 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Axiomatic Explanations for Neural Ranking Models
Jul 11, 2021
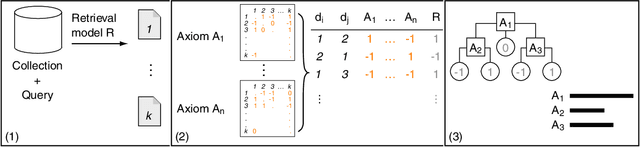
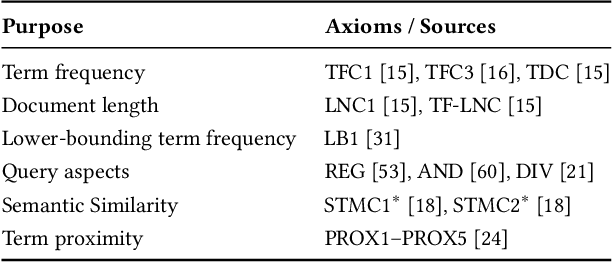
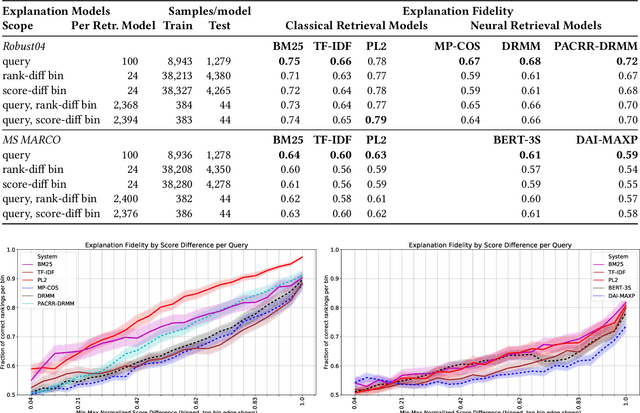
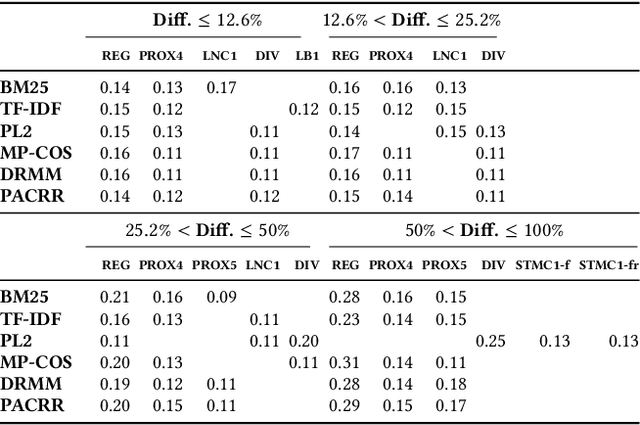
Recently, neural networks have been successfully employed to improve upon state-of-the-art performance in ad-hoc retrieval tasks via machine-learned ranking functions. While neural retrieval models grow in complexity and impact, little is understood about their correspondence with well-studied IR principles. Recent work on interpretability in machine learning has provided tools and techniques to understand neural models in general, yet there has been little progress towards explaining ranking models. We investigate whether one can explain the behavior of neural ranking models in terms of their congruence with well understood principles of document ranking by using established theories from axiomatic IR. Axiomatic analysis of information retrieval models has formalized a set of constraints on ranking decisions that reasonable retrieval models should fulfill. We operationalize this axiomatic thinking to reproduce rankings based on combinations of elementary constraints. This allows us to investigate to what extent the ranking decisions of neural rankers can be explained in terms of retrieval axioms, and which axioms apply in which situations. Our experimental study considers a comprehensive set of axioms over several representative neural rankers. While the existing axioms can already explain the particularly confident ranking decisions rather well, future work should extend the axiom set to also cover the other still "unexplainable" neural IR rank decisions.
