 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Triplot: model agnostic measures and visualisations for variable importance in predictive models that take into account the hierarchical correlation structure
Apr 07, 2021
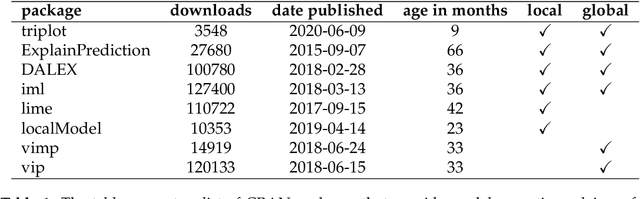
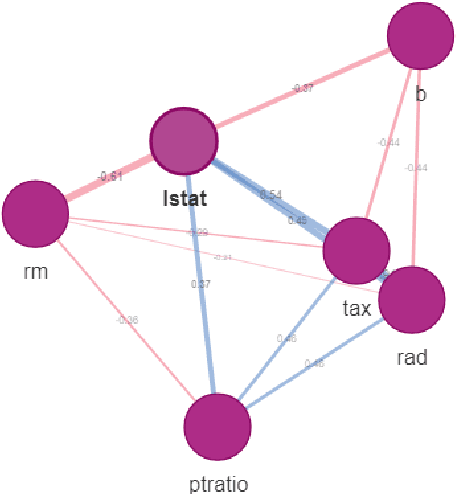
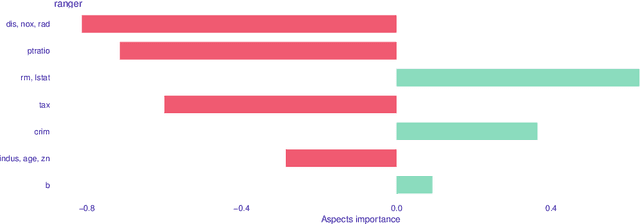
One of the key elements of explanatory analysis of a predictive model is to assess the importance of individual variables. Rapid development of the area of predictive model exploration (also called explainable artificial intelligence or interpretable machine learning) has led to the popularization of methods for local (instance level) and global (dataset level) methods, such as Permutational Variable Importance, Shapley Values (SHAP), Local Interpretable Model Explanations (LIME), Break Down and so on. However, these methods do not use information about the correlation between features which significantly reduce the explainability of the model behaviour. In this work, we propose new methods to support model analysis by exploiting the information about the correlation between variables. The dataset level aspect importance measure is inspired by the block permutations procedure, while the instance level aspect importance measure is inspired by the LIME method. We show how to analyze groups of variables (aspects) both when they are proposed by the user and when they should be determined automatically based on the hierarchical structure of correlations between variables. Additionally, we present the new type of model visualisation, triplot, which exploits a hierarchical structure of variable grouping to produce a high information density model visualisation. This visualisation provides a consistent illustration for either local or global model and data exploration. We also show an example of real-world data with 5k instances and 37 features in which a significant correlation between variables affects the interpretation of the effect of variable importance. The proposed method is, to our knowledge, the first to allow direct use of the correlation between variables in exploratory model analysis.
Fast Crack Detection Using Convolutional Neural Network
May 23, 2021



To improve the efficiency and reduce the labour cost of the renovation process, this study presents a lightweight Convolutional Neural Network (CNN)-based architecture to extract crack-like features, such as cracks and joints. Moreover, Transfer Learning (TF) method was used to save training time while offering comparable prediction results. For three different objectives: 1) Detection of the concrete cracks; 2) Detection of natural stone cracks; 3) Differentiation between joints and cracks in natural stone; We built a natural stone dataset with joints and cracks information as complementary for the concrete benchmark dataset. As the results show, our model is demonstrated as an effective tool for industry use.
