 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Relightable Neural Video Portrait
Jul 30, 2021
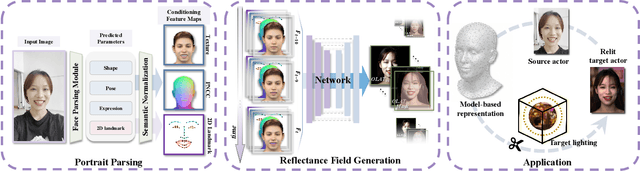

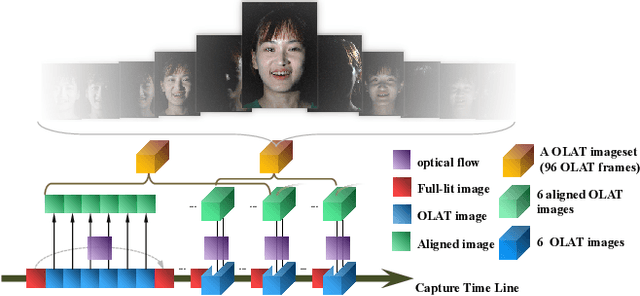
Photo-realistic facial video portrait reenactment benefits virtual production and numerous VR/AR experiences. The task remains challenging as the portrait should maintain high realism and consistency with the target environment. In this paper, we present a relightable neural video portrait, a simultaneous relighting and reenactment scheme that transfers the head pose and facial expressions from a source actor to a portrait video of a target actor with arbitrary new backgrounds and lighting conditions. Our approach combines 4D reflectance field learning, model-based facial performance capture and target-aware neural rendering. Specifically, we adopt a rendering-to-video translation network to first synthesize high-quality OLAT imagesets and alpha mattes from hybrid facial performance capture results. We then design a semantic-aware facial normalization scheme to enable reliable explicit control as well as a multi-frame multi-task learning strategy to encode content, segmentation and temporal information simultaneously for high-quality reflectance field inference. After training, our approach further enables photo-realistic and controllable video portrait editing of the target performer. Reliable face poses and expression editing is obtained by applying the same hybrid facial capture and normalization scheme to the source video input, while our explicit alpha and OLAT output enable high-quality relit and background editing. With the ability to achieve simultaneous relighting and reenactment, we are able to improve the realism in a variety of virtual production and video rewrite applications.
SemSegMap- 3D Segment-Based Semantic Localization
Jul 30, 2021
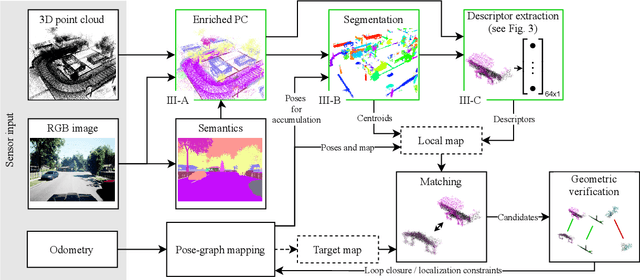
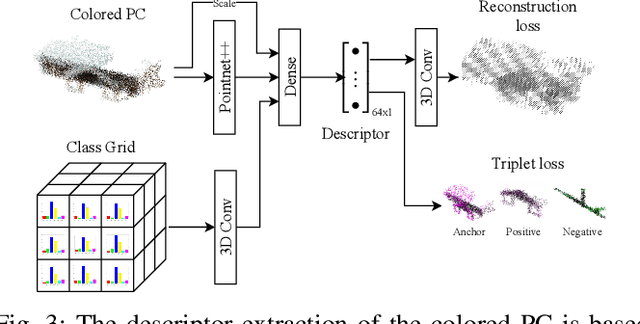
Localization is an essential task for mobile autonomous robotic systems that want to use pre-existing maps or create new ones in the context of SLAM. Today, many robotic platforms are equipped with high-accuracy 3D LiDAR sensors, which allow a geometric mapping, and cameras able to provide semantic cues of the environment. Segment-based mapping and localization have been applied with great success to 3D point-cloud data, while semantic understanding has been shown to improve localization performance in vision based systems. In this paper we combine both modalities in SemSegMap, extending SegMap into a segment based mapping framework able to also leverage color and semantic data from the environment to improve localization accuracy and robustness. In particular, we present new segmentation and descriptor extraction processes. The segmentation process benefits from additional distance information from color and semantic class consistency resulting in more repeatable segments and more overlap after re-visiting a place. For the descriptor, a tight fusion approach in a deep-learned descriptor extraction network is performed leading to a higher descriptiveness for landmark matching. We demonstrate the advantages of this fusion on multiple simulated and real-world datasets and compare its performance to various baselines. We show that we are able to find 50.9% more high-accuracy prior-less global localizations compared to SegMap on challenging datasets using very compact maps while also providing accurate full 6 DoF pose estimates in real-time.
