 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GSA-Forecaster: Forecasting Graph-Based Time-Dependent Data with Graph Sequence Attention
Apr 13, 2021
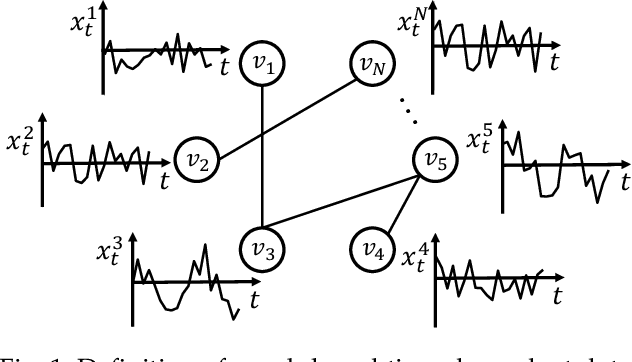


Forecasting graph-based time-dependent data has many practical applications. This task is challenging as models need not only to capture spatial dependency and temporal dependency within the data, but also to leverage useful auxiliary information for accurate predictions. In this paper, we analyze limitations of state-of-the-art models on dealing with temporal dependency. To address this limitation, we propose GSA-Forecaster, a new deep learning model for forecasting graph-based time-dependent data. GSA-Forecaster leverages graph sequence attention (GSA), a new attention mechanism proposed in this paper, for effectively capturing temporal dependency. GSA-Forecaster embeds the graph structure of the data into its architecture to address spatial dependency. GSA-Forecaster also accounts for auxiliary information to further improve predictions. We evaluate GSA-Forecaster with large-scale real-world graph-based time-dependent data and demonstrate its effectiveness over state-of-the-art models with 6.7% RMSE and 5.8% MAPE reduction.
An ontology-based approach to data exchanges for robot navigation on construction sites
Apr 20, 2021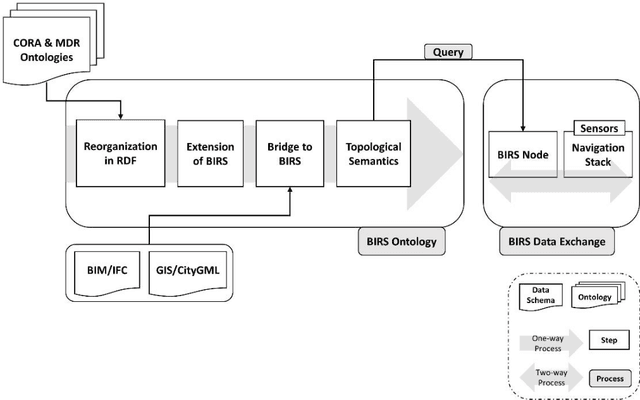

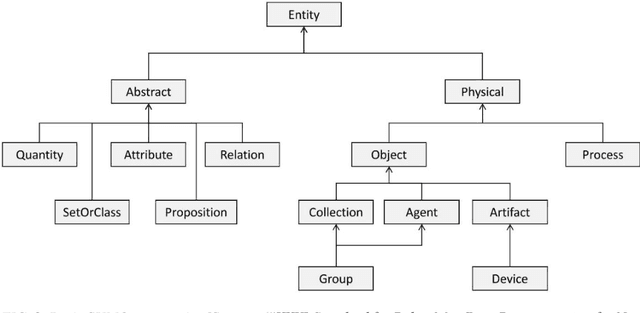
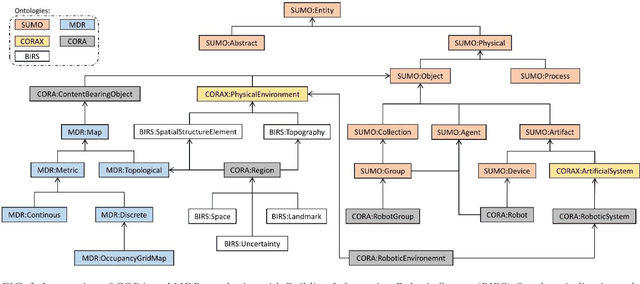
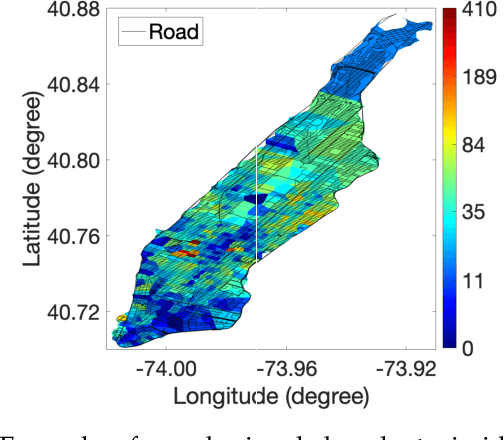
With growth in the use of autonomous Unmanned Ground Vehicle (UGV) for automated data collection from construction projects, the problem of inter-disciplinary semantic data sharing and exchanges between construction and robotic domains has attracted construction stakeholders' attention. Cross-domain data translation requires detailed specifications especially when it comes to semantic data translation. Building Information Modeling (BIM) and Geographic Information System (GIS) are the two technologies to capture and store construction data for indoor structure and outdoor environment respectively. In the absence of a standard format for data exchanges between the construction and robotic domains, the tools of both industries are yet to be integrated in a coherent deployment infrastructure. Hence, the semantics of BIM-GIS cannot be automatically integrated by any robotic platform. To enable semantic data transfer across