 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TCL: Transformer-based Dynamic Graph Modelling via Contrastive Learning
May 17, 2021
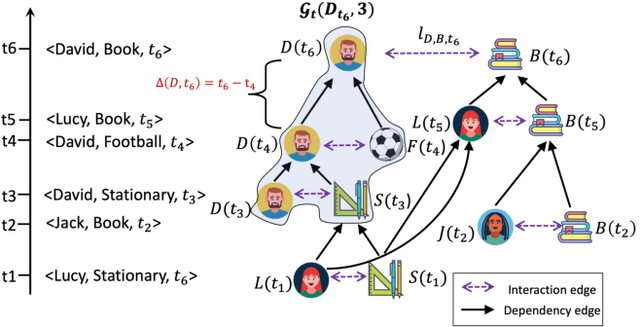
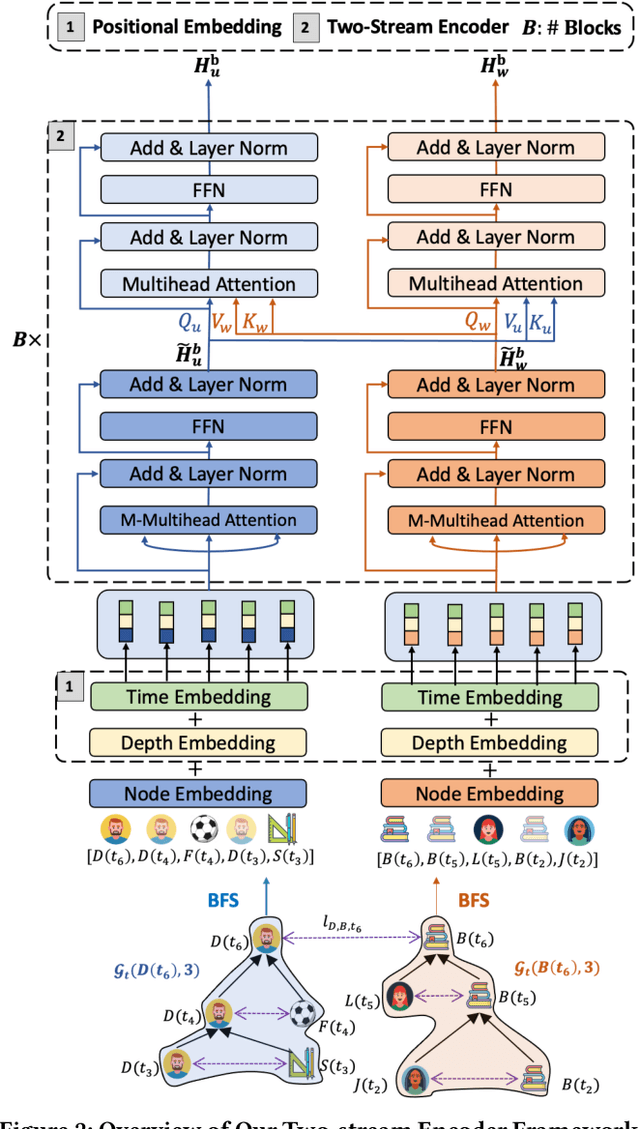
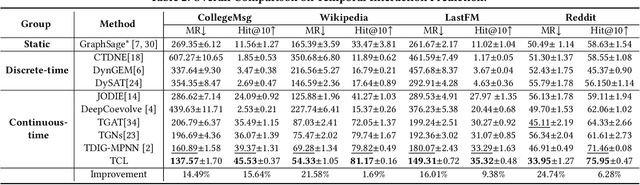
Dynamic graph modeling has recently attracted much attention due to its extensive applications in many real-world scenarios, such as recommendation systems, financial transactions, and social networks. Although many works have been proposed for dynamic graph modeling in recent years, effective and scalable models are yet to be developed. In this paper, we propose a novel graph neural network approach, called TCL, which deals with the dynamically-evolving graph in a continuous-time fashion and enables effective dynamic node representation learning that captures both the temporal and topology information. Technically, our model contains three novel aspects. First, we generalize the vanilla Transformer to temporal graph learning scenarios and design a graph-topology-aware transformer. Secondly, on top of the proposed graph transformer, we introduce a two-stream encoder that separately extracts representations from temporal neighborhoods associated with the two interaction nodes and then utilizes a co-attentional transformer to model inter-dependencies at a semantic level. Lastly, we are inspired by the recently developed contrastive learning and propose to optimize our model by maximizing mutual information (MI) between the predictive representations of two future interaction nodes. Benefiting from this, our dynamic representations can preserve high-level (or global) semantics about interactions and thus is robust to noisy interactions. To the best of our knowledge, this is the first attempt to apply contrastive learning to representation learning on dynamic graphs. We evaluate our model on four benchmark datasets for interaction prediction and experiment results demonstrate the superiority of our model.