BEFD: Boundary Enhancement and Feature Denoising for Vessel Segmentation
Apr 08, 2021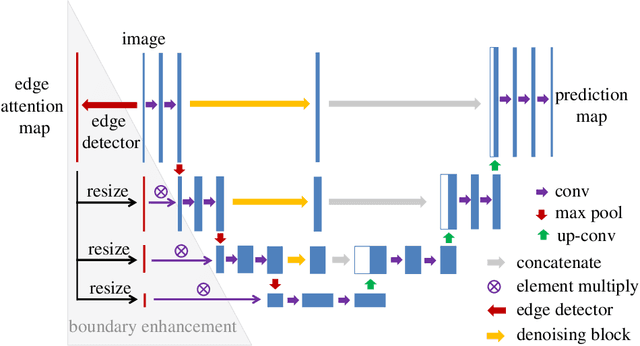
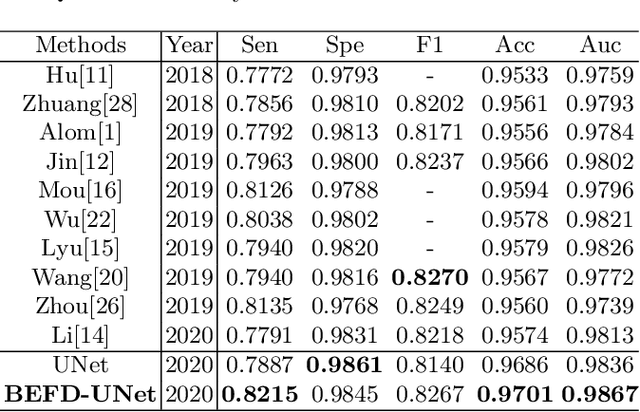
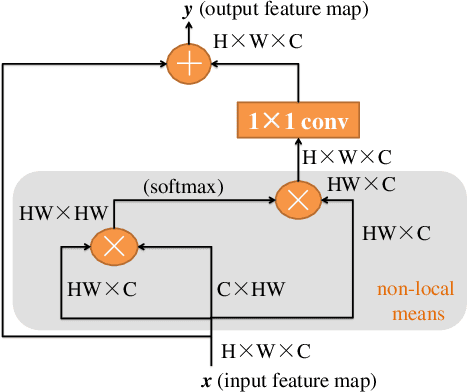
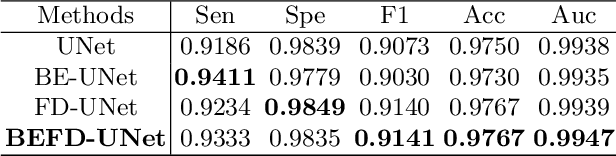
Blood vessel segmentation is crucial for many diagnostic and research applications. In recent years, CNN-based models have leaded to breakthroughs in the task of segmentation, however, such methods usually lose high-frequency information like object boundaries and subtle structures, which are vital to vessel segmentation. To tackle this issue, we propose Boundary Enhancement and Feature Denoising (BEFD) module to facilitate the network ability of extracting boundary information in semantic segmentation, which can be integrated into arbitrary encoder-decoder architecture in an end-to-end way. By introducing Sobel edge detector, the network is able to acquire additional edge prior, thus enhancing boundary in an unsupervised manner for medical image segmentation. In addition, we also utilize a denoising block to reduce the noise hidden in the low-level features. Experimental results on retinal vessel dataset and angiocarpy dataset demonstrate the superior performance of the new BEFD module.