Multilingual and crosslingual speech recognition using phonological-vector based phone embeddings
Jul 11, 2021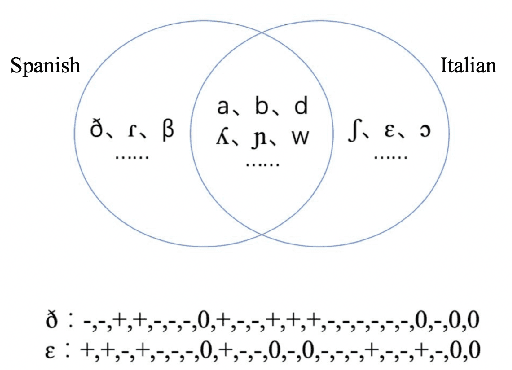
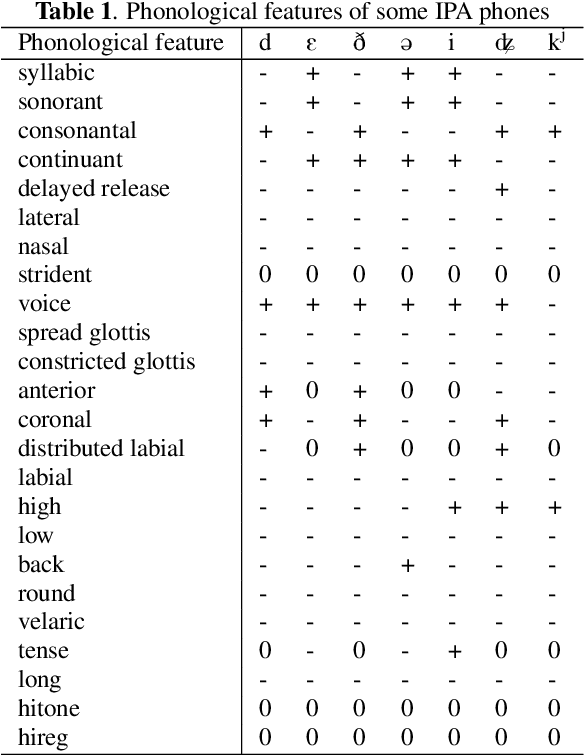
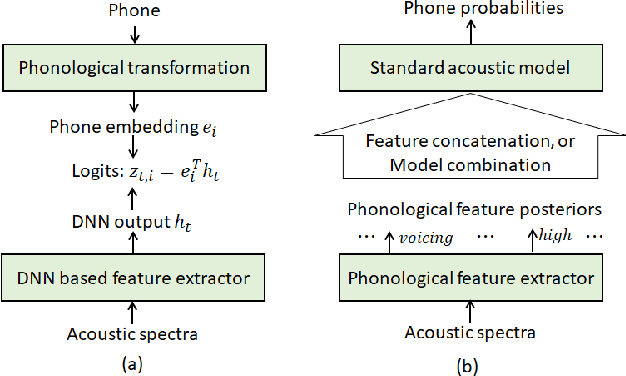
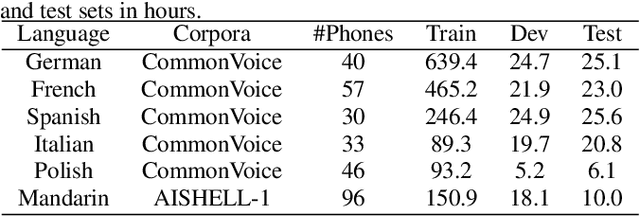
The use of phonological features (PFs) potentially allows language-specific phones to remain linked in training, which is highly desirable for information sharing for multilingual and crosslingual speech recognition methods for low-resourced languages. A drawback suffered by previous methods in using phonological features is that the acoustic-to-PF extraction in a bottom-up way is itself difficult. In this paper, we propose to join phonology driven phone embedding (top-down) and deep neural network (DNN) based acoustic feature extraction (bottom-up) to calculate phone probabilities. The new method is called JoinAP (Joining of Acoustics and Phonology). Remarkably, no inversion from acoustics to phonological features is required for speech recognition. For each phone in the IPA (International Phonetic Alphabet) table, we encode its phonological features to a phonological-vector, and then apply linear or nonlinear transformation of the phonological-vector to obtain the phone embedding. A series of multilingual and crosslingual (both zero-shot and few-shot) speech recognition experiments are conducted on the CommonVoice dataset (German, French, Spanish and Italian) and the AISHLL-1 dataset (Mandarin), and demonstrate the superiority of JoinAP with nonlinear phone embeddings over both JoinAP with linear phone embeddings and the traditional method with flat phone embeddings.