Discrete Auto-regressive Variational Attention Models for Text Modeling
Jun 16, 2021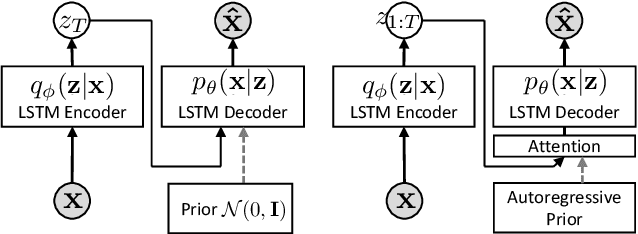
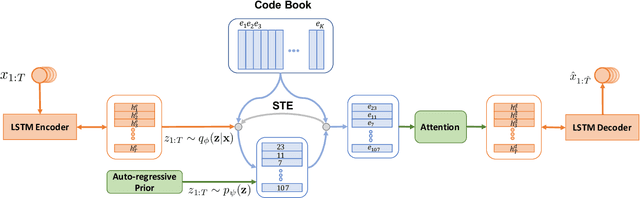
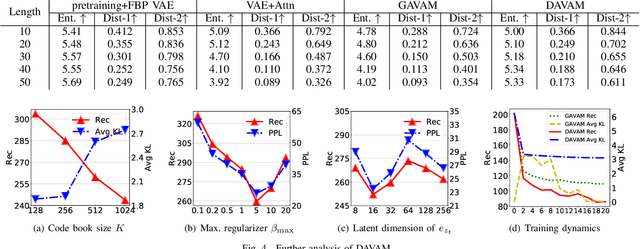
Variational autoencoders (VAEs) have been widely applied for text modeling. In practice, however, they are troubled by two challenges: information underrepresentation and posterior collapse. The former arises as only the last hidden state of LSTM encoder is transformed into the latent space, which is generally insufficient to summarize the data. The latter is a long-standing problem during the training of VAEs as the optimization is trapped to a disastrous local optimum. In this paper, we propose Discrete Auto-regressive Variational Attention Model (DAVAM) to address the challenges. Specifically, we introduce an auto-regressive variational attention approach to enrich the latent space by effectively capturing the semantic dependency from the input. We further design discrete latent space for the variational attention and mathematically show that our model is free from posterior collapse. Extensive experiments on language modeling tasks demonstrate the superiority of DAVAM against several VAE counterparts.
Hyperspectral Image Classification: Artifacts of Dimension Reduction on Hybrid CNN
Jan 25, 2021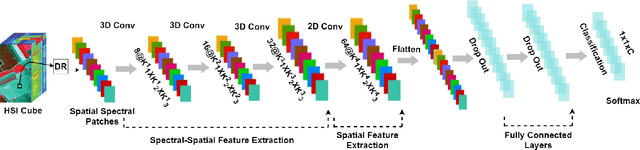
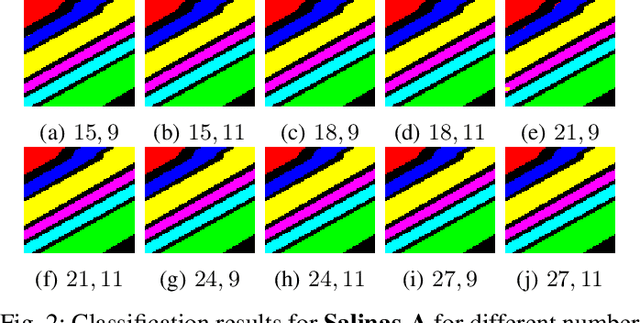
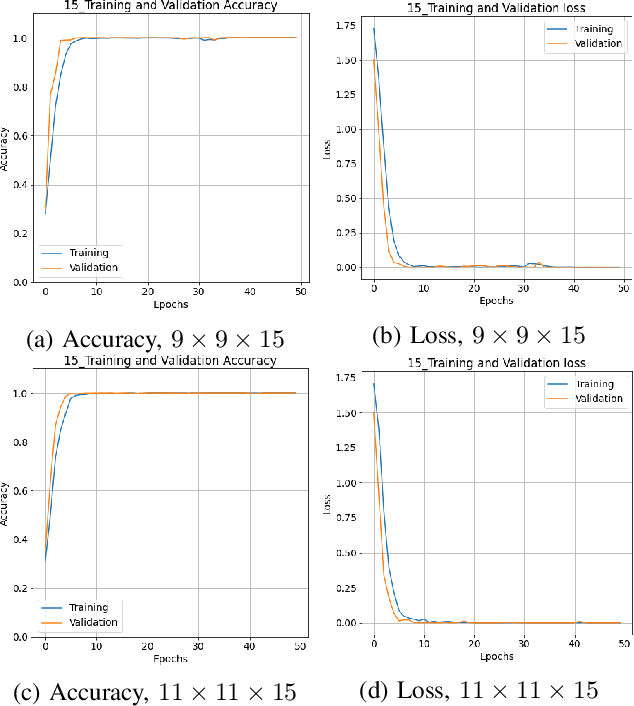
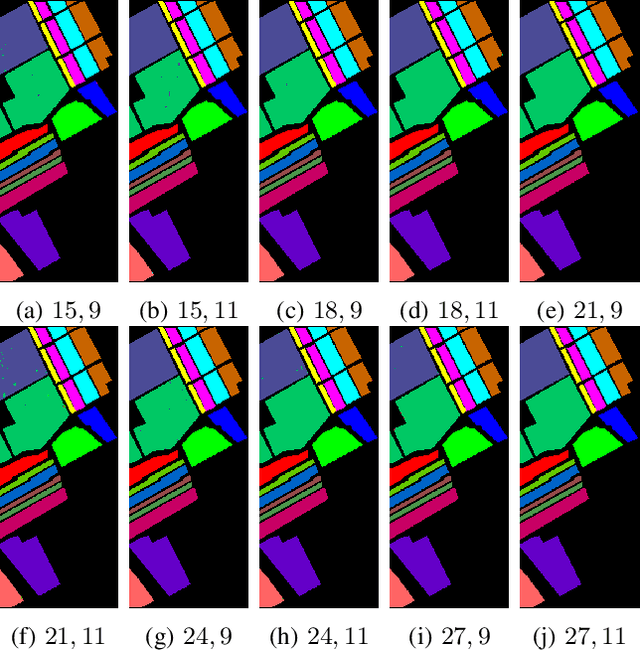
Convolutional Neural Networks (CNN) has been extensively studied for Hyperspectral Image Classification (HSIC) more specifically, 2D and 3D CNN models have proved highly efficient in exploiting the spatial and spectral information of Hyperspectral Images. However, 2D CNN only considers the spatial information and ignores the spectral information whereas 3D CNN jointly exploits spatial-spectral information at a high computational