 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Long-Short Temporal Modeling for Efficient Action Recognition
Jun 30, 2021

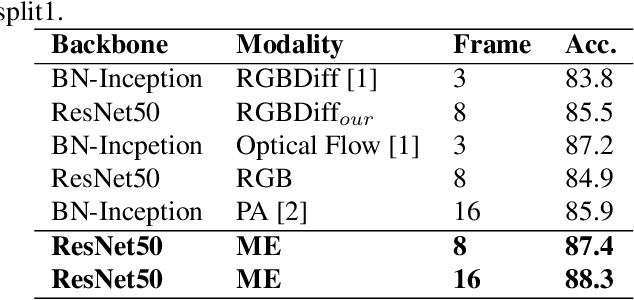
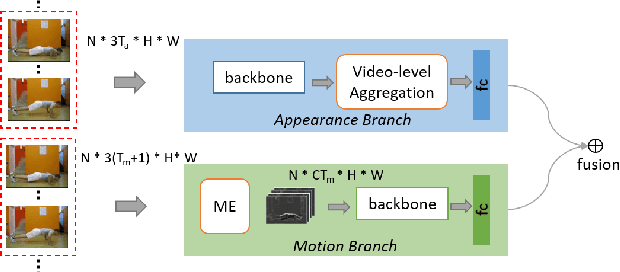
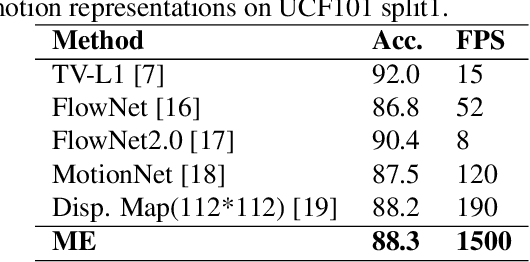
Efficient long-short temporal modeling is key for enhancing the performance of action recognition task. In this paper, we propose a new two-stream action recognition network, termed as MENet, consisting of a Motion Enhancement (ME) module and a Video-level Aggregation (VLA) module to achieve long-short temporal modeling. Specifically, motion representations have been proved effective in capturing short-term and high-frequency action. However, current motion representations are calculated from adjacent frames, which may have poor interpretation and bring useless information (noisy or blank). Thus, for short-term motions, we design an efficient ME module to enhance the short-term motions by mingling the motion saliency among neighboring segments. As for long-term aggregations, VLA is adopted at the top of the appearance branch to integrate the long-term dependencies across all segments. The two components of MENet are complementary in temporal modeling. Extensive experiments are conducted on UCF101 and HMDB51 benchmarks, which verify the effectiveness and efficiency of our proposed MENet.
Hierarchical Architectures in Reservoir Computing Systems
May 14, 2021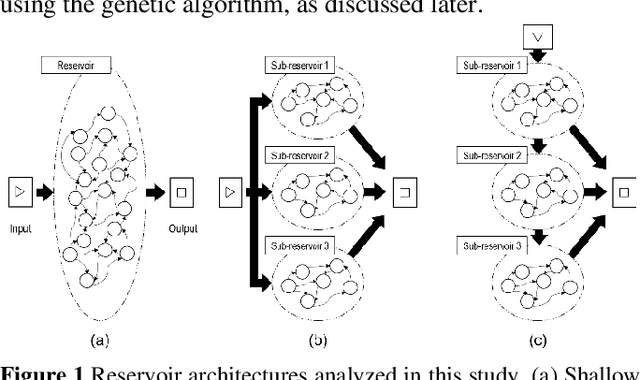
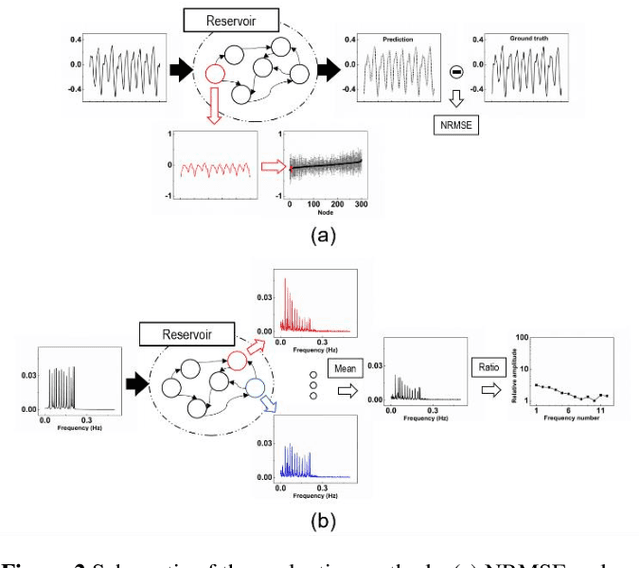
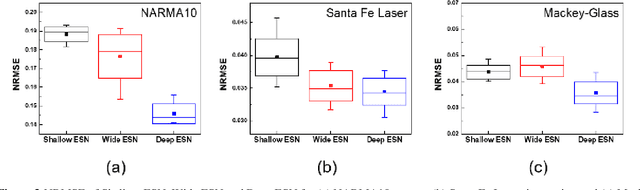
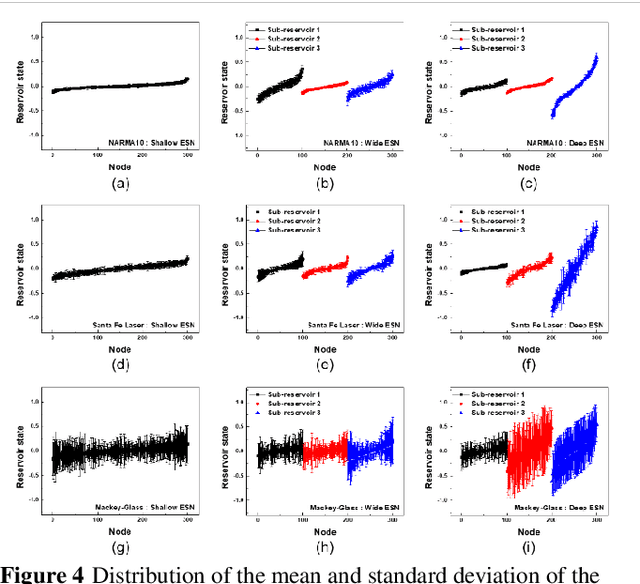