Iris Presentation Attack Detection by Attention-based and Deep Pixel-wise Binary Supervision Network
Jun 28, 2021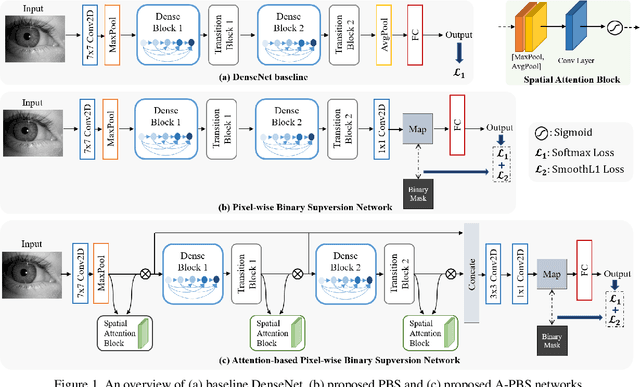
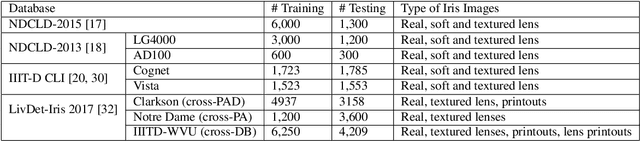
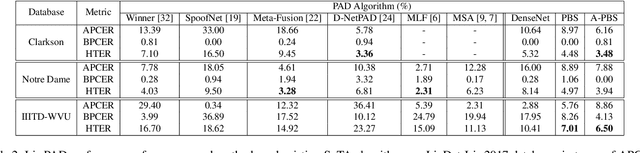
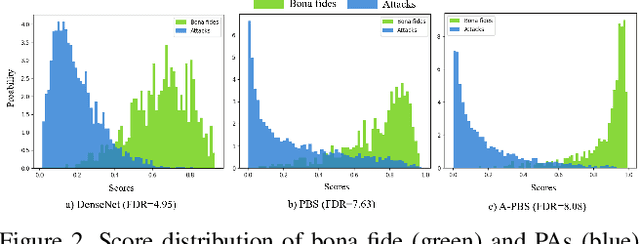
Iris presentation attack detection (PAD) plays a vital role in iris recognition systems. Most existing CNN-based iris PAD solutions 1) perform only binary label supervision during the training of CNNs, serving global information learning but weakening the capture of local discriminative features, 2) prefer the stacked deeper convolutions or expert-designed networks, raising the risk of overfitting, 3) fuse multiple PAD systems or various types of features, increasing difficulty for deployment on mobile devices. Hence, we propose a novel attention-based deep pixel-wise binary supervision (A-PBS) method. Pixel-wise supervision is first able to capture the fine-grained pixel/patch-level cues. Then, the attention mechanism guides the network to automatically find regions that most contribute to an accurate PAD decision. Extensive experiments are performed on LivDet-Iris 2017 and three other publicly available databases to show the effectiveness and robustness of proposed A-PBS methods. For instance, the A-PBS model achieves an HTER of 6.50% on the IIITD-WVU database outperforming state-of-the-art methods.