Polarized hyperspectral imaging with single fiber bundle via incoherent light transmission matrix approach
Jan 11, 2021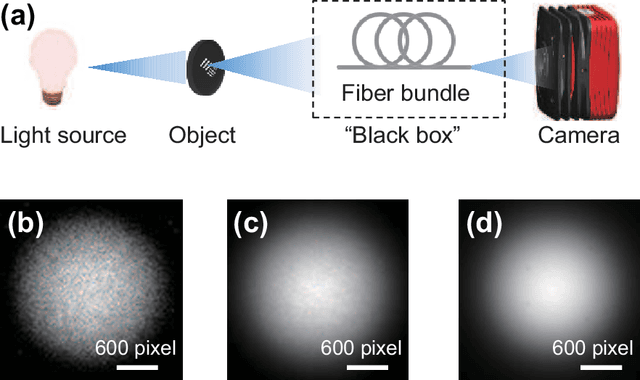
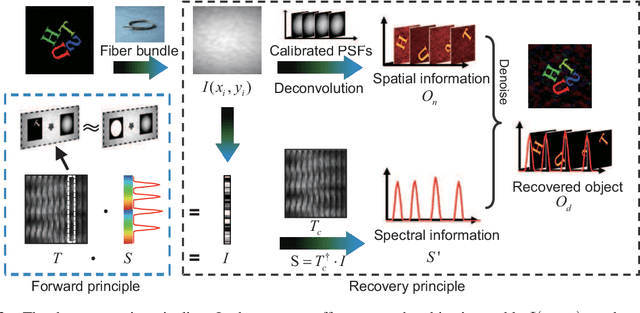
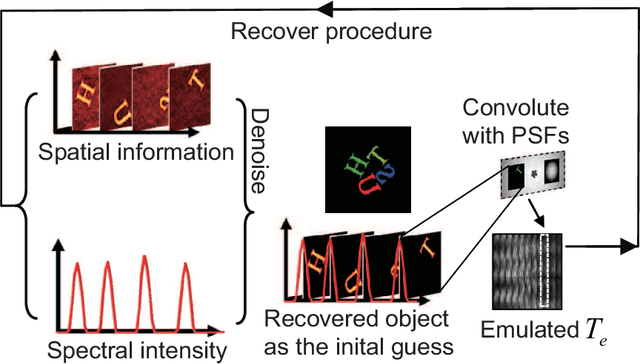
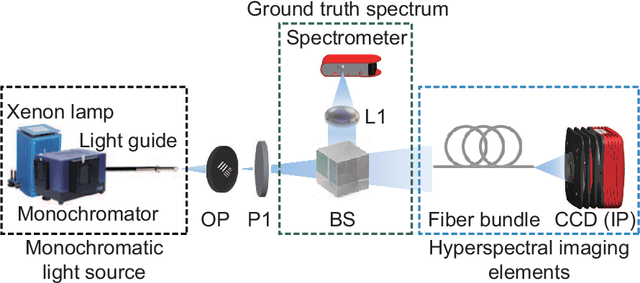
The scattering of multispectral incoherent light is a common and unfavorable signal scrambling in natural scenes. However, the blurred light spot due to scattering still holds lots of information remaining to be explored. Former methods failed to recover the polarized hyperspectral information from scattered incoherent light or relied on additional dispersion elements. Here we put forward the transmission matrix (TM) approach for extended objects under incoherent illumination by speculating the unknown TM through experimentally calibrated or digitally emulated ways. Employing a fiber bundle as a powerful imaging and dispersion element, we recover the spatial information in 252 polarized-spectral channels from a single speckle, thus achieving single-shot, high-resolution, broadband hyperspectral imaging for two polarization states with the cheap, compact, fiber-bundle-only system. Based on the scattering principle itself, our method not only greatly improves the robustness of the TM approach to retrieve the input spectral information, but also reveals the feasibility to explore the polarized spatio-spectral information from blurry speckles only with the help of simple optical setups.
