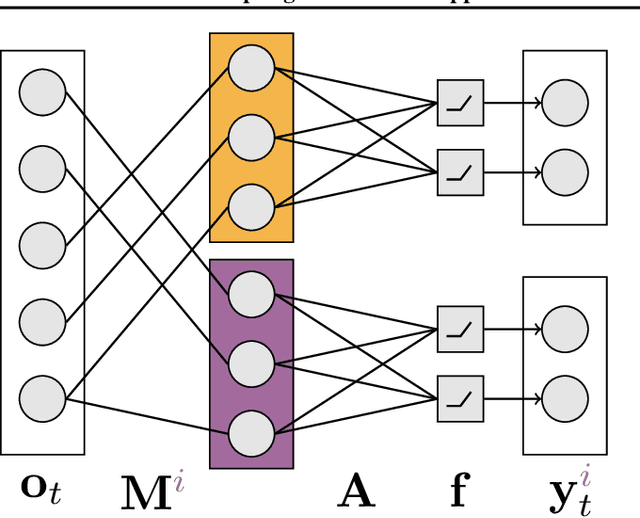
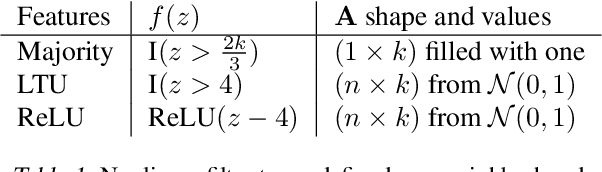

The performance of a reinforcement learning (RL) system depends on the computational architecture used to approximate a value function. Deep learning methods provide both optimization techniques and architectures for approximating nonlinear functions from noisy, high-dimensional observations. However, prevailing optimization techniques are not designed for strictly-incremental online updates. Nor are standard architectures designed for observations with an a priori unknown structure: for example, light sensors randomly dispersed in space. This paper proposes an online RL prediction algorithm with an adaptive architecture that efficiently finds useful nonlinear features. The algorithm is evaluated in a spatial domain with high-dimensional, stochastic observations. The algorithm outperforms non-adaptive baseline architectures and approaches the performance of an architecture given side-channel information. These results are a step towards scalable RL algorithms for more general problems, where the observation structure is not available.
Convolutional Transformer based Dual Discriminator Generative Adversarial Networks for Video Anomaly Detection
Jul 29, 2021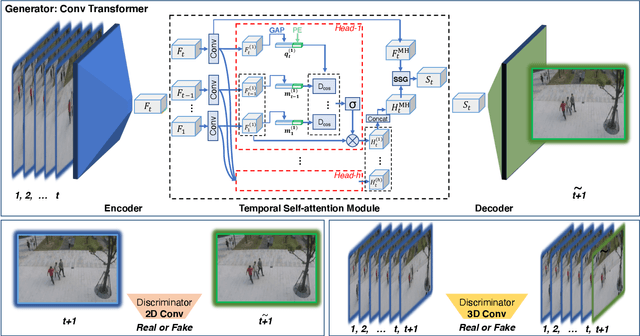

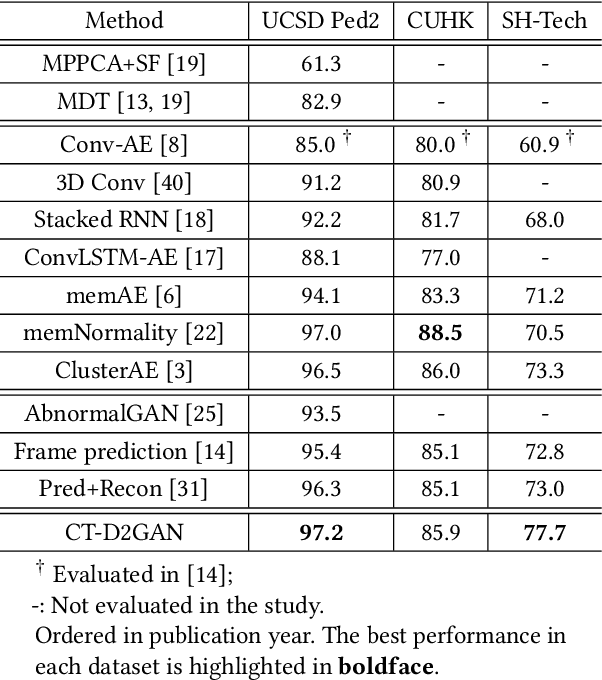
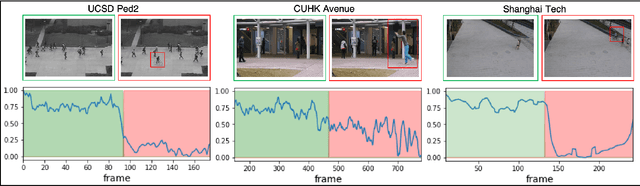
Detecting abnormal activities in real-world surveillance videos is an important yet challenging task as the prior knowledge about video anomalies is usually limited or unavailable. Despite that many approaches have been developed to resolve this problem, few of them can capture the normal spatio-temporal patterns effectively and efficiently. Moreover, existing works seldom explicitly consider the local consistency at frame level and global coherence of temporal dynamics in video sequences. To this end, we propose Convolutional Transformer based Dual Discriminator Generative Adversarial Networks (CT-D2GAN) to perform unsupervised video anomaly detection. Specifically, we first