Speech Synthesis from Text and Ultrasound Tongue Image-based Articulatory Input
Jul 05, 2021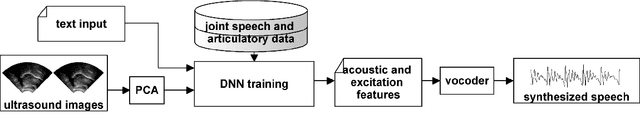
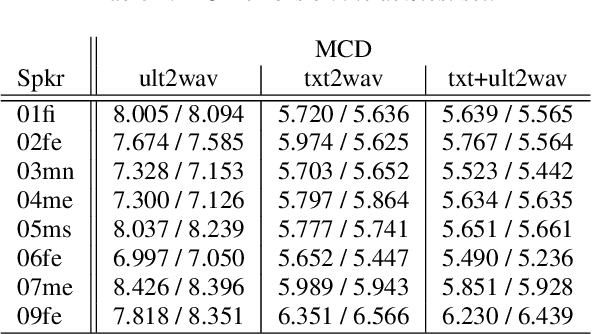
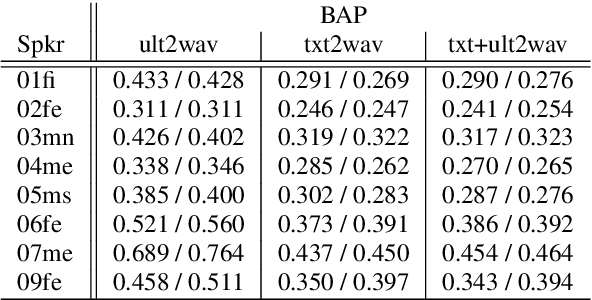
Articulatory information has been shown to be effective in improving the performance of HMM-based and DNN-based text-to-speech synthesis. Speech synthesis research focuses traditionally on text-to-speech conversion, when the input is text or an estimated linguistic representation, and the target is synthesized speech. However, a research field that has risen in the last decade is articulation-to-speech synthesis (with a target application of a Silent Speech Interface, SSI), when the goal is to synthesize speech from some representation of the movement of the articulatory organs. In this paper, we extend traditional (vocoder-based) DNN-TTS with articulatory input, estimated from ultrasound tongue images. We compare text-only, ultrasound-only, and combined inputs. Using data from eight speakers, we show that that the combined text and articulatory input can have advantages in limited-data scenarios, namely, it may increase the naturalness of synthesized speech compared to single text input. Besides, we analyze the ultrasound tongue recordings of several speakers, and show that misalignments in the ultrasound transducer positioning can have a negative effect on the final synthesis performance.
A Multi-Lead Fusion Method for the Accurate Delineation of QRS Complex Location in 12 Lead ECG Signal