Reservoir computing (RC) offers efficient temporal data processing with a low training cost by separating recurrent neural networks into a fixed network with recurrent connections and a trainable linear network. The quality of the fixed network, called reservoir, is the most important factor that determines the performance of the RC system. In this paper, we investigate the influence of the hierarchical reservoir structure on the properties of the reservoir and the performance of the RC system. Analogous to deep neural networks, stacking sub-reservoirs in series is an efficient way to enhance the nonlinearity of data transformation to high-dimensional space and expand the diversity of temporal information captured by the reservoir. These deep reservoir systems offer better performance when compared to simply increasing the size of the reservoir or the number of sub-reservoirs. Low frequency components are mainly captured by the sub-reservoirs in later stage of the deep reservoir structure, similar to observations that more abstract information can be extracted by layers in the late stage of deep neural networks. When the total size of the reservoir is fixed, tradeoff between the number of sub-reservoirs and the size of each sub-reservoir needs to be carefully considered, due to the degraded ability of individual sub-reservoirs at small sizes. Improved performance of the deep reservoir structure alleviates the difficulty of implementing the RC system on hardware systems.
A causal learning framework for the analysis and interpretation of COVID-19 clinical data
May 14, 2021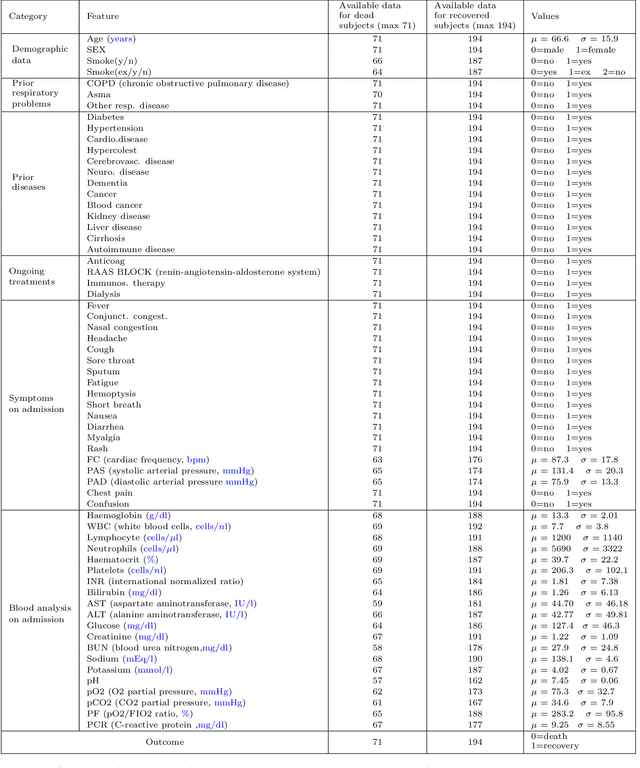
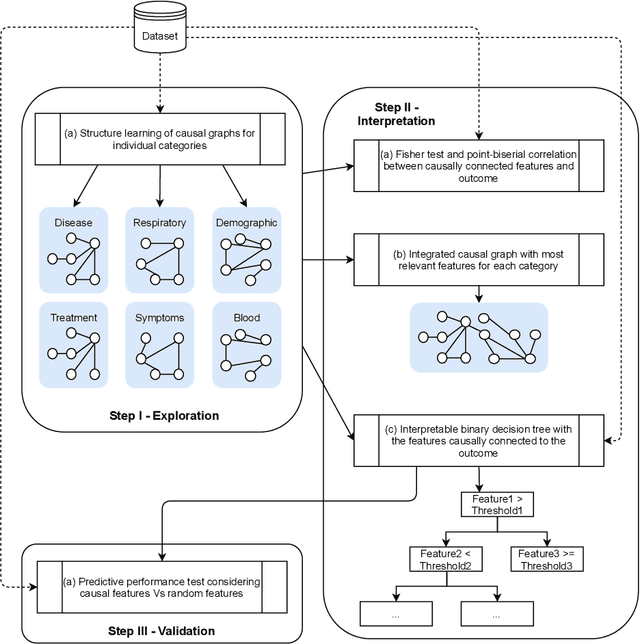
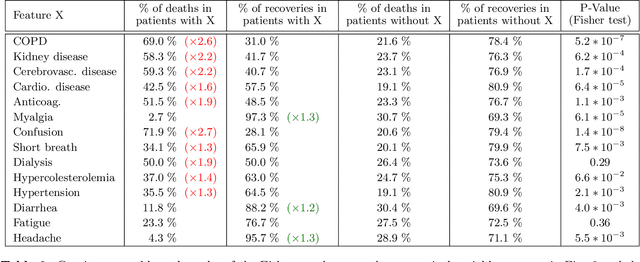
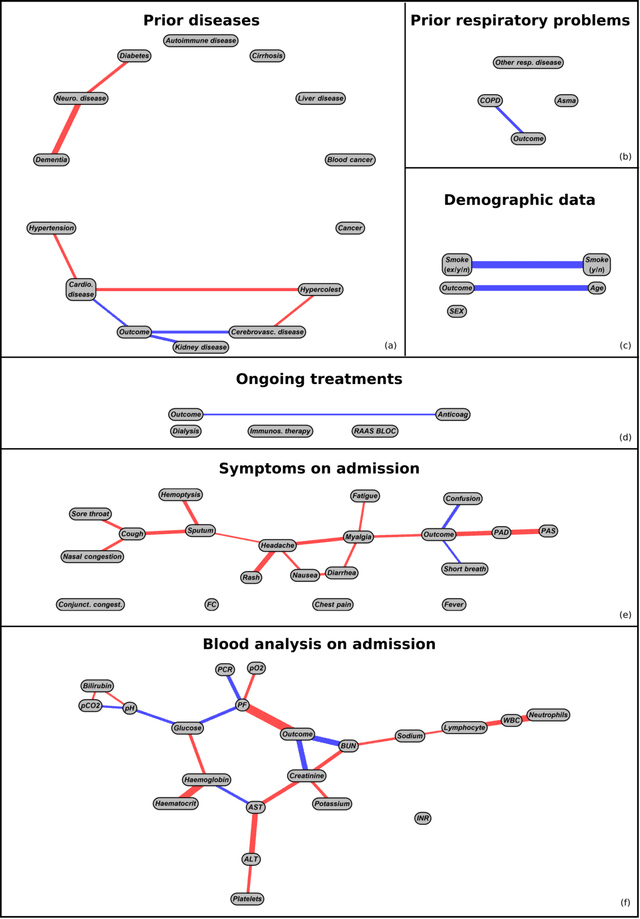
We present a workflow for clinical data analysis that relies on Bayesian Structure Learning (BSL), an unsupervised learning approach, robust to noise and biases, that allows to incorporate prior medical knowledge into the learning process and that provides explainable results in the form of a graph showing the causal connections among the analyzed features. The workflow consists in a multi-step approach that goes from identifying the main causes of patient's outcome through BSL, to the realization of a tool suitable for clinical practice, based on a Binary Decision Tree (BDT), to recognize patients at high-risk with information available already at hospital admission time. We evaluate our approach on a feature-rich COVID-19 dataset, showing that the proposed framework provides a schematic overview of the multi-factorial processes that jointly contribute to the outcome. We discuss how these computational findings are confirmed by current understanding of the COVID-19 pathogenesis. Further, our approach yields to a highly interpretable tool correctly predicting the outcome of 85% of subjects based exclusively on 3 features: age, a previous history of chronic obstructive pulmonary disease and the PaO2/FiO2 ratio at the time of arrival to the hospital. The inclusion of additional information from 4 routine blood tests (Creatinine, Glucose, pO2 and Sodium) increases predictive accuracy to 94.5%.