present a convolutional transformer to perform future frame prediction. It contains three key components, i.e., a convolutional encoder to capture the spatial information of the input video clips, a temporal self-attention module to encode the temporal dynamics, and a convolutional decoder to integrate spatio-temporal features and predict the future frame. Next, a dual discriminator based adversarial training procedure, which jointly considers an image discriminator that can maintain the local consistency at frame-level and a video discriminator that can enforce the global coherence of temporal dynamics, is employed to enhance the future frame prediction. Finally, the prediction error is used to identify abnormal video frames. Thoroughly empirical studies on three public video anomaly detection datasets, i.e., UCSD Ped2, CUHK Avenue, and Shanghai Tech Campus, demonstrate the effectiveness of the proposed adversarial spatio-temporal modeling framework.
Unsupervised Resource Allocation with Graph Neural Networks
Jun 17, 2021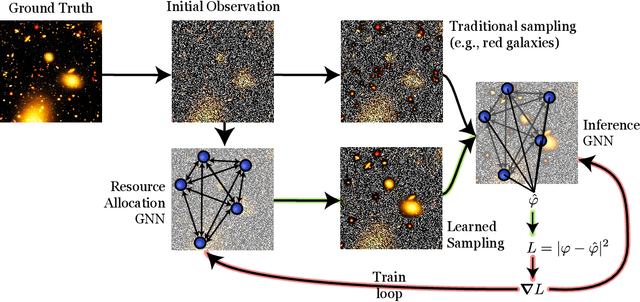

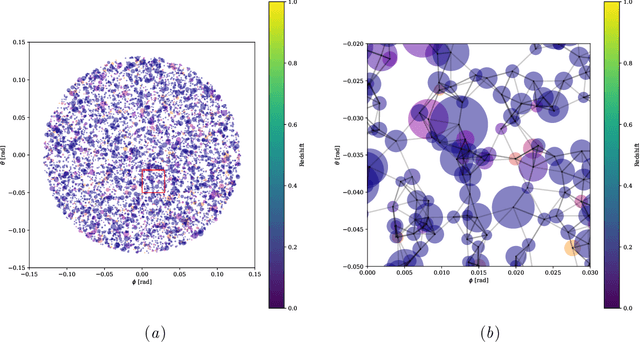
We present an approach for maximizing a global utility function by learning how to allocate resources in an unsupervised way. We expect interactions between allocation targets to be important and therefore propose to learn the reward structure for near-optimal allocation policies with a GNN. By relaxing the resource constraint, we can employ gradient-based optimization in contrast to more standard evolutionary algorithms. Our algorithm is motivated by a problem in modern astronomy, where one needs to select-based on limited initial information-among $10^9$ galaxies those whose detailed measurement will lead to optimal inference of the composition of the universe. Our technique presents a way of flexibly learning an allocation strategy by only requiring forward simulators for the physics of interest and the measurement process. We anticipate that our technique will also find applications in a range of resource allocation problems.