Jul 12, 2021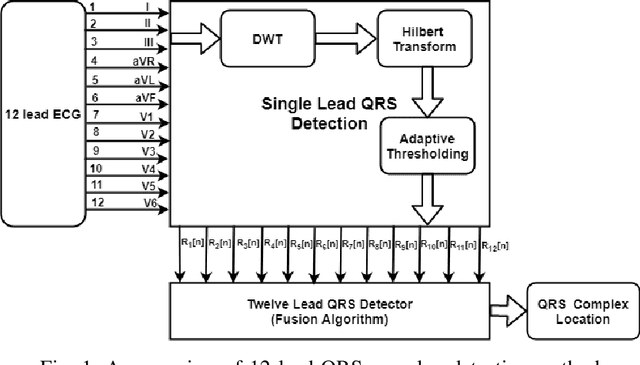
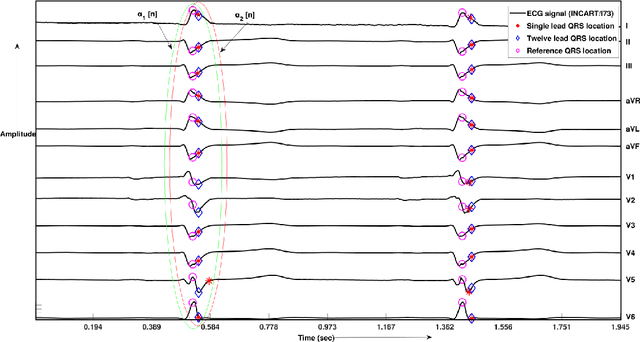
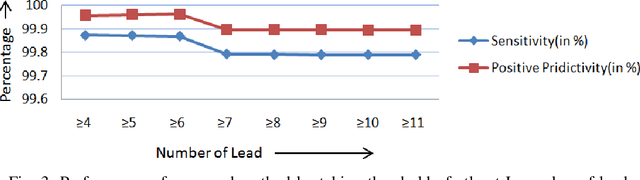
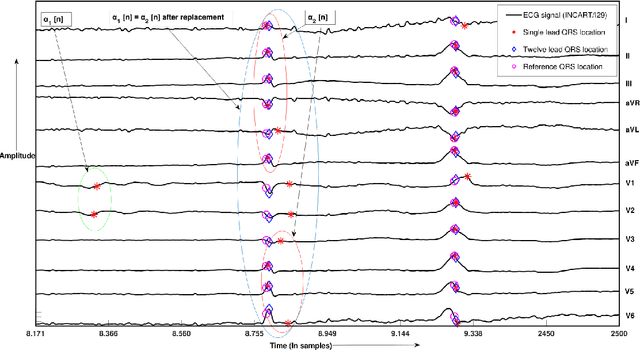
This paper presents a multi-lead fusion method for the accurate and automated detection of the QRS complex location in 12 lead ECG (Electrocardiogram) signals. The proposed multi-lead fusion method accurately delineates the QRS complex by the fusion of detected QRS complexes of the individual 12 leads. The proposed algorithm consists of two major stages. Firstly, the QRS complex location of each lead is detected by the single lead QRS detection algorithm. Secondly, the multi-lead fusion algorithm combines the information of the QRS complex locations obtained in each of the 12 leads. The performance of the proposed algorithm is improved in terms of Sensitivity and Positive Predictivity by discarding the false positives. The proposed method is validated on the ECG signals with various artifacts, inter and intra subject variations. The performance of the proposed method is validated on the long duration recorded ECG signals of St. Petersburg INCART database with Sensitivity of 99.87% and Positive Predictivity of 99.96% and on the short duration recorded ECG signals of CSE (Common Standards for Electrocardiography) multi-lead database with 100% Sensitivity and 99.13% Positive Predictivity.
Reconfigurable Intelligent Surfaces: Potentials, Applications, and Challenges for 6G Wireless Networks