Nearest Neighborhood-Based Deep Clustering for Source Data-absent Unsupervised Domain Adaptation
Jul 27, 2021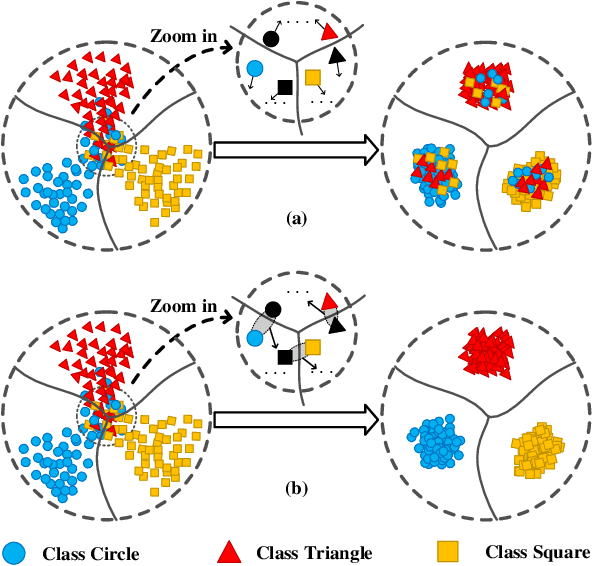
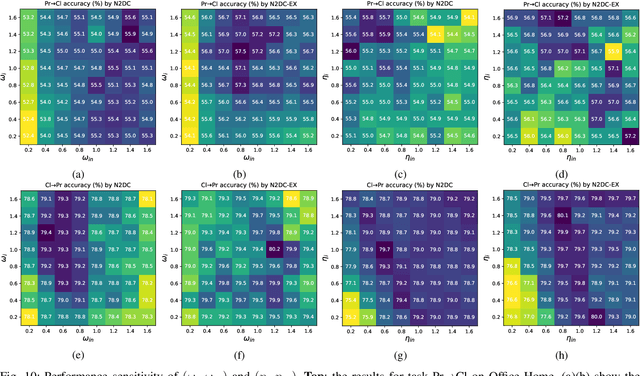
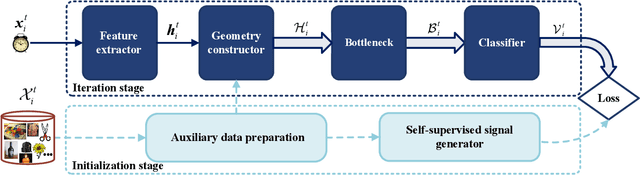
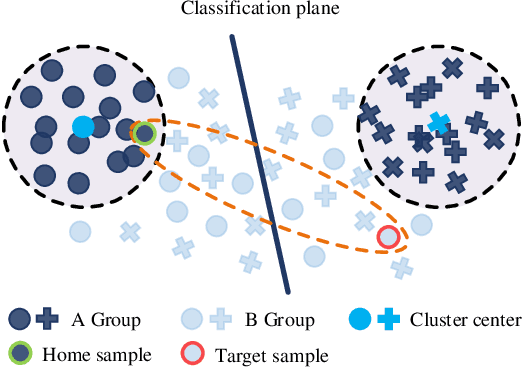
In the classic setting of unsupervised domain adaptation (UDA), the labeled source data are available in the training phase. However, in many real-world scenarios, owing to some reasons such as privacy protection and information security, the source data is inaccessible, and only a model trained on the source domain is available. This paper proposes a novel deep clustering method for this challenging task. Aiming at the dynamical clustering at feature-level, we introduce extra constraints hidden in the geometric structure between data to assist the process. Concretely, we propose a geometry-based constraint, named semantic consistency on the nearest neighborhood (SCNNH), and use it to encourage robust clustering. To reach this goal, we construct the nearest neighborhood for every target data and take it as the fundamental clustering unit by building our objective on the geometry. Also, we develop a more SCNNH-compliant structure with an additional semantic credibility constraint, named semantic hyper-nearest neighborhood (SHNNH). After that, we extend our method to this new geometry. Extensive experiments on three challenging UDA datasets indicate that our method achieves state-of-the-art results. The proposed method has significant improvement on all datasets (as we adopt SHNNH, the average accuracy increases by over 3.0\% on the large-scaled dataset). Code is available at https://github.com/tntek/N2DCX.