domains, semantic web technology has been widely used in multidisciplinary areas for interoperability. We exploit it to pave the way to a smarter, quicker and more precise robot navigation on job-sites. This paper develops a semantic web ontology integrating robot navigation and data collection to convey the meanings from BIM-GIS to the robot. The proposed Building Information Robotic System (BIRS) provides construction data that are semantically transferred to the robotic platform and can be used by the robot navigation software stack on construction sites. To reach this objective, we first need to bridge the knowledge representation between construction and robotic domains. Then, we develop a semantic database to integrate with Robot Operating System (ROS) which can communicate with the robot and the navigation system in order to provide the robot with semantic building data at each step of data collection. Finally, the proposed system is validated through a case study.
End-to-end Multi-modal Video Temporal Grounding
Jul 12, 2021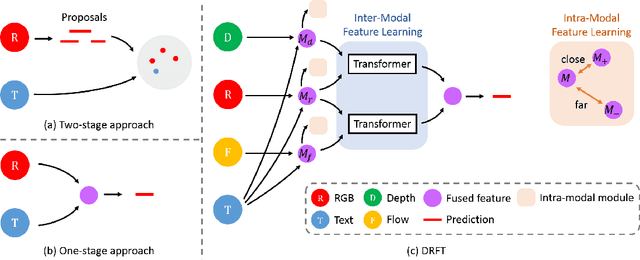

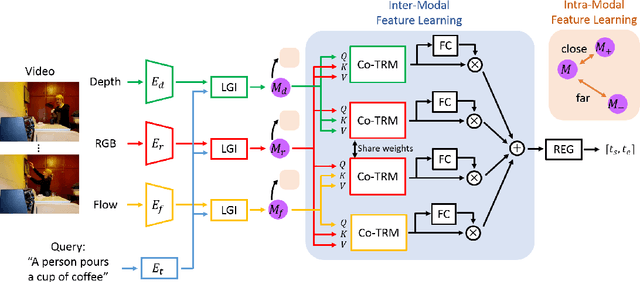
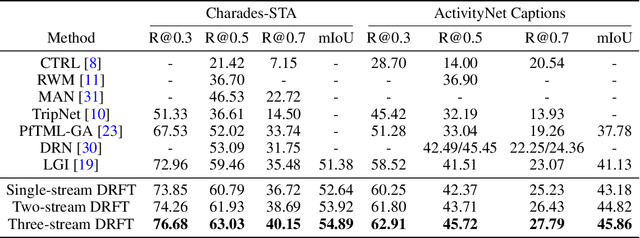
We address the problem of text-guided video temporal grounding, which aims to identify the time interval of certain event based on a natural language description. Different from most existing methods that only consider RGB images as visual features, we propose a multi-modal framework to extract complementary information from videos. Specifically, we adopt RGB images for appearance, optical flow for motion, and depth maps for image structure. While RGB images provide abundant visual cues of certain event, the performance may be affected by background clutters. Therefore, we use optical flow to focus on large motion and depth maps to infer the scene configuration when the action is related to objects recognizable with their shapes. To integrate the three modalities more effectively and enable inter-modal learning, we design a dynamic fusion scheme with transformers to model the interactions between modalities. Furthermore, we apply intra-modal self-supervised learning to enhance feature representations across videos for each modality, which also facilitates multi-modal learning. We conduct extensive experiments on the Charades-STA and ActivityNet Captions datasets, and show that the proposed method performs favorably against state-of-the-art approaches.