Jul 12, 2021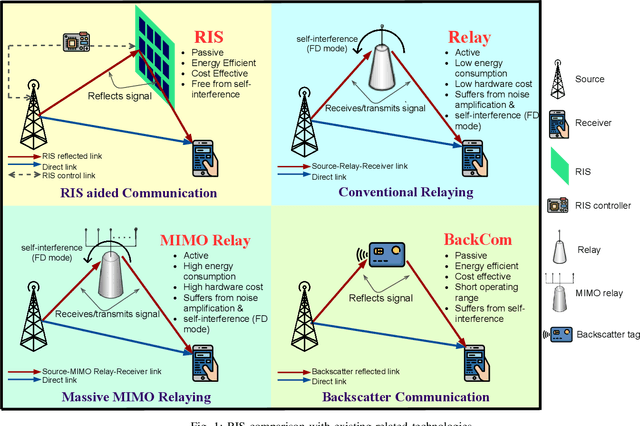
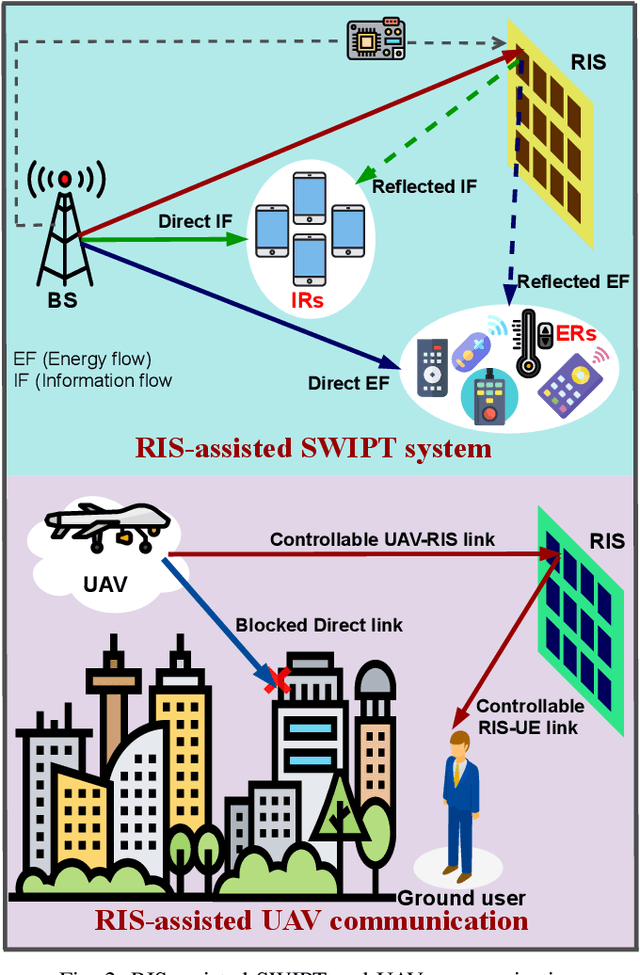
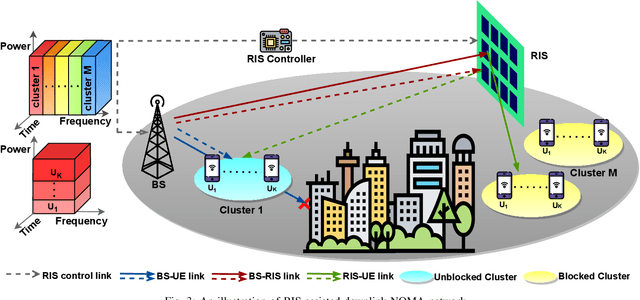
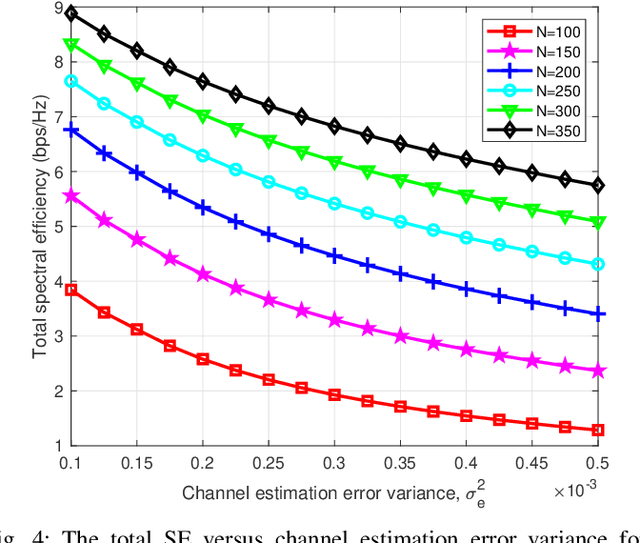
Reconfigurable intelligent surfaces (RISs), with the potential to realize a smart radio environment, have emerged as an energy-efficient and a cost-effective technology to support the services and demands foreseen for coming decades. By leveraging a large number of low-cost passive reflecting elements, RISs introduce a phase-shift in the impinging signal to create a favorable propagation channel between the transmitter and the receiver.~\textcolor{black}{In this article, we provide a tutorial overview of RISs for sixth-generation (6G) wireless networks. Specifically, we present a comprehensive discussion on performance gains that can be achieved by integrating RISs with emerging communication technologies. We address the practical implementation of RIS-assisted networks and expose the crucial challenges, including the RIS reconfiguration, deployment and size optimization, and channel estimation. Furthermore, we explore the integration of RIS and non-orthogonal multiple access (NOMA) under imperfect channel state information (CSI). Our numerical results illustrate the importance of better channel estimation in RIS-assisted networks and indicate the various factors that impact the size of RIS. Finally, we present promising future research directions for realizing RIS-assisted networks in 6G communication.