Individual risk profiling for portable devices using a neural network to process the recording of 30 successive pairs of cognitive reaction and emotional response to a multivariate situational risk assessment
Feb 28, 2021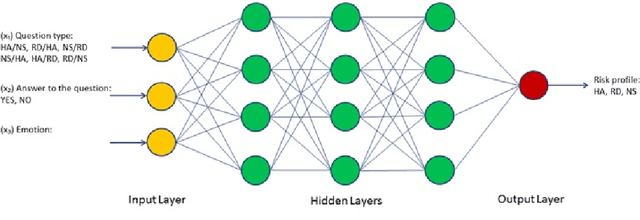
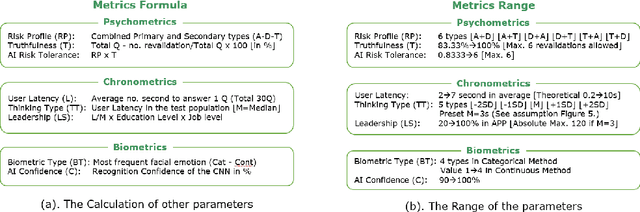
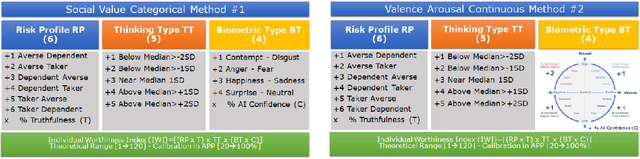
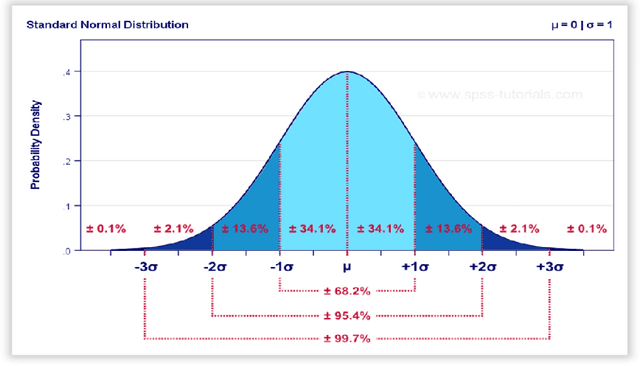
In this paper, we are presenting a novel method and system for neuropsychological performance testing that can establish a link between cognition and emotion. It comprises a portable device used to interact with a cloud service which stores user information under username and is logged into by user through the portable device; the user information is directly captured through the device and is processed by artificial neural network; and the tridimensional user information comprises user cognitive reactions, user emotional responses and user chronometrics. The multivariate situational risk assessment is used to evaluate the performance of the subject by capturing the 3 dimensions of each reaction to a series of 30 dichotomous questions describing various situations of daily life and challenging the user's knowledge, values, ethics, and principles. In industrial application, the timing of this assessment will depend on the user's need to obtain a service from a provider such as opening a bank account, getting a mortgage or an insurance policy, authenticating clearance at work or securing online payments.
