 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Instagram Filter Removal on Fashionable Images
Apr 11, 2021

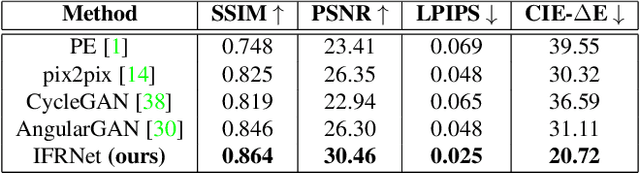

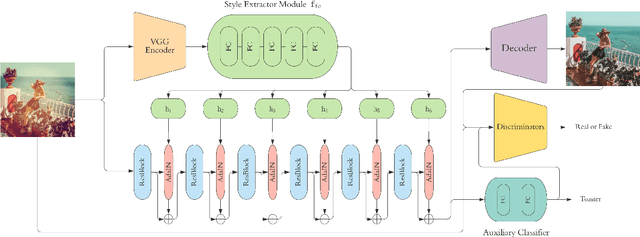
Social media images are generally transformed by filtering to obtain aesthetically more pleasing appearances. However, CNNs generally fail to interpret both the image and its filtered version as the same in the visual analysis of social media images. We introduce Instagram Filter Removal Network (IFRNet) to mitigate the effects of image filters for social media analysis applications. To achieve this, we assume any filter applied to an image substantially injects a piece of additional style information to it, and we consider this problem as a reverse style transfer problem. The visual effects of filtering can be directly removed by adaptively normalizing external style information in each level of the encoder. Experiments demonstrate that IFRNet outperforms all compared methods in quantitative and qualitative comparisons, and has the ability to remove the visual effects to a great extent. Additionally, we present the filter classification performance of our proposed model, and analyze the dominant color estimation on the images unfiltered by all compared methods.
LRG at TREC 2020: Document Ranking with XLNet-Based Models
Feb 28, 2021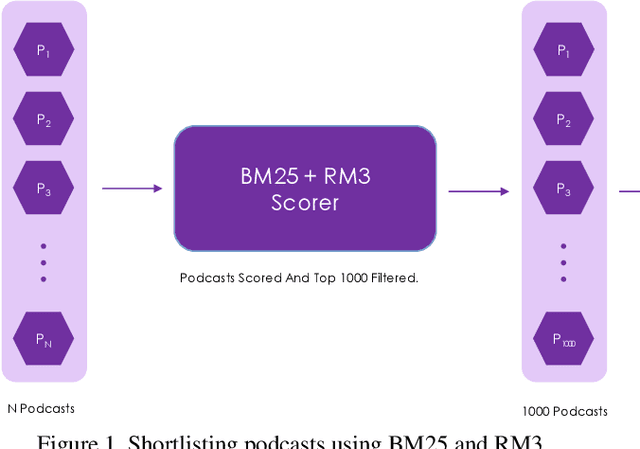

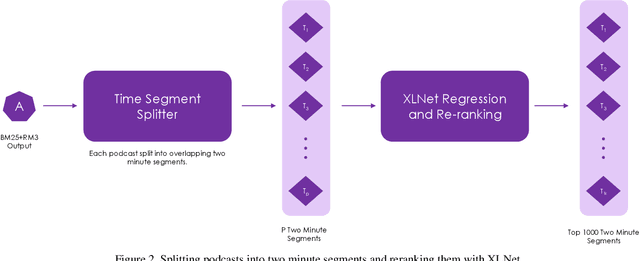
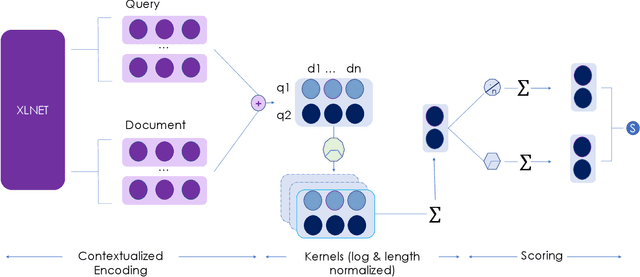
Establishing a good information retrieval system in popular mediums of entertainment is a quickly growing area of investigation for companies and researchers alike. We delve into the domain of information retrieval for podcasts. In Spotify's Podcast Challenge, we are given a user's query with a description to find the most relevant short segment from the given dataset having all the podcasts. Previous techniques that include solely classical Information Retrieval (IR) techniques, perform poorly when descriptive queries are presented. On the other hand, models which exclusively rely on large neural networks tend to perform better. The downside to this technique is that a considerable amount of time and computing power are required to infer the result. We experiment with two hybrid models which first filter out the best podcasts based on user's query with a classical IR technique, and then perform re-ranking on the shortlisted documents based on the detailed description using a transformer-based model.