Learning to Equalize OTFS
Jul 17, 2021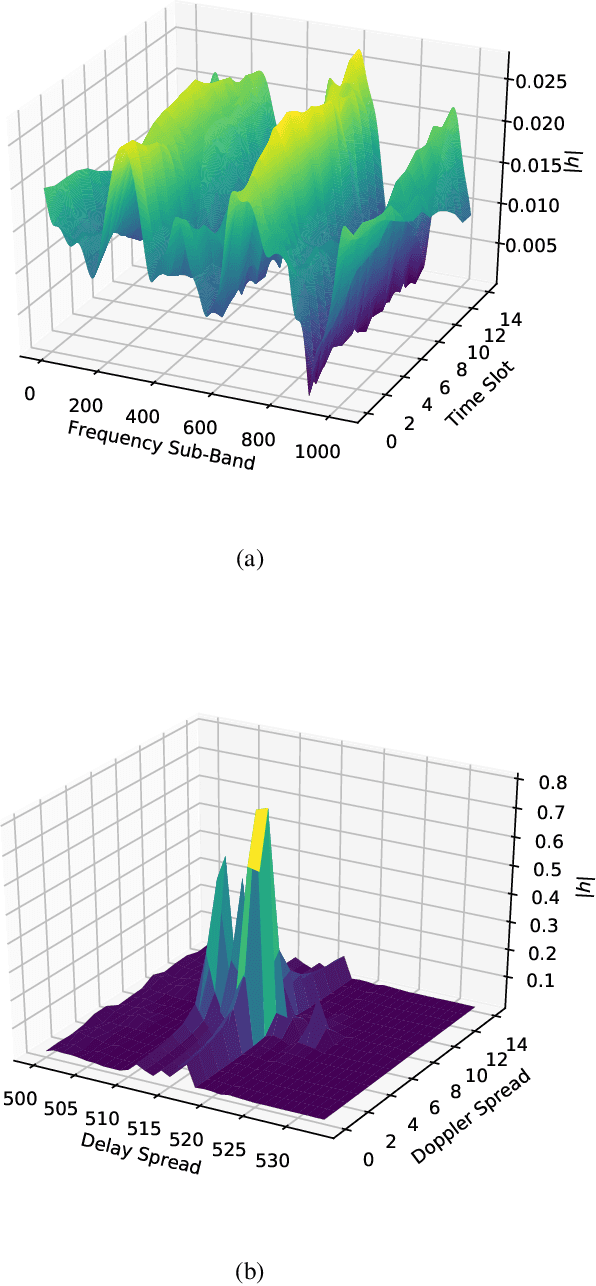
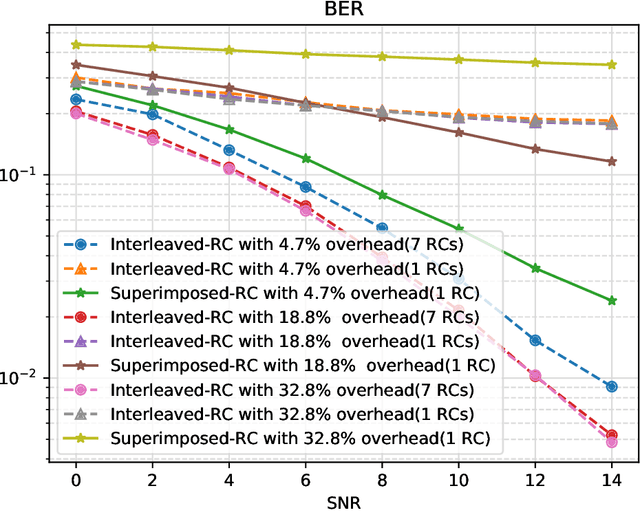
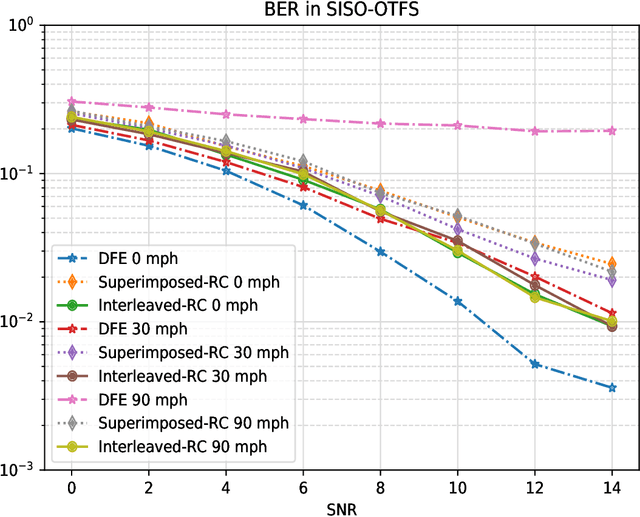
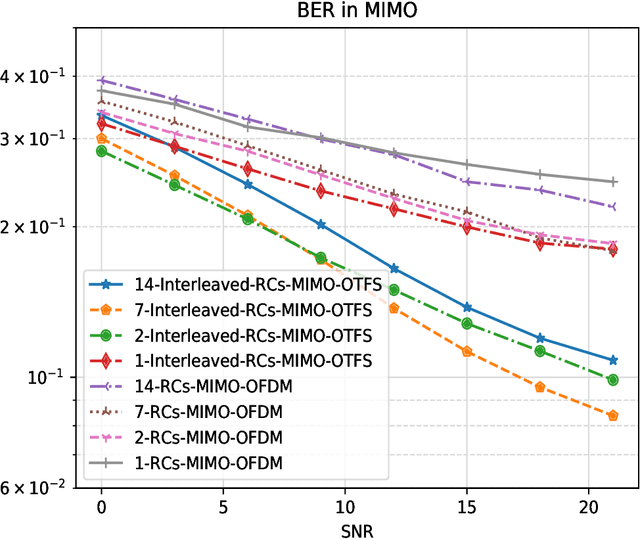
Orthogonal Time Frequency Space (OTFS) is a novel framework that processes modulation symbols via a time-independent channel characterized by the delay-Doppler domain. The conventional waveform, orthogonal frequency division multiplexing (OFDM), requires tracking frequency selective fading channels over the time, whereas OTFS benefits from full time-frequency diversity by leveraging appropriate equalization techniques. In this paper, we consider a neural network-based supervised learning framework for OTFS equalization. Learning of the introduced neural network is conducted in each OTFS frame fulfilling an online learning framework: the training and testing datasets are within the same OTFS-frame over the air. Utilizing reservoir computing, a special recurrent neural network, the resulting one-shot online learning is sufficiently flexible to cope with channel variations among different OTFS frames (e.g., due to the link/rank adaptation and user scheduling in cellular networks). The proposed method does not require explicit channel state information (CSI) and simulation results demonstrate a lower bit error rate (BER) than conventional equalization methods in the low signal-to-noise (SNR) regime under large Doppler spreads. When compared with its neural network-based counterparts for OFDM, the introduced approach for OTFS will lead to a better tradeoff between the processing complexity and the equalization performance.