Exploring Discourse Structures for Argument Impact Classification
Jun 02, 2021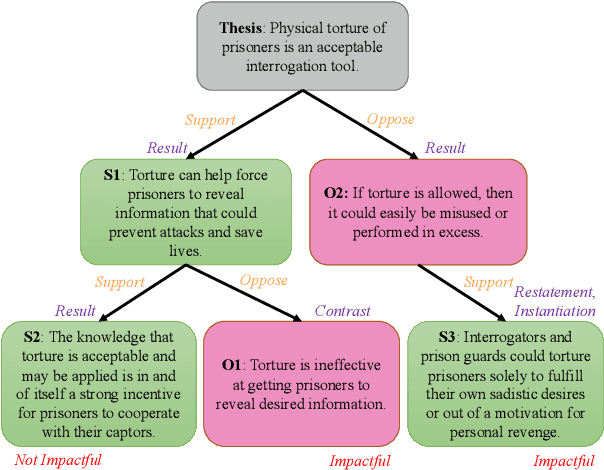
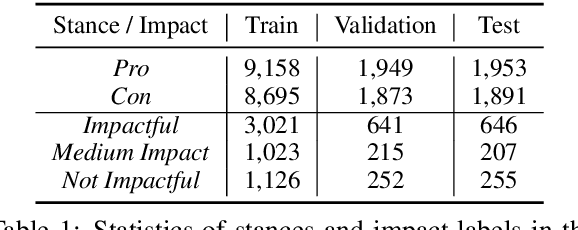

Discourse relations among arguments reveal logical structures of a debate conversation. However, no prior work has explicitly studied how the sequence of discourse relations influence a claim's impact. This paper empirically shows that the discourse relations between two arguments along the context path are essential factors for identifying the persuasive power of an argument. We further propose DisCOC to inject and fuse the sentence-level structural discourse information with contextualized features derived from large-scale language models. Experimental results and extensive analysis show that the attention and gate mechanisms that explicitly model contexts and texts can indeed help the argument impact classification task defined by Durmus et al. (2019), and discourse structures among the context path of the claim to be classified can further boost the performance.
Efficient Spatialtemporal Context Modeling for Action Recognition
Mar 20, 2021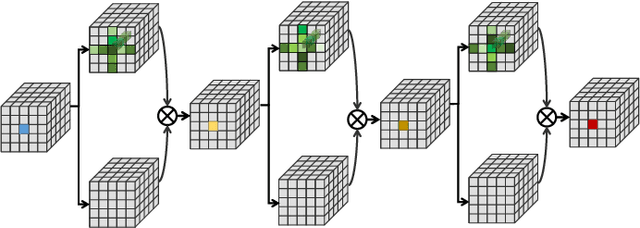
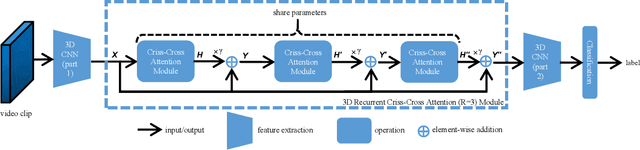
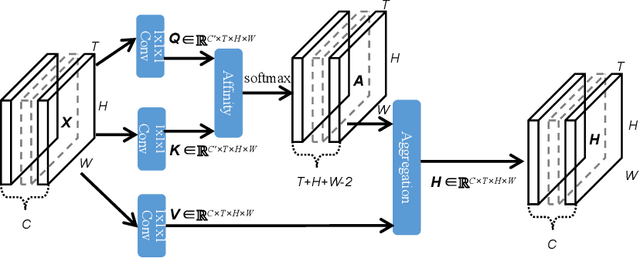
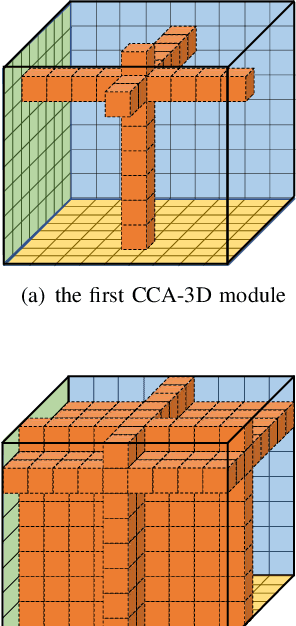
Contextual information plays an important role in action recognition. Local operations have difficulty to model the relation between two elements with a long-distance interval. However, directly modeling the contextual information between any two points brings huge cost in computation and memory, especially for action recognition, where there is an additional temporal dimension. Inspired from 2D criss-cross attention used in segmentation task, we propose a recurrent 3D criss-cross attention (RCCA-3D) module to model the dense long-range spatiotemporal contextual information in video for action recognition. The global context is factorized into sparse relation maps. We model the relationship between points in the same line along the direction of horizon, vertical and depth at each time, which forms a 3D criss-cross structure, and duplicate the same operation with recurrent mechanism to transmit the relation between points in a line to a plane finally to the whole spatiotemporal space. Compared with the non-local method, the proposed RCCA-3D module reduces the number of parameters and FLOPs by 25% and 11% for video context modeling. We evaluate the performance of RCCA-3D with two latest action recognition networks on three datasets and make a thorough analysis of the architecture, obtaining the best way to factorize and fuse the relation maps. Comparisons with other state-of-the-art methods demonstrate the effectiveness and efficiency of our model.