Adversarial for Good? How the Adversarial ML Community's Values Impede Socially Beneficial Uses of Attacks
Jul 11, 2021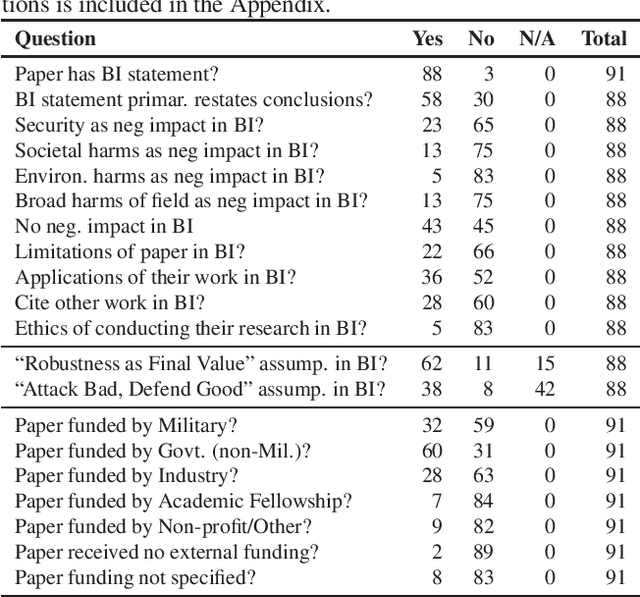
Attacks from adversarial machine learning (ML) have the potential to be used "for good": they can be used to run counter to the existing power structures within ML, creating breathing space for those who would otherwise be the targets of surveillance and control. But most research on adversarial ML has not engaged in developing tools for resistance against ML systems. Why? In this paper, we review the broader impact statements that adversarial ML researchers wrote as part of their NeurIPS 2020 papers and assess the assumptions that authors have about the goals of their work. We also collect information about how authors view their work's impact more generally. We find that most adversarial ML researchers at NeurIPS hold two fundamental assumptions that will make it difficult for them to consider socially beneficial uses of attacks: (1) it is desirable to make systems robust, independent of context, and (2) attackers of systems are normatively bad and defenders of systems are normatively good. That is, despite their expressed and supposed neutrality, most adversarial ML researchers believe that the goal of their work is to secure systems, making it difficult to conceptualize and build tools for disrupting the status quo.