cost. Therefore, this work proposed a lightweight CNN (3D followed by 2D-CNN) model which significantly reduces the computational cost by distributing spatial-spectral feature extraction across a lighter model alongside a preprocessing that has been carried out to improve the classification results. Five benchmark Hyperspectral datasets (i.e., SalinasA, Salinas, Indian Pines, Pavia University, Pavia Center, and Botswana) are used for experimental evaluation. The experimental results show that the proposed pipeline outperformed in terms of generalization performance, statistical significance, and computational complexity, as compared to the state-of-the-art 2D/3D CNN models except commonly used computationally expensive design choices.
Learning Reasoning Paths over Semantic Graphs for Video-grounded Dialogues
Mar 01, 2021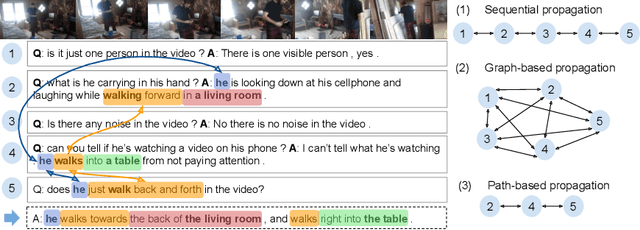
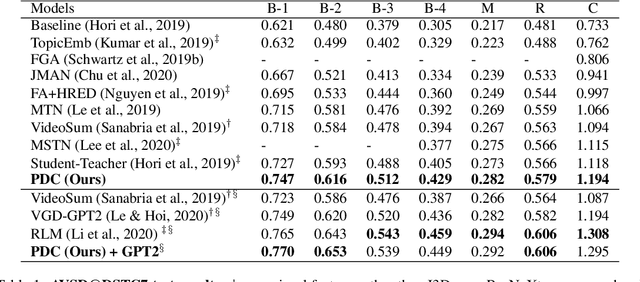
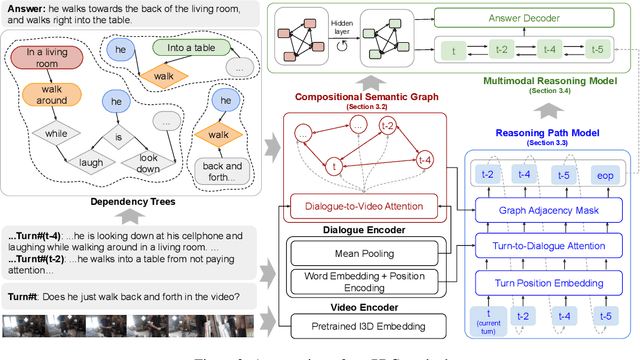

Compared to traditional visual question answering, video-grounded dialogues require additional reasoning over dialogue context to answer questions in a multi-turn setting. Previous approaches to video-grounded dialogues mostly use dialogue context as a simple text input without modelling the inherent information flows at the turn level. In this paper, we propose a novel framework of Reasoning Paths in Dialogue Context (PDC). PDC model discovers information flows among dialogue turns through a semantic graph constructed based on lexical components in each question and answer. PDC model then learns to predict reasoning paths over this semantic graph. Our path prediction model predicts a path from the current turn through past dialogue turns that contain additional visual cues to answer the current question. Our reasoning model sequentially processes both visual and textual information through this reasoning path and the propagated features are used to generate the answer. Our experimental results demonstrate the effectiveness of our method and provide additional insights on how models use semantic dependencies in a dialogue context to retrieve visual cues.
Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting
Jul 11, 2021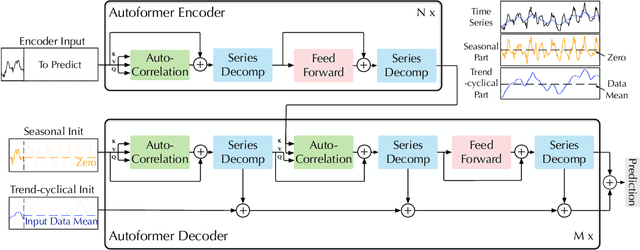
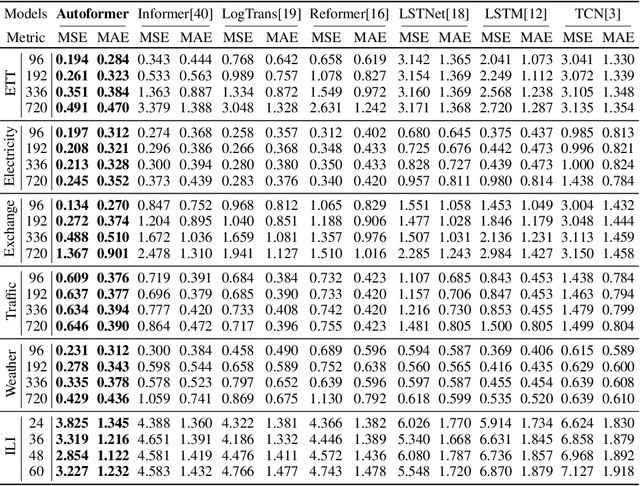
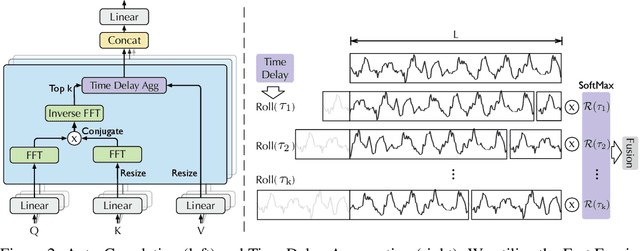
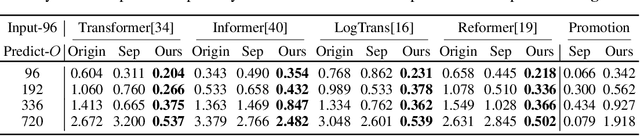
Extending the forecasting time is a critical demand for real applications, such as extreme weather early warning and long-term energy consumption planning. This paper studies the \textit{long-term forecasting} problem of time series. Prior Transformer-based models adopt various self-attention mechanisms to discover the long-range dependencies. However, intricate temporal patterns of the long-term future prohibit the model from finding reliable dependencies. Also, Transformers have to adopt the sparse versions of point-wise self-attentions for long series efficiency, resulting in the information utilization bottleneck. Towards these challenges, we propose Autoformer as a novel decomposition architecture with an Auto-Correlation mechanism. We go beyond the pre-processing convention of series decomposition and renovate it as a basic inner block of deep models. This design empowers Autoformer with progressive decomposition capacities for complex time series. Further, inspired by the stochastic process theory, we design the Auto-Correlation mechanism based on the series periodicity, which conducts the dependencies discovery and representation aggregation at the sub-series level. Auto-Correlation outperforms self-attention in both efficiency and accuracy. In long-term forecasting, Autoformer yields state-of-the-art accuracy, with a 38% relative improvement on six benchmarks, covering five practical applications: energy, traffic, economics, weather and disease.