Rethinking BiSeNet For Real-time Semantic Segmentation
Apr 27, 2021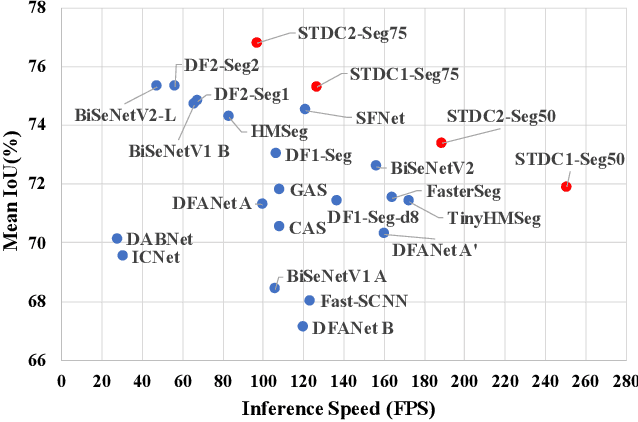
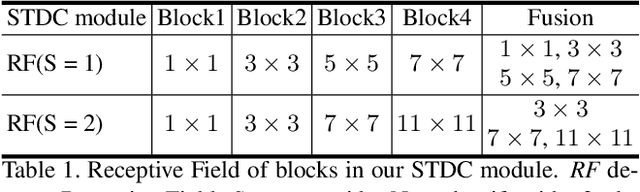
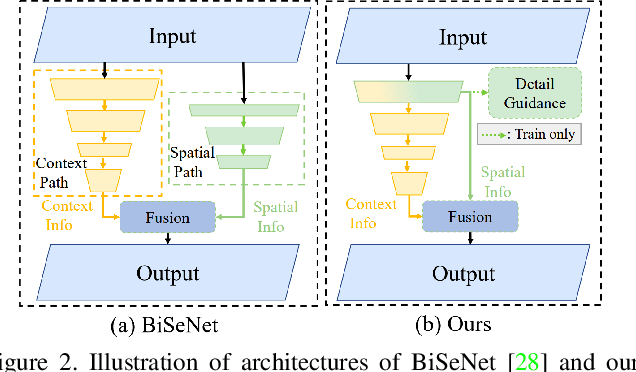
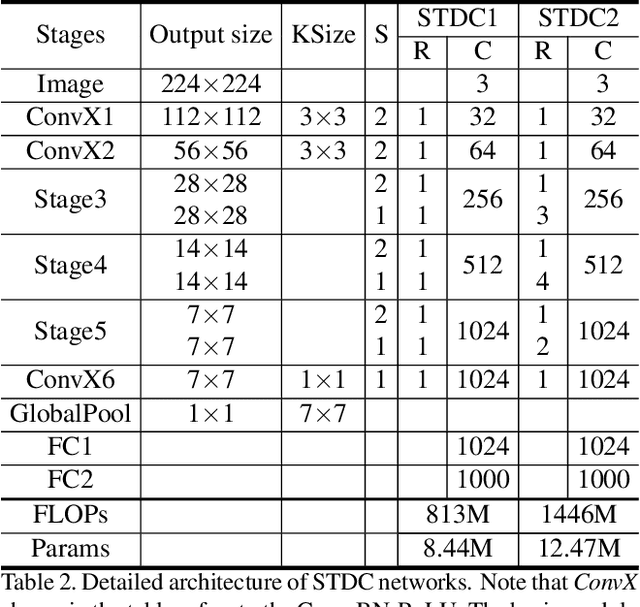
BiSeNet has been proved to be a popular two-stream network for real-time segmentation. However, its principle of adding an extra path to encode spatial information is time-consuming, and the backbones borrowed from pretrained tasks, e.g., image classification, may be inefficient for image segmentation due to the deficiency of task-specific design. To handle these problems, we propose a novel and efficient structure named Short-Term Dense Concatenate network (STDC network) by removing structure redundancy. Specifically, we gradually reduce the dimension of feature maps and use the aggregation of them for image representation, which forms the basic module of STDC network. In the decoder, we propose a Detail Aggregation module by integrating the learning of spatial information into low-level layers in single-stream manner. Finally, the low-level features and deep features are fused to predict the final segmentation results. Extensive