Multiple Object Tracking with Mixture Density Networks for Trajectory Estimation
Jun 22, 2021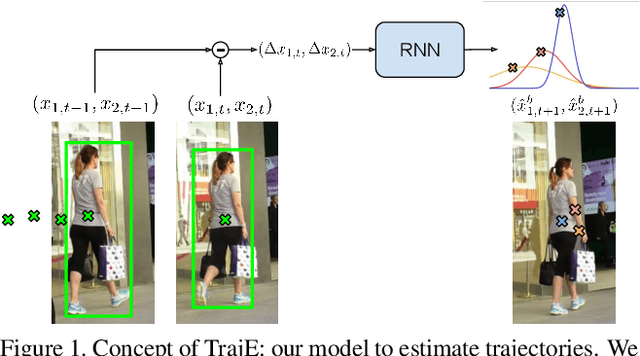
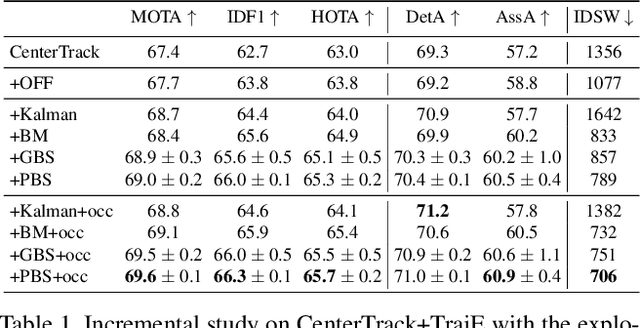

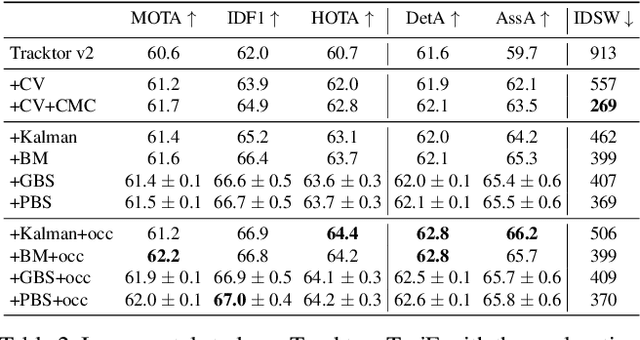
Multiple object tracking faces several challenges that may be alleviated with trajectory information. Knowing the posterior locations of an object helps disambiguating and solving situations such as occlusions, re-identification, and identity switching. In this work, we show that trajectory estimation can become a key factor for tracking, and present TrajE, a trajectory estimator based on recurrent mixture density networks, as a generic module that can be added to existing object trackers. To provide several trajectory hypotheses, our method uses beam search. Also, relying on the same estimated trajectory, we propose to reconstruct a track after an occlusion occurs. We integrate TrajE into two state of the art tracking algorithms, CenterTrack [63] and Tracktor [3]. Their respective performances in the MOTChallenge 2017 test set are boosted 6.3 and 0.3 points in MOTA score, and 1.8 and 3.1 in IDF1, setting a new state of the art for the CenterTrack+TrajE configuration
Modeling Relevance Ranking under the Pre-training and Fine-tuning Paradigm
Aug 12, 2021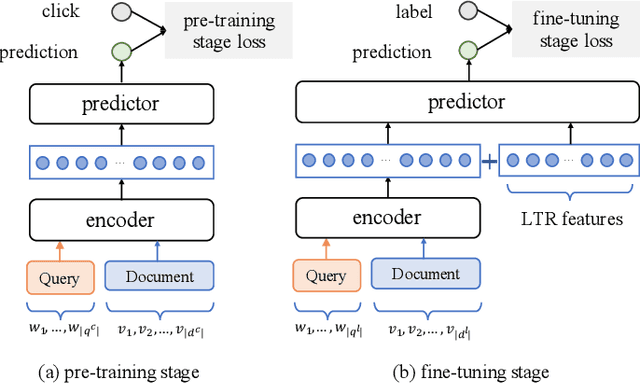
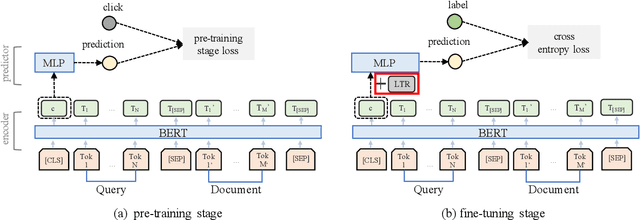
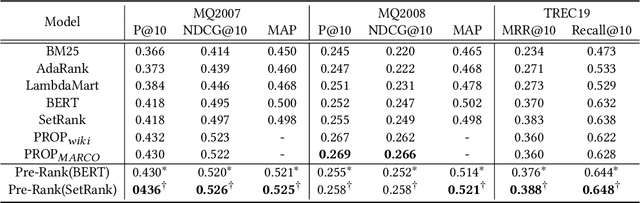
Recently, pre-trained language models such as BERT have been applied to document ranking for information retrieval, which first pre-train a general language model on an unlabeled large corpus and then conduct ranking-specific fine-tuning on expert-labeled relevance datasets. Ideally, an IR system would model relevance from a user-system dualism: the user's view and the system's view. User's view judges the relevance based on the activities of "real users" while the system's view focuses on the relevance signals from the system side, e.g., from the experts or algorithms, etc. Inspired by the user-system relevance views and the success of pre-trained language models, in this paper we propose a novel ranking framework called Pre-Rank that takes both user's view and system's view into consideration, under the pre-training and fine-tuning paradigm. Specifically, to model the user's view of relevance, Pre-Rank pre-trains the initial query-document representations based on large-scale user activities data such as the click log. To model the system's view of relevance, Pre-Rank further fine-tunes the model on expert-labeled relevance data. More importantly, the pre-trained representations, are fine-tuned together with handcrafted learning-to-rank features under a wide and deep network architecture. In this way, Pre-Rank can model the relevance by incorporating the relevant knowledge and signals from both real search users and the IR experts. To verify the effectiveness of Pre-Rank, we showed two implementations by using BERT and SetRank as the underlying ranking model, respectively. Experimental results base on three publicly available benchmarks showed that in both of the implementations, Pre-Rank can respectively outperform the underlying ranking models and achieved state-of-the-art performances.