Relightable Neural Video Portrait
Jul 30, 2021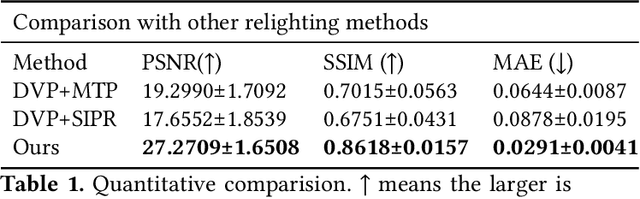
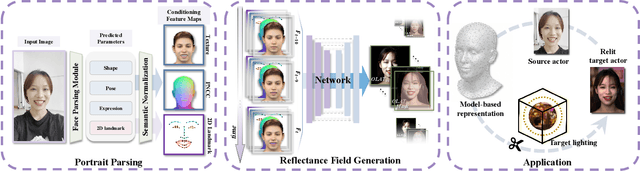

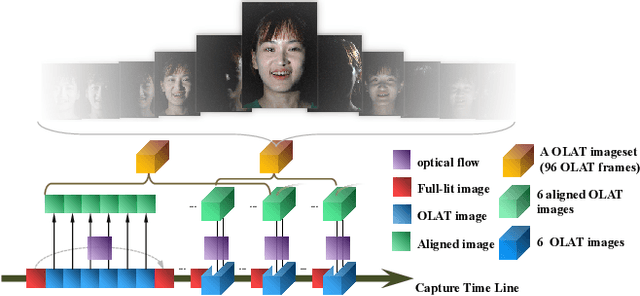
Photo-realistic facial video portrait reenactment benefits virtual production and numerous VR/AR experiences. The task remains challenging as the portrait should maintain high realism and consistency with the target environment. In this paper, we present a relightable neural video portrait, a simultaneous relighting and reenactment scheme that transfers the head pose and facial expressions from a source actor to a portrait video of a target actor with arbitrary new backgrounds and lighting conditions. Our approach combines 4D reflectance field learning, model-based facial performance capture and target-aware neural rendering. Specifically, we adopt a rendering-to-video translation network to first synthesize high-quality OLAT imagesets and alpha mattes from hybrid facial performance capture results. We then design a semantic-aware facial normalization scheme to enable reliable explicit control as well as a multi-frame multi-task learning strategy to encode content, segmentation and temporal information simultaneously for high-quality reflectance field inference. After training, our approach further enables photo-realistic and controllable video portrait editing of the target performer. Reliable face poses and expression editing is obtained by applying the same hybrid facial capture and normalization scheme to the source video input, while our explicit alpha and OLAT output enable high-quality relit and background editing. With the ability to achieve simultaneous relighting and reenactment, we are able to improve the realism in a variety of virtual production and video rewrite applications.
Hybrid approach to detecting symptoms of depression in social media entries
Jun 19, 2021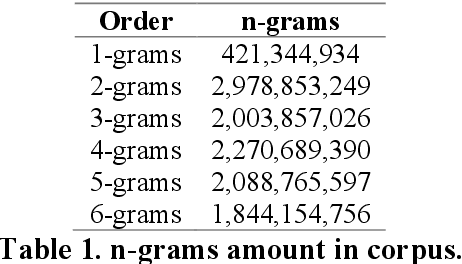

Sentiment and lexical analyses are widely used to detect depression or anxiety disorders. It has been documented that there are significant differences in the language used by a person with emotional disorders in comparison to a healthy individual. Still, the effectiveness of these lexical approaches could be improved further because the current analysis focuses on what the social media entries are about, and not how they are written. In this study, we focus on aspects in which these short texts are similar to each other, and how they were created. We present an innovative approach to the depression screening problem by applying Collgram analysis, which is a known effective method of obtaining linguistic information from texts. We compare these results with sentiment analysis based on the BERT architecture. Finally, we create a hybrid model achieving a diagnostic accuracy of 71%.