Centroid Transformers: Learning to Abstract with Attention
Mar 08, 2021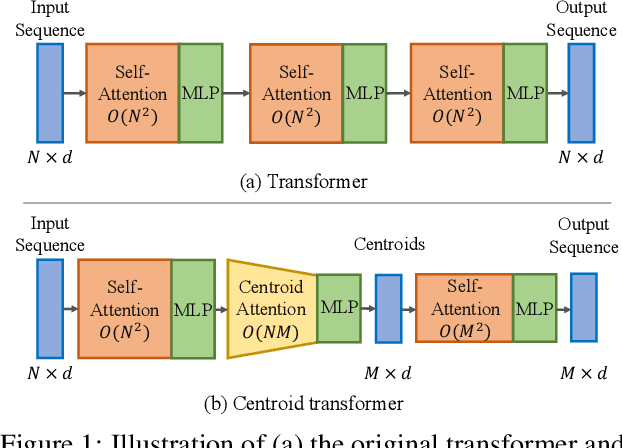

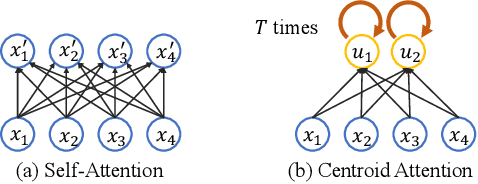
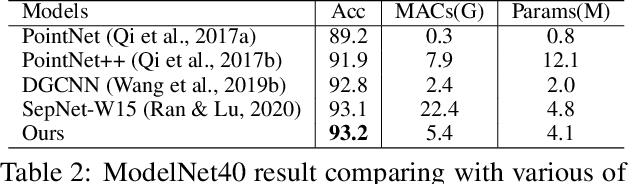
Self-attention, as the key block of transformers, is a powerful mechanism for extracting features from the inputs. In essence, what self-attention does is to infer the pairwise relations between the elements of the inputs, and modify the inputs by propagating information between input pairs. As a result, it maps inputs to N outputs and casts a quadratic $O(N^2)$ memory and time complexity. We propose centroid attention, a generalization of self-attention that maps N inputs to M outputs $(M\leq N)$, such that the key information in the inputs are summarized in the smaller number of outputs (called centroids). We design centroid attention by amortizing the gradient descent update rule of a clustering objective function on the inputs, which reveals an underlying connection between attention and clustering. By compressing the inputs to the centroids, we extract the key information useful for prediction and also reduce the computation of the attention module and the subsequent layers. We apply our method to various applications, including abstractive text summarization, 3D vision, and image processing. Empirical results demonstrate the effectiveness of our method over the standard transformers.
Legal Judgment Prediction with Multi-Stage CaseRepresentation Learning in the Real Court Setting
Jul 12, 2021

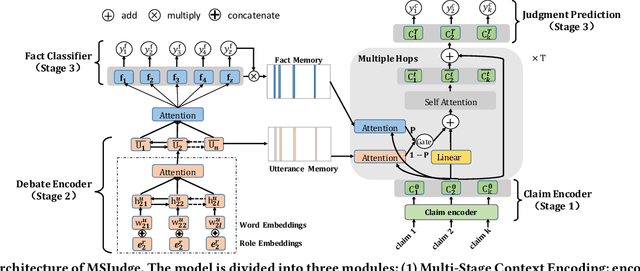
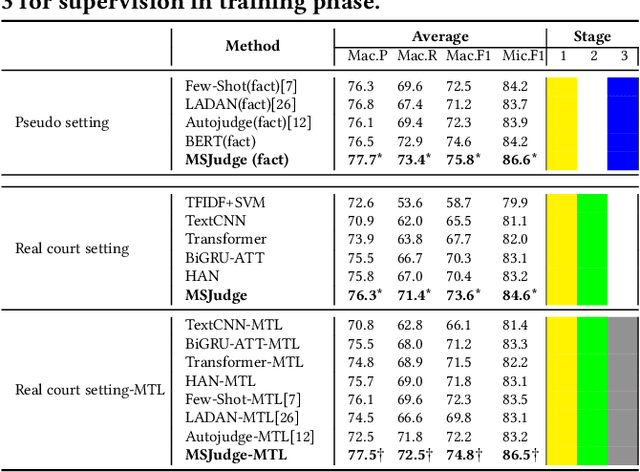