One Map Does Not Fit All: Evaluating Saliency Map Explanation on Multi-Modal Medical Images
Jul 11, 2021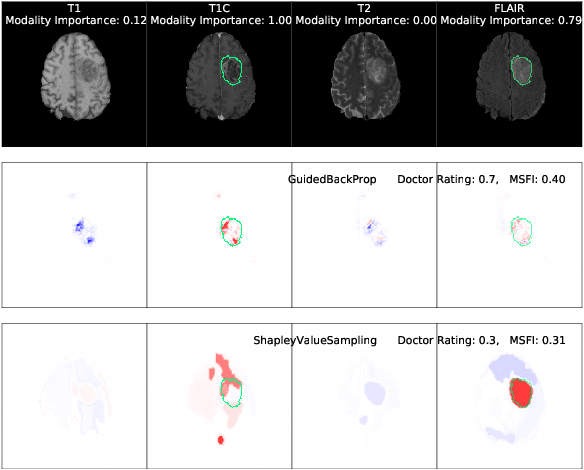

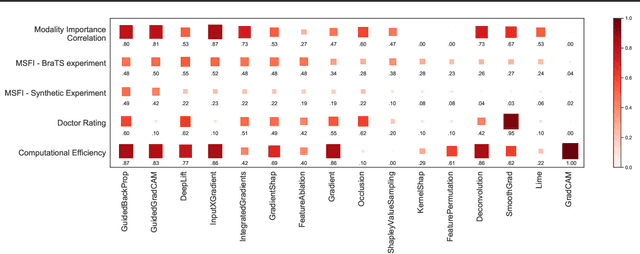
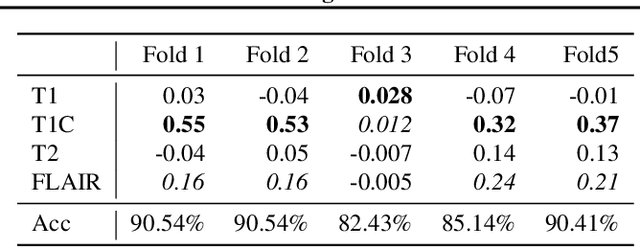
Being able to explain the prediction to clinical end-users is a necessity to leverage the power of AI models for clinical decision support. For medical images, saliency maps are the most common form of explanation. The maps highlight important features for AI model's prediction. Although many saliency map methods have been proposed, it is unknown how well they perform on explaining decisions on multi-modal medical images, where each modality/channel carries distinct clinical meanings of the same underlying biomedical phenomenon. Understanding such modality-dependent features is essential for clinical users' interpretation of AI decisions. To tackle this clinically important but technically ignored problem, we propose the MSFI (Modality-Specific Feature Importance) metric to examine whether saliency maps can highlight modality-specific important features. MSFI encodes the clinical requirements on modality prioritization and modality-specific feature localization. Our evaluations on 16 commonly used saliency map methods, including a clinician user study, show that although most saliency map methods captured modality importance information in general, most of them failed to highlight modality-specific important features consistently and precisely. The evaluation results guide the choices of saliency map methods and provide insights to propose new ones targeting clinical applications.
Individual risk profiling for portable devices using a neural network to process the cognitive reactions and the emotional responses to a multivariate situational risk assessment
Mar 07, 2021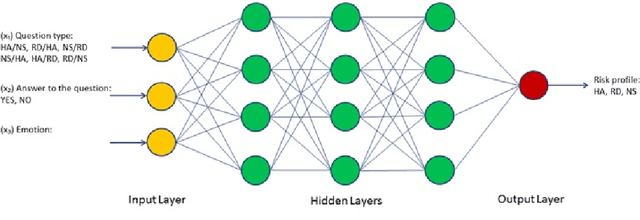
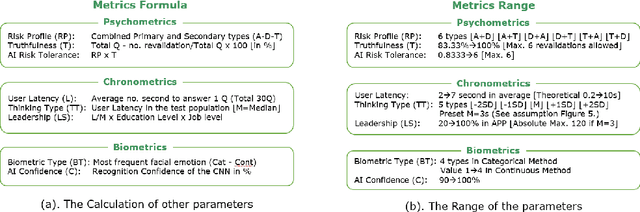
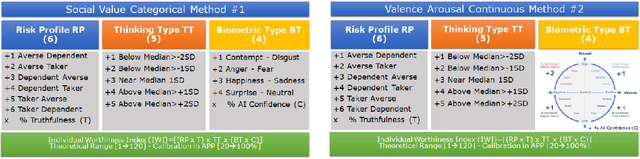
In this paper, we are presenting a novel method and system for neuropsychological performance testing that can establish a link between cognition and emotion. It comprises a portable device used to interact with a cloud service which stores user information under username and is logged into by the user through the portable device; the user information is directly captured through the device and is processed by artificial neural network; and this tridimensional information comprises user cognitive reactions, user emotional responses and user chronometrics. The multivariate situational risk assessment is used to evaluate the performance of the subject by capturing the 3 dimensions of each reaction to a series of 30 dichotomous questions describing various situations of daily life and challenging the user's knowledge, values, ethics, and principles. In industrial application, the timing of this assessment will depend on the user's need to obtain a service from a provider such as opening a bank account, getting a mortgage or an insurance policy, authenticating clearance at work or securing online payments.