Learning to Cluster Faces via Transformer
Apr 23, 2021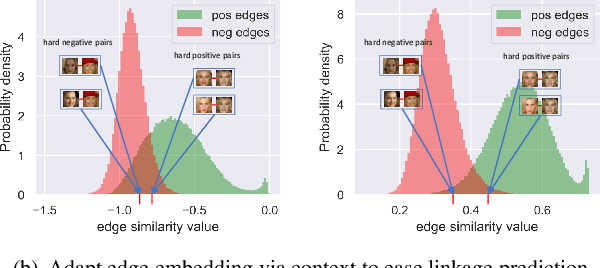
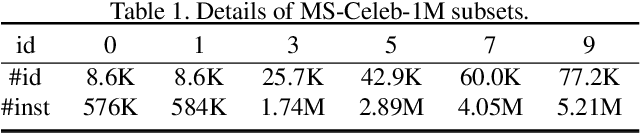
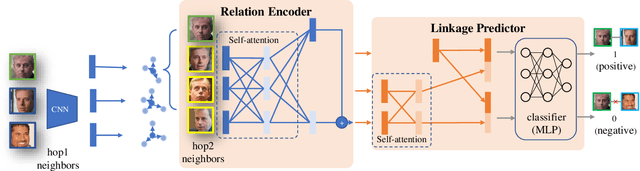
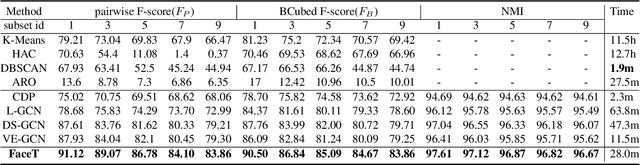
Face clustering is a useful tool for applications like automatic face annotation and retrieval. The main challenge is that it is difficult to cluster images from the same identity with different face poses, occlusions, and image quality. Traditional clustering methods usually ignore the relationship between individual images and their neighbors which may contain useful context information. In this paper, we repurpose the well-known Transformer and introduce a Face Transformer for supervised face clustering. In Face Transformer, we decompose the face clustering into two steps: relation encoding and linkage predicting. Specifically, given a face image, a \textbf{relation encoder} module aggregates local context information from its neighbors and a \textbf{linkage predictor} module judges whether a pair of images belong to the same cluster or not. In the local linkage graph view, Face Transformer can generate more robust node and edge representations compared to existing methods. Experiments on both MS-Celeb-1M and DeepFashion show that our method achieves state-of-the-art performance, e.g., 91.12\% in pairwise F-score on MS-Celeb-1M.
Sequential convolutional network for behavioral pattern extraction in gait recognition
Apr 23, 2021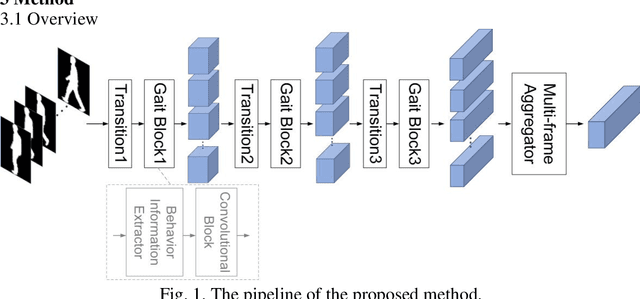
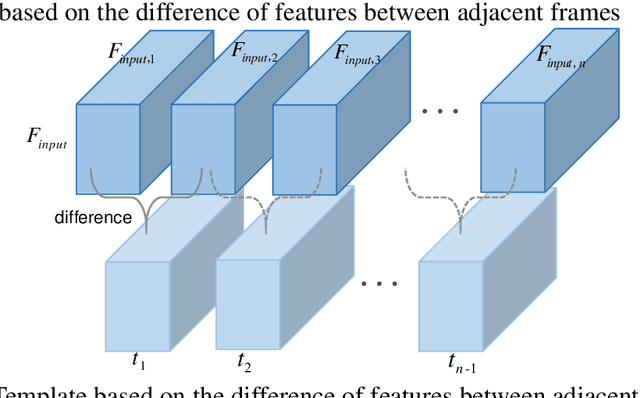
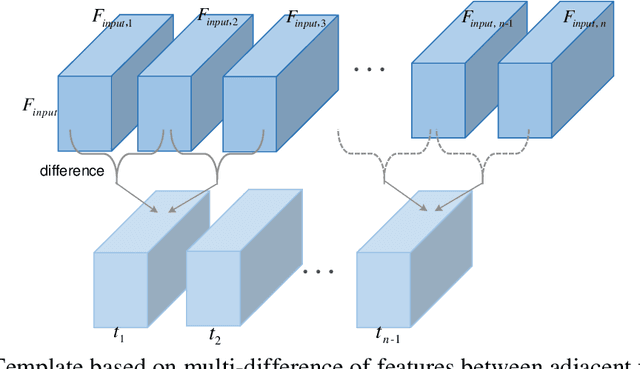
As a unique and promising biometric, video-based gait recognition has broad applications. The key step of this methodology is to learn the walking pattern of individuals, which, however, often suffers challenges to extract the behavioral feature from a sequence directly. Most existing methods just focus on either the appearance or the motion pattern. To overcome these limitations, we propose a sequential convolutional network (SCN) from a novel perspective, where spatiotemporal features can be learned by a basic convolutional backbone. In SCN, behavioral information extractors (BIE) are constructed to comprehend intermediate feature maps in time series through motion templates where the relationship between frames can be analyzed, thereby distilling the information of the walking pattern. Furthermore, a multi-frame aggregator in SCN performs feature integration on a sequence whose length is uncertain, via a mobile 3D convolutional layer. To demonstrate the effectiveness, experiments have been conducted on two popular public benchmarks, CASIA-B and OU-MVLP, and our approach is demonstrated superior performance, comparing with the state-of-art methods.