CrossATNet - A Novel Cross-Attention Based Framework for Sketch-Based Image Retrieval
Apr 20, 2021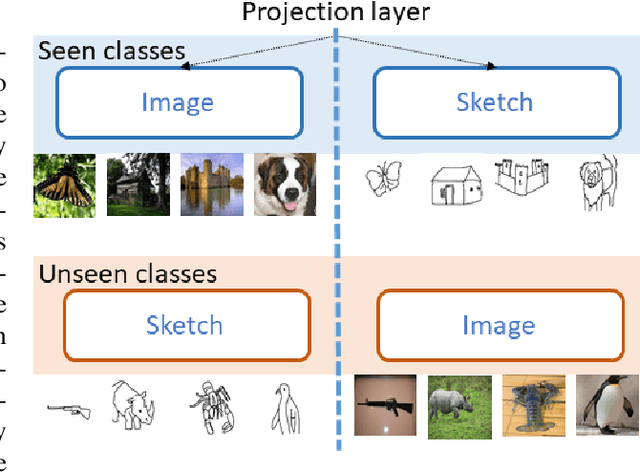
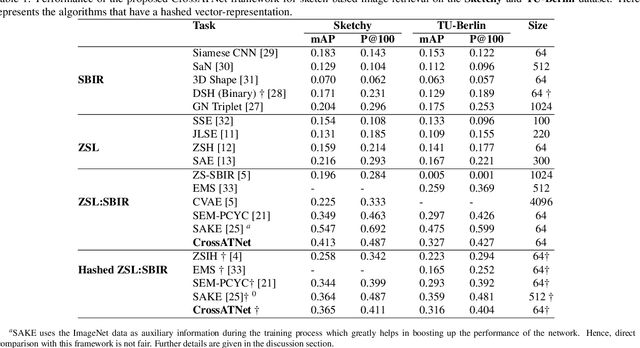
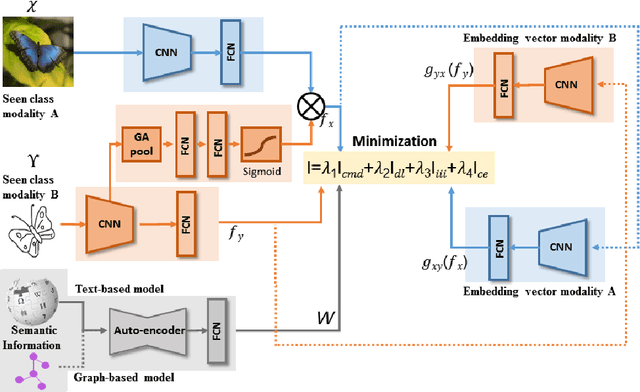
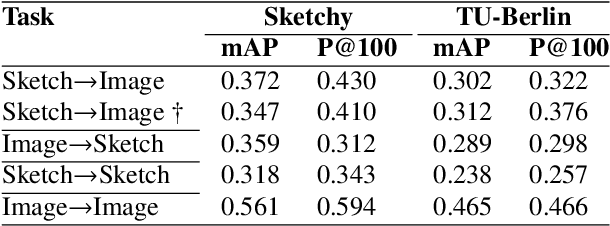
We propose a novel framework for cross-modal zero-shot learning (ZSL) in the context of sketch-based image retrieval (SBIR). Conventionally, the SBIR schema mainly considers simultaneous mappings among the two image views and the semantic side information. Therefore, it is desirable to consider fine-grained classes mainly in the sketch domain using highly discriminative and semantically rich feature space. However, the existing deep generative modeling-based SBIR approaches majorly focus on bridging the gaps between the seen and unseen classes by generating pseudo-unseen-class samples. Besides, violating the ZSL protocol by not utilizing any unseen-class information during training, such techniques do not pay explicit attention to modeling the discriminative nature of the shared space. Also, we note that learning a unified feature space for both the multi-view visual data is a tedious task considering the significant domain difference between sketches and color images. In this respect, as a remedy, we introduce a novel framework for zero-shot SBIR. While we define a cross-modal triplet loss to ensure the discriminative nature of the shared space, an innovative cross-modal attention learning strategy is also proposed to guide feature extraction from the image domain exploiting information from the respective sketch counterpart. In order to preserve the semantic consistency of the shared space, we consider a graph CNN-based module that propagates the semantic class topology to the shared space. To ensure an improved response time during inference, we further explore the possibility of representing the shared space in terms of hash codes. Experimental results obtained on the benchmark TU-Berlin and the Sketchy datasets confirm the superiority of CrossATNet in yielding state-of-the-art results.