REST: Relational Event-driven Stock Trend Forecasting
Feb 15, 2021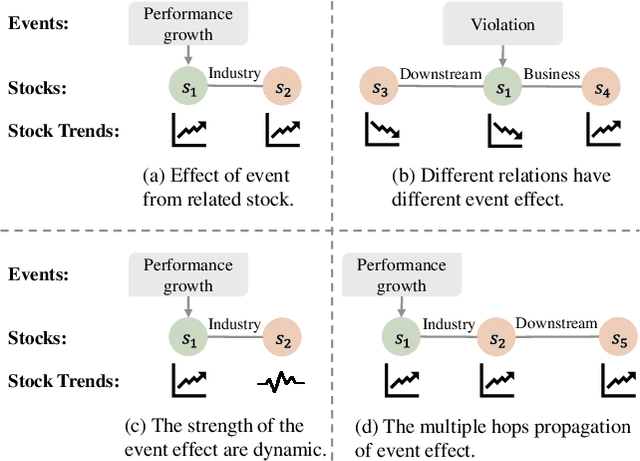

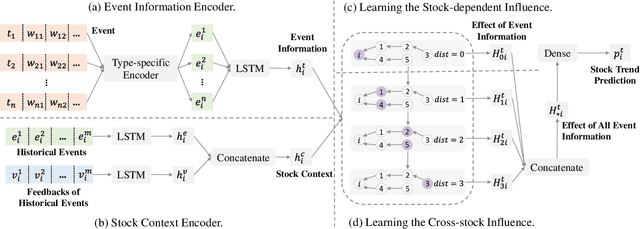
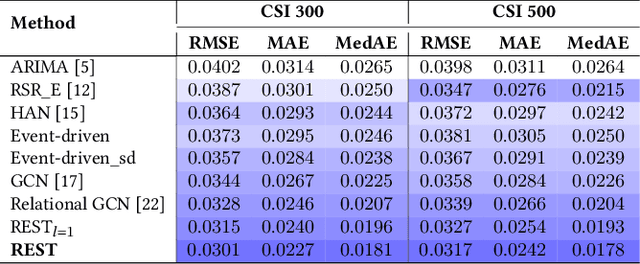
Stock trend forecasting, aiming at predicting the stock future trends, is crucial for investors to seek maximized profits from the stock market. Many event-driven methods utilized the events extracted from news, social media, and discussion board to forecast the stock trend in recent years. However, existing event-driven methods have two main shortcomings: 1) overlooking the influence of event information differentiated by the stock-dependent properties; 2) neglecting the effect of event information from other related stocks. In this paper, we propose a relational event-driven stock trend forecasting (REST) framework, which can address the shortcoming of existing methods. To remedy the first shortcoming, we propose to model the stock context and learn the effect of event information on the stocks under different contexts. To address the second shortcoming, we construct a stock graph and design a new propagation layer to propagate the effect of event information from related stocks. The experimental studies on the real-world data demonstrate the efficiency of our REST framework. The results of investment simulation show that our framework can achieve a higher return of investment than baselines.