Differential Privacy for Text Analytics via Natural Text Sanitization
Jun 02, 2021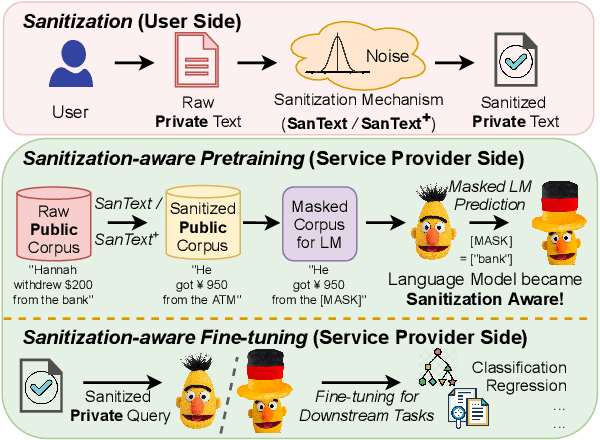
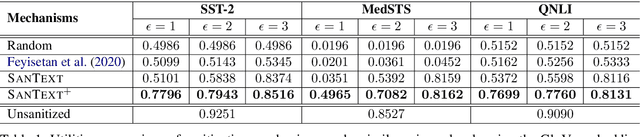
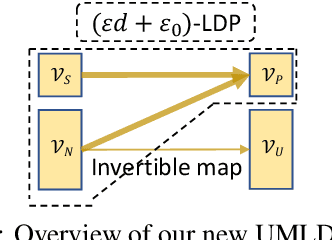
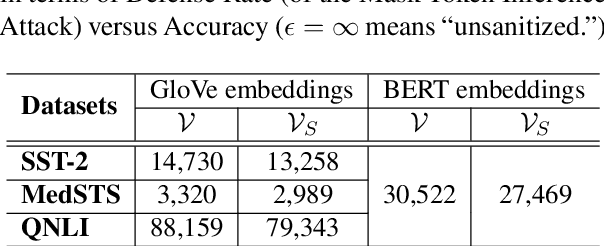
Texts convey sophisticated knowledge. However, texts also convey sensitive information. Despite the success of general-purpose language models and domain-specific mechanisms with differential privacy (DP), existing text sanitization mechanisms still provide low utility, as cursed by the high-dimensional text representation. The companion issue of utilizing sanitized texts for downstream analytics is also under-explored. This paper takes a direct approach to text sanitization. Our insight is to consider both sensitivity and similarity via our new local DP notion. The sanitized texts also contribute to our sanitization-aware pretraining and fine-tuning, enabling privacy-preserving natural language processing over the BERT language model with promising utility. Surprisingly, the high utility does not boost up the success rate of inference attacks.
Neural Networks for Information Retrieval
Jul 13, 2017
Machine learning plays a role in many aspects of modern IR systems, and deep learning is applied in all of them. The fast pace of modern-day research has given rise to many different approaches for many different IR problems. The amount of information available can be overwhelming both for junior students and for experienced researchers looking for new research topics and directions. Additionally, it is interesting to see what key insights into IR problems the new technologies are able to give us. The aim of this full-day tutorial is to give a clear overview of current tried-and-trusted neural methods in IR and how they benefit IR research. It covers key architectures, as well as the most promising future directions.