Exploiting Heterogeneous Graph Neural Networks with Latent Worker/Task Correlation Information for Label Aggregation in Crowdsourcing
Oct 25, 2020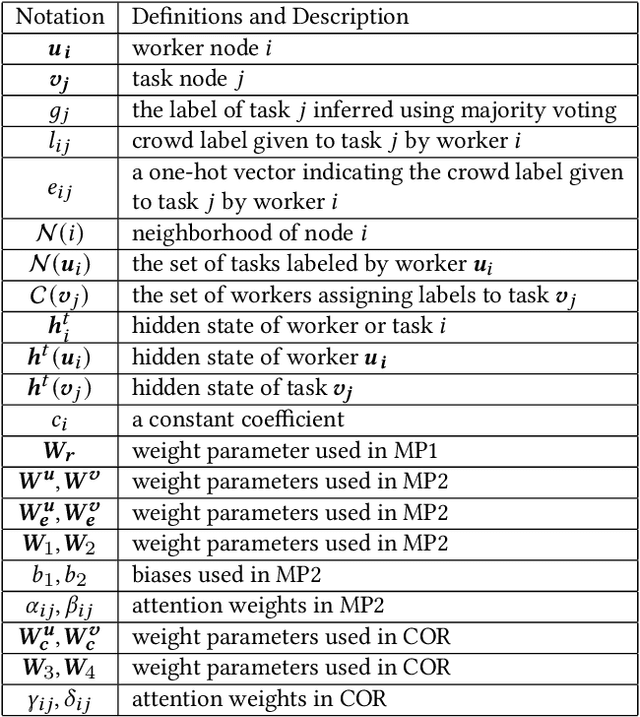

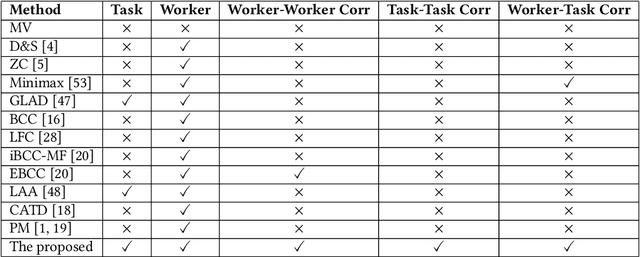
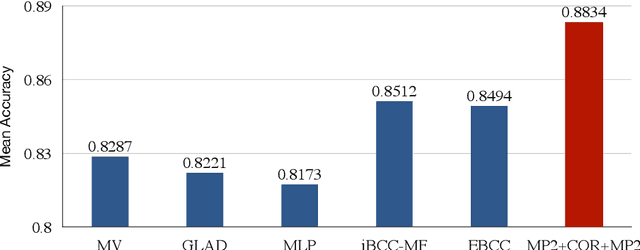
Crowdsourcing has attracted much attention for its convenience to collect labels from non-expert workers instead of experts. However, due to the high level of noise from the non-experts, an aggregation model that learns the true label by incorporating the source credibility is required. In this paper, we propose a novel framework based on graph neural networks for aggregating crowd labels. We construct a heterogeneous graph between workers and tasks and derive a new graph neural network to learn the representations of nodes and the true labels. Besides, we exploit the unknown latent interaction between the same type of nodes (workers or tasks) by adding a homogeneous attention layer in the graph neural networks. Experimental results on 13 real-world datasets show superior performance over state-of-the-art models.
A Closer Look at How Fine-tuning Changes BERT
Jun 27, 2021
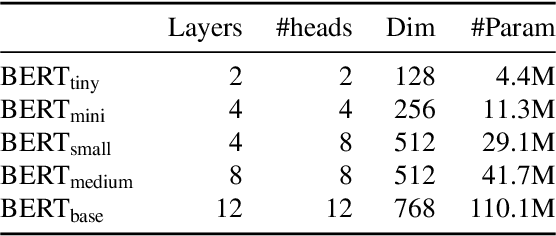
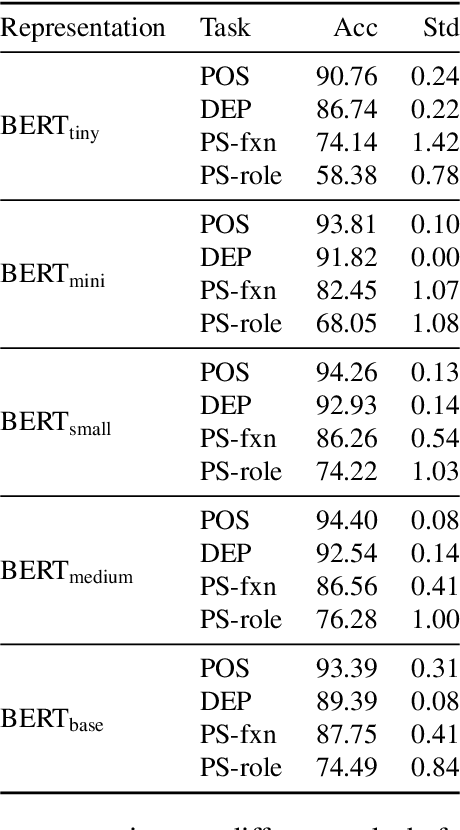
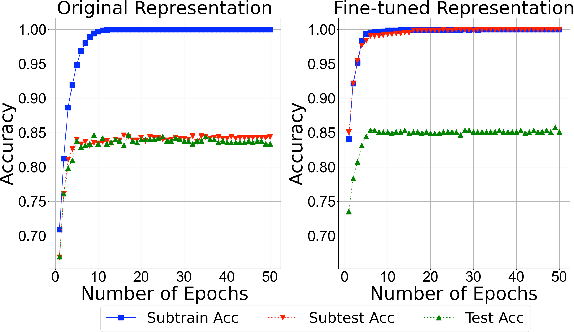
Given the prevalence of pre-trained contextualized representations in today's NLP, there have been several efforts to understand what information such representations contain. A common strategy to use such representations is to fine-tune them for an end task. However, how fine-tuning for a task changes the underlying space is less studied. In this work, we study the English BERT family and use two probing techniques to analyze how fine-tuning changes the space. Our experiments reveal that fine-tuning improves performance because it pushes points associated with a label away from other labels. By comparing the representations before and after fine-tuning, we also discover that fine-tuning does not change the representations arbitrarily; instead, it adjusts the representations to downstream tasks while preserving the original structure. Finally, using carefully constructed experiments, we show that fine-tuning can encode training sets in a representation, suggesting an overfitting problem of a new kind.