SemSegMap- 3D Segment-Based Semantic Localization
Jul 30, 2021
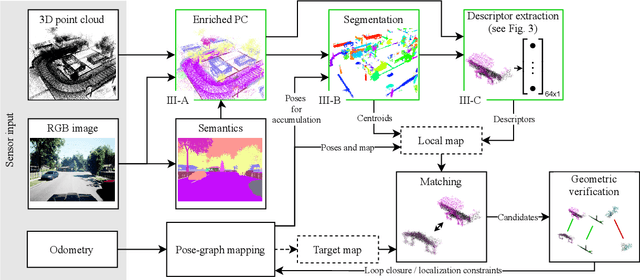
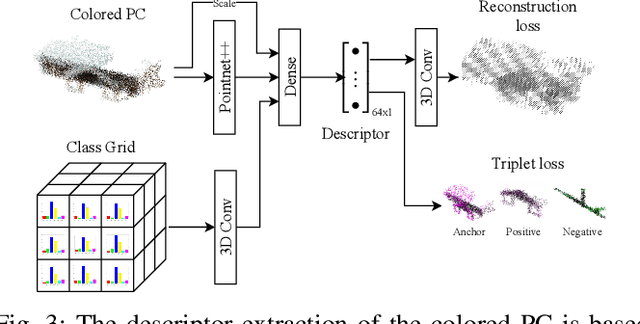
Localization is an essential task for mobile autonomous robotic systems that want to use pre-existing maps or create new ones in the context of SLAM. Today, many robotic platforms are equipped with high-accuracy 3D LiDAR sensors, which allow a geometric mapping, and cameras able to provide semantic cues of the environment. Segment-based mapping and localization have been applied with great success to 3D point-cloud data, while semantic understanding has been shown to improve localization performance in vision based systems. In this paper we combine both modalities in SemSegMap, extending SegMap into a segment based mapping framework able to also leverage color and semantic data from the environment to improve localization accuracy and robustness. In particular, we present new segmentation and descriptor extraction processes. The segmentation process benefits from additional distance information from color and semantic class consistency resulting in more repeatable segments and more overlap after re-visiting a place. For the descriptor, a tight fusion approach in a deep-learned descriptor extraction network is performed leading to a higher descriptiveness for landmark matching. We demonstrate the advantages of this fusion on multiple simulated and real-world datasets and compare its performance to various baselines. We show that we are able to find 50.9% more high-accuracy prior-less global localizations compared to SegMap on challenging datasets using very compact maps while also providing accurate full 6 DoF pose estimates in real-time.
Learnable Fourier Features for Multi-Dimensional Spatial Positional Encoding
Jun 23, 2021
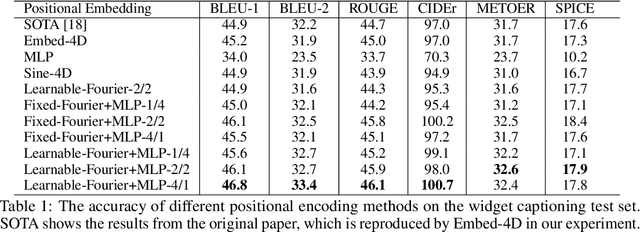
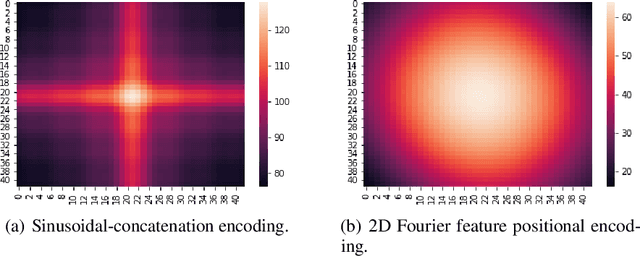

Attentional mechanisms are order-invariant. Positional encoding is a crucial component to allow attention-based deep model architectures such as Transformer to address sequences or images where the position of information matters. In this paper, we propose a novel positional encoding method based on learnable Fourier features. Instead of hard-coding each position as a token or a vector, we represent each position, which can be multi-dimensional, as a trainable encoding based on learnable Fourier feature mapping, modulated with a multi-layer perceptron. The representation is particularly advantageous for a spatial multi-dimensional position, e.g., pixel positions on an image, where $L_2$ distances or more complex positional relationships need to be captured. Our experiments based on several public benchmark tasks show that our learnable Fourier feature representation for multi-dimensional positional encoding outperforms existing methods by both improving the accuracy and allowing faster convergence.