Legal judgment prediction(LJP) is an essential task for legal AI. While prior methods studied on this topic in a pseudo setting by employing the judge-summarized case narrative as the input to predict the judgment, neglecting critical case life-cycle information in real court setting could threaten the case logic representation quality and prediction correctness. In this paper, we introduce a novel challenging dataset from real courtrooms to predict the legal judgment in a reasonably encyclopedic manner by leveraging the genuine input of the case -- plaintiff's claims and court debate data, from which the case's facts are automatically recognized by comprehensively understanding the multi-role dialogues of the court debate, and then learnt to discriminate the claims so as to reach the final judgment through multi-task learning. An extensive set of experiments with a large civil trial data set shows that the proposed model can more accurately characterize the interactions among claims, fact and debate for legal judgment prediction, achieving significant improvements over strong state-of-the-art baselines. Moreover, the user study conducted with real judges and law school students shows the neural predictions can also be interpretable and easily observed, and thus enhancing the trial efficiency and judgment quality.
Hyperspectral Image Classification: Artifacts of Dimension Reduction on Hybrid CNN
Jan 25, 2021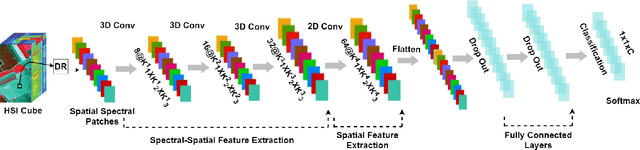
Convolutional Neural Networks (CNN) has been extensively studied for Hyperspectral Image Classification (HSIC) more specifically, 2D and 3D CNN models have proved highly efficient in exploiting the spatial and spectral information of Hyperspectral Images. However, 2D CNN only considers the spatial information and ignores the spectral information whereas 3D CNN jointly exploits spatial-spectral information at a high computational cost. Therefore, this work proposed a lightweight CNN (3D followed by 2D-CNN) model which significantly