Improving coreference resolution with automatically predicted prosodic information
Jul 28, 2017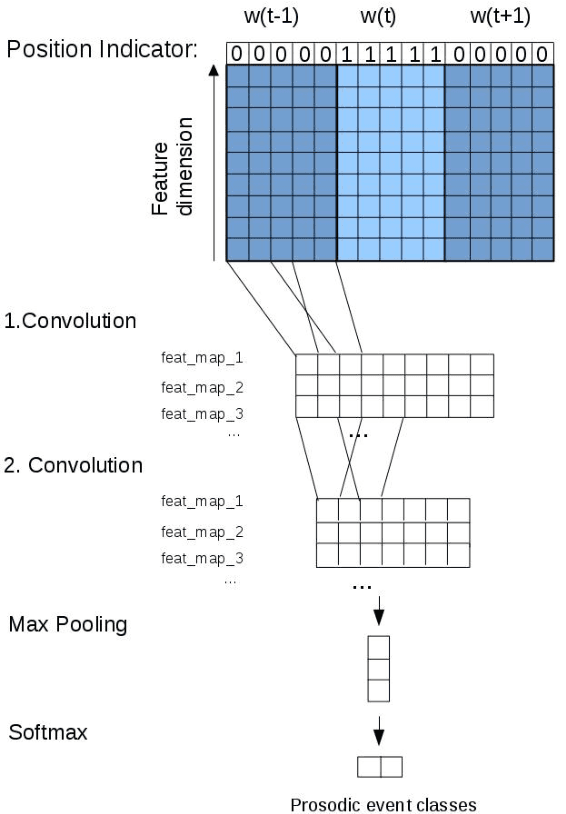
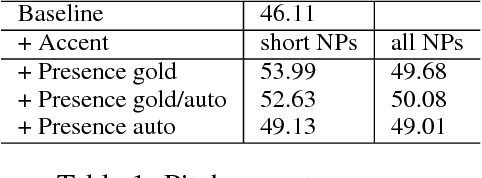
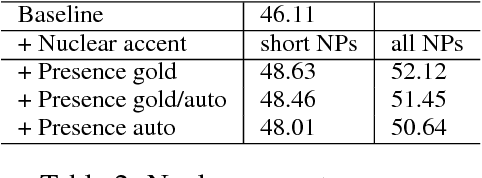
Adding manually annotated prosodic information, specifically pitch accents and phrasing, to the typical text-based feature set for coreference resolution has previously been shown to have a positive effect on German data. Practical applications on spoken language, however, would rely on automatically predicted prosodic information. In this paper we predict pitch accents (and phrase boundaries) using a convolutional neural network (CNN) model from acoustic features extracted from the speech signal. After an assessment of the quality of these automatic prosodic annotations, we show that they also significantly improve coreference resolution.