A Multi-Lead Fusion Method for the Accurate Delineation of QRS Complex Location in 12 Lead ECG Signal
Jul 12, 2021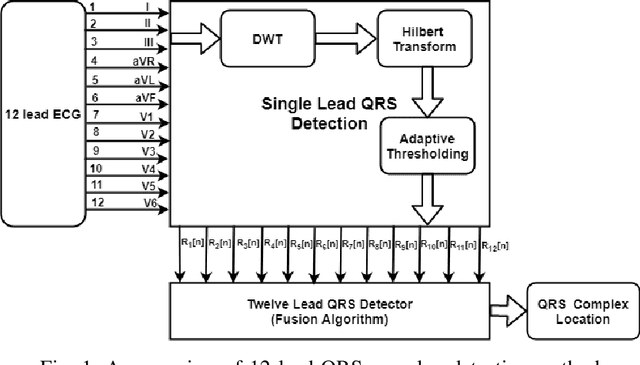
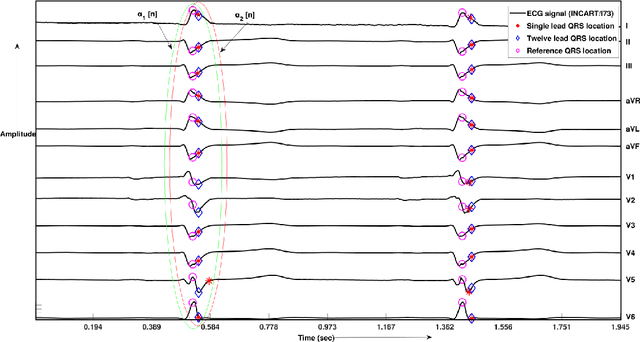
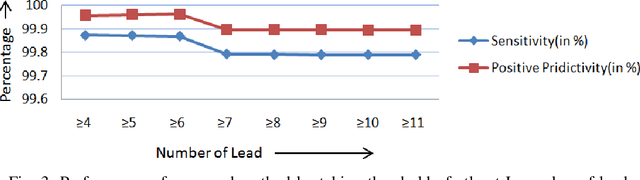
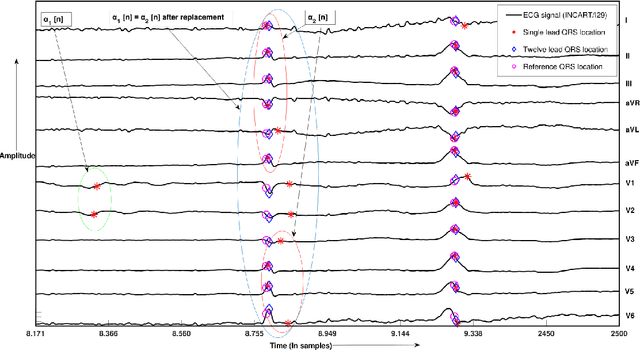
This paper presents a multi-lead fusion method for the accurate and automated detection of the QRS complex location in 12 lead ECG (Electrocardiogram) signals. The proposed multi-lead fusion method accurately delineates the QRS complex by the fusion of detected QRS complexes of the individual 12 leads. The proposed algorithm consists of two major stages. Firstly, the QRS complex location of each lead is detected by the single lead QRS detection algorithm. Secondly, the multi-lead fusion algorithm combines the information of the QRS complex locations obtained in each of the 12 leads. The performance of the proposed algorithm is improved in terms of Sensitivity and Positive Predictivity by discarding the false positives. The proposed method is validated on the ECG signals with various artifacts, inter and intra subject variations. The performance of the proposed method is validated on the long duration recorded ECG signals of St. Petersburg INCART database with Sensitivity of 99.87% and Positive Predictivity of 99.96% and on the short duration recorded ECG signals of CSE (Common Standards for Electrocardiography) multi-lead database with 100% Sensitivity and 99.13% Positive Predictivity.