reduces the computational cost by distributing spatial-spectral feature extraction across a lighter model alongside a preprocessing that has been carried out to improve the classification results. Five benchmark Hyperspectral datasets (i.e., SalinasA, Salinas, Indian Pines, Pavia University, Pavia Center, and Botswana) are used for experimental evaluation. The experimental results show that the proposed pipeline outperformed in terms of generalization performance, statistical significance, and computational complexity, as compared to the state-of-the-art 2D/3D CNN models except commonly used computationally expensive design choices.
Unsupervised Video Prediction from a Single Frame by Estimating 3D Dynamic Scene Structure
Jun 16, 2021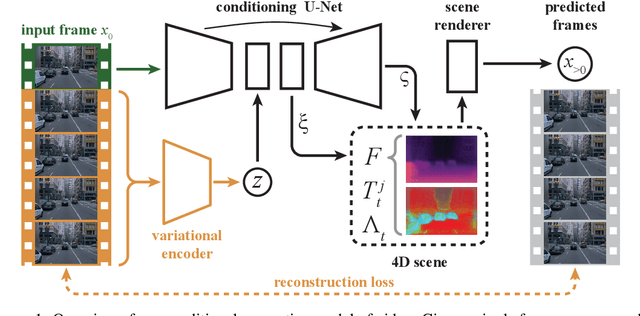
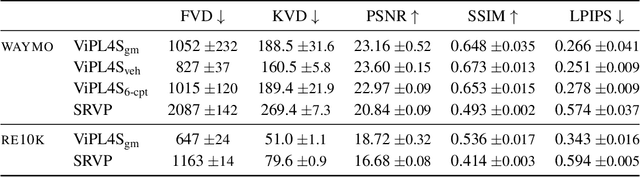

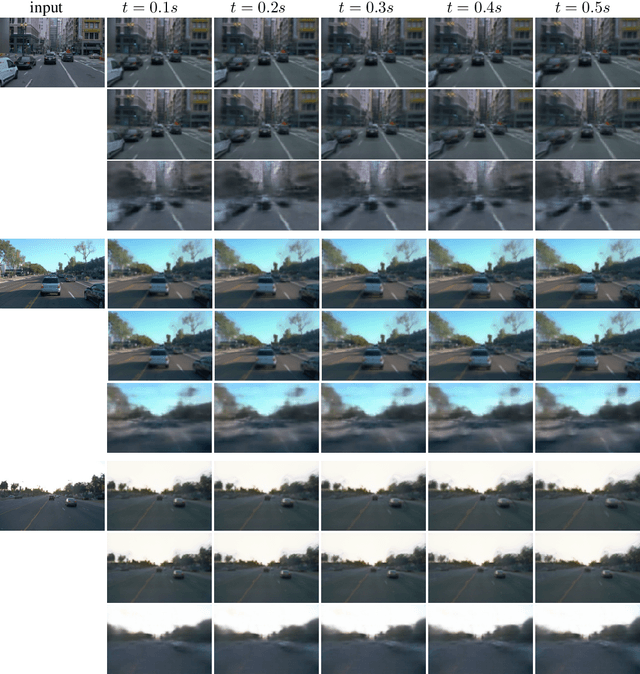
Our goal in this work is to generate realistic videos given just one initial frame as input. Existing unsupervised approaches to this task do not consider the fact that a video typically shows a 3D environment, and that this should remain coherent from frame to frame even as the camera and objects move. We address this by developing a model that first estimates the latent 3D structure of the scene, including the segmentation of any moving objects. It then predicts future frames by simulating the object and camera dynamics, and rendering the resulting views. Importantly, it is trained end-to-end using only the unsupervised objective of predicting future frames, without any 3D information nor segmentation annotations. Experiments on two challenging datasets of natural videos show that our model can estimate 3D structure and motion segmentation from a single frame, and hence generate plausible and varied predictions.