A Two-stage Deep Network for High Dynamic Range Image Reconstruction
Apr 19, 2021
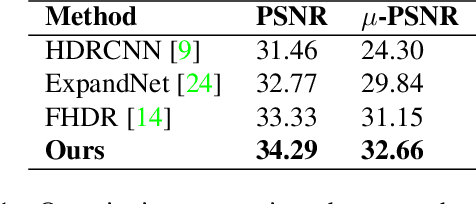


Mapping a single exposure low dynamic range (LDR) image into a high dynamic range (HDR) is considered among the most strenuous image to image translation tasks due to exposure-related missing information. This study tackles the challenges of single-shot LDR to HDR mapping by proposing a novel two-stage deep network. Notably, our proposed method aims to reconstruct an HDR image without knowing hardware information, including camera response function (CRF) and exposure settings. Therefore, we aim to perform image enhancement task like denoising, exposure correction, etc., in the first stage. Additionally, the second stage of our deep network learns tone mapping and bit-expansion from a convex set of data samples. The qualitative and quantitative comparisons demonstrate that the proposed method can outperform the existing LDR to HDR works with a marginal difference. Apart from that, we collected an LDR image dataset incorporating different camera systems. The evaluation with our collected real-world LDR images illustrates that the proposed method can reconstruct plausible HDR images without presenting any visual artefacts. Code available: https://github. com/sharif-apu/twostageHDR_NTIRE21.
Leveraging Evidential Deep Learning Uncertainties with Graph-based Clustering to Detect Anomalies
Jul 04, 2021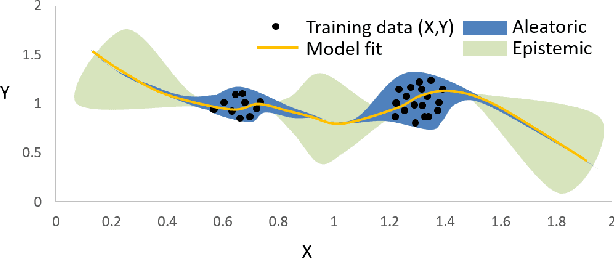
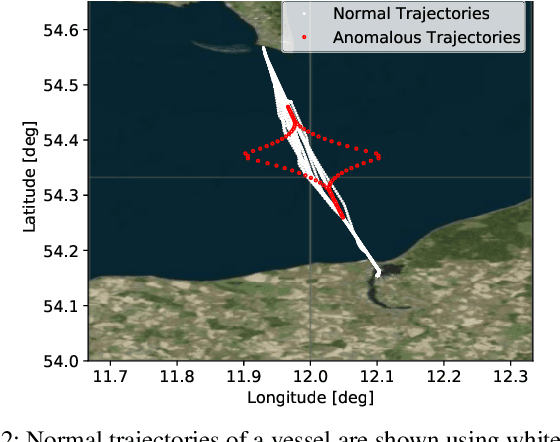
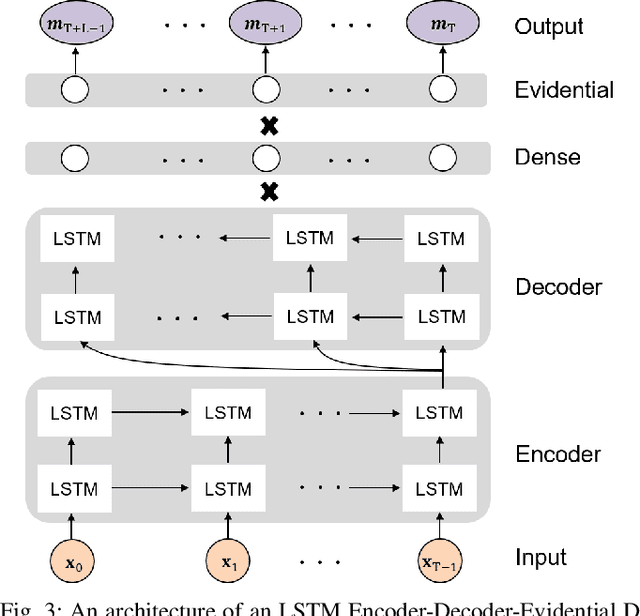
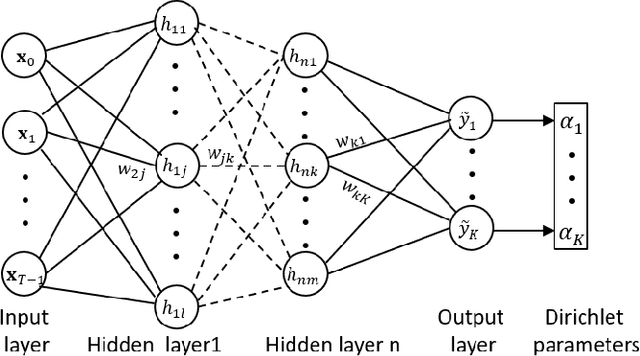
Understanding and representing traffic patterns are key to detecting anomalies in the maritime domain. To this end, we propose a novel graph-based traffic representation and association scheme to cluster trajectories of vessels using automatic identification system (AIS) data. We utilize the (un)clustered data to train a recurrent