Augmented Tensor Decomposition with Stochastic Optimization
Jul 14, 2021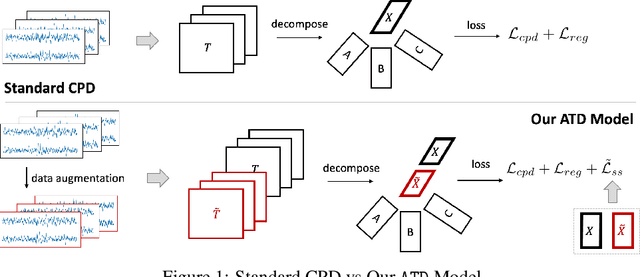

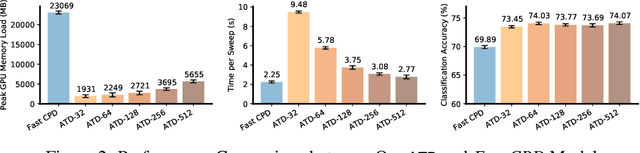
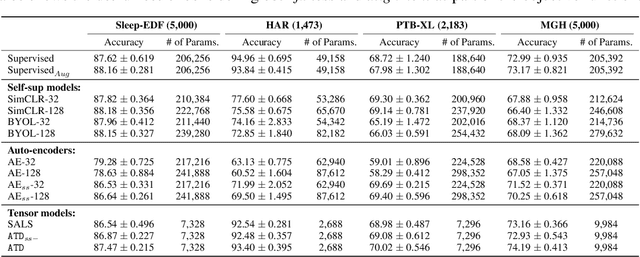
Tensor decompositions are powerful tools for dimensionality reduction and feature interpretation of multidimensional data such as signals. Existing tensor decomposition objectives (e.g., Frobenius norm) are designed for fitting raw data under statistical assumptions, which may not align with downstream classification tasks. Also, real-world tensor data are usually high-ordered and have large dimensions with millions or billions of entries. Thus, it is expensive to decompose the whole tensor with traditional algorithms. In practice, raw tensor data also contains redundant information while data augmentation techniques may be used to smooth out noise in samples. This paper addresses the above challenges by proposing augmented tensor decomposition (ATD), which effectively incorporates data augmentations to boost downstream classification. To reduce the memory footprint of the decomposition, we propose a stochastic algorithm that updates the factor matrices in a batch fashion. We evaluate ATD on multiple signal datasets. It shows comparable or better performance (e.g., up to 15% in accuracy) over self-supervised and autoencoder baselines with less than 5% of model parameters, achieves 0.6% ~ 1.3% accuracy gain over other tensor-based baselines, and reduces the memory footprint by 9X when compared to standard tensor decomposition algorithms.