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
Jul 28, 2021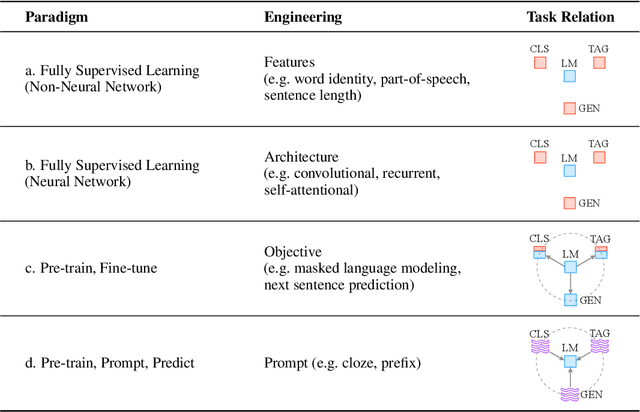
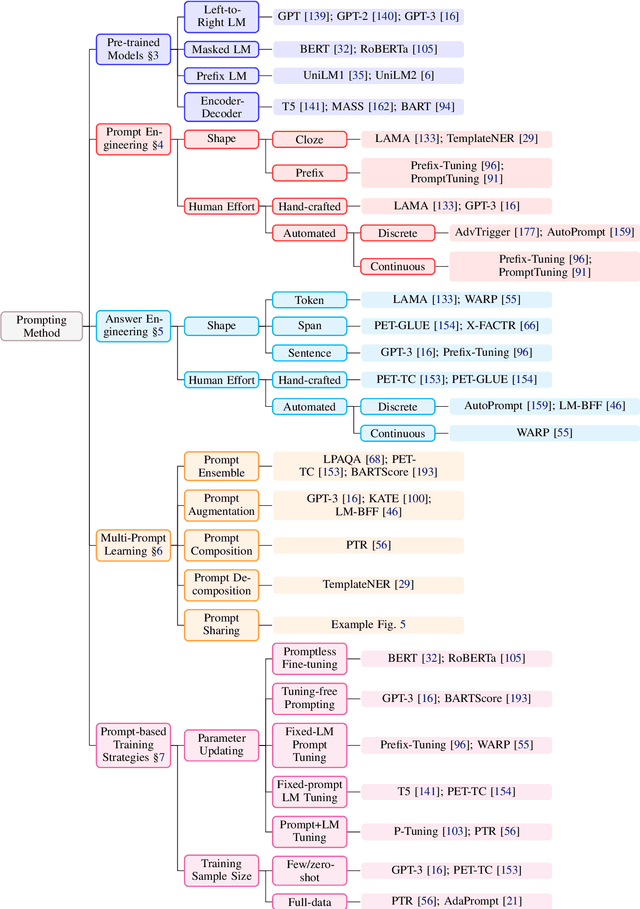
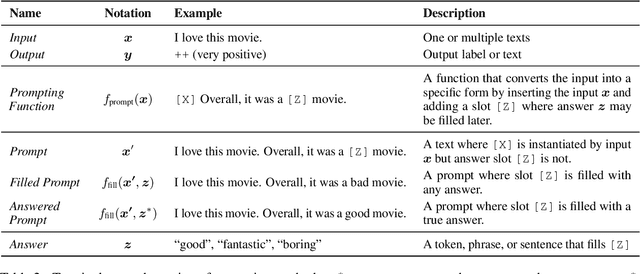
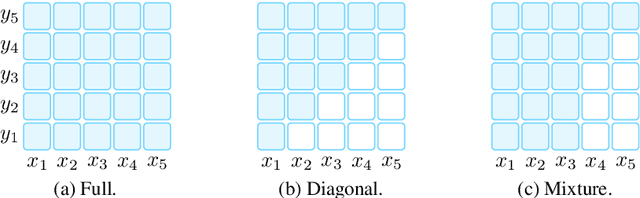
This paper surveys and organizes research works in a new paradigm in natural language processing, which we dub "prompt-based learning". Unlike traditional supervised learning, which trains a model to take in an input x and predict an output y as P(y|x), prompt-based learning is based on language models that model the probability of text directly. To use these models to perform prediction tasks, the original input x is modified using a template into a textual string prompt x' that has some unfilled slots, and then the language model is used to probabilistically fill the unfilled information to obtain a final string x, from which the final output y can be derived. This framework is powerful and attractive for a number of reasons: it allows the language model to be pre-trained on massive amounts of raw text, and by defining a new prompting function the model is able to perform few-shot or even zero-shot learning, adapting to new scenarios with few or no labeled data. In this paper we introduce the basics of this promising paradigm, describe a unified set of mathematical notations that can cover a wide variety of existing work, and organize existing work along several dimensions, e.g.the choice of pre-trained models, prompts, and tuning strategies. To make the field more accessible to interested beginners, we not only make a systematic review of existing works and a highly structured typology of prompt-based concepts, but also release other resources, e.g., a website http://pretrain.nlpedia.ai/ including constantly-updated survey, and paperlist.