experiments on Cityscapes and CamVid dataset demonstrate the effectiveness of our method by achieving promising trade-off between segmentation accuracy and inference speed. On Cityscapes, we achieve 71.9% mIoU on the test set with a speed of 250.4 FPS on NVIDIA GTX 1080Ti, which is 45.2% faster than the latest methods, and achieve 76.8% mIoU with 97.0 FPS while inferring on higher resolution images.
AWCD: An Efficient Point Cloud Processing Approach via Wasserstein Curvature
May 11, 2021


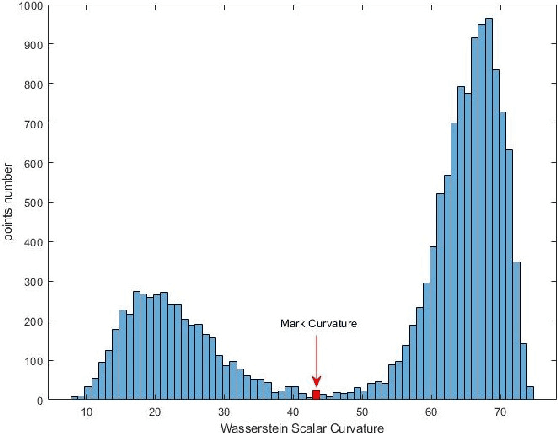
In this paper, we introduce the adaptive Wasserstein curvature denoising (AWCD), an original processing approach for point cloud data. By collecting curvatures information from Wasserstein distance, AWCD consider more precise structures of data and preserves stability and effectiveness even for data with noise in high density. This paper contains some theoretical analysis about the Wasserstein curvature and the complete algorithm of AWCD. In addition, we design digital experiments to show the denoising effect of AWCD. According to comparison results, we present the advantages of AWCD against traditional algorithms.