Metapaths guided Neighbors aggregated Network for?Heterogeneous Graph Reasoning
Mar 11, 2021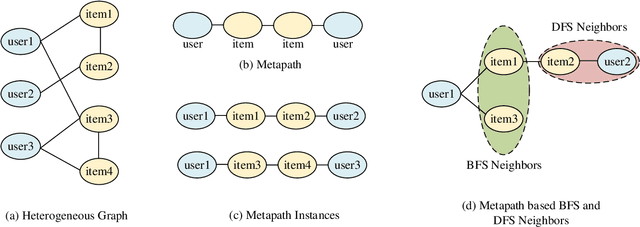
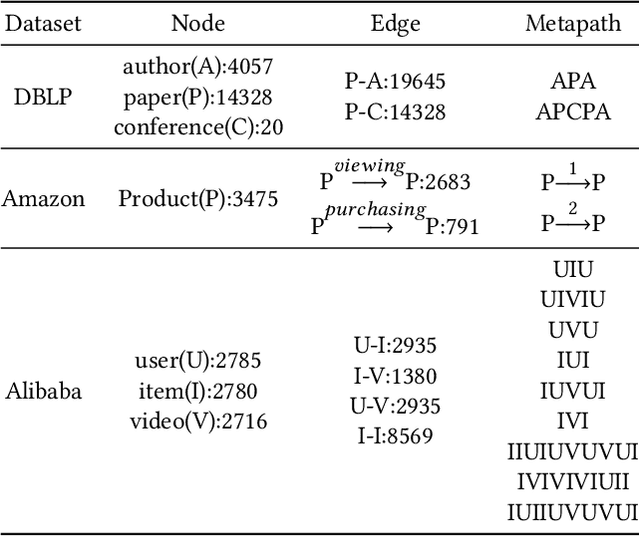
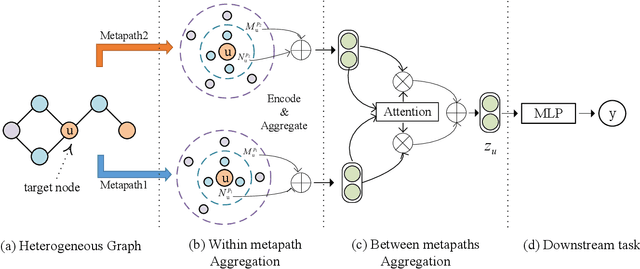
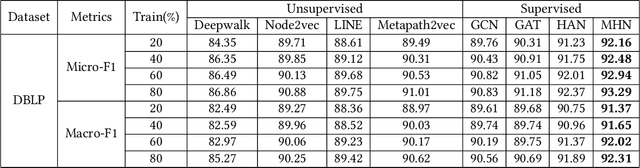
Most real-world datasets are inherently heterogeneous graphs, which involve a diversity of node and relation types. Heterogeneous graph embedding is to learn the structure and semantic information from the graph, and then embed it into the low-dimensional node representation. Existing methods usually capture the composite relation of a heterogeneous graph by defining metapath, which represent a semantic of the graph. However, these methods either ignore node attributes, or discard the local and global information of the graph, or only consider one metapath. To address these limitations, we propose a Metapaths-guided Neighbors-aggregated Heterogeneous Graph Neural Network(MHN) to improve performance. Specially, MHN employs node base embedding to encapsulate node attributes, BFS and DFS neighbors aggregation within a metapath to capture local and global information, and metapaths aggregation to combine different semantics of the heterogeneous graph. We conduct extensive experiments for the proposed MHN on three real-world heterogeneous graph datasets, including node classification, link prediction and online A/B test on Alibaba mobile application. Results demonstrate that MHN performs better than other state-of-the-art baselines.
M3D-VTON: A Monocular-to-3D Virtual Try-On Network
Aug 11, 2021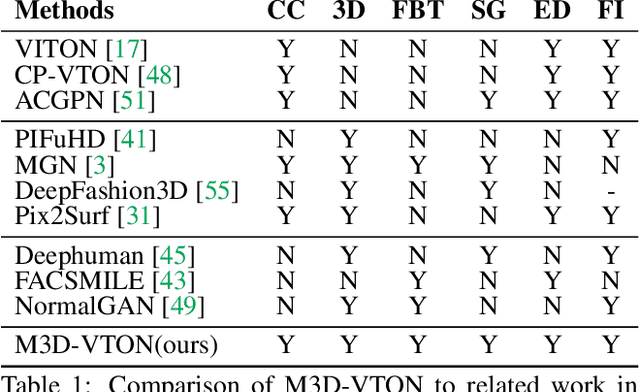
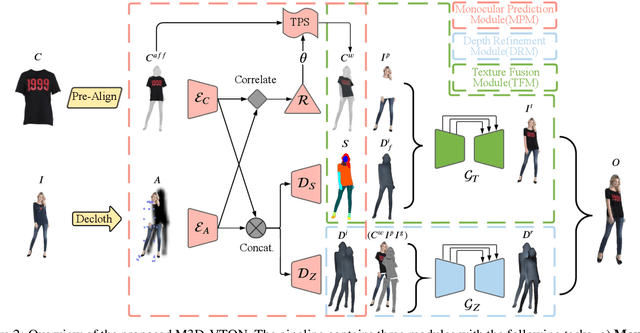
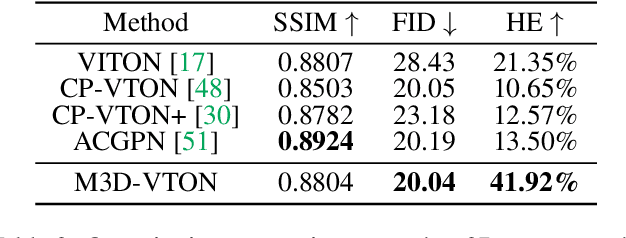
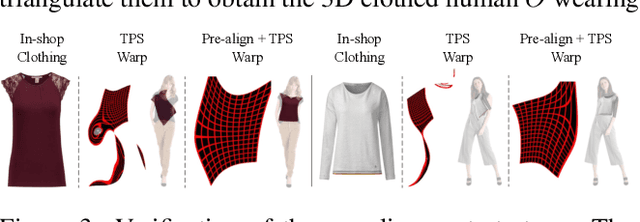
Virtual 3D try-on can provide an intuitive and realistic view for online shopping and has a huge potential commercial value. However, existing 3D virtual try-on methods mainly rely on annotated 3D human shapes and garment templates, which hinders their applications in practical scenarios. 