EA-Net: Edge-Aware Network for Flow-based Video Frame Interpolation
May 17, 2021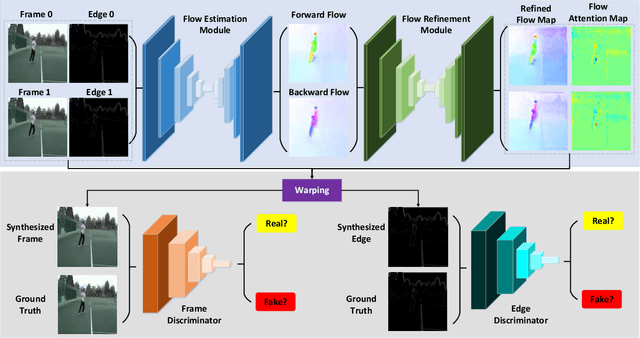



Video frame interpolation can up-convert the frame rate and enhance the video quality. In recent years, although the interpolation performance has achieved great success, image blur usually occurs at the object boundaries owing to the large motion. It has been a long-standing problem, and has not been addressed yet. In this paper, we propose to reduce the image blur and get the clear shape of objects by preserving the edges in the interpolated frames. To this end, the proposed Edge-Aware Network (EA-Net) integrates the edge information into the frame interpolation task. It follows an end-to-end architecture and can be separated into two stages, \emph{i.e.}, edge-guided flow estimation and edge-protected frame synthesis. Specifically, in the flow estimation stage, three edge-aware mechanisms are developed to emphasize the frame edges in estimating flow maps, so that the edge-maps are taken as the auxiliary information to provide more guidance to boost the flow accuracy. In the frame synthesis stage, the flow refinement module is designed to refine the flow map, and the attention module is carried out to adaptively focus on the bidirectional flow maps when synthesizing the intermediate frames. Furthermore, the frame and edge discriminators are adopted to conduct the adversarial training strategy, so as to enhance the reality and clarity of synthesized frames. Experiments on three benchmarks, including Vimeo90k, UCF101 for single-frame interpolation and Adobe240-fps for multi-frame interpolation, have demonstrated the superiority of the proposed EA-Net for the video frame interpolation task.
Hierarchical RNNs-Based Transformers MADDPG for Mixed Cooperative-Competitive Environments
May 11, 2021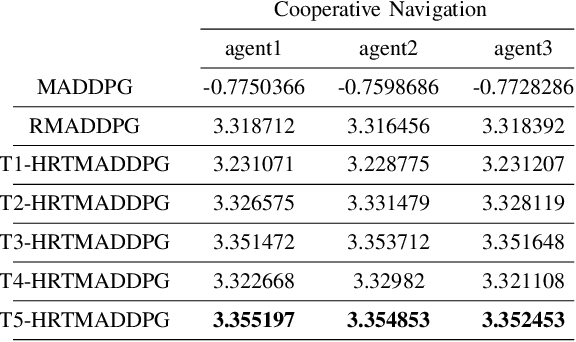
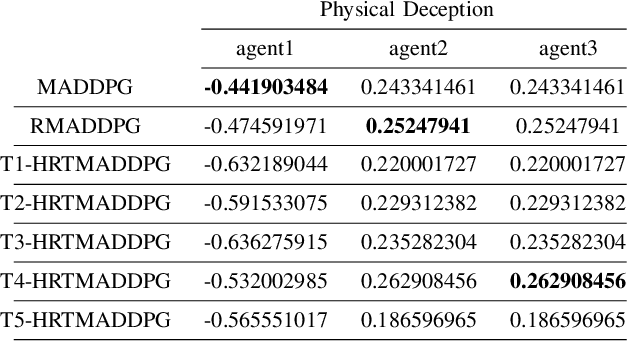
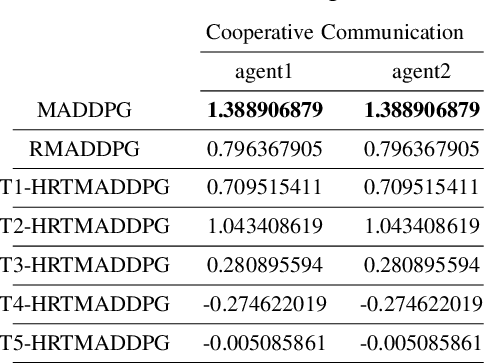
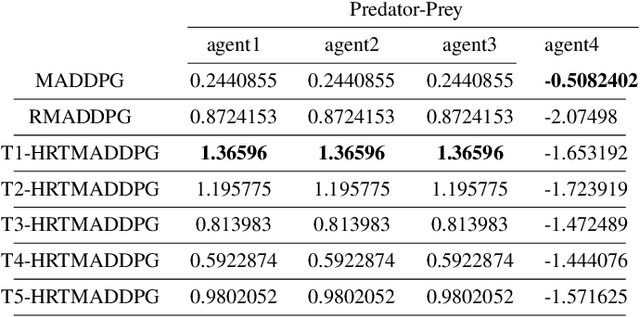
At present, attention mechanism has been widely applied to the fields of deep learning models. Structural models that based on attention mechanism can not only record the relationships between features position, but also can measure the importance of different features based on their weights. By establishing dynamically weighted parameters for choosing relevant and