Speech Synthesis from Text and Ultrasound Tongue Image-based Articulatory Input
Jul 05, 2021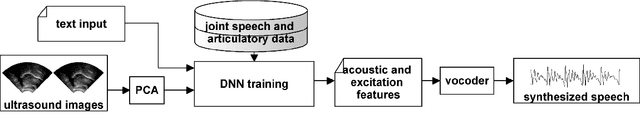
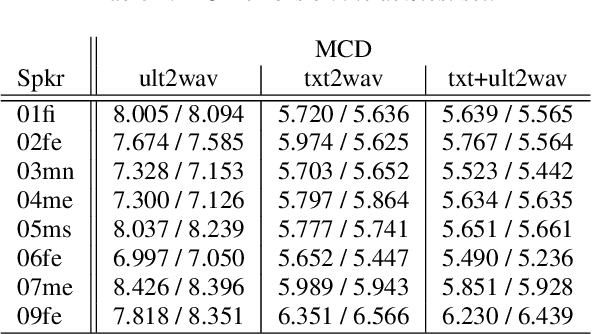
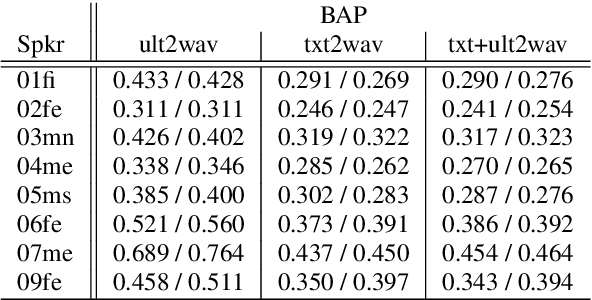
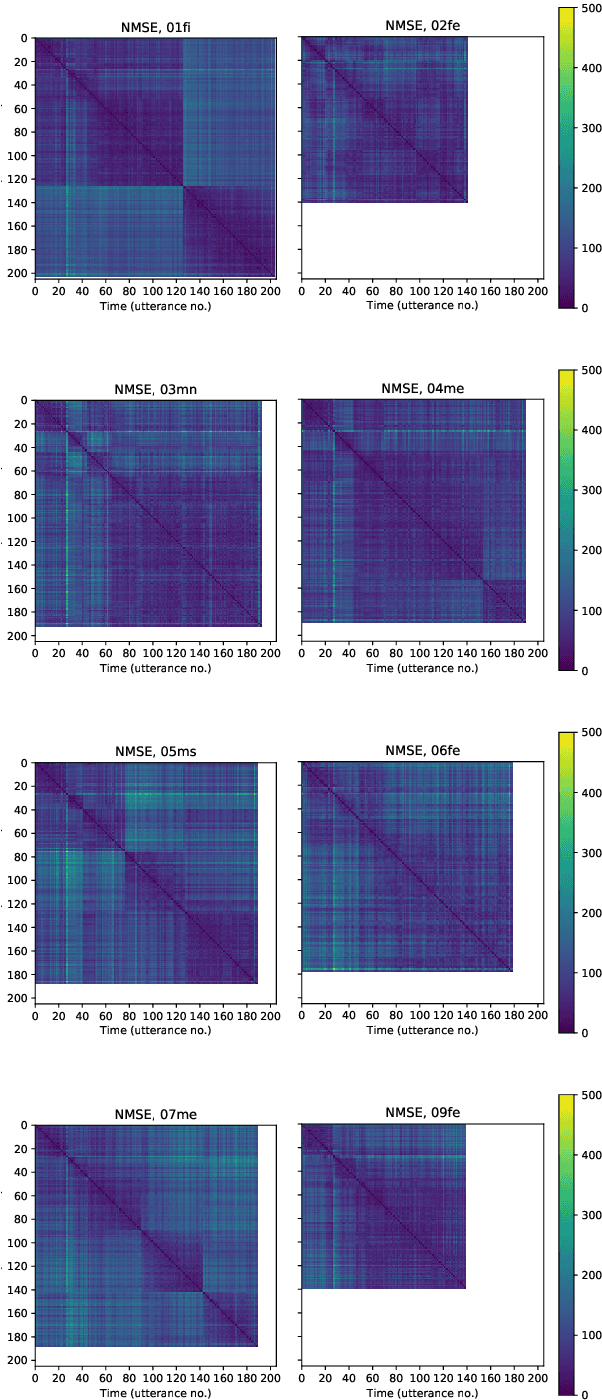
Articulatory information has been shown to be effective in improving the performance of HMM-based and DNN-based text-to-speech synthesis. Speech synthesis research focuses traditionally on text-to-speech conversion, when the input is text or an estimated linguistic representation, and the target is synthesized speech. However, a research field that has risen in the last decade is articulation-to-speech synthesis (with a target application of a Silent Speech Interface, SSI), when the goal is to synthesize speech from some representation of the movement of the articulatory organs. In this paper, we extend traditional (vocoder-based) DNN-TTS with articulatory input, estimated from ultrasound tongue images. We compare text-only, ultrasound-only, and combined inputs. Using data from eight speakers, we show that that the combined text and articulatory input can have advantages in limited-data scenarios, namely, it may increase the naturalness of synthesized speech compared to single text input. Besides, we analyze the ultrasound tongue recordings of several speakers, and show that misalignments in the ultrasound transducer positioning can have a negative effect on the final synthesis performance.