Modularity in Reinforcement Learning via Algorithmic Independence in Credit Assignment
Jul 03, 2021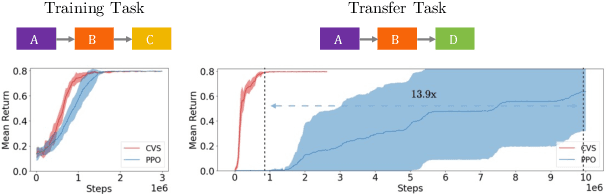
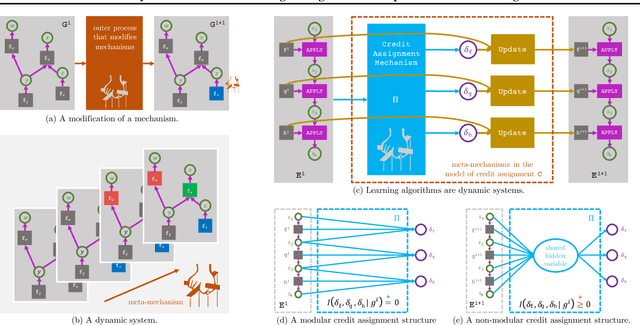
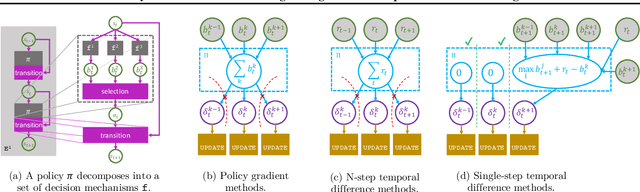
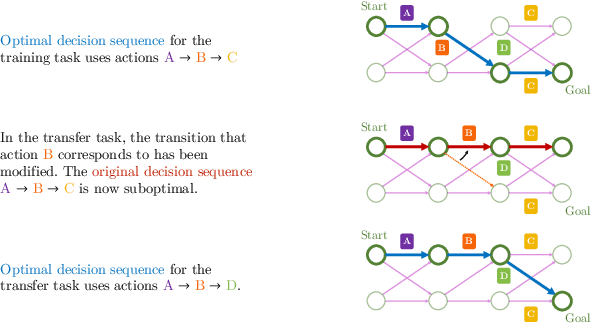
Many transfer problems require re-using previously optimal decisions for solving new tasks, which suggests the need for learning algorithms that can modify the mechanisms for choosing certain actions independently of those for choosing others. However, there is currently no formalism nor theory for how to achieve this kind of modular credit assignment. To answer this question, we define modular credit assignment as a constraint on minimizing the algorithmic mutual information among feedback signals for different decisions. We introduce what we call the modularity criterion for testing whether a learning algorithm satisfies this constraint by performing causal analysis on the algorithm itself. We generalize the recently proposed societal decision-making framework as a more granular formalism than the Markov decision process to prove that for decision sequences that do not contain cycles, certain single-step temporal difference action-value methods meet this criterion while all policy-gradient methods do not. Empirical evidence suggests that such action-value methods are more sample efficient than policy-gradient methods on transfer problems that require only sparse changes to a sequence of previously optimal decisions.