neural network (RNN)-based evidential regression model, which can predict a vessel's trajectory at future timesteps with its corresponding prediction uncertainty. This paper proposes the usage of a deep learning (DL)-based uncertainty estimation in detecting maritime anomalies, such as unusual vessel maneuvering. Furthermore, we utilize the evidential deep learning classifiers to detect unusual turns of vessels and the loss of AIS signal using predicted class probabilities with associated uncertainties. Our experimental results suggest that using graph-based clustered data improves the ability of the DL models to learn the temporal-spatial correlation of data and associated uncertainties. Using different AIS datasets and experiments, we demonstrate that the estimated prediction uncertainty yields fundamental information for the detection of traffic anomalies in the maritime and, possibly in other domains.
Representation Learning in Continuous-Time Score-Based Generative Models
May 29, 2021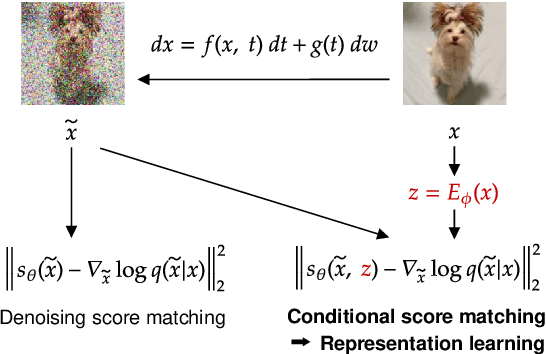
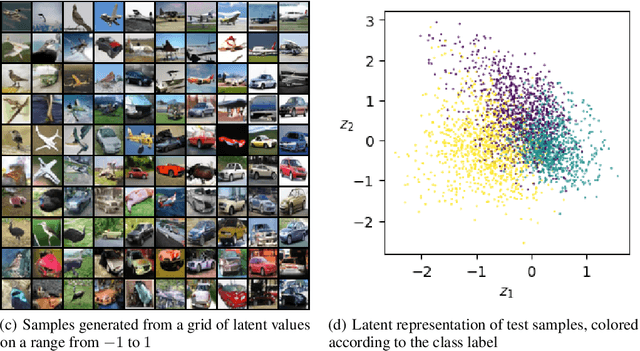
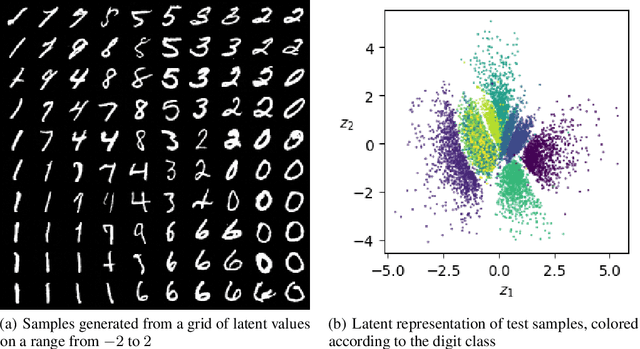
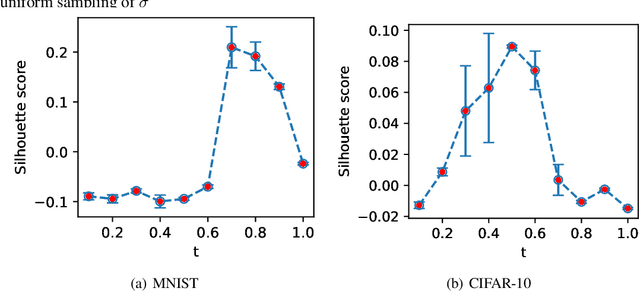
Score-based methods represented as stochastic differential equations on a continuous time domain have recently proven successful as a non-adversarial generative model. Training such models relies on denoising score matching, which can be seen as multi-scale denoising autoencoders. Here, we augment the denoising score-matching framework to enable representation learning without any supervised signal. GANs and VAEs learn representations by directly transforming latent codes to data samples. In contrast, score-based representation learning relies on a new formulation of the denoising score-matching objective and thus encodes information needed for denoising. We show how this difference allows for manual control of the level of detail encoded in the representation.