irrelevant features, the key information can be strengthened, and the irrelevant information can be weakened. Therefore, the efficiency of deep learning algorithms can be significantly elevated and improved. Although transformers have been performed very well in many fields including reinforcement learning, there are still many problems and applications can be solved and made with transformers within this area. MARL (known as Multi-Agent Reinforcement Learning) can be recognized as a set of independent agents trying to adapt and learn through their way to reach the goal. In order to emphasize the relationship between each MDP decision in a certain time period, we applied the hierarchical coding method and validated the effectiveness of this method. This paper proposed a hierarchical transformers MADDPG based on RNN which we call it Hierarchical RNNs-Based Transformers MADDPG(HRTMADDPG). It consists of a lower level encoder based on RNNs that encodes multiple step sizes in each time sequence, and it also consists of an upper sequence level encoder based on transformer for learning the correlations between multiple sequences so that we can capture the causal relationship between sub-time sequences and make HRTMADDPG more efficient.
Temporal Information Extraction by Predicting Relative Time-lines
Aug 28, 2018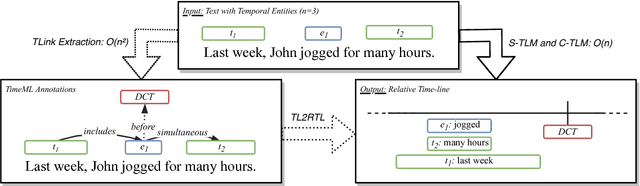
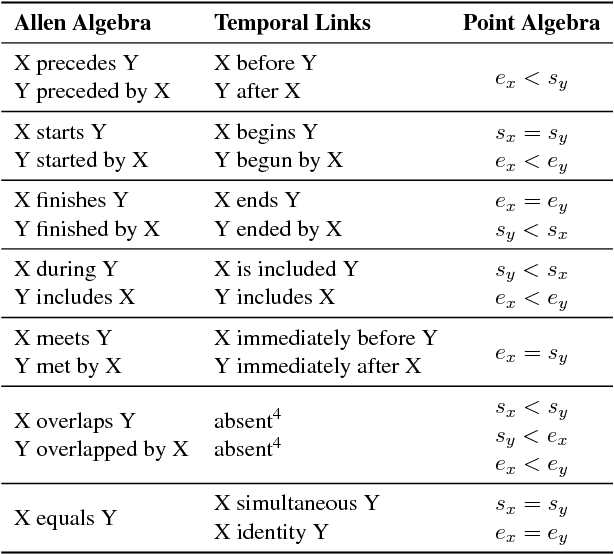
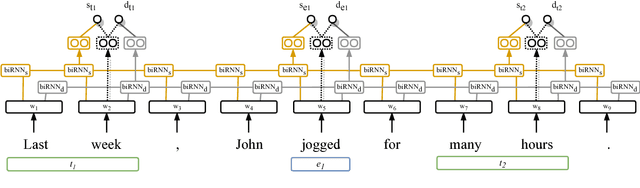

The current leading paradigm for temporal information extraction from text consists of three phases: (1) recognition of events and temporal expressions, (2) recognition of temporal relations among them, and (3) time-line construction from the temporal relations. In contrast to the first two phases, the last phase, time-line construction, received little attention and is the focus of this work. In this paper, we propose a new method to construct a linear time-line from a set of (extracted) temporal relations. But more importantly, we propose a novel paradigm in which we directly predict start and end-points for events from the text, constituting a time-line without going through the intermediate step of prediction of temporal relations as in earlier work. Within this paradigm, we propose two models that predict in linear complexity, and a new training loss using TimeML-style annotations, yielding promising results.