SilGAN: Generating driving maneuvers for scenario-based software-in-the-loop testing
Jul 05, 2021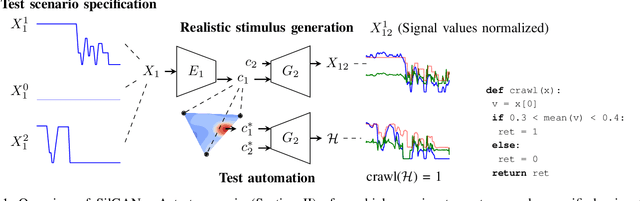
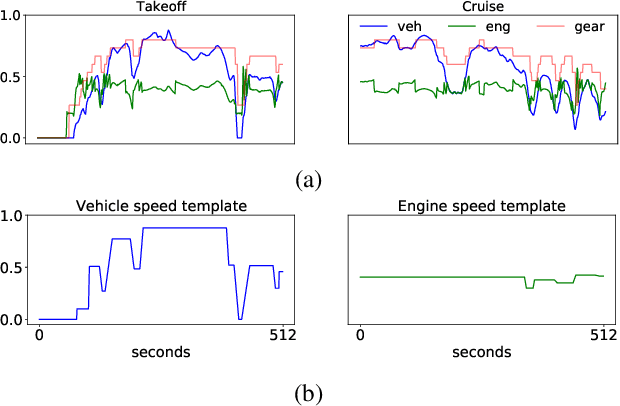
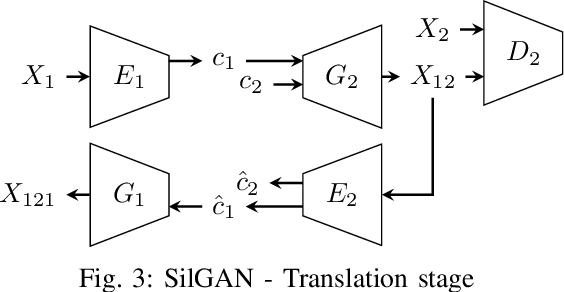
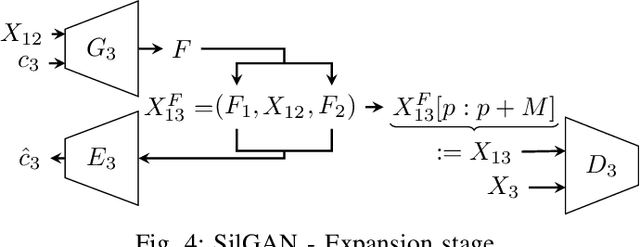
Automotive software testing continues to rely largely upon expensive field tests to ensure quality because alternatives like simulation-based testing are relatively immature. As a step towards lowering reliance on field tests, we present SilGAN, a deep generative model that eases specification, stimulus generation, and automation of automotive software-in-the-loop testing. The model is trained using data recorded from vehicles in the field. Upon training, the model uses a concise specification for a driving scenario to generate realistic vehicle state transitions that can occur during such a scenario. Such authentic emulation of internal vehicle behavior can be used for rapid, systematic and inexpensive testing of vehicle control software. In addition, by presenting a targeted method for searching through the information learned by the model, we show how a test objective like code coverage can be automated. The data driven end-to-end testing pipeline that we present vastly expands the scope and credibility of automotive simulation-based testing. This reduces time to market while helping maintain required standards of quality.