2D virtual try-on approaches provide a faster alternative to manipulate clothed humans, but lack the rich and realistic 3D representation. In this paper, we propose a novel Monocular-to-3D Virtual Try-On Network (M3D-VTON) that builds on the merits of both 2D and 3D approaches. By integrating 2D information efficiently and learning a mapping that lifts the 2D representation to 3D, we make the first attempt to reconstruct a 3D try-on mesh only taking the target clothing and a person image as inputs. The proposed M3D-VTON includes three modules: 1) The Monocular Prediction Module (MPM) that estimates an initial full-body depth map and accomplishes 2D clothes-person alignment through a novel two-stage warping procedure; 2) The Depth Refinement Module (DRM) that refines the initial body depth to produce more detailed pleat and face characteristics; 3) The Texture Fusion Module (TFM) that fuses the warped clothing with the non-target body part to refine the results. We also construct a high-quality synthesized Monocular-to-3D virtual try-on dataset, in which each person image is associated with a front and a back depth map. Extensive experiments demonstrate that the proposed M3D-VTON can manipulate and reconstruct the 3D human body wearing the given clothing with compelling details and is more efficient than other 3D approaches.
Embedding Adaptation is Still Needed for Few-Shot Learning
Apr 15, 2021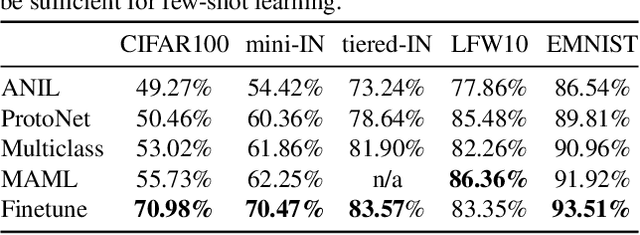
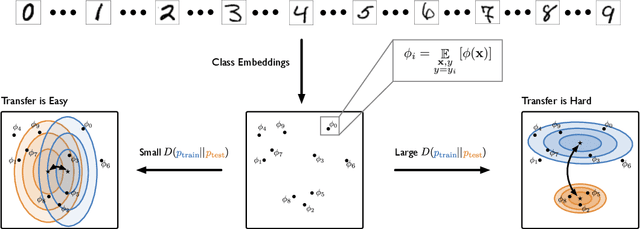
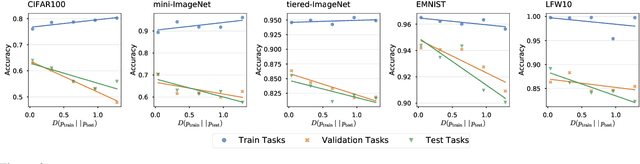
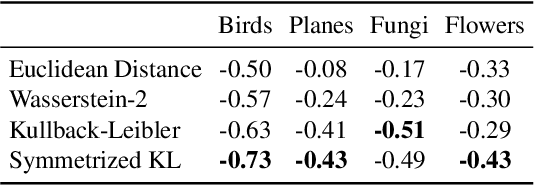
Constructing new and more challenging tasksets is a fruitful methodology to analyse and understand few-shot classification methods. Unfortunately, existing approaches to building those tasksets are somewhat unsatisfactory: they either assume train and test task distributions to be identical -- which leads to overly optimistic evaluations -- or take a "worst-case" philosophy -- which typically requires additional human labor such as obtaining semantic class relationships. We propose ATG, a principled clustering method to defining train and test tasksets without additional human knowledge. ATG models train and test task distributions while requiring them to share a predefined amount of information. We empirically demonstrate the effectiveness of ATG in generating tasksets that are easier, in-between, or harder than existing benchmarks, including those that rely on semantic information. Finally, we leverage our generated tasksets to shed a new light on few-shot classification: gradient-based methods -- previously believed to underperform -- can outperform metric-based ones when transfer is most challenging.