On the instability of embeddings for recommender systems: the case of Matrix Factorization
Apr 12, 2021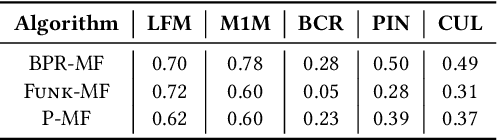
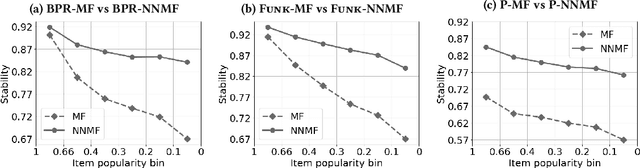
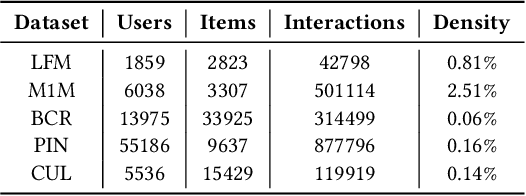
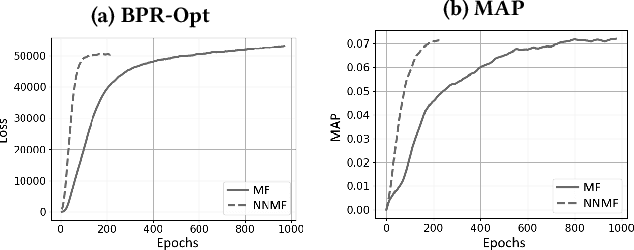
Most state-of-the-art top-N collaborative recommender systems work by learning embeddings to jointly represent users and items. Learned embeddings are considered to be effective to solve a variety of tasks. Among others, providing and explaining recommendations. In this paper we question the reliability of the embeddings learned by Matrix Factorization (MF). We empirically demonstrate that, by simply changing the initial values assigned to the latent factors, the same MF method generates very different embeddings of items and users, and we highlight that this effect is stronger for less popular items. To overcome these drawbacks, we present a generalization of MF, called Nearest Neighbors Matrix Factorization (NNMF). The new method propagates the information about items and users to their neighbors, speeding up the training procedure and extending the amount of information that supports recommendations and representations. We describe the NNMF variants of three common MF approaches, and with extensive experiments on five different datasets we show that they strongly mitigate the instability issues of the original MF versions and they improve the accuracy of recommendations on the long-tail.
Multi Point-Voxel Convolution (MPVConv) for Deep Learning on Point Clouds
Jul 28, 2021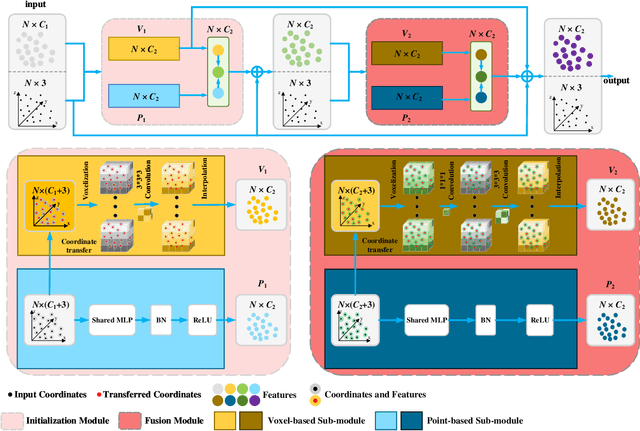



The existing 3D deep learning methods adopt either individual point-based features or local-neighboring voxel-based features, and demonstrate great potential for processing 3D data. However, the point based models are inefficient due to the unordered nature of point clouds and the voxel-based models suffer from large information loss. Motivated by the success of recent point-voxel representation, such as PVCNN, we propose a new convolutional neural network, called Multi Point-Voxel Convolution (MPVConv), for deep learning on point clouds. Integrating both the advantages of voxel and point-based methods, MPVConv can effectively increase the neighboring collection between point-based features and also promote independence among voxel-based features. Moreover, most of the existing approaches aim at solving one specific task, and only a few of them can handle a variety of tasks. Simply replacing the corresponding convolution module with MPVConv, we show that MPVConv can fit in different backbones to solve a wide range of 3D tasks. Extensive experiments on benchmark datasets such as ShapeNet Part, S3DIS and KITTI for various tasks show that MPVConv improves the accuracy of the backbone (PointNet) by up to \textbf{36\%}, and achieves higher accuracy than the voxel-based model with up to \textbf{34}$\times$ speedups. In addition, MPVConv outperforms the state-of-the-art point-based models with up to \textbf{8}$\times$ speedups. Notably, our MPVConv achieves better accuracy than the newest point-voxel-based model PVCNN (a model more efficient than PointNet) with lower latency.