The Case for Translation-Invariant Self-Attention in Transformer-Based Language Models
Jun 03, 2021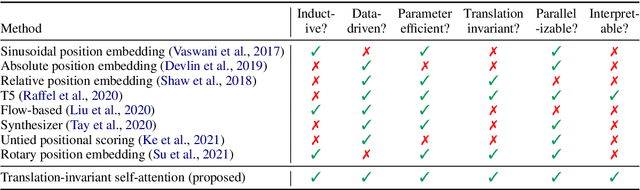
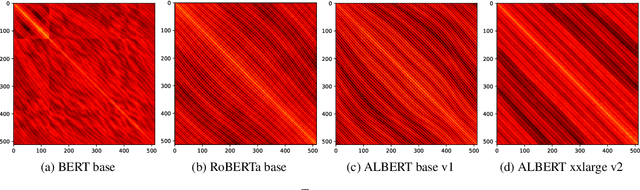
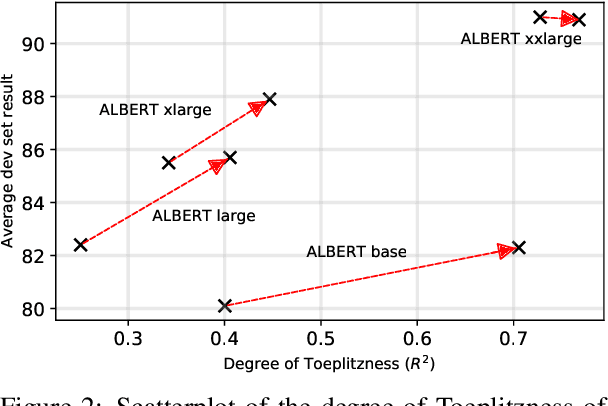
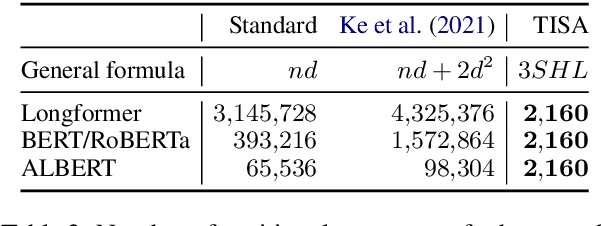
Mechanisms for encoding positional information are central for transformer-based language models. In this paper, we analyze the position embeddings of existing language models, finding strong evidence of translation invariance, both for the embeddings themselves and for their effect on self-attention. The degree of translation invariance increases during training and correlates positively with model performance. Our findings lead us to propose translation-invariant self-attention (TISA), which accounts for the relative position between tokens in an interpretable fashion without needing conventional position embeddings. Our proposal has several theoretical advantages over existing position-representation approaches. Experiments show that it improves on regular ALBERT on GLUE tasks, while only adding orders of magnitude less positional parameters.