Refined method to extract frequency-noise components of lasers by delayed self-heterodyne
Jun 02, 2021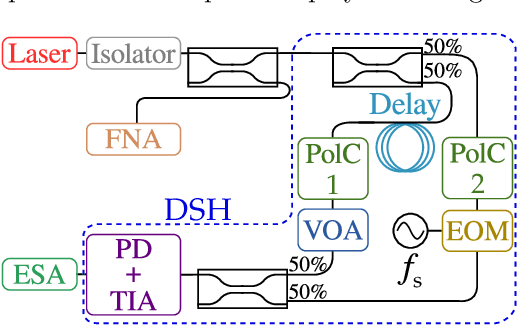
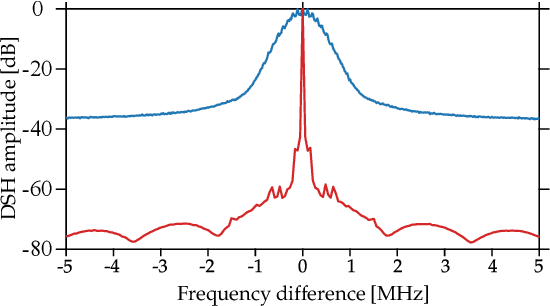
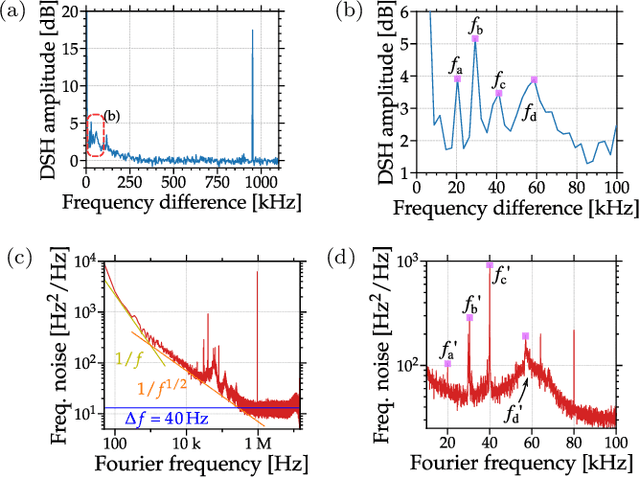
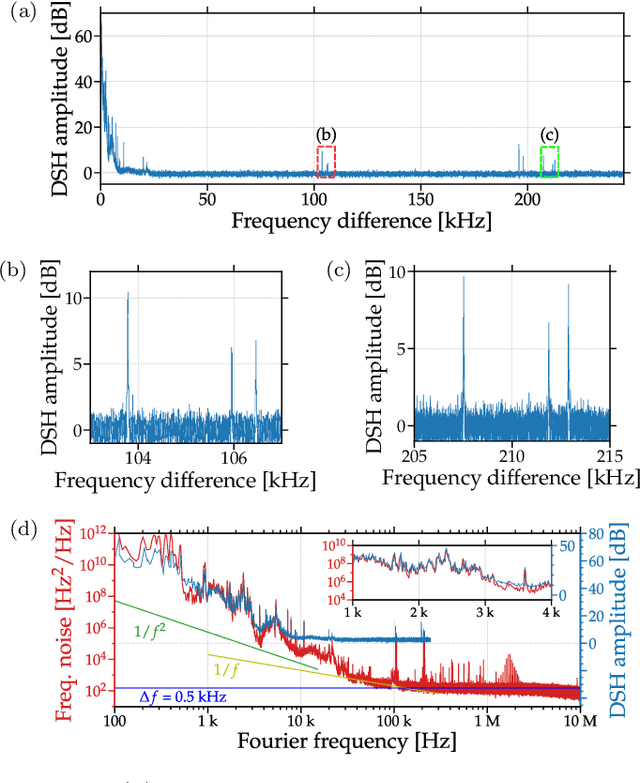
An essential metric to quantify the stability of a laser is its frequency noise (FN). This metric yields information on the linewidth and on noise components which limit its usage for high precision purposes such as coherent communication. Its experimental determination relies on challenging optical phase measurements, for which dedicated commercial instruments have been developed. In contrast, this work presents a simple and cost-effective method for extracting FN features employing a delayed self-heterodyne (DSH) setup. Using delay lengths much shorter than the coherence length of the laser, the DSH trace reveals a correspondence with the FN power spectral density (PSD) measured with commercial instruments. Results are found for multiple lasers, with discrepancies in intense dither tone frequencies below 0.2 percent
Towards Axiomatic Explanations for Neural Ranking Models
Jul 11, 2021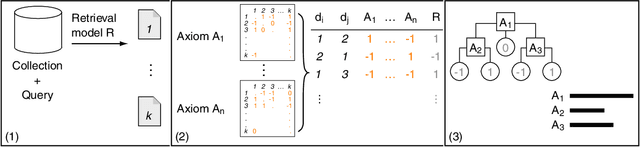
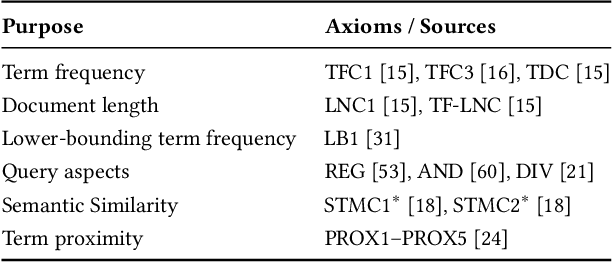
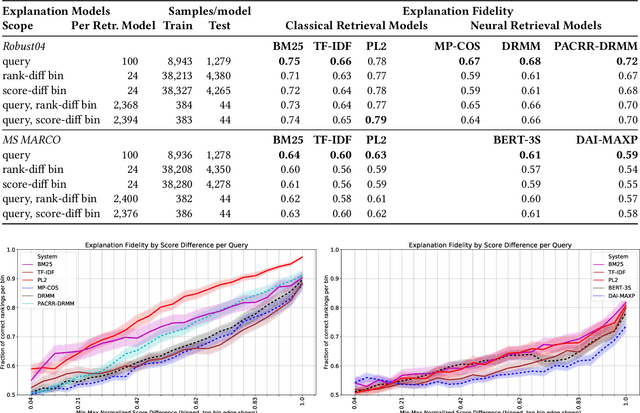
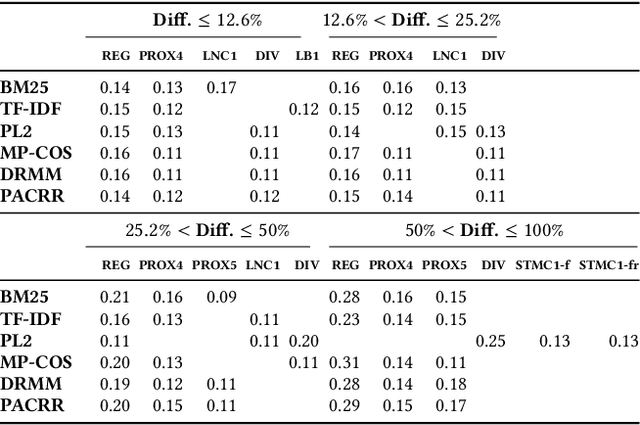
Recently, neural networks have been successfully employed to improve upon state-of-the-art performance in ad-hoc retrieval tasks via machine-learned ranking functions. While neural retrieval models grow in complexity and impact, little is understood about their correspondence with well-studied IR principles. Recent work on interpretability in machine learning has provided tools and techniques to understand neural models in general, yet there has been little progress towards explaining ranking models. We investigate whether one can explain the behavior of neural ranking models in terms of their congruence with well understood principles of document ranking by using established theories from axiomatic IR. Axiomatic analysis of information retrieval models has formalized a set of constraints on ranking decisions that reasonable retrieval models should fulfill. We operationalize this axiomatic thinking to reproduce rankings based on combinations of elementary constraints. This allows us to investigate to what extent the ranking decisions of neural rankers can be explained in terms of retrieval axioms, and which axioms apply in which situations. Our experimental study considers a comprehensive set of axioms over several representative neural rankers. While the existing axioms can already explain the particularly confident ranking decisions rather well, future work should extend the axiom set to also cover the other still "unexplainable" neural IR rank decisions.